Introduction to Deep Learning in Python
BasicSkill Level
4 h
263.1K learners

In questo tutorial su PyTorch vedremo le funzioni fondamentali che alimentano le reti neurali e costruiremo la nostra da zero. L'obiettivo principale dell'articolo è mostrare le basi di PyTorch, una libreria di tensori per il deep learning ottimizzata, fornendoti al contempo un quadro dettagliato di come funzionano le reti neurali.
Nota: dai un'occhiata a questo workspace su DataCamp per seguire il codice scritto in questo articolo.
Le reti neurali sono chiamate anche reti neurali artificiali (ANN). Questa architettura è alla base del deep learning, un sottoinsieme del machine learning che si occupa di algoritmi ispirati alla struttura e al funzionamento del cervello umano. In parole semplici, le reti neurali sono l'ossatura di architetture che imitano il modo in cui i neuroni biologici si inviano segnali a vicenda.
Di conseguenza, spesso troverai risorse che dedicano i primi cinque minuti a mappare la struttura neurale del cervello umano per aiutarti a visualizzare come funziona una rete neurale. Ma quando non hai cinque minuti da spendere, è più facile definire una rete neurale come una funzione che mappa input a output desiderati.
L'architettura generica di una rete neurale è composta da:
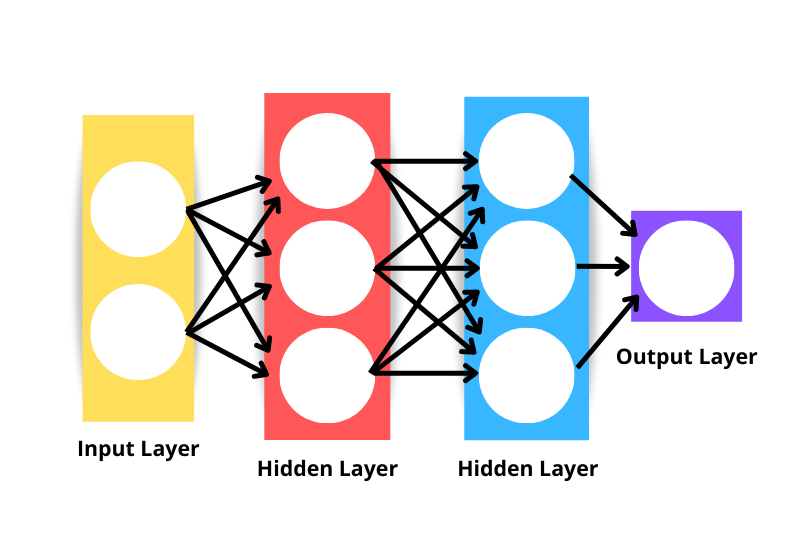
Nota che la rete neurale mostrata nell'immagine sopra sarebbe considerata a tre strati e non a quattro: questo perché non includiamo lo strato di input nel conteggio. Quindi, il numero di strati in una rete è dato dal numero di strati nascosti più lo strato di output.
Scomponiamo l'algoritmo in componenti più piccoli per capire meglio come funzionano le reti neurali.
L'inizializzazione dei pesi è il primo componente dell'architettura di una rete neurale. I pesi iniziali che impostiamo definiscono il punto di partenza per il processo di ottimizzazione del modello.
Il modo in cui impostiamo i pesi è importante, soprattutto quando costruisci reti profonde. Questo perché le reti profonde sono più soggette al problema del gradiente esplosivo o evanescente. I problemi di gradiente evanescente ed esplosivo sono due concetti al di fuori dell'ambito di questo articolo, ma descrivono entrambi uno scenario in cui l'algoritmo non riesce a imparare.
Ecco alcuni approcci comuni di inizializzazione dei pesi:
L'inizializzazione a zero significa che i pesi sono inizializzati a zero. Non è una buona soluzione perché la nostra rete neurale non riuscirebbe a rompere la simmetria: non imparerebbe.
Ogni volta che si usa un valore costante per inizializzare i pesi di una rete neurale, ci si può aspettare prestazioni scarse, poiché tutti gli strati impareranno la stessa cosa. Se tutte le uscite delle unità nascoste hanno la stessa influenza sul costo, anche i gradienti saranno identici.
L'inizializzazione casuale rompe la simmetria, quindi è meglio dell'inizializzazione a zero, ma alcuni fattori possono influenzare la qualità complessiva del modello.
