
programa
Fundamentos de la IA
10 h
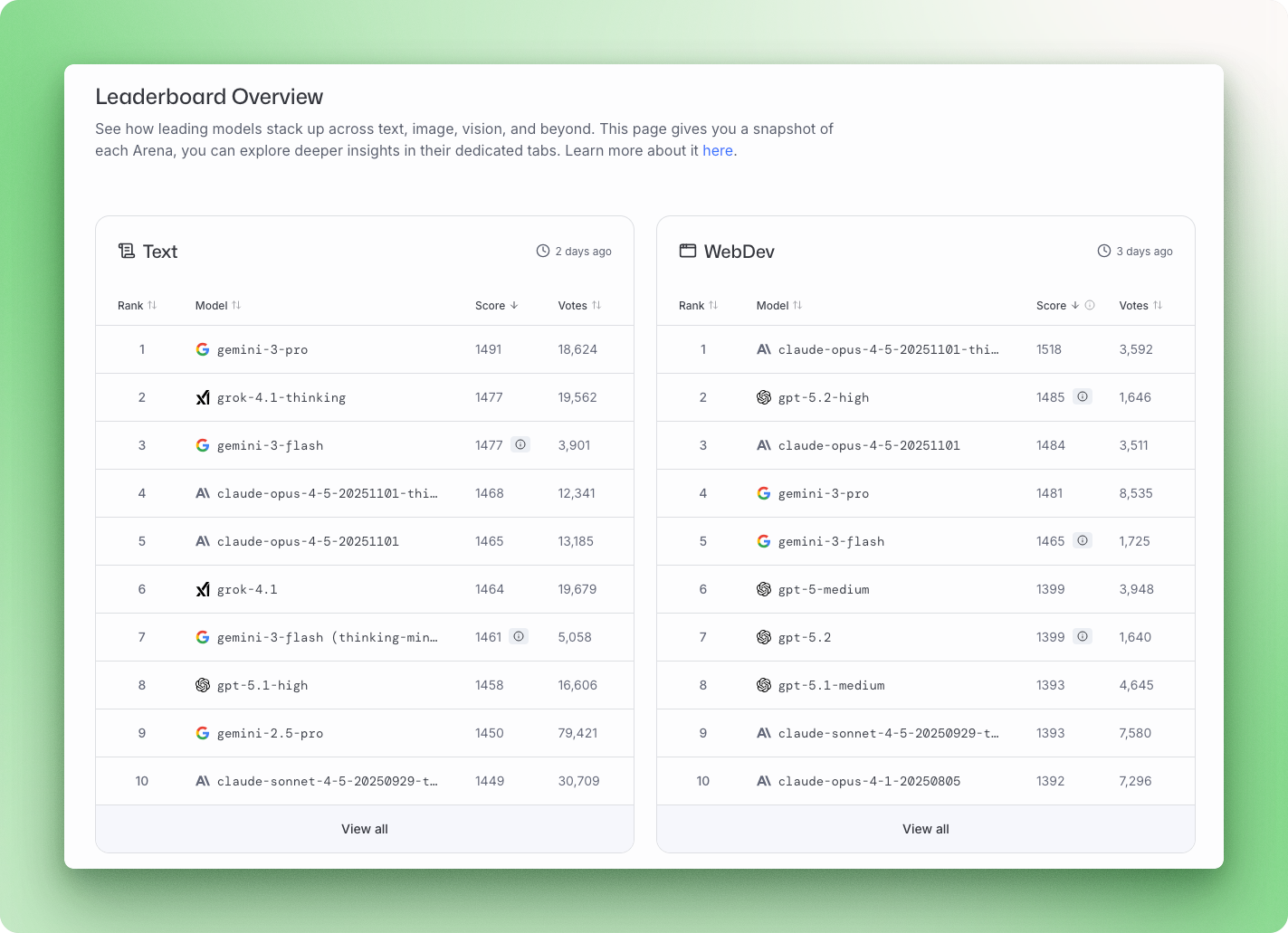
Casi cada semana se lanzan nuevos modelos de IA: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Cada lanzamiento viene acompañado de puntuaciones de referencia y afirmaciones de ser el mejor en algo. El problema: la mayoría de la gente no tiene ni idea de lo que significan estos números ni de cómo compararlos.
Los benchmarks de modelos de lenguaje grandes (LLM) son pruebas estandarizadas que miden el rendimiento de los modelos en tareas específicas, desde cuestionarios de conocimientos generales hasta complejos retos de codificación y problemas de razonamiento de varios pasos. Comprender lo que mide cada índice de referencia te ayuda a ir más allá del marketing y elegir el modelo adecuado para tus necesidades reales.
Esta guía desglosa las principales categorías de referencia, explica dónde encontrar las clasificaciones actuales y muestra cómo realizar tus propias evaluaciones. Al final, sabrás cómo leer una tabla de clasificación y elegir la IA que mejor se adapte a tu caso de uso.
Para profundizar en el funcionamiento interno de los LLM, consulta nuestros cursos sobre conceptos de LLM .
