Programa
Fundamentos da IA
10 h
Neste tutorial, vamos aprender a fazer o ajuste fino do Llama 3 com um conjunto de dados médicos. Também transformaremos o modelo em um formato pronto para uso local por meio do aplicativo Jan.
Mais especificamente, vamos:
Se você está procurando um programa selecionado para aprender IA, confira este programa de seis cursos sobre Fundamentos de IA.
A Meta lançou uma nova série de grandes modelos de linguagem (LLMs, Large Language Models) chamada Llama 3, uma coleção de modelos de texto para texto pré-treinados e ajustados por instruções.
O Llama 3 é um modelo de linguagem autorregressivo que usa uma arquitetura de transformador otimizada. Os modelos pré-treinados e ajustados por instruções vêm com 8 bilhões e 70 bilhões de parâmetros, com tamanho de contexto de 8 mil tokens.
O Llama 3 8B é o LLM preferido na Hugging Face. Sua versão ajustada por instruções é melhor do que o Gemma 7B-It, do Google, e o Mistral 7B Instruct em várias métricas de desempenho. A versão 70B ajustada por instruções superou o Gemini Pro 1.5 e o Claude Sonnet na maioria das métricas de desempenho:
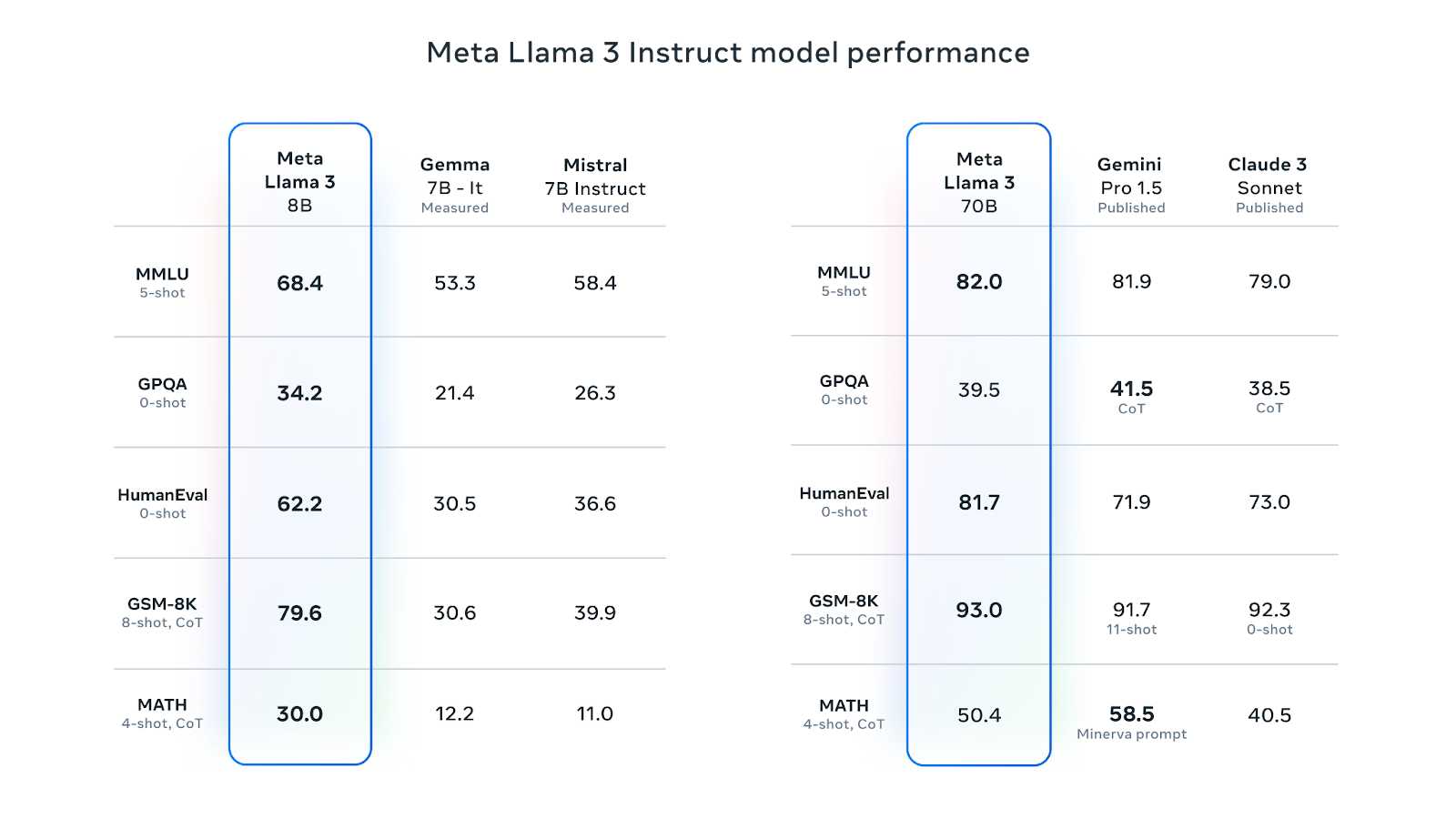
Fonte: Meta Llama 3
A Meta treinou o Llama 3 com uma nova combinação de dados online disponíveis publicamente, usando mais de 15 trilhões de tokens. O limite de conhecimento do modelo 8B é até março de 2023, enquanto o do modelo 70B é dezembro de 2023. Os modelos usam Grouped-Query Attention (GQA), que reduz a largura de banda da memória e aumenta a eficiência.
