
Programma
Nozioni di base sull'intelligenza artificiale
10 h
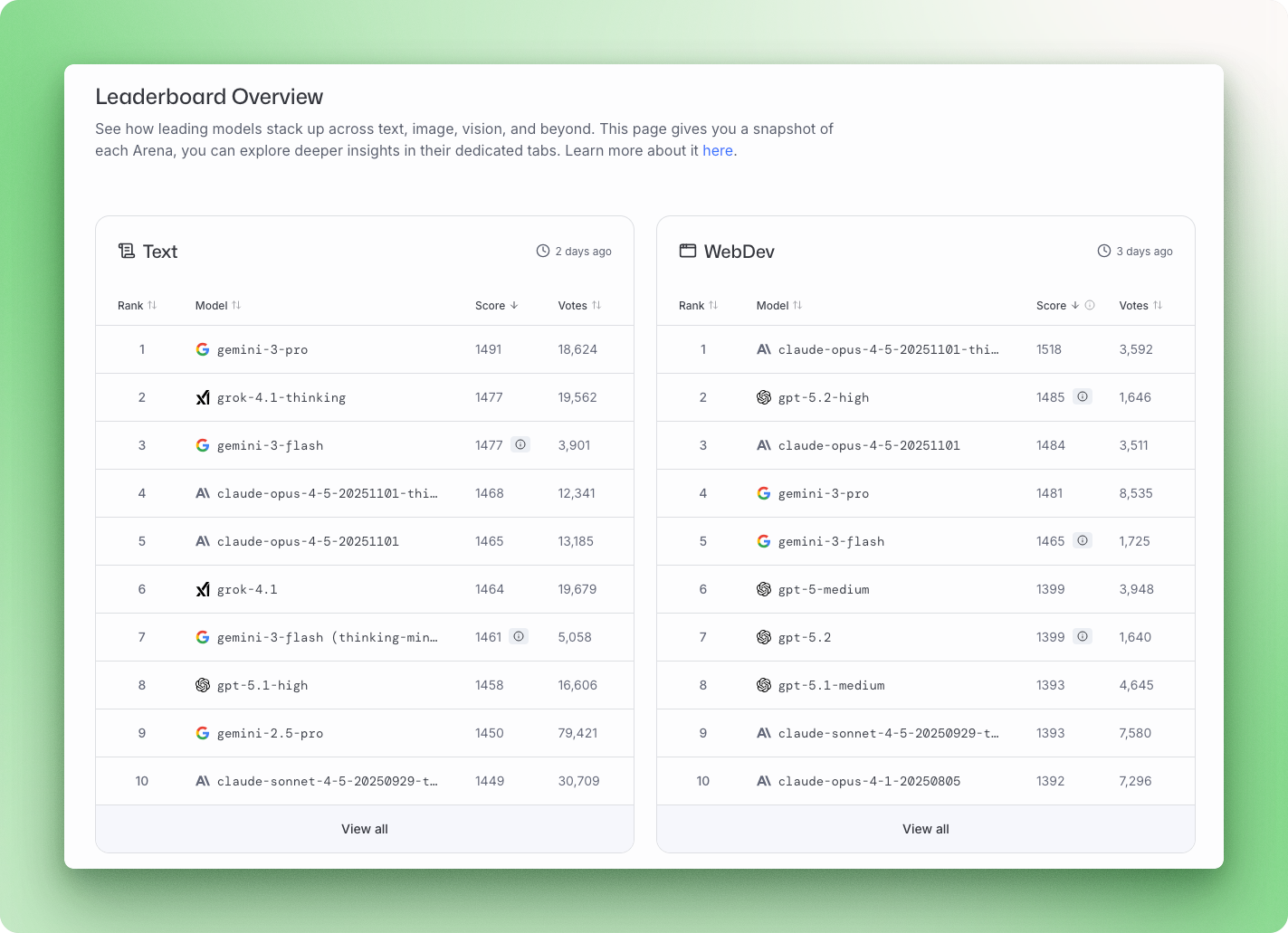
Nuovi modelli di AI escono quasi ogni settimana: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Ogni release arriva con punteggi di benchmark e affermazioni su chi sia il migliore in qualcosa. Il problema: quasi nessuno sa cosa significhino quei numeri o come confrontarli.
I benchmark per Large Language Model (LLM) sono test standardizzati che misurano quanto bene i modelli svolgono compiti specifici, dai quiz di conoscenza generale a sfide di coding complesse e problemi di ragionamento multi-step. Capire cosa misura ciascun benchmark ti aiuta a tagliare il marketing e scegliere il modello giusto per le tue reali esigenze.
