Curso
Streaming de dados com AWS Kinesis e Lambda
4 h
9.2K
Se estiver criando aplicativos modernos, você sabe como é importante lidar com grandes volumes de dados de forma eficiente. As plataformas de streaming de eventos são a solução ideal para processamento e análise de dados em tempo real.
Neste artigo, exploraremos duas das plataformas mais populares nesse espaço: Apache Kafka e Amazon Simple Queue Service (SQS). Compararemos os pontos fortes e fracos de cada plataforma e forneceremos insights práticos para ajudar você a tomar decisões informadas para seus projetos orientados por dados.
Para você que sabe exatamente o que está procurando e está apenas buscando uma comparação rápida entre o Apache Kafka e o Amazon SQS, a tabela abaixo servirá como um guia conciso. No entanto, se você estiver procurando por um mais detalhado, continue lendo para obter uma comparação abrangente.
|
Categoria |
Kafka |
SQS |
Vencedor |
|
Arquitetura |
Distribuído, pub-sub |
Centralizado, baseado em puxar |
Kafka |
|
Escalabilidade |
Altamente escalável para grandes volumes |
Altamente escalável para volumes menores |
Kafka para grandes, SQS para pequenos |
|
Persistência de mensagens |
Períodos de retenção configuráveis |
Períodos de retenção limitados |
Kafka |
|
Entrega de mensagens |
Pelo menos uma vez, exatamente uma vez com transações |
Pelo menos uma vez, exatamente uma vez com deduplicação |
Gravata |
|
Grupos de consumidores |
Com suporte |
Não suportado |
Kafka |
|
Integração |
Amplo ecossistema, conectores |
Integração estreita com o AWS |
Kafka para não AWS, SQS para AWS |
|
Facilidade de uso |
Curva de aprendizado mais acentuada |
Totalmente gerenciado, mais fácil de começar |
SQS |
|
Custo |
Código aberto, custos de infraestrutura |
Pagamento conforme o uso |
SQS para cargas de trabalho menores, Kafka para cargas de trabalho maiores |
|
Retenção de mensagens |
Mais longo |
14 dias |
Kafka |
|
Suporte a protocolos |
Múltiplos |
Limitada |
Kafka |
|
Dificuldade de sintaxe |
Mais complexo |
Simples e direto |
SQS |
As plataformas de streaming de eventos, como o Apache Kafka e o Amazon SQS, são as principais opções em ambientes modernos orientados por dados. Eles permitem que você colete, processe e analise os dados à medida que eles são gerados, possibilitando uma tomada de decisão mais rápida e uma melhor capacidade de resposta.
Esses são alguns dos motivos pelos quais as plataformas de streaming de eventos plataformas de streaming de eventos como o Kafka e o SQS são importantes:
As plataformas de streaming de eventos permitem a coleta contínua de dados e o processamento de dados em tempo real. Esse recurso é relevante para aplicativos que exigem percepções e ações imediatas, como comércio financeiro financeiros, detecção de fraudese monitoramento de mídia social. Ao processar os dados à medida que eles chegam, você pode tomar decisões oportunas e responder rapidamente a eventos emergentes.
Essas plataformas oferecem suporte à comunicação assíncrona, desacoplando os produtores e os consumidores de dados. Esse desacoplamento permite que diferentes componentes do sistema operem de forma independente, aumentando a resiliência e a flexibilidade. A comunicação assíncrona também permite que os serviços sejam dimensionados de forma independente e evoluam sem causar interrupções em outros componentes.
Tanto o Kafka quanto o SQS foram projetados para alta escalabilidade e confiabilidade. O Kafka pode lidar com milhões de eventos por segundo, escalonando horizontalmente por meio da adição de mais corretores. O SQS é dimensionado automaticamente para gerenciar volumes maiores de mensagens, tornando-o adequado para cargas de trabalho variadas. Esses recursos garantem que as plataformas possam atender às demandas de tarefas de processamento de dados em grande escala.