Os modelos Llama 3 foram lançados nos termos de uma licença comercial personalizada. Para acessar o modelo, você precisa preencher o formulário com seu nome, afiliação e e-mail e aceitar os termos e condições. Se você usar e-mails diferentes para plataformas diferentes, como Kaggle e Hugging Face, talvez seja necessário preencher o formulário várias vezes.
Você pode saber mais sobre o Llama 3 neste artigo: O que é o Llama 3?
Neste tutorial, faremos o ajuste fino do modelo Llama 3 8B-Chat usando o conjunto de dados ruslanmv/ai-medical-chatbot. O conjunto de dados contém 250 mil diálogos entre paciente e médico. Vamos usar o Kaggle Notebook para acessar esse modelo e GPUs gratuitas.
Antes de iniciarmos o Kaggle Notebook, preencha o formulário de download da Meta com seu e-mail do Kaggle e, em seguida, acesse a página do modelo Llama 3 no Kaggle e aceite o contrato. O processo de aprovação pode levar de um a dois dias.
Agora vamos seguir estas etapas:
1. Inicie um novo Notebook no Kaggle e adicione o modelo Llama 3 clicando no botão + Add Input (Adicionar entrada), selecionando a opção Models (Modelos) e clicando no botão de mais + ao lado do modelo Llama 3. Depois disso, selecione a estrutura, a variação e a versão corretas e adicione o modelo.
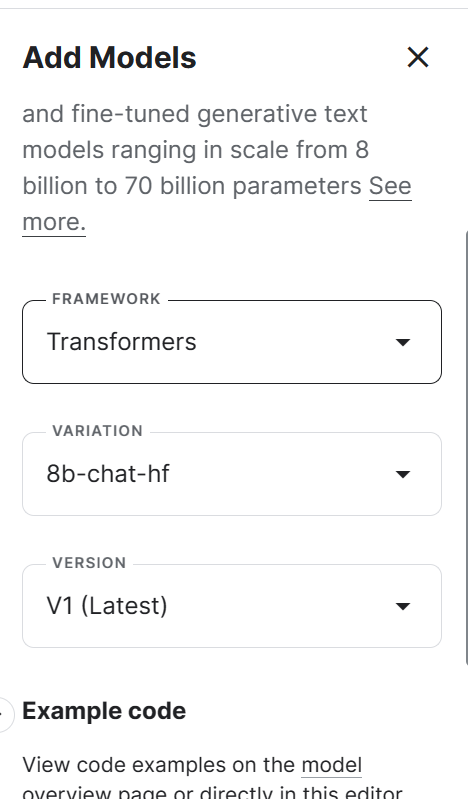
2. Vá até Session options (Opções da sessão) e selecione GPU P100 como acelerador.
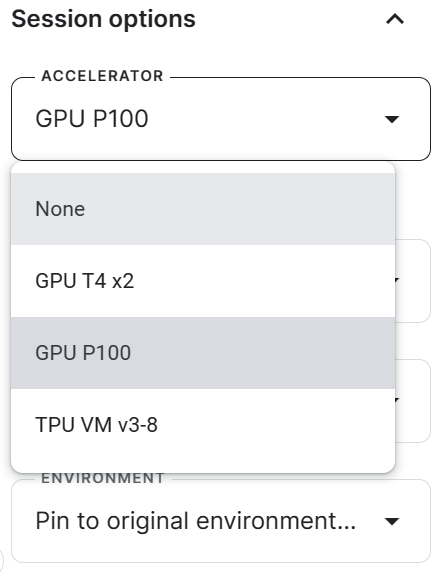
3. Gere o token Hugging Face e Weights & Biases e crie o Kaggle Secrets. Você pode criar e ativar Kaggle Secrets acessando Add-ons > Secrets > Add (Complementos > Segredos > Adicionar).
4. Inicie a sessão do Kaggle instalando todos os pacotes Python necessários.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandb5. Importe as páginas Python necessárias para carregar o conjunto de dados, o modelo, o tokenizador e o ajuste fino.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_format6. Vamos acompanhar o processo de treinamento usando a Weights & Biases e, em seguida, salvar o modelo ajustado no Hugging Face. Para isso, precisamos fazer login no Hugging Face Hub e na Weights & Biases usando a chave da API.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3 8B on Medical Dataset',
job_type="training",
anonymous="allow"
)7. Configure o modelo básico, o conjunto de dados e a variável do novo modelo. Vamos carregar o modelo básico do Kaggle e o conjunto de dados do HugginFace Hub e, em seguida, salvar o novo modelo.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
dataset_name = "ruslanmv/ai-medical-chatbot"
new_model = "llama-3-8b-chat-doctor"8. Defina o tipo de dados e a implementação da atenção.
torch_dtype = torch.float16
attn_implementation = "eager"Nesta parte, vamos carregar o modelo do Kaggle. No entanto, devido a restrições de memória, não é possível carregar o modelo completo. Portanto, estamos carregando o modelo usando precisão de 4 bits.
Nosso objetivo neste projeto é reduzir o uso de memória e acelerar o processo de ajuste fino.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)Carregue o tokenizador e, em seguida, configure um modelo e um tokenizador para tarefas de IA de conversação. Por padrão, ele usa o modelo chatml da OpenAI, que converte o texto de entrada em um formato semelhante a um bate-papo.
