
Lernpfad
Grundlagen der KI
10 Std.
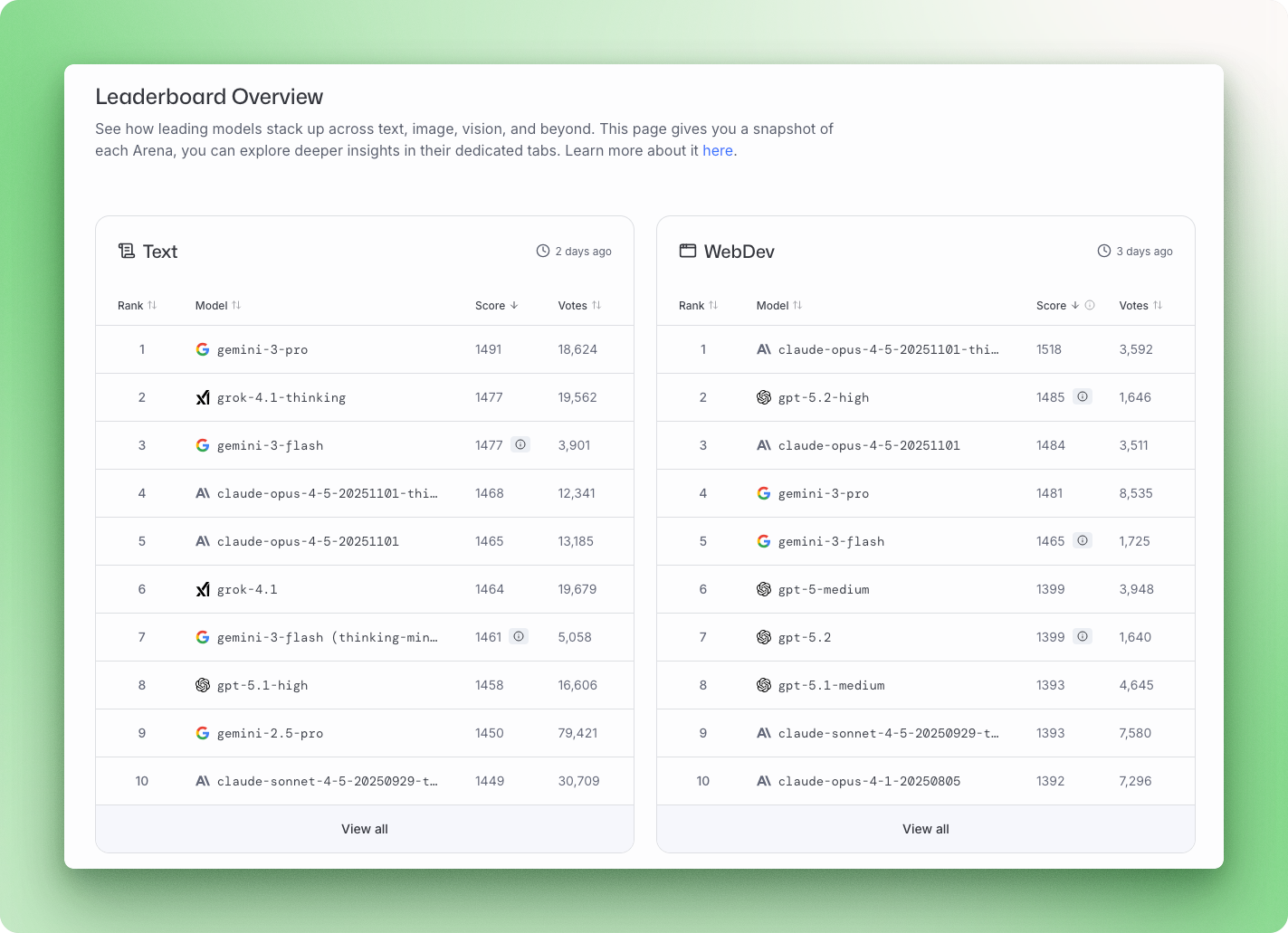
Neue KI-Modelle kommen fast jede Woche raus: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Jede neue Version kommt mit Benchmark-Ergebnissen und behauptet, in irgendwas die Beste zu sein. Das Problem: Die meisten Leute haben keine Ahnung, was diese Zahlen bedeuten oder wie man sie vergleicht.
Large Language Model (LLM)-Benchmarks sind standardisierte Tests, die zeigen, wie gut Modelle bei bestimmten Aufgaben abschneiden, von allgemeinen Wissensquizzen bis hin zu kniffligen Programmieraufgaben und mehrstufigen Denkaufgaben. Wenn du verstehst, was die einzelnen Benchmarks messen, kannst du dich nicht von Marketing-Versprechungen beeinflussen lassen und das richtige Modell für deine tatsächlichen Bedürfnisse auswählen.
Dieser Leitfaden erklärt die wichtigsten Benchmark-Kategorien, zeigt, wo du aktuelle Rankings findest, und hilft dir dabei, deine eigenen Bewertungen durchzuführen. Am Ende wirst du wissen, wie man eine Rangliste liest und die KI auswählt, die zu deinem Anwendungsfall passt.
Wenn du mehr darüber wissen willst, wie LLMs funktionieren, schau dir unsere LLMs-Konzeptkurs .
Ein LLM-Benchmark ist ein standardisierter Test, der misst, wie gut ein Sprachmodell mit einer bestimmten Art von Aufgabe klarkommt. Für jedes Modell, das den Test macht, werden die gleichen Fragen und die gleiche Bewertungsrubrik benutzt.
