Curso
Engenharia rápida com a API OpenAI
4 h
48K
Imagine que você tem um amigo brilhante que é incrivelmente bom em resolver problemas complexos. No entanto, toda vez que você faz uma nova pergunta a esse amigo, o processo deve começar do zero, com tudo o que foi aprendido nos problemas anteriores completamente esquecido.
Isso seria bastante frustrante, certo? Esse é exatamente o desafio que enfrentamos com os modelos de linguagem grandes (LLMs) quando se trata de tarefas de raciocínio complexas. Os LLMs são excelentes na geração de texto, mas muitas vezes têm dificuldades com tarefas de raciocínio complexas devido à sua incapacidade de reter o conhecimento de interações anteriores.
Imagine, no entanto, dar a esses LLMs um "caderno mental" para armazenar e reutilizar insights valiosos - essa é a essência do Buffer of Thoughts (BoT) (BoT).
Neste tutorial, exploraremos o Buffer of Thoughts (BoT), uma nova estrutura que está mudando a forma como os LLMs resolvem problemas complexos. Começarei explicando as ideias básicas por trás da BoT, incluindo o meta-buffer e o gerenciador de buffer. Em seguida, veremos como a BoT funciona passo a passo, desde a compreensão do problema até a localização e o uso dos modelos de pensamento corretos - você verá como a BoT torna os LLMs mais precisos, eficientes e confiáveis.
Também compartilharei alguns resultados impressionantes de experimentos realizados com este artigo que mostram o bom desempenho da BoT em diferentes tarefas. Ao final deste tutorial, você entenderá por que a BoT é uma grande novidade no momento e como ela pode ser usada em aplicativos do mundo real.
O Buffer of Thoughts (BoT) é uma nova estrutura projetada para aprimorar os recursos de raciocínio dos LLMs.
A BoT combina dois elementos principais para orientar os LLMs em tarefas de raciocínio complexas:
Vamos examinar esses dois componentes em mais detalhes.
O meta-buffer é como uma biblioteca de estratégias universais de solução de problemas. Ele armazena "modelos de pensamento", que são abordagens de alto nível para resolver problemas. Esses modelos são provenientes de diferentes tarefas com as quais o LLM se deparou.
Pense nisso como uma caixa de ferramentas repleta de ferramentas versáteis que podem ser adaptadas a muitos trabalhos diferentes.
O gerenciador de buffer é o organizador dinâmico do sistema BoT. Sua função inclui atualizar o meta-buffer com novos modelos de pensamento à medida que mais tarefas são resolvidas, selecionando os modelos de pensamento mais relevantes para cada novo problema e refinando os modelos existentes com base em sua eficácia.
É como ter um assistente pessoal que organiza constantemente suas anotações, destaca as informações mais úteis e ajuda você a aplicá-las a novos desafios.
A verdadeira mágica acontece por meio do raciocínio aumentado pelo pensamento. Ao se deparar com um novo problema, a estrutura da BoT:
1. Analisa o problema para entender seus principais elementos.
2. Recupera modelos de pensamento relevantes do meta-buffer.
3. Adapta esses modelos para criar uma estrutura de raciocínio específica para o problema.
4. Orienta o LLM no processo de solução de problemas usando essa estrutura.
Imagine que você é um chef. O meta-buffer seria seu livro de receitas pessoal. Esse livro de receitas não contém apenas receitas específicas, mas também uma variedade de técnicas de cozimento. Por exemplo, ele tem seções sobre como refogar legumes adequadamente, criar o molho de redução perfeito ou equilibrar sabores. Essas estratégias de alto nível podem ser aplicadas a uma ampla variedade de pratos.
Agora, imagine que você também tem um subchefe que é extremamente organizado e bem informado. Esse sous-chef é seu gerente de buffer. Eles o ajudam a decidir quais técnicas do seu livro de receitas são mais adequadas para o prato que você está preparando no momento. Enquanto você cozinha, o sous-chef faz anotações sobre o que funcionou bem e o que não funcionou, atualizando suas técnicas e estratégias de acordo.