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
model, tokenizer = setup_chat_format(model, tokenizer)O ajuste fino do modelo completo leva muito tempo. Portanto, para melhorar o tempo de treinamento, vamos anexar a camada do adaptador com alguns parâmetros, tornando todo o processo mais rápido e eficiente em termos de memória.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
model = get_peft_model(model, peft_config)Para carregar e pré-processar o conjunto de dados, vamos:
1. Carregar o conjunto de dados ruslanmv/ai-medical-chatbot, embaralhá-lo e selecionar apenas as 1.000 primeiras linhas. Isso reduz significativamente o tempo de treinamento.
2. Formatar o modelo de bate-papo para torná-lo coloquial. As perguntas do paciente e as respostas do médico serão combinadas em uma coluna chamada "text".
3. Exibir uma amostra da coluna de texto (a coluna "text" tem um formato semelhante a um bate-papo com tokens especiais).
#Importing the dataset
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
def format_chat_template(row):
row_json = [{"role": "user", "content": row["Patient"]},
{"role": "assistant", "content": row["Doctor"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc=4,
)
dataset['text'][3]
4. Dividir o conjunto de dados em um conjunto de treinamento e validação.
dataset = dataset.train_test_split(test_size=0.1)Estamos definindo os hiperparâmetros do modelo para que possamos executá-lo no Kaggle. Você pode saber mais sobre cada hiperparâmetro lendo o tutorial Ajuste Fino do Llama 2.
Estamos ajustando o modelo para uma época e registrando as métricas usando os pesos e os vieses.
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)Agora, vamos configurar um treinador de ajuste fino supervisionado (SFT, Supervised Fine-tuning) e fornecer um conjunto de dados de treinamento e avaliação, a configuração do LoRA, o argumento de treinamento, tokenizador e modelo. Estamos mantendo max_seq_length como 512 para evitar exceder a memória da GPU durante o treinamento.
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length=512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Daremos início ao processo de ajuste fino executando o seguinte código.
trainer.train()As perdas durante o treinamento e a validação diminuíram. Cogite treinar o modelo por três épocas com o conjunto de dados completo para obter melhores resultados.
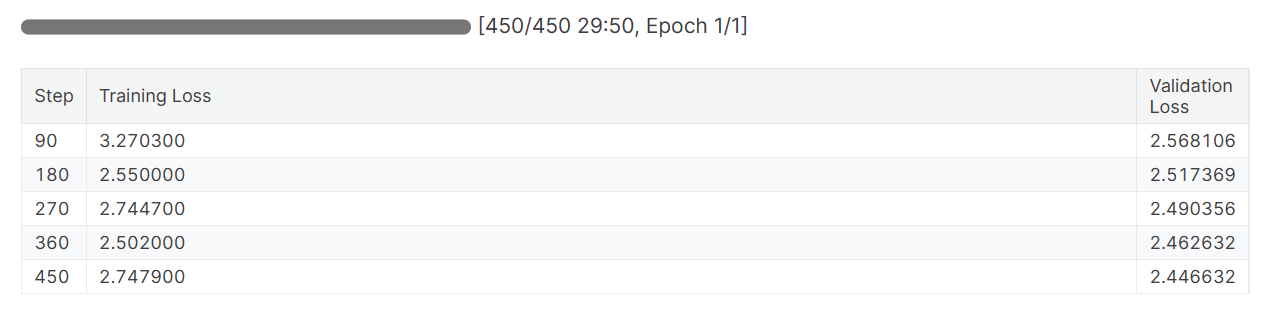
Quando você terminar a sessão da Weights & Biases, ela vai gerar o histórico e o resumo da execução.
wandb.finish()
model.config.use_cache = True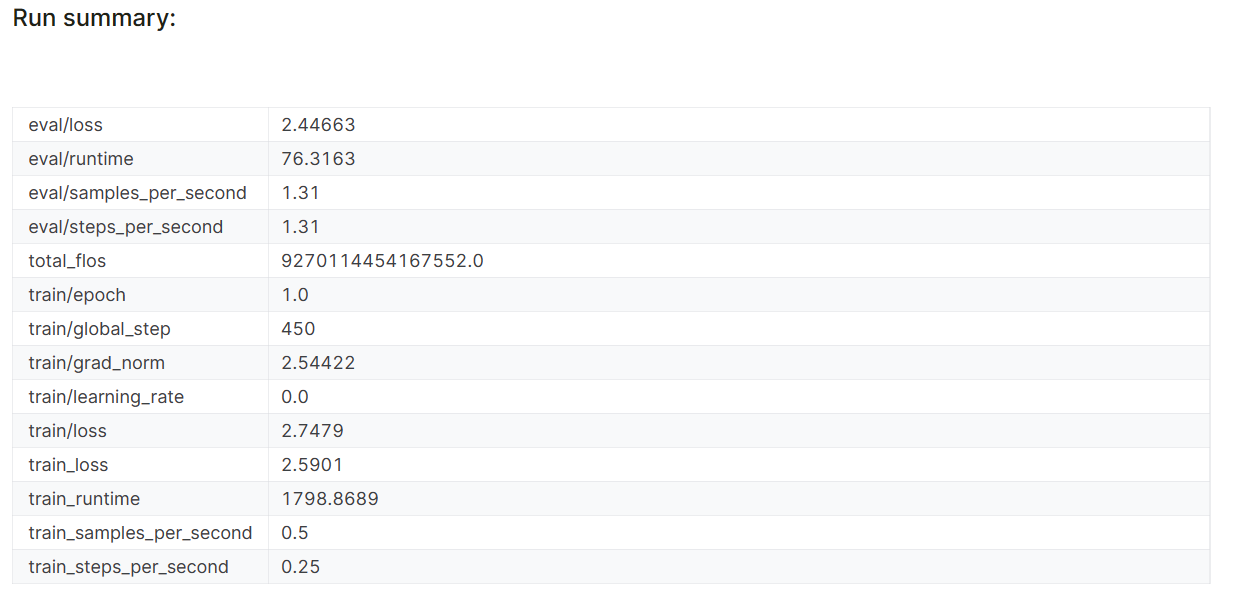
As métricas de desempenho do modelo também são armazenadas com o nome do projeto específico na sua conta da Weights & Biases.
