
Programa
Fundamentos da IA
10 h
Novos modelos de IA são lançados quase toda semana: Gêmeos 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Cada lançamento vem com pontuações de benchmark e afirmações de que é o melhor em alguma coisa. O problema: a maioria das pessoas não faz ideia do que esses números significam ou como compará-los.
Os benchmarks de Modelos de Linguagem Grande (LLM) são testes padronizados que medem o desempenho dos modelos em tarefas específicas, desde questionários de conhecimento geral até desafios complexos de codificação e problemas de raciocínio em várias etapas. Entender o que cada benchmark mede ajuda você a ignorar o marketing e escolher o modelo certo para suas necessidades reais.
Este guia detalha as principais categorias de referência, explica onde encontrar as classificações atuais e mostra como fazer suas próprias avaliações. No final, você vai saber como ler um quadro de líderes e escolher a IA que melhor se adapta ao seu caso de uso.
Pra saber mais sobre como os LLMs funcionam, dá uma olhada nos nossos conceitos de LLMs .
Um benchmark LLM é um teste padronizado que mede o desempenho de um modelo de linguagem em um tipo específico de tarefa. As mesmas perguntas e critérios de pontuação são usados para todos os modelos que fazem o teste.
Os números nos anúncios dos modelos vêm de alguns testes populares. Cada pontuação conta uma história diferente, e nenhum benchmark isolado consegue captar o quadro completo.
Os benchmarks são importantes por três motivos:
Comparando modelos: Quando a OpenAI lança o GPT-5.2 e a Anthropic lança o Claude Opus 4.5 no mesmo mês, os benchmarks nos dão um ponto em comum. Caso contrário, ficaremos presos a cada empresa reivindicando a vitória com base em exemplos selecionados.
Acompanhando o progresso: Faça o mesmo teste de desempenho ao longo do tempo e você vai ver se os modelos estão realmente melhorando. As pontuações do MMLU saltaram de 70% em 2022 para mais de 90% em 2025.
Identificando lacunas: Um modelo pode arrasar nas perguntas de cultura geral, mas se dar mal em matemática com várias etapas. Os benchmarks mostram essas fraquezas.
As pontuações dos benchmarks refletem mais do que a inteligência bruta. Vários fatores influenciam os números que você vê nas tabelas de classificação.
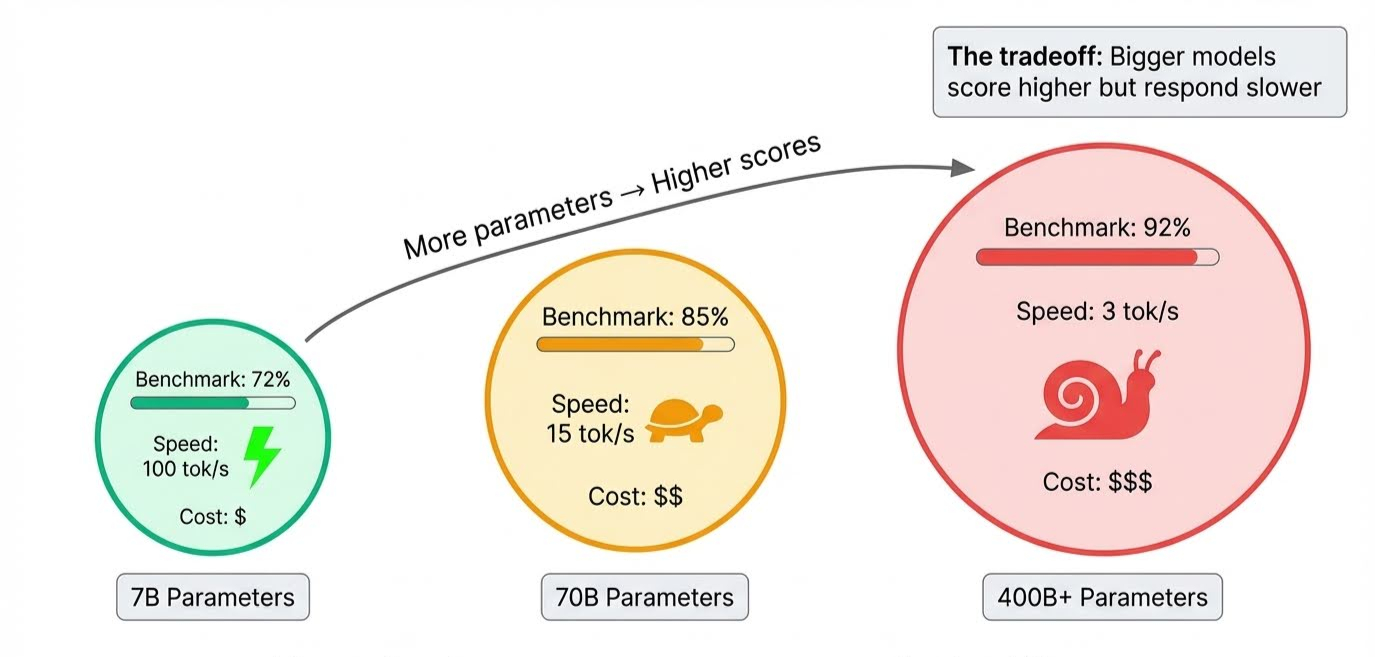
O tamanho do modelo é o mais óbvio. Os parâmetros guardam tudo o que um modelo aprende, e os modelos de fronteira têm centenas de bilhões deles. Mais parâmetros significam que o modelo pode lidar com raciocínios mais complexos e conter mais nuances, o que aumenta as pontuações.
A desvantagem aparece durante a inferência, quando o modelo realmente gera respostas: todos esses parâmetros precisam ser acionados em sequência, então modelos maiores são mais lentos. Um modelo pode superar todos os padrões de referência, mas demorar vários segundos para responder.
A duração do treinamento é mais complicada. Cada passagem pelos dados de treinamento é chamada deépoca (epoch) . Muito pouco, e o modelo não absorveu o suficiente para ter uma boa pontuação. Se forem muitos, ele começa a decorar exemplos em vez de aprender padrões que podem ser usados em novas questões. Isso é o sobreajuste, e os criadores de benchmarks tentam especificamente detectá-lo incluindo perguntas que o modelo não poderia ter visto durante o treinamento.
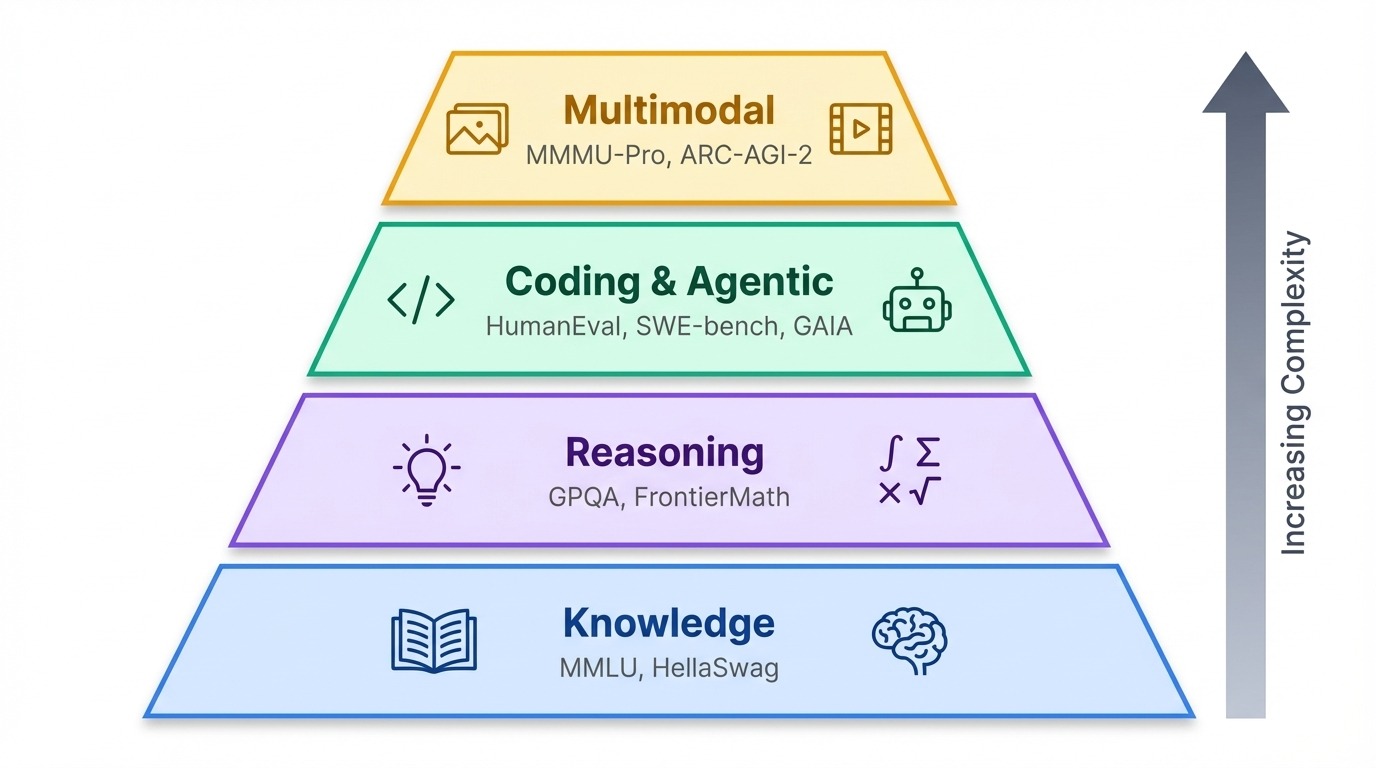
Com várias referências em uso hoje em dia, é legal agrupá-las de acordo com o que elas realmente testam.
Os benchmarks se agrupam em uma hierarquia aproximada. Basicamente, os testes de conhecimento verificam o que um modelo sabe. Além disso, os benchmarks de raciocínio testam o quão bem ele pensa. No topo, estão os testes agênicos e multimodais que medem se a IA pode agir no mundo real ou processar informações além do texto.
MMLU (Compreensão Multitarefa Massiva de Linguagem) abrange 57 disciplinas acadêmicas, do ensino médio ao nível profissional, abrangendo tudo, desde álgebra abstrata até religiões mundiais. Durante anos, foi o teste padrão para avaliar o conhecimento geral, mas agora os modelos de ponta estão todos acima de 88%, o que não deixa muito espaço para diferenciá-los.
Essa saturação levou os pesquisadores a fazerem testes mais difíceis. O GPQA (Graduate-level Google-Proof Q&A) faz 448 perguntas sobre biologia, física e química que especialistas na área criaram pra não poderem ser pesquisadas.
O benchmark tem três níveis de dificuldade, sendo que o Diamante tem as perguntas mais difíceis. Mesmo com acesso ilimitado à internet, quem não é especialista só acerta 34% — só 9% a mais do que você esperaria de um palpite aleatório com quatro opções de resposta. A partir de dezembro de 2025, Gemini 3 Pro está na frente do GPQA Diamond com 92,6%.
O benchmarkGDPval (valorizado pelo Produto Interno Bruto) da OpenAI mede algo diferente: a produção real de trabalho. Ele abrange 44 profissões em setores que movimentam US$ 3 trilhões em atividade econômica anual, pedindo aos modelos que produzam resultados como resumos jurídicos, apresentações de slides e especificações de engenharia, em vez de responder a perguntas de múltipla escolha. O recém-lançado GPT-5.2 é o líder nesse aspecto.
O HellaSwag testa o raciocínio lógico apresentando situações do dia a dia e pedindo aos modelos que escolham a frase seguinte mais plausível. Uma pessoa que está preparando o jantar pega uma panela. E agora, o que vai rolar?
As respostas erradas foram feitas de propósito pra enganar a IA: elas usam palavras que, estatisticamente, se encaixam no contexto, mas descrevem resultados impossíveis (a panela flutua, o fogão vira um gato). Os humanos têm uma pontuação de 95,6% porque sabemos como as cozinhas funcionam. Os modelos são enganados porque eles prevêem palavras prováveis, não eventos prováveis.
Os benchmarks mais recentes aumentam ainda mais a dificuldade:
O FrontierMath apresenta problemas nunca antes publicados, criados por matemáticos pesquisadores, nos quais mesmo os melhores modelos obtêm pontuação inferior a 20%.
O Último Exame da Humanidade reúne 2.500 perguntas de nível avançado, feitas pra não dar pra adivinhar as respostas.
O MathArena pega problemas de 2025 competições de matemática pra garantir que não tenha nenhuma sobreposição de dados de treinamento.
HumanEval é o clássico teste de codificação: Tem 164 problemas em Python onde os modelos escrevem funções a partir de docstrings e são avaliados com base na aprovação do código nos testes unitários. A maioria dos modelos de ponta atuais tem uma pontuação acima de 85%, então os pesquisadores criaram versões mais difíceis, comoo HumanEval+, com casos de teste mais rigorosos.
O SWE-bench (, ou Benchmark de Engenharia de Software) vai além de funções isoladas. Ele coloca os modelos em repositórios reais do GitHub e pede pra eles corrigirem bugs de verdade. O modelo precisa dar uma olhada no código, entender o problema e criar um patch que funcione.
O SWE-bench Verified é uma versão menor e super selecionada do SWE-bench original, que filtra tarefas de alta qualidade aprovadas por engenheiros humanos. Em dezembro de 2025, o Claude Opus 4.5 foi o primeiro modelo a passar dos 80% no SWE-bench Verified (80,9%).
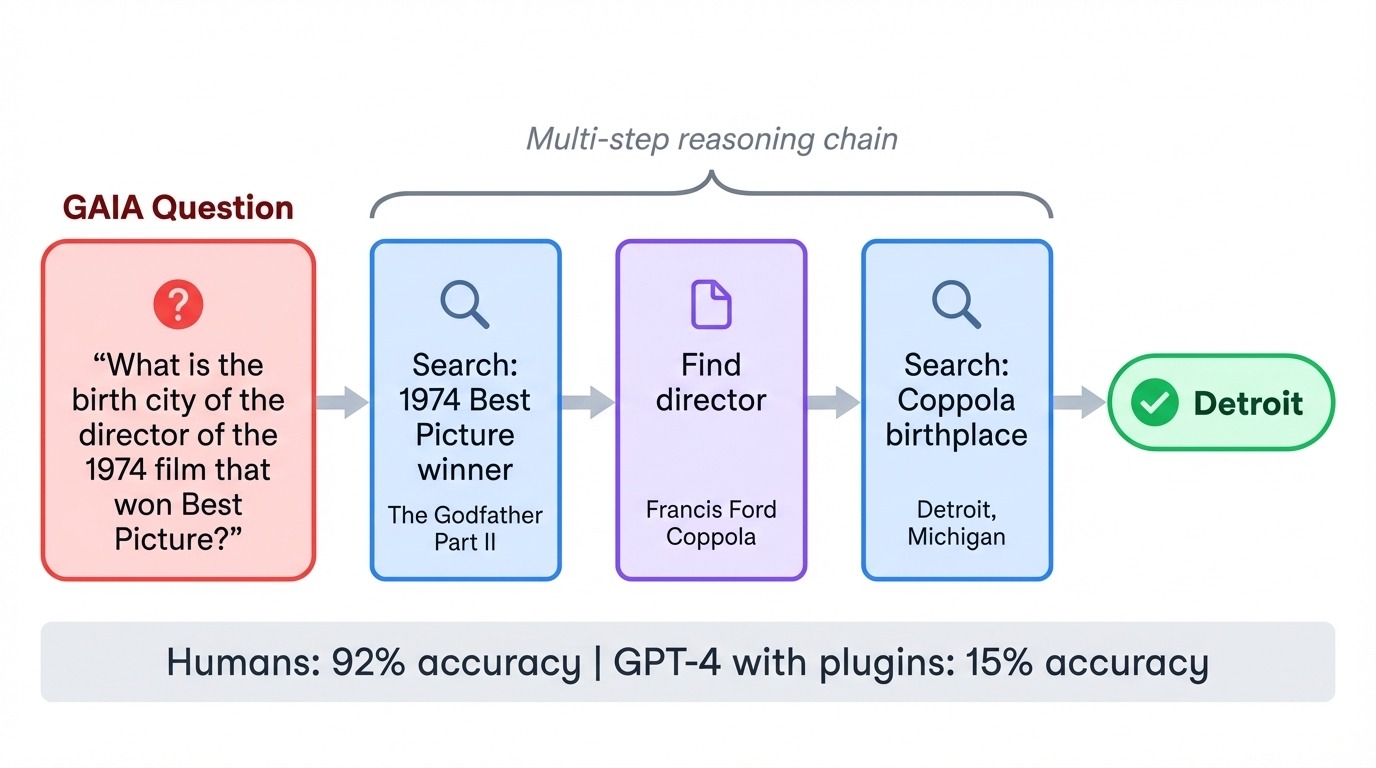
Os GAIA (, ou Assistentes de Inteligência Artificial Geral) invertem a relação habitual entre dificuldade e complexidade. Suas 466 tarefas são super fáceis para os humanos (92% de precisão), mas bem difíceis para a IA. Quando o GPT-4 tentou o GAIA pela primeira vez com plugins, ele só conseguiu 15%. Cada tarefa precisa de várias etapas: pesquisar na internet, ler documentos, fazer cálculos e juntar as respostas.
Uma pergunta típica poderia ser sobre a cidade natal do diretor de um filme específico dos anos 70, exigindo que o modelo identificasse o filme, encontrasse o diretor e, em seguida, pesquisasse detalhes biográficos. O benchmark testa se os modelos conseguem coordenar ferramentas e executar planos com várias etapas sem perder o programa.
Por fim, a WebArena implemente modelos em ambientes web auto-hospedados, onde eles precisam fazer tarefas como reservar voos, gerenciar sistemas de conteúdo e navegar em sites de comércio eletrônico interagindo com interfaces reais de navegadores.
Os benchmarks só de texto não estão pegando uma tendência que tá crescendo. OMMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning) da testa o raciocínio visual em 30 assuntos, colocando perguntas diretamente nas imagens, fazendo com que os modelos leiam e interpretem as informações visuais ao mesmo tempo.
O benchmark filtra as perguntas que os modelos só de texto poderiam responder, garantindo que a visão realmente importa. O Gemini 3 Pro lidera aqui com 81%.
Alguns benchmarks levam o raciocínio visual a um outro nível.
O MathVista, por exemplo, junta a percepção visual com o raciocínio matemático. Os problemas incluem interpretar gráficos de funções, ler tabelas científicas e resolver geometria a partir de diagramas. O Video-MMMU leva isso pra compreensão temporal, testando se os modelos conseguem raciocinar sobre causalidade e sequências entre quadros de vídeo, em vez de imagens únicas.
O ARC-AGI-2 ( ) continua sendo o desafio que a IA ainda não conseguiu resolver. Cada tarefa mostra alguns exemplos de grade de entrada-saída e pede para o modelo descobrir a regra de transformação e, depois, aplicar a uma nova entrada.
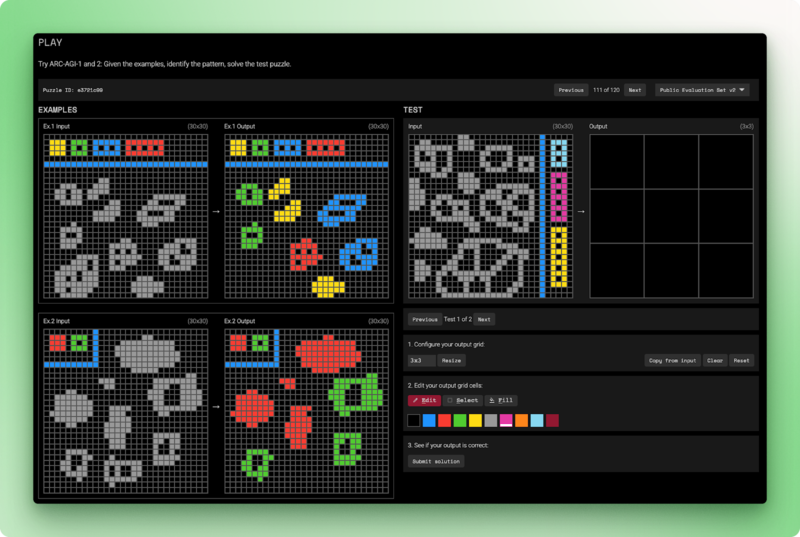
Os humanos resolvem esses quebra-cabeças em menos de duas tentativas. Os modelos de linguagem pura têm uma pontuação de 0%. Os melhores sistemas híbridos chegam a 54%, e isso custa US$ 30 por tarefa. O ARC-AGI-2 testa a inteligência fluida: raciocínio a partir de princípios básicos, em vez de correspondência de padrões observados durante o treinamento.
Os benchmarks geram pontuações, mas os rankings decidem como apresentá-las. Diferentes plataformas priorizam diferentes fatores: preferência humana, transparência de código aberto ou avaliação multidimensional. Saber qual ranking consultar depende do que você quer medir.
A LMArena (LMSYS Chatbot Arena) tem uma abordagem diferente dos benchmarks automatizados. Em vez de pontuar as respostas com base em uma rubrica, ele pede para as pessoas escolherem a melhor resposta. Os usuários mandam uma sugestão, recebem respostas de dois modelos anônimos e votam na que mais curtem. Os modelos ficam escondidos até depois da votação, evitando que o viés da marca influencie as escolhas.
A plataforma usa um modelo estatístico Bradley-Terry para transformar mais de 5 milhões de votos em pares em classificações. Em dezembro de 2025, o Gemini 3 Pro liderava a Arena geral com uma pontuação de 1501, seguido pelo Grok 4.1 com 1483, depois o Claude Opus 4.5 e o GPT-5.2.
O LMArena capta algo que os benchmarks não capturam: se uma resposta realmente parece útil. A questão é que respostas detalhadas e que soam confiantes podem ganhar votos, mesmo quando existe uma resposta mais curta e precisa.
O Open LLM Leaderboard da Hugging Face foca em modelos de código aberto e os testa usando o EleutherAI Evaluation Harness. A versão 2 foi lançada em junho de 2024 com benchmarks mais difíceis, depois que os modelos de fronteira saturaram o conjunto de testes original.
A bateria atual inclui GPQA, MATH Nível 5 e MMLU-PRO, com pontuação normalizada em que 0 significa desempenho aleatório e 100 significa perfeito. Os principais modelos abertos incluem Qwen3, Llama 3.3 70B e DeepSeek V3.1, todos competindo bem perto dos líderes de código fechado.
O Stanford HELM (Avaliação Holística de Modelos de Linguagem) mede mais do que só se os resultados dos modelos são precisos. Cada modelo é avaliado em sete dimensões por cenário: precisão, calibração, robustez, imparcialidade, viés, toxicidade e eficiência.
A estrutura abrange 42 cenários e programa claramente onde os modelos falham, não só onde eles funcionam. A HELM também tem um ranking de segurança separado que avalia riscos como violência, fraude e assédio. Em dezembro de 2025, o Claude 3.5 Sonnet ficou em primeiro lugar nas pontuações gerais de segurança.
Nenhuma empresa ganha em todos os lugares. Mas, assim que você comparar algumas tabelas de classificação, os padrões começam a aparecer.
Os modelos Gemini do Google mandam bem em testes multimodais e raciocínio científico. O Gemini 3 Pro lidera o GPQA Diamond com 91,9% e está no topo da Arena geral. A linha Claude da Anthropic é ótima em programação e segurança. O Claude Opus 4.5 tem o recorde verificado pelo SWE-bench com 80,9%, e o Claude 3.5 Sonnet lidera o HELM Safety.
Os modelos GPT da OpenAI continuam sendo generalistas fortes, competitivos na maioria dos benchmarks, sem nenhuma fraqueza que se destaque. A série Llama da Meta mostra que o código aberto pode competir com os modelos fechados em várias tarefas, com Llama 3.3 70B rivalizando com os resultados de sistemas proprietários muito maiores.
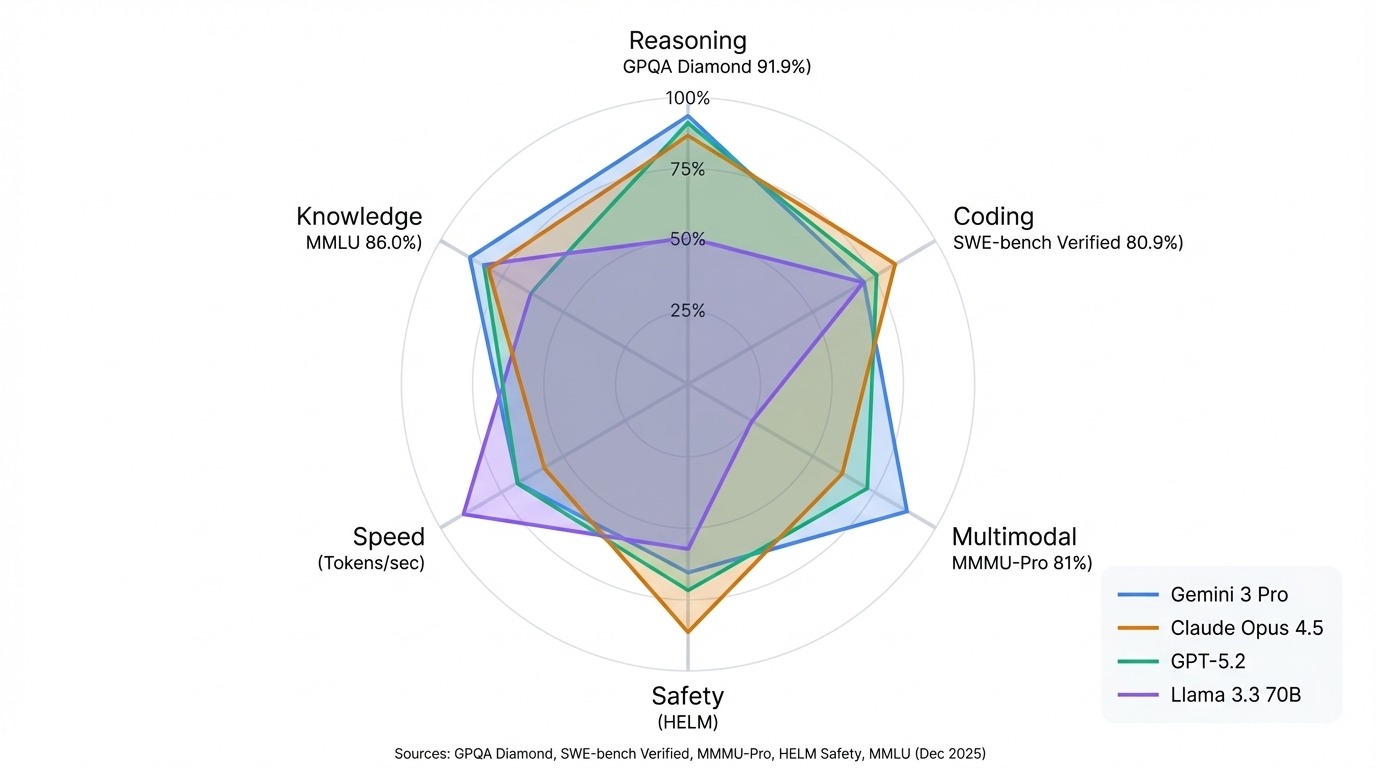
O padrão que mais importa: combine o quadro de líderes com o seu caso de uso. As classificações da arena mostram a qualidade das conversas. As pontuações HELM mostram confiabilidade e segurança. O Hugging Face acompanha o que você mesmo pode executar. Um modelo que está no topo de uma lista pode ficar no meio do pelotão em outra, e isso não é um problema nas classificações. São testes diferentes que medem coisas diferentes.
Os rankings mostram como os modelos se comparam em testes padrão, mas às vezes você precisa de respostas específicas para a sua situação.
Você pode estar escolhendo entre modelos de código aberto para o seu hardware ou verificando se um modelo ajustado não perdeu a capacidade de raciocínio geral. Em outros casos, os benchmarks padrão simplesmente não cobrem o seu domínio.
Em todos esses casos, você pode querer pensar em fazer você mesmo uma avaliação comparativa dos LLMs. Vou te mostrar como fazer e o que você precisa ter em mente.
O EleutherAI LM Evaluation Harness é o padrão da indústria para fazer essas avaliações localmente. Ele alimenta o Hugging Face Open LLM Leaderboard e suporta mais de 60 benchmarks.
Funciona de forma diferente da maneira como a maioria das pessoas interage com os chatbots. Ele não só “conversa” com o modelo, mas também faz uma análise matemática mais determinística.
Para perguntas de múltipla escolha, que são um método comum em benchmarks como MMLU ou ARC, o harness não pede ao modelo para gerar “A”, “B”, “C” ou “D”. Em vez disso, ele cria prompts separados para cada opção e pergunta ao modelo qual é a probabilidade de cada uma delas. A opção com a maior log-verossimilhança é então considerada como a escolha do modelo.
Outros benchmarks exigem uma abordagem generativa, em que o modelo produz uma resposta de texto completo em vez de selecionar uma probabilidade. Quando a geração estiver pronta, o harness analisa a saída usando expressões regulares (regex), pegando o valor específico necessário para comparar com a chave de respostas.
Vamos ver como fazer sua primeira avaliação LLM.
Você pode instalar o kit de avaliação usando pip:
pip install lm-evalAntes de fazer uma avaliação completa, teste o pipeline com uma amostra pequena. A bandeira ` --limit ` limita o benchmark a um número específico de exemplos. Esse exemplo testa o Qwen2.5-1.5B-Instruct, um modelo pequeno que rola na maioria dos hardwares sem precisar de uma GPU top de linha, usando o benchmark HellaSwag:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Tarefas |
Versão |
Filtro |
n-shot |
Métrico |
|
Valor |
|
Stderr |
|
hellaswag |
1 |
nenhum |
0 |
acc |
↑ |
0,3 |
± |
0,1528 |
|
nenhum |
0 |
acc_norm |
↑ |
0,4 |
± |
0,1633 |
A saída mostra duas métricas de precisão: a precisão bruta ( acc ) e a precisão ajustada (acc_norm ), que corrige o viés do modelo para completudes mais curtas ou mais longas. Além disso, o erro padrão é relatado, o qual diminui à medida que o tamanho da amostra aumenta. No nosso primeiro teste, usando só 10 amostras, o alto Stderr (0,15) quer dizer que essas pontuações são estimativas aproximadas.
Tira o --limit pra rodar o benchmark completo. Para vários benchmarks em uma única passagem, liste-os separados por vírgulas:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsDefina --device com base no seu hardware: mps para Apple Silicon, cuda:0 para GPUs NVIDIA ou cpu como alternativa. O MMLU completo leva de 1 a 2 horas em uma GPU moderna; benchmarks menores, como o HellaSwag, terminam em minutos.
Para testes de latência e taxa de transferência, O Ollama executa modelos localmente e relata tokens por segundo em diferentes níveis de quantização. Um modelo de 7B pode gerar mais de 100 tokens por segundo em um V100, enquanto um modelo de 70B cai para um dígito.
Tem algumas dicas que é bom lembrar quando você estiver comparando um LLM.
Primeiro e mais importante, você precisa ter certeza de que o modelo não viu as perguntas de avaliação durante o treinamento. Se isso acontecer, você está apenas medindo o sobreajuste, e não a capacidade de raciocínio do modelo, como falamos no começo. Nesse caso, as pontuações de referência perderiam o sentido.
Para ter resultados que dão certo sempre, a variação nas respostas do modelo precisa ser o menor possível. Isso pode ser feito colocando a temperatura em zero pra dar mais importância pra precisão do que pra criatividade.
O conjunto inclui prompts padronizados de poucos disparos para cada benchmark. Use-os em vez de escrever suas próprias instruções, já que pequenas mudanças na formulação afetam as pontuações mais do que se imagina. Mas, pra trabalhos específicos de domínio, é sempre bom criar um pequeno conjunto de testes com exemplos reais da sua área antes de usar um modelo na produção.
Os benchmarks padrão são ótimos pra conferir fatos, mas têm dificuldade em medir as nuances. Para tarefas abertas, como resumos ou redação criativa, o LLM-as-a-judge usa um modelo mais robusto para avaliar os resultados em termos de utilidade e precisão.
Normalmente, o juiz recebe uma rubrica e é solicitado a atribuir uma pontuação numérica (por exemplo, de 1 a 10) ou fazer uma comparação entre pares para decidir qual das duas respostas é melhor. Embora não sejam perfeitas, essas avaliações batem com o que as pessoas preferem em cerca de 80-85% das vezes. Então, o LLM como juiz é uma alternativa que dá pra ajustar ao tamanho, em vez de usar revisões humanas caras.
A avaliação da IA está mudando tão rápido quanto os próprios modelos. À medida que referências como o MMLU ficam saturadas, os pesquisadores estão criando testes mais difíceis que testam a profundidade do raciocínio, em vez do conhecimento memorizado. FrontierMath e Humanity's Last Exam mostram essa nova fronteira de dificuldade, onde até os melhores modelos têm dificuldade.
Os sinais mais amplos apontam para uma direção: mais computação de treinamento, algoritmos mais inteligentes e conjuntos de benchmarks que acompanham o progresso. Os testes multimodais estão ampliando o que pedimos aos modelos para fazer, desde ler gráficos até entender sequências de vídeo.
Mas a conclusão continua simples. Nenhuma pontuação isolada conta toda a história. Uma modelo que lidera a Arena pode ficar para trás no banco da SWE. O modelo de codificação superior pode ter uma pontuação média em segurança. Combine o benchmark com o que você realmente precisa: raciocínio, geração de código, compreensão visual ou velocidade bruta. Essa é a única comparação que importa.
Para levar suas habilidades além do benchmarking, aprenda a construir e ajustar LLMs por conta própria com nosso Desenvolvimento de Grandes Modelos de Linguagem skill track.
Cursos de LLM
Programa
Programa
Curso
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
13 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
