
Curso
Statistical Thinking in Python (Part 1)
3 h
186.5K
Graus de liberdade são um daqueles termos estatísticos que muitas vezes parecem abstratos ou confusos à primeira vista. Você já deve ter ouvido esse termo em algum livro didático.
A resposta curta é que os graus de liberdade medem o quanto seus dados podem variar quando certas restrições, como uma média ou total fixo, são impostas. Se isso parecer confuso, não se preocupe: Neste artigo, a partir da próxima seção, vou explicar tudo com mais detalhes. Vou explicar por que eles existem e dar exemplos claros para que você possa estudá-los e desenvolver uma intuição rigorosa.
Os graus de liberdade são o número de valores em um conjunto de dados ou cálculo que podem variar livremente depois que todas as restrições forem consideradas.
Imagina que te pedem para escolher três números que, somados, dêem exatamente 30. Você pode escolher livremente os dois primeiros números, mas o terceiro número é automaticamente fixado para que o total seja 30. Isso reduz o número de valores que podem realmente variar. Então, os graus de liberdade mostram quantas informações independentes ficam depois de aplicar as restrições.
Em geral, os graus de liberdade são calculados como o número de observações n menos o número de restrições ou parâmetros estimados a partir dos dados.
Diferentes testes estatísticos aplicam diferentes restrições, e é por isso que as fórmulas variam, como no caso de n-1 para um teste t de amostra única. Na prática, raramente é necessário calcular os graus de liberdade manualmente, pois os softwares estatísticos fazem isso automaticamente. Mas, entender o princípio geral vai te ajudar a interpretar os resultados da maneira certa.
Os graus de liberdade existem porque os cálculos estatísticos dependem muito de estimativas, como a média ou a variância da amostra, que usam as informações dos dados. Então, sem levar em conta essas limitações, nossas estimativas de variabilidade, intervalos de confiança, valores p e outras coisas ficariam imprecisas.
Em geral, graus de liberdade mais altos geralmente levam a estimativas mais precisas e intervalos de confiança mais estreitos. Elas também aparecem nos testes de hipóteses porque decidem qual distribuição usar e quanta informação o teste tem. Isso afeta diretamente a confiabilidade da inferência estatística.
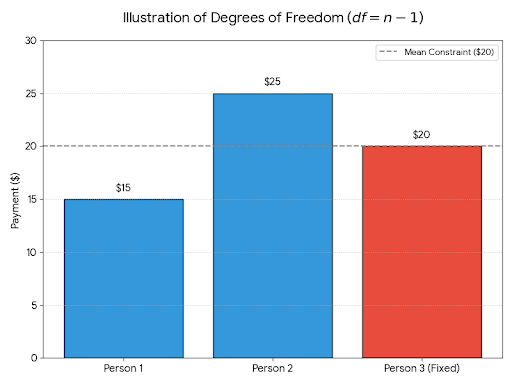
Imagina que você tem três amigos que estão dividindo uma conta de restaurante de $60. Você quer que o pagamento médio seja de $20 por pessoa, então siga os próximos passos:
|
Pessoa |
Participação ($) |
|
Primeira pessoa |
15 |
|
Segunda Pessoa |
25 |
|
Terceira Pessoa |
20 |
|
Média |
20 |
Então, mesmo que você tenha três valores, só dois podiam variar. A gente diz que o último foi determinado pela restrição (que é a média fixa). Então, os graus de liberdade aqui são iguais a 3-1=2.
Isso mostra que o número de pontos de dados (3) não é igual aos graus de liberdade (2). Dizemos que a restrição usa um grau de liberdade.
Nesta seção, vou mostrar alguns exemplos de graus de liberdade em testes estatísticos comuns e como usá-los.
Para um teste t de uma amostra, os graus de liberdade = n - 1. Nesse caso, um grau de liberdade é usado porque estimamos a média amostral a partir dos dados. Para uma amostra maior, a gente acaba com um df maior e testes t mais confiáveis.
Num teste qui-quadrado de adequação, os graus de liberdade = número de categorias - 1. Então, a regra é que a frequência total observada tem que ser igual à frequência total esperada.
Na ANOVA unidirecional, os graus de liberdade são divididos entre grupos (k-1, onde k é o número de grupos) e dentro dos grupos (N-k, onde N = tamanho total da amostra). Isso mostra as restrições das médias dos dois grupos e da média geral do conjunto de dados.
Nesta seção, vou falar sobre algumas das ideias mais erradas sobre graus de liberdade. Primeiro, os graus de liberdade não são o tamanho da amostra, porque eles geralmente são menores por causa das restrições que os reduzem.
Em outras palavras, graus de liberdade não são a mesma coisa que o número de variáveis ou parâmetros. Eles contam especificamente as informações independentes após as restrições.
Além disso, graus de liberdade mais altos nem sempre são melhores, e sempre há uma desvantagem, porque graus de liberdade muito altos podem indicar ajustes excessivos ou suposições irrealistas em alguns contextos.
O tamanho da amostra n é o número total de observações. Embora os graus de liberdade não sejam exatamente o tamanho da amostra, eles são muito influenciados por ela. Isso vem do fato de que os graus de liberdade são normalmente n menos o número de restrições ou parâmetros estimados. É por isso que df é quase sempre menor que n. A relação entre eles existe porque estimar os parâmetros coloca restrições nos dados.
A regra geral é focar menos no cálculo exato e mais no que a restrição realmente representa.
Baixos graus de liberdade significam menos informações independentes, o que, por sua vez, leva a intervalos de confiança mais amplos e menor poder estatístico. Você deve confiar nos resultados do seu software, mas sempre faça verificações de sanidade, como perguntar se os graus de liberdade relatados fazem sentido, considerando o tamanho da sua amostra e o teste que está sendo feito.
Os graus de liberdade medem a quantidade de informação realmente independente disponível nos seus dados após considerar todas as restrições. A ideia principal a ter em mente é simples: sempre que você estima um parâmetro ou impõe uma restrição, você perde um grau de liberdade. Então, entender esse conceito melhora sua intuição estatística e te ajuda a interpretar os resultados dos testes com mais confiança. Com a prática, os graus de liberdade vão parecer bem menos misteriosos e muito mais significativos.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Matt Crabtree
10 min
blog
Elena Kosourova
15 min
blog
Matt Crabtree
15 min
blog
Tim Lu
12 min
Tutorial
Tutorial
Abid Ali Awan


