
Tracks
Cơ bản về Trí tuệ Nhân tạo
10 giờ
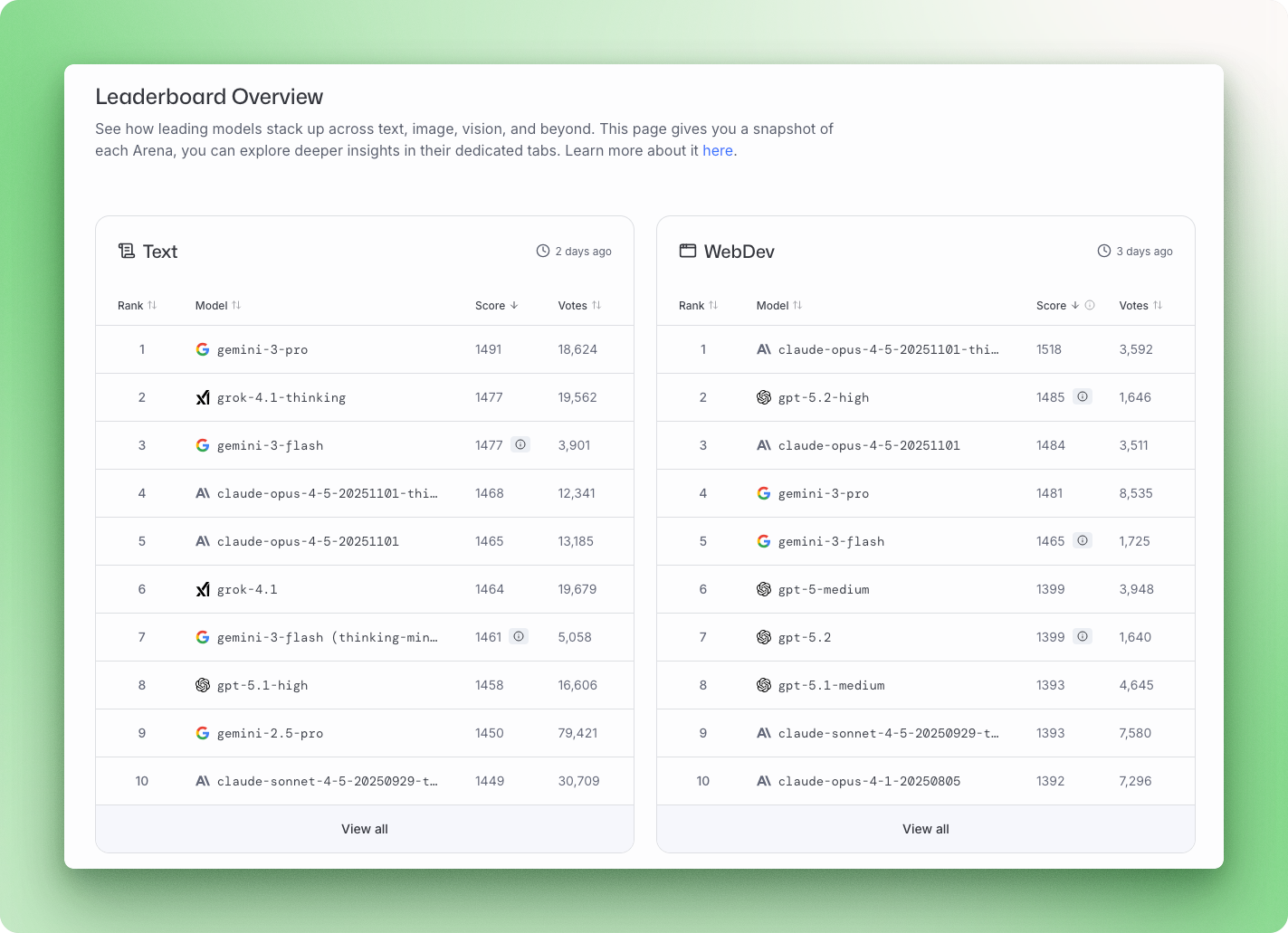
Các mô hình AI mới ra mắt gần như hàng tuần: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Mỗi lần phát hành lại kèm điểm benchmark và tuyên bố "tốt nhất" ở một khía cạnh nào đó. Vấn đề là: đa số không biết những con số này nghĩa là gì hay so sánh chúng ra sao.
Benchmark dành cho Mô hình ngôn ngữ lớn (LLM) là các bài kiểm tra tiêu chuẩn hóa đo lường mức độ mô hình thực hiện tốt các tác vụ cụ thể, từ câu đố kiến thức tổng quát đến thử thách lập trình phức tạp và bài toán suy luận nhiều bước. Hiểu mỗi benchmark đo cái gì sẽ giúp bạn vượt qua lớp "tiếp thị" và chọn đúng mô hình cho nhu cầu thực tế.
Hướng dẫn này phân tích các nhóm benchmark chính, giải thích nơi tìm xếp hạng hiện tại, và chỉ cho bạn cách tự chạy đánh giá. Kết thúc, bạn sẽ biết cách đọc bảng xếp hạng và chọn AI phù hợp với trường hợp sử dụng của mình.
Để đào sâu cách LLM hoạt động phía sau, hãy xem khóa học LLMs Concepts của chúng tôi.