Per esempio, se i pesi sono inizializzati casualmente con valori grandi, ci si può aspettare che ogni moltiplicazione di matrici produca un valore significativamente più grande. Quando in tali scenari si applica una funzione di attivazione sigmoide, il risultato è un valore vicino a uno, il che rallenta la velocità di apprendimento.
Un altro scenario in cui l'inizializzazione casuale può causare problemi è quando i pesi sono inizializzati casualmente con valori piccoli. In questo caso, ogni moltiplicazione di matrici produrrà valori significativamente più piccoli e applicare una funzione sigmoide restituirà un valore più vicino a zero, il che rallenta comunque la velocità di apprendimento.
L'inizializzazione Xavier o Glorot è un approccio euristico usato per inizializzare i pesi. È comune vedere questo approccio quando si applica una funzione di attivazione tanh o sigmoide alla media pesata. L'approccio è stato proposto per la prima volta nel 2010 nell'articolo di ricerca Understanding the difficulty of training deep feedforward neural networks di Xavier Glorot e Yoshua Bengio. Questa tecnica di inizializzazione mira a mantenere costante la varianza nella rete per evitare che i gradienti esplodano o scompaiano.
L'inizializzazione He o Kaiming è un altro approccio euristico. La differenza rispetto all'euristica di Xavier è che He utilizza un diverso fattore di scala per i pesi che tiene conto della non linearità delle funzioni di attivazione.
Quindi, quando si usa la funzione di attivazione ReLU negli strati, l'inizializzazione He è l'approccio consigliato. Puoi approfondire in Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification di He et al.
Le reti neurali funzionano calcolando una media pesata più un termine di bias e applicando una funzione di attivazione per aggiungere una trasformazione non lineare. Nella formulazione della media pesata, ogni peso determina l'importanza di ciascuna feature (cioè quanto contribuisce a prevedere l'output).
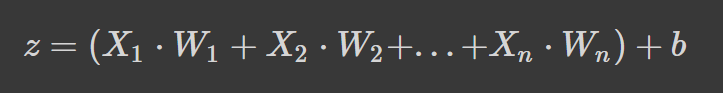
La formula sopra è la media pesata più un termine di bias, dove
Se la formula ti sembra familiare è perché è la regressione lineare. Senza introdurre la non linearità nei neuroni, avremmo una regressione lineare, che è un modello semplice. La trasformazione non lineare permette alla rete neurale di imparare pattern complessi.
Abbiamo già accennato ad alcune funzioni di attivazione nella sezione inizializzazione dei pesi, ma ora conosci anche la loro importanza in un'architettura di rete neurale.
Approfondiamo alcune funzioni di attivazione comuni che è probabile tu veda leggendo articoli di ricerca e il codice di altre persone.
La funzione sigmoide è caratterizzata da una curva a forma di "S" compresa tra zero e uno. È una funzione derivabile, il che significa che la pendenza della curva può essere trovata in qualsiasi coppia di punti, ed è monotòna, cioè non è interamente crescente né interamente decrescente. In genere useresti la sigmoide per problemi di classificazione binaria.
Ecco come puoi visualizzare la tua sigmoide in Python:
# Sigmoid function in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = 1/(1 + np.exp(-x))
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()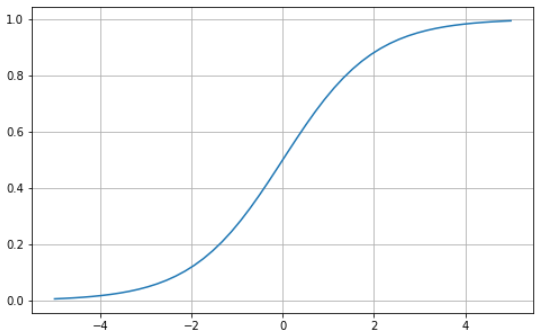
La tangente iperbolica (tanh) ha la stessa curva a "S" della sigmoide, tranne che i valori sono compresi tra -1 e 1. Quindi, gli input piccoli vengono mappati più vicino a -1, e quelli grandi più vicino a 1.
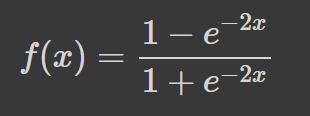
Ecco un esempio di funzione tanh visualizzata con Python:
# tanh function in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = np.tanh(x)
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()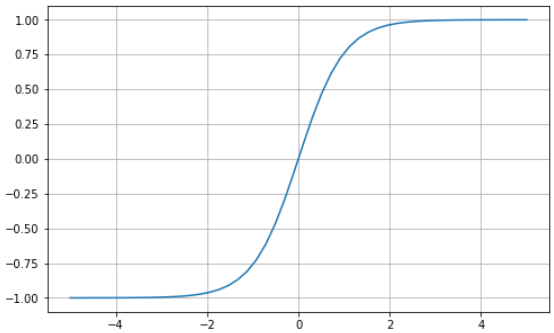
La funzione softmax è generalmente usata come funzione di attivazione nello strato di output. È una generalizzazione della sigmoide a più dimensioni. Perciò viene usata nelle reti neurali per prevedere l'appartenenza a classi su più di due etichette.
Usare la sigmoide o la tanh per costruire reti neurali profonde è rischioso, poiché sono più soggette al problema del gradiente evanescente. La funzione di attivazione rectified linear unit (ReLU) è arrivata come soluzione a questo problema ed è spesso la funzione di attivazione predefinita per diverse reti neurali.
Ecco un esempio visivo della funzione ReLU in Python:
# ReLU in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = [max(0, i) for i in x]
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()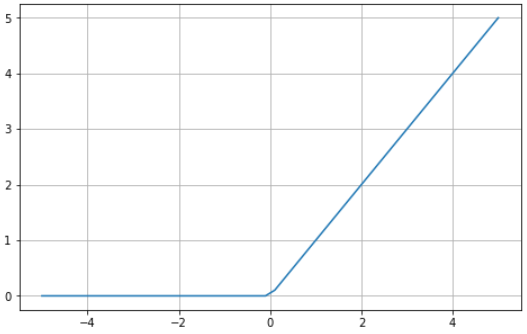
La ReLU è compresa tra zero e infinito: nota che per valori di input minori o uguali a zero la funzione restituisce zero, mentre per valori maggiori di zero restituisce il valore di input fornito (cioè, se inserisci due, verrà restituito due). In definitiva, la ReLU si comporta in modo molto simile a una funzione lineare, rendendola più facile da ottimizzare e implementare.
Il processo dallo strato di input a quello di output è noto come forward pass o propagazione in avanti. In questa fase, le uscite generate dal modello vengono usate per calcolare una funzione di costo e determinare come la rete neurale sta performando dopo ogni iterazione. Queste informazioni vengono poi fatte risalire attraverso il modello per correggere i pesi, così che il modello possa fare previsioni migliori, in un processo noto come backpropagation.
Alla fine della prima propagazione in avanti, la rete fa previsioni usando i pesi inizializzati, che non sono ottimizzati. È quindi molto probabile che le previsioni del modello non siano accurate. Usando la loss calcolata nella propagazione in avanti, facciamo risalire le informazioni attraverso la rete per mettere a punto i pesi in un processo noto come backpropagation.
In sostanza, usiamo la funzione di ottimizzazione per aiutarci a individuare i pesi che possono ridurre il tasso di errore, rendendo il modello più affidabile e aumentando la sua capacità di generalizzare a nuove istanze. La matematica di come questo funzioni è oltre lo scopo di questo articolo, ma chi è interessato può approfondire la backpropagation nel nostro corso Introduction to Deep Learning in Python.
In questa sezione costruiremo un semplice modello di rete neurale artificiale usando la libreria PyTorch. Dai un'occhiata a questo workspace DataCamp per seguire il codice
PyTorch è una delle librerie più popolari per il deep learning. Offre un'esperienza di debug molto più diretta rispetto a TensorFlow. Ha anche diversi altri vantaggi come il training distribuito, un ecosistema solido, il supporto cloud, la possibilità di scrivere codice pronto per la produzione, ecc. Puoi saperne di più su PyTorch nello skill track Introduction to Deep Learning with PyTorch.
Passiamo al tutorial.
Il dataset che useremo nel tutorial è make_circles di scikit-learn: vedi la documentazione. È un dataset giocattolo che contiene un cerchio grande con un cerchio più piccolo in un piano bidimensionale e due feature. Per la nostra dimostrazione, abbiamo usato 10.000 campioni e aggiunto una deviazione standard di 0,05 di rumore gaussiano ai dati.
Prima di costruire la rete neurale, è buona pratica dividere i dati in training e test set, così da valutare le prestazioni del modello su dati mai visti.
