
Cursus
Fondamentaux de la gouvernance des données
10 h
Garantissez la conformité et protégez votre entreprise avec DataCamp for Business. Des cours spécialisés et un suivi centralisé pour protéger vos données.

Dans le domaine de la science des données, l'anonymisation des données fait référence au processus de modification d'un ensemble de données de telle sorte qu'il devient impossible ou très difficile d'identifier des individus sur la base des données disponibles.
Le processus d'anonymisation des données consiste essentiellement à supprimer ou à transformer les informations personnelles identifiables (IPI) des ensembles de données, telles que les noms et les adresses, tout en conservant l'utilité des données à des fins d'analyse.
Il minimise également le risque de fuites de données et de réidentification, ce qui nous permet de partager et d'analyser les données en toute sécurité sans compromettre la vie privée des individus.
Un cas célèbre de processus d'anonymisation des données non rigoureux s'est produit en 2006, lorsque Netflix a publié un ensemble de données de films contenant des données d'utilisateurs dans le cadre du concours Netflix Prize, qui visait à améliorer son système de recommandation.
Des chercheurs de l'université du Texas ont démontré la vulnérabilité des données anonymes en réidentifiant des personnes à l'aide de données IMDb accessibles au public. Cet incident a suscité de vives inquiétudes quant à l'efficacité des techniques d'anonymisation des données et a mis en évidence la nécessité d'adopter des approches plus méticuleuses.
La suppression des IPI n'est pas la seule méthode d'anonymisation des données. Dans certains cas, les données peuvent également être généralisées pour réduire l'unicité des individus dans un ensemble de données. Un exemple est le remplacement des âges exacts par des tranches d'âge. En outre, les données peuvent également être perturbées en introduisant de légères inexactitudes, ce qui rend plus difficile l'établissement d'un lien entre les nouvelles données et un individu.
Connaître les différentes techniques d'anonymisation des données peut nous aider à choisir celle qui convient le mieux à notre cas d'utilisation. Dans cette section, nous examinerons les plus courantes.
Comme indiqué plus haut, l'anonymisation des données ne consiste pas seulement à supprimer les IPI. Au lieu de supprimer les données, la généralisation les transforme en une forme plus large et moins identifiable. En d'autres termes, la généralisation réduit la granularité des données pour empêcher l'identification. Cela permet aux données de rester utiles pour l'analyse tout en réduisant le risque de ré-identification.
Par exemple, lorsque vous traitez des données personnelles telles que la date de naissance, au lieu d'indiquer la date de naissance exacte, les données sont généralisées au mois et à l'année, ou seulement à l'année, afin d'empêcher l'identification tout en conservant le groupe d'âge pertinent pour l'analyse. Les tableaux suivants présentent quelques exemples simples d'anonymisation des données par généralisation sur l'âge et la localisation :
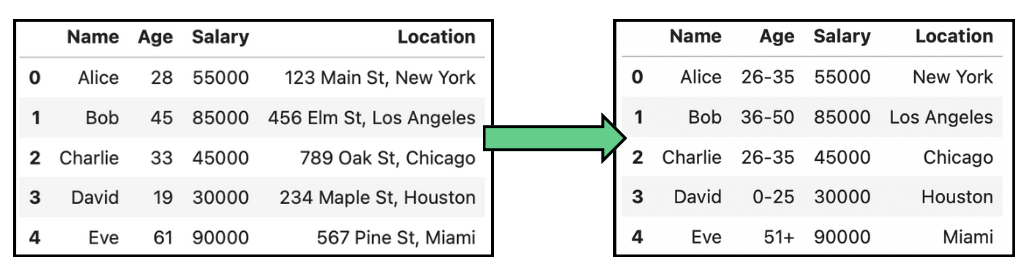
Exemple d'anonymisation des données par généralisation des données d'âge et de localisation.
Cette technique est surtout utilisée dans les études démographiques et les études de marché, mais elle peut entraîner une perte d'utilité des données, ce qui rend difficile une analyse détaillée.
La généralisation est souvent utilisée en conjonction avec d'autres techniques telles que K-Anonymatoù plusieurs enregistrements sont généralisés jusqu'à ce qu'ils ne puissent être distingués d'au moins k autres enregistrements, ce qui réduit le risque de ré-identification des individus.
Dans les analyses où il n'est pas nécessaire de disposer de points de données individuels précis, mais d'une distribution globale, il est possible d'appliquer une perturbation des données. Il s'agit du processus de modification des données d'origine d'une manière contrôlée afin de protéger la vie privée. Cette modification peut inclure diverses techniques telles que la randomisation, la mise à l'échelle ou l'échange de valeurs. La perturbation des données vise à obscurcir les données tout en conservant leur utilité pour l'analyse.
Un cas concret de perturbation des données est l'ajout de bruit. L'ajout de bruit consiste à introduire des changements aléatoires ou systématiques, appelés "bruit", dans les données. Ce bruit obscurcit les vraies valeurs des points de données sensibles, ce qui rend plus difficile la ré-identification des individus. Dans l'image suivante, nous avons modifié les traitements originaux présentés dans les tableaux ci-dessus en ajoutant du bruit gaussien:
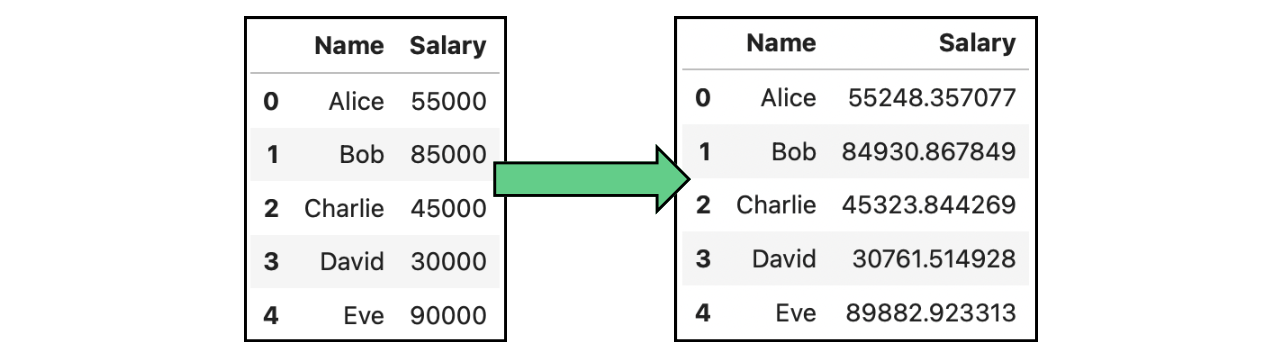
Exemple d'anonymisation des données par ajout de bruit : données contenant des salaires.
Au lieu d'ajouter du bruit aux données réelles, une autre approche de l'anonymisation des données consiste à générer de fausses données, sous certaines conditions. Lagénération de données synthétiques est le processus de création d'ensembles de données artificielles qui reproduisent les propriétés statistiques des données originales sans inclure d'informations réelles et identifiables. Il s'agit d'une alternative à l'analyse d'un ensemble de données respectueuses de la vie privée qui reproduit les schémas et la structure de l'ensemble de données original.
Le processus de génération de données avec la même distribution de données nécessite une modélisation statistique pour identifier les modèles, les relations et les distributions que nous devons reproduire. En général, la génération de données synthétiques est plus difficile à mettre en œuvre.
Je vous recommande de consulter les ressources suivantes pour en savoir plus :
La pseudonymisation consiste à remplacer les identifiants d'un ensemble de données par des pseudonymes ou de faux identifiants afin d'empêcher l'identification directe des personnes. Contrairement à l'anonymisation complète, les données pseudonymisées peuvent être réidentifiées à l'aide d'une clé qui relie les pseudonymes aux identités réelles.