Một LLM benchmark là bài kiểm tra tiêu chuẩn hóa đo mức độ mô hình ngôn ngữ xử lý tốt một loại tác vụ cụ thể. Cùng một bộ câu hỏi và thang chấm điểm được áp dụng cho mọi mô hình tham gia bài kiểm tra.
Các con số trong thông báo phát hành mô hình đến từ một vài bài kiểm tra phổ biến. Mỗi điểm số kể một câu chuyện khác nhau, và không có benchmark đơn lẻ nào cho bức tranh toàn diện.
Benchmark quan trọng vì ba lý do:
So sánh mô hình: Khi OpenAI ra mắt GPT-5.2 và Anthropic phát hành Claude Opus 4.5 trong cùng tháng, benchmark tạo ra "mẫu số chung". Nếu không, chúng ta chỉ còn mỗi công ty tự nhận chiến thắng dựa trên ví dụ chọn lọc.
Theo dõi tiến bộ: Chạy cùng một benchmark theo thời gian, bạn sẽ thấy mô hình có thực sự tốt hơn không. Điểm MMLU đã tăng từ 70% năm 2022 lên hơn 90% năm 2025.
Phát hiện khoảng trống: Một mô hình có thể "cân" câu hỏi kiến thức tổng quát nhưng lại "khựng" ở toán nhiều bước. Benchmark làm lộ những điểm yếu này.
Điểm benchmark phản ánh nhiều hơn là "trí tuệ thô". Nhiều yếu tố định hình các con số bạn thấy trên bảng xếp hạng.
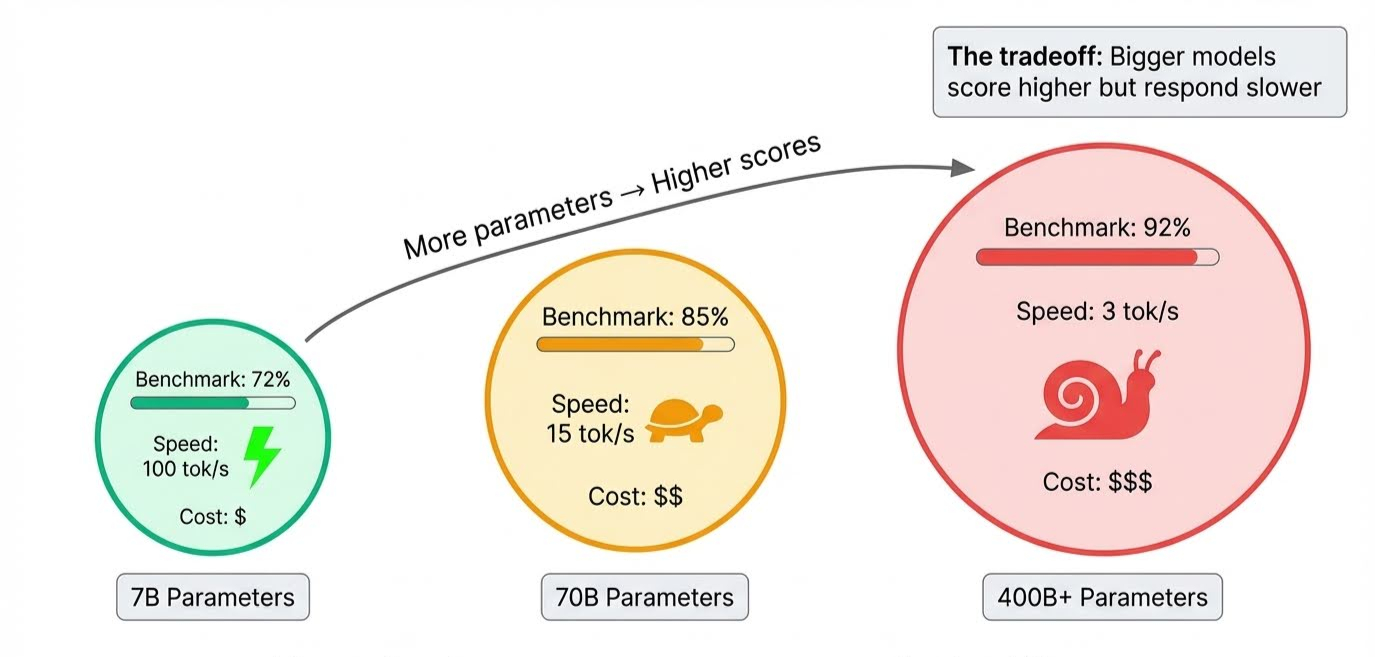
Kích thước mô hình là yếu tố hiển nhiên. Tham số lưu trữ những gì mô hình học được, và các mô hình tiên phong chứa hàng trăm tỷ tham số. Nhiều tham số hơn giúp mô hình xử lý suy luận phức tạp và nắm bắt sắc thái tốt hơn, từ đó đẩy điểm số lên.
Cái giá phải trả thể hiện ở giai đoạn suy luận (inference), khi mô hình thực sự tạo phản hồi: tất cả tham số đó phải kích hoạt tuần tự, nên mô hình lớn sẽ chậm hơn. Một mô hình có thể dẫn đầu mọi benchmark nhưng mất vài giây mới trả lời.
