
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
The constantly changing data landscape, coupled with the rapid progress in Generative AI over the past two years, has reshaped the direction of semantic search, increasingly boosting the popularity of semantic search applications.
Search and retrieval is the process of locating and obtaining specific information or data from a larger database or collection based on query criteria. The advancement in AI has increased the quest for more accurate, context-aware, and efficient search methodologies and has led to the emergence of semantic search applications everywhere.
Semantic search transcends the limitations of traditional keyword-based searches by understanding the intent and contextual meaning of queries, thereby delivering more relevant and precise results.
To build an end-to-end semantic search application, one must understand several key concepts such as Embeddings, Vector Databases, Distance Metrics, etc., and also learn how-to-use products/services like Pinecone and OpenAI’s GPT to build and deploy end-to-end semantic search applications.
By the end of this blog, readers will gain a comprehensive understanding of the principles of semantic search, embeddings, and the role of vector databases, and will finally learn how to implement semantic search in Python using:
If you're curious to learn more with some hands-on exercises, check out our course, Vector Databases for Embeddings with Pinecone.
Embedding is a core concept in machine learning. It bridges the gap between the complex, nuanced world of human language and understanding and the precise, mathematical representation of the human world into numbers.
Unstructured data, like text, images, audio, and video files, does not conform to a specific, organized format, posing challenges for storage and processing in conventional databases. Its analysis for machine learning and AI applications often requires transformation into multi-dimensional numeric representations through vector embeddings. The process of converting unstructured data into multidimensional numeric vectors is called Embedding.
Embeddings are multi-dimensional numerical representations of text, images, or any type of unstructured data, enabling machines to learn the complexity of human communication, relationships among concepts, or patterns within data in a way that’s computationally efficient and contextually rich.
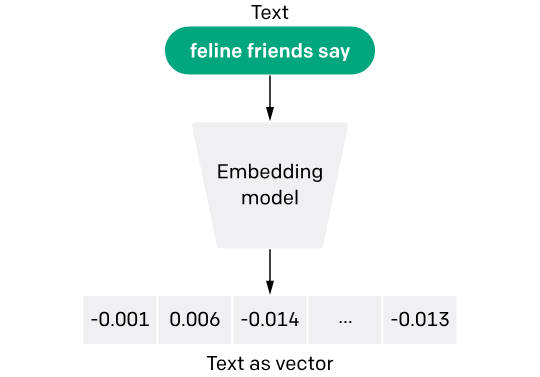
OpenAI’s text and code embedding model (Image Source)
The core idea behind embedding models is that similar items can be represented by points that are close to each other in a high-dimensional space. This concept allows for the capture of intricate relationships within the data, such as synonyms, analogies, or even more abstract connections, by reducing the vast complexity of human language or other data types into a form that machines can work with.
For instance, in text data, words are transformed into vectors (numbers), which are essentially arrays of numbers. These vectors encapsulate the essence of the words’ meaning, usage, and context within the fabric of a language model's understanding.
The length of the vector, as returned by the embedding model, depends on the model you are using. For example, if you are using OpenAI’s embedding model, the length of the vector will always be `1536`.
Behind the scenes, the embedding model is just a giant Neural Network Model trained on an extremely large corpus of data. The model learns to assign vectors to the input data in such a way that the geometric relationship between these vectors mirrors the semantic or conceptual relationships between the data instances.
For example, in a well-trained embedding model, the vector representing the word "king" minus the vector for "man" plus the vector for "woman" might result in a vector very close to the one representing "queen." This ability to perform arithmetic operations with meanings is a powerful demonstration of how embeddings capture the underlying semantics of language.
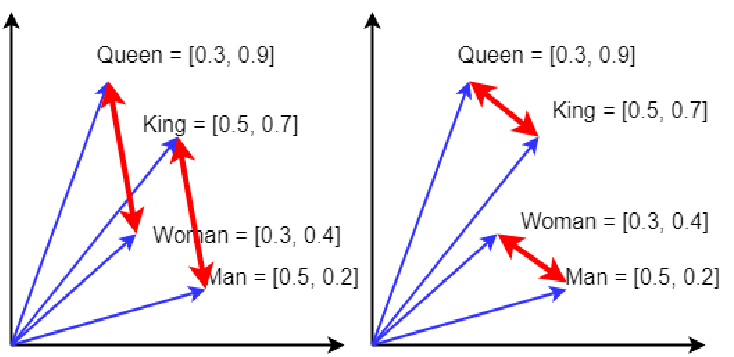
The classical king + woman − man ≈ queen example of neural word embeddings (Image Source)
If you want, you can train your own embedding model, but that may require the collection of a very large amount of data and resources to train a gigantic neural network model that may cost millions of dollars and take several months to train.
The other alternative, which is more practical, is to use some kind of pre-trained embedding model. There are many open-source embedding models available on Hugging Face that you can download and use locally, or you can use proprietary models provided by companies like OpenAI, Anthropic, Cohere, etc.
In this blog, we will use OpenAI’s `text-embedding-ada-002` model, which is priced modestly ($0.00010 per 1K tokens). This means a book of 1000 pages will cost roughly less than $1 only.
Embeddings are crucial for a multitude of applications across various domains. In semantic search, they allow systems to go beyond simple keyword matching, enabling the retrieval of results that are contextually related to the query, even if the exact words aren't used in the content. This capability dramatically improves the relevance and accuracy of search results, making information discovery more intuitive and efficient.
Embeddings are not limited to text. Image embeddings, for example, enable similar advancements in computer vision, allowing machines to recognize objects, scenes, and activities in images and videos by understanding them in a high-dimensional vector space. This understanding is not just about identifying pixels but grasping the essence of what those pixels represent.
Embedding models are not just transformative but extremely useful as they convert the complexity of real-world data into a language (numeric vectors) that machines can understand and act upon, enabling a wide range of applications that rely on deep semantic understanding and intelligent data processing.
To learn more about Embeddings, check out the Introduction to Text Embeddings with the OpenAI API blog.
Vector databases represent a relatively new category of non-relational data storage, which is becoming increasingly popular due to the recent advancements in generative AI and large language models.
Unlike traditional relational databases that organize data in rows and columns or other types of non-relational data stores like Document Database, which organizes data as a json or xml object, vector databases are designed to store and handle multidimensional vector data efficiently.
A vector database is a specialized database optimized for storing and querying vectors. Vectors are essentially arrays of numbers that represent data points in a multi-dimensional space.
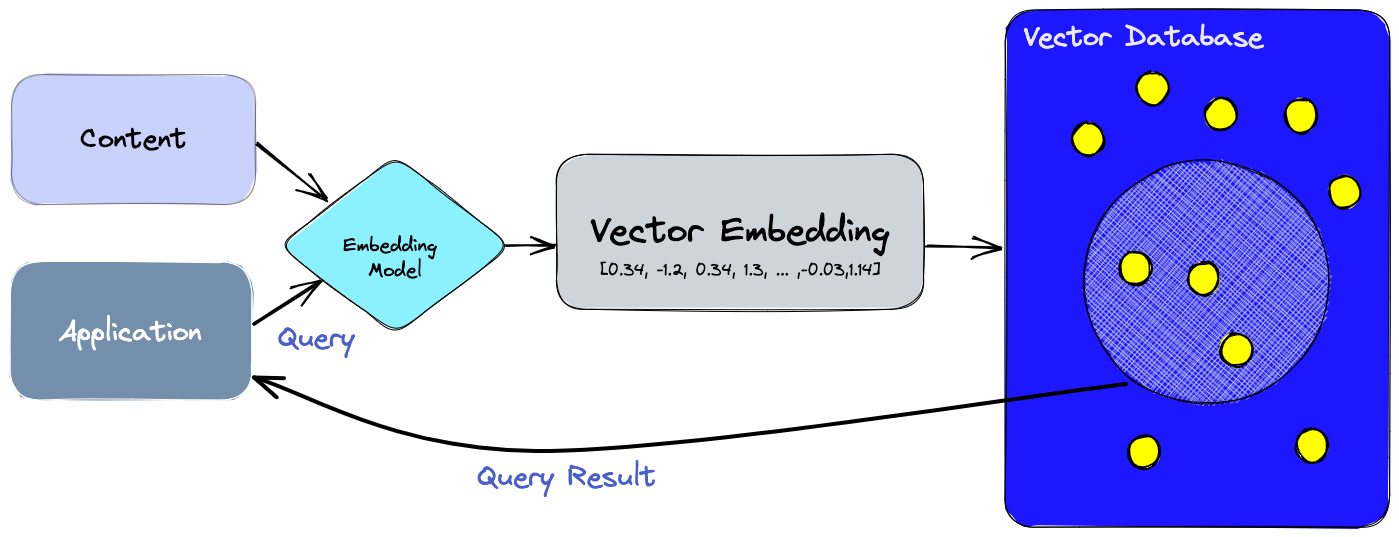
The key advantage of vector databases is their ability to perform similarity searches efficiently. This means they can quickly find items in the database that are "closest" to a given query item, according to some measure of distance or similarity.
This capability is crucial for applications like recommendation systems, where you might want to find products similar to what a user likes, or in semantic search applications, where the goal is to find documents that are semantically related to a query phrase.
Vector databases use a variety of algorithms for indexing and searching vectors, often relying on Approximate Nearest Neighbor (ANN) search techniques.
Semantic search represents a significant leap in improving how search engines understand and process user queries. Unlike traditional search methods that focus on literal matches between the query's text and the content of documents, semantic search delves into the intent and contextual meaning behind a query.
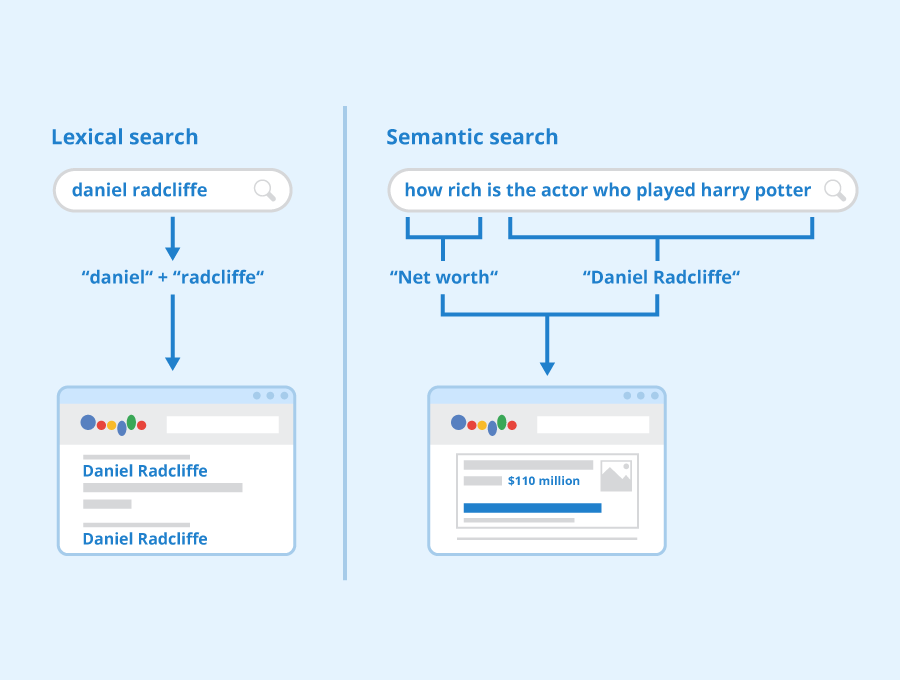
Lexical Search vs. Semantic Search (Image Source)
The evolution of search technologies towards semantic search in the last decade has been driven by several factors. Voice search, powered by virtual assistants like Siri, Alexa, and Google Assistant, relies heavily on natural language processing to understand and execute user commands.
The conversational nature of voice searches demands an understanding of context, requiring search engines to grasp the meaning behind whole sentences or longer phrases.
The complexity of human language is a big barrier for traditional lexical-based search applications, which semantic search is overcoming pretty quickly. There are thousands of words in the English language that have multiple meanings and the actual meaning depends on the context in which the word was used. These words are known as polysemous words.
For example, A word like "table" could refer to a piece of furniture or a data arrangement, depending on the context.
The rise of multimodal large language models (LLMs) is a leading driver behind the exploding popularity of semantic search applications. Semantic search, which aims to understand the searcher's intent and the contextual meaning of terms as they appear in the searchable dataspace, is being significantly enhanced by the capabilities of multimodal LLMs.
As these models evolve, they not only understand and generate text but also interpret and create content across various formats, including images, audio, and videos. These advancements mean that searches can now go beyond mere keyword matching to comprehend the nuances of language, the subtleties of different media, and the complex relationships between concepts.
For instance, a search query could be made using natural language, and the system could return results that are not only text-based but also include relevant images, video clips, or audio snippets, all understood and curated by the AI to match the query's intent.
Semantic search has a broad range of applications across various domains, offering substantial benefits in enhancing the relevance and precision of search results:
Interested in learning more about Vector Databases? Check out this Comprehensive guide to the best vector databases.

The landscape of vector databases (Image Source)
Pinecone is a specialized vector database designed to handle complex, high-dimensional data. It offers advanced search and indexing capabilities, enabling data engineers and scientists to build and run large-scale machine learning projects efficiently.
If you want to dive deeper into Pinecone, check out Mastering Vector Databases with Pinecone Tutorial: A Comprehensive Guide on Datacamp.
OpenAI offers access to all the models via its platform API. This includes the popular GPT, DALL-E, and Whisper models, in addition to three embedding models.

These APIs can be interfaced with through HTTP requests, enabling compatibility with any programming language capable of HTTP communication.
Python users can also use the openai library to interact with these APIs, which makes it even simpler and easier to use. This library can be installed using pip install openai.
Utilizing the OpenAI API in Python with the openai library requires only a minimal amount of code.
import os
os.environ["OPENAI_API_KEY"] = " "
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are expert in Fitness & Health."},
{"role": "user", "content": "Explain what is Keto diet?"}
]
)
print(completion.choices[0].message)Output: (truncated)
ChatCompletionMessage(content="The ketogenic diet, commonly known as the keto diet, is a low-carbohydrate, high-fat diet. The diet is named after ketosis, a metabolic state where your body starts burning fat for energy instead of carbohydrates. This is accomplished by drastically reducing your intake of carbohydrates and increasing your intake of fats….", role='assistant', function_call=None, tool_calls=None)
Discover how ChatGPT and large language models are revolutionizing the digital landscape! Dive into Datacamp’s cheat sheet to master the essentials of leveraging one of the most potent AI APIs available - the OpenAI API.
After you sign up for an OpenAI account. simply head over to https://platform.openai.com/api-keys
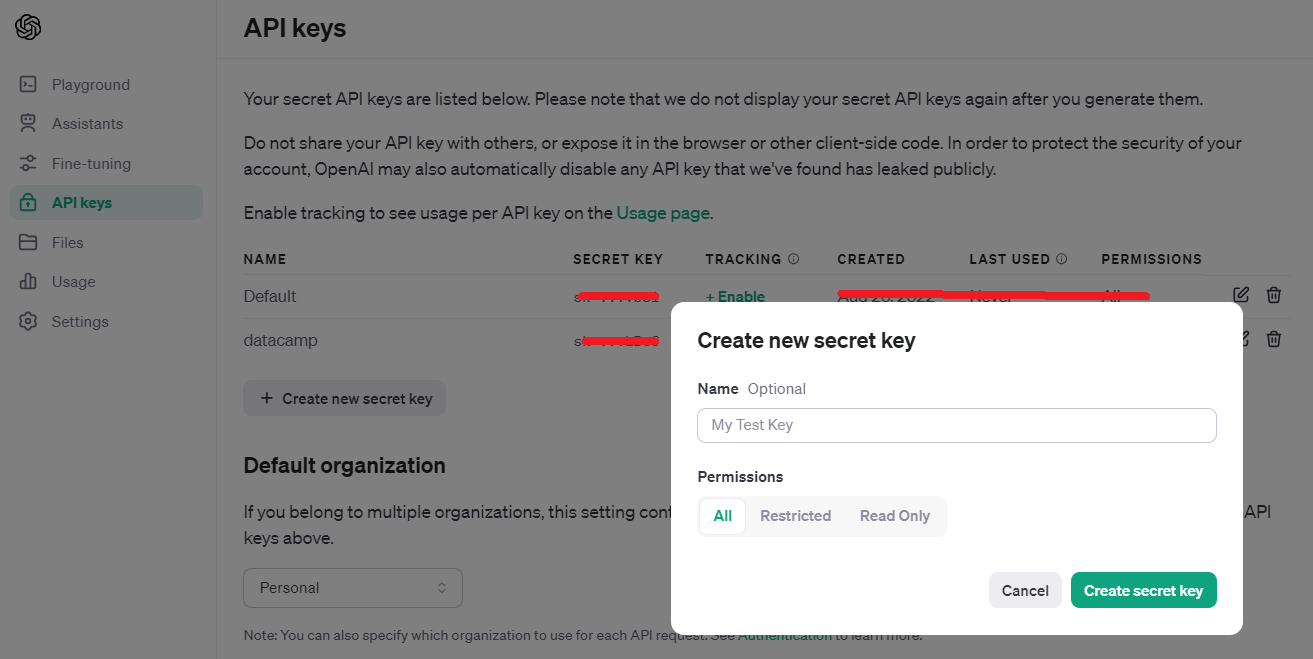
API Keys platform.openai.com
For Pinecone, login to your account and click on API Keys. You can click on the `Click API Key` button in the right corner.
Unlike OpenAI, with Pinecone, you don’t necessarily need to copy the API key when you generate one because there is a copy icon under the Actions column that you can use anytime you want.
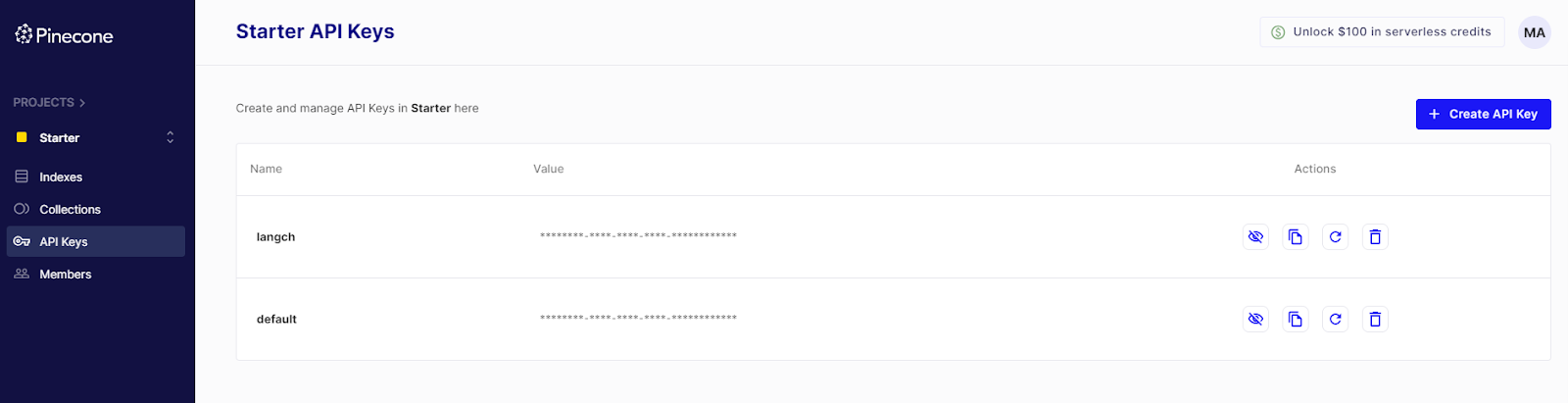
API Keys - Pinecone
After obtaining OpenAI and Pinecone API keys, assign them to variables in the Notebook or set them as environment variables using the Python os module.
OPENAI_API_KEY = '...'
PINECONE_API_KEY = '...'To implement this tutorial, you need the following libraries installed using pip. You must use the exact versions otherwise, the code below won’t work.
!pip install pinecone-client==3.0.0
!pip install pinecone-datasets==0.7.0
!pip install openai==0.28The pinecone-datasets library includes several datasets pre-embedded with OpenAI's embedding-ada-002 model.
For this example, we'll use the `wikipedia-simple-text-embedding-ada-002-100K` dataset, sampling just 5,000 of its 100,000 documents and their embeddings.
import pinecone_datasets
# load dataset from pinecone
dataset = pinecone_datasets.load_dataset('wikipedia-simple-text-embedding-ada-002-100K')
# drop metadata column and renamed blob to metadata
dataset.documents.drop(['metadata'], axis=1, inplace=True)
dataset.documents.rename(columns={'blob': 'metadata'}, inplace=True)
# sample 5k documents
dataset.documents.drop(dataset.documents.index[5_000:], inplace=True)
dataset.head()
Sample Dataset
In Pinecone, an index represents the highest organizational unit for vector data. It handles the storage of vectors, processes queries for its stored vectors, and performs various operations on the vector data it holds.
from pinecone import Pinecone, ServerlessSpec
# configure client
pc = Pinecone(api_key=PINECONE_API_KEY)
# configure serverless spec
spec = ServerlessSpec(cloud='aws', region='us-west-2')
# set index name
index_name = 'semantic-search-demo'
# we create a new index
pc.create_index(
index_name,
dimension=1536, # dimensionality of text-embedding-ada-002
metric='cosine',
spec=spec
)
The code above initializes the Pinecone instance, creating an index named semantic-search-demo. At this point, you will be able to see this index in the UI as well.

Given that our data already includes embedded representations, we can skip the embedding process and proceed directly to inserting data into the newly created index.
For datasets without embedded representations, first embed the raw data using the OpenAI API (refer to step 5 below for instructions).
index = pc.Index(index_name)
for batch in dataset.iter_documents(batch_size=100):
index.upsert(batch)After the code runs successfully, you can also view the data in the user interface.
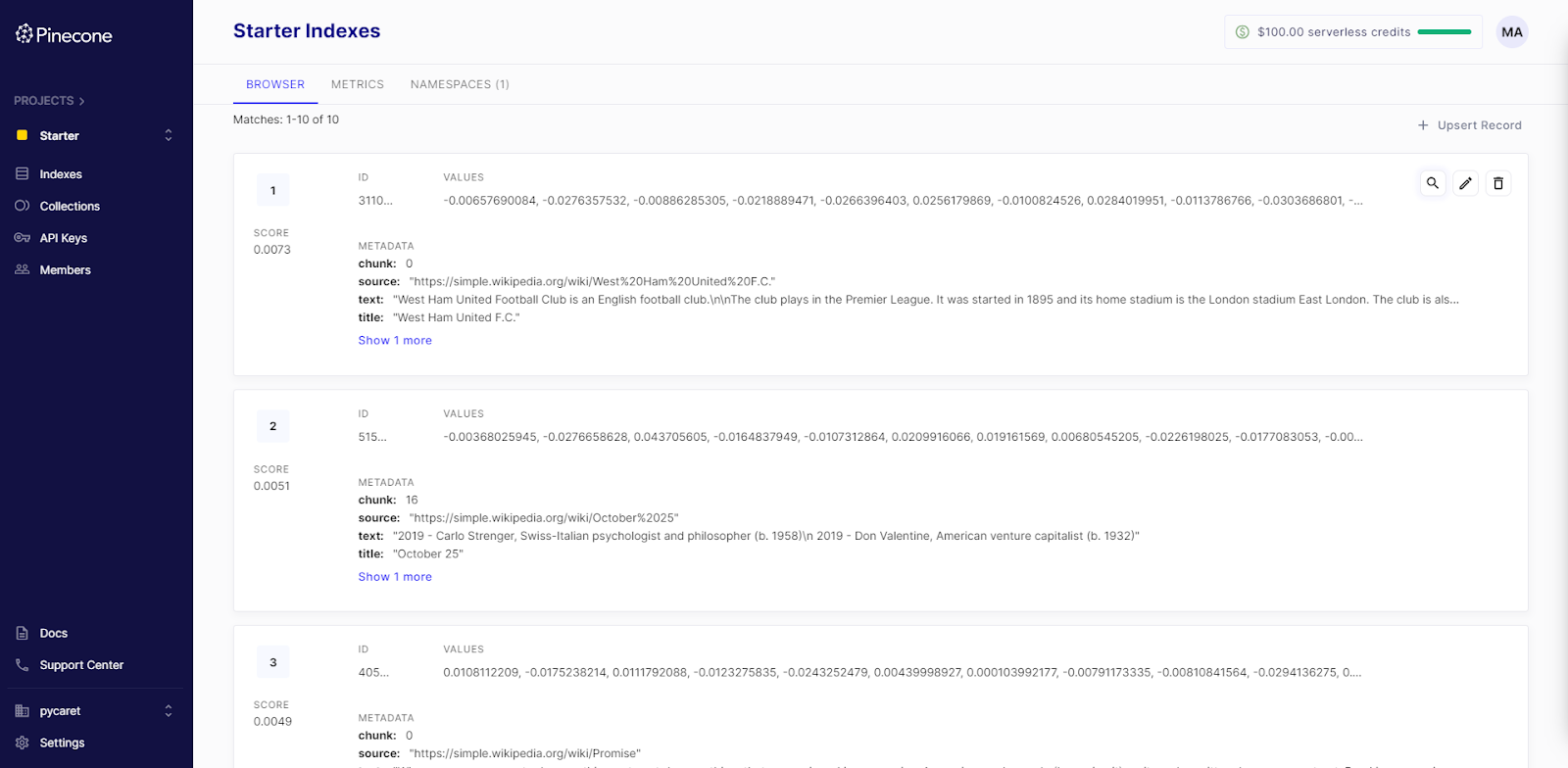
New data or queries need to be embedded with the same model to ensure matching vector dimensions. Since our dataset uses text-embedding-ada-002, we'll create a function that utilizes the OpenAI API to embed new queries using this identical model.
import openai
openai.api_key = OPENAI_API_KEY
def get_embedding(text_to_embed):
# Embed a line of text
response = openai.Embedding.create(
model= "text-embedding-ada-002",
input=[text_to_embed]
)
# Extract the AI output embedding as a list of floats
embedding = response['data'][0]['embedding']
return embeddingquery = "What are some easter related events in Western Christianity?"
result = get_embedding(query)
print(len(result))
print(result)Output:
1536
[0.014745471067726612, -0.03282099589705467, -0.006603493355214596, -0.0025058642495423555,.........]
The length of result is 1536, aligning with the dimension specified during the index creation.
Sending a search query is pretty straightforward:
query_result = index.query(vector=result, top_k=3, include_metadata=True)
print(query_result)Output:
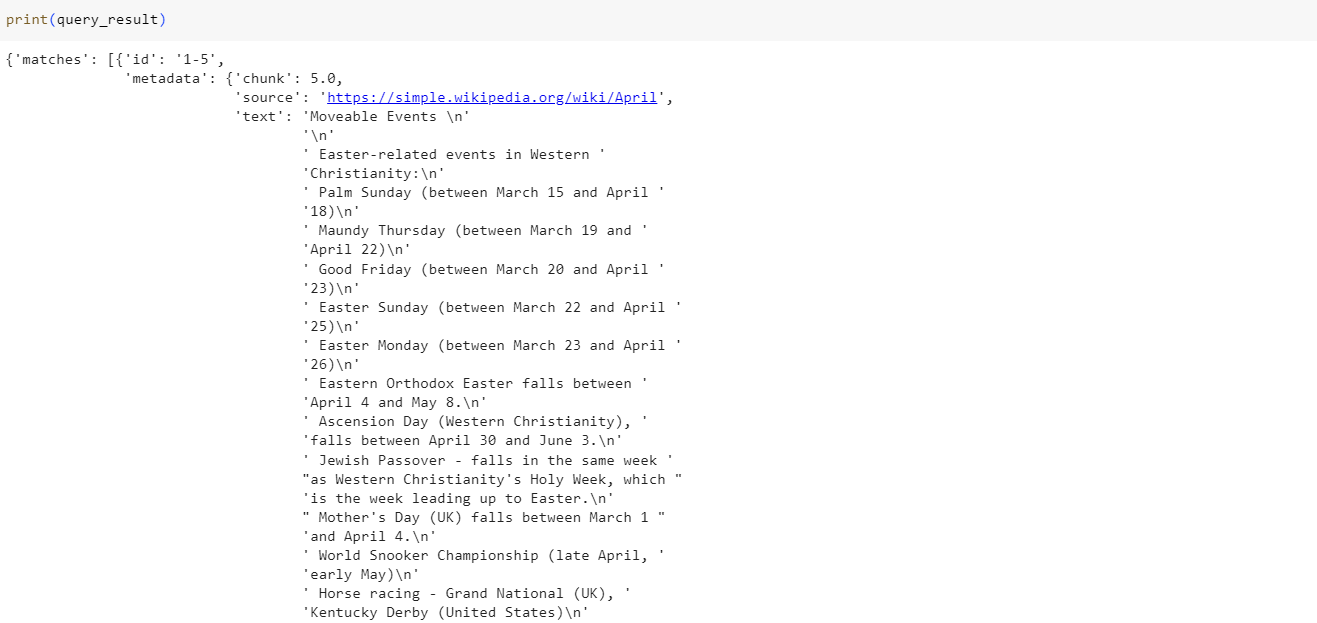
The query_result produces a dictionary with a list of the top 3 matches corresponding to the user's query. These Top N matches can now be utilized for downstream tasks, such as offering context for prompts in Retrieval Augmented Generation (RAG) scenarios or building Chatbots.
In this tutorial, we've introduced several key underlying concepts, such as embedding and vector databases, to understand the complete mechanics of semantic search applications.
With the advent of Generative AI and the continuous evolution of Multi-modal LLMs, the power of semantic search has expanded, offering unprecedented precision and understanding of the complexity and nuances of unstructured data.
By leveraging the capabilities of Pinecone, a cutting-edge vector database, and the sophisticated embedding models provided by OpenAI, developers and data scientists now have the tools at their fingertips to create semantic search applications that transcend traditional keyword-based search methodologies.
Through this guide, we've also explored the significance of embeddings in bridging the gap between the complexity of human language and the numerical representations that are needed for machine learning, unveiling how these representations enable machines to grasp the subtleties of context and intent.
It's clear that the future of search lies in the understanding of language and other unstructured forms of data powered by AI. Whether for e-commerce, content discovery, customer support, or knowledge management, the principles and practices outlined in this blog offer a foundational blueprint for harnessing the power of semantic search to create more intelligent, responsive, and user-centric search experiences.
If you want to learn more about building Semantic Search applications using Pinecone, check out Semantic Search with Pinecone code-along, or if you are interested in learning more about the functionality that underpins popular AI applications like ChatGPT, check out the course Working with the OpenAI API. Plus, don't forget to check out our course, Vector Databases for Embeddings with Pinecone.
Learn More About Working With OpenAI!
Programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
code-along
James Briggs
code-along
James Briggs
code-along
Vincent Vankrunkelsven



