
Track
Data Governance Fundamentals
10 hr
Ensure compliance and protect your business with DataCamp for Business. Specialized courses and centralized tracking to safeguard your data.

In data science, data anonymization refers to the process of modifying a dataset in such a way that it becomes impossible or very difficult to identify individuals based on the available data.
In essence, the data anonymization process consists of removing or transforming personally identifiable information (PII) from datasets, such as names and addresses, while still retaining the utility of the data for analysis.
It also minimizes the risk of data leakages and re-identification, allowing us to share and analyze data safely without compromising individual privacy.
One famous case of a non-rigorous data anonymization process occurred in 2006, when Netflix released a movie dataset containing user data as part of the Netflix Prize competition, which aimed to improve their recommendation system.
Researchers from the University of Texas demonstrated the vulnerability of the anonymized data by re-identifying individuals using publicly available IMDb data. This incident raised significant concerns about the effectiveness of data anonymization techniques and highlighted the need for more meticulous approaches.
Removing PIIs is not the only approach for data anonymization. In some cases, data can be also generalized to reduce the uniqueness of individuals in a dataset. One example of this is replacing exact ages by age ranges. In addition, data can be also perturbed by introducing slight inaccuracies, making it harder to link the new data back to an individual.
Knowing the different data anonymization techniques can help us in selecting the most suitable one for our use-case. In this section, we will explore the most common ones.
As mentioned above, data anonymization is not only about removing PIIs. Instead of removing data, generalization transforms it into a broader, less identifiable form. In other words, generalization reduces the granularity of data to prevent identification. This allows the data to remain useful for analysis while lowering the risk of re-identification.
For example, when dealing with personal data such as birth date, instead of showing the exact birth date, the data is generalized to the month and year, or just the year, to prevent identification while keeping the age group relevant for analysis. The following tables show some simple examples of data anonymization by generalization on age and location:
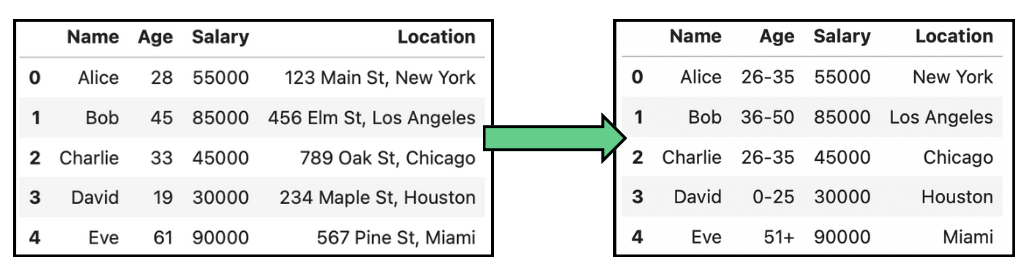
Example of data anonymization by generalization in age and location data.
This technique is mostly used in demographic studies and market research, but it can lead to a loss of data utility, making detailed analysis difficult.
Generalization is often used in conjunction with other techniques like K-Anonymity, where multiple records are generalized until they cannot be distinguished from at least k other records, reducing the risk of re-identifying individuals.
In analyses where precise individual data points are not necessary but the overall distribution, data perturbation can be applied. It refers to the process of modifying the original data in a controlled manner to protect privacy. This modification can include various techniques like randomization, scaling, or swapping values. Data perturbation aims to obscure the data while retaining its usefulness for analysis.
One concrete case of data perturbation is noise addition. Noise addition consists of introducing random or systematic changes, the so-called “noise”, to the data. This noise obscures the true values of sensitive data points, making it more difficult to re-identify individuals. In the following image, we have modified the original salaries shown in the tables above by adding Gaussian noise:
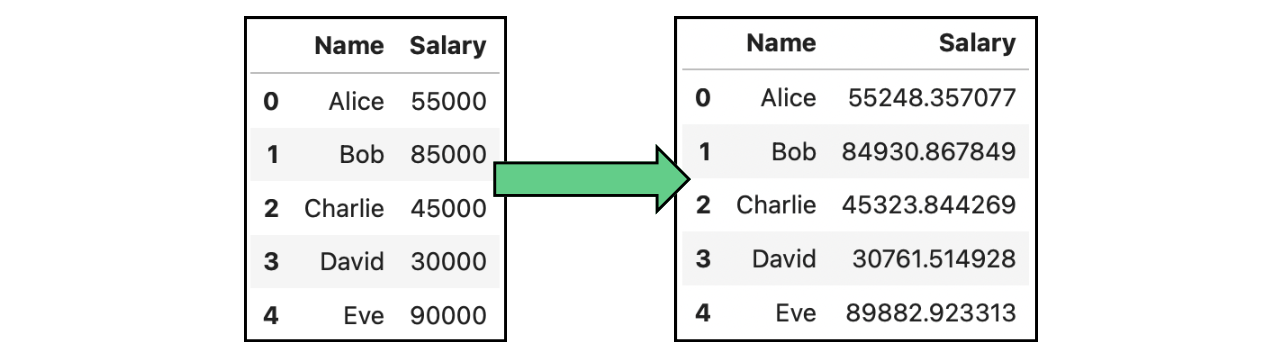
Example of data anonymization by noise addition data containing salaries.