Thời lượng huấn luyện phức tạp hơn. Mỗi lượt đi qua dữ liệu huấn luyện gọi là một epoch. Quá ít thì mô hình chưa hấp thụ đủ để đạt điểm cao. Quá nhiều thì bắt đầu ghi nhớ ví dụ thay vì học mẫu có thể chuyển giao sang câu hỏi mới. Đó là overfitting, và các nhà thiết kế benchmark cố tình bắt lỗi bằng cách đưa vào câu hỏi mà mô hình khó có thể từng thấy trong huấn luyện.
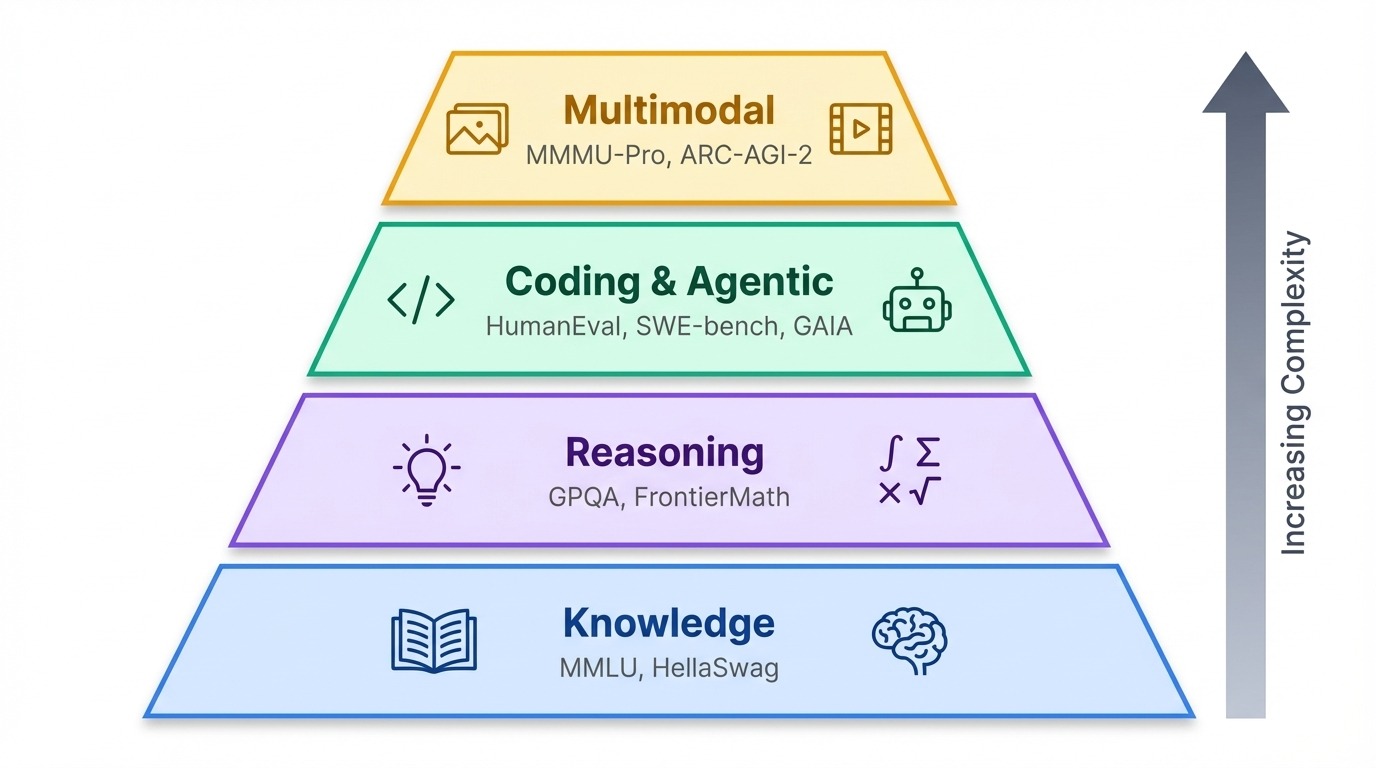
Với hàng chục benchmark đang dùng hiện nay, việc nhóm chúng theo nội dung kiểm tra thực sự sẽ hữu ích.
Benchmark gom lại thành một hệ thống phân cấp tương đối. Nền tảng là bài kiểm tra kiến thức xem mô hình biết gì. Cao hơn là benchmark suy luận kiểm tra mô hình tư duy tốt đến đâu. Trên cùng là bài kiểm tra đặc tác và đa phương thức đo lường khả năng AI hành động trong thế giới thực hoặc xử lý thông tin vượt ngoài văn bản.
MMLU (Massive Multitask Language Understanding) bao phủ 57 môn học học thuật từ trung học đến trình độ chuyên nghiệp, trải dài từ đại số trừu tượng đến tôn giáo thế giới. Nhiều năm liền, đây là bài kiểm tra chuẩn cho kiến thức tổng quát, nhưng các mô hình tiên phong giờ đây tụ lại trên 88%, khiến khó phân biệt.
Sự bão hòa đó đẩy giới nghiên cứu hướng đến bài kiểm tra khó hơn. GPQA (Graduate-level Google-Proof Q&A) đặt 448 câu hỏi về sinh học, vật lý và hóa học do chuyên gia thiết kế để không thể tra cứu.
