Python'da Derin Öğrenmeye Giriş
247.1K learners

Bu PyTorch eğitiminde, sinir ağlarını çalıştıran temel işlevleri ele alacak ve sıfırdan kendi ağımızı kuracağız. Bu makalenin temel amacı, optimize edilmiş bir derin öğrenme tensör kütüphanesi olan PyTorch'un temellerini göstermek ve aynı zamanda sinir ağlarının nasıl çalıştığına dair ayrıntılı bir arka plan sağlamaktır.
Not: Bu makalede yazılan kodu adım adım takip etmek için şu DataCamp çalışma alanına göz atın.
Sinir ağları, yapay sinir ağları (YSA) olarak da adlandırılır. Bu mimari, insan beyninin yapısından ve işlevinden ilham alan algoritmalarla ilgilenen makine öğrenmesinin bir alt kümesi olan derin öğrenmenin temelini oluşturur. Basitçe söylemek gerekirse, sinir ağları biyolojik nöronların birbirlerine nasıl sinyal gönderdiğini taklit eden mimarilerin temelini oluşturur.
Bu nedenle, sinir ağının görsel olarak nasıl çalıştığını kavramanıza yardımcı olmak için ilk birkaç dakikasını beynin sinir yapısını haritalamaya ayıran kaynaklara sıkça rastlarsınız. Ancak fazladan beş dakikanız olmadığında, sinir ağını girdileri istenen çıktılara eşleyen bir fonksiyon olarak tanımlamak daha kolaydır.
Genel sinir ağı mimarisi aşağıdakilerden oluşur:
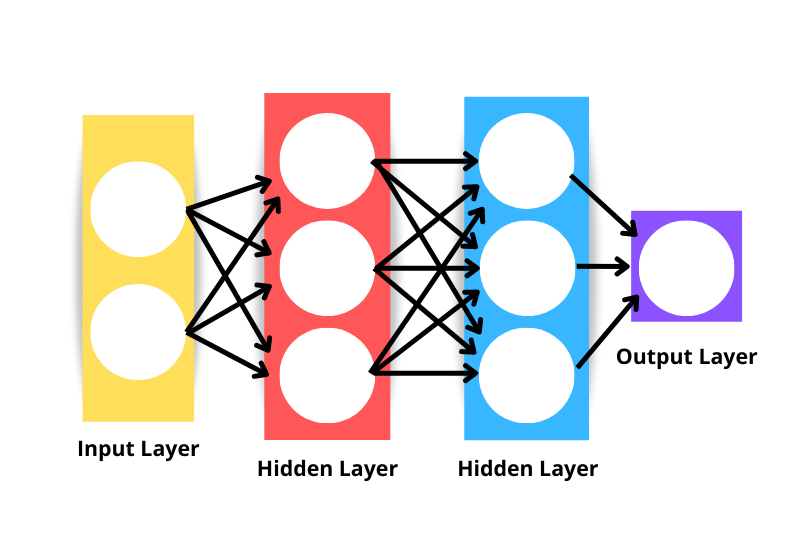
Yukarıdaki görseldeki sinir ağı, dört değil üç katmanlı sinir ağı olarak kabul edilir; çünkü girdi katmanını katman olarak dahil etmeyiz. Dolayısıyla bir ağdaki katman sayısı, gizli katmanların sayısı ile çıktı katmanının toplamıdır.
Sinir ağlarının nasıl çalıştığını daha iyi anlamak için algoritmayı daha küçük bileşenlere ayıralım.
Ağırlık başlatma, sinir ağı mimarisindeki ilk bileşendir. Başlangıç ağırlıkları, sinir ağı modelinin optimizasyon süreci için başlangıç noktasını tanımlar.