Instead of adding noise to the real data, another approach to data anonymization is to generate fake data, under certain conditions. Synthetic data generation is the process of creating artificial datasets that replicate the statistical properties of the original data without including real, identifiable information. It serves as an alternative to analyze a privacy-compliant dataset that mimics the patterns and structure of the original one.
The process of generating data with the same data distribution requires statistical modeling to identify the patterns, relationships, and distributions that we need to replicate. In general, synthetic data generation is more difficult to implement.
I recommend checking out the following resources to learn more:
Pseudonymization implies replacing identifiers in a dataset with pseudonyms or fake identifiers to prevent direct identification of individuals. Unlike full anonymization, pseudonymized data can be re-identified using a key that links the pseudonyms to real identities.
This technique is commonly used in medical research, data analytics, and customer data processing, allowing analysis without revealing individual identities, but having the option to trace them back in safe environments.
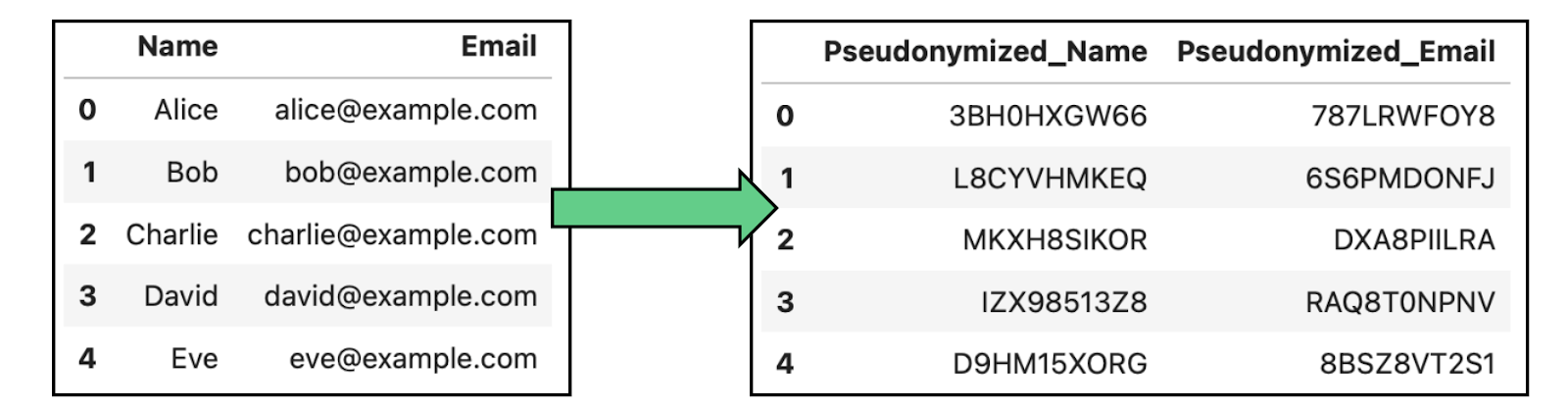
Example of data anonymization by pseudonymization in data containing names and emails.
Another commonly used technique is data masking, which involves altering or obfuscating the original data while maintaining its format and structure. In practice, there are two different approaches to data masking:
The following image shows some common transformations in data masking:

Example of data anonymization by data masking data containing Social Security Numbers (SSN), phones and credit card numbers.
Due to the importance of data anonymization, several tools have been developed to make the process smoother for developers, as well as to provide validation tools out-of-the-box. In this section, we will explore three tools, each one more suited depending on our use-case.
ARX is an open-source data anonymization tool that supports various privacy-preserving techniques. It is ideal for research, healthcare, and any organization dealing with large datasets that require rigorous anonymization.
Screenshot of the ARX main page.
If you are a researcher aiming to release your data public, ARX might be the best option for you.
IBM’s Guardium is a solution designed to protect sensitive data across hybrid, multi-cloud environments. It offers end-to-end data encryption, pseudonymization, and fine-grained access controls to ensure data privacy throughout its lifecycle. It has different independent products both for monitoring and protection:

Screenshot of the IBM Guard main page.
This tool is well-suited for enterprises with complex data environments, particularly those using multi-cloud infrastructures where data protection, access control, and regulatory compliance are critical.
Finally, TensorFlow Privacy extends the TensorFlow machine learning framework by adding support for differential privacy. In other words, it enables developers to build machine learning models that protect individual data privacy by limiting the amount of information that can be extracted about any single data point.
Screenshot of the TensorFlow Privacy main page.
TensorFlow Privacy is perfect for companies or individuals developing the models themselves.
Below, we’ve created a comparison table showing the different data anonymization tools and how they compare:
|
Tool |
Description |
Key Features |
Ideal Use Case |
Limitations |
|
ARX |
Open-source anonymization tool with various privacy-preserving techniques. |
- K-Anonymity, L-Diversity, T-Closeness support - Risk Analysis - Re-identification Testing |
Research, Healthcare, and Public Data Sharing |
Complex configuration for beginners |
|
IBM Guardium |
Comprehensive data security and anonymization solution for hybrid cloud. |
- End-to-end data encryption - Data Masking - Access Control - Monitoring and Alerts |
Enterprises with complex, hybrid, and multi-cloud environments |
High cost; best suited for large enterprises |
|
Google TensorFlow Privacy |
Framework for training machine learning models with differential privacy. |
- Differential Privacy support - Seamless TensorFlow integration - Model fine-tuning for privacy |
Machine learning applications with sensitive data |
Limited to TensorFlow ecosystem |
Knowing the available data anonymization techniques and tools is important, but choosing the right technique for our use case is even more challenging. Let’s explore the step-by-step process for implementing data anonymization in practice:
The first step is to understand what type of data we are working with and which elements require protection. This involves identifying PIIs, such as names, addresses, Social Security numbers, or medical data.
Next, we should determine how the data will be used after anonymization. Will it be for internal research, public sharing, or training machine learning models? This step is important since some data may require stronger anonymization techniques based on regulatory requirements.
Different types of data and applications require tailored anonymization techniques. It is important to match the appropriate technique to the nature of the data, privacy requirements, and intended use based on the techniques discussed.
After applying the appropriate anonymization techniques, it is important to verify their effectiveness to ensure that the data is truly protected. I would personally recommend using risk assessment tools such as the ones presented above to check how easily the anonymized data can be re-identified by comparing it with external data sources.Finally, if you are conducting a data anonymization process as part of a company, consider regularly auditing anonymized data, especially if the data is frequently shared or updated.
This helps maintain compliance with privacy regulations and ensures that anonymization remains effective over time. For more information on privacy regulations, check the article What is the EU AI Act? A Summary Guide for Leaders.
As you may have noticed, data masking is slightly different from the other data anonymization techniques presented so far. While data anonymization involves making data completely unidentifiable by removing or altering personal identifiers, data masking involves obscuring sensitive data by replacing it with padding or fictitious values while maintaining the original data format, i.e., data is not altered, just obscured.
General anonymization is permanent and irreversible, while masking is often reversible. Masking maintains data structure and usability for specific internal applications, whereas anonymization may sacrifice some data utility in exchange for stronger privacy protection.
In summary, if your primary goal is to permanently protect privacy, especially for data that may be shared externally or analyzed for insights, data anonymization is the best approach. However, if you need to protect data in non-production environments, most of the time data masking is enough.
The main challenge in data anonymization is the trade-off between the degree of anonymization and the usefulness of the data. Over-anonymization can degrade data quality, making it less valuable for analysis or machine learning, while under-anonymization might leave privacy vulnerabilities. Striking the right balance between anonymization and retaining data utility is a significant challenge.
Additionally, anonymizing data to meet various privacy laws is complex, especially since different regions and industries have varying requirements, and these laws evolve over time. To ensure better protection, I would recommend establishing a robust end-to-end process that includes continuous monitoring of the data and refinement of the data anonymization techniques.
Data anonymization is also a hot topic in the context of Large Language Models (LLMs) such as ChatGPT. It is crucial for ensuring that sensitive information is not leaked or exposed during the use of these models.
Since LLMs are trained on massive unstructured datasets, sourced from publicly available text such as emails, chat logs, and documents, there is a risk that sensitive personal information could inadvertently be included in the training data, raising privacy concerns.
When dealing with unstructured data, it is more difficult to identify and ensure the complete removal of sensitive personal information before training. That is why monitoring the outputs of LLMs and filtering out any responses that might expose sensitive information is crucial for mitigating the risk of data leakage after deployment.
Finally, new options such as fine-tuning models with specific privacy safeguards and using encrypted environments for training are also emerging, but as user, we can always try to be careful and not share our personal information with the tool.
As the use of data-driven applications grows, the collection of individuals’ data also increases, making the safeguarding of personal information more critical than ever.
As users, we should be aware of the risks of data breaches, and as developers, we should stay informed about the latest anonymization techniques to ensure data protection in our applications. This awareness is especially important when data is made public, as the risk of re-identification is higher. By prioritizing data privacy and continuously refining anonymization practices, we can create safer and more responsible applications.
Finally, if you are interested in applying all these techniques in Python, the course Data Privacy and Anonymization in Python is for you!
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more
Top DataCamp Courses
Track
Course
Course
blog
Kurtis Pykes
15 min
blog
Matt Crabtree
10 min
blog
Sejal Jaiswal
12 min
blog
Javier Canales Luna
14 min
blog
Kurtis Pykes
15 min
podcast
