
programa
Fundamentos de la Gobernanza de Datos
10 h
Garantiza el cumplimiento y protege tu empresa con DataCamp para empresas. Cursos especializados y seguimiento centralizado para salvaguardar tus datos.

En ciencia de datos, la anonimización de datos se refiere al proceso de modificar un conjunto de datos de forma que resulte imposible o muy difícil identificar a los individuos basándose en los datos disponibles.
En esencia, el proceso de anonimización de datos consiste en eliminar o transformar la información personal identificable (IPI) de los conjuntos de datos, como nombres y direcciones, conservando la utilidad de los datos para el análisis.
También minimiza el riesgo de fuga de datos y de reidentificación, permitiéndonos compartir y analizar datos de forma segura sin comprometer la privacidad individual.
Un caso famoso de proceso de anonimización de datos no riguroso ocurrió en 2006, cuando Netflix publicó un conjunto de datos de películas con datos de usuarios como parte del concurso Premio Netflix, cuyo objetivo era mejorar su sistema de recomendaciones.
Investigadores de la Universidad de Texas demostraron la vulnerabilidad de los datos anonimizados volviendo a identificar a personas utilizando datos de IMDb disponibles públicamente. Este incidente suscitó una gran preocupación sobre la eficacia de las técnicas de anonimización de datos y puso de relieve la necesidad de enfoques más meticulosos.
Eliminar las IPI no es el único enfoque para la anonimización de datos. En algunos casos, los datos también pueden generalizarse para reducir la unicidad de los individuos de un conjunto de datos. Un ejemplo de ello es sustituir las edades exactas por intervalos de edad. Además, los datos también pueden alterarse introduciendo ligeras inexactitudes, lo que hace más difícil relacionar los nuevos datos con un individuo.
Conocer las distintas técnicas de anonimización de datos puede ayudarnos a seleccionar la más adecuada para nuestro caso de uso. En esta sección, exploraremos las más comunes.
Como ya se ha dicho, la anonimización de datos no consiste sólo en eliminar las IPI. En lugar de eliminar los datos, la generalización los transforma en una forma más amplia y menos identificable. En otras palabras, la generalización reduce la granularidad de los datos para evitar la identificación. Esto permite que los datos sigan siendo útiles para el análisis, al tiempo que se reduce el riesgo de reidentificación.
Por ejemplo, cuando se trata de datos personales como la fecha de nacimiento, en lugar de mostrar la fecha exacta de nacimiento, los datos se generalizan al mes y al año, o sólo al año, para evitar la identificación y mantener al mismo tiempo el grupo de edad relevante para el análisis. Las tablas siguientes muestran algunos ejemplos sencillos de anonimización de datos mediante la generalización de la edad y la ubicación:
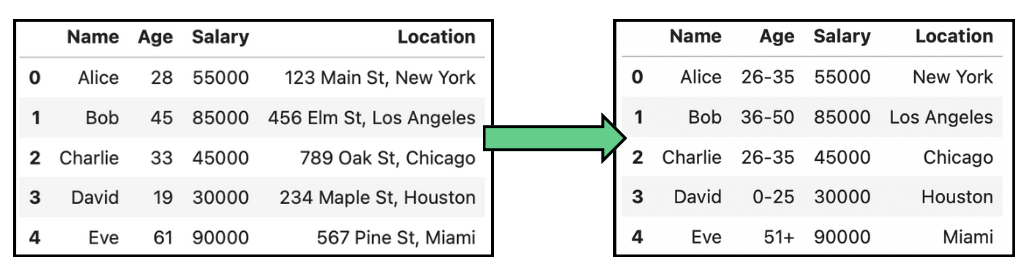
Ejemplo de anonimización de datos por generalización en datos de edad y localización.
Esta técnica se utiliza sobre todo en estudios demográficos y de mercado, pero puede provocar una pérdida de utilidad de los datos, lo que dificulta el análisis detallado.