Die Zahlen in den Modellankündigungen kommen von ein paar bekannten Tests. Jede Punktzahl hat ihre eigene Geschichte, und kein einzelner Maßstab zeigt das ganze Bild.
Benchmarks sind aus drei Gründen wichtig:
Modelle vergleichen: Wenn OpenAI GPT-5.2 rausbringt und Anthropic im selben Monat Claude Opus 4.5 veröffentlicht, geben uns Benchmarks eine gemeinsame Basis. Sonst bleibt es dabei, dass jedes Unternehmen anhand ausgewählter Beispiele den Sieg für sich beansprucht.
Fortschritte verfolgen: Mach denselben Benchmark-Test über einen längeren Zeitraum und du kannst sehen, ob die Modelle wirklich besser werden. Die MMLU -Werte sind von 70 % im Jahr 2022 auf über 90 % im Jahr 2025 gestiegen.
Lücken erkennen: Ein Modell kann bei Allgemeinwissen-Fragen super abschneiden, aber bei mehrstufigen Matheaufgaben total versagen. Benchmarks zeigen diese Schwächen auf.
Benchmark-Ergebnisse zeigen mehr als nur die reine Intelligenz. Viele Sachen beeinflussen die Zahlen, die du in den Ranglisten siehst.
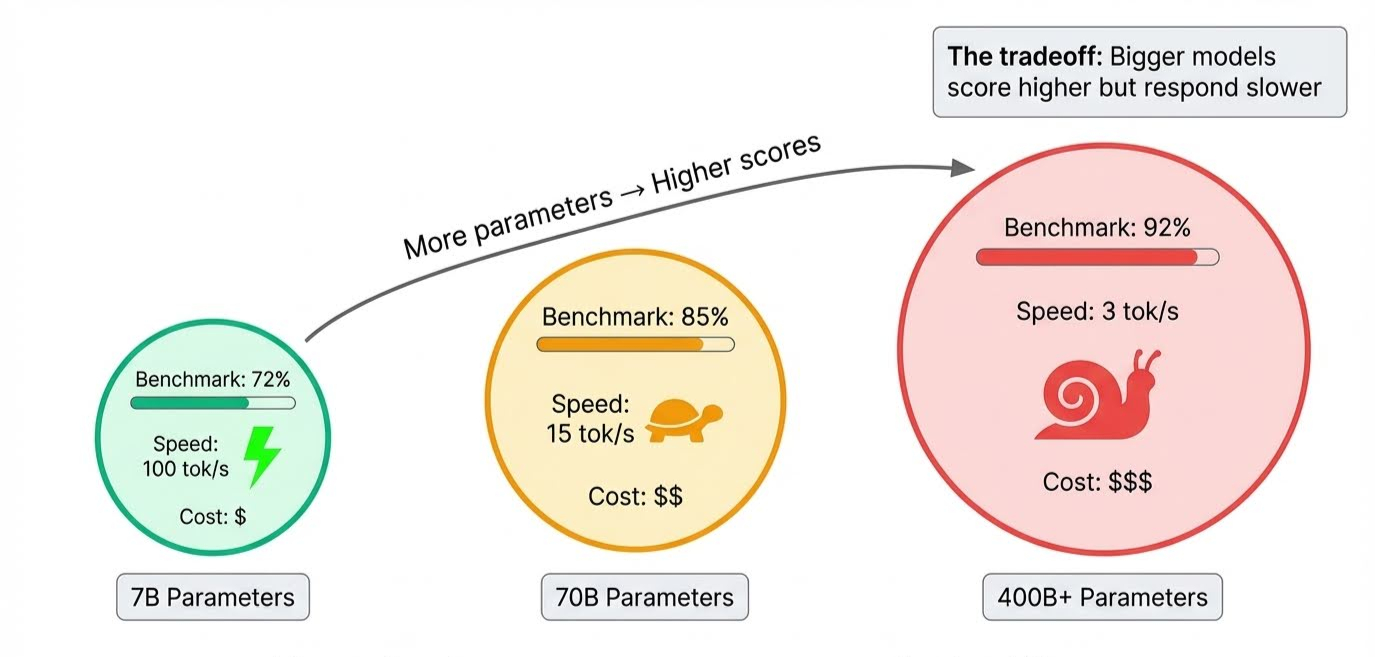
Die Modellgröße ist das Offensichtliche. Parameter speichern alles, was ein Modell lernt, und Frontier-Modelle haben Hunderte von Milliarden davon. Mehr Parameter bedeuten, dass das Modell komplexere Schlussfolgerungen ziehen und mehr Nuancen berücksichtigen kann, was die Punktzahlen in die Höhe treibt.
Der Kompromiss zeigt sich beim Inferenz, wenn das Modell tatsächlich Antworten generiert: Alle diese Parameter müssen nacheinander ausgelöst werden, sodass größere Modelle langsamer sind. Ein Modell kann zwar alle Benchmarks anführen, aber mehrere Sekunden für die Antwort brauchen.
Die Dauer der Ausbildung ist schwieriger. Jeder Durchlauf der Trainingsdaten wird als„ “ bezeichnet, also als „Durchlauf“ (epoch). Zu wenig, und das Modell hat nicht genug aufgenommen, um gut abzuschneiden. Wenn es zu viele sind, fängt es an, Beispiele auswendig zu lernen, anstatt Muster zu lernen, die man auf neue Fragen anwenden kann. Das ist Überanpassung, und Benchmark-Entwickler versuchen gezielt, das zu erkennen, indem sie Fragen einbauen, die das Modell während des Trainings nicht sehen konnte.