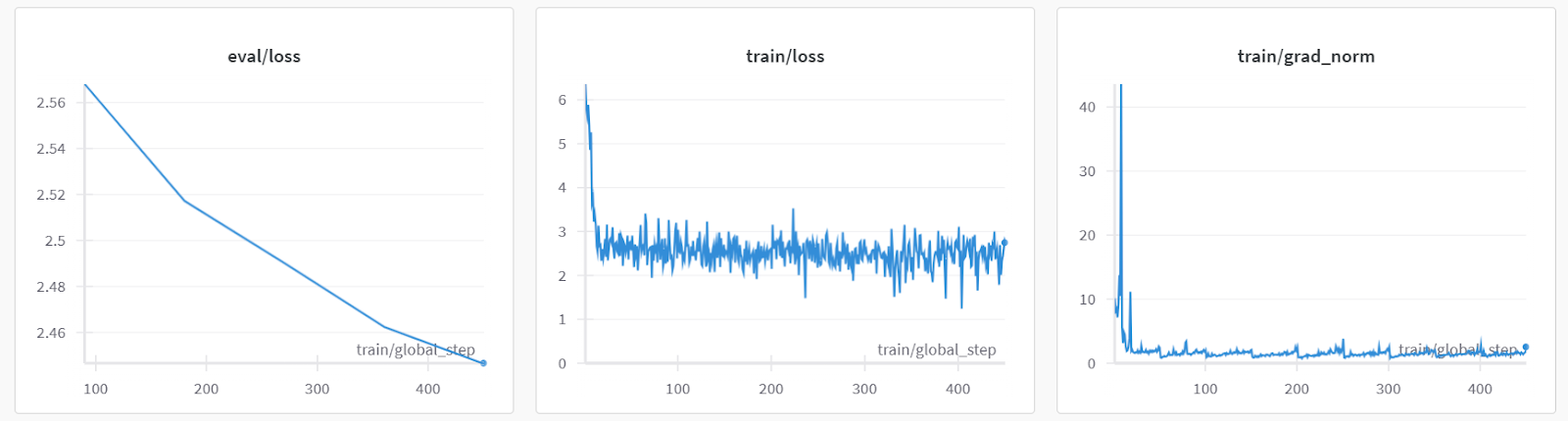
Vamos avaliar o modelo com uma consulta de amostra de paciente para verificar se ele está devidamente ajustado.
Para gerar uma resposta, precisamos converter as mensagens em formato de bate-papo, passá-las pelo tokenizador, inserir o resultado no modelo e, em seguida, decodificar o token gerado para exibir o texto.
messages = [
{
"role": "user",
"content": "Hello doctor, I have bad acne. How do I get rid of it?"
}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False,
add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True,
truncation=True).to("cuda")
outputs = model.generate(**inputs, max_length=150,
num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])
Acontece que podemos obter resultados médios mesmo com uma única época.
Agora, vamos salvar o adaptador ajustado e enviá-lo para o Hugging Face Hub. A API do Hub cria automaticamente o repositório e armazena o arquivo do adaptador.
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)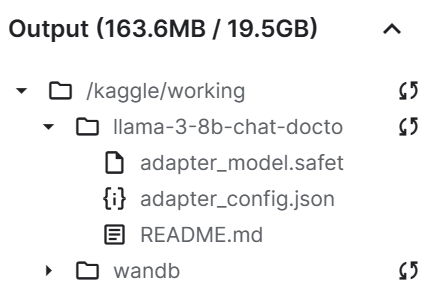
Como podemos ver, o arquivo do adaptador salvo é consideravelmente menor do que o modelo básico.
Por fim, vamos salvar o notebook com o arquivo do adaptador para mesclá-lo com o modelo básico no novo notebook.
Para salvar o Kaggle Notebook, clique no botão Save Version (Salvar versão), no canto superior direito, selecione o tipo de versão como Quick Save (Salvamento rápido), abra a configuração avançada, selecione Always save output when creating a Quick Save (Sempre salvar a saída ao criar um salvamento rápido) e pressione o botão Save (Salvar).
Se você estiver enfrentando um problema ao executar o código, consulte este Kaggle Notebook: Ajuste fino do Llama 3 8B com o conjunto de dados médicos.
Fizemos um ajuste fino em nosso modelo usando a GPU. Você também pode aprender a fazer o ajuste fino de LLMs usando as TPUs seguindo o tutorial Como Fazer o Ajuste Fino e Inferências com o Modelo Gemma do Google Usando TPUs.
Se quiser saber como fazer o ajuste fino de outros modelos, confira este Tutorial de Mistral 7B: Guia Passo a Passo para Usar e Fazer o Ajuste Fino do Mistral 7B.