Questa guida scompone le principali categorie di benchmark, spiega dove trovare le classifiche aggiornate e ti mostra come eseguire le tue valutazioni. Alla fine, saprai leggere una leaderboard e scegliere l'AI che si adatta al tuo caso d'uso.
Per approfondire come funzionano gli LLM sotto il cofano, dai un'occhiata al nostro corso LLMs Concepts.
Un benchmark LLM è un test standardizzato che misura quanto bene un modello linguistico gestisce un determinato tipo di compito. Le stesse domande e lo stesso criterio di valutazione vengono applicati a ogni modello che sostiene il test.
I numeri nei comunicati sui modelli provengono da una manciata di test popolari. Ogni punteggio racconta una storia diversa e nessun benchmark singolo cattura l'intero quadro.
I benchmark sono importanti per tre ragioni:
Confrontare i modelli: Quando OpenAI rilascia GPT-5.2 e Anthropic pubblica Claude Opus 4.5 nello stesso mese, i benchmark ci danno un terreno comune. Altrimenti, restiamo bloccati con ogni azienda che rivendica la vittoria basandosi su esempi selezionati ad arte.
Monitorare i progressi: Esegui lo stesso benchmark nel tempo e puoi vedere se i modelli stanno davvero migliorando. I punteggi MMLU sono passati dal 70% nel 2022 a oltre il 90% nel 2025.
Individuare le lacune: Un modello può dominare le domande di conoscenza generale ma incepparsi sulla matematica multi-step. I benchmark fanno emergere queste debolezze.
I punteggi dei benchmark riflettono più dell'intelligenza grezza. Diversi fattori plasmano i numeri che vedi nelle classifiche.
La dimensione del modello è quella ovvia. I parametri memorizzano tutto ciò che un modello apprende, e i modelli all'avanguardia ne contengono centinaia di miliardi. Più parametri significano capacità di gestire ragionamenti più complessi e maggiore finezza, il che fa salire i punteggi.
Il compromesso emerge in inference, quando il modello genera le risposte: tutti quei parametri devono attivarsi in sequenza, quindi i modelli più grandi sono più lenti. Un modello può primeggiare in ogni benchmark ma impiegare diversi secondi per rispondere.
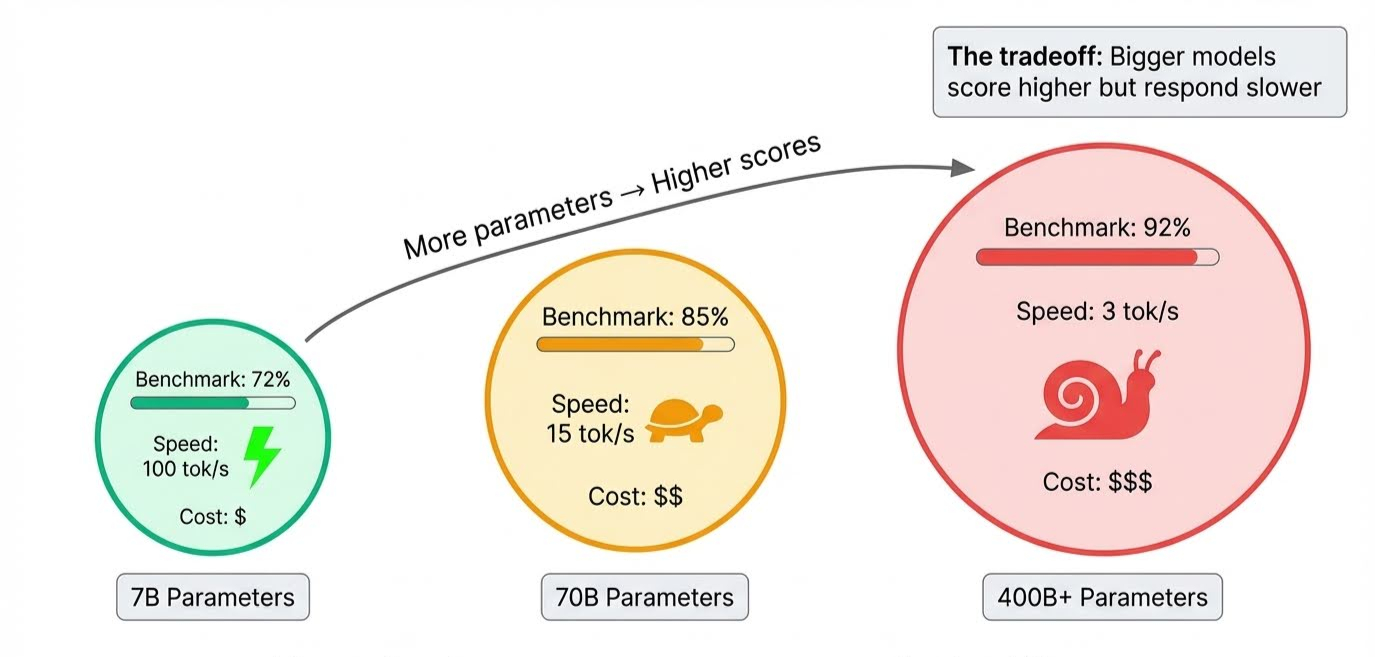
La durata dell'addestramento è più insidiosa. Ogni passaggio sui dati di training si chiama epoca (epoch). Se sono troppo poche, il modello non ha assimilato abbastanza per ottenere buoni punteggi. Se sono troppe, inizia a memorizzare esempi invece di apprendere schemi che si trasferiscono a nuove domande. Questo è l'overfitting, e i designer dei benchmark cercano specificamente di intercettarlo includendo domande che il modello non potrebbe aver visto durante l'addestramento.