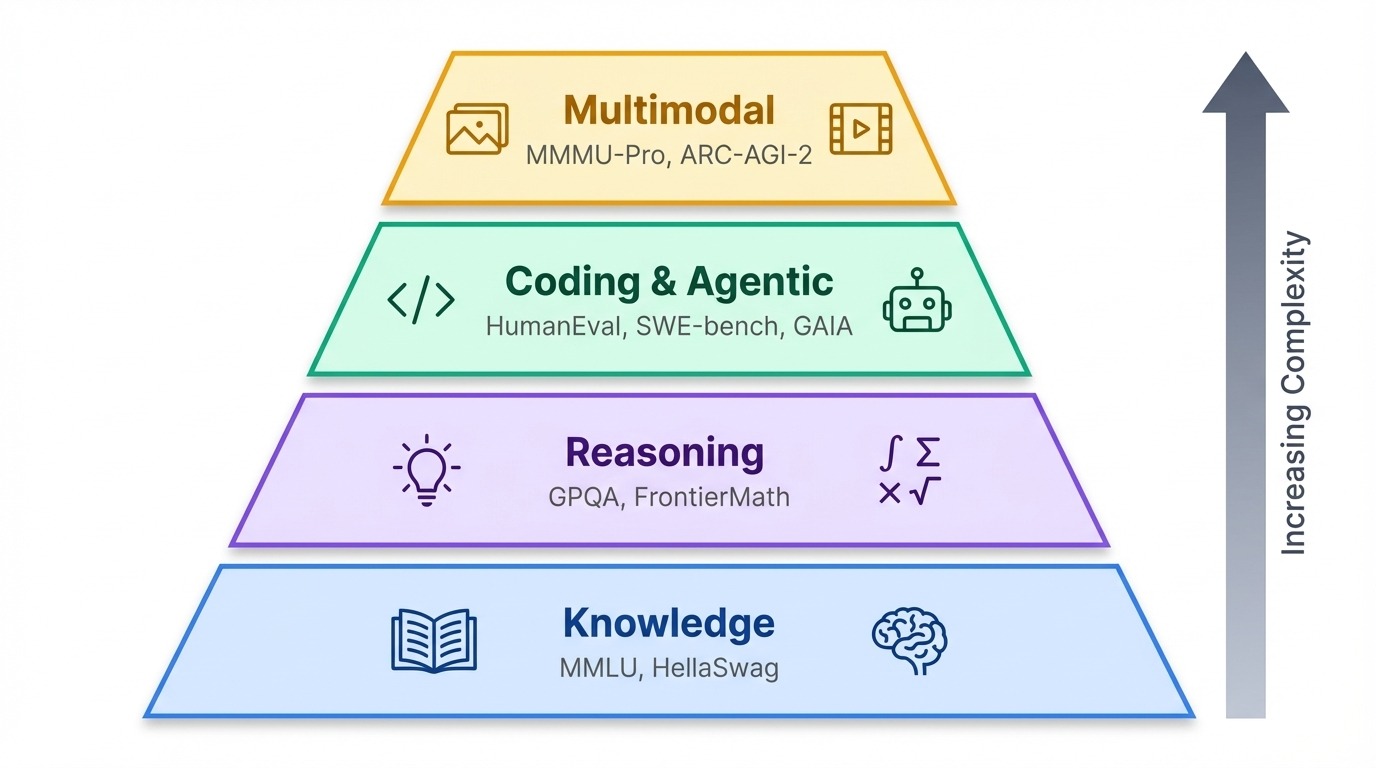
Bei den vielen Benchmarks, die heute verwendet werden, ist es hilfreich, sie nach dem zu gruppieren, was sie tatsächlich testen.
Benchmarks ordnen sich in eine grobe Rangfolge ein. Im Grunde checken Wissenstests, was ein Modell weiß. Außerdem checken Benchmarks, wie gut es denkt. Ganz oben stehen agentenbasierte und multimodale Tests, die prüfen, ob KI in der echten Welt agieren oder Infos über Text hinaus verarbeiten kann.
MMLU (Massive Multitask Language Understanding) deckt 57 akademische Fächer von der Oberstufe bis zum Profi-Level ab, von abstrakter Algebra bis hin zu Weltreligionen. Jahrelang war das der Standardtest für Allgemeinwissen, aber jetzt liegen die Modelle an der Spitze alle über 88 % und es ist echt schwer, sie auseinanderzuhalten.
Diese Sättigung hat die Forscher dazu gebracht, härtere Tests zu machen. GPQA (Graduate-level Google-Proof Q&A) stellt 448 Fragen aus den Bereichen Biologie, Physik und Chemie, die von Fachleuten so gestaltet wurden, dass sie nicht durchsuchbar sind.
Der Benchmark hat drei Schwierigkeitsstufen, wobei „Diamond“ die schwierigsten Fragen hat. Selbst mit unbegrenztem Internetzugang schaffen Nicht-Experten nur 34 % – das sind gerade mal 9 % mehr als das, was man bei vier Antwortmöglichkeiten durch reines Raten erwarten würde. Ab Dezember 2025 führt Gemini 3 Pro mit 92,6 % vor GPQA Diamond.