Quando um novo pedido é recebido, você não começa do zero. Em vez disso, você consulta seu livro de receitas (meta-buffer) para obter as melhores técnicas e conta com seu sous-chef (gerenciador de buffer) para guiá-lo pelo processo de forma eficiente. O sous-chef se lembra do que funcionou melhor em pratos semelhantes no passado e ajuda você a ajustar sua abordagem, garantindo que a refeição seja preparada rapidamente e com o mais alto padrão.

Veja como o processo funcionaria em sua cozinha:
Agora que entendemos o que é a BoT e seus principais componentes, podemos dar uma olhada em como ela funciona nos bastidores. Vamos dividi-lo em quatro elementos:
O destilador de problemas funciona como um tradutor habilidoso, convertendo problemas complexos em uma linguagem que a BoT possa entender e trabalhar com facilidade.
Imagine-o como um leitor meticuloso que extrai informações críticas e restrições do problema de entrada, da mesma forma que destaca as partes mais importantes de um capítulo de um livro didático.
Uma vez que o destilador de problemas tenha identificado esses elementos-chave, ele os organiza em conceitos e estruturas de alto nível. Esse processo pode ser comparado à criação de um resumo conciso de um artigo longo, concentrando-se nas ideias principais e deixando de fora os detalhes desnecessários.
Por exemplo, suponha que você receba um problema complexo sobre horários de trens. O destilador de problemas extrairia cuidadosamente os elementos essenciais, como "velocidades dos trens", "horários de partida" e "distância entre as estações". Em seguida, você organizaria esses elementos em um formato estruturado que fosse fácil de ser processado e compreendido pela BoT.
O meta-buffer é o banco de conhecimento da BoT, armazenando e organizando modelos de pensamento para fácil acesso. Ele contém modelos de pensamento e suas descrições, categorizando-os para uma recuperação eficiente.
É como uma biblioteca bem organizada em que cada livro (modelo de pensamento) tem uma descrição detalhada e é colocado na seção correta.
Quando a BoT precisa recuperar um modelo de pensamento, ela encontra o mais relevante comparando o problema destilado com as descrições do modelo. Esse processo é semelhante ao de um bibliotecário que encontra rapidamente o livro perfeito com base na sua descrição do que você precisa.
A BoT também pode reconhecer quando uma tarefa é totalmente nova e exige um novo modelo de pensamento. Isso é como perceber que você precisa criar uma nova categoria em sua biblioteca pessoal para um tipo exclusivo de livro.
Seguindo nosso exemplo do problema do trem, a BoT teria vários modelos de pensamento em seu meta-buffer, cada um com uma descrição detalhada. Por exemplo, alguns modelos podem estar relacionados ao gerenciamento de tempo, outros ao raciocínio espacial e outros a estratégias de otimização.
Quando o BoT encontra o problema do horário do trem, ele recupera o modelo de pensamento mais relevante comparando os elementos destilados do problema, como "velocidades do trem", "horários de partida" e "distância entre estações", com as descrições em seu meta-buffer. Por exemplo, a BoT pode selecionar um modelo de pensamento especializado em programação e otimização de tempo para lidar com esse problema de forma eficaz.
Suponha que a BoT reconheça que o problema de programação de trens envolve um elemento único que ela nunca encontrou antes, como um tipo incomum de restrição ou um novo objetivo de otimização. Nesse caso, ele pode identificar que essa tarefa é totalmente nova e requer um novo modelo de pensamento.
Suponha que o problema envolva a coordenação de horários em vários meios de transporte (trens, ônibus, voos). Nesse caso, a BoT pode criar e armazenar um novo modelo de pensamento que aborde a programação multimodal, garantindo que ela esteja mais bem preparada para problemas semelhantes no futuro.
Dessa forma, o meta-buffer permite que a BoT armazene, recupere e crie com eficiência novas estratégias para a solução de problemas, aumentando sua capacidade de lidar com tarefas complexas.
É aqui que a BoT aplica os modelos de pensamento selecionados para resolver o problema específico em questão.
Para modelos existentes, o modelo de pensamento recuperado é adaptado para se adequar ao problema atual. É semelhante a usar uma receita, mas ajustando os ingredientes e as quantidades para um grupo maior. A BoT ajusta o modelo de pensamento para atender às especificidades do problema, garantindo uma solução personalizada e eficaz.