Un benchmark LLM es una prueba estandarizada que mide la capacidad de un modelo lingüístico para realizar un tipo específico de tarea. Se aplican las mismas preguntas y la misma rúbrica de puntuación a todos los modelos que realizan la prueba.
Los números que aparecen en los anuncios de los modelos provienen de unas cuantas pruebas populares. Cada puntuación cuenta una historia diferente, y ningún indicador por sí solo refleja la situación completa.
Los puntos de referencia son importantes por tres razones:
Comparación de modelos: Cuando OpenAI lanza GPT-5.2 y Anthropic lanza Claude Opus 4.5 en el mismo mes, las pruebas de rendimiento nos proporcionan un terreno común. De lo contrario, nos veremos obligados a escuchar a cada empresa proclamar su victoria basándose en ejemplos seleccionados de forma sesgada.
Seguimiento del progreso: Ejecuta la misma prueba de rendimiento a lo largo del tiempo y podrás comprobar si los modelos realmente están mejorando. Las puntuaciones MMLU pasaron del 70 % en 2022 a más del 90 % en 2025.
Detectar lagunas: Un modelo puede destacar en preguntas de cultura general, pero fallar en matemáticas de varios pasos. Los puntos de referencia ponen de manifiesto estas debilidades.
Las puntuaciones de referencia reflejan más que la inteligencia pura. Hay múltiples factores que influyen en las cifras que ves en las tablas de clasificación.
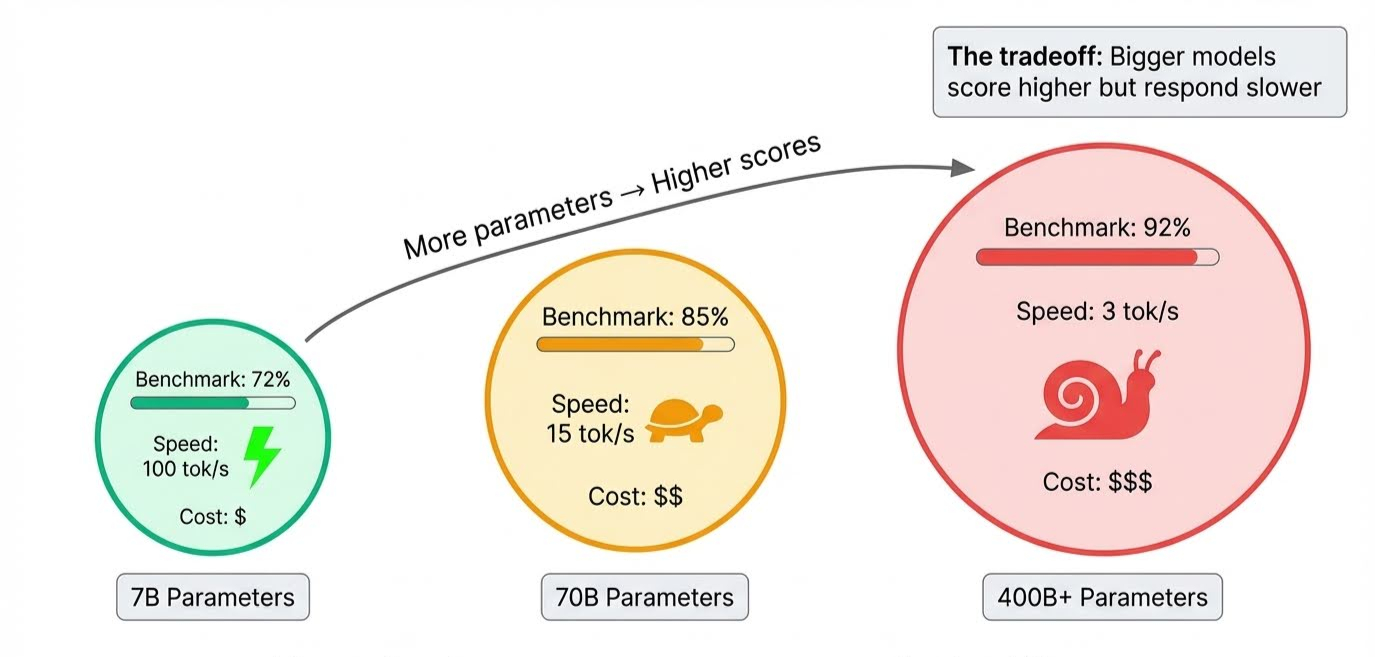
El tamaño del modelo es lo más obvio. Los parámetros almacenan todo lo que aprende un modelo, y los modelos de frontera contienen cientos de miles de millones de ellos. Un mayor número de parámetros significa que el modelo puede manejar razonamientos más complejos y captar más matices, lo que eleva las puntuaciones.
La compensación se manifiesta durante la inferencia, cuando el modelo genera respuestas: todos esos parámetros deben activarse en secuencia, por lo que los modelos más grandes son más lentos. Un modelo puede superar todas las pruebas comparativas, pero tardar varios segundos en responder.
La duración de la formación es más complicada. Cada pasada por los datos de entrenamiento se denomina época (epoch) . Demasiado pocos, y el modelo no ha absorbido lo suficiente como para obtener una buena puntuación. Si hay demasiados, empieza a memorizar ejemplos en lugar de aprender patrones que se pueden aplicar a nuevas preguntas. Eso es sobreajuste, y los diseñadores de pruebas de rendimiento intentan detectarlo específicamente incluyendo preguntas que el modelo no podría haber visto durante el entrenamiento.
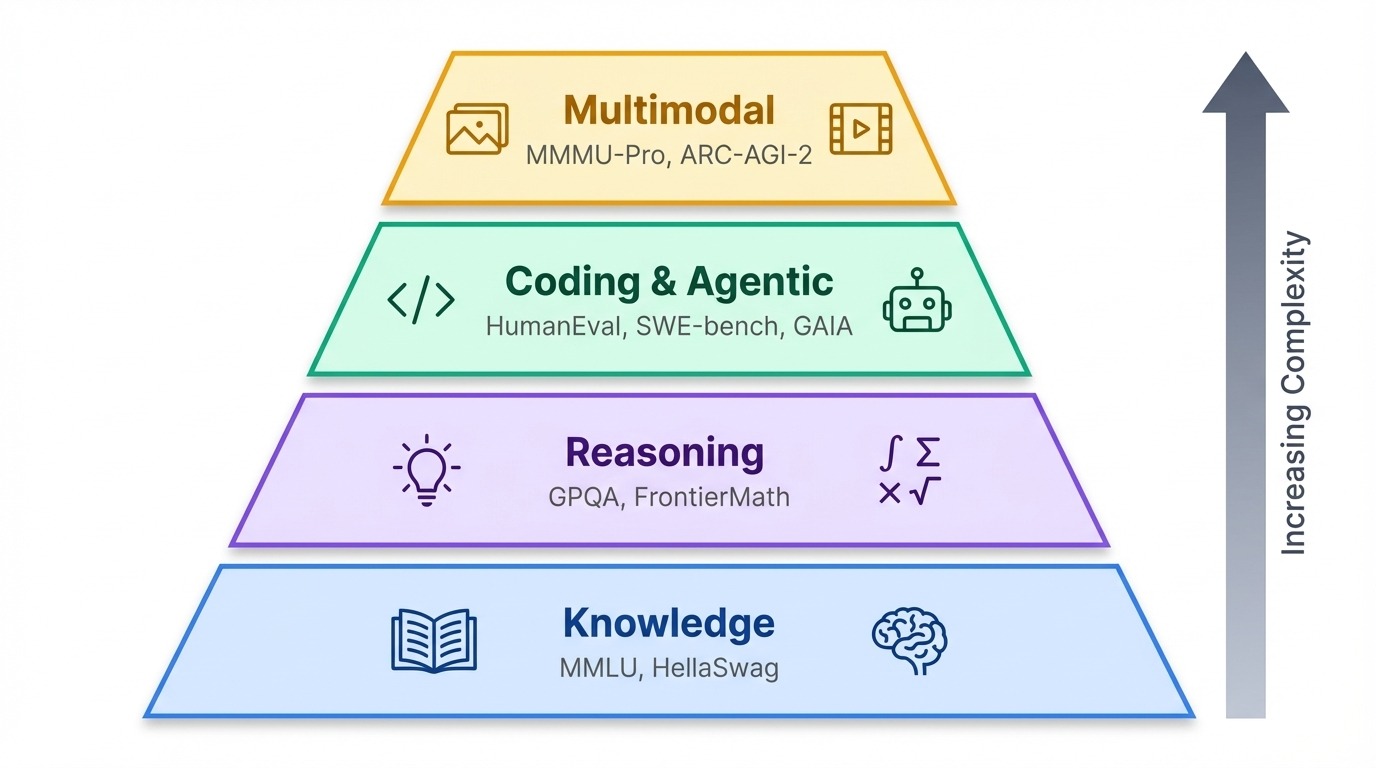
Con docenas de puntos de referencia en uso hoy en día, resulta útil agruparlos según lo que realmente evalúan.
Los puntos de referencia se agrupan en una jerarquía aproximada. En esencia, las pruebas de conocimientos comprueban lo que sabe un modelo. Además, los puntos de referencia de razonamiento evalúan tu capacidad de pensar. En la parte superior se encuentran las pruebas agénicas y multimodales, que miden si la IA puede actuar en el mundo real o procesar información más allá del texto.
MMLU (Comprensión masiva multitarea del lenguaje) abarca 57 materias académicas, desde el nivel secundario hasta el profesional, que abarcan desde el álgebra abstracta hasta las religiones del mundo. Durante años, sirvió como prueba de referencia para los conocimientos generales, pero ahora los modelos de vanguardia se agrupan por encima del 88 %, lo que deja poco margen para distinguirlos.
Esa saturación empujó a los investigadores a realizar pruebas más exigentes. GPQA (Preguntas y respuestas de nivel universitario a prueba de Google) plantea 448 preguntas sobre biología, física y química que expertos en la materia han diseñado para que no se puedan buscar.
