Programa
Processamento de Linguagem Natural em Python
20 h
As descobertas científicas raramente ocorrem em um vácuo. Em vez disso, eles costumam ser o penúltimo degrau de uma escada construída com base no conhecimento humano acumulado. Para entender o sucesso dos grandes modelos de linguagem (LLMs), como o ChatGPT e o Google Bart, precisamos voltar no tempo e falar sobre o BERT.
Desenvolvido em 2018 por pesquisadores do Google, o BERT é um dos primeiros LLMs. Com seus resultados surpreendentes, ele rapidamente se tornou uma linha de base onipresente em tarefas de PLN, incluindo compreensão geral da linguagem, perguntas e respostas e reconhecimento de entidades nomeadas.
Interessado em saber mais sobre LLMs? Inicie o Capítulo 1 do nosso curso Conceitos de modelos de linguagem grande (LLMs) hoje mesmo.
É justo dizer que o BERT preparou o caminho para a revolução da IA generativa que estamos testemunhando atualmente. Apesar de ser um dos primeiros LLMs, o BERT ainda é amplamente usado, com milhares de modelos BERT de código aberto, gratuitos e pré-treinados disponíveis para casos de uso específicos, como análise de sentimentos, análise de notas clínicas e detecção de comentários tóxicos.
Tem curiosidade sobre o BERT? Continue lendo o artigo, onde exploraremos a arquitetura do Ber, o funcionamento interno da tecnologia, algumas de suas aplicações no mundo real e suas limitações.
O BERT (sigla em inglês para Bidirectional Encoder Representations from Transformers) é um modelo de código aberto desenvolvido pelo Google em 2018. Foi um experimento ambicioso para testar o desempenho do chamado transformador - uma arquitetura neural inovadora apresentada pelos pesquisadores do Google no famoso artigo Attention is All You Need em 2017 - em tarefas de linguagem natural (NLP).
A chave para o sucesso do BERT é sua arquitetura de transformador. Antes do surgimento dos transformadores, modelar a linguagem natural era uma tarefa muito desafiadora. Apesar do surgimento de redes neurais sofisticadas - a saber, redes neurais recorrentes ou convolucionais - os resultados foram apenas parcialmente bem-sucedidos.
O principal desafio está no mecanismo de redes neurais usado para prever a palavra ausente em uma frase. Naquela época, as redes neurais de última geração dependiam da arquitetura codificador-decodificador, um mecanismo poderoso, mas que consome muito tempo e recursos e não é adequado para a computação paralela.
Com esses desafios em mente, os pesquisadores do Google desenvolveram o transformer, uma arquitetura neural inovadora baseada no mecanismo de atenção, conforme explicado na seção a seguir.
Vamos dar uma olhada em como o BERT funciona, abordando a tecnologia por trás do modelo, como ele é treinado e como processa os dados.
As redes neurais recorrentes e convolucionais usam computação sequencial para gerar previsões. Ou seja, eles podem prever qual palavra seguirá uma sequência de determinadas palavras depois de treinados em grandes conjuntos de dados. Nesse sentido, eles foram considerados algoritmos unidirecionais ou livres de contexto.
Por outro lado, os modelos alimentados por transformadores, como o BERT, que também se baseiam na arquitetura codificador-decodificador, são bidirecionais porque preveem palavras com base nas palavras anteriores e nas palavras seguintes. Isso é obtido por meio do mecanismo de autoatenção, uma camada que é incorporada tanto no codificador quanto no decodificador. O objetivo da camada de atenção é capturar as relações contextuais existentes entre diferentes palavras na frase de entrada.
Atualmente, há muitas versões do BERT pré-treinado, mas, no artigo original, o Google treinou duas versões do BERT: BERTbase e BERTlarge com diferentes arquiteturas neurais. Em essência, o BERTbase foi desenvolvido com 12 camadas de transformadores, 12 camadas de atenção e 110 milhões de parâmetros, enquanto o BERTlarge usou 24 camadas de transformadores, 16 camadas de atenção e 340 milhões de parâmetros. Como esperado, o BERTlarge superou seu irmão menor nos testes de precisão.
Para saber em detalhes como a arquitetura do codificador-decodificador funciona nos transformadores, recomendamos que você leia nossa Introdução ao uso de transformadores e Hugging Face.
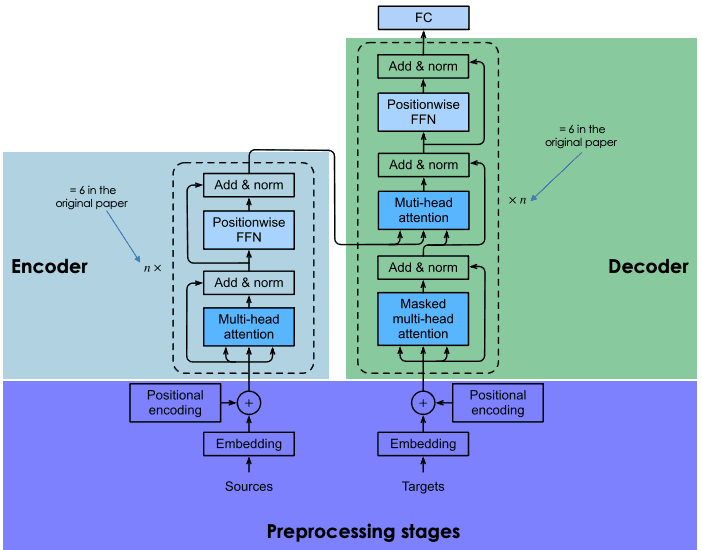
Uma explicação da arquitetura dos transformadores
Os transformadores são treinados do zero em um enorme corpus de dados, seguindo um processo demorado e caro (que somente um grupo limitado de empresas, incluindo o Google, pode pagar).
No caso do BERT, ele foi pré-treinado durante quatro dias na Wikipédia (~2,5 bilhões de palavras) e no BooksCorpus do Google (~800 milhões de palavras). Isso permite que o modelo adquira conhecimento não apenas em inglês, mas também em muitos outros idiomas de todo o mundo.
Para otimizar o processo de treinamento, o Google desenvolveu um novo hardware, o chamado TPU (Tensor Processing Unit), projetado especificamente para tarefas de aprendizado de máquina.
Para evitar interações desnecessárias e dispendiosas no processo de treinamento, os pesquisadores do Google usaram técnicas de aprendizagem por transferência para separar a fase de (pré)treinamento da fase de ajuste fino. Isso permite que os desenvolvedores escolham modelos pré-treinados, refinem os dados do par entrada-saída da tarefa de destino e treinem novamente a cabeça do modelo pré-treinado usando dados específicos do domínio. Esse recurso é o que torna os LLMs, como o BERT, o modelo de base de inúmeros aplicativos criados com base neles,
O elemento-chave para alcançar a aprendizagem bidirecional no BERT (e em todo LLM baseado em transformadores) é o mecanismo de atenção. Esse mecanismo é baseado na modelagem de linguagem mascarada (MLM). Ao mascarar uma palavra em uma frase, essa técnica força o modelo a analisar as palavras restantes em ambas as direções da frase para aumentar as chances de prever a palavra mascarada. O MLM baseia-se em técnicas já testadas no campo da visão computacional e é excelente para tarefas que exigem uma boa compreensão contextual de uma sequência inteira.
O BERT foi o primeiro LLM a aplicar essa técnica. Em particular, 15% das palavras tokenizadas foram mascaradas durante o treinamento. O resultado mostra que o BERT pode prever as palavras ocultas com alta precisão.
Tem curiosidade sobre a modelagem de linguagem mascarada? Confira nosso Curso de Conceitos de Modelos de Linguagem Grandes (LLMs) para saber todos os detalhes sobre essa técnica inovadora.
Alimentado por transformadores, o BERT conseguiu obter resultados de última geração em várias tarefas de PNL. Aqui estão alguns dos testes em que o BERT se destaca:
Muitos LLMs foram testados em conjuntos experimentais, mas poucos foram incorporados a aplicativos bem estabelecidos. Esse não é o caso do BERT, que é usado todos os dias por milhões de pessoas (mesmo que não saibamos disso).
Um ótimo exemplo é a Pesquisa Google. Em 2020, o Google anunciou que havia adotado o BERT por meio da Pesquisa Google em mais de 70 idiomas. Isso significa que o Google usa o BERT para classificar o conteúdo e exibir snippets em destaque. Com o mecanismo de atenção, o Google agora pode usar o contexto de sua pergunta para fornecer informações úteis, conforme mostrado no exemplo a seguir.
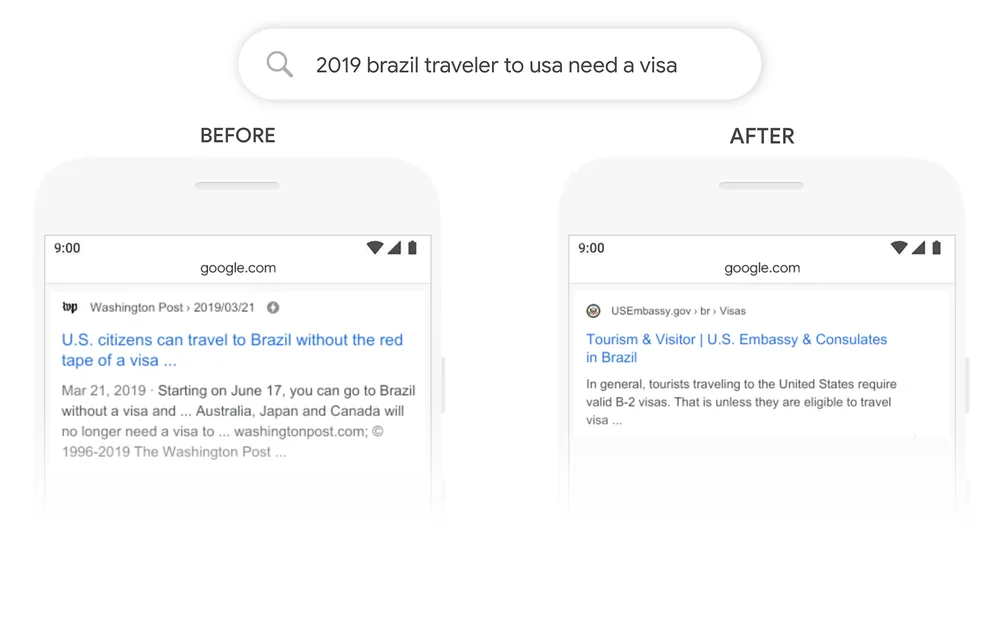
Fonte: Google
Mas isso é apenas uma parte da história. O sucesso do BERT se deve em grande parte à sua natureza de código aberto, que permitiu que os desenvolvedores acessassem o código-fonte do BERT original e criassem novos recursos e melhorias.
Isso resultou em um bom número de variantes do BERT. Abaixo, você pode encontrar algumas das variantes mais conhecidas:
Se você quiser saber mais sobre o movimento LLM de código aberto, recomendamos que leia nossa publicação com os principais LLMs de código aberto em 2023
Um dos melhores aspectos do BERT e dos LLMs em geral é que o processo de pré-treinamento é separado do processo de ajuste fino. Isso significa que os desenvolvedores podem usar versões pré-treinadas do BERT e personalizá-las para seus casos de uso específicos.
No caso do BERT, há centenas de versões ajustadas do BERT desenvolvidas para uma ampla diversidade de tarefas de PNL. Abaixo, você pode encontrar uma lista muito, muito limitada de versões ajustadas do BERT:
O BERT vem com as limitações e os problemas tradicionais associados aos LLMs. As previsões do BERT são sempre baseadas na quantidade e na qualidade dos dados usados para treiná-lo. Se os dados de treinamento forem limitados, ruins e tendenciosos, o BERT poderá gerar resultados imprecisos e prejudiciais ou até mesmo as chamadas alucinações LLM.
No caso do BERT original, isso é ainda mais provável, pois o modelo foi treinado sem o Reinforcement Learning from Human Feedback (RLHF), uma técnica padrão usada por modelos mais avançados, como o ChatGPT, o LLaMA 2 e o Google Bard, para aumentar a segurança da IA. O RLHF envolve o uso de feedback humano para monitorar e orientar o processo de aprendizagem do LLM durante o treinamento, garantindo assim sistemas eficazes, mais seguros e confiáveis.
Além disso, embora possa ser considerado um modelo pequeno em comparação com outros LLMs de última geração, como o ChatGPT, ele ainda requer uma quantidade considerável de capacidade de computação para ser executado, sem falar em treiná-lo do zero. Portanto, os desenvolvedores com recursos limitados talvez não consigam usá-lo.
O BERT foi um dos primeiros LLMs modernos. Mas, longe de ser antiquado, o BERT ainda é um dos LLMs mais bem-sucedidos e amplamente utilizados. Graças à sua natureza de código aberto, atualmente existem várias variantes e centenas de versões pré-treinadas do BERT projetadas para tarefas específicas de PNL.
Se você estiver interessado em acompanhar o BERT e os desenvolvimentos recentes da PNL, o DataCamp está aqui para ajudar. Confira nossos materiais selecionados e fique por dentro da atual revolução da IA generativa!
Comece sua jornada de PNL hoje mesmo!
Programa
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
8 min
blog
Javier Canales Luna
8 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
