
Program
AI Temelleri
10 sa
Yeni yapay zekâ modelleri neredeyse haftalık çıkıyor: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Her sürüm, belirli bir konuda en iyisi olduğuna dair iddialarla birlikte kıyaslama puanlarıyla geliyor. Sorun şu: Çoğu kişi bu sayıların ne anlama geldiğini veya nasıl karşılaştırılacağını bilmiyor.
Büyük Dil Modeli (LLM) kıyaslamaları, modellerin geniş bilgi testlerinden karmaşık kodlama görevlerine ve çok adımlı akıl yürütme problemlerine kadar belirli görevlerde ne kadar iyi performans gösterdiğini ölçen standartlaştırılmış testlerdir. Her bir kıyaslamanın neyi ölçtüğünü anlamak, pazarlama söylemini aşmanıza ve gerçek ihtiyaçlarınıza uygun modeli seçmenize yardımcı olur.
Bu rehber, başlıca kıyaslama kategorilerini açıklıyor, güncel sıralamaları nerede bulacağınızı anlatıyor ve kendi değerlendirmelerinizi nasıl çalıştıracağınızı gösteriyor. Sonunda, bir lider tablosunu nasıl okuyacağınızı ve kullanım senaryonuza uyan yapay zekâyı nasıl seçeceğinizi bileceksiniz.
LLM’lerin kaputun altında nasıl çalıştığını daha derin öğrenmek için LLMs Concepts kursumuza göz atın.
Bir LLM kıyaslaması, bir dil modelinin belirli bir türdeki görevi ne kadar iyi yerine getirdiğini ölçen standart bir testtir. Teste giren her model için aynı sorular ve değerlendirme rubriği uygulanır.
Model duyurularındaki rakamlar, birkaç popüler testten gelir. Her puan farklı bir hikâye anlatır ve tek bir kıyaslama tüm resmi yansıtmaz.
Kıyaslamalar üç nedenle önemlidir:
Modelleri karşılaştırma: OpenAI aynı ayda GPT-5.2’yi, Anthropic ise Claude Opus 4.5’i çıkardığında, kıyaslamalar ortak bir zemin sağlar. Aksi hâlde, her şirket seçmece örneklere dayanarak zafer ilan eder ve biz de ortada kalırız.
İlerlemeyi izleme: Aynı kıyaslamayı zaman içinde çalıştırırsanız, modellerin gerçekten gelişip gelişmediğini görebilirsiniz. MMLU puanları 2022’de %70’ten 2025’te %90’ın üzerine çıktı.
Boşlukları belirleme: Bir model genel bilgi sorularında parlayıp çok adımlı matematikte tökezleyebilir. Kıyaslamalar bu zayıflıkları ortaya çıkarır.
Kıyaslama puanları, ham zekâdan fazlasını yansıtır. Lider tablolarında gördüğünüz rakamları şekillendiren birden çok etken vardır.
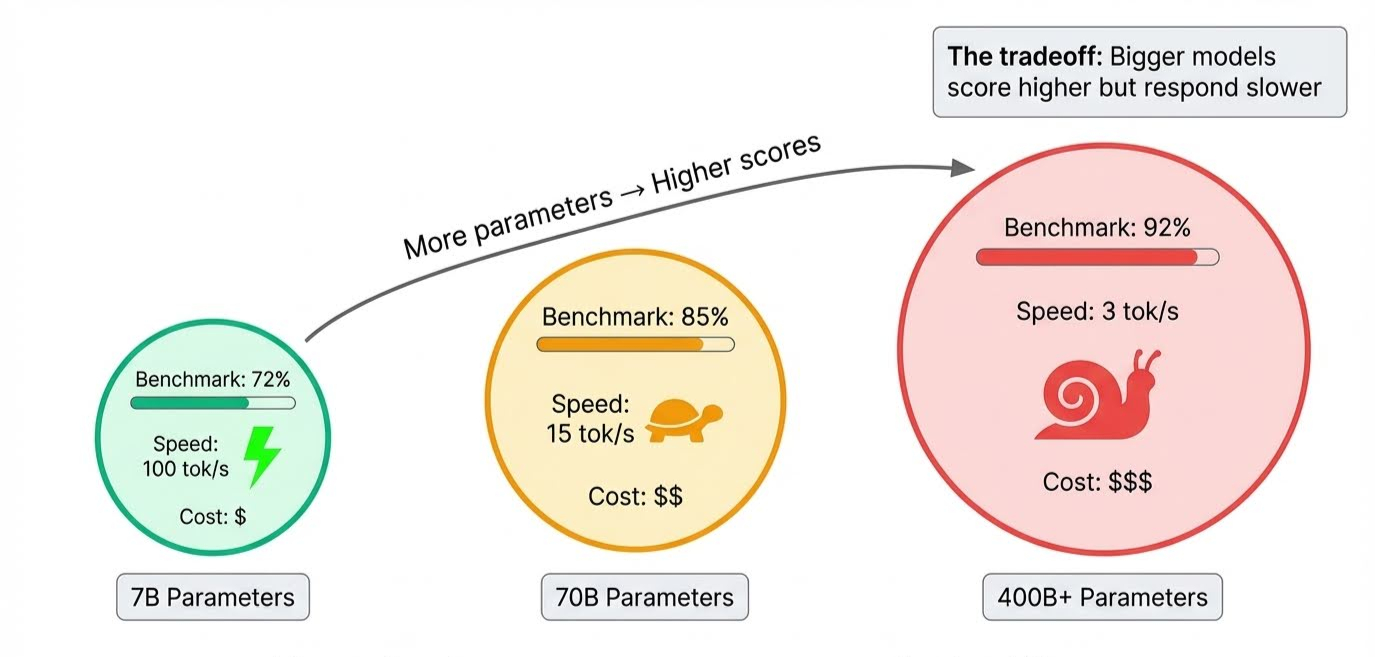
Model boyutu bariz olandır. Parametreler, bir modelin öğrendiği her şeyi depolar ve öncü modeller yüz milyarlarca parametre içerir. Daha fazla parametre, modelin daha karmaşık akıl yürütmeyi ve daha fazla nüansı taşıyabilmesi demektir; bu da puanları yükseltir.