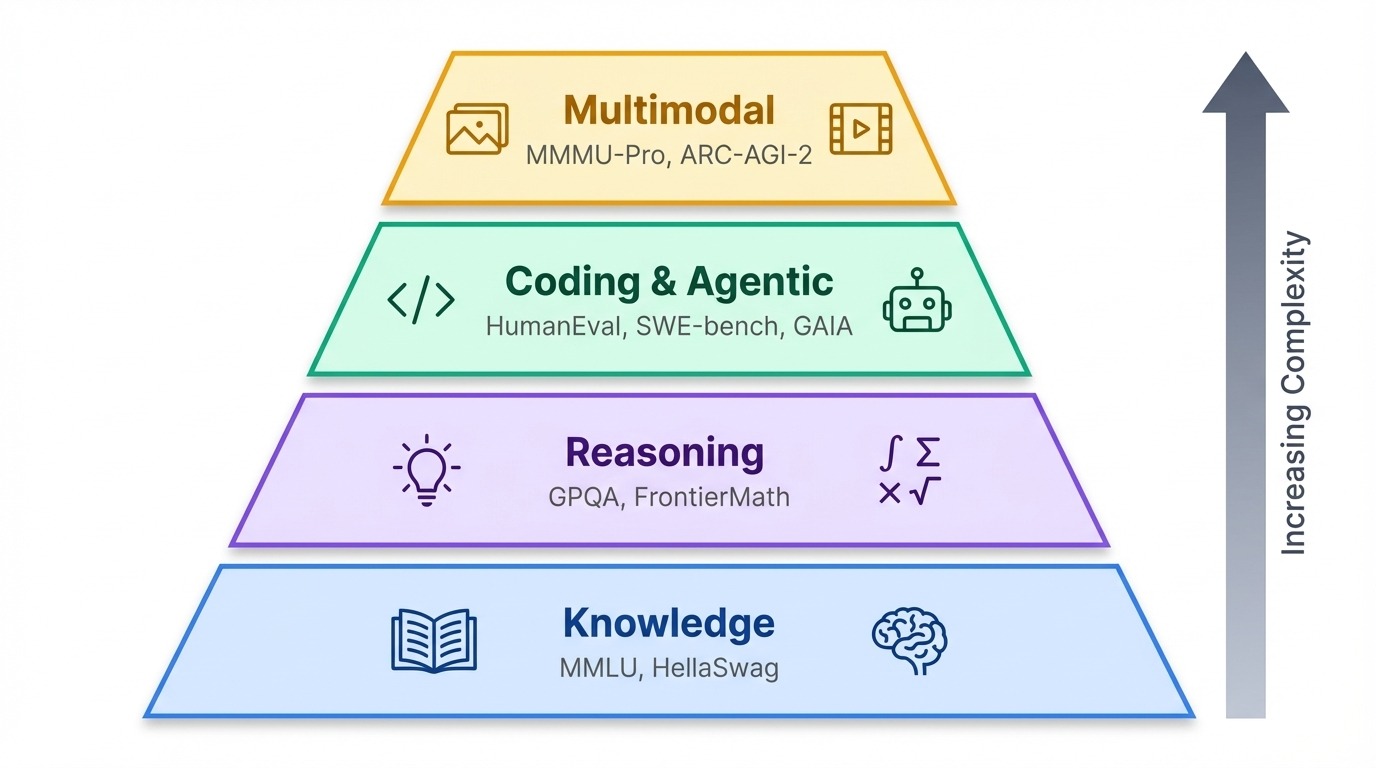
Con dozzine di benchmark in uso oggi, aiuta raggrupparli in base a ciò che testano davvero.