Para usar o modelo ajustado localmente, precisamos primeiro mesclar o adaptador com o modelo básico e, em seguida, salvar o modelo completo.
Vamos seguir estas etapas:
1. Crie um novo Kaggle Notebook e instale todos os pacotes Python necessários. Verifique se você está usando a GPU como acelerador.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trl2. Faça login no Hugging Face Hub usando o Kaggle Secrets. Isso ajuda a carregar facilmente o modelo completo e ajustado.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)3. Adicione o modelo Llama 3 8B Chat e um Notebook do Kaggle ajustado que salvamos recentemente. Podemos adicionar os Notebooks na sessão atual da mesma forma que adicionamos um conjunto de dados e modelos.
Ao adicionar o Notebook à sessão do Kaggle, é possível acessar os arquivos de saída. No nosso caso, é um arquivo de adaptador de modelo.
4. Defina a variável com a localização do modelo básico e do adaptador.
base_model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
new_model = "/kaggle/input/fine-tune-llama-3-8b-on-medical-dataset/llama-3-8b-chat-doctor/"Primeiro, carregamos o tokenizador e o modelo básico usando a biblioteca transformers. Em seguida, configuramos o formato de bate-papo usando a biblioteca trl. Por fim, carregamos e mesclamos o adaptador ao modelo básico usando a biblioteca PEFT.
A função merge_and_unload() nos ajuda a mesclar os pesos do adaptador com o modelo básico e a usá-lo como modelo autônomo.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, new_model)
model = model.merge_and_unload()Para verificar se o modelo foi mesclado corretamente, faremos uma inferência simples usando pipeline da biblioteca transformers. Vamos converter a mensagem usando o modelo de chat e, em seguida, fornecer um prompt para o pipeline. O pipeline foi inicializado usando o modelo, o tokenizador e o tipo de tarefa.
Como observação, você pode definir device_map como "auto" se quiser usar várias GPUs.
messages = [{"role": "user", "content": "Hello doctor, I have bad acne. How do I get rid of it?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
Nosso modelo ajustado está funcionando como esperado depois de ser mesclado.
Agora vamos salvar um tokenizador e um modelo usando a função save_pretrained().
model.save_pretrained("llama-3-8b-chat-doctor")
tokenizer.save_pretrained("llama-3-8b-chat-doctor")Os arquivos do modelo são armazenados no formato safetensors, e o tamanho total do modelo é de cerca de 16 GB.
Podemos enviar todos os arquivos para o Hugging Face Hub usando a função push_to_hub().
model.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)
tokenizer.push_to_hub("llama-3-8b-chat-doctor", use_temp_dir=False)No final, podemos salvar o Kaggle Notebook da mesma forma que fizemos anteriormente.
O uso do Adaptador ajustado para modelagem completa do Kaggle Notebook ajuda a resolver qualquer problema relacionado à execução do código por conta própria.
Não é possível usar os arquivos safetensors localmente, pois a maioria dos chatbots de IA locais não é compatível com eles. Em vez disso, vamos convertê-lo no formato de arquivo GGUF com llama.cpp.
Inicie a nova sessão do Kaggle Notebook e adicione o Notebook Fine Tuned Adapter to the full model.
Clone o repositório llama.cpp e instale a estrutura llama.cpp usando o comando make, conforme mostrado abaixo.
Como observação, o comando abaixo funciona apenas com o Kaggle Notebook. Talvez você precise fazer algumas alterações para executá-lo em outras plataformas ou localmente.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullPara converter o modelo no formato GGUF, execute o comando a seguir na célula do Kaggle Notebook.
convert-hf-to-gguf.py requer o diretório do modelo de entrada, o diretório do arquivo de saída e um tipo de saída.
!python convert-hf-to-gguf.py /kaggle/input/fine-tuned-adapter-to-full-model/llama-3-8b-chat-doctor/ \
--outfile /kaggle/working/llama-3-8b-chat-doctor.gguf \
--outtype f16Em poucos minutos, o modelo é convertido e salvo localmente. Em seguida, você pode salvar o notebook para salvar o arquivo.
Se você tiver problemas para executar o código acima, consulte o Kaggle Notebook HF LLM to GGUF.
Os laptops comuns não têm memória RAM e GPU suficientes para carregar todo o modelo, por isso temos que quantificar o modelo GGUF, reduzindo o modelo de 16 GB para cerca de 4-5 GB.
Inicie a nova sessão do Kaggle Notebook e adicione o Notebook HF LLM to GGUF.
Em seguida, instale o llama.cpp executando o seguinte comando na célula do Kaggle Notebook.
%cd /kaggle/working
!git clone --depth=1 https://github.com/ggerganov/llama.cpp.git
%cd /kaggle/working/llama.cpp
!sed -i 's|MK_LDFLAGS += -lcuda|MK_LDFLAGS += -L/usr/local/nvidia/lib64 -lcuda|' Makefile
!LLAMA_CUDA=1 conda run -n base make -j > /dev/nullO script de quantização requer o diretório do modelo GGUF, o diretório do arquivo de saída e um método de quantização. Estamos convertendo o modelo usando o método Q4_K_M.
%cd /kaggle/working/
!./llama.cpp/llama-quantize /kaggle/input/hf-llm-to-gguf/llama-3-8b-chat-doctor.gguf llama-3-8b-chat-doctor-Q4_K_M.gguf Q4_K_M
O tamanho do modelo diminuiu consideravelmente de 15.317,05 MB para 4.685,32 MB.