Bu ödünleşim çıkarım sırasında, yani model yanıt ürettiğinde ortaya çıkar: tüm bu parametrelerin ardışık olarak devreye girmesi gerekir, bu yüzden büyük modeller daha yavaştır. Bir model tüm kıyaslamalarda zirveye oturabilir ama yanıt vermesi birkaç saniye sürebilir.
Eğitim süresi daha çetrefillidir. Eğitim verilerindeki her geçişe epoch denir. Çok az olursa model iyi puan almak için yeterince özümsediğini göstermez. Çok fazla olursa da yeni sorulara aktarılabilecek kalıpları öğrenmek yerine örnekleri ezberlemeye başlar. Buna aşırı uyum denir ve kıyaslama tasarımcıları, eğitim sırasında modelin göremeyeceği soruları dahil ederek bunu özellikle yakalamaya çalışırlar.
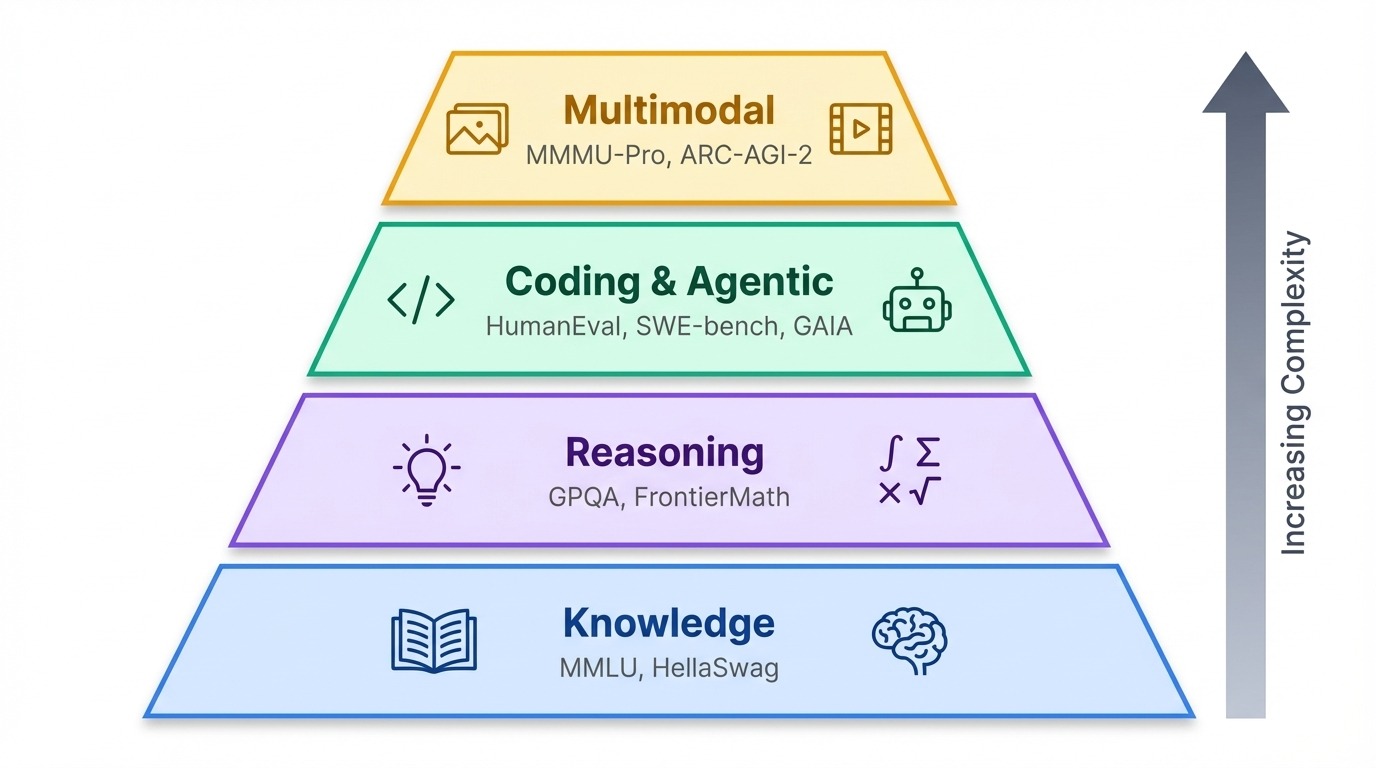
Bugün kullanılan düzinelerce kıyaslama varken, onları gerçekte neyi test ettiklerine göre gruplamak yardımcı olur.