I benchmark si raggruppano in una gerarchia approssimativa. Alla base, i test di conoscenza verificano cosa sa un modello. Più in alto, i benchmark di ragionamento indagano quanto bene pensa. In cima ci sono test agentici e multimodali che misurano se l'AI può agire nel mondo reale o elaborare informazioni oltre il testo.
MMLU (Massive Multitask Language Understanding) copre 57 materie accademiche dal liceo al livello professionale, spaziando dall'algebra astratta alle religioni del mondo. Per anni è stato il test di riferimento per la conoscenza generale, ma i modelli all'avanguardia ora si raggruppano oltre l'88%, lasciando poco margine per distinguerli.
Quella saturazione ha spinto i ricercatori verso test più difficili. GPQA (Graduate-level Google-Proof Q&A) pone 448 domande in biologia, fisica e chimica progettate da esperti di dominio per essere non ricercabili.
Il benchmark ha tre livelli di difficoltà, con Diamond che contiene le domande più dure. Anche con accesso illimitato al web, i non esperti ottengono solo il 34%—appena il 9% in più rispetto al risultato atteso da una scelta casuale con quattro opzioni di risposta. A dicembre 2025, Gemini 3 Pro guida GPQA Diamond con il 92,6%.
Il benchmark GDPval (Gross Domestic Product-valued) di OpenAI misura qualcosa di diverso: la produzione di lavoro nel mondo reale. Copre 44 professioni in settori che valgono 3.000 miliardi di dollari di attività economica annua, chiedendo ai modelli di produrre deliverable come pareri legali, slide deck e specifiche ingegneristiche anziché rispondere a domande a scelta multipla. Il recente GPT-5.2 è il leader in questo ambito.
HellaSwag indaga il ragionamento di buon senso presentando scenari quotidiani e chiedendo ai modelli di scegliere la frase successiva più plausibile. Una persona che cucina la cena prende una padella. Cosa succede dopo?
Le risposte errate sono state scritte appositamente per ingannare l'AI: usano parole che si adattano statisticamente al contesto ma descrivono esiti impossibili (la padella vola via, la cucina si trasforma in un gatto). Gli umani ottengono il 95,6% perché sappiamo come funziona una cucina. I modelli si fanno ingannare perché prevedono parole probabili, non eventi probabili.
I benchmark più nuovi spingono ancora di più la difficoltà:
FrontierMath propone problemi inediti di matematici di ricerca, dove anche i migliori modelli stanno sotto il 20%.
Humanity's Last Exam raccoglie 2.500 domande di livello esperto progettate per resistere ai tentativi di indovinare.
MathArena prende problemi da competizioni di matematica del 2025 per garantire zero sovrapposizioni con i dati di training.
HumanEval è il classico test di coding: contiene 164 problemi Python in cui i modelli scrivono funzioni partendo dai docstring e vengono valutati in base al superamento dei test unitari. La maggior parte dei modelli all'avanguardia attuali supera l'85%, quindi i ricercatori hanno creato varianti più difficili come HumanEval+ con casi di test più rigorosi.
SWE-bench (Software Engineering Benchmark) va oltre le funzioni isolate. Inserisce i modelli in repository GitHub reali e chiede loro di correggere bug reali. Il modello deve navigare nel codebase, capire il problema e produrre una patch funzionante.
SWE-bench Verified è un sottoinsieme più piccolo e altamente curato dell'originale SWE-bench, che filtra compiti di alta qualità verificati da ingegneri umani. A dicembre 2025, Claude Opus 4.5 è il primo modello a superare l'80% in SWE-bench Verified (80,9%).