El índice de referencia tiene tres niveles de dificultad, siendo el nivel Diamante el que contiene las preguntas más difíciles. Incluso con acceso ilimitado a Internet, los no expertos solo obtienen un 34 %, solo un 9 % más que el resultado que cabría esperar de adivinar al azar entre cuatro opciones de respuesta. A partir de diciembre de 2025, Gemini 3 Pro lidera el GPQA Diamond con un 92,6 %.
El índice de referenciaGDPval (valor del producto interior bruto) de OpenAI mide algo diferente: el rendimiento laboral en el mundo real. Abarca 44 profesiones de distintos sectores con un valor de 3 billones de dólares en actividad económica anual, y pide a los modelos que produzcan resultados como informes legales, presentaciones de diapositivas y especificaciones técnicas, en lugar de responder a preguntas de opción múltiple. El recientemente lanzado GPT-5.2 es líder en este sentido.
HellaSwag analiza el razonamiento basado en el sentido común presentando situaciones cotidianas y pidiendo a los modelos que elijan la siguiente frase más plausible. Una persona que está preparando la cena coge una sartén. ¿Qué pasa después?
Las respuestas incorrectas se escribieron específicamente para engañar a la IA: utilizan palabras que, estadísticamente, encajan en el contexto, pero describen resultados imposibles (la sartén flota, la estufa se convierte en un gato). Los humanos obtenéis una puntuación del 95,6 % porque sabemos cómo funcionan las cocinas. Los modelos se equivocan porque predicen palabras probables, no acontecimientos probables.
Los últimos puntos de referencia aumentan aún más la dificultad:
FrontierMath incluye problemas nunca antes publicados, creados por matemáticos investigadores, en los que incluso los mejores modelos obtienen una puntuación inferior al 20 %.
El último examen de la humanidad recopila 2500 preguntas de nivel experto diseñadas para evitar las respuestas aleatorias.
MathArena extrae problemas de 2025 concursos de matemáticas para garantizar que no haya solapamiento en los datos de entrenamiento.
HumanEval es la clásica prueba de codificación: Contiene 164 problemas de Python en los que los modelos escriben funciones a partir de cadenas de documentación y se califican en función de si el código supera las pruebas unitarias. La mayoría de los modelos de frontera actuales obtienen una puntuación superior al 85 %, por lo que los investigadores crearon variantes más difíciles, como HumanEval+, con casos de prueba más rigurosos.
SWE-bench (Software Engineering Benchmark) va más allá de las funciones aisladas. Coloca modelos en repositorios GitHub reales y les pide que corrijan errores reales. El modelo debe navegar por el código base, comprender el problema y producir un parche que funcione.
SWE-bench Verified es un subconjunto más pequeño y altamente seleccionado del SWE-bench original, que filtra tareas de alta calidad revisadas por ingenieros humanos. En diciembre de 2025, Claude Opus 4.5 es el primer modelo en superar el 80 % en SWE-bench Verified (80,9 %).