Kıyaslamalar kabaca bir hiyerarşide kümelenir. Tabanında, bilgi testleri bir modelin ne bildiğini yoklar. Onun üstünde, akıl yürütme kıyaslamaları nasıl düşündüğünü araştırır. En tepede ise yapıcı (agentic) ve çok kipli testler yer alır; bunlar, yapay zekânın gerçek dünyada eyleme geçip geçemediğini veya metin ötesi bilgiyi işleyip işleyemediğini ölçer.
MMLU (Massive Multitask Language Understanding), lise seviyesinden profesyonel seviyeye kadar 57 akademik konuyu kapsar; soyut cebirden dünya dinlerine kadar her şeyi içerir. Yıllarca genel bilgi için başvurulan test oldu ancak öncü modeller artık %88’in üzerine kümelendiğinden, aralarında ayrım yapmak için pek alan bırakmıyor.
Bu doygunluk, araştırmacıları daha zor testlere yöneltti. GPQA (Lisansüstü düzeyde Google’dan etkilenmeyen S&C) biyoloji, fizik ve kimyada arama ile bulunamayacak şekilde alan uzmanlarınca tasarlanmış 448 soru sorar.
Kıyaslamanın üç zorluk seviyesi vardır; Diamond, en zor soruları içerir. Sınırsız web erişimiyle bile, uzman olmayanlar sadece %34 alır—dört şıklı sorularda rastgele tahminden yalnızca %9 daha iyi. Aralık 2025 itibarıyla Gemini 3 Pro GPQA Diamond’a %92,6 ile liderlik ediyor.
OpenAI’nın GDPval (Gayrisafi Yurtiçi Hasıla değerli) kıyaslaması farklı bir şeyi ölçer: gerçek dünya iş çıktısı. Yıllık 3 trilyon $ ekonomik faaliyete karşılık gelen sektörlerde 44 mesleği kapsar ve modellerden çoktan seçmeli soru yerine, hukuk notu, slayt destesi, mühendislik şartnamesi gibi çıktılar üretmelerini ister. Yeni yayımlanan GPT-5.2 bu bakımdan liderdir.
HellaSwag, gündelik senaryolar sunarak ve en olası bir sonraki cümleyi seçmesini isteyerek sağduyu akıl yürütmesini yoklar. Akşam yemeği pişiren biri tavaya uzanır. Sonra ne olur?
Yanlış cevaplar özellikle yapay zekâyı kandırmak için yazılmıştır: bağlama istatistiksel olarak uyan kelimeler kullanırlar ama imkânsız sonuçları tasvir ederler (tava uçar gider, ocak kediye dönüşür). İnsanlar mutfakların nasıl çalıştığını bildiğimiz için %95,6 alır. Modeller ise olası olayları değil, olası kelimeleri tahmin ettikleri için kandırılır.
En yeni kıyaslamalar zorluğu daha da artırıyor:
FrontierMath, araştırmacı matematikçilerden daha önce hiç yayımlanmamış problemler içerir; en iyi modeller bile %20’nin altında puan alır.
Humanity's Last Exam, tahmini engelleyecek şekilde tasarlanmış 2.500 uzman düzeyinde soruyu derler.
MathArena, eğitim verileriyle sıfır örtüşme garantisi için 2025 matematik yarışmalarından problemler çeker.
HumanEval klasik kodlama testidir: 164 Python problemi içerir; modeller docstring’lerden fonksiyon yazar ve kodun birim testlerini geçip geçmediğine göre notlandırılır. Mevcut öncü modellerin çoğu %85’in üzerinde puan aldığından, araştırmacılar daha sıkı test senaryoları içeren HumanEval+ gibi daha zor varyantlar oluşturdu.
SWE-bench (Yazılım Mühendisliği Kıyaslaması) yalıtılmış fonksiyonların ötesine geçer. Modelleri gerçek GitHub depolarına bırakır ve gerçek hataları düzeltmelerini ister. Model, kod tabanında gezinmeli, sorunu anlamalı ve çalışan bir yama üretmelidir.
SWE-bench Verified, insan mühendisler tarafından denetlenmiş yüksek kaliteli görevleri filtreleyen, özgün SWE-bench’in daha küçük ve titizlikle derlenmiş bir alt kümesidir. Aralık 2025 itibarıyla, Claude Opus 4.5 SWE-bench Verified’da %80,9 ile 80 barajını aşan ilk modeldir.
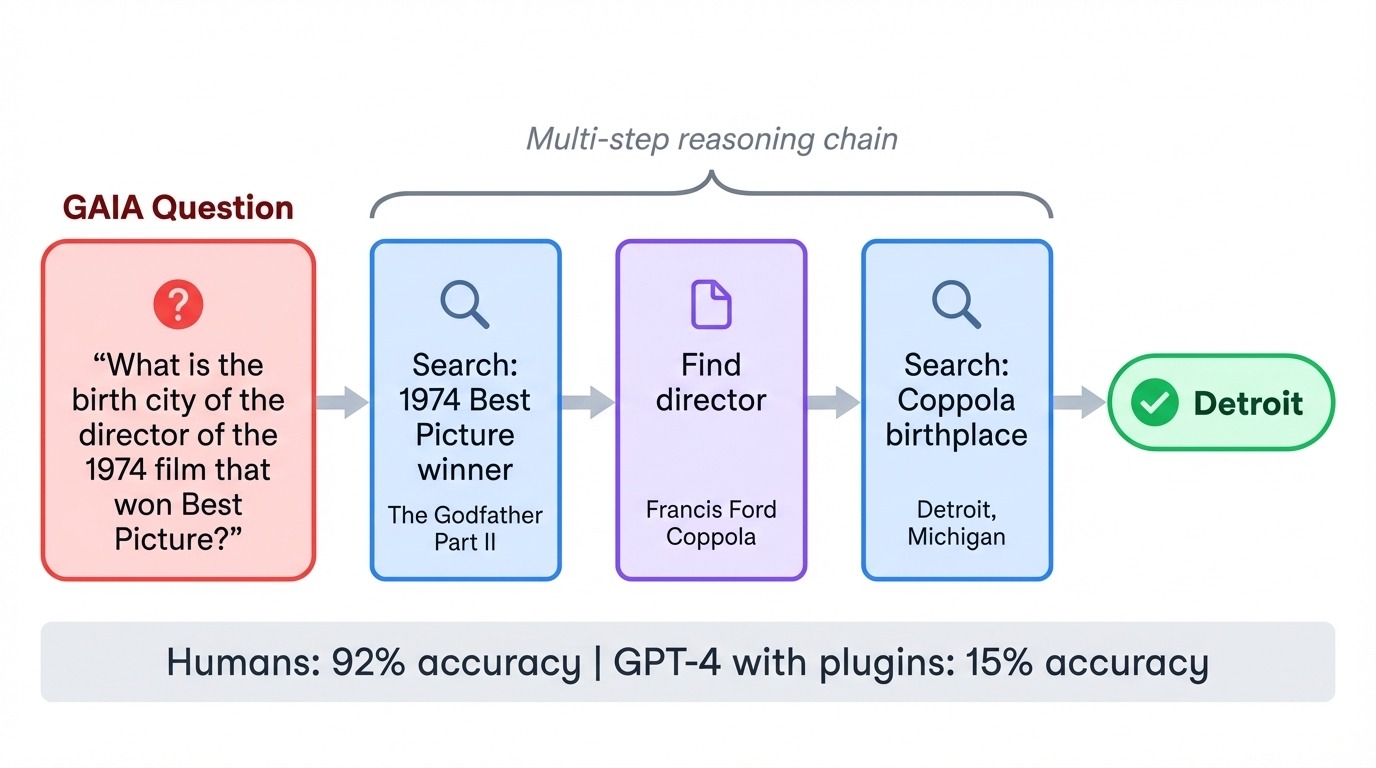
GAIA (Genel Yapay Zekâ Asistanları) alışıldık zorluk ilişkisini tersine çevirir. 466 görevi insanlar için çocuk oyuncağıdır (%92 doğruluk) ama yapay zekâ için zorludur. GPT-4 ilk kez eklentilerle GAIA’yı denediğinde sadece %15 almıştı. Her görev, web’de arama, belge okuma, hesaplama yapma ve yanıtları sentezleme gibi birden çok adımı zincirlemeyi gerektirir.
Tipik bir soru, belirli bir 1970’ler filminin yönetmeninin doğum şehrini isteyebilir; bu da modelin filmi belirlemesini, yönetmeni bulmasını ve sonra biyografik ayrıntıları aramasını gerektirir. Kıyaslama, modellerin araçları koordine edip çok adımlı planları kopmadan uygulayabilmesini test eder.
Son olarak, WebArena modelleri, uçak bileti rezervasyonu, içerik sistemleri yönetimi ve e-ticaret sitelerinde gezinme gibi görevleri gerçek tarayıcı arayüzleriyle etkileşime girerek tamamlamaları gereken kendi barındırılan web ortamlarına yerleştirir.
Yalnızca metin tabanlı kıyaslamalar büyüyen bir sınırı ıskalar. MMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning), soruları doğrudan görsellere gömerek 30 disiplinde görsel akıl yürütmeyi test eder; bu da modelleri aynı anda görsel bilgiyi okumaya ve yorumlamaya zorlar.
Kıyaslama, yalnızca metin tabanlı modellerin cevaplayabileceği soruları eler; böylece görmenin gerçekten fark yaratması sağlanır. Burada lider Gemini 3 Pro, %81 ile öndedir.
Bazı kıyaslamalar görsel akıl yürütmeyi bir üst seviyeye taşır.
MathVista örneğin, görsel algıyı matematiksel akıl yürütmeyle birleştirir. Problemler arasında fonksiyon grafikleri yorumlama, bilimsel grafikler okuma ve diyagramlardan geometri çözme bulunur. Video-MMMU bunu zamansal anlama boyutuna genişleterek, modellerin tekil görüntüler yerine video kareleri boyunca nedensellik ve diziler hakkında akıl yürütüp yürütemediğini test eder.
ARC-AGI-2 ise hâlâ yapay zekânın çözemediği kıyaslamadır. Her görev, birkaç girdi-çıktı ızgara örneği sunar ve modelden dönüşüm kuralını çıkarıp yeni bir girdiye uygulamasını ister.
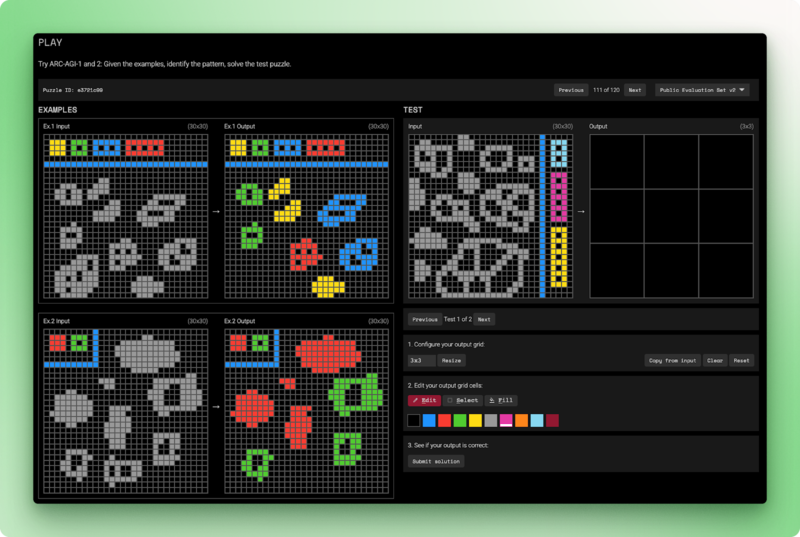
İnsanlar bu bulmacaları iki denemeden kısa sürede çözer. Salt dil modelleri %0 alır. En iyi hibrit sistemler %54’e ulaşır; o da görev başına 30 $ maliyetle. ARC-AGI-2, eğitim sırasında görülen kalıpları eşleştirmek yerine ilk prensiplerden akıl yürütmeyi sınar.
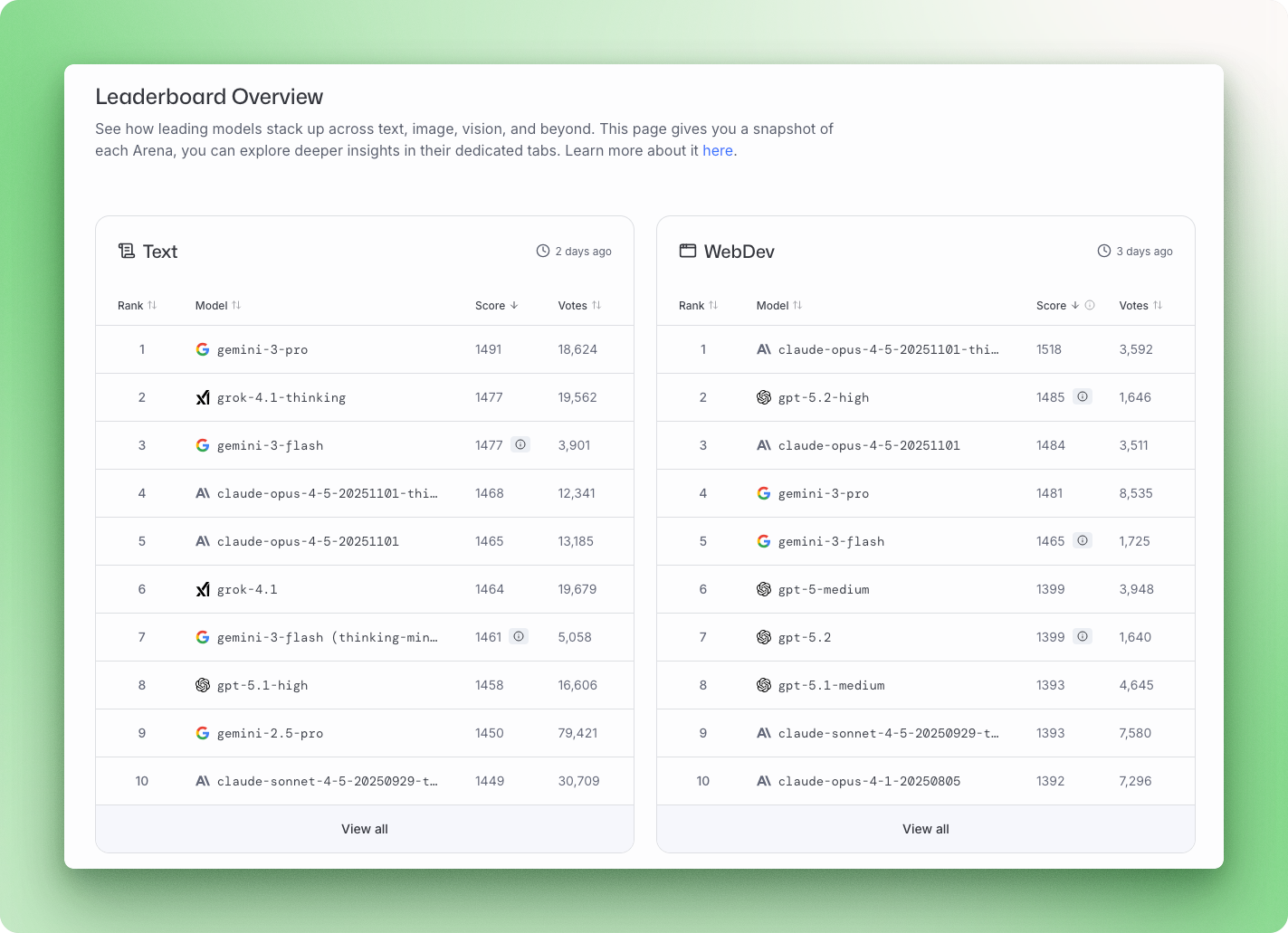
Kıyaslamalar puan üretir ama bu puanların nasıl sunulacağını lider tabloları belirler. Farklı platformlar farklı unsurları önceler: insan tercihi, açık kaynak şeffaflığı veya çok boyutlu değerlendirme. Hangi lider tablosuna bakacağınızı bilmek, neyi ölçmek istediğinize bağlıdır.
LMArena (LMSYS Chatbot Arena), otomatik kıyaslamalardan farklı bir yaklaşım benimser. Yanıtları bir rubriğe göre puanlamak yerine, insanların daha iyi yanıtı seçmesini ister. Kullanıcılar bir istem gönderir, iki anonim modelden çıktı alır ve tercih ettiklerine oy verir. Markaya yönelik önyargıyı önlemek için oy bitene kadar modeller gizli kalır.
Platform, 5 milyonun üzerindeki ikili oyunu sıralara dönüştürmek için Bradley-Terry istatistiksel modelini kullanır. Aralık 2025 itibarıyla Gemini 3 Pro, genel Arena’da 1501 puanla liderdir; onu 1483 ile Grok 4.1, ardından Claude Opus 4.5 ve GPT-5.2 izler.
LMArena, kıyaslamaların ıskaladığı bir şeyi yakalar: bir yanıtın gerçekten faydalı gelip gelmediğini. Ödünleşim ise şudur: Daha kısa ama daha doğru bir yanıt varken, uzun ve kendinden emin görünen yanıtlar oy kazanabilir.
Hugging Face’in Open LLM Leaderboard’u, açık kaynak modellerine odaklanır ve bunları EleutherAI Evaluation Harness kullanarak standart testlerden geçirir. Sürüm 2, öncü modellerin özgün test setini doyuma ulaştırmasının ardından, Haziran 2024’te daha zor kıyaslamalarla yayımlandı.
Mevcut batarya GPQA, MATH Seviye 5 ve MMLU-PRO’yu içerir; 0’ın rastgele performansı, 100’ün kusursuzluğu temsil ettiği normalize puanlama kullanılır. Önde gelen açık modeller arasında Qwen3, Llama 3.3 70B ve DeepSeek V3.1 bulunur; bunların tümü kapalı kaynak liderlerine çok yakın rekabet eder.
Stanford HELM (Holistic Evaluation of Language Models), modellerin sonuçlarının doğruluğundan fazlasını ölçer. Her model, senaryo başına yedi boyutta değerlendirilir: doğruluk, kalibrasyon, sağlamlık, adillik, önyargı, toksisite ve verimlilik.
Çerçeve 42 senaryoyu kapsar ve yalnızca başarıları değil, modellerin nerede başarısız olduğunu da açıkça izler. HELM ayrıca şiddet, dolandırıcılık ve taciz gibi riskleri değerlendiren ayrı bir güvenlik lider tablosu çalıştırır. Aralık 2025 itibarıyla, birleşik güvenlik puanlarında en üstte Claude 3.5 Sonnet yer alır.
Tek bir şirket her yerde kazanmıyor. Ancak birkaç lider tablosunu çapraz referanslar referanslamaya başlar başlamaz, bazı kalıplar ortaya çıkıyor.
Google’ın Gemini modelleri, çok kipli kıyaslamalarda ve bilimsel akıl yürütmede baskın. Gemini 3 Pro, GPQA Diamond’da %91,9 ile lider ve genel Arena’nın zirvesinde. Anthropic’in Claude serisi, kodlama ve güvenlikte mükemmel. Claude Opus 4.5, SWE-bench Verified rekorunu %80,9 ile elinde tutuyor ve Claude 3.5 Sonnet HELM Safety’de lider.
OpenAI’nın GPT modelleri, belirgin bir zayıflığı olmadan, çoğu kıyaslamada rekabetçi kalan güçlü genelistlerdir. Meta’nın Llama serisi, açık kaynağın birçok görevde kapalı modellerle boy ölçüşebileceğini kanıtlıyor; Llama 3.3 70B, çok daha büyük mülki sistemlerin çıktılarıyla boy ölçüşüyor.
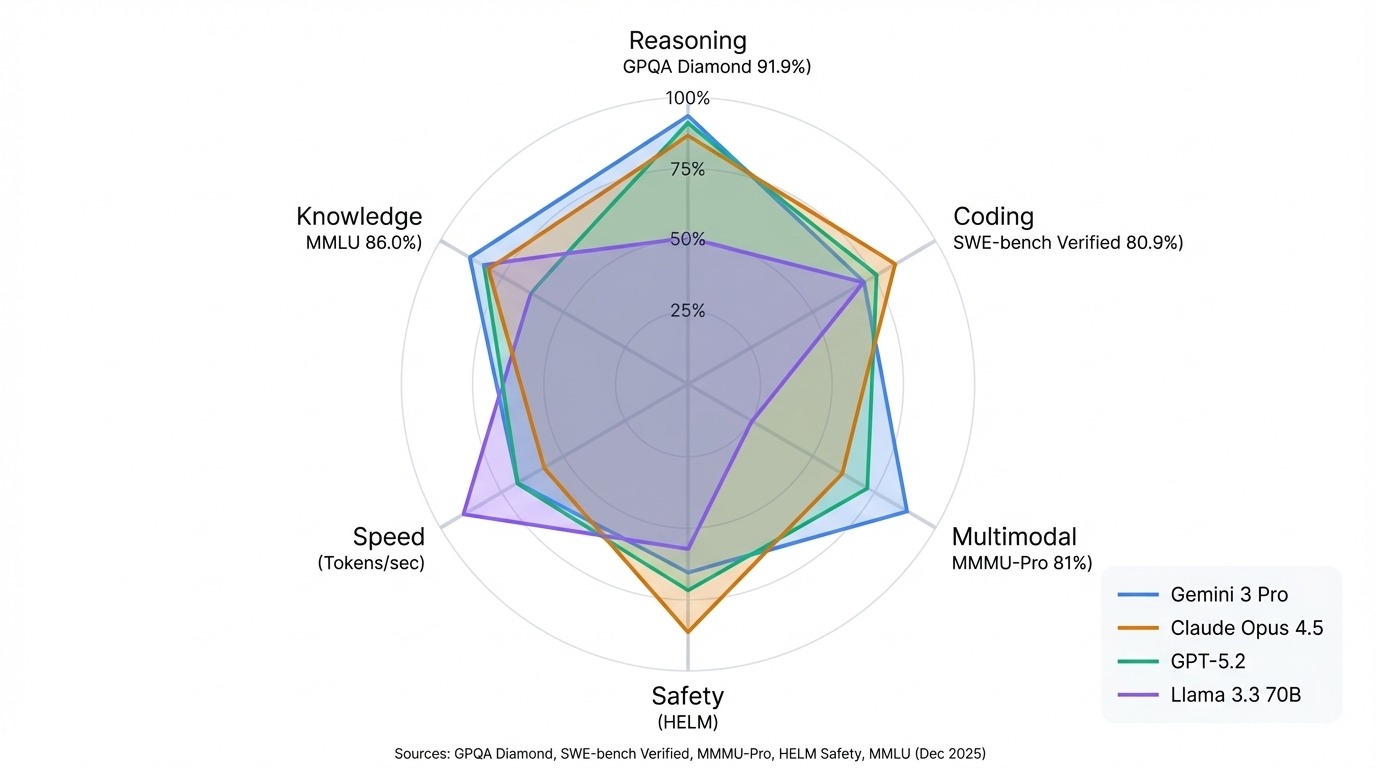
En önemli kalıp: lider tablosunu kullanım senaryonuza eşleştirin. Arena sıralamaları sohbet kalitesini yansıtır. HELM puanları güvenilirlik ve güvenliği gösterir. Hugging Face, kendi başınıza çalıştırabileceklerinizi izler. Bir listede zirvede olan bir model, başka bir listede orta sıralarda yer alabilir; bu sıralamaların kusuru değil, farklı testlerin farklı şeyleri ölçmesidir.
Lider tabloları, modellerin standart testlerde nasıl karşılaştırıldığını gösterir; ancak bazen sizin durumunuza özgü yanıtlara ihtiyaç duyarsınız.
Donanımınız için açık kaynak modeller arasında seçim yapıyor olabilir ya da ince ayar yaptığınız bir modelin genel akıl yürütme yeteneğini kaybetmediğini doğruluyor olabilirsiniz. Başka durumlarda, standart kıyaslamalar alanınızı kapsamıyor olabilir.
Tüm bu durumlarda, LLM’leri kendiniz kıyaslamayı düşünebilirsiniz. Bunu nasıl yapacağınızı ve akılda tutulması gerekenleri göstereceğim.
EleutherAI LM Evaluation Harness, bu değerlendirmeleri yerelde çalıştırmak için sektör standardıdır. Hugging Face Open LLM Leaderboard’u besler ve 60’tan fazla kıyaslamayı destekler.
Çoğu kişinin sohbet botlarıyla etkileşim kurma şeklinden farklı çalışır. Sadece modelle "sohbet" etmez; daha belirleyici, matematiksel bir analiz yapar.
MMLU veya ARC gibi kıyaslamalarda yaygın olan çoktan seçmeli sorular için, harness modelden "A", "B", "C" veya "D" çıktısı istemez. Bunun yerine, her bir seçenek için ayrı istemler oluşturur ve modelden her birinin ne kadar olası olduğunu sorar. En yüksek log-olasılığa sahip seçenek, modelin tercihi olarak alınır.
Diğer kıyaslamalar, modelin olasılık seçmek yerine tam metin bir yanıt ürettiği üretken bir yaklaşım gerektirir. Üretim tamamlandığında harness, çıktıyı düzenli ifadeler (regex) kullanarak ayrıştırır ve yanıt anahtarıyla doğrulanması gereken belirli değeri çıkarır.
Hadi ilk LLM değerlendirmenizi nasıl çalıştıracağınıza bakalım.
Değerlendirme harness’ını pip kullanarak kurabilirsiniz:
pip install lm-evalTam bir değerlendirme çalıştırmadan önce, hattı küçük bir örnekle test edin. --limit bayrağı, kıyaslamayı belirli sayıda örnekle sınırlar. Bu örnek, yüksek seviye bir GPU gerektirmeden çoğu donanımda çalışabilen küçük bir model olan Qwen2.5-1.5B-Instruct’ı HellaSwag kıyaslamasıyla test eder:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Görevler |
Sürüm |
Filtre |
n-shot |
Metri̇k |
|
Değer |
|
Std.hata |
|
hellaswag |
1 |
yok |
0 |
acc |
↑ |
0.3 |
± |
0.1528 |
|
yok |
0 |
acc_norm |
↑ |
0.4 |
± |
0.1633 |
Çıktı iki doğruluk metriği gösterir: acc ham doğruluktur; acc_norm ise modelin daha kısa veya daha uzun tamamlamalara eğilimini ayarlar. Ayrıca, örneklem büyüdükçe küçülen standart hata raporlanır. Yalnızca 10 örnek kullandığımız ilk testte yüksek Stderr (0,15) bu puanların kaba tahminler olduğu anlamına gelir.
Tam kıyaslamayı çalıştırmak için --limit bayrağını kaldırın. Tek seferde birden fazla kıyaslama için, virgülle listeleyin:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./results--device değerini donanımınıza göre ayarlayın: mps Apple Silicon için, cuda:0 NVIDIA GPU’lar için veya cpu yedek olarak. Tam MMLU, modern bir GPU’da 1-2 saat sürer; HellaSwag gibi daha küçük kıyaslamalar dakikalar içinde biter.
Gecikme ve veri işleme hızı (throughput) testleri için, Ollama modelleri yerelde çalıştırır ve farklı quantization seviyelerinde saniye başına token değerlerini raporlar. 7B’lik bir model V100’de saniyede 100+ token üretebilirken, 70B’lik bir model tek hanelere düşer.
Bir LLM’i kıyaslarken akılda tutulması gereken birkaç en iyi uygulama vardır.
Her şeyden önce, modelin eğitim sırasında değerlendirme sorularını görmediğinden emin olmanız gerekir. Görmüşse, başta tartıştığımız gibi modelin akıl yürütme yeteneğini değil, yalnızca aşırı uyumu ölçersiniz. Bu durumda kıyaslama puanları anlamını yitirir.
Tekrarlanabilir sonuçlar için model yanıtlarındaki değişkenlik mümkün olduğunca düşük tutulmalıdır. Bu, yaratıcılık yerine doğruluğu yeğlemek için sıcaklığı sıfıra ayarlayarak sağlanabilir.
Harness, her kıyaslama için standartlaştırılmış birkaç-atış (few-shot) istemler içerir. Puanları beklenenden fazla etkileyen küçük kelime değişikliklerinden kaçınmak için kendi istemlerinizi yazmak yerine bunları kullanın. Ancak, alana özgü işler için, üretime geçmeden önce kendi alanınızdaki gerçek örneklerden küçük bir test seti oluşturmalısınız.
Standart kıyaslamalar, olguları kontrol etmekte iyidir ama nüansı ölçmekte zorlanır. Özetleme veya yaratıcı yazı gibi açık uçlu görevler için, hakem olarak LLM yaklaşımı, çıktıları faydalılık ve doğruluk açısından notlamak üzere daha güçlü bir modeli kullanır.
Hakeme tipik olarak bir rubrik verilir ve ya sayısal bir puan (örn. 1-10) ataması ya da iki yanıt arasında hangisinin daha iyi olduğuna karar vermek için ikili karşılaştırma yapması istenir. Mükemmel olmasa da bu yargılar, insan tercihleriyle yaklaşık %80-85 oranında örtüşür. Bu nedenle, hakem olarak LLM, pahalı insan incelemesine ölçeklenebilir bir alternatif sunar.
Yapay zekâ değerlendirmesi, modellerin kendisi kadar hızlı değişiyor. MMLU gibi kıyaslamalar doygunluğa ulaştıkça, araştırmacılar ezberlenmiş bilgiden ziyade akıl yürütme derinliğini yoklayan daha zor testler geliştiriyor. FrontierMath ve Humanity's Last Exam, en iyi modellerin bile zorlandığı bu yeni zorluk sınırını temsil ediyor.
Daha geniş sinyaller tek bir yöne işaret ediyor: daha fazla eğitim hesabı (compute), daha akıllı algoritmalar ve ilerlemeye ayak uyduran kıyaslama paketleri. Çok kipli testler, modellerden istediklerimizi genişletiyor; grafik okumaktan video dizilerini anlamaya kadar.
Ama çıkarım basit kalıyor. Tek bir puan tüm hikâyeyi anlatmaz. Arena’da lider olan bir model, SWE-bench’te geride kalabilir. En iyi kodlama modeli, güvenlikte orta sıralarda olabilir. Kıyaslamayı gerçekten ihtiyacınız olana eşleyin: akıl yürütme, kod üretimi, görsel anlama veya ham hız. Önemli olan tek karşılaştırma budur.
Yeteneklerinizi kıyaslamanın ötesine taşımak için, LLM’leri kendiniz inşa etmeyi ve ince ayar yapmayı Developing Large Language Models beceri yolumuzla öğrenin.
LLM Kursları
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