Benchmark có ba mức độ khó, với Diamond là khó nhất. Ngay cả khi được truy cập web không giới hạn, người không chuyên chỉ đạt 34%—chỉ 9% cao hơn mức đoán ngẫu nhiên với bốn lựa chọn. Tính đến tháng 12/2025, Gemini 3 Pro dẫn đầu GPQA Diamond với 92,6%.
Benchmark GDPval (Gross Domestic Product-valued) của OpenAI đo lường một điều khác: sản lượng công việc trong thế giới thực. Nó bao phủ 44 nghề trên các lĩnh vực trị giá 3 nghìn tỷ đô la hoạt động kinh tế hàng năm, yêu cầu mô hình tạo ra sản phẩm như bản ghi nhớ pháp lý, slide deck, và đặc tả kỹ thuật thay vì trả lời trắc nghiệm. GPT-5.2 mới phát hành gần đây là mô hình dẫn đầu ở khía cạnh này.
HellaSwag kiểm tra suy luận thường thức bằng cách đưa ra các tình huống thường ngày và yêu cầu mô hình chọn câu tiếp theo hợp lý nhất. Một người đang nấu ăn với tay lấy chảo. Chuyện gì xảy ra tiếp theo?
Các đáp án sai được viết riêng để đánh lừa AI: chúng dùng từ ngữ phù hợp ngữ cảnh về mặt thống kê nhưng mô tả kết cục bất khả (cái chảo bay đi, bếp biến thành con mèo). Con người đạt 95,6% vì chúng ta biết bếp hoạt động thế nào. Mô hình bị đánh lừa vì chúng dự đoán từ ngữ có khả năng xuất hiện, không phải sự kiện có khả năng xảy ra.
Các benchmark mới nhất đẩy độ khó lên nữa:
FrontierMath có các bài toán chưa từng công bố của nhà toán học nghiên cứu, nơi ngay cả mô hình tốt nhất cũng dưới 20%.
Humanity's Last Exam tổng hợp 2.500 câu hỏi trình độ chuyên gia được thiết kế chống đoán mò.
MathArena lấy bài từ các kỳ thi toán năm 2025 để đảm bảo không trùng dữ liệu huấn luyện.
HumanEval là bài kiểm tra lập trình kinh điển: chứa 164 bài Python nơi mô hình viết hàm từ docstring và được chấm dựa trên việc vượt qua unit test. Đa số mô hình tiên phong hiện nay đạt trên 85%, nên các biến thể khó hơn như HumanEval+ ra đời với ca kiểm thử khắt khe hơn.
SWE-bench (Software Engineering Benchmark) vượt khỏi phạm vi hàm cô lập. Nó đưa mô hình vào các repo GitHub thực và yêu cầu sửa lỗi thật. Mô hình phải điều hướng codebase, hiểu vấn đề, và tạo bản vá hoạt động.
SWE-bench Verified là tập con nhỏ, tuyển chọn kỹ từ SWE-bench gốc, lọc các tác vụ chất lượng cao do kỹ sư con người thẩm định. Tính đến tháng 12/2025, Claude Opus 4.5 là mô hình đầu tiên vượt 80% ở SWE-bench Verified (80,9%).
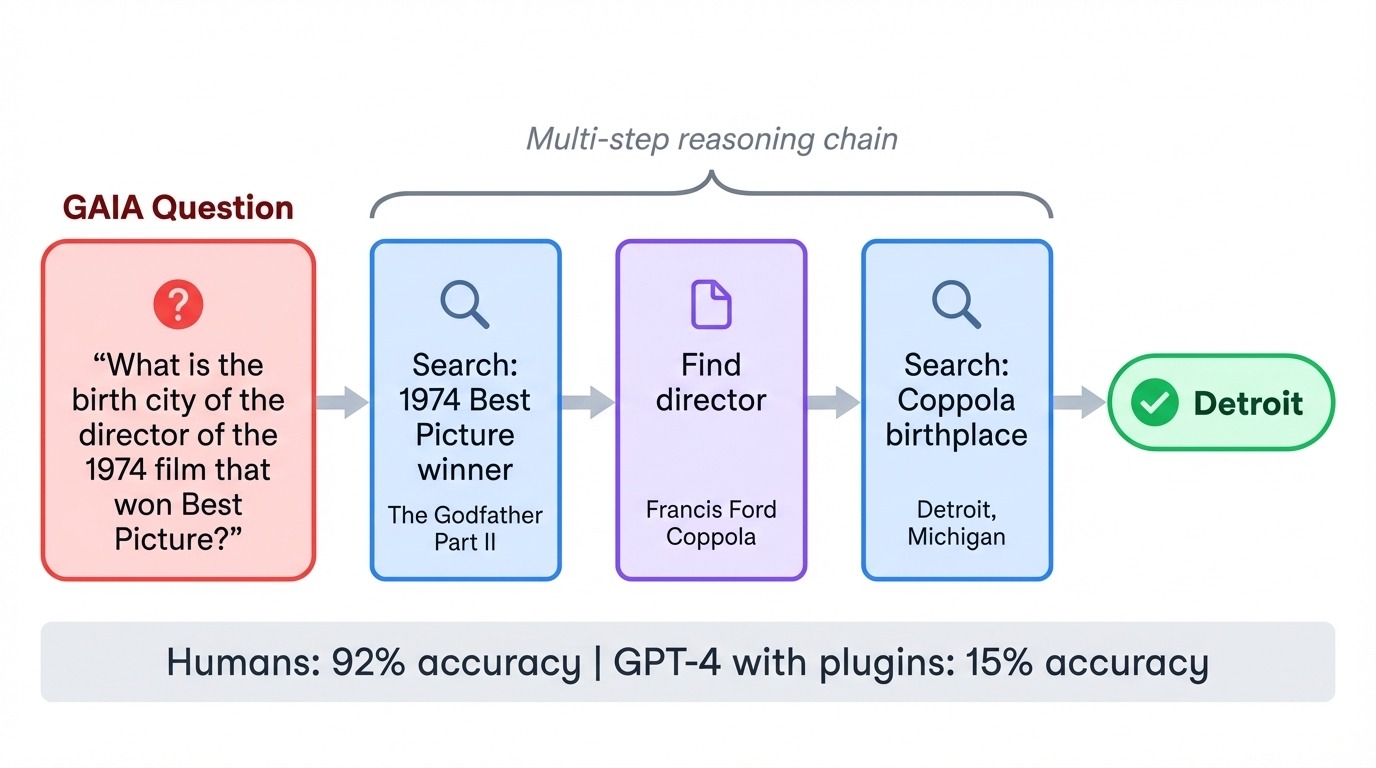
GAIA (General AI Assistants) đảo ngược mối quan hệ độ khó thường thấy. 466 tác vụ của nó cực dễ với con người (độ chính xác 92%) nhưng rất khó với AI. Khi GPT-4 lần đầu thử GAIA với plugin, chỉ đạt 15%. Mỗi tác vụ yêu cầu xâu chuỗi nhiều bước: tìm kiếm web, đọc tài liệu, tính toán, và tổng hợp câu trả lời.
Một câu hỏi điển hình có thể yêu cầu thành phố sinh của đạo diễn một bộ phim thập niên 1970 cụ thể, buộc mô hình xác định bộ phim, tìm đạo diễn, rồi tra cứu tiểu sử. Benchmark này kiểm tra liệu mô hình có thể phối hợp công cụ và thực thi kế hoạch nhiều bước mà không lạc hướng hay không.
Cuối cùng, WebArena triển khai mô hình trong môi trường web tự lưu trữ, nơi chúng phải hoàn thành các tác vụ như đặt vé máy bay, quản lý hệ thống nội dung, và điều hướng trang thương mại điện tử bằng cách tương tác với giao diện trình duyệt thực.
Các benchmark chỉ văn bản bỏ lỡ một mặt trận đang mở rộng. Benchmark MMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning) kiểm tra suy luận thị giác trên 30 môn bằng cách nhúng câu hỏi trực tiếp vào hình ảnh, buộc mô hình đọc và diễn giải thông tin thị giác đồng thời.
Benchmark loại bỏ câu hỏi mà mô hình chỉ-văn-bản có thể trả lời, đảm bảo thị giác thực sự quan trọng. Gemini 3 Pro dẫn đầu ở đây với 81%.
Một số benchmark đưa suy luận thị giác lên tầm cao mới.
MathVista chẳng hạn, kết hợp nhận thức thị giác với suy luận toán học. Bài toán gồm diễn giải đồ thị hàm, đọc biểu đồ khoa học, và giải hình học từ sơ đồ. Video-MMMU mở rộng sang hiểu biết theo thời gian, kiểm tra liệu mô hình có thể suy luận về quan hệ nhân quả và chuỗi sự kiện qua các khung hình video thay vì ảnh đơn lẻ.
ARC-AGI-2 vẫn là benchmark mà AI chưa chinh phục. Mỗi tác vụ đưa ra một vài ví dụ lưới đầu vào-đầu ra và yêu cầu mô hình suy ra quy tắc biến đổi, rồi áp dụng cho đầu vào mới.
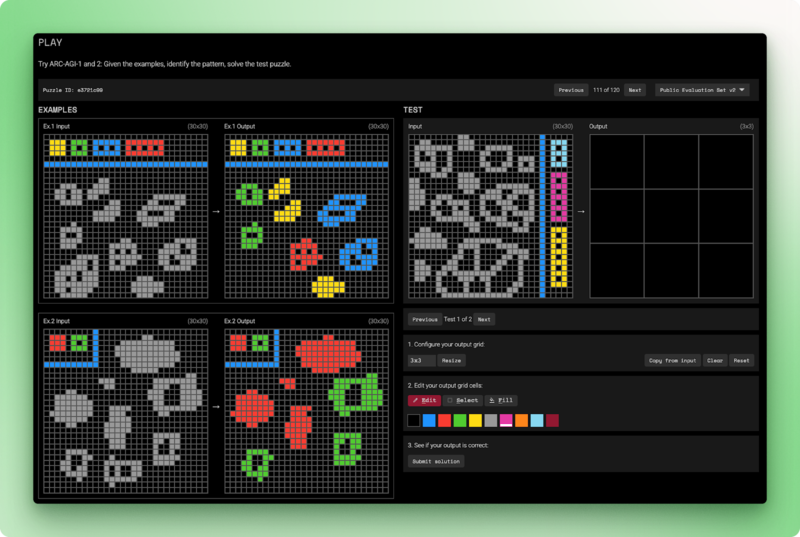
Con người giải những câu đố này dưới hai lần thử. Mô hình ngôn ngữ thuần đạt 0%. Hệ thống lai tốt nhất đạt 54%, với chi phí 30 đô mỗi tác vụ. ARC-AGI-2 kiểm tra trí thông minh linh hoạt: suy luận từ nguyên lý đầu tiên thay vì khớp mẫu đã thấy trong huấn luyện.
Benchmark tạo ra điểm số, nhưng bảng xếp hạng quyết định cách trình bày. Các nền tảng khác nhau ưu tiên yếu tố khác nhau: sở thích của con người, tính minh bạch nguồn mở, hay đánh giá đa chiều. Biết nên tham khảo bảng xếp hạng nào tùy vào điều bạn quan tâm đo lường.
LMArena (LMSYS Chatbot Arena) tiếp cận khác các benchmark tự động. Thay vì chấm câu trả lời theo thang điểm, nó yêu cầu con người chọn phản hồi tốt hơn. Người dùng gửi prompt, nhận kết quả từ hai mô hình ẩn danh, và bình chọn cái họ thích. Mô hình được giữ ẩn cho đến sau khi bỏ phiếu, tránh thiên kiến thương hiệu.
Nền tảng dùng mô hình thống kê Bradley-Terry để chuyển hơn 5 triệu lá phiếu cặp đôi thành xếp hạng. Tính đến tháng 12/2025, Gemini 3 Pro dẫn đầu Arena tổng thể với điểm 1501, theo sau là Grok 4.1 với 1483, rồi đến Claude Opus 4.5 và GPT-5.2.
LMArena nắm bắt điều benchmark bỏ lỡ: phản hồi có thực sự hữu ích hay không. Đổi lại, những câu trả lời dài dòng, tự tin có thể giành phiếu ngay cả khi có đáp án ngắn hơn nhưng chính xác hơn.
Open LLM Leaderboard của Hugging Face tập trung vào mô hình nguồn mở và chạy chúng qua các bài kiểm tra tiêu chuẩn bằng EleutherAI Evaluation Harness. Phiên bản 2 ra mắt tháng 6/2024 với benchmark khó hơn, sau khi các mô hình tiên phong đã bão hòa bộ bài kiểm tra gốc.
Bộ hiện tại gồm GPQA, MATH Level 5, và MMLU-PRO, với điểm chuẩn hóa nơi 0 là ngẫu nhiên và 100 là hoàn hảo. Các mô hình mở hàng đầu gồm Qwen3, Llama 3.3 70B, và DeepSeek V3.1, tất cả cạnh tranh ở mức sát nút với các mô hình đóng.
Stanford HELM (Holistic Evaluation of Language Models) đo lường nhiều hơn là kết quả có chính xác không. Mỗi mô hình được đánh giá theo bảy chiều cho mỗi kịch bản: độ chính xác, hiệu chỉnh, khả năng chống chịu, công bằng, thiên kiến, độc hại, và hiệu quả.
Khung này bao phủ 42 kịch bản và theo dõi rõ nơi mô hình thất bại, không chỉ nơi chúng thành công. HELM cũng có bảng xếp hạng an toàn riêng đánh giá rủi ro như bạo lực, lừa đảo, và quấy rối. Tính đến tháng 12/2025, Claude 3.5 Sonnet xếp hạng cao nhất về điểm an toàn tổng hợp.
Không có công ty nào chiến thắng ở mọi nơi. Tuy vậy, khi bạn đối chiếu vài bảng xếp hạng, các mẫu hình bắt đầu hiện ra.
Các mô hình Gemini của Google thống trị benchmark đa phương thức và suy luận khoa học. Gemini 3 Pro dẫn đầu GPQA Diamond với 91,9% và đứng đầu Arena tổng thể. Dòng Claude của Anthropic xuất sắc ở lập trình và an toàn. Claude Opus 4.5 giữ kỷ lục SWE-bench Verified ở 80,9%, và Claude 3.5 Sonnet dẫn đầu HELM Safety.
Các mô hình GPT của OpenAI vẫn là những "tay toàn năng", cạnh tranh trên hầu hết benchmark mà không có điểm yếu nổi bật. Dòng Llama của Meta cho thấy nguồn mở có thể sánh ngang mô hình đóng ở nhiều tác vụ, với Llama 3.3 70B cho đầu ra ngang ngửa hệ thống độc quyền lớn hơn nhiều.
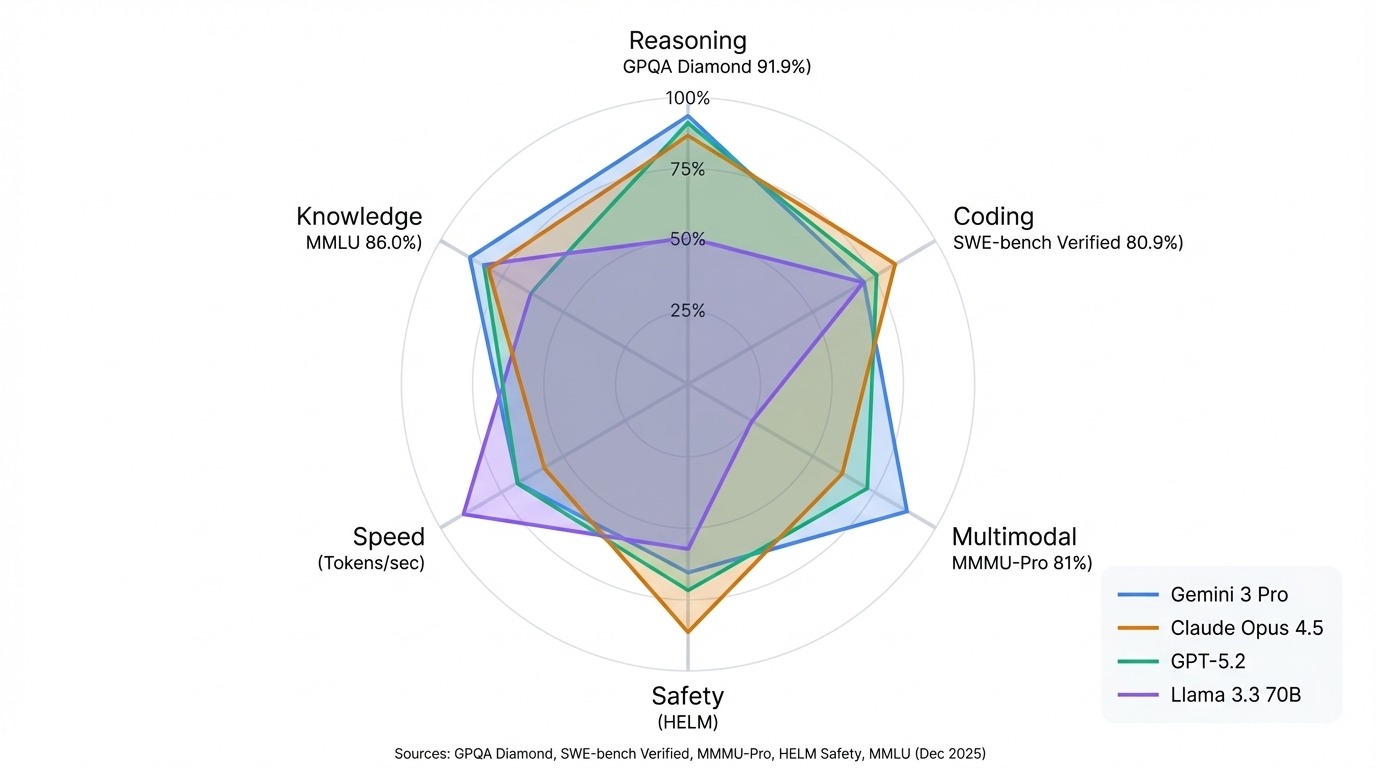
Mẫu hình quan trọng nhất: ghép bảng xếp hạng với trường hợp sử dụng. Arena phản ánh chất lượng hội thoại. HELM cho thấy độ tin cậy và an toàn. Hugging Face theo dõi những gì bạn có thể tự chạy. Một mô hình đứng đầu danh sách này có thể ở nhóm giữa ở danh sách khác, và đó không phải lỗi của xếp hạng. Đó là các phép đo khác nhau đo các điều khác nhau.
Bảng xếp hạng cho bạn biết mô hình so với nhau trên bài kiểm tra chuẩn, nhưng đôi khi bạn cần câu trả lời riêng cho tình huống của mình.
Bạn có thể đang chọn giữa các mô hình nguồn mở phù hợp phần cứng của bạn, hoặc xác minh một mô hình fine-tune không đánh mất khả năng suy luận tổng quát. Những trường hợp khác, benchmark chuẩn đơn giản là không bao phủ lĩnh vực của bạn.
Trong tất cả các trường hợp đó, bạn có thể cân nhắc tự benchmark LLM. Tôi sẽ chỉ bạn cách làm và những điều cần lưu ý.
EleutherAI LM Evaluation Harness là tiêu chuẩn ngành để chạy các đánh giá này tại chỗ. Nó vận hành Open LLM Leaderboard của Hugging Face và hỗ trợ hơn 60 benchmark.
Nó hoạt động khác cách đa số người dùng tương tác với chatbot. Nó không chỉ "trò chuyện" với mô hình; nó thực hiện phân tích toán học mang tính quyết định hơn.
Với câu hỏi trắc nghiệm, vốn phổ biến trong benchmark như MMLU hay ARC, harness không yêu cầu mô hình xuất "A", "B", "C" hay "D". Thay vào đó, nó tạo prompt riêng cho từng lựa chọn và hỏi mô hình mức độ khả dĩ của mỗi lựa chọn. Phương án có log-likelihood cao nhất được coi là lựa chọn của mô hình.
Các benchmark khác cần cách tiếp cận sinh văn bản, nơi mô hình tạo phản hồi đầy đủ thay vì chọn xác suất. Sau khi sinh xong, harness sẽ phân tích đầu ra bằng regex để trích xuất giá trị cụ thể nhằm so khớp với đáp án.
Hãy xem cách chạy đánh giá LLM đầu tiên.
Bạn có thể cài harness bằng pip:
pip install lm-evalTrước khi chạy đánh giá đầy đủ, hãy thử đường ống với mẫu nhỏ. Cờ --limit giới hạn benchmark ở số ví dụ chỉ định. Ví dụ này kiểm tra Qwen2.5-1.5B-Instruct, một mô hình nhỏ chạy được trên hầu hết phần cứng mà không cần GPU cao cấp, với benchmark HellaSwag:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Tác vụ |
Phiên bản |
Bộ lọc |
n-shot |
Chỉ số |
|
Giá trị |
|
Độ lệch chuẩn |
|
hellaswag |
1 |
none |
0 |
acc |
↑ |
0.3 |
± |
0.1528 |
|
none |
0 |
acc_norm |
↑ |
0.4 |
± |
0.1633 |
Đầu ra hiển thị hai chỉ số độ chính xác: acc là độ chính xác thô, còn acc_norm điều chỉnh thiên lệch của mô hình về phần hoàn thành ngắn hoặc dài. Ngoài ra, báo cáo độ lệch chuẩn, sẽ giảm khi kích thước mẫu tăng. Trong bài thử đầu tiên với chỉ 10 mẫu, Stderr cao (0,15) nghĩa là các điểm này chỉ là ước lượng thô.
Bỏ --limit để chạy trọn bộ benchmark. Để chạy nhiều benchmark trong một lượt, liệt kê bằng dấu phẩy:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsThiết lập --device theo phần cứng của bạn: mps cho Apple Silicon, cuda:0 cho GPU NVIDIA, hoặc cpu dự phòng. MMLU đầy đủ mất 1–2 giờ trên GPU hiện đại; benchmark nhỏ như HellaSwag hoàn tất trong vài phút.
Để kiểm tra độ trễ và thông lượng, Ollama chạy mô hình cục bộ và báo cáo số token mỗi giây qua các mức lượng tử hóa khác nhau. Mô hình 7B có thể sinh 100+ token/giây trên V100, trong khi mô hình 70B giảm xuống một chữ số.
Có một vài thực hành tốt cần ghi nhớ khi benchmark LLM.
Đầu tiên và quan trọng nhất, bạn phải đảm bảo mô hình chưa từng thấy câu hỏi đánh giá trong quá trình huấn luyện. Nếu có, bạn chỉ đang đo lường overfitting thay vì khả năng suy luận, như đã bàn lúc đầu. Khi đó, điểm benchmark trở nên vô nghĩa.
Để có kết quả tái lập, cần giảm tối đa biến thiên trong câu trả lời của mô hình. Có thể đạt được bằng cách đặt temperature về 0 để ưu tiên độ chính xác hơn tính sáng tạo.
Harness có sẵn prompt few-shot chuẩn hóa cho mỗi benchmark. Hãy dùng chúng thay vì tự viết prompt, vì thay đổi nhỏ về câu chữ ảnh hưởng điểm số nhiều hơn bạn nghĩ. Tuy nhiên, với công việc theo lĩnh vực, bạn luôn nên xây một bộ kiểm thử nhỏ từ ví dụ thực tế trong ngành trước khi chọn mô hình cho sản xuất.
Benchmark chuẩn rất giỏi kiểm tra sự thật, nhưng khó đo lường sắc thái. Với tác vụ mở như tóm tắt hay sáng tác, LLM-đóng-vai-trọng-tài dùng một mô hình mạnh hơn để chấm đầu ra theo độ hữu ích và chính xác.
Trọng tài thường được cung cấp thang điểm và được yêu cầu hoặc gán điểm số (ví dụ 1–10) hoặc so sánh cặp để quyết định câu trả lời nào tốt hơn. Dù không hoàn hảo, các phán xét này tương đồng với sở thích của con người khoảng 80–85%. Vì vậy, LLM-đóng-vai-trọng-tài là lựa chọn có thể mở rộng thay cho đánh giá thủ công tốn kém.
Đánh giá AI đang thay đổi nhanh như chính các mô hình. Khi các benchmark như MMLU bão hòa, giới nghiên cứu xây các bài kiểm tra khó hơn để thăm dò chiều sâu suy luận thay vì kiến thức ghi nhớ. FrontierMath và Humanity's Last Exam đại diện cho mặt trận độ khó mới, nơi ngay cả mô hình tốt nhất cũng chật vật.
Những tín hiệu rộng hơn chỉ về một hướng: nhiều tài nguyên tính toán huấn luyện hơn, thuật toán thông minh hơn, và bộ benchmark theo kịp tiến bộ. Các bài kiểm tra đa phương thức đang mở rộng phạm vi yêu cầu mô hình làm, từ đọc biểu đồ đến hiểu chuỗi video.
Nhưng thông điệp vẫn đơn giản. Không một điểm số nào kể hết câu chuyện. Mô hình dẫn đầu Arena có thể tụt hậu ở SWE-bench. Mô hình lập trình đứng đầu có thể ở nhóm giữa về an toàn. Hãy ghép benchmark với thứ bạn thực sự cần: suy luận, sinh mã, hiểu thị giác, hay tốc độ thuần. Đó là phép so sánh duy nhất quan trọng.
Để đưa năng lực của bạn vượt ra ngoài benchmark, hãy học xây dựng và fine-tune LLM với Developing Large Language Models skill track của chúng tôi.
Khóa học về LLM
Tracks
Tracks
Courses