La generalización se utiliza a menudo junto con otras técnicas como K-Anonimatoen la que se generalizan varios registros hasta que no puedan distinguirse de al menos otros k registros, reduciendo el riesgo de reidentificación de los individuos.
En los análisis en los que no se necesitan puntos de datos individuales precisos, sino la distribución global, se puede aplicar la perturbación de datos. Se refiere al proceso de modificar los datos originales de forma controlada para proteger la privacidad. Esta modificación puede incluir varias técnicas como la aleatorización, el escalado o el intercambio de valores. La perturbación de datos pretende oscurecer los datos conservando su utilidad para el análisis.
Un caso concreto de perturbación de datos es la adición de ruido. La adición de ruido consiste en introducir cambios aleatorios o sistemáticos, el llamado "ruido", en los datos. Este ruido oscurece los verdaderos valores de los puntos de datos sensibles, dificultando la reidentificación de los individuos. En la imagen siguiente, hemos modificado los salarios originales que aparecen en las tablas anteriores añadiendo ruido gaussiano:
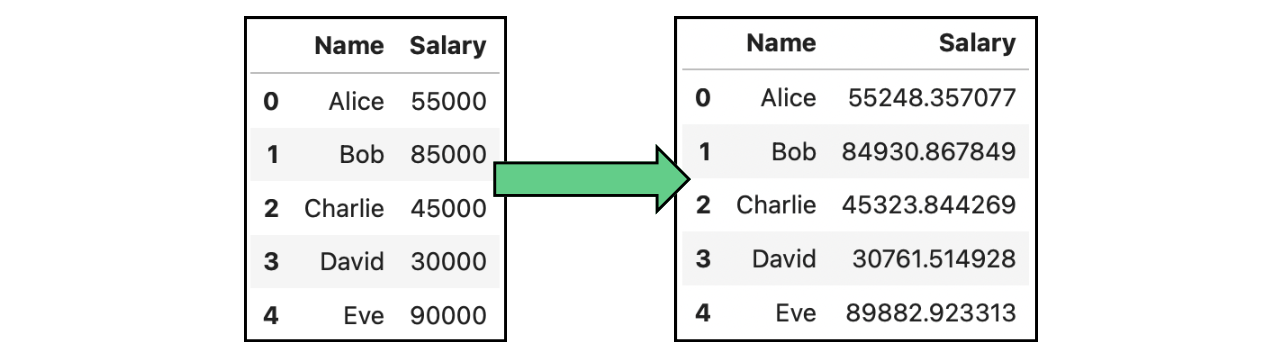
Ejemplo de anonimización de datos por adición de ruido datos que contienen salarios.
En lugar de añadir ruido a los datos reales, otro enfoque de la anonimización de datos consiste en generar datos falsos, en determinadas condiciones. Lageneración de datos sintéticos es el proceso de creación de conjuntos de datos artificiales que reproducen las propiedades estadísticas de los datos originales sin incluir información real e identificable. Sirve como alternativa para analizar un conjunto de datos respetuoso con la privacidad que imita los patrones y la estructura del original.
El proceso de generar datos con la misma distribución requiere un modelado estadístico para identificar los patrones, las relaciones y las distribuciones que necesitamos reproducir. En general, la generación de datos sintéticos es más difícil de implementar.
Te recomiendo que consultes los siguientes recursos para saber más:
La seudonimización implica sustituir los identificadores de un conjunto de datos por seudónimos o identificadores falsos para evitar la identificación directa de las personas. A diferencia de la anonimización completa, los datos seudonimizados pueden volver a identificarse utilizando una clave que vincule los seudónimos a las identidades reales.
Esta técnica se utiliza habitualmente en la investigación médica, el análisis de datos y el procesamiento de datos de clientes, ya que permite realizar análisis sin revelar las identidades individuales, pero teniendo la opción de rastrearlas en entornos seguros.