Ağırlıkları nasıl belirlediğimiz özellikle derin ağlar kurarken önemlidir. Çünkü derin ağlar, patlayan veya sönümlenen gradyan sorununa daha yatkındır. sönümlenen ve patlayan gradyan problemleri bu makalenin kapsamını aşan iki kavramdır, ancak her ikisi de algoritmanın öğrenemediği bir durumu tanımlar.
Her ne kadar ağırlık başlatma sönümlenen veya patlayan gradyan sorununu tamamen çözmese de, kesinlikle önlenmesine katkı sağlar.
İşte birkaç yaygın ağırlık başlatma yaklaşımı:
Sıfırdan başlatma, ağırlıkların sıfır olarak başlatılması anlamına gelir. Bu iyi bir çözüm değildir çünkü sinir ağımız simetriyi kıramaz - öğrenemez.
Bir sinir ağının ağırlıklarını başlatmak için sabit bir değer kullanıldığında, tüm katmanlar aynı şeyi öğreneceğinden zayıf performans bekleyebiliriz. Gizli birimlerin tüm çıktıları maliyet üzerinde aynı etkiye sahipse, gradyanlar da özdeş olacaktır.
Rastgele başlatma simetriyi kırar; bu nedenle sıfırdan başlatmadan daha iyidir, ancak bazı faktörler modelin genel kalitesini belirleyebilir.
Örneğin, ağırlıklar büyük değerlerle rastgele başlatılırsa her matris çarpımının çok daha büyük bir değerle sonuçlanmasını bekleyebiliriz. Böyle senaryolarda sigmoid aktivasyon fonksiyonu uygulandığında sonuç bire yakın bir değer olur ve bu da öğrenme hızını yavaşlatır.
Rastgele başlatmanın sorun yaratabileceği bir diğer senaryo da ağırlıkların küçük değerlere rastgele başlatılmasıdır. Bu durumda, her matris çarpımı çok daha küçük değerler üretecek ve sigmoid fonksiyonu uygulandığında sıfıra daha yakın bir değer döndürecektir; bu da öğrenme hızını yine yavaşlatır.
Xavier veya Glorot başlatma - her iki adla da anılır - ağırlıkları başlatmak için kullanılan sezgisel bir yaklaşımdır. Tanjant hiperbolik (tanh) veya sigmoid aktivasyon fonksiyonu ağırlıklı ortalamaya uygulandığında bu yaklaşımı görmek yaygındır. Yaklaşım ilk olarak 2010'da Xavier Glorot ve Yoshua Bengio'nun Understanding the difficulty of training deep feedforward neural networks başlıklı araştırma makalesinde önerildi. Bu başlatma tekniğinin amacı, ağ genelinde varyansı eşit tutarak gradyanların patlamasını veya sönümlenmesini önlemektir.
He veya Kaiming başlatma da başka bir sezgisel yaklaşımdır. He ve Xavier sezgisinden farkı, He başlatmanın, aktivasyon fonksiyonlarının doğrusal olmayanlığını dikkate alan farklı bir ölçekleme katsayısı kullanmasıdır.
Bu nedenle, katmanlarda ReLU aktivasyon fonksiyonu kullanıldığında He başlatma önerilir. Bu yaklaşımla ilgili daha fazla bilgiyi He ve arkadaşlarının Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification çalışmasında bulabilirsiniz.
Sinir ağları, ağırlıklı ortalama ile bir bias terimini alıp bir aktivasyon fonksiyonu uygulayarak doğrusal olmayan bir dönüşüm eklemek suretiyle çalışır. Ağırlıklı ortalama formülasyonunda, her bir ağırlık her özelliğin önemini belirler (yani çıktının tahminine ne kadar katkıda bulunduğunu).
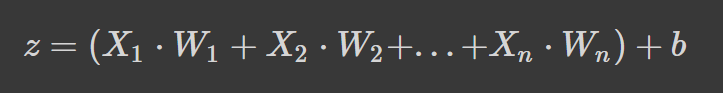
Yukarıdaki formül, bias terimi eklenmiş ağırlıklı ortalamadır ve burada,
Formül tanıdık geliyorsa bunun nedeni doğrusal regresyon olmasıdır. Nöronlara doğrusal olmayanlık katmadan doğrusal regresyon elde ederdik ki bu basit bir modeldir. Doğrusal olmayan dönüşüm, sinir ağımızın karmaşık örüntüleri öğrenmesine olanak tanır.
Ağırlık başlatma bölümünde bazı aktivasyon fonksiyonlarına değinmiştik; şimdi ise sinir ağı mimarisinde neden bu kadar önemli olduklarını biliyorsunuz.
Araştırma makaleleri ve başkalarının kodlarını okurken sıkça karşınıza çıkacak bazı yaygın aktivasyon fonksiyonlarına daha yakından bakalım.
Sigmoid fonksiyonu, sıfır ile bir değerleri arasında sınırlı, “S” şeklinde bir eğriyle karakterizedir. Türevi alınabilir bir fonksiyondur, yani eğrinin herhangi iki noktasındaki eğimi bulunabilir; ve tekdüze (monotonik) olup bütünüyle artan veya azalan değildir. Sigmoid aktivasyon fonksiyonunu genellikle ikili sınıflandırma problemlerinde kullanırsınız.
İşte Python kullanarak kendi sigmoid fonksiyonunuzu nasıl görselleştirebileceğiniz:
# Sigmoid function in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = 1/(1 + np.exp(-x))
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()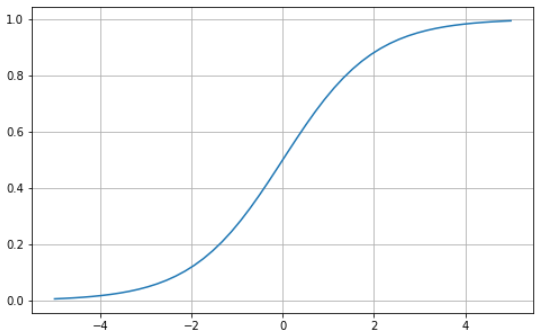
Hiperbolik tanjant (tanh), sigmoid fonksiyonuyla aynı “S” şeklindeki eğriye sahiptir; ancak değerler -1 ile 1 arasında sınırlıdır. Dolayısıyla küçük girdiler -1'e, daha büyük girdiler ise 1'e daha yakın değerlerle eşlenir.
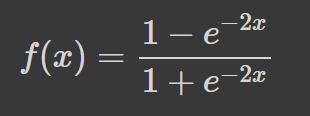
İşte Python kullanılarak görselleştirilmiş bir tanh fonksiyonu örneği:
# tanh function in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = np.tanh(x)
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()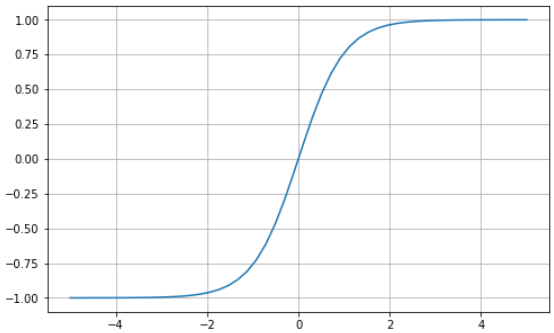
Softmax fonksiyonu genellikle çıktı katmanında aktivasyon fonksiyonu olarak kullanılır. Sigmoid fonksiyonunun çok boyutlu genellemesidir. Bu nedenle, ikiden fazla etiket üzerinde sınıf üyeliğini tahmin etmek için sinir ağlarında kullanılır.
Derin sinir ağları kurarken sigmoid veya tanh fonksiyonunu kullanmak risklidir; çünkü sönümlenen gradyan problemine daha yatkındırlar. Düzleştirilmiş doğrusal birim (ReLU) aktivasyon fonksiyonu bu soruna bir çözüm olarak ortaya çıktı ve birçok sinir ağı için sıklıkla varsayılan aktivasyon fonksiyonudur.
İşte Python kullanarak ReLU fonksiyonuna görsel bir örnek:
# ReLU in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = [max(0, i) for i in x]
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()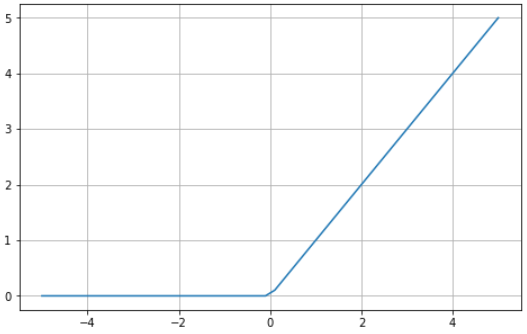
ReLU sıfır ile sonsuz arasında sınırlıdır: girdi değeri sıfırdan küçük veya eşitse fonksiyon sıfır döndürür; sıfırın üzerindeki değerler için girilen değeri geri verir (yani iki girerseniz iki döner). Nihayetinde, ReLU fonksiyonu doğrusal bir fonksiyona oldukça benzer davranır; bu da optimize etmeyi ve uygulamayı çok daha kolay hale getirir.
Girdiden çıktı katmanına kadar olan süreç ileri geçiş veya ileri besleme olarak bilinir. Bu aşamada, model tarafından üretilen çıktılar bir maliyet fonksiyonu hesaplamak için kullanılır ve her yineleme sonrasında sinir ağının performansı değerlendirilir. Bu bilgi daha sonra geri yayılım adı verilen bir süreçle model üzerinden geri geçirilerek ağırlıklar düzeltilir ve modelin daha iyi tahmin yapması sağlanır.
İlk ileri geçişin sonunda, ağ henüz ayarlanmamış başlatılmış ağırlıkları kullanarak tahminler yapar. Dolayısıyla modelin yaptığı tahminlerin doğru olmama olasılığı yüksektir. İleri beslemeden hesaplanan kaybı kullanarak, geri yayılım adı verilen bir süreçte ağırlıkları ince ayar yapmak üzere bilgiyi ağdan geri geçiririz.
Sonuçta, hata oranını azaltabilecek ağırlıkları belirlememize yardımcı olması için optimizasyon fonksiyonunu kullanıyoruz; bu da modeli daha güvenilir kılar ve yeni örneklere genelleme yeteneğini artırır. Bunun nasıl çalıştığına dair matematiksel detaylar bu makalenin kapsamı dışındadır; ancak ilgilenen okuyucu geri yayılım hakkında daha fazla bilgiyi Python'da Derin Öğrenmeye Giriş kursumuzda edinebilir.
Bu bölümde, PyTorch kütüphanesini kullanarak basit bir yapay sinir ağı modeli kuracağız. Kodları takip etmek için şu DataCamp çalışma alanına göz atın
PyTorch, derin öğrenme için en popüler kütüphanelerden biridir. TensorFlow'a kıyasla çok daha doğrudan bir hata ayıklama deneyimi sunar. Dağıtık eğitim, sağlam bir ekosistem, bulut desteği, üretime hazır kod yazma imkânı gibi çeşitli avantajlara sahiptir. PyTorch hakkında daha fazla bilgiyi PyTorch ile Derin Öğrenmeye Giriş beceri yolunda edinebilirsiniz.
Hadi eğitime başlayalım.
Bu eğitimde kullanacağımız veri kümesi, scikit-learn'den make_circles'tır - dokümantasyona bakın. İki boyutlu bir düzlemde büyük bir daire içinde daha küçük bir daire ve iki özellik içeren bir oyuncak veri kümesidir. Gösterimimiz için 10.000 örnek kullandık ve verilere 0,05 standart sapmalı Gauss gürültüsü ekledik.
Sinir ağımızı kurmadan önce, modelin görülmemiş veriler üzerindeki performansını değerlendirebilmek için verimizi eğitim ve test kümelerine ayırmak iyi bir uygulamadır.
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
# Create a dataset with 10,000 samples.
X, y = make_circles(n_samples = 10000,
noise= 0.05,
random_state=26)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.33, random_state=26)
# Visualize the data.
fig, (train_ax, test_ax) = plt.subplots(ncols=2, sharex=True, sharey=True, figsize=(10, 5))
train_ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Spectral)
train_ax.set_title("Training Data")
train_ax.set_xlabel("Feature #0")
train_ax.set_ylabel("Feature #1")
test_ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test)
test_ax.set_xlabel("Feature #0")
test_ax.set_title("Testing data")
plt.show()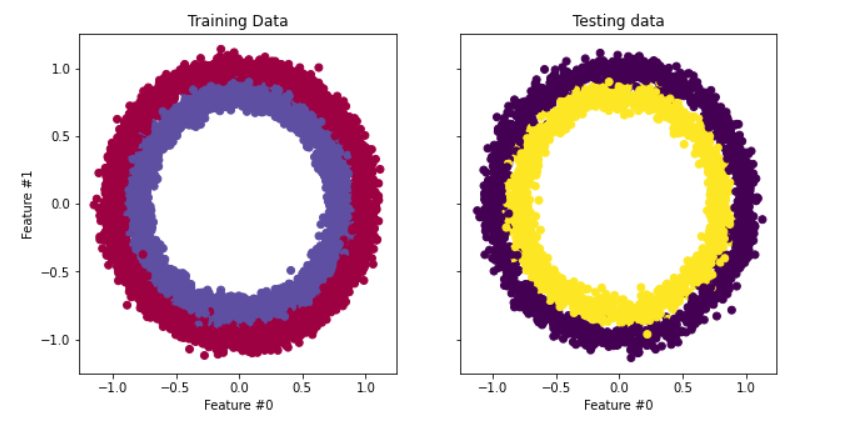
Bir sonraki adım, eğitim ve test verilerini NumPy dizilerinden PyTorch tensörlerine dönüştürmektir. Bunu yapmak için eğitim ve test dosyalarımız için özel bir veri kümesi oluşturacağız. Ayrıca verimizi partiler (batch) hâlinde eğitebilmek için PyTorch’un Dataloader modülünden yararlanacağız. Kod şöyle:
import warnings
warnings.filterwarnings("ignore")
!pip install torch -q
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
# Convert data to torch tensors
class Data(Dataset):
def __init__(self, X, y):
self.X = torch.from_numpy(X.astype(np.float32))
self.y = torch.from_numpy(y.astype(np.float32))
self.len = self.X.shape[0]
def __getitem__(self, index):
return self.X[index], self.y[index]
def __len__(self):
return self.len
batch_size = 64
# Instantiate training and test data
train_data = Data(X_train, y_train)
train_dataloader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
test_data = Data(X_test, y_test)
test_dataloader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
# Check it's working
for batch, (X, y) in enumerate(train_dataloader):
print(f"Batch: {batch+1}")
print(f"X shape: {X.shape}")
print(f"y shape: {y.shape}")
break
"""
Batch: 1
X shape: torch.Size([64, 2])
y shape: torch.Size([64])
"""Şimdi sinir ağımızı uygulamaya ve eğitmeye geçelim.
ReLU aktivasyon fonksiyonunu (torch.nn.functional.relu) kullanan basit bir iki katmanlı sinir ağı uygulayacağız. Bunu yapmak için, PyTorch'ta tüm sinir ağı modüllerinin temel sınıfı olan nn.Module'den miras alan NeuralNetwork adlı bir sınıf oluşturacağız.
Kod şöyle:
import torch
from torch import nn
from torch import optim
input_dim = 2
hidden_dim = 10
output_dim = 1
class NeuralNetwork(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(NeuralNetwork, self).__init__()
self.layer_1 = nn.Linear(input_dim, hidden_dim)
nn.init.kaiming_uniform_(self.layer_1.weight, nonlinearity="relu")
self.layer_2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = torch.nn.functional.relu(self.layer_1(x))
x = torch.nn.functional.sigmoid(self.layer_2(x))
return x
model = NeuralNetwork(input_dim, hidden_dim, output_dim)
print(model)
"""
NeuralNetwork(
(layer_1): Linear(in_features=2, out_features=10, bias=True)
(layer_2): Linear(in_features=10, out_features=1, bias=True)
)
"""Ve hepsi bu kadar.
Modeli eğitmek için, gradyanları hesaplamak üzere kullanacağımız bir kayıp fonksiyonu ve parametreleri güncellemek için bir optimize edici tanımlamalıyız. Gösterimimizde, öğrenme oranı 0,1 olan ikili çapraz entropi ve stokastik gradyan inişi kullanacağız.
learning_rate = 0.1
loss_fn = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=leaHaydi modelimizi eğitelim
num_epochs = 100
loss_values = []
for epoch in range(num_epochs):
for X, y in train_dataloader:
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
pred = model(X)
loss = loss_fn(pred, y.unsqueeze(-1))
loss_values.append(loss.item())
loss.backward()
optimizer.step()
print("Training Complete")
"""
Training Complete
"""Kayıp değerlerini izlediğimiz için, modelin zaman içindeki kaybını görselleştirebiliriz.
step = range(len(loss_values))
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(step, np.array(loss_values))
plt.title("Step-wise Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()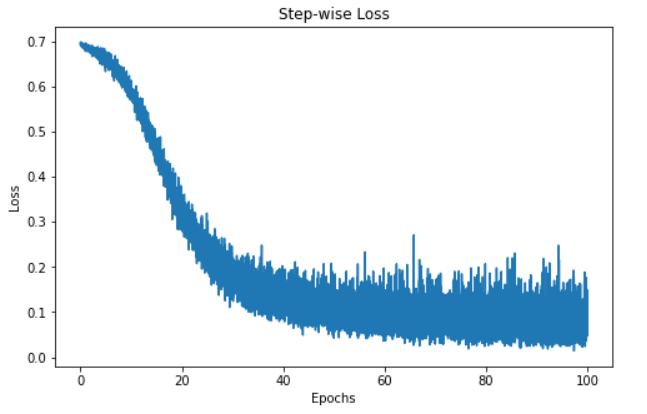
Yukarıdaki görselleştirme, modelimizin 100 epoch boyunca kaybını gösteriyor. Başlangıçta kayıp 0,7 seviyesindeydi ve kademeli olarak azaldı - bu da modelimizin zamanla tahminlerini iyileştirdiğini gösterir. Ancak, model yaklaşık 60. epoch civarında plato yapıyor gibi görünüyor; bunun çeşitli nedenleri olabilir, örneğin model, kayıp fonksiyonunun yerel veya küresel bir minimum bölgesinde olabilir.
Yine de model eğitildi ve yeni örneklerde tahmin yapmaya hazır - bir sonraki bölümde bunun nasıl yapılacağına bakalım.
PyTorch sinir ağımızla tahmin yapmak oldukça basittir.
import itertools # Import this at the top of your script
# Initialize required variables
y_pred = []
y_test = []
correct = 0
total = 0
"""
We're not training so we don't need to calculate the gradients for our outputs
"""
with torch.no_grad():
for X, y in test_dataloader:
outputs = model(X) # Get model outputs
predicted = np.where(outputs.numpy() < 0.5, 0, 1) # Convert to NumPy and apply threshold
predicted = list(itertools.chain(*predicted)) # Flatten predictions
y_pred.append(predicted) # Append predictions
y_test.append(y.numpy()) # Append true labels as NumPy
total += y.size(0) # Increment total count
correct += (predicted == y.numpy()).sum().item() # Count correct predictions
print(f'Accuracy of the network on the 3300 test instances: {100 * correct // total}%')
"""
Accuracy of the network on the 3300 test instances: 97%
"""
Not: Kodu her çalıştırdığınızda farklı bir çıktı üretileceğinden, aynı sonuçları elde etmeyebilirsiniz.
Yukarıdaki kod, test_dataloader değişkeninde saklanan test partileri boyunca gradyanları hesaplamadan döngü kurar. Daha sonra, partideki örnekleri tahmin eder ve sonuçları outputs adlı bir değişkende saklarız. Ardından, 0,5'ten küçük tüm değerleri 0'a, 0,5'e eşit veya daha büyük olanları 1'e ayarlarız. Bu değerler tahminlerimiz için bir listeye eklenir.
Bundan sonra, partideki örneklerin gerçek tahminlerini total adlı bir değişkene ekleriz. Ardından, gerçek sınıflarla eşit olan tahminlerin sayısını belirleyerek doğru tahminlerin sayısını hesaplarız ve bunları toplarız. Her parti için doğru tahminlerin toplam sayısı artırılır ve correct değişkenimizde saklanır.
Genel modelin doğruluğunu hesaplamak için, doğru tahminlerin sayısını 100 ile çarparız (yüzde elde etmek için) ve ardından test setimizdeki örnek sayısına böleriz. Modelimiz %97 doğruluk elde etti. Performansı daha iyi anlamak için karışıklık matrisi ve scikit-learn’ün classification_report çıktısını kullanarak daha derine iniyoruz.
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = list(itertools.chain(*y_pred))
y_test = list(itertools.chain(*y_test))
print(classification_report(y_test, y_pred))
"""
precision recall f1-score support
0.0 0.98 0.97 0.98 1635
1.0 0.98 0.98 0.98 1665
accuracy 0.98 3300
macro avg 0.98 0.98 0.98 3300
weighted avg 0.98 0.98 0.98 3300
"""
cf_matrix = confusion_matrix(y_test, y_pred)
plt.subplots(figsize=(8, 5))
sns.heatmap(cf_matrix, annot=True, cbar=False, fmt="g")
plt.show()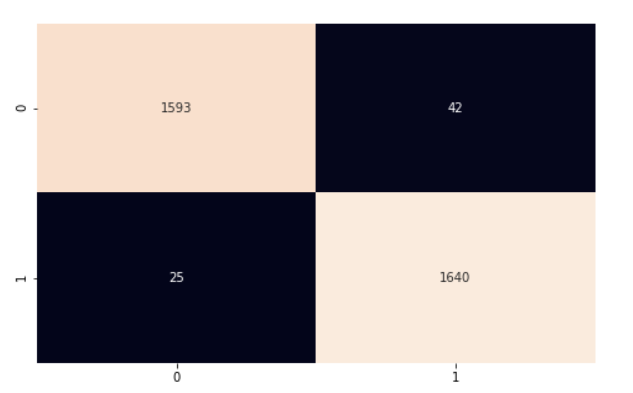
Modelimiz oldukça iyi performans gösteriyor. Bu makalede ele aldıklarımızın pekişmesi için kodu keşfetmenizi ve bazı değişiklikler yapmanızı öneririm.
Bu PyTorch eğitiminde, sinir ağlarının temel prensiplerini ele aldık ve derin öğrenme için bir Python kütüphanesi olan PyTorch'u kullanarak ağımızı uyguladık. Sınıflandırma için scikit-learn’ün daire veri kümesini kullanarak iki katmanlı bir sinir ağını eğittik. Ardından veriler üzerinde tahminler yaptık ve sonuçlarımızı doğruluk metriğini kullanarak değerlendirdik.
Python için Kurslar
Kurs
Kurs