Quando você se depara com uma nova tarefa para a qual não há modelos disponíveis, a BoT recorre a modelos predefinidos e de uso geral. Pense nisso como o uso de técnicas básicas de cozinha para preparar um prato que você nunca fez antes. A confiança nos princípios fundamentais permite que a BoT navegue por problemas desconhecidos e desenvolva novas estratégias conforme necessário.
Para o nosso problema de programação de trens, a BoT recuperaria um modelo de pensamento focado na otimização e programação de tempo. Para se adequar ao problema atual, a BoT adaptaria esse modelo. Por exemplo, se o modelo de pensamento original incluir um método para otimizar a programação de um único trem, a BoT o modificará para lidar com vários trens, velocidades variadas e diferentes horários de partida. Essa abordagem personalizada garante que todos os trens operem de forma eficiente e pontual, levando em conta as restrições exclusivas do problema atual.
Mas agora, suponha que o BoT se depare com um novo aspecto do problema de programação de trens, como a integração de programações de trens com programações de ônibus e voos para criar um sistema de transporte multimodal contínuo. Como não há um modelo de pensamento existente para esse cenário específico, a BoT usa modelos predefinidos e de uso geral. A BoT pode aplicar princípios fundamentais de programação e otimização, como dividir o problema em partes menores, analisar cada modo de transporte separadamente e, em seguida, integrar as soluções. Por meio desse processo, a BoT pode desenvolver novas estratégias e modelos, aumentando sua capacidade de lidar com problemas semelhantes de programação multimodal no futuro.
O gerenciador de buffer é o componente de aprendizado e otimização do sistema, melhorando constantemente a base de conhecimento da BoT.
No processo de destilação de modelos, o gerente de buffer resume o processo de solução de problemas em pensamentos de alto nível. É como escrever um documento de "lições aprendidas" após a conclusão de um projeto, capturando a essência do que foi eficaz e por quê.
Para atualizações dinâmicas, o gerenciador de buffer atualiza o meta-buffer com novos modelos de pensamento. Ele usa limites de similaridade para decidir se você deve adicionar novos modelos ou atualizar os existentes, garantindo que o meta-buffer permaneça leve e eficiente. Isso é semelhante a um chef que aprimora constantemente seu livro de receitas, acrescentando novas técnicas e melhorando as existentes, mantendo o livro conciso e prático.
Imagine que o BoT acabou de resolver um problema complexo de programação de trens que envolve vários trens, velocidades variadas e diferentes horários de partida. Depois de concluir essa tarefa, o gerente de buffer resume o processo de solução de problemas em pensamentos de alto nível, capturando as principais estratégias que funcionaram bem, como técnicas específicas para otimizar a sobreposição de horários ou lidar com horários de pico de viagem.
Agora, suponha que a BoT se depare com um problema de programação de trens semelhante, mas ligeiramente diferente, no futuro. O gerenciador de buffer atualiza o meta-buffer com novos modelos de pensamento baseados nessa experiência. Por exemplo, se o novo problema envolver a integração de programações de trens com programações de ônibus, o gerente de buffer poderá refinar o modelo de programação de trens existente para incluir técnicas de integração multimodal.