Der GDPval-Benchmark (, bewertet nach dem Bruttoinlandsprodukt) von OpenAI misst was anderes: die tatsächliche Arbeitsleistung. Es deckt 44 Berufe aus verschiedenen Branchen ab, die zusammen eine jährliche Wirtschaftsleistung von 3 Billionen Dollar machen. Dabei sollen die Modelle Ergebnisse wie juristische Schriftsätze, Präsentationen und technische Spezifikationen liefern, statt Multiple-Choice-Fragen zu beantworten. Das kürzlich veröffentlichte GPT-5.2 ist in dieser Hinsicht führend.
HellaSwag testet, wie gut Leute mit gesundem Menschenverstand umgehen können, indem es alltägliche Situationen zeigt und die Models bittet, den passendsten nächsten Satz auszuwählen. Jemand, der Abendessen macht, greift nach einer Pfanne. Was passiert als Nächstes?
Die falschen Antworten wurden extra geschrieben, um die KI zu verwirren: Sie benutzen Wörter, die statistisch zum Kontext passen, aber unmögliche Ergebnisse beschreiben (die Pfanne schwimmt davon, der Herd verwandelt sich in eine Katze). Wir Menschen kriegen 95,6 %, weil wir wissen, wie Küchen funktionieren. Modelle werden getäuscht, weil sie wahrscheinlichere Wörter vorhersagen, nicht wahrscheinlichere Ereignisse.
Die neuesten Benchmarks machen es noch schwieriger:
FrontierMath hat noch nie veröffentlichte Aufgaben von Forschungsmathematikern, bei denen selbst die besten Modelle unter 20 % liegen.
Die letzte Prüfung der Menschheit hat 2.500 Fragen auf Expertenniveau zusammengestellt, bei denen man nicht einfach raten kann.
MathArena nutzt Aufgaben aus 2025 Mathematikwettbewerben, um sicherzustellen, dass sich die Trainingsdaten nicht überschneiden.
HumanEval ist der klassische Codierungstest: Es gibt 164 Python-Aufgaben, bei denen Modelle Funktionen aus Docstrings schreiben und danach bewertet werden, ob der Code die Unit-Tests besteht. Die meisten aktuellen Frontier-Modelle erreichen Werte über 85 %, daher haben die Forscher schwierigere Varianten wie„ “ und „HumanEval+“ mit strengeren Testfällen entwickelt.
Der SWE-Benchmark () geht über einzelne Funktionen hinaus. Es legt Modelle in echten GitHub-Repositorys ab und bittet sie, echte Fehler zu beheben. Das Modell muss sich in der Codebasis zurechtfinden, das Problem verstehen und einen funktionierenden Patch erstellen.
SWE-bench Verified ist eine kleinere, sorgfältig zusammengestellte Untergruppe des ursprünglichen SWE-bench, die nach hochwertigen Aufgaben filtert, die von menschlichen Ingenieuren geprüft wurden. Im Dezember 2025 ist Claude Opus 4.5 das erste Modell, das bei SWE-bench Verified die 80-Prozent-Marke geknackt hat (80,9 %).
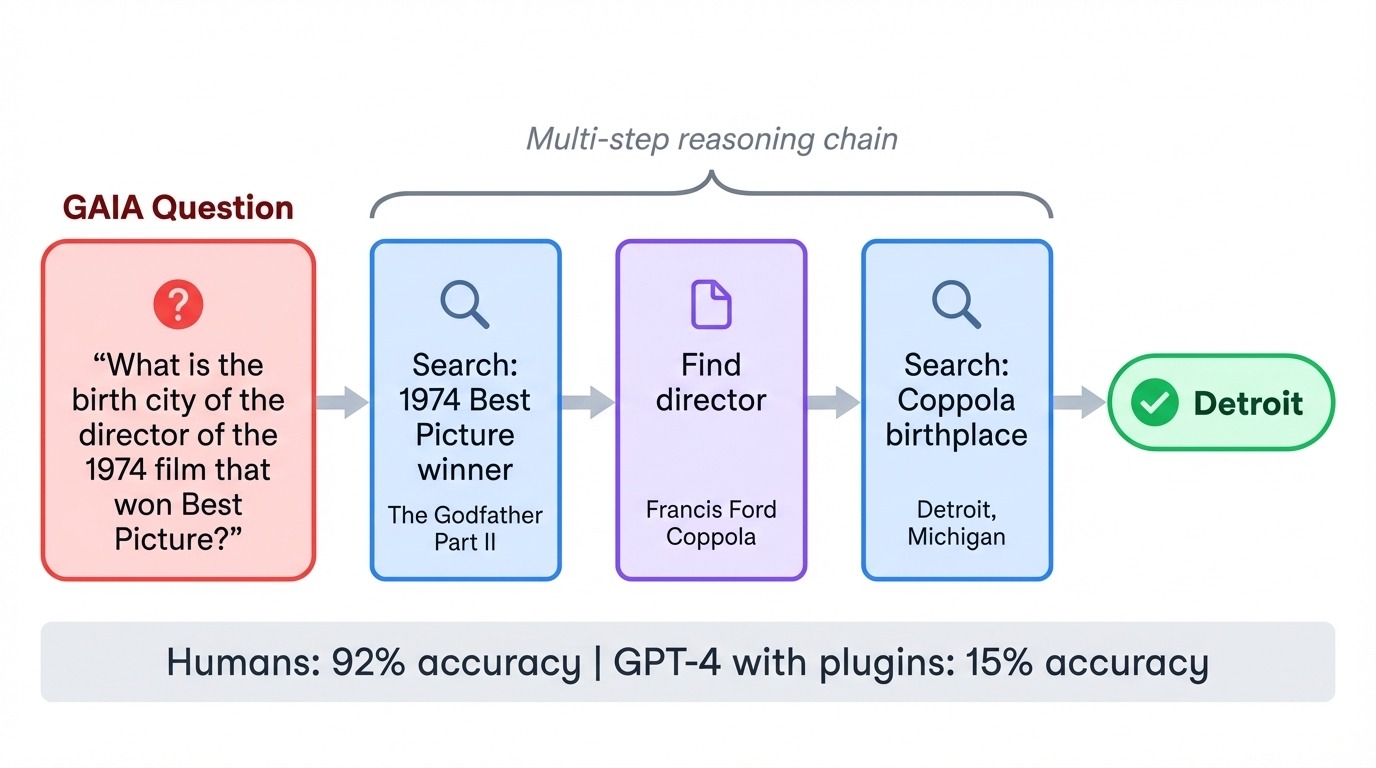
GAIA (, allgemeine KI-Assistenten) dreht die üblichen Schwierigkeiten um. Die 466 Aufgaben sind für Menschen echt einfach (92 % Genauigkeit), aber für KI echt hart. Als GPT-4 zum ersten Mal GAIA mit Plugins ausprobierte, hat es nur 15 % geschafft. Jede Aufgabe braucht mehrere Schritte: im Internet suchen, Dokumente lesen, Berechnungen machen und Antworten zusammenfassen.