Cette technique est couramment utilisée dans la recherche médicale, l'analyse des données et le traitement des données clients. Elle permet d'effectuer des analyses sans révéler l'identité des personnes, mais en ayant la possibilité de les retracer dans des environnements sûrs.
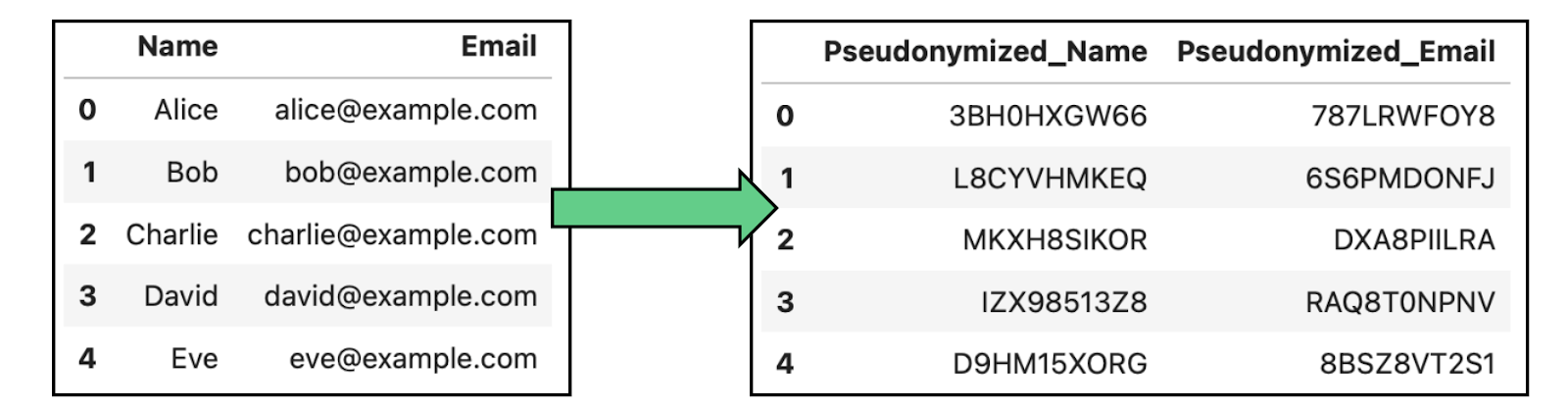
Exemple d'anonymisation des données par pseudonymisation dans les données contenant des noms et des courriels.
Une autre technique couramment utilisée est le masquage des données, qui consiste à modifier ou à obscurcir les données originales tout en conservant leur format et leur structure. Dans la pratique, il existe deux approches différentes du masquage des données :
L'image suivante montre quelques transformations courantes dans le masquage de données :

Exemple d'anonymisation des données par masquage des données contenant des numéros de sécurité sociale (SSN), de téléphone et de carte de crédit.
En raison de l'importance de l'anonymisation des données, plusieurs outils ont été développés pour faciliter le processus pour les développeurs, ainsi que pour fournir des outils de validation prêts à l'emploi. Dans cette section, nous allons explorer trois outils, chacun plus adapté à notre cas d'utilisation.
ARX est un outil d'anonymisation des données à code source ouvert qui prend en charge diverses techniques de préservation de la vie privée. Il est idéal pour la recherche, les soins de santé et toute organisation traitant de grands ensembles de données qui nécessitent une anonymisation rigoureuse.
Capture d'écran de la page principale d'ARX.
Si vous êtes un chercheur et que vous souhaitez rendre vos données publiques, ARX pourrait être la meilleure option pour vous.
Guardium d'IBM est une solution conçue pour protéger les données sensibles dans les environnements hybrides et multi-cloud. Il offre un cryptage des données de bout en bout, une pseudonymisation et des contrôles d'accès précis afin de garantir la confidentialité des données tout au long de leur cycle de vie. Il dispose de différents produits indépendants pour la surveillance et la protection :

Capture d'écran de la page principale d'IBM Guard.
Cet outil est bien adapté aux entreprises disposant d'environnements de données complexes, en particulier celles qui utilisent des infrastructures multi-cloud où la protection des données, le contrôle d'accès et la conformité réglementaire sont essentiels.
Enfin, TensorFlow Privacy étend le cadre d'apprentissage machine TensorFlow en ajoutant la prise en charge de la confidentialité différentielle. En d'autres termes, il permet aux développeurs d'élaborer des modèles d'apprentissage automatique qui protègent la confidentialité des données individuelles en limitant la quantité d'informations pouvant être extraites d'un seul point de données.
Capture d'écran de la page principale de TensorFlow Privacy.
TensorFlow Privacy est parfait pour les entreprises ou les particuliers qui développent eux-mêmes les modèles.
Ci-dessous, nous avons créé un tableau comparatif présentant les différents outils d'anonymisation des données et leur comparaison :
|
Outil |
Description |
Caractéristiques principales |
Cas d'utilisation idéal |
Limites |
|
ARX |
Outil d'anonymisation open-source avec diverses techniques de préservation de la vie privée. |
- K-Anonymat, L-Diversité, T-Closeness support - Analyse des risques - Test de réidentification |
Recherche, soins de santé et partage des données publiques |
Configuration complexe pour les débutants |
|
IBM Guardium |
Solution complète de sécurité et d'anonymisation des données pour le cloud hybride. |
- Cryptage des données de bout en bout - Masquage des données - Contrôle d'accès - Surveillance et alertes |
Les entreprises dotées d'environnements complexes, hybrides et multi-cloud. |
Coût élevé ; mieux adapté aux grandes entreprises |
|
Google TensorFlow Confidentialité |
Cadre pour la formation de modèles d'apprentissage automatique avec confidentialité différentielle. |
- Soutien différentiel à la protection de la vie privée - Intégration transparente de TensorFlow - Ajustement du modèle pour la protection de la vie privée |
Applications d'apprentissage automatique avec des données sensibles |
Limité à l'écosystème TensorFlow |
Il est important de connaître les techniques et les outils d'anonymisation des données disponibles, mais le choix de la bonne technique pour notre cas d'utilisation est encore plus difficile. Examinons le processus étape par étape de mise en œuvre de l'anonymisation des données dans la pratique :
La première étape consiste à comprendre le type de données avec lesquelles nous travaillons et les éléments qui doivent être protégés. Il s'agit d'identifier les IIP, telles que les noms, les adresses, les numéros de sécurité sociale ou les données médicales.
Ensuite, nous devons déterminer comment les données seront utilisées après l'anonymisation. Sera-t-il destiné à la recherche interne, au partage public ou à la formation de modèles d'apprentissage automatique ? Cette étape est importante car certaines données peuvent nécessiter des techniques d'anonymisation plus poussées en raison d'exigences réglementaires.
Différents types de données et d'applications nécessitent des techniques d'anonymisation adaptées. Il est important d'adapter la technique appropriée à la nature des données, aux exigences en matière de protection de la vie privée et à l'utilisation prévue, sur la base des techniques examinées.
Après avoir appliqué les techniques d'anonymisation appropriées, il est important de vérifier leur efficacité pour s'assurer que les données sont réellement protégées. Enfin, si vous menez un processus d'anonymisation des données dans le cadre d'une entreprise, envisagez d'auditer régulièrement les données anonymisées, surtout si elles sont fréquemment partagées ou mises à jour.
Cela permet de respecter les réglementations en matière de protection de la vie privée et de garantir que l'anonymisation reste efficace au fil du temps. Pour plus d'informations sur les réglementations en matière de protection de la vie privée, consultez l'article Qu'est-ce que la loi européenne sur l'intelligence artificielle ? Un guide de synthèse pour les dirigeants.
Comme vous l'avez peut-être remarqué, le masquage des données est légèrement différent des autres techniques d'anonymisation des données présentées jusqu'à présent. Alors que l'anonymisation des données consiste à rendre les données totalement non identifiables en supprimant ou en modifiant les identifiants personnels, le masquage des données consiste à obscurcir les données sensibles en les remplaçant par des valeurs de remplissage ou fictives tout en conservant le format original des données, c'est-à-dire que les données ne sont pas modifiées, mais simplement obscurcies.
L'anonymisation générale est permanente et irréversible, tandis que le masquage est souvent réversible. Le masquage préserve la structure des données et la facilité d'utilisation pour des applications internes spécifiques, tandis que l'anonymisation peut sacrifier une partie de l'utilité des données en échange d'une protection plus forte de la vie privée.
En résumé, si votre objectif principal est de protéger en permanence la vie privée, en particulier pour les données susceptibles d'être partagées à l'extérieur ou analysées pour en tirer des enseignements, l'anonymisation des données est la meilleure approche. Toutefois, si vous devez protéger des données dans des environnements de non-production, le masquage des données suffit la plupart du temps.
Le principal défi de l'anonymisation des données est le compromis entre le degré d'anonymisation et l'utilité des données. La sur-anonymisation peut dégrader la qualité des données, les rendant moins utiles pour l'analyse ou l'apprentissage automatique, tandis que la sous-anonymisation peut laisser des failles dans la protection de la vie privée. Trouver le bon équilibre entre l'anonymisation et le maintien de l'utilité des données est un défi de taille.
En outre, l'anonymisation des données pour satisfaire aux diverses lois sur la protection de la vie privée est complexe, d'autant plus que les exigences varient selon les régions et les secteurs d'activité, et que ces lois évoluent au fil du temps. Pour garantir une meilleure protection, je recommanderais d'établir un processus solide de bout en bout qui comprend un contrôle continu des données et un perfectionnement des techniques d'anonymisation des données.
L'anonymisation des données est également un sujet d'actualité dans le contexte des grands modèles linguistiques (LLM) tels que ChatGPT. Il est essentiel de veiller à ce que les informations sensibles ne soient pas divulguées ou exposées lors de l'utilisation de ces modèles.
Étant donné que les LLM sont formés sur des ensembles massifs de données non structurées, provenant de textes accessibles au public tels que des courriels, des journaux de discussion et des documents, il existe un risque que des informations personnelles sensibles soient incluses par inadvertance dans les données de formation, ce qui pose des problèmes de protection de la vie privée.
Lorsqu'il s'agit de données non structurées, il est plus difficile d'identifier et de garantir la suppression complète des informations personnelles sensibles avant la formation. C'est la raison pour laquelle il est essentiel de surveiller les résultats des LLM et de filtrer toute réponse susceptible d'exposer des informations sensibles afin d'atténuer le risque de fuite de données après le déploiement.
Enfin, de nouvelles options telles que l'affinement des modèles avec des garanties de confidentialité spécifiques et l'utilisation d'environnements cryptés pour la formation sont également en train d'émerger, mais en tant qu'utilisateur, nous pouvons toujours essayer d'être prudents et de ne pas partager nos informations personnelles avec l'outil.
L'utilisation croissante d'applications basées sur les données s'accompagne d'une augmentation de la collecte de données individuelles, ce qui rend la protection des informations personnelles plus essentielle que jamais.
En tant qu'utilisateurs, nous devons être conscients des risques de violation des données, et en tant que développeurs, nous devons rester informés des dernières techniques d'anonymisation afin de garantir la protection des données dans nos applications. Cette sensibilisation est particulièrement importante lorsque les données sont rendues publiques, car le risque de réidentification est plus élevé. En donnant la priorité à la confidentialité des données et en affinant continuellement les pratiques d'anonymisation, nous pouvons créer des applications plus sûres et plus responsables.
Enfin, si vous souhaitez appliquer toutes ces techniques en Python, la formation Confidentialité des données et anonymisation en Python est faite pour vous !
Permettez à votre équipe d'accéder à l'ensemble de la bibliothèque DataCamp, avec des rapports centralisés, des missions, des projets et bien d'autres choses encore.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours