
Programa
Fundamentos da IA
10 h
O Qwen3 é uma das mais completas suítes de modelos de peso aberto lançadas até o momento.
Ele vem da equipe Qwen da Alibaba e inclui modelos que aumentam o desempenho em nível de pesquisa, bem como versões menores que podem ser executadas localmente em hardware mais modesto.
Neste blog, apresentarei uma rápida visão geral do conjunto completo do Qwen3, explicarei como os modelos foram desenvolvidos, analisarei os resultados de benchmark e mostrarei como você pode acessá-los e começar a usá-los.
Nossa equipe também está trabalhando em tutoriais que mostram como executar o Qwen3 localmente e como ajustar os modelos do Qwen3. Certificar-me-ei de atualizar este artigo assim que eles estiverem prontos, portanto, se você voltar aqui nos próximos dois ou três dias, encontrará links para esses recursos adicionados nesta introdução.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O Qwen3 é a mais recente família de modelos de idiomas grandes da equipe Qwen da Alibaba. Todos os modelos da linha são abertos sob a licença Apache 2.0.
O que me chamou a atenção de imediato foi a introdução de um orçamento de pensamento que os usuários podem controlar diretamente no aplicativo Qwen. Isso proporciona aos usuários comuns um controle granular sobre o processo de raciocínio, algo que antes só podia ser feito de forma programática.
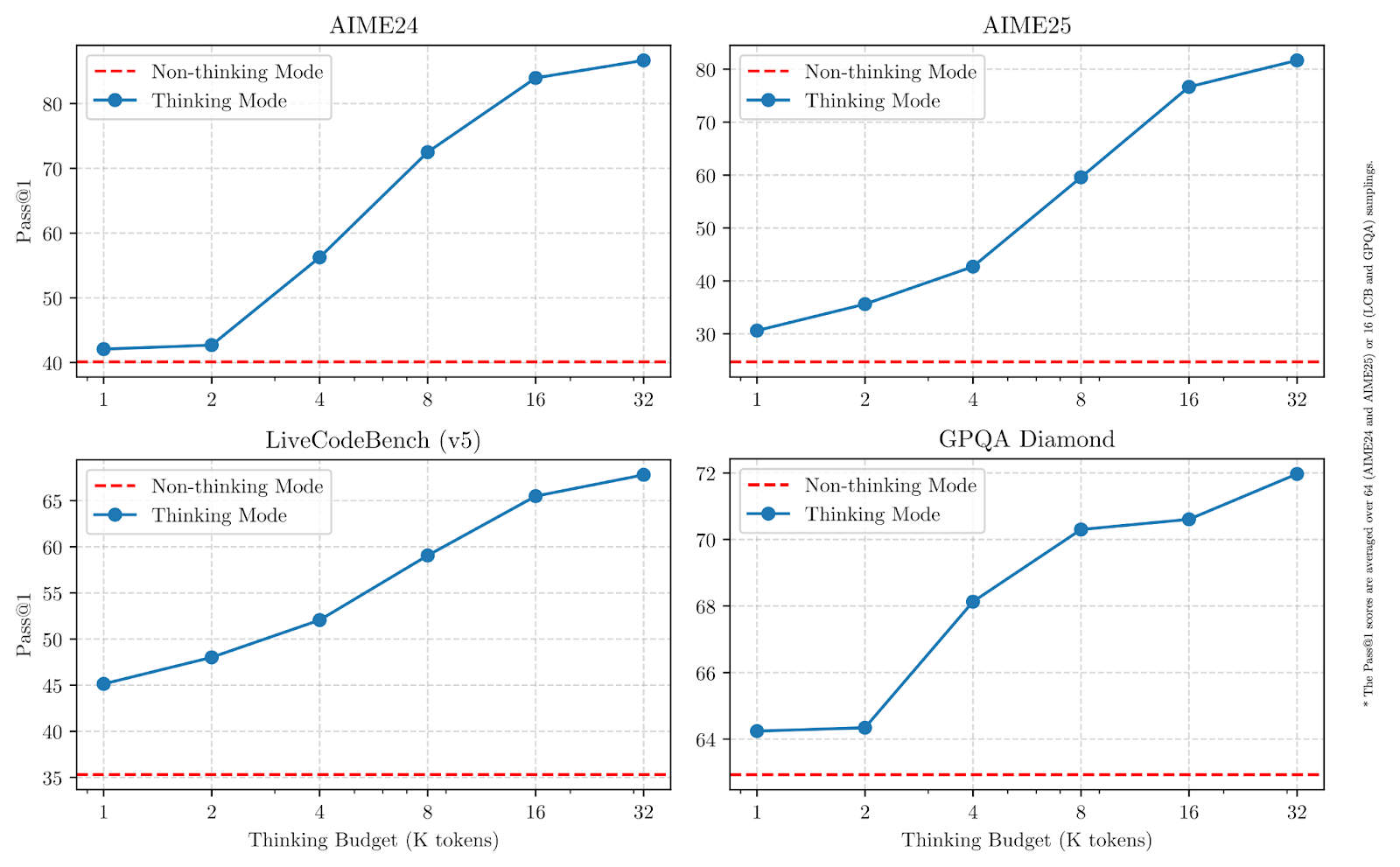
Como podemos ver nos gráficos abaixo, aumentar os orçamentos de raciocínio melhora significativamente o desempenho, especialmente em matemática, codificação e ciências.
Fonte: Qwen
Nos testes de benchmark, o carro-chefe Qwen3-235B-A22B tem um desempenho competitivo em relação a outros modelos de primeira linha e apresenta resultados mais fortes do que o DeepSeek-R1 em codificação, matemática e raciocínio geral. Vamos explorar rapidamente cada modelo e entender para que ele foi projetado.
Esse é o maior modelo da linha Qwen3. Ele usa uma mistura de especialistas (MoE) com 235 bilhões de parâmetros totais e 22 bilhões ativos por etapa de geração.
Em um modelo MoE, apenas um pequeno subconjunto de parâmetros é ativado em cada etapa, o que torna sua execução mais rápida e econômica em comparação com modelos densos (como o GPT-4o), em que todos os parâmetros são sempre usados.
O modelo tem bom desempenho em tarefas de matemática, raciocínio e codificação e, em comparações de benchmark, supera modelos como o DeepSeek-R1.
O Qwen3-30B-A3B é um modelo MoE menor, com 30 bilhões de parâmetros totais e apenas 3 bilhões ativos em cada etapa. Apesar do baixo número de ativos, seu desempenho é comparável ao de modelos densos muito maiores, como o QwQ-32B. É uma opção prática para usuários que desejam uma combinação de capacidade de raciocínio e custos de inferência mais baixos. Assim como o modelo 235B, ele suporta uma janela de contexto de 128K e está disponível no Apache 2.0.
Os seis modelos densos na versão Qwen3 seguem uma arquitetura mais tradicional em que todos os parâmetros estão ativos em cada etapa. Eles abrangem uma ampla gama de casos de uso:
Qwen3-32B, 14B, 8B suportam janelas de contexto de 128K, enquanto Qwen3-4B, 1.7B, 0.6B suportam 32K. Todos são abertos e licenciados sob o Apache 2.0. Os modelos menores desse grupo são adequados para implementações leves, enquanto os maiores estão mais próximos dos LLMs de uso geral.
O Qwen3 oferece diferentes modelos, dependendo da profundidade de raciocínio, da velocidade e do custo computacional que você precisa. Aqui está uma rápida visão geral do site :
|
Modelo |
Tipo |
Comprimento do contexto |
Melhor para |
|
Qwen3-235B-A22B |
MdE |
128K |
Tarefas de pesquisa, fluxos de trabalho de agentes, cadeias de raciocínio longas |
|
Qwen3-30B-A3B |
MdE |
128K |
Raciocínio equilibrado com menor custo de inferência |
|
Qwen3-32B |
Dense |
128K |
Implantações de uso geral de alto nível |
|
Qwen3-14B |
Dense |
128K |
Aplicativos de médio porte que precisam de raciocínio sólido |
|
Qwen3-8B |
Dense |
128K |
Tarefas de raciocínio leves |
|
Qwen3-4B |
Dense |
32K |
Aplicativos menores, inferência mais rápida |
|
Qwen3-1.7B |
Dense |
32K |
Casos de uso móveis e incorporados |
|
Qwen3-0.6B |
Dense |
32K |
Configurações muito leves ou restritas |
Se você estivertrabalhando em tarefas que exijam raciocínio mais profundo, uso de ferramentas de agente ou manuseio de contextos longos, o Qwen3-235B-A22B lhe dará a maior flexibilidade.
Para os casos em que você deseja manter a inferência mais rápida e barata e, ao mesmo tempo, lidar com tarefas moderadamente complexas, o Qwen3-30B-A3B é uma boa opção.
Os modelos densos oferecem implementações mais simples e latência previsível, o que os torna mais adequados para aplicativos de menor escala.
Os modelos Qwen3 foram criados por meio de uma fase de pré-treinamento de três estágios, seguida por um pipeline de pós-treinamento de quatro estágios.
O pré-treinamento é quando o modelo aprende padrões gerais a partir de grandes quantidades de dados (linguagem, lógica, matemática, código) sem que você saiba exatamente o que fazer. O pós-treinamento é quando o modelo é ajustado para se comportar de maneiras específicas, como raciocinar com cuidado ou seguir instruções.
Vou examinar as duas partes em termos simples, sem me aprofundar em detalhes técnicos.
Em comparação com o Qwen2.5, o conjunto de dados de pré-treinamento do Qwen3 foi significativamente ampliado. Cerca de 36 trilhões de tokens foram usados, dobrando a quantidade da geração anterior. Os dados incluíam conteúdo da Web, texto extraído de documentos e exemplos sintéticos de matemática e código gerados pelos modelos Qwen2.5.
O processo de pré-treinamento seguiu três etapas:
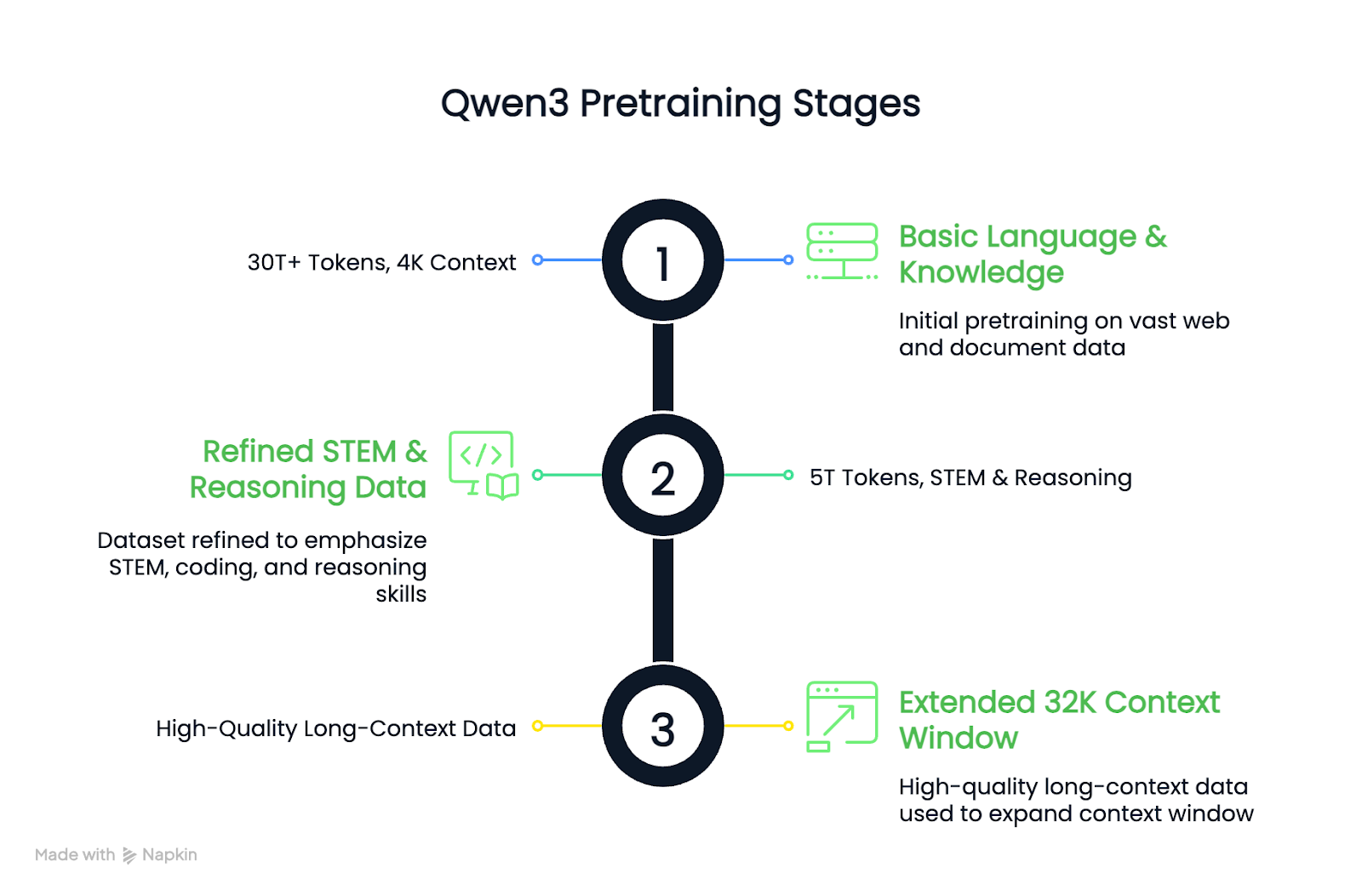
O resultado é que os modelos de base Qwen3 densos se igualam ou superam os modelos de base Qwen2.5 maiores, usando menos parâmetros, especialmente em tarefas STEM e de raciocínio.
O pipeline pós-treinamento do Qwen3 concentrou-se na integração de raciocínio profundo e recursos de resposta rápida em um único modelo. Primeiro, vamos dar uma olhada no diagrama abaixo e, em seguida, explicarei passo a passo:
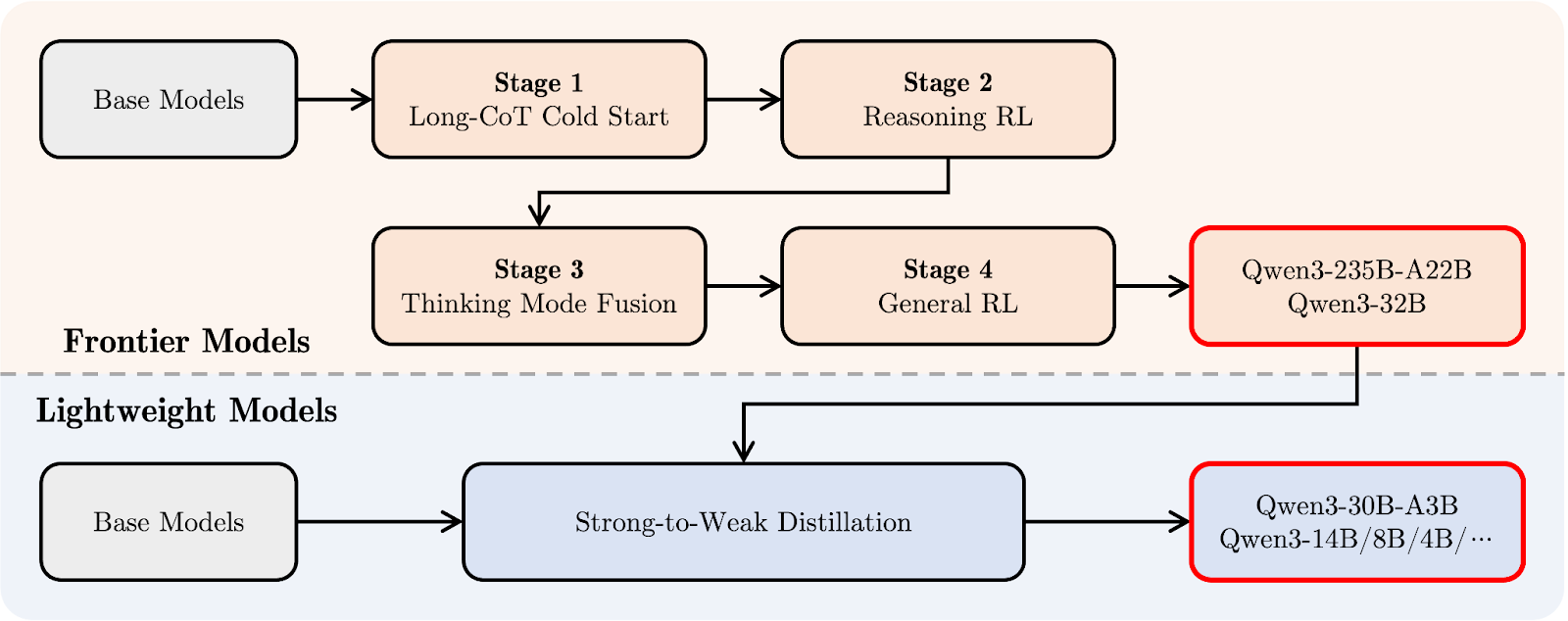
Pipeline pós-treinamento do Qwen 3. Fonte: Qwen
Na parte superior (em laranja), você pode ver o caminho de desenvolvimento dos "Frontier Models" maiores, como o Qwen3-235B-A22B e o Qwen3-32B. Tudo começa com uma Longa cadeia de raciocínio Cold Start (estágio 1), em que o modelo aprende a raciocinar passo a passo em tarefas mais difíceis.
Isso é seguido por Raciocínio Aprendizado por reforço (RL) (estágio 2) para estimular melhores estratégias de solução de problemas. No estágio 3, chamado Thinking Mode Fusion, Qwen3 aprende a equilibrar o raciocínio lento e cuidadoso com respostas mais rápidas. Por fim, o estágio deRL geral do aprimora seu comportamento em uma ampla gama de tarefas, como o acompanhamento de instruções e casos de uso de agentes.
Abaixo disso (em azul claro), você verá o caminho para os "Modelos leves", como o Qwen3-30B-A3B e os modelos menores e densos. Esses modelos são treinados usando a destilação de forte a fraco destilaçãoum processo em que o conhecimento dos modelos maiores é compactado em modelos menores e mais rápidos, sem perder muita capacidade de raciocínio.
Em termos simples: os modelos grandes foram treinados primeiro e, em seguida, os modelos leves foram destilados a partir deles. Dessa forma, toda a família Qwen3 compartilha um estilo de pensamento semelhante, mesmo em modelos de tamanhos muito diferentes.
Os modelos Qwen3 foram avaliados em uma série de benchmarks de raciocínio, codificação e conhecimento geral. Os resultados mostram que o Qwen3-235B-A22B lidera a linha de produtos na maioria das tarefas, mas os modelos menores Qwen3-30B-A3B e Qwen3-4B também oferecem bom desempenho.
Na maioria dos benchmarks, o Qwen3-235B-A22B está entre os modelos de melhor desempenho, embora nem sempre seja o líder.
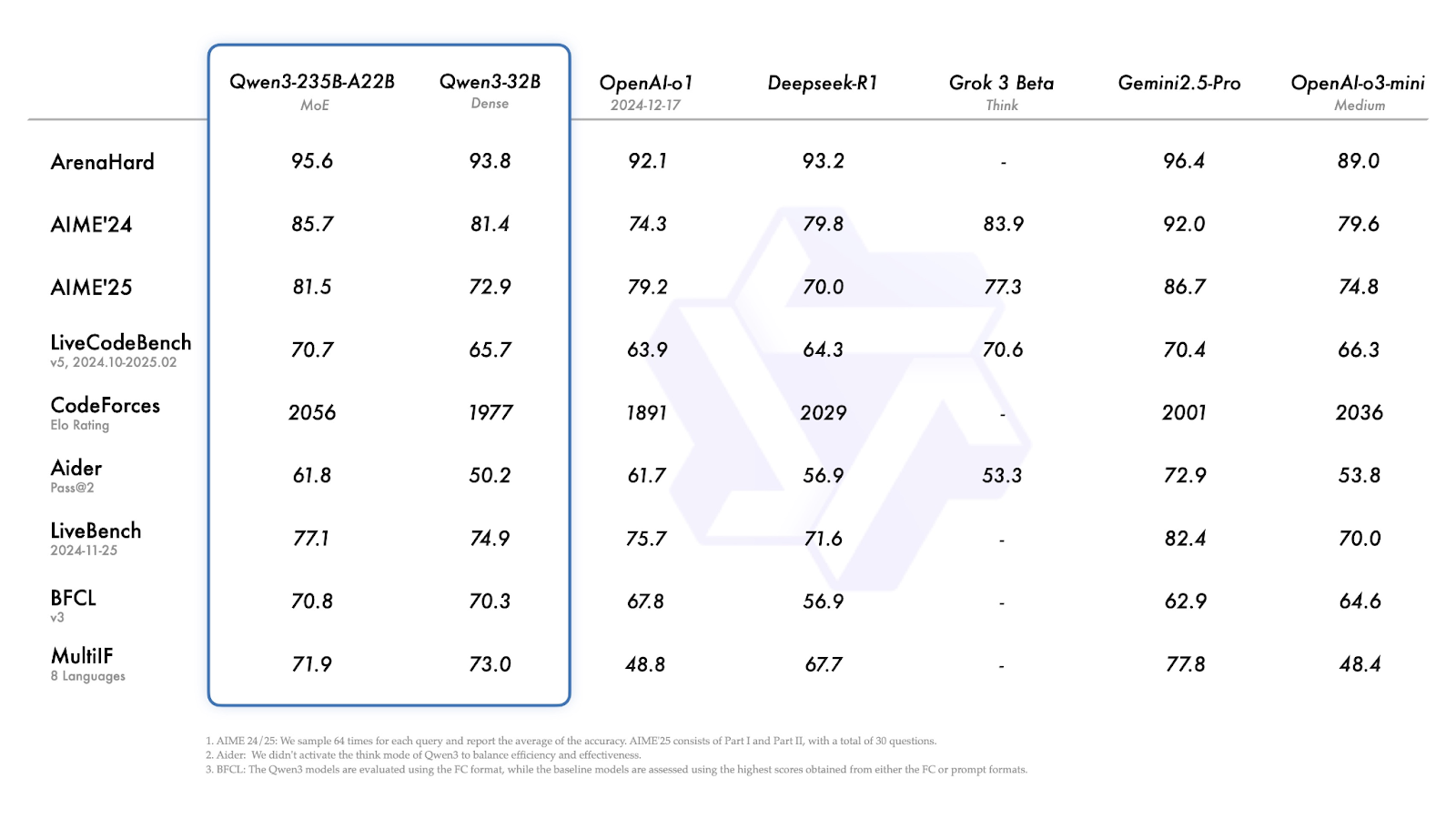
Fonte: Qwen
Vamos explorar rapidamente os resultados acima:
O Qwen3-30B-A3B (o modelo MoE menor) tem um bom desempenho em quase todos os benchmarks, consistentemente igualando ou superando modelos densos de tamanho semelhante.
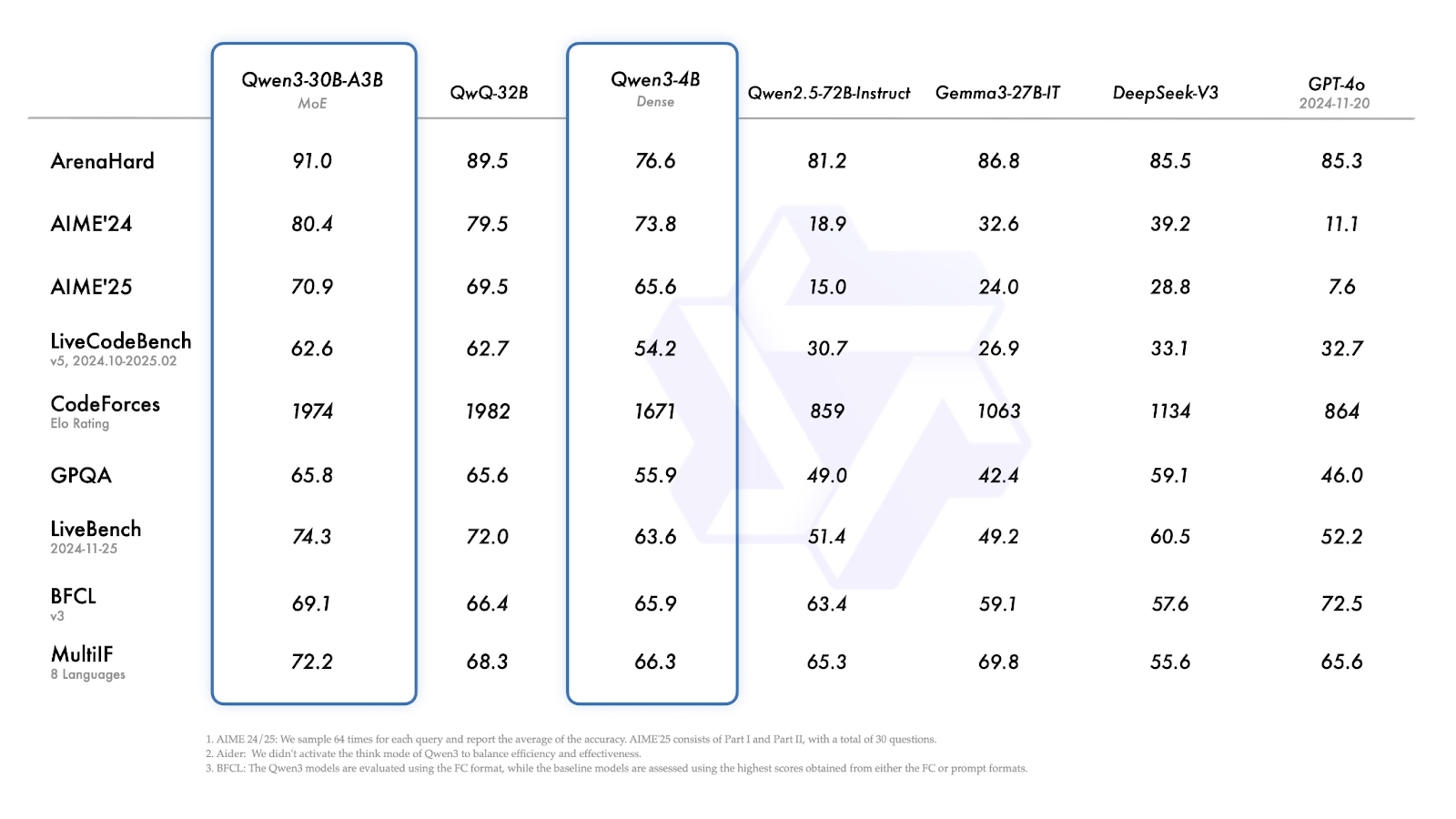
Fonte: Qwen
O Qwen3-4B apresenta um desempenho sólido para seu tamanho:
Os modelos Qwen3 estão disponíveis publicamente e podem ser usados no aplicativo de bate-papo, via API, baixados para implantação local ou integrados a configurações personalizadas.
Você pode experimentar o Qwen3 diretamente em chat.qwen.ai.
Você só poderá acessar três modelos da família Qwen 3 no aplicativo de bate-papo: Qwen3-235B, Qwen3-30B e Qwen3-32B:
O Qwen3 trabalha com formatos de API compatíveis com OpenAI por meio de provedores como ModelScope ou DashScope. Ferramentas como vLLM e SGLang oferecem um serviço eficiente para implantação local ou auto-hospedada. O blog oficial do O blog oficial do Qwen 3 tem mais detalhes sobre isso.
Todos os modelos Qwen3, tanto MoE quanto densos, são liberados sob a licença Apache 2.0. Eles estão disponíveis em:
Você também pode executar o Qwen3 localmente usando:
O Qwen3 é uma das mais completas suítes de modelos de peso aberto lançadas até o momento.
O principal modelo 235B MoE tem um bom desempenho em tarefas de raciocínio, matemática e codificação, enquanto as versões 30B e 4B oferecem alternativas práticas para implantações em menor escala ou com orçamento limitado. A capacidade de ajustar o orçamento de raciocínio do modelo adiciona uma camada extra de flexibilidade para usuários regulares.
No momento, o Qwen3 é uma versão completa que abrange uma ampla gama de casos de uso e está pronto para ser usado em configurações de pesquisa e produção.
Aprenda IA com estes cursos!
Programa
Programa
Programa
blog
Richie Cotton
7 min
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan