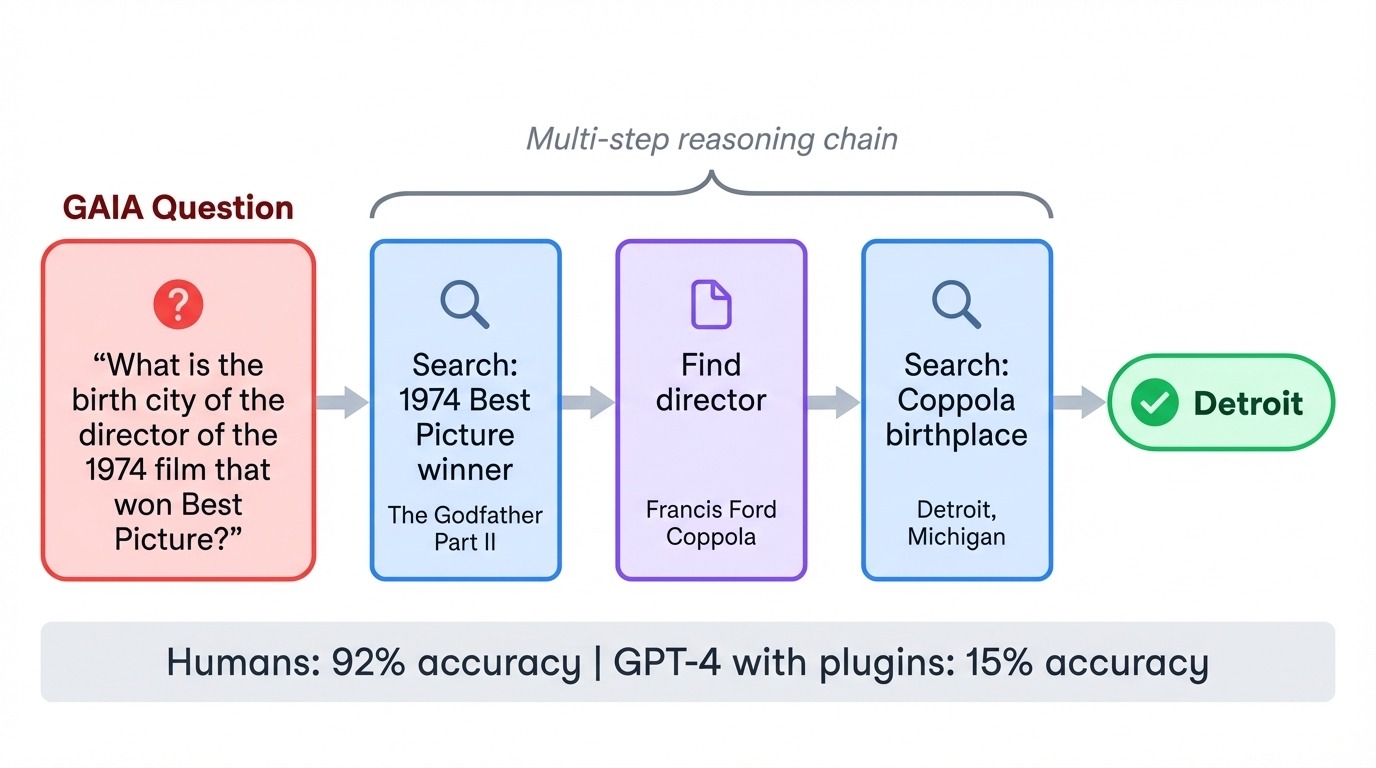
GAIA (General AI Assistants) inverte il solito rapporto di difficoltà. I suoi 466 compiti sono banali per gli umani (92% di accuratezza) ma durissimi per l'AI. Quando GPT-4 ha affrontato per la prima volta GAIA con i plugin, ha ottenuto solo il 15%. Ogni compito richiede di concatenare più passaggi: cercare sul web, leggere documenti, fare calcoli e sintetizzare risposte.
Una domanda tipica potrebbe chiedere la città di nascita del regista di un particolare film degli anni '70, richiedendo al modello di identificare il film, trovare il regista e poi cercare i dettagli biografici. Il benchmark testa se i modelli sanno coordinare strumenti ed eseguire piani multi-step senza perdere il filo.
Infine, WebArena schiera i modelli in ambienti web self-hosted dove devono completare attività come prenotare voli, gestire sistemi di contenuti e navigare siti e-commerce interagendo con interfacce browser reali.
I benchmark solo testo mancano un fronte in crescita. Il benchmark MMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning) testa il ragionamento visivo su 30 materie incorporando le domande direttamente nelle immagini, costringendo i modelli a leggere e interpretare informazioni visive contemporaneamente.
Il benchmark filtra le domande a cui i modelli solo testo potrebbero rispondere, garantendo che la visione conti davvero. Qui guida Gemini 3 Pro con l'81%.
Alcuni benchmark portano il ragionamento visivo al livello successivo.
MathVista, per esempio, combina percezione visiva e ragionamento matematico. I problemi includono l'interpretazione di grafici di funzioni, la lettura di chart scientifici e la risoluzione di geometria da diagrammi. Video-MMMU estende questo alla comprensione temporale, testando se i modelli sanno ragionare su causalità e sequenze attraverso fotogrammi video anziché singole immagini.
ARC-AGI-2 rimane il benchmark che l'AI non ha ancora superato. Ogni compito presenta alcuni esempi input-output a griglia e chiede al modello di inferire la regola di trasformazione, poi applicarla a un nuovo input.
Gli umani risolvono questi puzzle in meno di due tentativi. I modelli puramente linguistici ottengono 0%. I migliori sistemi ibridi arrivano al 54%, e a un costo di 30 dollari per compito. ARC-AGI-2 testa l'intelligenza fluida: ragionare dai primi principi invece di abbinare schemi visti durante l'addestramento.
I benchmark generano punteggi, ma le leaderboard decidono come presentarli. Piattaforme diverse danno priorità a fattori diversi: preferenze umane, trasparenza open-source o valutazioni multidimensionali. Sapere quale leaderboard consultare dipende da cosa ti interessa misurare.
La LMArena (LMSYS Chatbot Arena) adotta un approccio diverso rispetto ai benchmark automatizzati. Invece di valutare le risposte con un criterio, chiede alle persone di scegliere la risposta migliore. Gli utenti inviano un prompt, ricevono output da due modelli anonimi e votano quello che preferiscono. I modelli restano nascosti fino dopo il voto, prevenendo bias di marca.
La piattaforma usa un modello statistico Bradley-Terry per convertire oltre 5 milioni di voti a coppie in classifiche. A dicembre 2025, Gemini 3 Pro guida l'Arena complessiva con un punteggio di 1501, seguito da Grok 4.1 a 1483, poi Claude Opus 4.5 e GPT-5.2.
La LMArena cattura qualcosa che i benchmark non colgono: se una risposta sembra davvero utile. Il rovescio della medaglia è che risposte verbose e sicure di sé possono vincere voti anche quando esiste una risposta più breve e accurata.
La Open LLM Leaderboard di Hugging Face si concentra sui modelli open-source e li sottopone a test standardizzati usando l'EleutherAI Evaluation Harness. La versione 2 è stata lanciata a giugno 2024 con benchmark più difficili, dopo che i modelli all'avanguardia avevano saturato la suite originale.
La batteria attuale include GPQA, MATH Livello 5 e MMLU-PRO, con punteggi normalizzati dove 0 significa performance casuale e 100 perfetta. Tra i migliori modelli open figurano Qwen3, Llama 3.3 70B e DeepSeek V3.1, tutti in competizione a ridosso dei leader closed-source.
Stanford HELM (Holistic Evaluation of Language Models) misura più del semplice fatto che i risultati dei modelli siano accurati. Ogni modello viene valutato su sette dimensioni per scenario: accuratezza, calibrazione, robustezza, correttezza, bias, tossicità ed efficienza.
Il framework copre 42 scenari e traccia esplicitamente dove i modelli falliscono, non solo dove riescono. HELM gestisce anche una leaderboard separata per la sicurezza, valutando rischi come violenza, frode e molestie. A dicembre 2025, Claude 3.5 Sonnet è al primo posto per punteggi di sicurezza aggregati.
Nessuna singola azienda vince ovunque. Tuttavia, non appena incroci poche leaderboard, iniziano a emergere schemi.
I modelli Gemini di Google dominano i benchmark multimodali e il ragionamento scientifico. Gemini 3 Pro guida GPQA Diamond al 91,9% ed è in cima all'Arena complessiva. La linea Claude di Anthropic eccelle nel coding e nella sicurezza. Claude Opus 4.5 detiene il record di SWE-bench Verified all'80,9% e Claude 3.5 Sonnet guida HELM Safety.
I modelli GPT di OpenAI restano forti generalisti, competitivi nella maggior parte dei benchmark senza un singolo punto di debolezza evidente. La serie Llama di Meta dimostra che l'open-source può eguagliare i modelli closed in molti compiti, con Llama 3.3 70B che rivaleggia con output di sistemi proprietari molto più grandi.