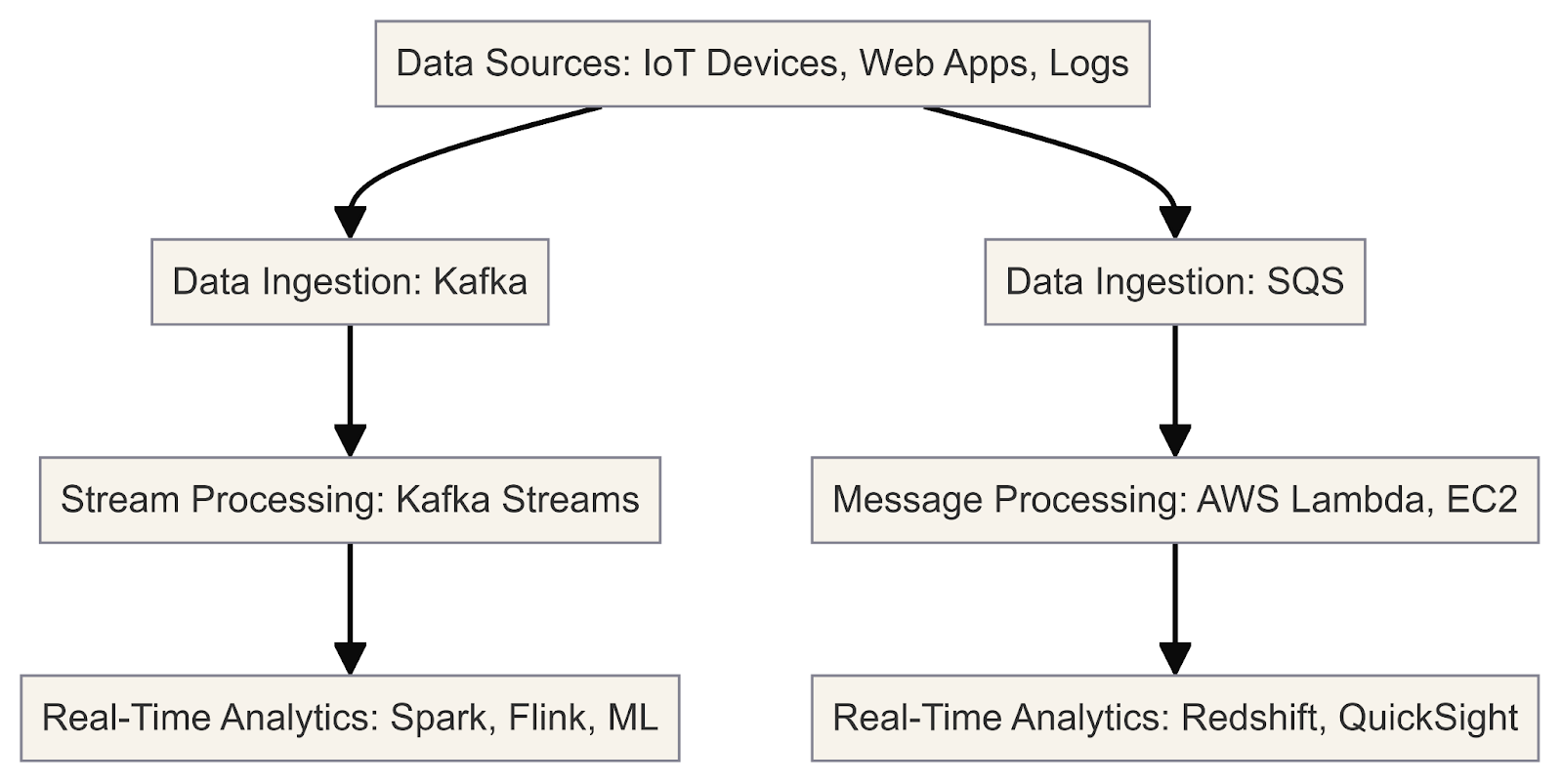
Este diagrama ilustra o fluxo de trabalho de análise e processamento de dados em tempo real usando o Kafka e o SQS
Agora que esclarecemos a importância das plataformas de streaming, vamos analisar o Kafka e o SQS em detalhes.
O Apache Kafka é uma plataforma de streaming de eventos distribuídos de código aberto projetada para lidar com grandes volumes de feeds de dados em tempo real. Ele é usado com frequência para tarefas como mensagens, agregação de logs, processamento de fluxo e logs de confirmação.