Eine typische Frage könnte nach dem Geburtsort des Regisseurs eines bestimmten Films aus den 1970er Jahren fragen, wobei das Modell den Film identifizieren, den Regisseur finden und dann biografische Details nachschlagen muss. Der Benchmark testet, ob Modelle Tools koordinieren und mehrstufige Pläne umsetzen können, ohne den Lernpfad zu verlieren.
Schließlich setzt WebArena Modelle in selbst gehosteten Webumgebungen ein, wo sie Aufgaben wie Flugbuchungen, die Verwaltung von Content-Systemen und die Navigation auf E-Commerce-Websites erledigen müssen, indem sie mit echten Browser-Schnittstellen interagieren.
Nur-Text-Benchmarks verpassen eine wachsende Grenze. Der„ “-BenchmarkMMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning) testet das visuelle Schlussfolgern bei 30 Themen, indem Fragen direkt in Bilder eingebettet werden, sodass die Modelle gezwungen sind, visuelle Infos gleichzeitig zu lesen und zu interpretieren.
Der Benchmark filtert Fragen raus, die reine Textmodelle beantworten könnten, und stellt so sicher, dass das Sehen wirklich wichtig ist. Gemini 3 Pro liegt hier mit 81 % vorne.
Einige Benchmarks bringen das visuelle Denken auf die nächste Stufe.
MathVista kombiniert zum Beispiel visuelle Wahrnehmung mit mathematischem Denken. Zu den Problemen gehören das Verstehen von Funktionsgraphen, das Lesen von wissenschaftlichen Diagrammen und das Lösen von Geometrieaufgaben anhand von Diagrammen. Video-MMMU erweitert das auf das zeitliche Verständnis und checkt, ob Modelle über Kausalität und Abläufe über mehrere Videobilder hinweg nachdenken können, statt nur über einzelne Bilder.
ARC-AGI-2 ( ) ist immer noch der Maßstab, den die KI noch nicht geknackt hat. Jede Aufgabe zeigt ein paar Beispiele für Eingabe-Ausgabe-Gitter und verlangt vom Modell, die Transformationsregel zu ermitteln und sie dann auf eine neue Eingabe anzuwenden.
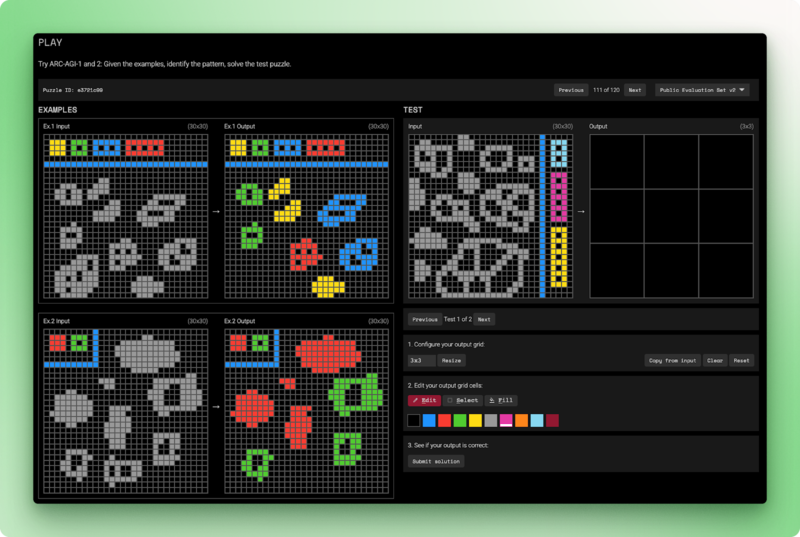
Menschen lösen diese Rätsel in weniger als zwei Versuchen. Reine Sprachmodelle kriegen 0 %. Die besten Hybridsysteme schaffen 54 %, und das kostet 30 Dollar pro Aufgabe. ARC-AGI-2 checkt die fluide Intelligenz: Es geht darum, von Grundprinzipien auszugehen, statt nur Muster zu erkennen, die man beim Training gesehen hat.
Benchmarks liefern Ergebnisse, aber Ranglisten entscheiden, wie diese präsentiert werden. Verschiedene Plattformen legen Wert auf unterschiedliche Sachen: menschliche Vorlieben, Transparenz bei Open Source oder mehrdimensionale Bewertung. Welches Leaderboard du dir anschauen solltest, hängt davon ab, was du messen willst.
Die LMArena (LMSYS Chatbot Arena) macht es anders als automatisierte Benchmarks. Anstatt Antworten anhand einer Rubrik zu bewerten, werden Menschen gebeten, die bessere Antwort auszuwählen. Die Nutzer geben eine Eingabe ein, kriegen Ergebnisse von zwei anonymen Modellen und stimmen für das, was ihnen besser gefällt. Die Modelle bleiben bis nach der Abstimmung geheim, damit die Wahl nicht durch Markenvorlieben beeinflusst wird.
Die Plattform nutzt ein statistisches Modell von Bradley-Terry, um über 5 Millionen paarweise abgegebene Stimmen in Ranglisten umzuwandeln. Im Dezember 2025 führt Gemini 3 Pro die Gesamtwertung der Arena mit 1501 Punkten an, gefolgt von Grok 4.1 mit 1483 Punkten, dann Claude Opus 4.5 und GPT-5.2.
Die LMArena fängt etwas ein, was Benchmarks übersehen: ob eine Antwort sich wirklich hilfreich anfühlt. Der Kompromiss ist, dass ausführliche, selbstbewusst klingende Antworten Stimmen gewinnen können, auch wenn es eine kürzere, genauere Antwort gibt.
Das Open LLM Leaderboard von Hugging Face konzentriert sich auf Open-Source-Modelle und testet sie mit standardisierten Tests, die den EleutherAI Evaluation Harness nutzen. Version 2 kam im Juni 2024 raus und hatte schwierigere Benchmarks, nachdem die Frontier-Modelle die ursprüngliche Testsuite voll ausgereizt hatten.
Der aktuelle Test umfasst GPQA, MATH Level 5 und MMLU-PRO mit einer normierten Bewertung, bei der 0 eine zufällige Leistung und 100 eine perfekte Leistung bedeutet. Zu den besten Open-Source-Modellen gehören Qwen3, Llama 3.3 70B und DeepSeek V3.1, die alle mit den führenden Closed-Source-Modellen mithalten können.
Stanford HELM (Holistic Evaluation of Language Models) schaut nicht nur, ob die Ergebnisse der Modelle richtig sind. Jedes Modell wird pro Szenario anhand von sieben Kriterien bewertet: Genauigkeit, Kalibrierung, Robustheit, Fairness, Voreingenommenheit, Toxizität und Effizienz.
Das Rahmenwerk deckt 42 Szenarien ab und zeigt genau, wo Modelle versagen, nicht nur, wo sie funktionieren. HELM hat auch eine eigene Sicherheitsrangliste, die Risiken wie Gewalt, Betrug und Belästigung bewertet. Im Dezember 2025 hat Claude 3.5 Sonnet die besten Gesamt-Sicherheitswerte.
Kein Unternehmen kann überall gewinnen. Sobald du aber ein paar Ranglisten miteinander vergleichst, fallen dir Muster auf.
Die Gemini-Modelle von Google sind echt gut bei multimodalen Benchmarks und wissenschaftlichem Denken. Gemini 3 Pro führt GPQA Diamond mit 91,9 % an und steht in der Arena insgesamt an erster Stelle. Die Claude-Reihe von Anthropic ist echt gut in Sachen Programmierung und Sicherheit. Claude Opus 4.5 hat mit 80,9 % den SWE-Bench-Verified-Rekord und Claude 3.5 Sonnet führt bei HELM Safety.
Die GPT-Modelle von OpenAI sind nach wie vor starke Allrounder, die in den meisten Benchmarks gut abschneiden und keine besonderen Schwächen haben. Die Llama-Serie von Meta zeigt, dass Open Source bei vielen Aufgaben mit geschlossenen Modellen mithalten kann, mit Llama 3.3 70B konkurriert mit den Ergebnissen von viel größeren proprietären Systemen.
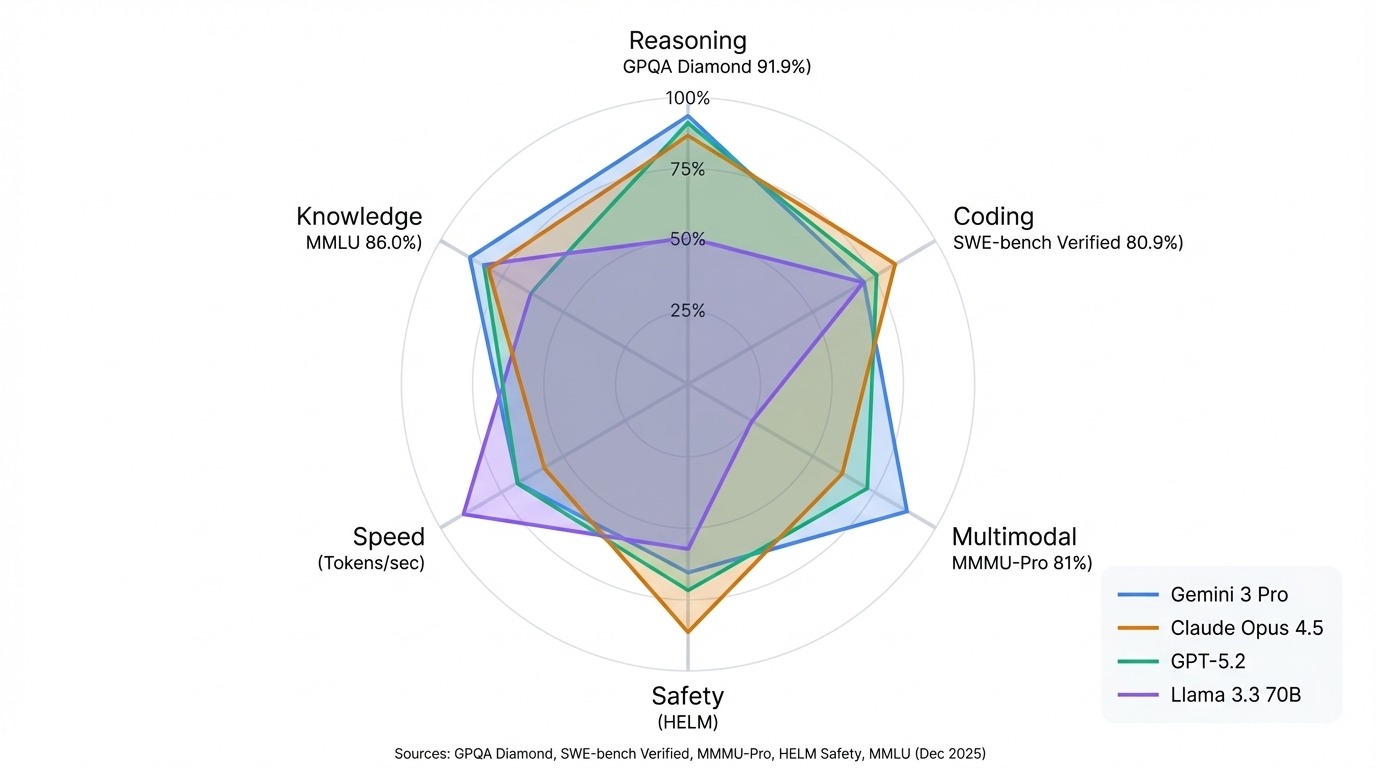
Das wichtigste Muster: Pass die Rangliste an deinen Anwendungsfall an. Die Arena-Rangliste zeigt, wie gut die Unterhaltungen sind. Die HELM-Werte zeigen Zuverlässigkeit und Sicherheit. Hugging Face zeigt dir, was du selbst machen kannst. Ein Modell, das in einer Liste ganz oben steht, kann in einer anderen Liste nur im Mittelfeld landen, und das ist kein Fehler in der Rangliste. Es sind verschiedene Tests, die unterschiedliche Sachen messen.
Ranglisten zeigen dir, wie Modelle in Standardtests abschneiden, aber manchmal brauchst du Antworten, die genau auf deine Situation zugeschnitten sind.
Vielleicht suchst du zwischen Open-Source-Modellen für deine Hardware oder checkst, ob ein fein abgestimmtes Modell seine allgemeine Denkfähigkeit behalten hat. In anderen Fällen decken die Standard-Benchmarks deinen Bereich einfach nicht ab.
In all diesen Fällen solltest du vielleicht mal überlegen, LLMs selbst zu benchmarken. Ich zeig dir, wie's geht und was du dabei beachten musst.
Der EleutherAI LM Evaluation Harness ist der Standard in der Branche, um diese Bewertungen lokal durchzuführen. Es treibt das Hugging Face Open LLM Leaderboard an und unterstützt über 60 Benchmarks.
Es funktioniert anders, als die meisten Leute mit Chatbots umgehen. Es unterhält sich nicht einfach mit dem Modell, sondern macht eine genauere mathematische Analyse.
Bei Multiple-Choice-Fragen, die bei Benchmarks wie MMLU oder ARC oft vorkommen, verlangt das Testprogramm nicht, dass das Modell „A”, „B”, „C” oder „D” ausgibt. Stattdessen macht es für jede Option eigene Eingabeaufforderungen und fragt das Modell, wie wahrscheinlich jede davon ist. Die Option mit der höchsten log-Wahrscheinlichkeit wird dann als Modellauswahl genommen.
Andere Benchmarks brauchen einen generativen Ansatz, bei dem das Modell eine Volltextantwort gibt, anstatt eine Wahrscheinlichkeit auszuwählen. Sobald die Generierung fertig ist, schaut sich das Programm die Ausgabe mit regulären Ausdrücken (regex) an und holt sich den Wert raus, den es braucht, um ihn mit dem Lösungsschlüssel zu vergleichen.
Schauen wir mal, wie du deine erste LLM-Bewertung durchführst.
Du kannst das Evaluierungs-Harness mit „ pip “ installieren:
pip install lm-evalBevor du eine vollständige Auswertung machst, probier die Pipeline erst mal mit einer kleinen Probe aus. Das Flag „ --limit “ begrenzt den Benchmark auf eine bestimmte Anzahl von Beispielen. Dieses Beispiel testet Qwen2.5-1.5B-Instruct, ein kleines Modell, das auf den meisten Geräten läuft, ohne dass man eine High-End-GPU braucht, und zwar mit dem HellaSwag-Benchmark:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Aufgaben |
Version |
Filter |
n-Schuss |
Metrisch |
|
Wert |
|
Stderr |
|
hellaswag |
1 |
keine |
0 |
acc |
↑ |
0,3 |
± |
0,1528 |
|
keine |
0 |
acc_norm |
↑ |
0,4 |
± |
0,1633 |
Die Ausgabe zeigt zwei Genauigkeitsmetriken: „ acc “ ist die Rohgenauigkeit, während „ acc_norm “ die Verzerrung des Modells in Richtung kürzerer oder längerer Vervollständigungen anpasst. Außerdem wird der Standardfehler angegeben, der mit zunehmender Stichprobengröße kleiner wird. Stderr In unserem ersten Test mit nur 10 Proben zeigt der hohe Korrelationskoeffizient (0,15), dass diese Werte nur grobe Schätzungen sind.
Entferne „ --limit “, um den kompletten Benchmark durchzuführen. Wenn du mehrere Benchmarks in einem Durchgang machen willst, schreib sie einfach mit Kommas dazwischen auf:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsStell „ --device “ entsprechend deiner Hardware ein: „ mps “ für Apple Silicon, „ cuda:0 “ für NVIDIA-GPUs oder „ cpu “ als Fallback. Die komplette MMLU dauert auf einer modernen GPU 1–2 Stunden; kleinere Benchmarks wie HellaSwag sind in wenigen Minuten fertig.
Für Latenz- und Durchsatztests Ollama Modelle lokal und gibt die Anzahl der Token pro Sekunde für verschiedene Quantisierungsstufen an. Ein 7B-Modell kann auf einem V100 über 100 Token pro Sekunde machen, während ein 70B-Modell nur noch einstellige Werte schafft.
Beim Benchmarking eines LLM solltest du ein paar bewährte Vorgehensweisen beachten.
Als Erstes und Wichtigstes musst du sicherstellen, dass das Modell die Bewertungsfragen während des Trainings nicht gesehen hat. Wenn ja, misst du nur die Überanpassung und nicht die Fähigkeit des Modells, Schlussfolgerungen zu ziehen, wie am Anfang besprochen. In diesem Fall würden die Benchmark-Ergebnisse sinnlos werden.
Um Ergebnisse zu kriegen, die man wiederholen kann, sollte man die Schwankungen in den Antworten des Modells so gering wie möglich halten. Das kann man machen, indem man die Temperatur auf Null stellt, um Genauigkeit vor Kreativität zu bevorzugen.
Der Harness hat standardisierte Few-Shot-Prompts für jeden Benchmark. Benutz sie, anstatt deine eigenen Eingabeaufforderungen zu schreiben, weil kleine Änderungen im Wortlaut die Ergebnisse stärker beeinflussen als erwartet. Für domänenspezifische Aufgaben solltest du aber immer erst mal ein kleines Testset aus echten Beispielen aus deinem Bereich zusammenstellen, bevor du dich für ein Modell für die Produktion entscheidest.
Standard-Benchmarks sind super, um Fakten zu checken, haben aber Probleme, Nuancen zu messen. Bei offenen Aufgaben wie Zusammenfassungen oder kreativem Schreiben nutzt LLM-as-a-judge ein stärkeres Modell, um die Ergebnisse nach Nützlichkeit und Genauigkeit zu bewerten.
Der Richter kriegt normalerweise eine Bewertungsrubrik und soll entweder eine Punktzahl (z. B. 1–10) vergeben oder einen paarweisen Vergleich machen, um zu entscheiden, welche von zwei Antworten besser ist. Auch wenn sie nicht perfekt sind, stimmen diese Einschätzungen in etwa 80 bis 85 % der Fälle mit den menschlichen Vorlieben überein. Deshalb ist LLM-as-a-judge eine gute Alternative zu teuren menschlichen Überprüfungen.
Die Bewertung von KI entwickelt sich genauso schnell weiter wie die Modelle selbst. Da Benchmarks wie MMLU an ihre Grenzen stoßen, entwickeln Forscher anspruchsvollere Tests, die eher die Tiefe des logischen Denkens als das auswendig gelernte Wissen prüfen. FrontierMath und Humanity's Last Exam zeigen diese neue Schwierigkeitsgrenze, wo selbst die besten Modelle Probleme haben.
Die allgemeinen Anzeichen zeigen in eine Richtung: mehr Rechenleistung für das Training, intelligentere Algorithmen und Benchmark-Suiten, die mit dem Fortschritt mithalten können. Multimodale Tests erweitern die Aufgaben, die wir Modellen stellen, vom Lesen von Diagrammen bis zum Verstehen von Videosequenzen.
Aber das Fazit bleibt einfach. Keine einzelne Punktzahl sagt alles aus. Ein Model, das die Arena anführt, könnte auf der SWE-Bank zurückbleiben. Das Top-Codierungsmodell könnte in Sachen Sicherheit im Mittelfeld landen. Pass den Maßstab an das an, was du wirklich brauchst: Argumentation, Codegenerierung, visuelles Verständnis oder reine Geschwindigkeit. Das ist der einzige Vergleich, der zählt.
Um deine Fähigkeiten über das Benchmarking hinaus zu erweitern, lerne mit unserem Kurs selbst, wie man LLMs erstellt und optimiert. Entwicklung großer Sprachmodelle Lernpfad
LLM-Kurse
Lernpfad
Lernpfad
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Zoumana Keita
15 Min.
Blog
Matt Crabtree
14 Min.
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo