
Cursus
Principes fondamentaux de l'IA
10 h
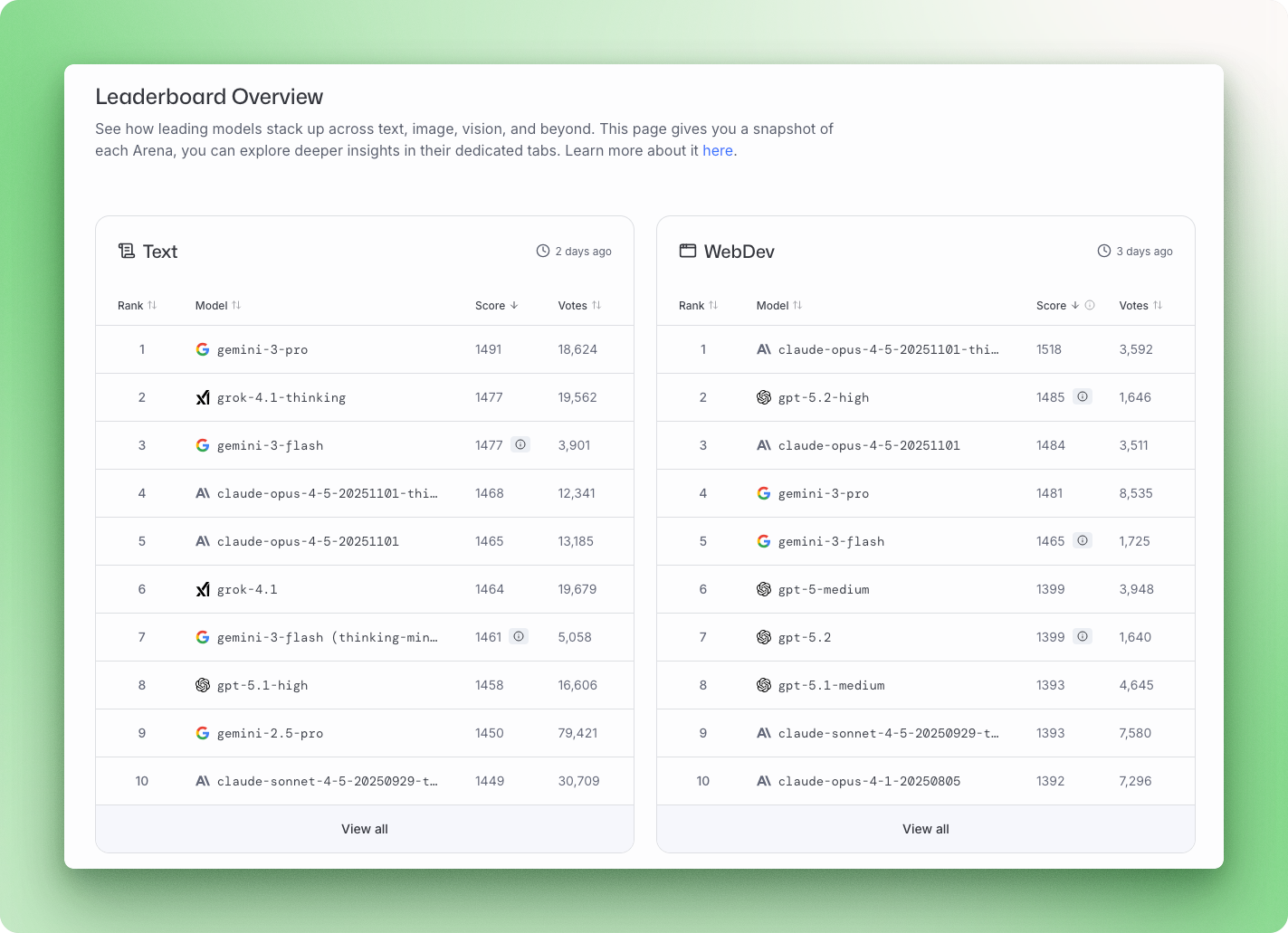
De nouveaux modèles d'IA apparaissent presque chaque semaine : Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Chaque nouvelle version est accompagnée de résultats de tests de performance et revendique la prééminence dans un domaine particulier. Le problème : la plupart des gens ne comprennent pas la signification de ces chiffres ni comment les comparer.
Les benchmarks des modèles linguistiques à grande échelle (LLM) sont des tests standardisés qui évaluent les performances des modèles sur des tâches spécifiques, allant de questionnaires de connaissances générales à des défis de codage complexes et des problèmes de raisonnement en plusieurs étapes. Comprendre ce que mesure chaque indice de référence vous aide à faire abstraction du marketing et à choisir le modèle adapté à vos besoins réels.
Ce guide présente les principales catégories de référence, explique où trouver les classements actuels et vous montre comment réaliser vos propres évaluations. À la fin, vous saurez comment interpréter un classement et choisir l'IA qui correspond à votre cas d'utilisation.
Pour approfondir vos connaissances sur le fonctionnement interne des LLM, veuillez consulter notre cours sur les concepts des LLM .
Un benchmark LLM est un test standardisé qui mesure la capacité d'un modèle linguistique à traiter un type de tâche spécifique. Les mêmes questions et la même grille d'évaluation sont utilisées pour tous les modèles qui passent le test.
Les chiffres indiqués dans les annonces relatives aux modèles proviennent d'une sélection de tests reconnus. Chaque score reflète une situation différente, et aucun indice de référence ne permet à lui seul de dresser un tableau complet.
Les benchmarks sont importants pour trois raisons :
Comparaison des modèles : Lorsque OpenAI lance GPT-5.2 et Anthropic publie Claude Opus 4.5 au cours du même mois, les benchmarks nous fournissent un terrain d'entente. Sinon, nous nous retrouverons dans une situation où chaque entreprise revendiquera la victoire en s'appuyant sur des exemples choisis de manière sélective.
Suivi des progrès : Effectuez le même test de performance au fil du temps et vous pourrez constater si les modèles s'améliorent réellement. Les scores MMLU ont augmenté de 70 % en 2022 à plus de 90 % en 2025.
Identifier les lacunes : Un modèle peut exceller dans les questions de culture générale, mais rencontrer des difficultés avec les problèmes mathématiques à plusieurs étapes. Les tests de performance mettent en évidence ces faiblesses.
Les résultats des tests de performance reflètent davantage que la simple intelligence brute. Plusieurs facteurs influencent les chiffres que vous voyez dans les classements.
La taille du modèle est un élément évident. Les paramètres stockent tout ce qu'un modèle apprend, et les modèles de pointe en contiennent des centaines de milliards. Plus il y a de paramètres, plus le modèle peut gérer des raisonnements complexes et prendre en compte des nuances, ce qui améliore les scores.
Le compromis apparaît lors de l'inférence, lorsque le modèle génère effectivement des réponses : tous ces paramètres doivent être activés dans l'ordre, ce qui rend les modèles plus volumineux plus lents. Un modèle peut être en tête de tous les classements, mais prendre plusieurs secondes pour répondre.
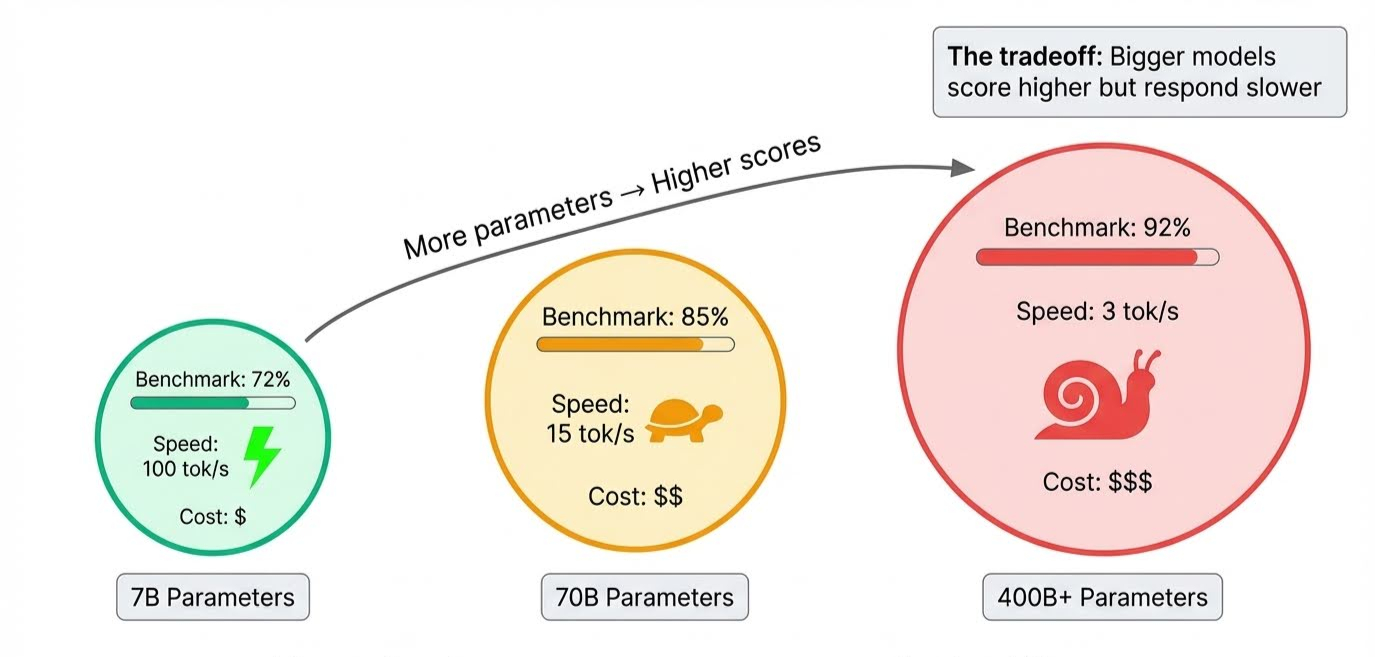
La durée de la formation est plus complexe. Chaque passage dans les données d'entraînement est appelé uneépreuve d' . Trop peu, et le modèle n'a pas absorbé suffisamment d'informations pour obtenir un bon score. S'il y en a trop, il commence à mémoriser des exemples au lieu d'apprendre des modèles qui peuvent être appliqués à de nouvelles questions. C'est le surajustement, et les concepteurs de benchmarks tentent spécifiquement de le détecter en incluant des questions que le modèle n'aurait pas pu voir pendant l'entraînement.
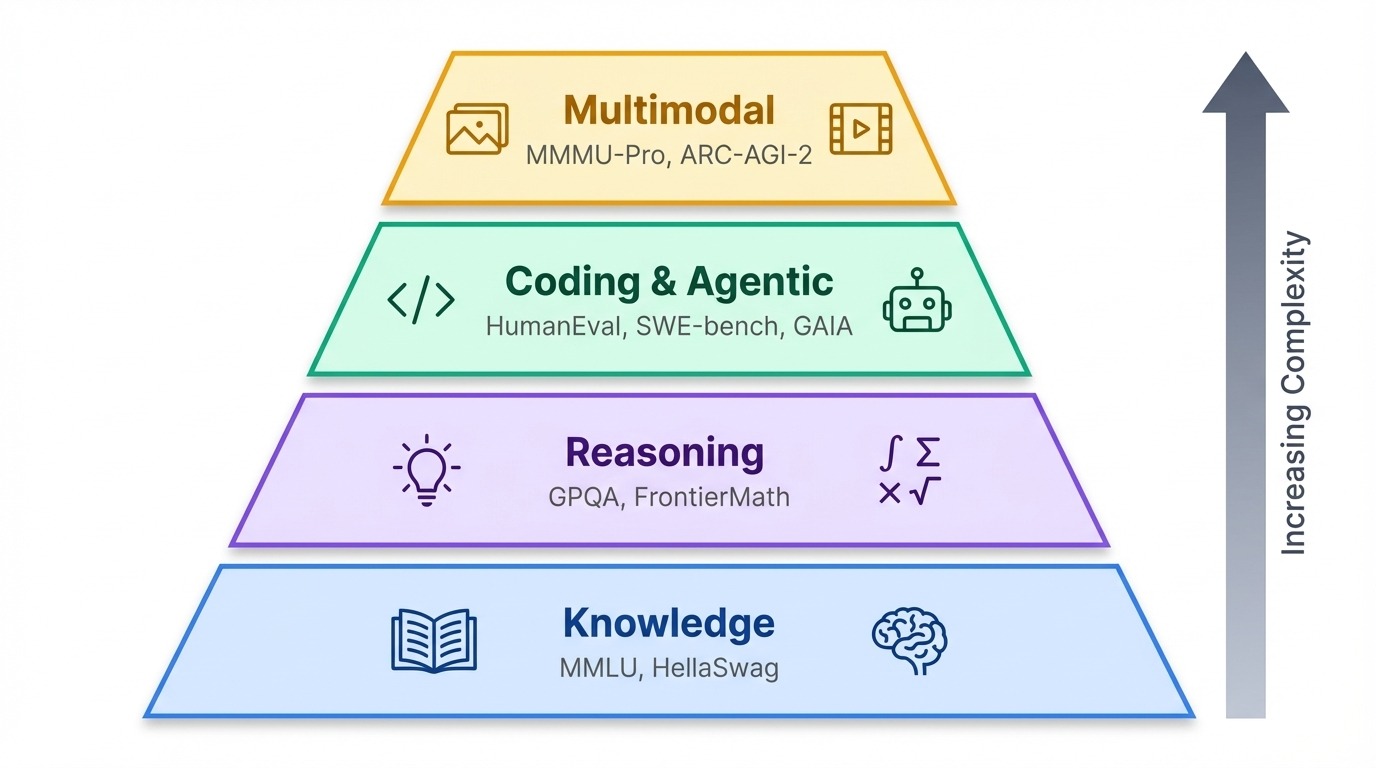
Avec les nombreuses mesures de performance actuellement utilisées, il est utile de les regrouper en fonction de ce qu'elles évaluent réellement.
Les benchmarks sont regroupés selon une hiérarchie approximative. À la base, les tests de connaissances évaluent ce qu'un modèle sait. En outre, les tests de raisonnement évaluent la qualité de son raisonnement. Au sommet se trouvent les tests agentiels et multimodaux qui évaluent si l'IA est capable d'agir dans le monde réel ou de traiter des informations autres que du texte.
MMLU (Massive Multitask Language Understanding) couvre 57 matières scolaires, du niveau secondaire au niveau professionnel, allant de l'algèbre abstraite aux religions du monde. Pendant des années, il a été le test de référence en matière de culture générale, mais les modèles de pointe se situent désormais tous au-dessus de 88 %, ce qui laisse peu de marge pour les distinguer les uns des autres.
Cette saturation a incité les chercheurs à mettre en place des tests plus rigoureux. GPQA (Graduate-level Google-Proof Q&A) pose 448 questions en biologie, physique et chimie, conçues par des experts dans ces domaines pour être impossibles à trouver par une simple recherche.
Le test comporte trois niveaux de difficulté, le niveau Diamant contenant les questions les plus difficiles. Même avec un accès illimité à Internet, les non-experts n'obtiennent qu'un score de 34 %, soit seulement 9 % de plus que le résultat auquel on pourrait s'attendre en répondant au hasard parmi quatre options. À compter de décembre 2025, Gemini 3 Pro devance GPQA Diamond avec 92,6 %.
Le benchmarkGDPval (Gross Domestic Product-valued) d'OpenAI mesure un élément différent : la production réelle. Il couvre 44 professions dans divers secteurs représentant une activité économique annuelle de 3 000 milliards de dollars, et demande aux modèles de produire des livrables tels que des mémoires juridiques, des présentations PowerPoint et des spécifications techniques plutôt que de répondre à des questions à choix multiples. Le récent lancement du GPT-5.2 est à la pointe dans ce domaine.
HellaSwag explore le raisonnement fondé sur le bon sens en présentant des scénarios quotidiens et en demandant aux modèles de sélectionner la phrase suivante la plus plausible. Une personne qui prépare le dîner prend une poêle. Quelle sera la suite des événements ?
Les réponses incorrectes ont été rédigées spécifiquement pour induire en erreur l'IA : elles utilisent des mots qui, statistiquement, correspondent au contexte, mais décrivent des résultats impossibles (la poêle flotte, la cuisinière se transforme en chat). Les humains obtiennent un score de 95,6 % car nous comprenons le fonctionnement des cuisines. Les modèles sont trompés car ils prédisent des mots probables, et non des événements probables.
Les derniers benchmarks augmentent encore le niveau de difficulté :
FrontierMath propose des problèmes inédits élaborés par des mathématiciens chercheurs, où même les meilleurs modèles obtiennent un score inférieur à 20 %.
Le dernier examen de l'humanité compile 2 500 questions de niveau expert conçues pour empêcher toute approximation.
MathArena sélectionne des problèmes issus de 2025 concours de mathématiques afin de garantir qu'il n'y ait aucun chevauchement entre les données d'entraînement.
HumanEval est le test de codage classique : Il contient 164 problèmes Python dans lesquels les modèles écrivent des fonctions à partir de chaînes de documentation et sont notés en fonction de la réussite du code aux tests unitaires. La plupart des modèles de pointe actuels obtiennent un score supérieur à 85 %, c'est pourquoi les chercheurs ont créé des variantes plus complexes tellesqu' t HumanEval+ avec des cas de test plus rigoureux.
SWE-bench (, ou benchmark en génie logiciel) va au-delà des fonctions isolées. Il place les modèles dans de véritables dépôts GitHub et leur demande de corriger des bogues réels. Le candidat doit être capable de naviguer dans le code source, de comprendre le problème et de produire un correctif fonctionnel.
SWE-bench Verified est un sous-ensemble plus restreint et soigneusement sélectionné du SWE-bench original, qui filtre les tâches de haute qualité vérifiées par des ingénieurs humains. En décembre 2025, Claude Opus 4.5 est le premier modèle à dépasser les 80 % dans le classement SWE-bench Verified (80,9 %).
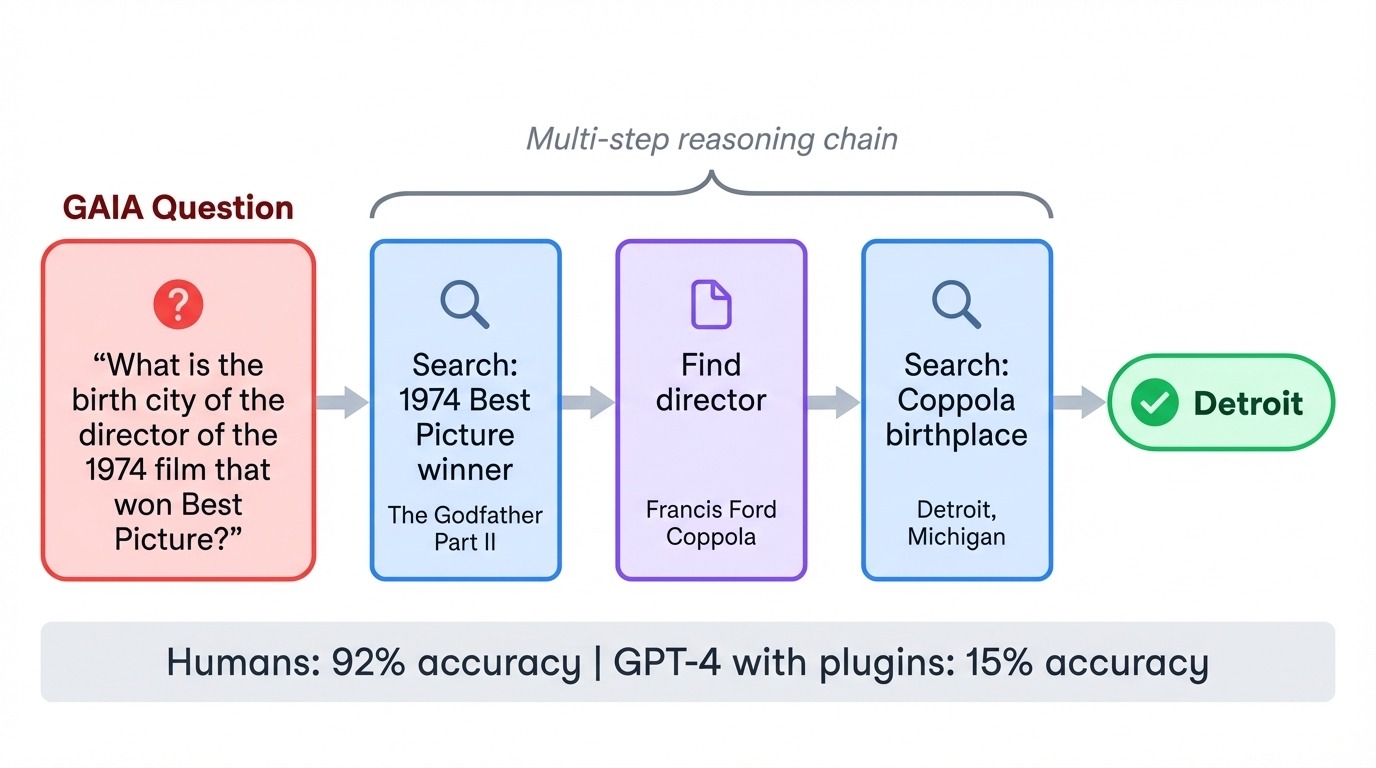
GAIA (, assistants généraux d'IA) inverse la relation habituelle entre difficulté et complexité. Ses 466 tâches sont extrêmement simples pour les humains (92 % de précision), mais extrêmement difficiles pour l'IA. Lorsque GPT-4 a tenté pour la première fois GAIA avec des plugins, il n'a obtenu qu'un score de 15 %. Chaque tâche nécessite l'enchaînement de plusieurs étapes : effectuer des recherches sur Internet, lire des documents, effectuer des calculs et synthétiser les réponses.
Une question type pourrait porter sur la ville natale du réalisateur d'un film spécifique des années 1970, ce qui nécessiterait que le modèle identifie le film, trouve le réalisateur, puis recherche des informations biographiques. Le test évalue si les modèles sont capables de coordonner des outils et d'exécuter des plans en plusieurs étapes sans perdre le cursus.
Enfin, WebArena déploie des modèles dans des environnements web auto-hébergés où ils doivent accomplir des tâches telles que la réservation de vols, la gestion de systèmes de contenu et la navigation sur des sites de commerce électronique en interagissant avec des interfaces de navigateur réelles.
Les tests de performance basés uniquement sur du texte ne prennent pas en compte une frontière en pleine expansion. Le benchmarkMMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning)de l' , évalue le raisonnement visuel de 30 sujets en intégrant des questions directement dans des images, obligeant ainsi les modèles à lire et à interpréter simultanément les informations visuelles.
Le benchmark élimine les questions auxquelles les modèles textuels pourraient répondre, garantissant ainsi que la vision joue un rôle déterminant. Gemini 3 Pro est en tête avec 81 %.
Certains benchmarks élèvent le raisonnement visuel à un niveau supérieur.
MathVista, par exemple, combine la perception visuelle et le raisonnement mathématique. Les difficultés rencontrées comprennent l'interprétation des graphiques de fonctions, la lecture de tableaux scientifiques et la résolution de problèmes de géométrie à partir de diagrammes. Video-MMMU étend cette approche à la compréhension temporelle, en testant si les modèles peuvent raisonner sur la causalité et les séquences à travers les images vidéo plutôt que sur des images individuelles.
L'ARC-AGI-2 ( ) reste la référence que l'IA n'a pas encore réussi à dépasser. Chaque tâche présente quelques exemples de grilles d'entrée-sortie et demande au modèle de déduire la règle de transformation, puis de l'appliquer à une nouvelle entrée.
Les individus résolvent ces énigmes en moins de deux tentatives. Les modèles linguistiques purs obtiennent un score de 0 %. Les meilleurs systèmes hybrides atteignent 54 %, pour un coût de 30 dollars par tâche. L'ARC-AGI-2 évalue l'intelligence fluide : raisonnement à partir de principes fondamentaux plutôt que comparaison de modèles observés pendant la formation.
Les benchmarks génèrent des scores, mais ce sont les classements qui déterminent la manière de les présenter. Différentes plateformes accordent la priorité à différents facteurs : préférence humaine, transparence open source ou évaluation multidimensionnelle. Le choix du classement à consulter dépend de ce que vous souhaitez mesurer.
La LMArena (LMSYS Chatbot Arena) adopte une approche différente de celle des benchmarks automatisés. Au lieu de noter les réponses selon une grille d'évaluation, il demande à des personnes de sélectionner la meilleure réponse. Les utilisateurs soumettent une invite, reçoivent les résultats de deux modèles anonymes et votent pour celui qu'ils préfèrent. Les modèles restent confidentiels jusqu'à la fin du vote, ce qui évite que les préférences pour certaines marques n'influencent les choix.
La plateforme utilise un modèle statistique Bradley-Terry pour convertir plus de 5 millions de votes par paires en classements. En décembre 2025, Gemini 3 Pro est en tête du classement général de l'Arena avec un score de 1501, suivi de Grok 4.1 avec 1483, puis de Claude Opus 4.5 et GPT-5.2.
LMArena identifie un élément que les benchmarks ne prennent pas en compte : le caractère réellement utile d'une réponse. Le compromis est que des réponses détaillées et assurées peuvent obtenir des votes, même lorsqu'il existe une réponse plus courte et plus précise.
Le classement Open LLM Leaderboard de Hugging Face se concentre sur les modèles open source et les soumet à des tests standardisés à l'aide du harnais d'évaluation EleutherAI. La version 2 a été lancée en juin 2024 avec des critères de référence plus exigeants, après que les modèles de pointe aient saturé la suite de tests initiale.
La batterie actuelle comprend GPQA, MATH niveau 5 et MMLU-PRO, avec une notation normalisée où 0 correspond à une performance aléatoire et 100 à une performance parfaite. Les principaux modèles ouverts comprennent Qwen3, Llama 3.3 70B et DeepSeek V3.1, qui rivalisent tous avec les leaders du secteur des logiciels propriétaires.
Stanford HELM (Holistic Evaluation of Language Models) évalue plus que la simple précision des résultats des modèles. Chaque modèle est évalué selon sept critères par scénario : précision, calibrage, robustesse, équité, biais, toxicité et efficacité.
Le cadre couvre 42 scénarios et suit explicitement les cas où les modèles échouent, et pas seulement ceux où ils réussissent. HELM gère également un classement distinct en matière de sécurité qui évalue les risques tels que la violence, la fraude et le harcèlement. En décembre 2025, Claude 3.5 Sonnet occupe la première place du classement général en matière de sécurité.
Aucune entreprise ne peut réussir dans tous les domaines. Cependant, dès que l'on compare plusieurs classements, des tendances commencent à se dessiner.
Les modèles Gemini de Google dominent les benchmarks multimodaux et le raisonnement scientifique. Gemini 3 Pro est en tête du classement GPQA Diamond avec 91,9 % et occupe la première place du classement général Arena. La gamme Claude d'Anthropic se distingue par ses performances en matière de codage et de sécurité. Claude Opus 4.5 détient le record vérifié par SWE-bench avec 80,9 %, et Claude 3.5 Sonnet est en tête du classement HELM Safety.
Les modèles GPT d'OpenAI restent des généralistes performants, compétitifs dans la plupart des benchmarks, sans aucune faiblesse notable. La série Llama de Meta démontre que l'open source peut rivaliser avec les modèles fermés dans de nombreuses tâches, avec Llama 3.3 70B rivalisant avec les résultats de systèmes propriétaires beaucoup plus importants.
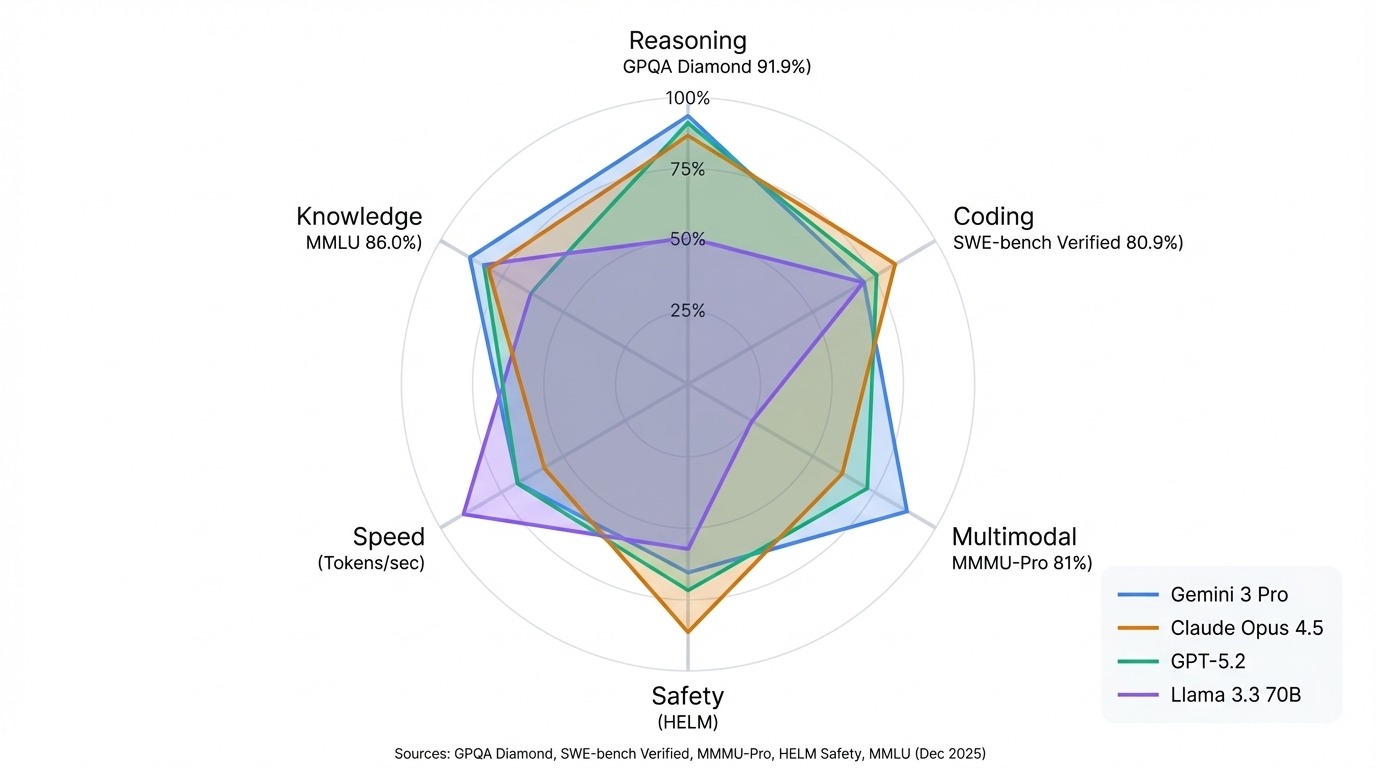
Le modèle le plus pertinent : adaptez le classement à votre cas d'utilisation. Les classements de l'arène reflètent la qualité des conversations. Les résultats HELM démontrent la fiabilité et la sécurité. Hugging Face suit ce que vous pouvez exécuter vous-même. Un modèle qui arrive en tête d'un classement peut se classer en milieu de tableau dans un autre, et cela ne constitue pas une erreur dans le classement. Il s'agit de tests différents qui mesurent des éléments différents.
Les classements vous indiquent comment les modèles se comparent lors de tests standard, mais il est parfois nécessaire d'obtenir des réponses spécifiques à votre situation.
Vous pourriez être amené à choisir entre différents modèles open source pour votre matériel informatique ou à vérifier qu'un modèle optimisé n'a pas perdu sa capacité de raisonnement général. Dans d'autres cas, les critères de référence standard ne couvrent tout simplement pas votre domaine.
Dans tous ces cas, il pourrait être judicieux d'envisager de comparer vous-même les LLM. Je vais vous expliquer comment procéder et ce dont vous devez tenir compte.
Le harnais d'évaluation EleutherAI LM est la norme industrielle pour effectuer ces évaluations localement. Il alimente le classement Hugging Face Open LLM et prend en charge plus de 60 benchmarks.
Son fonctionnement diffère de la manière dont la plupart des gens interagissent avec les chatbots. Il ne se contente pas de « discuter » avec le modèle, il effectue une analyse mathématique plus déterministe.
Pour les questions à choix multiples, qui constituent une méthode courante dans les benchmarks tels que MMLU ou ARC, le harnais ne demande pas au modèle de fournir les réponses « A », « B », « C » ou « D ». Au lieu de cela, il crée des invites distinctes pour chaque option et demande au modèle quelle est la probabilité de chacune d'entre elles. L'option présentant la plus grande log-vraisemblance est alors retenue comme choix du modèle.
D'autres critères de référence nécessitent une approche générative, dans laquelle le modèle produit une réponse en texte intégral plutôt que de sélectionner une probabilité. Une fois la génération terminée, le harnais analyse la sortie à l'aide d'expressions régulières (regex), en extrayant la valeur spécifique nécessaire pour la vérifier par rapport au corrigé.
Voyons comment effectuer votre première évaluation LLM.
Vous pouvez installer le harnais d'évaluation à l'aide de l'outil d'évaluation de l'pip:
pip install lm-evalAvant de procéder à une évaluation complète, veuillez tester le pipeline avec un petit échantillon. Le drapeau ` --limit ` limite le benchmark à un nombre spécifié d'exemples. Cet exemple teste Qwen2.5-1.5B-Instruct, un modèle compact qui fonctionne sur la plupart des matériels sans nécessiter de GPU haut de gamme, à l'aide du benchmark HellaSwag :
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Tâches |
Version |
Filtre |
n-shot |
Système métrique |
|
Valeur |
|
Stderr |
|
hellaswag |
1 |
aucun |
0 |
acc |
↑ |
0,3 |
± |
0,1528 |
|
aucun |
0 |
acc_norm |
↑ |
0,4 |
± |
0,1633 |
Le résultat affiche deux mesures de précision : l' acc correspond à la précision brute, tandis que l' acc_norm e ajuste le biais du modèle vers des complétions plus courtes ou plus longues. De plus, l'erreur type est indiquée, celle-ci diminuant à mesure que la taille de l'échantillon augmente. Dans notre premier test utilisant seulement 10 échantillons, l'Stderr e élevée (0,15) indique que ces scores sont des estimations approximatives.
Veuillez supprimer --limit pour exécuter le benchmark complet. Pour plusieurs benchmarks en un seul passage, veuillez les énumérer en les séparant par des virgules :
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsVeuillez définir --device en fonction de votre matériel : mps pour Apple Silicon, cuda:0 pour les GPU NVIDIA ou cpu comme solution de secours. Le MMLU complet nécessite 1 à 2 heures sur un GPU moderne ; les benchmarks plus petits comme HellaSwag s'exécutent en quelques minutes.
Pour les tests de latence et de débit, Ollama exécute des modèles localement et rend compte du nombre de jetons par seconde pour différents niveaux de quantification. Un modèle 7B peut générer plus de 100 jetons par seconde sur un V100, tandis qu'un modèle 70B tombe à moins de dix.
Il existe quelques bonnes pratiques à garder à l'esprit lors de l'évaluation comparative d'un LLM.
Tout d'abord, et surtout, il est essentiel de s'assurer que le modèle n'a pas été exposé aux questions d'évaluation pendant l'entraînement. Si tel est le cas, vous mesurez simplement le surajustement plutôt que la capacité de raisonnement du modèle, comme indiqué au début. Dans ce cas, les scores de référence deviendraient insignifiants.
Afin d'obtenir des résultats reproductibles, la variabilité des réponses du modèle doit être maintenue aussi faible que possible. Pour ce faire, il est possible de régler la température à zéro afin de privilégier la précision plutôt que la créativité.
Le harnais comprend des invites standardisées à quelques essais pour chaque référence. Veuillez les utiliser à la place de vos propres invites, car de légères modifications dans la formulation peuvent influencer les scores plus que prévu. Pour les travaux spécifiques à un domaine, il est toutefois recommandé de toujours constituer un petit ensemble de tests à partir d'exemples réels dans votre domaine avant de vous engager dans un modèle pour la production.
Les critères de référence standard sont excellents pour vérifier les faits, mais ont du mal à mesurer les nuances. Pour les tâches ouvertes telles que la synthèse ou l'écriture créative, LLM-as-a-judge utilise un modèle plus performant pour évaluer les résultats en fonction de leur utilité et de leur précision.
Le juge reçoit généralement une grille d'évaluation et est invité à attribuer une note numérique (par exemple, de 1 à 10) ou à effectuer une comparaison par paires afin de déterminer laquelle des deux réponses est la plus appropriée. Bien qu'elles ne soient pas parfaites, ces évaluations correspondent aux préférences humaines dans environ 80 à 85 % des cas. Par conséquent, LLM-as-a-judge offre une alternative évolutive à l'examen humain coûteux.
L'évaluation de l'IA évolue aussi rapidement que les modèles eux-mêmes. À mesure que les tests de référence tels que le MMLU atteignent leur limite, les chercheurs élaborent des tests plus complexes qui évaluent la profondeur du raisonnement plutôt que les connaissances mémorisées. FrontierMath et Humanity's Last Exam représentent cette nouvelle frontière de difficulté, où même les meilleurs modèles rencontrent des difficultés.
Les signaux généraux indiquent une direction : davantage de puissance de calcul pour l'entraînement, des algorithmes plus intelligents et des suites de tests de performance qui suivent le rythme des progrès. Les tests multimodaux élargissent le champ des tâches que nous demandons aux modèles d'accomplir, de la lecture de graphiques à la compréhension de séquences vidéo.
Cependant, la conclusion reste simple. Aucun score ne reflète à lui seul la réalité. Un modèle menant l'Arena pourrait être en retard sur le banc SWE. Le modèle de codage supérieur pourrait obtenir une note moyenne en matière de sécurité. Adaptez le critère de référence à vos besoins réels : raisonnement, génération de code, compréhension visuelle ou vitesse brute. C'est la seule comparaison qui importe.
Pour développer vos compétences au-delà du benchmarking, apprenez à créer et à affiner vous-même des modèles linguistiques à grande échelle grâce à notre développement de grands modèles linguistiques cursus track.
Cours de maîtrise en droit
Cursus
Cursus
Cours
blog
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
Zoumana Keita
15 min
blog
Kurtis Pykes
15 min
Tutoriel