A arquitetura do Kafka foi desenvolvida para alta escalabilidade e tolerância a falhas, o que o torna uma solução ideal para aplicativos orientados por dados. Pense no Kafka como um pipeline de dados de alto desempenho que permite que você crie facilmente pipelines de dados em tempo real pipelines de dados e aplicativos em tempo real.
Como desenvolvedor, você pode aproveitar os componentes principais do Kafka para lidar com fluxos de dados em tempo real de forma eficiente. Aqui está um exemplo prático de como o Kafka funciona com o Python:
Visite o site do Apache Kafka e faça o download a versão mais recente. Escolha o download binário que corresponde ao seu sistema operacional.
Extraia o arquivo baixado para um diretório de sua escolha. Esse diretório será o diretório de instalação do Kafka.
Em um Terminal, navegue até o diretório do Kafka extraído e inicie os serviços do Zookeeper e do broker Kafka usando os scripts fornecidos:
# Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka broker
bin/kafka-server-start.sh config/server.propertiesObserve que o Zookeeper está atualmente marcado como obsoleto e está planejado para ser removido no Apache Kafka 4.0. Para obter mais detalhes, consulte a documentação.
Os corretores são os servidores Kafka que lidam com o armazenamento e a replicação de fluxos de dados. Você pode interagir com os corretores por meio de ferramentas de linha de comando ou programaticamente usando bibliotecas de clientes.
Aqui está um exemplo de uso de ferramentas de linha de comando para gerenciar e interagir com os tópicos do Kafka:
bin/kafka-topics.sh --create --topic my_topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1bin/kafka-topics.sh --list --bootstrap-server localhost:9092bin/kafka-console-producer.sh --topic my_topic --bootstrap-server localhost:9092bin/kafka-console-consumer.sh --topic my_topic --bootstrap-server localhost:9092 --from-beginningCertifique-se de que você tenha o Python instalado em seu sistema. As bibliotecas de cliente Python do Kafka são compatíveis com o Python 3.7 e versões posteriores.
Crie um ambiente virtual para isolar as dependências do seu projeto. Você pode usar o site venv.
Esta é a biblioteca oficial do cliente Python do Apache Kafka:
pip install kafka-pythonDependendo dos requisitos do seu projeto, talvez você precise instalar bibliotecas adicionais, como json, para serialização/desserialização de JSON.
Em seguida, use o script a seguir para listar os corretores de forma programática:
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# List the available brokers
brokers = admin_client.describe_cluster()
print("Brokers:", brokers['brokers'])Partições são uma forma de o Kafka obter paralelismo e escalabilidade. Cada partição é uma sequência ordenada e imutável de registros que é continuamente anexada. Você pode configurar o número de partições de um tópico ao criá-lo:
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# Create a new topic with 3 partitions
topic = NewTopic(name="social-media-posts", num_partitions=3, replication_factor=1)
admin_client.create_topics([topic])Entender as partições pode ajudar você a otimizar seus aplicativos para obter melhor desempenho e tolerância a falhas.
Com o Kafka e as bibliotecas Python necessárias instaladas, agora você pode começar a escrever seus aplicativos produtores e consumidores do Kafka em Python.
Aqui está um exemplo de como você pode criar um produtor Kafka para publicar posts de mídia social e um consumidor para processá-los:
Os produtores são os clientes que publicam fluxos de dados nos tópicos do Kafka. Eles podem ser integrados aos seus aplicativos, serviços ou fontes de dados para enviar dados para o Kafka em tempo real.
from kafka import KafkaProducer
import json
# Create a Kafka producer
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda m: json.dumps(m).encode('utf-8'))
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Publish the social media post to the 'social-media-posts' topic
producer.send('social-media-posts', social_media_post)Os consumidores são os clientes que se inscrevem em um ou mais tópicos e consomem fluxos de dados do Kafka. Eles podem implementar vários padrões de consumo com base nos requisitos do seu aplicativo.
from kafka import KafkaConsumer
import json
# Create a Kafka consumer
consumer = KafkaConsumer('social-media-posts',
bootstrap_servers='localhost:9092',
value_deserializer=lambda m: json.loads(m.decode('utf-8')))
# Consume and process social media posts
for message in consumer:
social_media_post = message.value
print(f"Received post: {social_media_post}")
# Process the social media post...Este código de amostra fornece uma visão geral abrangente da instalação do Kafka, da configuração do ambiente Python e da implementação de produtores e consumidores do Kafka para processamento de dados em tempo real.
O SQS é um serviço de enfileiramento de mensagens totalmente gerenciado serviço de enfileiramento de mensagens fornecido pela AWS. Ele permite que você desacoplar e dimensionar microsserviços, sistemas distribuídos e aplicativos sem servidor.
Em sua essência, o SQS é um sistema de filas distribuídas que permite que você envie, armazene e receba mensagens entre componentes de software de forma assíncrona. Essas mensagens podem ser quaisquer dados de texto, notificações do sistema ou até mesmo ponteiros para dados maiores armazenados em outros serviços da AWS, como o S3 ou DynamoDB.
Um dos principais benefícios do SQS é que ele elimina a necessidade de gerenciar sua infraestrutura de enfileiramento de mensagens. O AWS lida com os aspectos subjacentes de gerenciamento de filas, dimensionamento e tolerância a falhas, permitindo que você se concentre na lógica do aplicativo.
O SQS oferece dois tipos de filas:
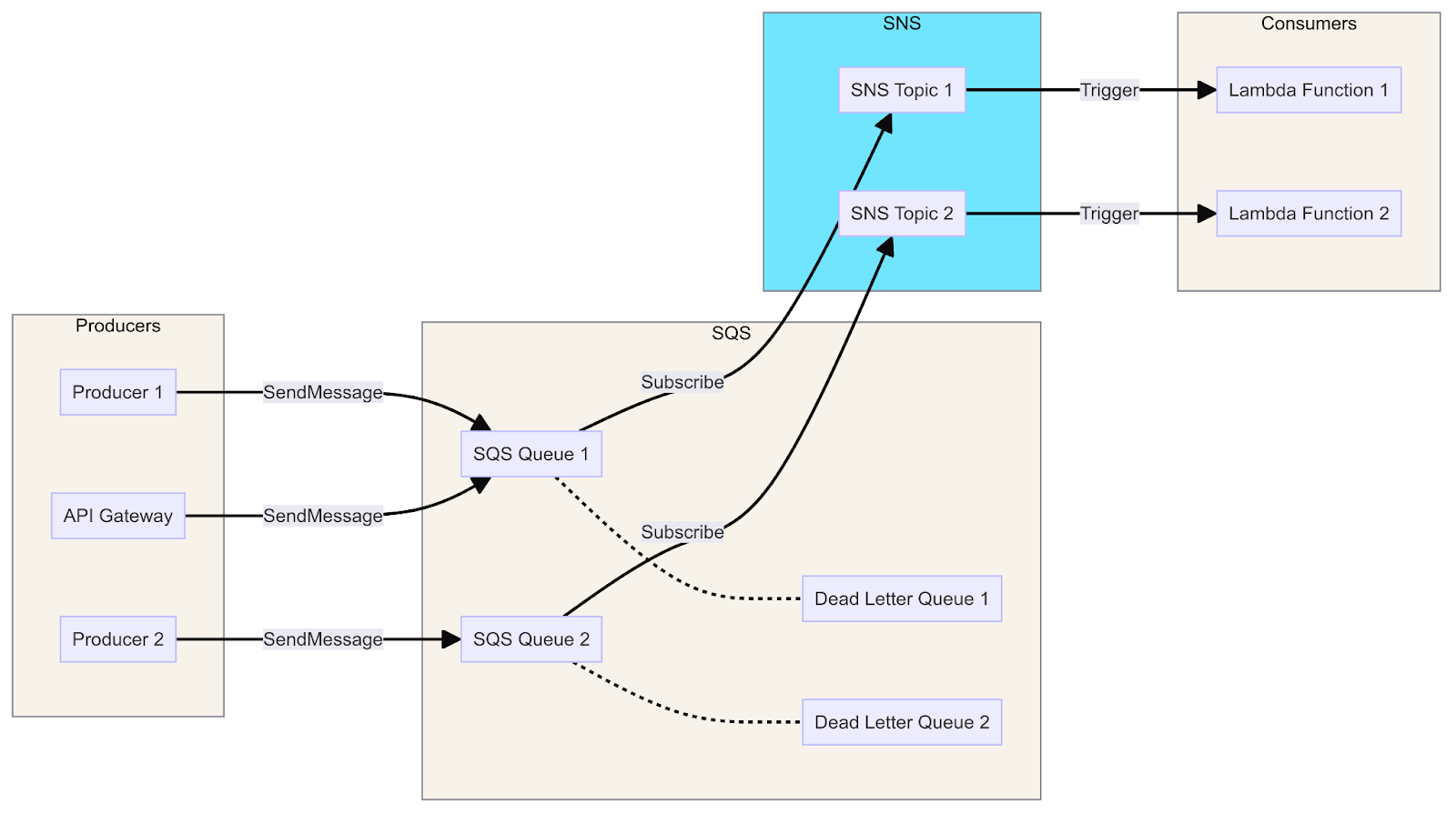
Uma das vantagens do SQS é que ele faz parte do ecossistema do ecossistema do AWSe, portanto, pode ser facilmente integrado a outros serviços da AWS. A forma como essa integração ocorre depende do fato de o serviço ser um produtor ou um consumidor:
Um diagrama que mostra a integração do SQS com o Lambda, o SNS e o API Gateway ilustra o fluxo de mensagens dos produtores para os consumidores por meio de filas, tópicos e funções.
Agora vamos ver os produtores e consumidores em ação. Aqui você encontra um guia para configurar e usar o AWS SQS com Python, incluindo etapas básicas para instalação e um exemplo de produtor e consumidor para o SQS:
Se você ainda não tiver uma, crie uma conta da AWS em Nível gratuito da AWS.
Instale e configure a interface de linha de comando (CLI) do AWS para gerenciar seus recursos do AWS.
# Install AWS CLI
pip install awscli
# Configure AWS CLI with your credentials
aws configureForneça a chave de acesso do AWS, a chave secreta, a região e o formato de saída quando solicitado.
Usaremos o boto3 a biblioteca oficial do AWS SDK para Python, para que você possa interagir com o SQS usando Python.
boto3pip install boto3Crie uma fila SQS usando o console de gerenciamento do AWS ou programaticamente usando o boto3.
import boto3
# Create SQS client
sqs = boto3.client('sqs')
# Create a new queue
response = sqs.create_queue(
QueueName='social-media-posts',
Attributes={
'DelaySeconds': '0',
'MessageRetentionPeriod': '86400' # 1 day
}
)
print(response['QueueUrl'])Um produtor envia mensagens para a fila SQS.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Send message to SQS queue
response = sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(social_media_post)
)
print(response['MessageId'])Um consumidor recebe e processa mensagens da fila SQS.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Receive messages from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
MaxNumberOfMessages=10,
WaitTimeSeconds=10
)
if 'Messages' in response:
for message in response['Messages']:
social_media_post = json.loads(message['Body'])
print(f"Received post: {social_media_post}")
# Process the social media post...
# Delete received message from queue
sqs.delete_message(
QueueUrl=queue_url,
ReceiptHandle=message['ReceiptHandle']
)
else:
print('No messages received')É assim que você pode criar facilmente uma fila SQS, enviar mensagens como um produtor e receber mensagens como um consumidor. O exemplo anterior abrange as etapas básicas para que você possa começar.
Para obter etapas mais detalhadas de configuração, não deixe de conferir a documentação do AWS SQS.
Agora, vamos fazer uma comparação lado a lado do Kafka e do SQS e ver suas semelhanças.
Tanto o Kafka quanto o SQS são sistemas de enfileiramento de mensagens projetados para facilitar a comunicação assíncrona entre diferentes componentes de um sistema distribuído. Eles atuam como intermediários, permitindo que os produtores enviem mensagens e que os consumidores recebam e processem essas mensagens.
O Kafka e o SQS desacoplam produtores e consumidores, permitindo que eles operem de forma independente e sejam dimensionados de forma independente. Essa dissociação promove o acoplamento frouxo, a tolerância a falhas e o dimensionamento em sistemas distribuídos.
Tanto o Kafka quanto o SQS oferecem mecanismos para persistência de mensagens, garantindo que elas não sejam perdidas em caso de falhas ou reinicializações do sistema. O Kafka armazena mensagens em um log de confirmação distribuído, enquanto o SQS armazena mensagens em uma fila altamente durável e disponível.
O Kafka e o SQS foram projetados para serem sistemas altamente dimensionáveis. O Kafka pode ser dimensionado horizontalmente com a adição de mais brokers ao cluster, enquanto o SQS pode ser dimensionado automaticamente para lidar com volumes crescentes de mensagens.
Tanto o Kafka quanto o SQS oferecem recursos de integração com outros sistemas e serviços. O Kafka tem um amplo ecossistema de conectores e integrações, enquanto o SQS se integra perfeitamente a outros serviços do AWS.
Embora o Kafka e o SQS tenham garantias de ordenação diferentes por padrão, ambos os sistemas oferecem mecanismos para preservar a ordenação das mensagens quando necessário. O Kafka oferece entrega ordenada dentro de partições, enquanto o SQS oferece filas FIFO para processamento de mensagens estritamente ordenadas.
O Kafka e o SQS fornecem recursos de monitoramento e métricas, permitindo que os usuários acompanhem e monitorem o desempenho e a integridade de seus sistemas de mensagens.
Tanto o Kafka quanto o SQS oferecem recursos de segurança, como criptografia, controle de acesso e mecanismos de autenticação, para proteger os dados em trânsito e em repouso.
Agora, vamos fazer uma comparação lado a lado do Kafka e do SQS e observar suas diferenças mais importantes.
O Kafka é uma plataforma de streaming distribuída que segue um modelo de publicação e assinatura. Ele consiste em um cluster de corretores que armazenam e gerenciam fluxos de dados em tópicos. Os produtores publicam mensagens em tópicos e os consumidores se inscrevem em tópicos para receber mensagens.
O SQS é um serviço de mensagens totalmente gerenciado fornecido pelo AWS. Ele segue um modelo baseado em fila em que as mensagens são enviadas para uma fila e os consumidores pesquisam a fila para receber mensagens.
O Kafka oferece a semântica de entrega "at-least-once", o que significa que as mensagens podem ser entregues uma ou mais vezes. Ele também oferece suporte à entrega "exatamente uma vez" por meio do uso de produtores idempotentes e gravações transacionais.
O SQS garante a entrega "pelo menos uma vez". Para outros protocolos, como HTTP/HTTPS, e-mail e SMS, o Amazon SNS deve ser usado em conjunto com o SQS.
O Kafka mantém a ordem das mensagens dentro das partições, garantindo que as mensagens sejam entregues na ordem em que foram produzidas.
O SQS não garante a ordenação de mensagens por padrão. No entanto, ele oferece suporte a tópicos FIFO, que preservam a ordem exata das mensagens.
O Kafka armazena mensagens em disco em um log de confirmação distribuído, proporcionando durabilidade e tolerância a falhas. As mensagens podem ser retidas por um período configurável, permitindo que os consumidores rebobinem e reproduzam as mensagens.
O SQS não oferece persistência de mensagens a longo prazo. As mensagens são armazenadas temporariamente até serem entregues a todos os assinantes ou até expirarem (com base no período de retenção configurado).
O Kafka foi projetado para ser dimensionado horizontalmente, adicionando mais brokers ao cluster. Ele também oferece suporte a tópicos de particionamento para paralelismo e balanceamento de carga.
O SQS é um serviço totalmente gerenciado que é dimensionado automaticamente para lidar com volumes crescentes de mensagens sem a necessidade de intervenção manual.
O Kafka tem um rico ecossistema de conectores e integrações com várias fontes de dados, sinks e estruturas de processamento, como Apache Spark, Apache Flink e Apache Kafka Streams.
O SQS se integra perfeitamente a outros serviços do AWS, permitindo que você envie notificações a vários pontos de extremidade, incluindo funções do AWS Lambda, filas do SQS e pontos de extremidade HTTP/HTTPS.
O Kafka usa principalmente ferramentas de interface de linha de comando, como o kafka-topics, para gerenciar tópicos e outras tarefas administrativas. Não há uma interface de usuário integrada dedicada, mas ferramentas de terceiros, como o Kafka Manager, o Kafka Tool e o Confluent Control Center, oferecem interfaces baseadas na Web para gerenciar clusters do Kafka.
O SQS, como um serviço totalmente gerenciado, integra-se perfeitamente ao console de gerenciamento do AWS. Essa interface baseada na Web permite que os usuários criem, configurem e monitorem facilmente as filas do SQS sem a necessidade de ferramentas adicionais.
O Kafka oferece bibliotecas de clientes para várias linguagens, como Java, Python e Go. Sua sintaxe pode ser complexa devido a conceitos como tópicos, partições, offsets e grupos de consumidores.
O SQS fornece SDKs para várias linguagens, incluindo Java, Python e Node.js. Sua sintaxe é mais simples e se concentra no envio e recebimento de mensagens de e para filas. A sintaxe do SQS é mais simples, enquanto a sintaxe do Kafka é mais complexa devido à sua natureza distribuída e aos recursos avançados.
O preço do Kafka varia de acordo com o modelo de implantação (serviços autogerenciados ou gerenciados, como o Confluent Cloud ou o Amazon MSK).
O SQS segue um modelo de preços de pagamento conforme o uso, com base no número de solicitações e transferências de dados.
Depois de analisar as semelhanças e diferenças, aqui está uma comparação detalhada entre o Apache Kafka e o Amazon SQS, com foco em qual deles é o vencedor para cada categoria, dependendo do caso.
O Kafka é um sistema de mensagens distribuído, pub-sub, que opera em uma arquitetura de log distribuído, em que as mensagens são preservadas em um log de confirmação distribuído.
Por outro lado, o SQS é um sistema de mensagens totalmente gerenciado e baseado em pull que se baseia em uma arquitetura de corretor de mensagens, com um serviço central orquestrando o gerenciamento de filas.
A arquitetura distribuída do Kafka o torna mais dimensionável e tolerante a falhas, enquanto a arquitetura centralizada do SQS simplifica o gerenciamento, mas pode se tornar um gargalo.
O Kafka e o Amazon SQS oferecem alta escalabilidade. O Kafka é conhecido por seus recursos de streaming de alto rendimento, tolerante a falhas e horizontalmente dimensionável. Ele pode lidar com grandes volumes de dados e tem períodos de retenção de dados estendidos.
O Amazon SQS é famoso por sua capacidade de lidar com milhões de mensagens por segundo e pelo escalonamento automático em resposta ao tráfego variável.
O Kafka é mais dimensionável para lidar com grandes volumes de dados e fornecer períodos de retenção mais longos, enquanto o SQS é mais fácil de dimensionar automaticamente para cargas de trabalho menores.
O Kafka foi projetado para garantir a persistência dos dados por meio de seu sistema de registro replicado. Ele oferece flexibilidade ao permitir a configuração do período de retenção e do espaço em disco usado para o armazenamento de dados.
Por outro lado, o SQS garante a persistência das mensagens armazenando-as em vários data centers, o que aumenta a durabilidade do sistema. Ele vem com um período de retenção padrão de 4 dias, que pode ser ajustado até um máximo de 14 dias com base nos requisitos do usuário.
Ambas as plataformas oferecem persistência de mensagens, mas o Kafka oferece mais flexibilidade na configuração de períodos de retenção e armazenamento.
O Apache Kafka e o Amazon SQS oferecem recursos robustos de mensagens com entrega garantida. O Kafka garante a entrega de mensagens "pelo menos uma vez" e pode alcançar a semântica "exatamente uma vez" por meio de mecanismos como gravações de mensagens idempotentes e suporte transacional.
Por outro lado, o SQS também garante a entrega de mensagens "pelo menos uma vez" e fornece a semântica de entrega "exatamente uma vez" por meio de seus mecanismos de desduplicação.
Ambas as plataformas oferecem garantias semelhantes de entrega de mensagens, sendo que o Kafka oferece recursos mais avançados, como gravações e transações idempotentes.
Uma diferença importante entre o Kafka e o SQS é como eles lidam com o consumo de mensagens.
O Kafka usa grupos de consumidores para leitura independente de diferentes partições, permitindo o balanceamento de carga e a tolerância a falhas. O SQS não oferece suporte integrado a grupos de consumidores, portanto, são necessárias filas separadas para cada consumidor a fim de obter uma funcionalidade semelhante.
Isso mostra as diversas abordagens que o Kafka e o SQS adotam para gerenciar as interações do consumidor com as mensagens.
O suporte do Kafka para grupos de consumidores o torna mais adequado para cenários que envolvem vários consumidores e balanceamento de carga.
O Kafka conta com um ecossistema de integração mais amplo e oferece conectores para vários sistemas e estruturas de dados. Por outro lado, o SQS é totalmente integrado a outros serviços do AWS, o que facilita a incorporação em qualquer arquitetura baseada no AWS.
O SQS é o vencedor para arquiteturas baseadas no AWS, enquanto o Kafka oferece mais flexibilidade para integração com sistemas e estruturas que não sejam do AWS.
Ao comparar o Kafka e o SQS, fica claro que eles atendem a necessidades diferentes. O Kafka exige um pouco mais em termos de instalação e configuração, apresentando uma curva de aprendizado mais acentuada, principalmente quando você se aprofunda nos conceitos de sistemas distribuídos.
Por outro lado, o SQS se destaca por sua simplicidade. Como um serviço totalmente gerenciado, ele exige o mínimo de instalação e configuração, o que o torna uma opção mais acessível para casos de uso simples.
O SQS é mais fácil de usar e de começar a usar, enquanto o Kafka exige mais experiência em sistemas distribuídos e configuração.
O Kafka, uma plataforma de código aberto, precisa de investimento em infraestrutura e gerenciamento, mas pode ser mais econômico para lidar com cargas de trabalho de grande escala. Por outro lado, o SQS oferece um serviço totalmente gerenciado com um modelo de preço de pagamento conforme o uso, o que o torna potencialmente mais econômico para cargas de trabalho menores.
O SQS geralmente é mais econômico para cargas de trabalho menores, enquanto o Kafka pode ser mais econômico para cargas de trabalho em grande escala, dependendo dos custos de infraestrutura e gerenciamento.
Para entender o Kafka, você deve se aprofundar em sistemas distribuídos e processamento de fluxo. Ele é rico em conceitos como tópicos, partições, compensações e grupos de consumidores. Por outro lado, o SQS tem uma API fácil de usar, o que simplifica o envio e o recebimento de mensagens de filas com SDKs em várias linguagens de programação.
O SQS é o vencedor em termos de dificuldade de sintaxe. Ele oferece uma API mais direta e fácil de usar, facilitando a integração com os aplicativos. A sintaxe do Kafka pode ser mais complexa devido à sua natureza distribuída e aos recursos avançados de streaming.
|
Kafka |
SQS |
|
Distribuído, pub-sub |
Centralizado, baseado em puxar |
|
Altamente escalável para grandes volumes |
Altamente escalável para volumes menores |
|
Períodos de retenção configuráveis |
Períodos de retenção limitados |
|
Pelo menos uma vez, exatamente uma vez com transações |
Pelo menos uma vez, exatamente uma vez com deduplicação |
|
Com suporte |
Não suportado |
|
Amplo ecossistema, conectores |
Integração estreita com o AWS |
|
Curva de aprendizado mais acentuada |
Totalmente gerenciado, mais fácil de começar |
|
Código aberto, custos de infraestrutura |
Pagamento conforme o uso |
|
Mais longo |
14 dias |
|
Múltiplos |
Limitada |
|
Mais complexo |
Simples e direto |
Concluindo, se você precisar de um serviço gerenciado e de rápida implantação que se integre bem ao ecossistema do AWS, o AWS SQS é a melhor opção. Ele simplifica o gerenciamento de filas e é dimensionado sem esforço, o que o torna ideal para muitos aplicativos padrão.
Como alternativa, se o seu projeto exigir alta taxa de transferência, baixa latência e a capacidade de ajustar o sistema, o Apache Kafka oferece flexibilidade para streaming e processamento de dados em tempo real.
A escolha da ferramenta certa dependerá das necessidades específicas do seu projeto, incluindo fatores como facilidade de uso, desempenho, escalabilidade e integração. Tanto o Kafka quanto o SQS têm seus pontos fortes, e entendê-los ajudará você a aproveitar a melhor plataforma para seu próximo projeto orientado por dados!
Para continuar aprendendo sobre esses tópicos, confira estes recursos:
Saiba mais sobre infraestrutura e gerenciamento de dados de fluxo com estes cursos!
Curso
Curso
Curso
blog
Adejumo Ridwan Suleiman
13 min
blog
Tim Lu
11 min
blog
Çağlar Uslu
15 min
Tutorial
Natassha Selvaraj
Tutorial
Zoumana Keita