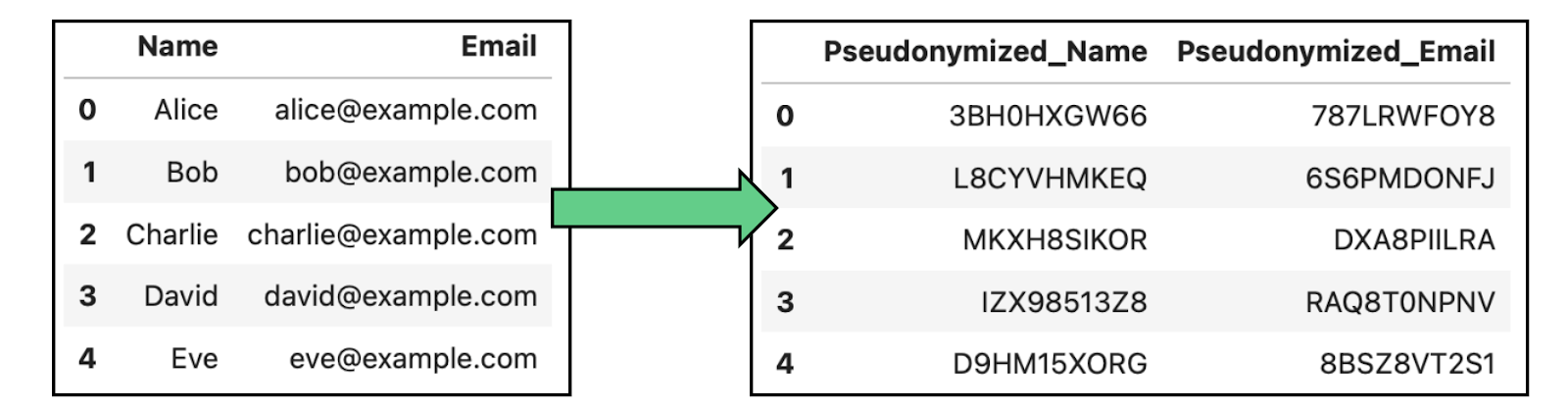
Ejemplo de anonimización de datos mediante seudonimización en datos que contienen nombres y correos electrónicos.
Otra técnica muy utilizada es el enmascaramiento de datos, que consiste en alterar u ofuscar los datos originales manteniendo su formato y estructura. En la práctica, existen dos enfoques diferentes para el enmascaramiento de datos:
La siguiente imagen muestra algunas transformaciones habituales en el enmascaramiento de datos:

Ejemplo de anonimización de datos mediante enmascaramiento de datos que contienen números de la Seguridad Social (SSN), teléfonos y números de tarjetas de crédito.
Debido a la importancia de la anonimización de datos, se han desarrollado varias herramientas para facilitar el proceso a los desarrolladores, así como para proporcionar herramientas de validación listas para usar. En esta sección, exploraremos tres herramientas, cada una más adecuada en función de nuestro caso de uso.
ARX es una herramienta de anonimización de datos de código abierto que admite varias técnicas de preservación de la privacidad. Es ideal para la investigación, la sanidad y cualquier organización que trabaje con grandes conjuntos de datos que requieran una anonimización rigurosa.
Captura de pantalla de la página principal de ARX.
Si eres investigador y quieres hacer públicos tus datos, ARX puede ser la mejor opción para ti.
Guardium de IBM es una solución diseñada para proteger datos sensibles en entornos híbridos y multi-nube. Ofrece encriptación de datos de extremo a extremo, seudonimización y controles de acceso de grano fino para garantizar la privacidad de los datos durante todo su ciclo de vida. Dispone de diferentes productos independientes, tanto de vigilancia como de protección:

Captura de pantalla de la página principal de IBM Guard.
Esta herramienta es muy adecuada para empresas con entornos de datos complejos, sobre todo las que utilizan infraestructuras multi-nube en las que la protección de datos, el control de acceso y el cumplimiento de la normativa son fundamentales.
Por último, TensorFlow Privacy amplía el marco de aprendizaje automático TensorFlow añadiendo soporte para la privacidad diferencial. En otras palabras, permite a los desarrolladores crear modelos de aprendizaje automático que protejan la privacidad de los datos individuales, limitando la cantidad de información que puede extraerse sobre un único punto de datos.
Captura de pantalla de la página principal de Privacidad de TensorFlow.
TensorFlow Privacidad es perfecto para empresas o particulares que desarrollen ellos mismos los modelos.
A continuación, hemos creado una tabla comparativa que muestra las diferentes herramientas de anonimización de datos y cómo se comparan:
|
Herramienta |
Descripción |
Características principales |
Caso de uso ideal |
Limitaciones |
|
ARX |
Herramienta de anonimización de código abierto con varias técnicas de preservación de la privacidad. |
- K-Anonimato, L-Diversidad, T-Apoyo a la cerrazón - Análisis de riesgos - Pruebas de reidentificación |
Investigación, asistencia sanitaria e intercambio público de datos |
Configuración compleja para principiantes |
|
IBM Guardium |
Solución integral de seguridad y anonimización de datos para la nube híbrida. |
- Cifrado de datos de extremo a extremo - Enmascaramiento de datos - Control de acceso - Supervisión y alertas |
Empresas con entornos complejos, híbridos y multi-nube |
Coste elevado; más adecuado para grandes empresas |
|
Privacidad de Google TensorFlow |
Marco para el entrenamiento de modelos de aprendizaje automático con privacidad diferencial. |
- Apoyo a la privacidad diferencial - Integración perfecta con TensorFlow - Ajuste del modelo para la privacidad |
Aplicaciones de aprendizaje automático con datos sensibles |
Limitado al ecosistema TensorFlow |
Conocer las técnicas y herramientas de anonimización de datos disponibles es importante, pero elegir la técnica adecuada para nuestro caso de uso es aún más difícil. Exploremos el proceso paso a paso para aplicar la anonimización de datos en la práctica:
El primer paso es comprender con qué tipo de datos estamos trabajando y qué elementos requieren protección. Se trata de identificar IPI, como nombres, direcciones, números de la Seguridad Social o datos médicos.
A continuación, debemos determinar cómo se utilizarán los datos tras la anonimización. ¿Será para investigación interna, para compartir públicamente o para entrenar modelos de aprendizaje automático? Este paso es importante, ya que algunos datos pueden requerir técnicas de anonimización más fuertes en función de los requisitos normativos.
Los distintos tipos de datos y aplicaciones requieren técnicas de anonimización adaptadas. Es importante adecuar la técnica apropiada a la naturaleza de los datos, los requisitos de privacidad y el uso previsto según las técnicas comentadas.
Tras aplicar las técnicas de anonimización adecuadas, es importante verificar su eficacia para garantizar que los datos están realmente protegidos. Personalmente, recomendaría utilizar herramientas de evaluación de riesgos como las presentadas anteriormente para comprobar la facilidad con que los datos anonimizados pueden volver a identificarse comparándolos con fuentes de datos externas.Por último, si estás llevando a cabo un proceso de anonimización de datos como parte de una empresa, considera la posibilidad de auditar periódicamente los datos anonimizados, especialmente si los datos se comparten o actualizan con frecuencia.
Esto ayuda a mantener el cumplimiento de la normativa sobre privacidad y garantiza que la anonimización siga siendo efectiva a lo largo del tiempo. Para más información sobre la normativa de privacidad, consulta el artículo ¿Qué es la Ley de IA de la UE? Guía resumida para líderes.
Como habrás observado, el enmascaramiento de datos es ligeramente diferente de las demás técnicas de anonimización de datos presentadas hasta ahora. Mientras que la anonimización de datos consiste en hacer que los datos sean completamente inidentificables eliminando o alterando los identificadores personales, el enmascaramiento de datos consiste en oscurecer los datos sensibles sustituyéndolos por valores de relleno o ficticios, manteniendo el formato original de los datos, es decir, los datos no se alteran, sólo se oscurecen.
La anonimización general es permanente e irreversible, mientras que el enmascaramiento suele ser reversible. El enmascaramiento mantiene la estructura y la utilidad de los datos para aplicaciones internas específicas, mientras que la anonimización puede sacrificar parte de la utilidad de los datos a cambio de una mayor protección de la privacidad.
En resumen, si tu objetivo principal es proteger permanentemente la privacidad, especialmente de los datos que pueden compartirse externamente o analizarse para obtener información, la anonimización de datos es el mejor enfoque. Sin embargo, si necesitas proteger datos en entornos que no son de producción, la mayoría de las veces basta con enmascarar los datos.
El principal reto de la anonimización de datos es el equilibrio entre el grado de anonimización y la utilidad de los datos. Una anonimización excesiva puede degradar la calidad de los datos, haciéndolos menos valiosos para el análisis o el aprendizaje automático, mientras que una anonimización insuficiente podría dejar vulnerabilidades de privacidad. Encontrar el equilibrio adecuado entre la anonimización y la conservación de la utilidad de los datos es un reto importante.
Además, anonimizar los datos para cumplir las distintas leyes de privacidad es complejo, sobre todo porque las distintas regiones e industrias tienen requisitos diferentes, y estas leyes evolucionan con el tiempo. Para garantizar una mejor protección, recomendaría establecer un sólido proceso de principio a fin que incluya la supervisión continua de los datos y el perfeccionamiento de las técnicas de anonimización de datos.
La anonimización de datos también es un tema candente en el contexto de los Grandes Modelos Lingüísticos (LLM), como ChatGPT. Es crucial para garantizar que no se filtre ni se exponga información sensible durante el uso de estos modelos.
Dado que los LLM se entrenan con conjuntos de datos masivos no estructurados, procedentes de textos de acceso público como correos electrónicos, registros de chat y documentos, existe el riesgo de que se incluya inadvertidamente información personal sensible en los datos de entrenamiento, lo que plantea problemas de privacidad.
Cuando se trata de datos no estructurados, es más difícil identificar y garantizar la eliminación completa de la información personal sensible antes de la formación. Por eso, supervisar las salidas de los LLM y filtrar las respuestas que puedan exponer información sensible es crucial para mitigar el riesgo de fuga de datos tras su despliegue.
Por último, también están surgiendo nuevas opciones, como afinar los modelos con salvaguardias específicas de privacidad y utilizar entornos encriptados para el entrenamiento, pero como usuario, siempre podemos intentar ser cuidadosos y no compartir nuestra información personal con la herramienta.
A medida que crece el uso de aplicaciones basadas en datos, también aumenta la recopilación de datos de las personas, lo que hace que la salvaguarda de la información personal sea más crítica que nunca.
Como usuarios, debemos ser conscientes de los riesgos de las violaciones de datos, y como desarrolladores, debemos mantenernos informados sobre las últimas técnicas de anonimización para garantizar la protección de datos en nuestras aplicaciones. Esta concienciación es especialmente importante cuando los datos se hacen públicos, ya que el riesgo de reidentificación es mayor. Dando prioridad a la privacidad de los datos y perfeccionando continuamente las prácticas de anonimización, podemos crear aplicaciones más seguras y responsables.
Por último, si te interesa aplicar todas estas técnicas en Python, ¡el curso Privacidad de Datos y Anonimización en Python es para ti!
Consigue que tu equipo acceda a toda la biblioteca de DataCamp, con informes centralizados, tareas, proyectos y mucho más
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Sejal Jaiswal
12 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
14 min
blog
Javier Canales Luna
12 min
blog
Tim Lu
12 min