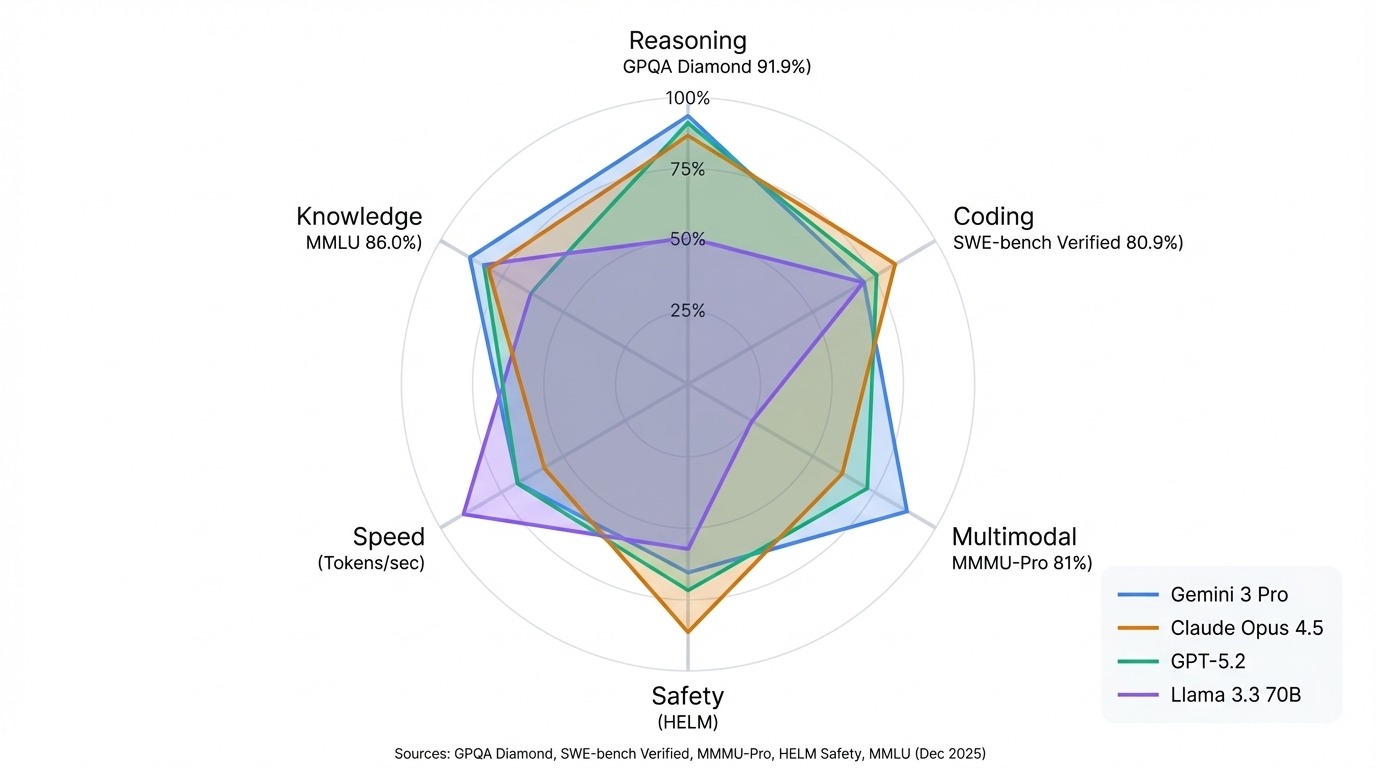
Il pattern che conta di più: abbina la leaderboard al tuo caso d'uso. Le classifiche dell'Arena riflettono la qualità conversazionale. I punteggi HELM mostrano affidabilità e sicurezza. Hugging Face tiene traccia di ciò che puoi eseguire in autonomia. Un modello in cima a una lista può essere a metà classifica in un'altra, e non è un difetto delle classifiche. Sono test diversi che misurano cose diverse.
Le leaderboard ti dicono come i modelli si confrontano su test standard, ma a volte ti servono risposte specifiche per la tua situazione.
Potresti dover scegliere tra modelli open-source per il tuo hardware, o verificare che un modello fine-tuned non abbia perso capacità di ragionamento generale. In altri casi, i benchmark standard semplicemente non coprono il tuo dominio.
In tutti questi casi, potresti voler considerare di fare benchmark degli LLM in autonomia. Ti mostrerò come farlo e cosa tenere a mente.
L' EleutherAI LM Evaluation Harness è lo standard del settore per eseguire queste valutazioni in locale. Alimenta la Open LLM Leaderboard di Hugging Face e supporta oltre 60 benchmark.
Funziona in modo diverso da come la maggior parte delle persone interagisce con i chatbot. Non si limita a "chattare" con il modello; esegue un'analisi matematica più deterministica.
Per le domande a scelta multipla, che sono un metodo comune in benchmark come MMLU o ARC, l'harness non chiede al modello di restituire "A", "B", "C" o "D". Invece, costruisce prompt separati per ogni singola opzione e chiede al modello quanto è probabile ciascuna di esse. L'opzione con la maggiore log-verosimiglianza viene quindi presa come scelta del modello.
Altri benchmark richiedono un approccio generativo, in cui il modello produce una risposta in testo pieno anziché selezionare una probabilità. Una volta completata la generazione, l'harness analizza l'output usando espressioni regolari (regex), estraendo il valore specifico necessario per verificarlo rispetto alla soluzione.
Vediamo come eseguire la tua prima valutazione LLM.
Puoi installare l'evaluation harness usando pip:
pip install lm-evalPrima di eseguire una valutazione completa, testa la pipeline con un piccolo campione. Il flag --limit limita il benchmark a un numero specificato di esempi. Questo esempio testa Qwen2.5-1.5B-Instruct, un modello piccolo che gira sulla maggior parte dell'hardware senza richiedere una GPU di fascia alta, usando il benchmark HellaSwag:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Tasks |
Version |
Filter |
n-shot |
Metric |
|
Value |
|
Stderr |
|
hellaswag |
1 |
none |
0 |
acc |
↑ |
0.3 |
± |
0.1528 |
|
none |
0 |
acc_norm |
↑ |
0.4 |
± |
0.1633 |
L'output mostra due metriche di accuratezza: acc è l'accuratezza grezza, mentre acc_norm corregge la tendenza del modello verso completamenti più brevi o più lunghi. Inoltre viene riportato l'errore standard, che si riduce all'aumentare della dimensione del campione. Nel nostro primo test con soli 10 campioni, l'elevato Stderr (0,15) indica che questi punteggi sono stime approssimative.
Rimuovi --limit per eseguire il benchmark completo. Per più benchmark in un unico passaggio, elencali separandoli con virgole:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsImposta --device in base al tuo hardware: mps per Apple Silicon, cuda:0 per GPU NVIDIA, oppure cpu come fallback. L'MMLU completo richiede 1-2 ore su una GPU moderna; benchmark più piccoli come HellaSwag si concludono in pochi minuti.
Per testare latenza e throughput, Ollama esegue i modelli in locale e riporta i token al secondo a diversi livelli di quantizzazione. Un modello 7B può generare oltre 100 token al secondo su una V100, mentre un 70B scende a una cifra.
Ci sono alcune best practice da tenere a mente quando fai benchmark di un LLM.
Prima di tutto e più importante, devi assicurarti che il modello non abbia visto le domande di valutazione durante l'addestramento. Se le ha viste, stai semplicemente misurando l'overfitting anziché la capacità di ragionare del modello, come discusso all'inizio. In tal caso, i punteggi dei benchmark diventerebbero privi di significato.
Per ottenere risultati riproducibili, la variabilità nelle risposte del modello dovrebbe essere mantenuta il più bassa possibile. Questo si può ottenere impostando la temperatura a zero per privilegiare l'accuratezza rispetto alla creatività.
L'harness include prompt few-shot standardizzati per ciascun benchmark. Usali invece di scrivere i tuoi prompt, poiché piccole variazioni di formulazione influenzano i punteggi più del previsto. Per lavori specifici di dominio, tuttavia, dovresti sempre costruire un piccolo set di test da esempi reali del tuo campo prima di impegnarti su un modello per la produzione.
I benchmark standard sono ottimi per verificare i fatti, ma faticano a misurare le sfumature. Per compiti aperti come il riassunto o la scrittura creativa, LLM-as-a-judge usa un modello più forte per valutare gli output in termini di utilità e accuratezza.
Al giudice viene solitamente fornita una rubrica e viene chiesto di assegnare un punteggio numerico (ad esempio, 1-10) o di eseguire un confronto a coppie per decidere quale delle due risposte sia migliore. Pur non essendo perfetti, questi giudizi si allineano con le preferenze umane circa nell'80-85% dei casi. Pertanto, LLM-as-a-judge offre un'alternativa scalabile a revisioni umane costose.
La valutazione dell'AI sta cambiando veloce quanto i modelli stessi. Man mano che benchmark come MMLU si saturano, i ricercatori costruiscono test più difficili che indagano la profondità del ragionamento piuttosto che la conoscenza memorizzata. FrontierMath e Humanity's Last Exam rappresentano questo nuovo fronte di difficoltà, dove anche i migliori modelli faticano.
I segnali più ampi puntano in un'unica direzione: più compute per l'addestramento, algoritmi più intelligenti e suite di benchmark che tengano il passo con i progressi. I test multimodali stanno ampliando ciò che chiediamo ai modelli di fare, dalla lettura di grafici alla comprensione di sequenze video.
Ma la lezione resta semplice. Nessun punteggio singolo racconta l'intera storia. Un modello in testa all'Arena può essere indietro su SWE-bench. Il modello migliore nel coding può stare a metà classifica sulla sicurezza. Abbina il benchmark a ciò di cui hai davvero bisogno: ragionamento, generazione di codice, comprensione visiva o pura velocità. È l'unico confronto che conta.
Per andare oltre il benchmarking, impara a costruire e fare fine-tuning degli LLM con la nostra skill track Developing Large Language Models.
Corsi sugli LLM
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