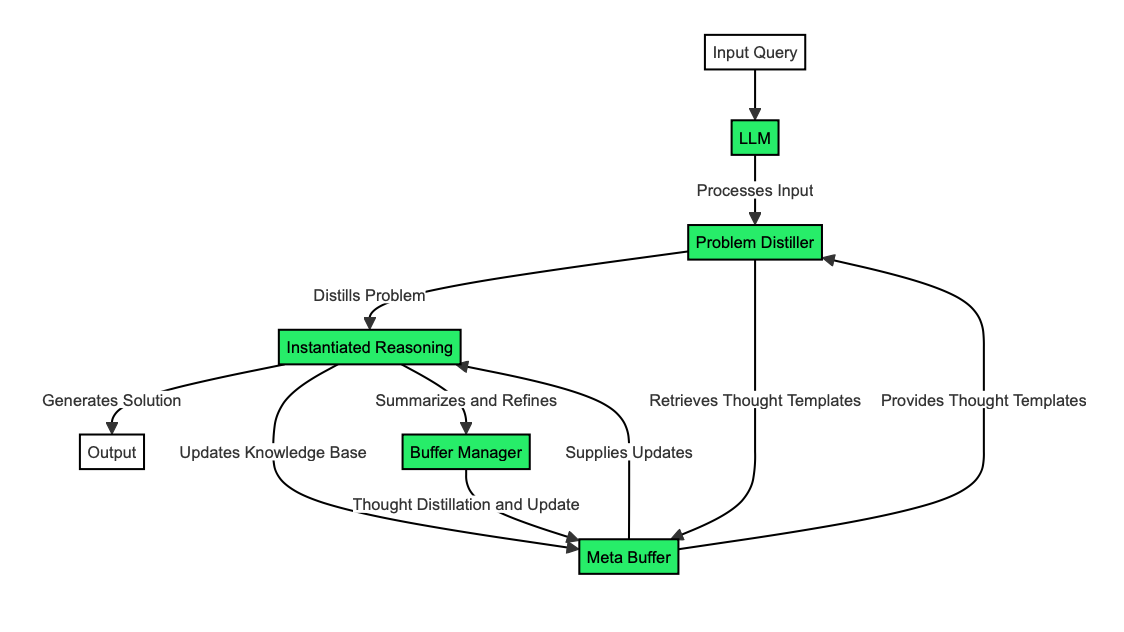
A estrutura Buffer of Thoughts (BoT) oferece várias vantagens significativas para o desenvolvimento do raciocínio LLM, como maior precisão, eficiência de raciocínio e robustez do modelo.
A BoT melhora significativamente a precisão do raciocínio dos LLMs por meio de sua nova abordagem:
A BoT melhora consideravelmente a eficiência do raciocínio LLM, economizando tempo e recursos computacionais:
A BoT melhora a robustez dos LLMs, tornando-os mais confiáveis e consistentes em várias tarefas:
A estrutura do Buffer of Thoughts (BoT) foi testada em uma ampla gama de tarefas, com resultados impressionantes. Para obter informações mais detalhadas, consulte o papel e o repositório do GitHubonde os resultados abordados nesta seção são apresentados em mais detalhes.
A BoT foi avaliada em 10 tarefas desafiadoras de raciocínio intensivo, demonstrando versatilidade e eficácia. Essas tarefas incluíam:
Essas tarefas foram escolhidas para representar uma variedade de cenários de raciocínio complexos, desde a solução de problemas matemáticos até jogos estratégicos e manipulação de linguagem.
O BoT demonstrou melhorias significativas no desempenho em relação aos métodos anteriores de última geração:
O que é particularmente impressionante é que a BoT alcançou esses resultados exigindo apenas cerca de 12% do custo computacional dos métodos de solicitação de várias consultas!
Também foi constatado que a implementação da BoT com modelos de linguagem menores, como o Llama3-8Btem o potencial de superar o desempenho de modelos maiores, como o Llama3-70. Essa descoberta mostra que a BoT pode melhorar significativamente os recursos de modelos de linguagem mais compactos e eficientes.
Esses resultados mostram que a BoT pode aumentar a precisão e, ao mesmo tempo, manter-se eficiente e robusta em diferentes tarefas de raciocínio. Os resultados consistentes destacam as melhorias de desempenho confiáveis da BoT. No entanto, são necessários mais verificações e testes independentes em tarefas mais diversas para entender completamente os recursos e as limitações da BoT.
Já cobrimos bastante coisa hoje, então vamos encerrar com algumas conclusões e pensamentos importantes sobre o rumo que a BoT está tomando.

Isso tudo é para você explorar o Buffer of Thoughts. Espero que este tutorial tenha dado a você uma compreensão clara de seus principais conceitos, funcionamento, benefícios e impacto potencial no raciocínio de IA.
Obrigado pela leitura e até a próxima!
Se você quiser saber mais sobre engenharia de prontidão, recomendo estes blogs:
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
5 min
blog
Javier Canales Luna
11 min
blog
Bhavishya Pandit
9 min
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
Tutorial
Josep Ferrer