Para enviar o arquivo único para o Hugging Face Hub, vamos:
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
from huggingface_hub import HfApi
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
api = HfApi()
api.upload_file(
path_or_fileobj="/kaggle/working/llama-3-8b-chat-doctor-Q4_K_M.gguf",
path_in_repo="llama-3-8b-chat-doctor-Q4_K_M.gguf",
repo_id="kingabzpro/llama-3-8b-chat-doctor",
repo_type="model",
)
Nosso modelo foi enviado com sucesso para o servidor remoto, conforme mostrado abaixo.
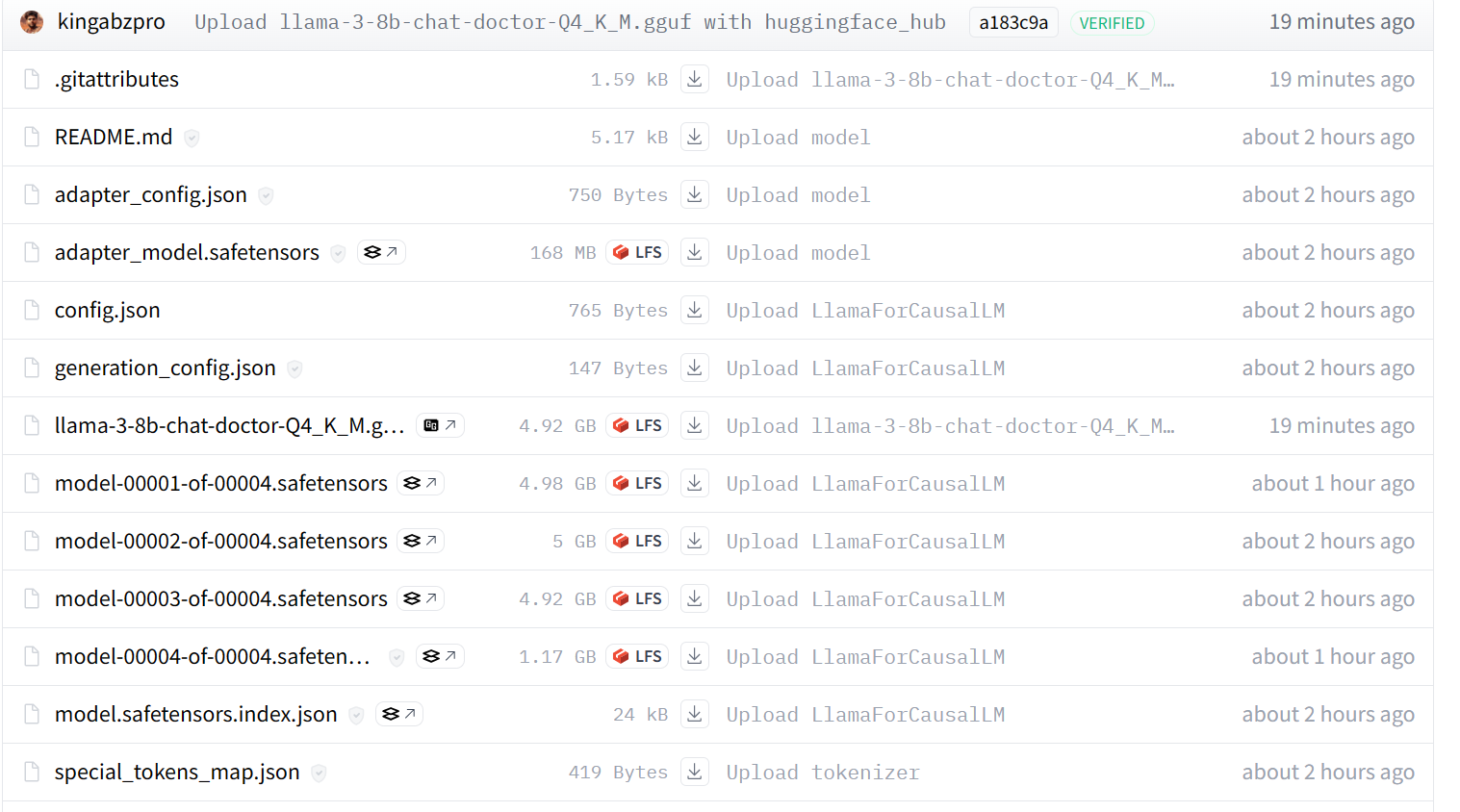
Se você ainda estiver com problemas, consulte o Kaggle Notebook GGUF to Quantize, que contém o código inteiro e o resultado.
Se estiver procurando uma maneira mais simples de converter e quantizar o modelo, acesse este Hugging Face Space e coloque nele o Hub Model Id.
Para usar o modelo GGUF localmente, você deve fazer o download e importá-lo no aplicativo Jan.
Para fazer o download do modelo, é preciso:
1. Acessar nosso repositório Hugging Face.
2. Clicar na guia Files (Arquivos).
3. Clicar no arquivo do modelo quantizado com a extensão GGUF.

4. Clicar no botão download.
Leva alguns minutos para fazer o download do arquivo localmente.
Baixe e instale o aplicativo Jan em Jan AI.