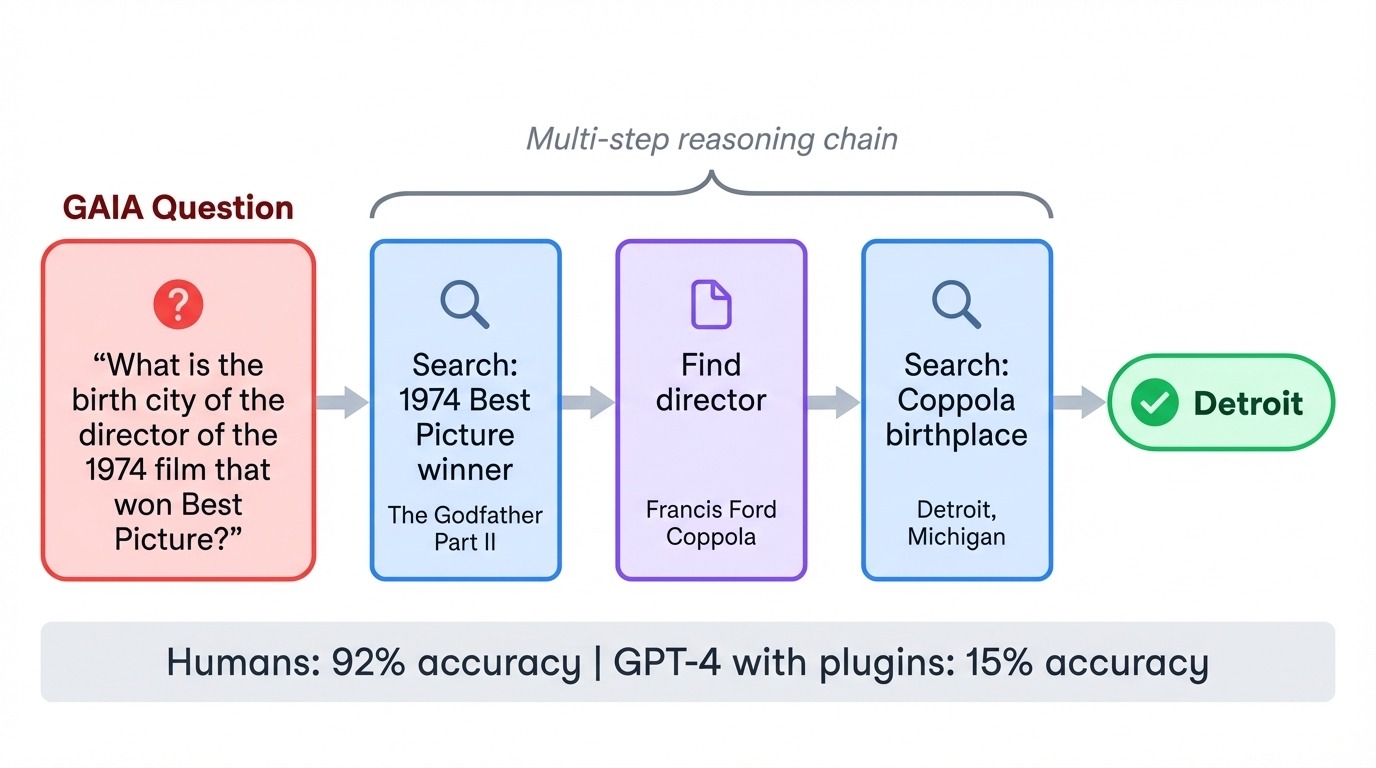
GAIA (, Asistentes de IA General) invierte la relación habitual entre dificultad y complejidad. Sus 466 tareas son muy fáciles para los humanos (92 % de precisión), pero brutales para la IA. Cuando GPT-4 intentó por primera vez GAIA con complementos, obtuvo una puntuación de solo el 15 %. Cada tarea requiere encadenar varios pasos: buscar en la web, leer documentos, hacer cálculos y sintetizar respuestas.
Una pregunta típica podría ser la ciudad natal del director de una película concreta de los años 70, lo que requeriría que el modelo identificara la película, encontrara al director y luego buscara datos biográficos. La prueba de referencia evalúa si los modelos pueden coordinar herramientas y ejecutar planes de varios pasos sin perder el programa.
Por último, WebArena implementa modelos en entornos web autohospedados en los que deben completar tareas como reservar vuelos, gestionar sistemas de contenido y navegar por sitios de comercio electrónico interactuando con interfaces de navegador reales.
Los puntos de referencia basados únicamente en texto pasan por alto una frontera en expansión. El benchmarkMMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning, comprensión y razonamiento multimodal multidisciplinar masivo)de evalúa el razonamiento visual en 30 materias mediante la incorporación de preguntas directamente en imágenes, lo que obliga a los modelos a leer e interpretar la información visual al mismo tiempo.
El punto de referencia filtra las preguntas que podrían responder los modelos basados únicamente en texto, lo que garantiza que la visión realmente importe. Gemini 3 Pro lidera aquí con un 81 %.
Algunos puntos de referencia llevan el razonamiento visual a un nivel superior.
MathVista, por ejemplo, combina la percepción visual con el razonamiento matemático. Los problemas incluyen interpretar gráficos de funciones, leer tablas científicas y resolver problemas de geometría a partir de diagramas. Video-MMMU amplía esto a la comprensión temporal, comprobando si los modelos pueden razonar sobre la causalidad y las secuencias a través de fotogramas de vídeo en lugar de imágenes individuales.
ARC-AGI-2 sigue siendo el punto de referencia que la IA aún no ha superado. Cada tarea presenta algunos ejemplos de parillas de entrada-salida y solicita al modelo que deduzca la regla de transformación y, a continuación, la aplique a una nueva entrada.
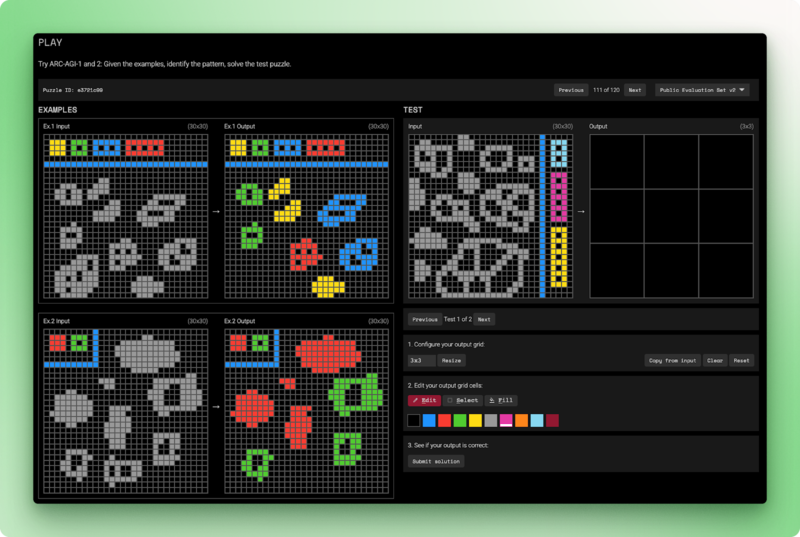
Los seres humanos resuelven estos rompecabezas en menos de dos intentos. Los modelos de lenguaje puro obtienen una puntuación del 0 %. Los mejores sistemas híbridos alcanzan el 54 %, y eso a un costo de 30 dólares por tarea. ARC-AGI-2 evalúa la inteligencia fluida: razonamiento a partir de principios básicos en lugar de patrones observados durante el entrenamiento.
Las pruebas de rendimiento generan puntuaciones, pero las tablas de clasificación deciden cómo presentarlas. Las diferentes plataformas priorizan diferentes factores: las preferencias humanas, la transparencia del código abierto o la evaluación multidimensional. Saber qué tabla de clasificación consultar depende de lo que te interese medir.
LMArena (LMSYS Chatbot Arena) adopta un enfoque diferente al de los benchmarks automatizados. En lugar de puntuar las respuestas según una rúbrica, se pide a los seres humanos que elijan la mejor respuesta. Los usuarios envían una solicitud, reciben respuestas de dos modelos anónimos y votan por el que prefieren. Los modelos permanecen ocultos hasta después de la votación, lo que evita que los prejuicios hacia las marcas influyan en las decisiones.
La plataforma utiliza un modelo estadístico Bradley-Terry para convertir más de 5 millones de votos por pares en clasificaciones. En diciembre de 2025, Gemini 3 Pro lidera la clasificación general de Arena con una puntuación de 1501, seguido de Grok 4.1 con 1483, Claude Opus 4.5 y GPT-5.2.
LMArena capta algo que los puntos de referencia no detectan: si una respuesta realmente resulta útil. La contrapartida es que las respuestas prolijas y que suenan seguras pueden ganar votos incluso cuando existe una respuesta más breve y precisa.
La tabla de clasificación Open LLM de Hugging Face se centra en modelos de código abierto y los somete a pruebas estandarizadas utilizando EleutherAI Evaluation Harness. La versión 2 se lanzó en junio de 2024 con pruebas de rendimiento más difíciles, después de que los modelos de vanguardia hubieran saturado el conjunto de pruebas original.
La batería actual incluye GPQA, MATH Nivel 5 y MMLU-PRO, con puntuación normalizada en la que 0 significa rendimiento aleatorio y 100 significa perfecto. Entre los modelos abiertos más destacados se encuentran Qwen3, Llama 3.3 70B y DeepSeek V3.1, todos ellos compitiendo a poca distancia de los líderes de código cerrado.
Stanford HELM (Evaluación holística de modelos lingüísticos) mide más que la precisión de los resultados de los modelos. Cada modelo se evalúa en siete dimensiones por escenario: precisión, calibración, solidez, imparcialidad, sesgo, toxicidad y eficiencia.
El marco abarca 42 escenarios y programa de forma explícita los casos en los que los modelos fallan, no solo de aquellos en los que tienen éxito. HELM también mantiene una clasificación de seguridad independiente que evalúa riesgos como la violencia, el fraude y el acoso. En diciembre de 2025, Claude 3.5 Sonnet ocupa el primer puesto en la clasificación general de seguridad.
Ninguna empresa gana en todos los ámbitos. Sin embargo, en cuanto se comparan varias tablas de clasificación, empiezan a aparecer patrones.
Los modelos Gemini de Google dominan los benchmarks multimodales y el razonamiento científico. Gemini 3 Pro lidera GPQA Diamond con un 91,9 % y encabeza la clasificación general de Arena. La línea Claude de Anthropic destaca por su codificación y seguridad. Claude Opus 4.5 ostenta el récord verificado por SWE-bench con un 80,9 %, y Claude 3.5 Sonnet lidera HELM Safety.
Los modelos GPT de OpenAI siguen siendo generalistas sólidos, competitivos en la mayoría de los puntos de referencia y sin ninguna debilidad destacada. La serie Llama de Meta demuestra que el código abierto puede igualar a los modelos cerrados en muchas tareas, con Llama 3.3 70B rivalizando con los resultados de sistemas propietarios mucho más grandes.
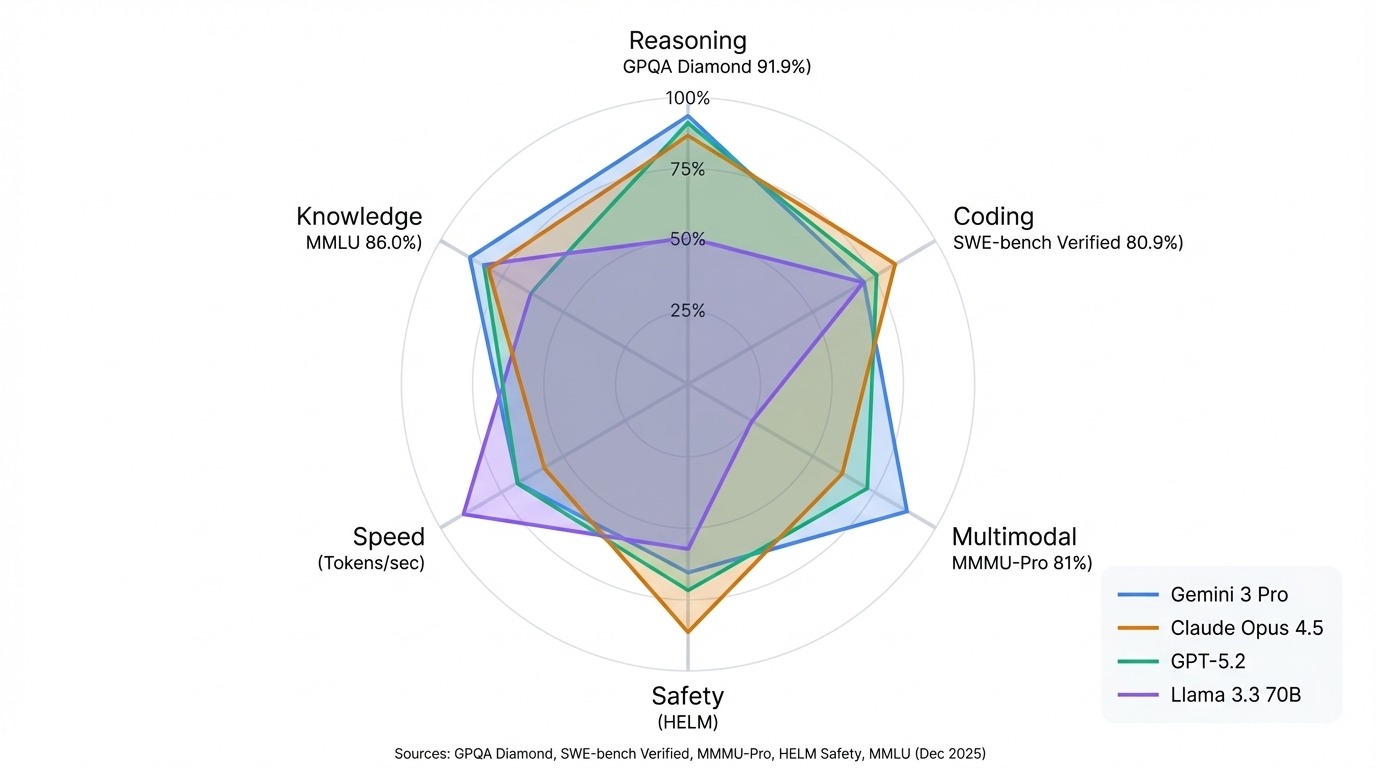
El patrón más importante: adapta la tabla de clasificación a tu caso de uso. Las clasificaciones de la arena reflejan la calidad de la conversación. Las puntuaciones HELM demuestran fiabilidad y seguridad. Hugging Face realiza un seguimiento de lo que puedes ejecutar tú mismo. Un modelo que encabeza una lista puede ocupar un lugar intermedio en otra, y eso no es un defecto de las clasificaciones. Son pruebas diferentes que miden cosas diferentes.
Las tablas de clasificación te indican cómo se comparan los modelos en pruebas estándar, pero a veces necesitas respuestas específicas para tu situación.
Es posible que estés eligiendo entre modelos de código abierto para tu hardware o verificando que un modelo ajustado no haya perdido la capacidad de razonamiento general. En otros casos, los puntos de referencia estándar simplemente no cubren tu dominio.
En todos esos casos, es posible que quieras considerar la posibilidad de realizar tú mismo una evaluación comparativa de los LLM. Te mostraré cómo hacerlo y lo que debes tener en cuenta.
El EleutherAI LM Evaluation Harness es el estándar del sector para realizar estas evaluaciones a nivel local. Impulsa la clasificación Hugging Face Open LLM y admite más de 60 puntos de referencia.
Funciona de manera diferente a como la mayoría de la gente interactúa con los chatbots. No solo «chatea» con el modelo, sino que realiza un análisis matemático más determinista.
En el caso de las preguntas de opción múltiple, que son un método habitual en pruebas comparativas como MMLU o ARC, el arnés no pide al modelo que genere «A», «B», «C» o «D». En su lugar, construye indicaciones separadas para cada opción y pregunta al modelo cuál es la probabilidad de cada una de ellas. La opción con la mayor verosimilitud logarítmica se toma entonces como la elección del modelo.
Otros puntos de referencia requieren un enfoque generativo, en el que el modelo produce una respuesta de texto completo en lugar de seleccionar una probabilidad. Una vez completada la generación, el arnés analiza el resultado utilizando expresiones regulares (regex) y extrae el valor específico necesario para verificarlo con la clave de respuestas.
Veamos cómo ejecutar tu primera evaluación LLM.
Puedes instalar el arnés de evaluación utilizando pip:
pip install lm-evalAntes de realizar una evaluación completa, prueba el proceso con una pequeña muestra. La bandera ` --limit ` restringe el punto de referencia a un número específico de ejemplos. Este ejemplo prueba Qwen2.5-1.5B-Instruct, un modelo pequeño que funciona en la mayoría del hardware sin necesidad de una GPU de gama alta, utilizando el benchmark HellaSwag:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Tareas |
Versión |
Filtro |
n-shot |
Métrico |
|
Valor |
|
Stderr |
|
hellaswag |
1 |
ninguno |
0 |
acc |
↑ |
0,3 |
± |
0,1528 |
|
ninguno |
0 |
acc_norm |
↑ |
0,4 |
± |
0,1633 |
El resultado muestra dos métricas de precisión: la precisión bruta ( acc ) y la precisión ajustada (acc_norm ), que corrige el sesgo del modelo hacia completaciones más cortas o más largas. Además, se informa del error estándar, que se reduce a medida que aumenta el tamaño de la muestra. Stderr En nuestra primera prueba, en la que solo utilizamos 10 muestras, el alto índice de correlación (0,15) significa que estas puntuaciones son estimaciones aproximadas.
Elimina « --limit » para ejecutar la prueba de rendimiento completa. Para múltiples puntos de referencia en una sola pasada, enumeradlos con comas:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsConfigura --device según tu hardware: mps para Apple Silicon, cuda:0 para GPU NVIDIA o cpu como alternativa. El MMLU completo tarda entre 1 y 2 horas en una GPU moderna; pruebas de rendimiento más pequeñas, como HellaSwag, se completan en cuestión de minutos.
Para las pruebas de latencia y rendimiento, Ollama ejecuta modelos localmente e informa de los tokens por segundo en diferentes niveles de cuantificación. Un modelo de 7000 millones de bits puede generar más de 100 tokens por segundo en un V100, mientras que un modelo de 70 000 millones de bits cae a cifras de un solo dígito.
Hay algunas prácticas recomendadas que debes tener en cuenta al evaluar un LLM.
En primer lugar, y lo más importante, debes asegurarte de que el modelo no haya visto las preguntas de evaluación durante el entrenamiento. Si lo hacen, solo estás midiendo el sobreajuste en lugar de la capacidad de razonamiento del modelo, como se ha comentado al principio. En este caso, las puntuaciones de referencia perderían todo su significado.
Para obtener resultados reproducibles, la variabilidad en las respuestas del modelo debe mantenerse lo más baja posible. Esto se puede lograr ajustando la temperatura a cero para favorecer la precisión por encima de la creatividad.
El arnés incluye indicaciones estandarizadas de pocos disparos para cada punto de referencia. Úsalas en lugar de escribir tus propias indicaciones, ya que los pequeños cambios en la redacción afectan a las puntuaciones más de lo esperado. Sin embargo, para trabajos específicos de un dominio, siempre debes crear un pequeño conjunto de pruebas a partir de ejemplos reales de tu campo antes de comprometerte con un modelo para la producción.
Los parámetros de referencia estándar son excelentes para verificar datos, pero tienen dificultades para medir los matices. Para tareas abiertas, como la síntesis o la escritura creativa, LLM-as-a-judge utiliza un modelo más sólido para calificar los resultados en función de su utilidad y precisión.
Normalmente, al juez se le proporciona una rúbrica y se te pide que asignes una puntuación numérica (por ejemplo, del 1 al 10) o que realices una comparación por pares para decidir cuál de las dos respuestas es mejor. Aunque no son perfectas, estas valoraciones coinciden con las preferencias humanas en aproximadamente el 80-85 % de los casos. Por lo tanto, LLM-as-a-judge ofrece una alternativa escalable a la costosa revisión humana.
La evaluación de la IA está cambiando tan rápido como los propios modelos. A medida que los puntos de referencia como MMLU se saturan, los investigadores están creando pruebas más difíciles que evalúan la profundidad del razonamiento en lugar del conocimiento memorizado. FrontierMath y Humanity's Last Exam representan esta nueva frontera de dificultad, donde incluso los mejores modelos tienen dificultades.
Las señales generales apuntan en una misma dirección: más potencia de cálculo para el entrenamiento, algoritmos más inteligentes y conjuntos de pruebas de rendimiento que sigan el ritmo del progreso. Las pruebas multimodales están ampliando lo que pedimos a los modelos que hagan, desde leer gráficos hasta comprender secuencias de vídeo.
Pero la conclusión sigue siendo sencilla. Ninguna puntuación por sí sola cuenta toda la historia. Una modelo que lidera la Arena podría quedarse atrás en el banco de la SWE. El modelo de codificación superior podría obtener una puntuación media en materia de seguridad. Adapta el punto de referencia a lo que realmente necesitas: razonamiento, generación de código, comprensión visual o velocidad pura. Esa es la única comparación que importa.
Para llevar tus habilidades más allá de la evaluación comparativa, aprende a crear y ajustar modelos de lenguaje grande (LLM) por tu cuenta con nuestro Desarrollo de grandes modelos lingüísticos skill track.
Cursos de máster en Derecho
programa
programa
Curso
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
