
Track
AI Fundamentals
10 hr
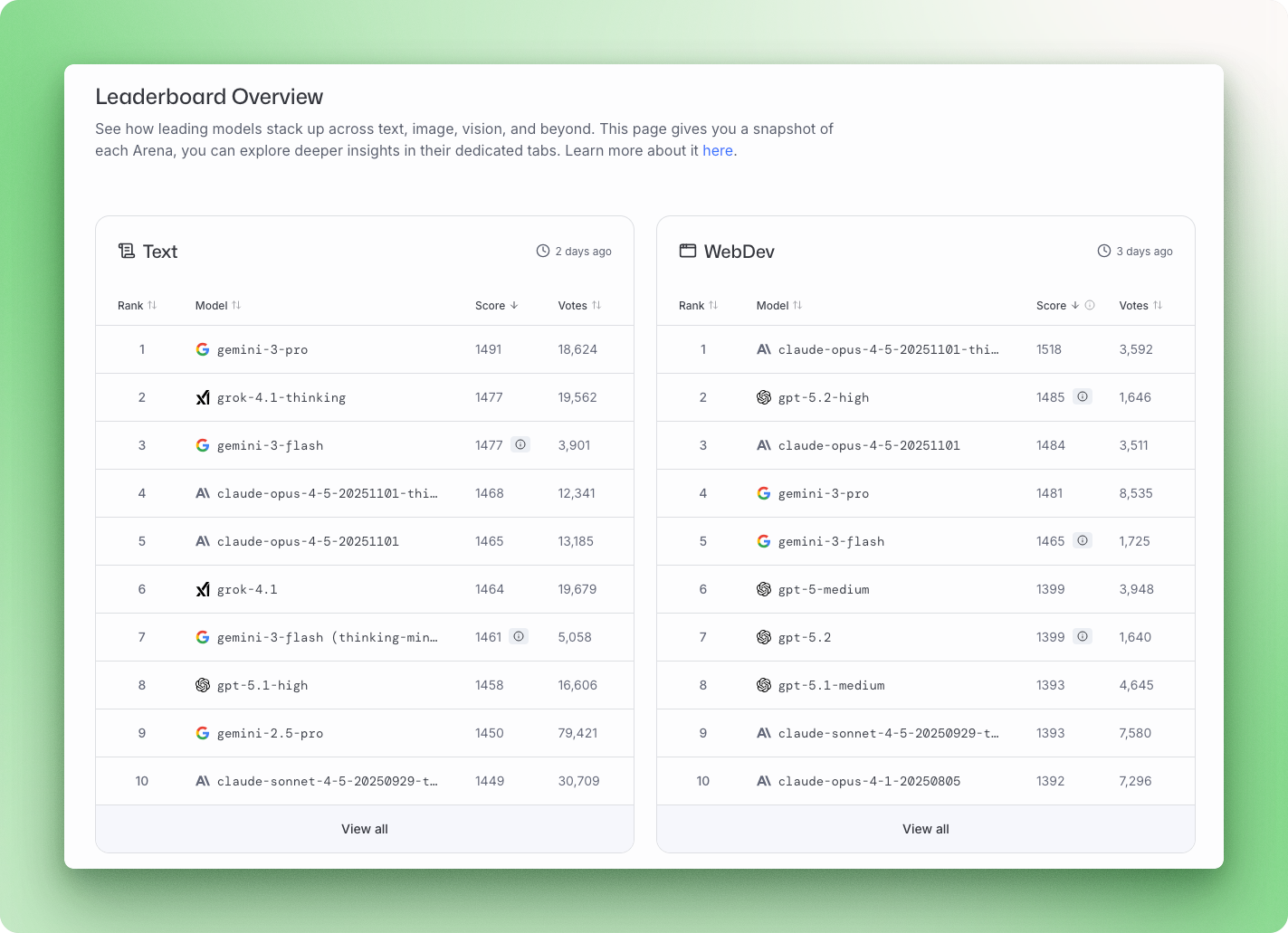
New AI models drop almost weekly: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Each release comes with benchmark scores and claims about being the best at something. The problem: most people have no idea what these numbers mean or how to compare them.
Large Language Model (LLM) benchmarks are standardized tests that measure how well models perform on specific tasks, from broad knowledge quizzes to complex coding challenges and multi-step reasoning problems. Understanding what each benchmark measures helps you cut through the marketing and pick the right model for your actual needs.
This guide breaks down the major benchmark categories, explains where to find current rankings, and shows you how to run your own evaluations. By the end, you'll know how to read a leaderboard and choose the AI that fits your use case.
For a deeper dive into how LLMs work under the hood, check out our LLMs Concepts course.
An LLM benchmark is a standardized test that measures how well a language model handles a specific type of task. The same questions and scoring rubric are applied to every model that takes the test.
The numbers in model announcements come from a handful of popular tests. Each score tells a different story, and no single benchmark captures the full picture.
Benchmarks are important for three reasons:
Comparing models: When OpenAI drops GPT-5.2 and Anthropic releases Claude Opus 4.5 in the same month, benchmarks give us common ground. Otherwise, we're stuck with each company claiming victory based on cherry-picked examples.
Tracking progress: Run the same benchmark over time, and you can see whether models are actually getting better. MMLU scores jumped from 70% in 2022 to over 90% in 2025.
Spotting gaps: A model might crush general knowledge questions but choke on multi-step math. Benchmarks surface these weaknesses.
Benchmark scores reflect more than raw intelligence. Multiple factors shape the numbers you see on leaderboards.
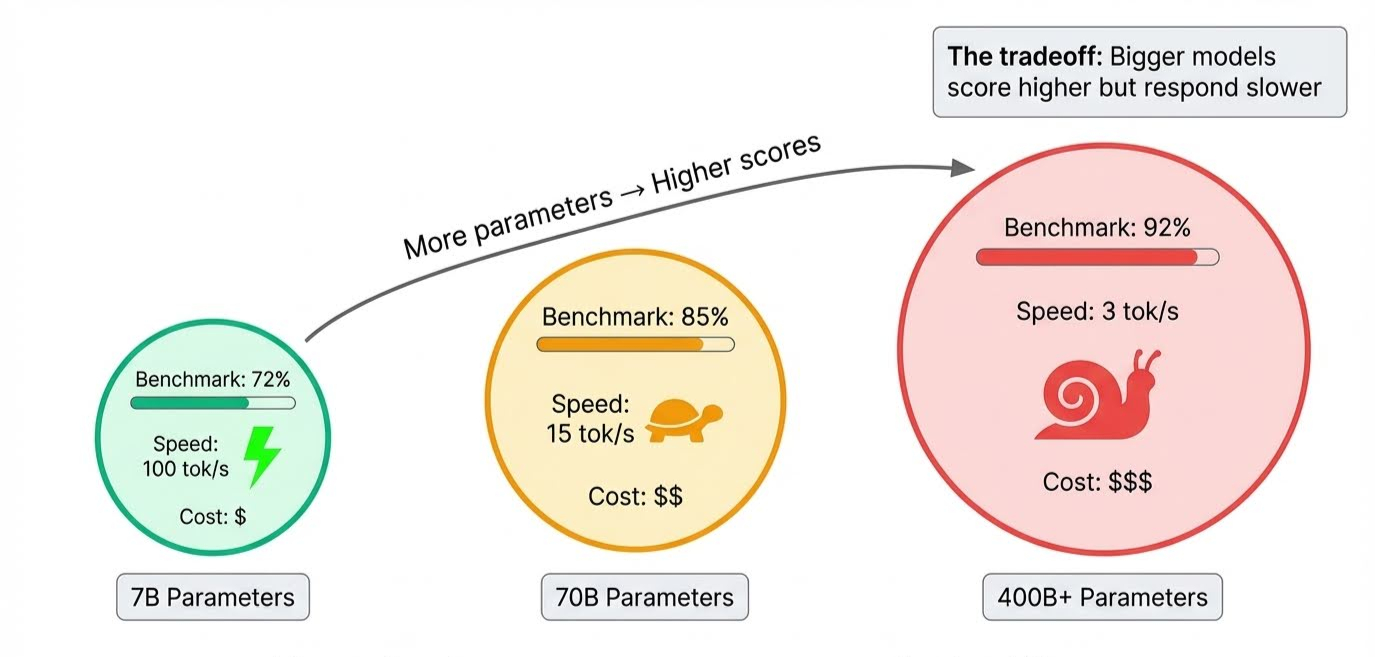
Model size is the obvious one. Parameters store everything a model learns, and frontier models pack hundreds of billions of them. More parameters mean the model can handle more complex reasoning and hold more nuance, which pushes scores up.
The trade-off shows up during inference, when the model actually generates responses: all those parameters need to fire in sequence, so bigger models are slower. A model might top every benchmark but take several seconds to answer.
Training duration is trickier. Each pass through the training data is called an epoch. Too few, and the model hasn't absorbed enough to score well. Too many and it starts memorizing examples instead of learning patterns that transfer to new questions. That's overfitting, and benchmark designers specifically try to catch it by including questions the model couldn't have seen during training.
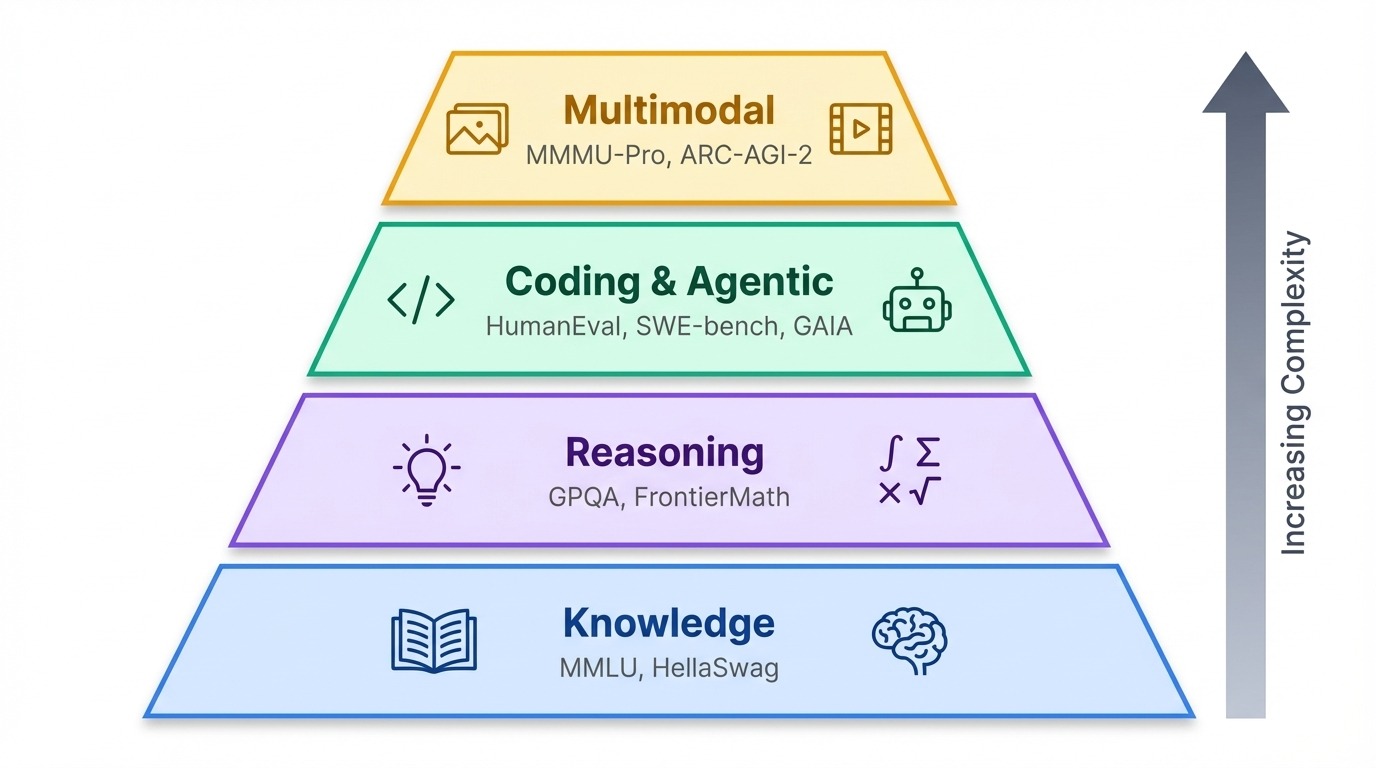
With dozens of benchmarks in use today, it helps to group them by what they actually test.
Benchmarks cluster into a rough hierarchy. At the base, knowledge tests check what a model knows. Above that, reasoning benchmarks probe how well it thinks. At the top sit agentic and multimodal tests that measure whether AI can act in the real world or process information beyond text.
MMLU (Massive Multitask Language Understanding) covers 57 academic subjects from high school to professional level, spanning everything from abstract algebra to world religions. For years, it served as the go-to test for general knowledge, but frontier models now cluster above 88%, leaving little room to tell them apart.
That saturation pushed researchers toward harder tests. GPQA (Graduate-level Google-Proof Q&A) asks 448 questions in biology, physics, and chemistry that domain experts designed to be unsearchable.
The benchmark has three difficulty tiers, with Diamond containing the hardest questions. Even with unlimited web access, non-experts score just 34%—only 9% above the result you would expect from random guessing with four answer options. As of December 2025, Gemini 3 Pro leads GPQA Diamond at 92.6%.
OpenAI's GDPval (Gross Domestic Product-valued) benchmark measures something different: real-world work output. It covers 44 occupations across sectors worth $3 trillion in annual economic activity, asking models to produce deliverables like legal briefs, slide decks, and engineering specs rather than answer multiple-choice questions. The recently released GPT-5.2 is the leader in this regard.
HellaSwag probes common-sense reasoning by presenting everyday scenarios and asking models to pick the most plausible next sentence. A person cooking dinner reaches for a pan. What happens next?
The wrong answers were written specifically to fool AI: they use words that statistically fit the context but describe impossible outcomes (the pan floats away, the stove turns into a cat). Humans score 95.6% because we know how kitchens work. Models get tricked because they predict likely words, not likely events.
The newest benchmarks push difficulty further:
FrontierMath features never-before-published problems from research mathematicians, where even the best models score below 20%.
Humanity's Last Exam compiles 2,500 expert-level questions designed to resist guessing.
MathArena pulls problems from 2025 math competitions to guarantee zero training data overlap.
HumanEval is the classic coding test: It contains 164 Python problems where models write functions from docstrings and are graded on whether the code passes unit tests. Most current frontier models score above 85%, so researchers created more difficult variants like HumanEval+ with more rigorous test cases.
SWE-bench (Software Engineering Benchmark) moves beyond isolated functions. It drops models into real GitHub repositories and asks them to fix actual bugs. The model must navigate the codebase, understand the issue, and produce a working patch.
SWE-bench Verified is a smaller, highly curated subset of the original SWE-bench, which filters for high-quality tasks vetted by human engineers. As of December 2025, Claude Opus 4.5 is the first model to break 80% in SWE-bench Verified (80.9%).
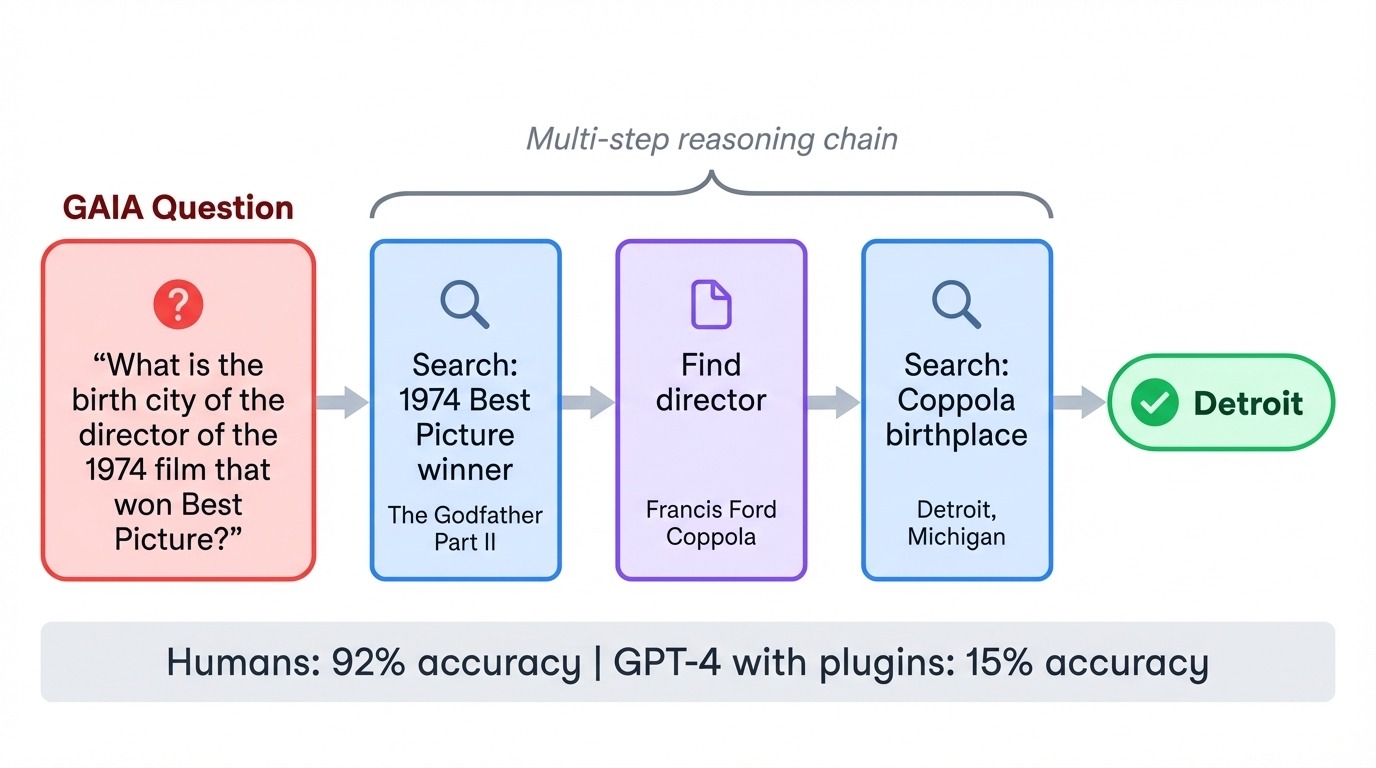
GAIA (General AI Assistants) inverts the usual difficulty relationship. Its 466 tasks are trivially easy for humans (92% accuracy) but brutal for AI. When GPT-4 first attempted GAIA with plugins, it scored just 15%. Each task requires chaining multiple steps: searching the web, reading documents, doing calculations, and synthesizing answers.
A typical question might ask for the birth city of the director of a specific 1970s film, requiring the model to identify the film, find the director, and then look up biographical details. The benchmark tests whether models can coordinate tools and execute multi-step plans without losing track.
Finally, WebArena deploys models in self-hosted web environments where they must complete tasks like booking flights, managing content systems, and navigating e-commerce sites by interacting with actual browser interfaces.
Text-only benchmarks miss a growing frontier. The MMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning) benchmark tests visual reasoning across 30 subjects by embedding questions directly into images, forcing models to read and interpret visual information at the same time.
The benchmark filters out questions that text-only models could answer, ensuring that vision actually matters. Gemini 3 Pro leads here at 81%.
Some benchmarks take visual reasoning to the next level.
MathVista, for instance, combines visual perception with mathematical reasoning. Problems include interpreting function plots, reading scientific charts, and solving geometry from diagrams. Video-MMMU extends this to temporal understanding, testing whether models can reason about causality and sequences across video frames rather than single images.
ARC-AGI-2 remains the benchmark that AI has not yet cracked. Each task presents a few input-output grid examples and asks the model to infer the transformation rule, then apply it to a new input.
Humans solve these puzzles in under two attempts. Pure language models score 0%. The best hybrid systems reach 54%, and that at a cost of $30 per task. ARC-AGI-2 tests fluid intelligence: reasoning from first principles rather than matching patterns seen during training.
Benchmarks generate scores, but leaderboards decide how to present them. Different platforms prioritize different factors: human preference, open-source transparency, or multi-dimensional evaluation. Knowing which leaderboard to consult depends on what you care about measuring.
The LMArena (LMSYS Chatbot Arena) takes a different approach than automated benchmarks. Instead of scoring answers against a rubric, it asks humans to pick the better response. Users submit a prompt, receive outputs from two anonymous models, and vote for the one they prefer. The models stay hidden until after the vote, preventing brand bias from influencing choices.
The platform uses a Bradley-Terry statistical model to convert over 5 million pairwise votes into rankings. As of December 2025, Gemini 3 Pro leads the overall Arena with a score of 1501, followed by Grok 4.1 at 1483, then Claude Opus 4.5 and GPT-5.2.
The LMArena captures something benchmarks miss: whether a response actually feels helpful. The trade-off is that verbose, confident-sounding answers can win votes even when a shorter, more accurate response exists.
Hugging Face’s Open LLM Leaderboard focuses on open-source models and runs them through standardized tests using the EleutherAI Evaluation Harness. Version 2 launched in June 2024 with more difficult benchmarks, after frontier models had saturated the original test suite.
The current battery includes GPQA, MATH Level 5, and MMLU-PRO, with normalized scoring where 0 means random performance and 100 means perfect. Top open models include Qwen3, Llama 3.3 70B, and DeepSeek V3.1, all competing within striking distance of closed-source leaders.
Stanford HELM (Holistic Evaluation of Language Models) measures more than whether the models’ results are accurate. Each model gets evaluated across seven dimensions per scenario: accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency.
The framework covers 42 scenarios and explicitly tracks where models fail, not just where they succeed. HELM also runs a separate safety leaderboard assessing risks like violence, fraud, and harassment. As of December 2025, Claude 3.5 Sonnet ranks highest on aggregate safety scores.
No single company wins everywhere. However, as soon as you cross-reference a few leaderboards, patterns start to show up.
Google's Gemini models dominate multimodal benchmarks and scientific reasoning. Gemini 3 Pro leads GPQA Diamond at 91.9% and tops the Arena overall. Anthropic's Claude line excels at coding and safety. Claude Opus 4.5 holds the SWE-bench Verified record at 80.9%, and Claude 3.5 Sonnet leads HELM Safety.
OpenAI's GPT models remain strong generalists, competitive across most benchmarks without a single standout weakness. Meta's Llama series proves open-source can match closed models on many tasks, with Llama 3.3 70B rivaling outputs from much larger proprietary systems.
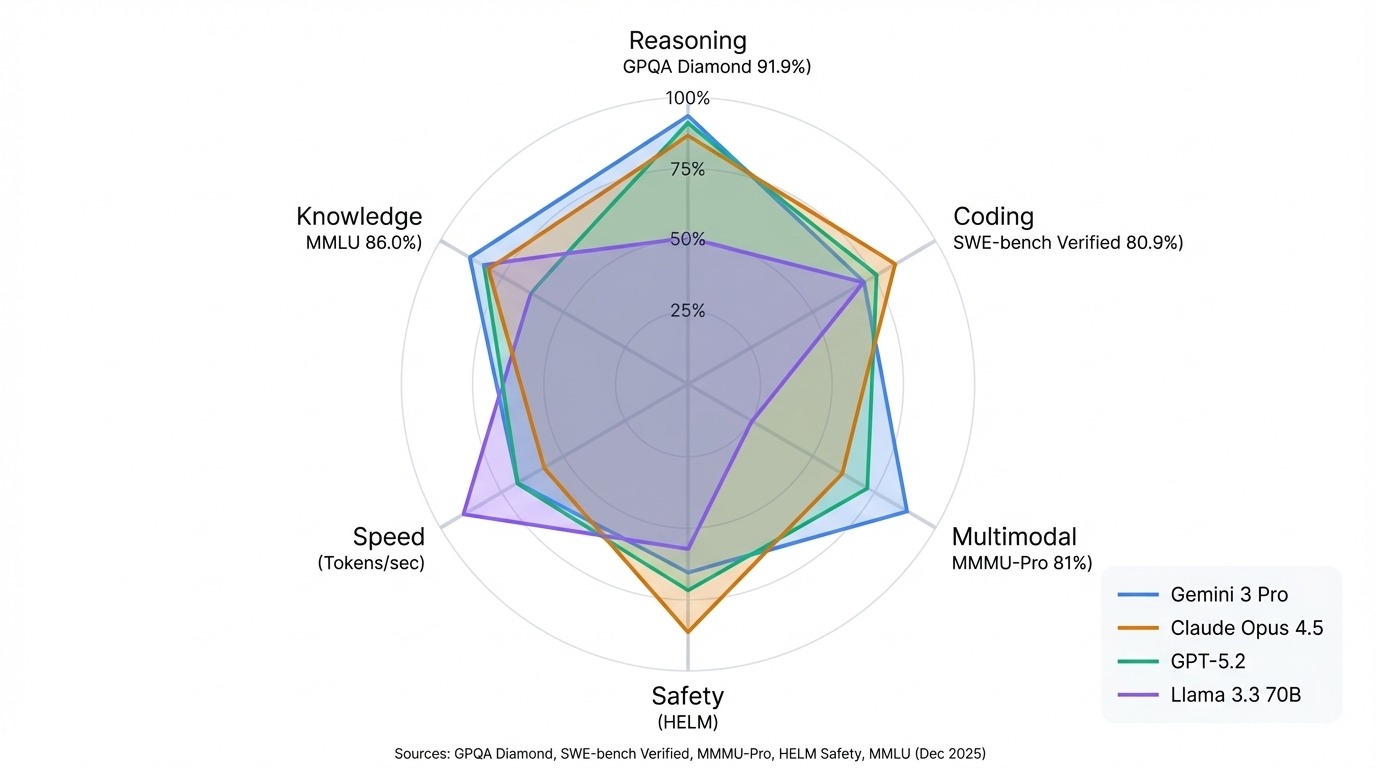
The pattern that matters most: match the leaderboard to your use case. Arena rankings reflect conversational quality. HELM scores show reliability and safety. Hugging Face tracks what you can run yourself. A model topping one list might rank mid-pack on another, and that's not a flaw in the rankings. It's different tests measuring different things.
Leaderboards tell you how models compare on standard tests, but sometimes you need answers specific to your situation.
You might be choosing between open-source models for your hardware, or verifying a fine-tuned model hasn’t lost general reasoning ability. In other cases, the standard benchmarks simply don't cover your domain.
In all of those cases, you might want to consider benchmarking LLMs yourself. I’ll show you how to do it and what you need to keep in mind.
The EleutherAI LM Evaluation Harness is the industry standard for running these evaluations locally. It powers the Hugging Face Open LLM Leaderboard and supports over 60 benchmarks.
It works differently from how most people interact with chatbots. It doesn't just "chat" with the model; it performs a more deterministic mathematical analysis.
For multiple-choice questions, which are a common method in benchmarks like MMLU or ARC, the harness does not ask the model to output "A," "B," "C," or "D." Instead, it constructs separate prompts for every single option and asks the model how likely each of them is. The option with the highest log-likelihood is then taken as the model’s choice.
Other benchmarks require a generative approach, where the model produces a full-text response rather than selecting a probability. Once the generation is complete, the harness parses the output using regular expressions (regex), extracting the specific value needed to verify it against the answer key.
Let's see how to run your first LLM evaluation.
You can install the evaluation harness using pip:
pip install lm-evalBefore running a full evaluation, test the pipeline with a small sample. The --limit flag restricts the benchmark to a specified number of examples. This example tests Qwen2.5-1.5B-Instruct, a small model that runs on most hardware without requiring a high-end GPU, using the HellaSwag benchmark:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Tasks |
Version |
Filter |
n-shot |
Metric |
|
Value |
|
Stderr |
|
hellaswag |
1 |
none |
0 |
acc |
↑ |
0.3 |
± |
0.1528 |
|
none |
0 |
acc_norm |
↑ |
0.4 |
± |
0.1633 |
The output shows two accuracy metrics: acc is raw accuracy, while acc_norm adjusts for the model's bias toward shorter or longer completions. Additionally, the standard error is reported, which shrinks as the sample size increases. In our first test using only 10 samples, the high Stderr (0.15) means these scores are rough estimates.
Remove --limit to run the complete benchmark. For multiple benchmarks in one pass, list them with commas:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsSet --device based on your hardware: mps for Apple Silicon, cuda:0 for NVIDIA GPUs, or cpu as a fallback. Full MMLU takes 1-2 hours on a modern GPU; smaller benchmarks like HellaSwag finish in minutes.
For latency and throughput testing, Ollama runs models locally and reports tokens per second across different quantization levels. A 7B model might generate 100+ tokens per second on a V100, while a 70B model drops to single digits.
There are a few best practices to keep in mind when benchmarking an LLM.
First and most importantly, you have to make sure that the model hasn’t seen the evaluation questions during training. If they do, you are merely measuring overfitting rather than the model’s ability to reason, as discussed in the beginning. In this case, the benchmark scores would become meaningless.
To get reproducible results, the variability in the model’s answers should be kept as low as possible. This can be achieved by setting the temperature to zero to favor accuracy over creativity.
The harness includes standardized few-shot prompts for each benchmark. Use them instead of writing your own prompts, since small wording changes affect scores more than expected. For domain-specific work, however, you should always build a small test set from real examples in your field before committing to a model for production.
Standard benchmarks excel at checking facts, but struggle to measure nuance. For open-ended tasks like summarization or creative writing, LLM-as-a-judge uses a stronger model to grade outputs on helpfulness and accuracy.
The judge is typically given a rubric and asked to either assign a numerical score (e.g., 1-10) or perform a pairwise comparison to decide which of two answers is better. While not perfect, these judgments align with human preferences around 80-85% of the time. Therefore, LLM-as-a-judge offers a scalable alternative to expensive human review.
AI evaluation is changing as fast as the models themselves. As benchmarks like MMLU saturate, researchers are building harder tests that probe reasoning depth rather than memorized knowledge. FrontierMath and Humanity's Last Exam represent this new difficulty frontier, where even the best models struggle.
The broader signals point in one direction: more training compute, smarter algorithms, and benchmark suites that keep pace with progress. Multimodal tests are expanding what we ask models to do, from reading charts to understanding video sequences.
But the takeaway stays simple. No single score tells the whole story. A model leading the Arena might trail on the SWE-bench. The top coding model might score mid-pack on safety. Match the benchmark to what you actually need: reasoning, code generation, visual understanding, or raw speed. That's the only comparison that matters.
To take your abilities beyond benchmarking, learn building and fine-tuning LLMs yourself with our Developing Large Language Models skill track.
LLM Courses
Track
Track
Course
blog
Rajesh Kumar
15 min
blog
Javier Canales Luna
12 min
blog
Tim Lu
15 min
Tutorial
Abid Ali Awan
Tutorial
Maria Eugenia Inzaugarat
Tutorial
Abid Ali Awan