Isto é o que vemos quando iniciamos o aplicativo Jan:
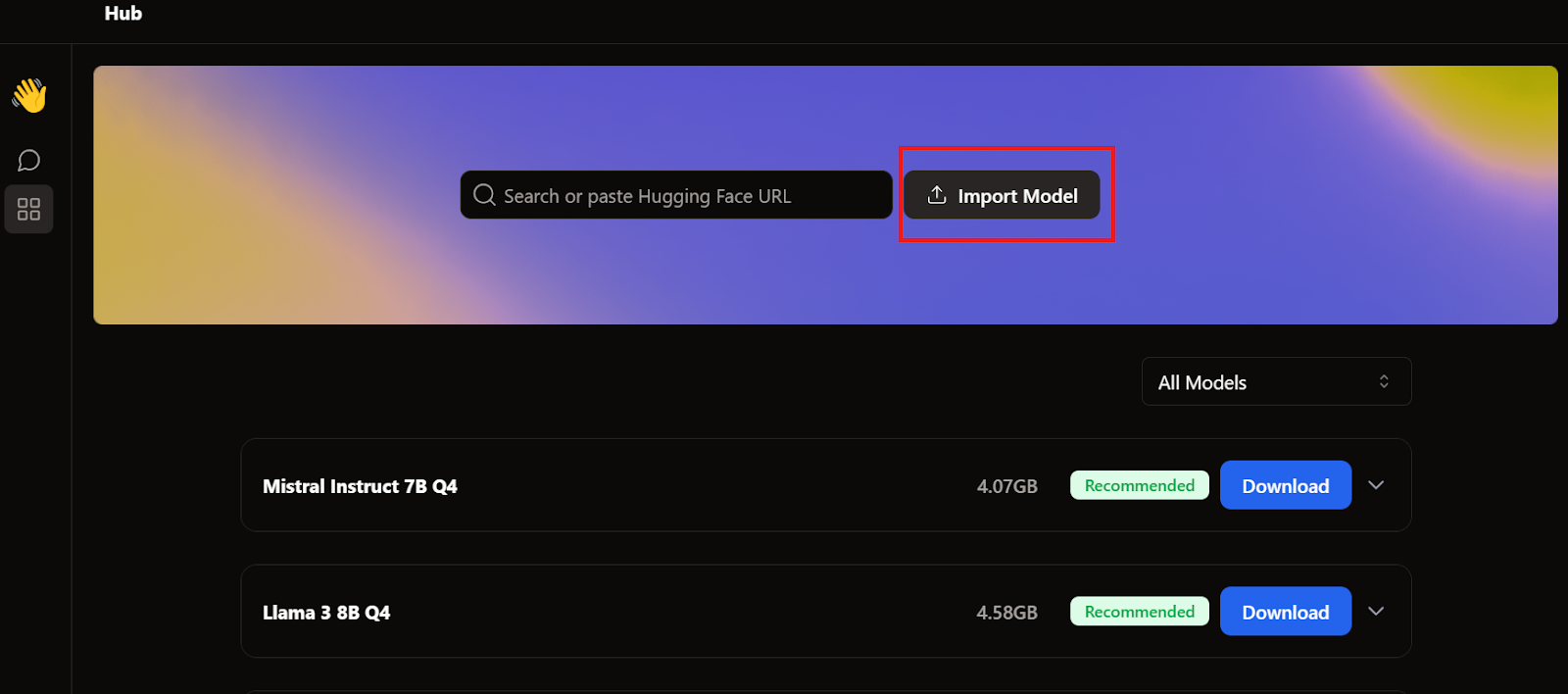
Para adicionar o modelo ao aplicativo Jan, precisamos importar o arquivo GGUF quantizado.
É preciso acessar o menu do Hub e clicar em Import Model (Importar modelo), conforme mostrado abaixo. Colocamos o local do arquivo baixado recentemente, e é isso.
Acessamos o menu Thread e selecionamos o modelo com ajuste fino.
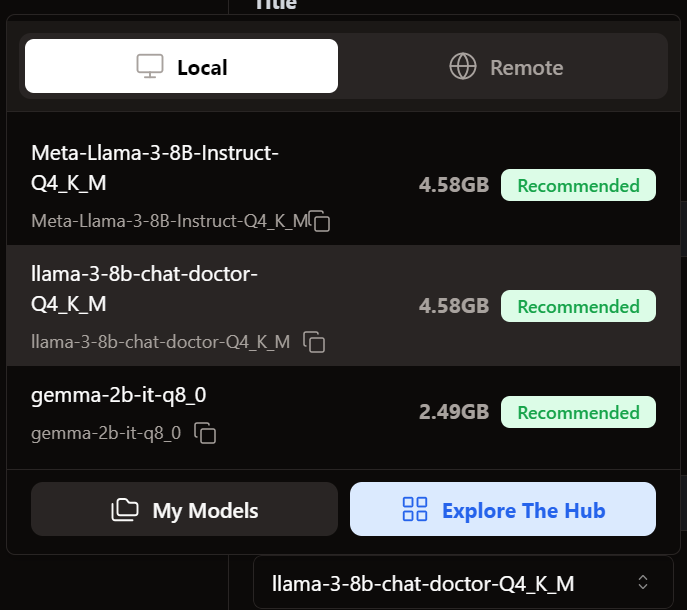
Antes de usar o modelo, precisamos personalizá-lo para exibir a resposta corretamente. Primeiro, modificamos o modelo Prompt na seção Model Parameters (Parâmetros do modelo).
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistantAdicionamos o token Stop e alteramos o token max para 512 nos parâmetros de inferência.
<endofstring>, Best, Regards, Thanks,-->Começamos a escrever as consultas, e o médico responderá de acordo.
Nosso modelo ajustado está funcionando perfeitamente no local.
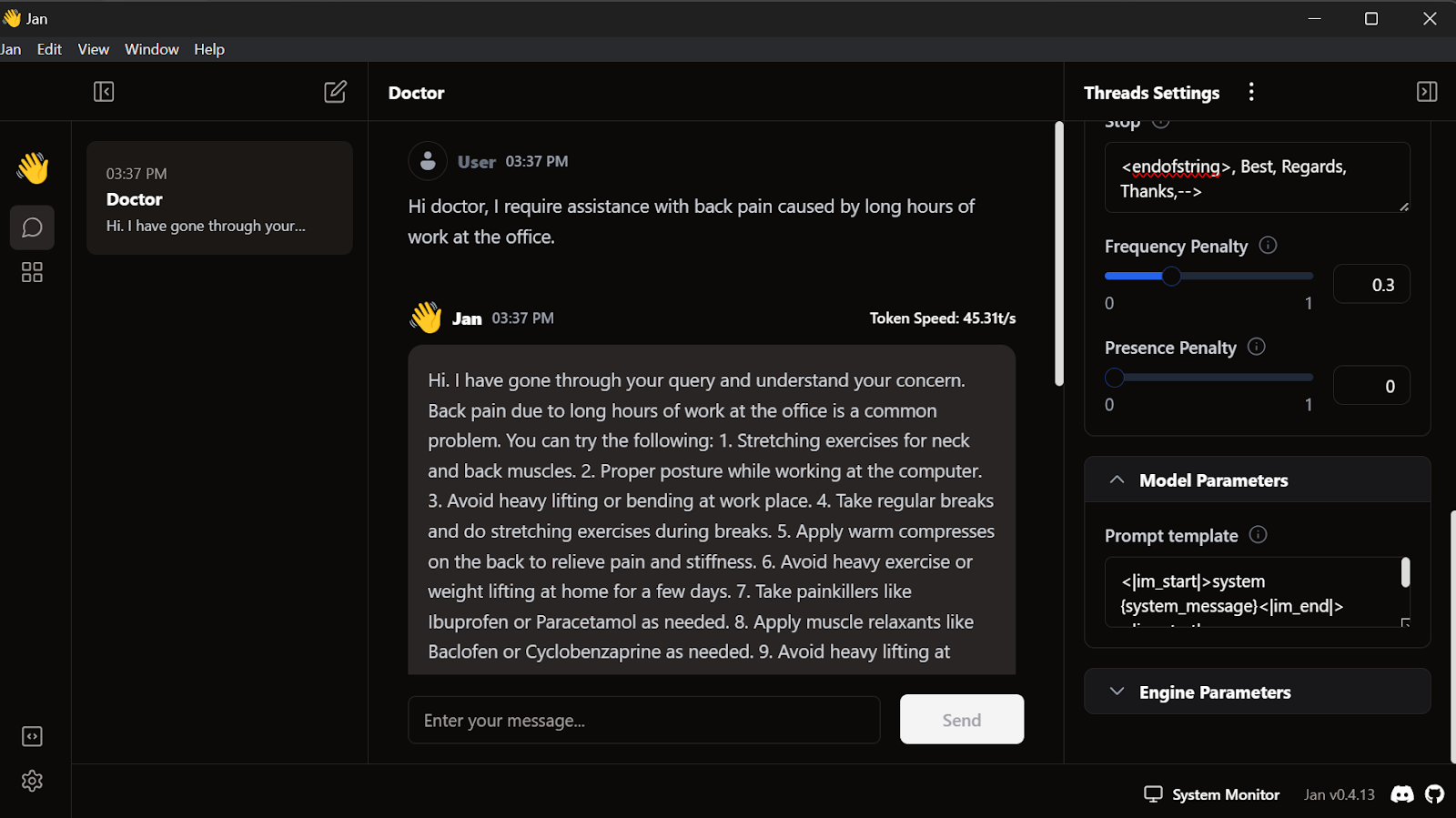
Esse modelo funciona com GPT4ALL, Llama.cpp, Ollama e muitos outros aplicativos locais de IA. Para saber como usar cada um deles, confira este tutorial sobre como executar LLMs localmente.
O ajuste fino do modelo Llama 3 com um conjunto de dados personalizado e seu uso local abriram muitas possibilidades para a criação de aplicativos inovadores. Entre os possíveis casos de uso estão soluções de IA de conversação privadas e personalizadas, chatbots especializados em um domínio, classificação de textos, tradução de idiomas, sistemas de recomendação personalizados para responder a perguntas e até mesmo aplicativos de automação de marketing e saúde.
Com as estruturas Ollama e Langchain, o desenvolvimento do próprio aplicativo de IA está mais acessível do que nunca, exigindo apenas algumas linhas de código. Para fazer isso, siga o tutorial LlamaIndex: Uma Estrutura de Dados para Aplicativos Baseados em Grandes Modelos de Linguagem (LLMs).
Neste tutorial, aprendemos a fazer o ajuste fino do Llama 3 8B Chat com um conjunto de dados médicos. Passamos pelo processo de mesclagem do adaptador com o modelo básico, convertendo-o no formato GGUF e quantizando-o para uso local com um aplicativo de chatbot do Jan.
Se quiser saber mais, confira este programa de habilidades de quatro cursos sobre o Desenvolvimento de Grandes Modelos de Linguagem.
Aprenda IA com estes cursos!
Programa
Programa
Programa
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan