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
# Create a dataset with 10,000 samples.
X, y = make_circles(n_samples = 10000,
noise= 0.05,
random_state=26)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.33, random_state=26)
# Visualize the data.
fig, (train_ax, test_ax) = plt.subplots(ncols=2, sharex=True, sharey=True, figsize=(10, 5))
train_ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Spectral)
train_ax.set_title("Training Data")
train_ax.set_xlabel("Feature #0")
train_ax.set_ylabel("Feature #1")
test_ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test)
test_ax.set_xlabel("Feature #0")
test_ax.set_title("Testing data")
plt.show()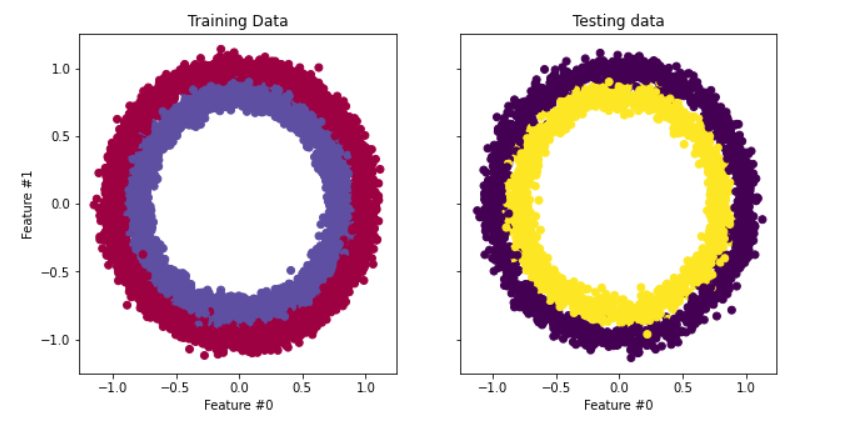
Il passo successivo è convertire i dati di training e test da array NumPy a tensori PyTorch. Per farlo creeremo un dataset personalizzato per i nostri file di training e test. Useremo anche il modulo Dataloader di PyTorch per addestrare i dati in batch. Ecco il codice:
import warnings
warnings.filterwarnings("ignore")
!pip install torch -q
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
# Convert data to torch tensors
class Data(Dataset):
def __init__(self, X, y):
self.X = torch.from_numpy(X.astype(np.float32))
self.y = torch.from_numpy(y.astype(np.float32))
self.len = self.X.shape[0]
def __getitem__(self, index):
return self.X[index], self.y[index]
def __len__(self):
return self.len
batch_size = 64
# Instantiate training and test data
train_data = Data(X_train, y_train)
train_dataloader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
test_data = Data(X_test, y_test)
test_dataloader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
# Check it's working
for batch, (X, y) in enumerate(train_dataloader):
print(f"Batch: {batch+1}")
print(f"X shape: {X.shape}")
print(f"y shape: {y.shape}")
break
"""
Batch: 1
X shape: torch.Size([64, 2])
y shape: torch.Size([64])
"""Ora passiamo all'implementazione e al training della rete neurale.
Implementeremo una semplice rete neurale a due strati che usa la funzione di attivazione ReLU (torch.nn.functional.relu). Per farlo creeremo una classe chiamata NeuralNetwork che eredita da nn.Module, la classe base per tutti i moduli di rete neurale costruiti in PyTorch.
Ecco il codice:
import torch
from torch import nn
from torch import optim
input_dim = 2
hidden_dim = 10
output_dim = 1
class NeuralNetwork(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(NeuralNetwork, self).__init__()
self.layer_1 = nn.Linear(input_dim, hidden_dim)
nn.init.kaiming_uniform_(self.layer_1.weight, nonlinearity="relu")
self.layer_2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = torch.nn.functional.relu(self.layer_1(x))
x = torch.nn.functional.sigmoid(self.layer_2(x))
return x
model = NeuralNetwork(input_dim, hidden_dim, output_dim)
print(model)
"""
NeuralNetwork(
(layer_1): Linear(in_features=2, out_features=10, bias=True)
(layer_2): Linear(in_features=10, out_features=1, bias=True)
)
"""E questo è tutto.
Per addestrare il modello dobbiamo definire una funzione di loss per calcolare i gradienti e un ottimizzatore per aggiornare i parametri. Per la nostra dimostrazione useremo la binary crossentropy e la discesa del gradiente stocastica con un learning rate di 0,1.
learning_rate = 0.1
loss_fn = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=leaAlleniamo il nostro modello
num_epochs = 100
loss_values = []
for epoch in range(num_epochs):
for X, y in train_dataloader:
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
pred = model(X)
loss = loss_fn(pred, y.unsqueeze(-1))
loss_values.append(loss.item())
loss.backward()
optimizer.step()
print("Training Complete")
"""
Training Complete
"""Dato che abbiamo tracciato i valori della loss, possiamo visualizzare l'andamento della loss del modello nel tempo.
step = range(len(loss_values))
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(step, np.array(loss_values))
plt.title("Step-wise Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()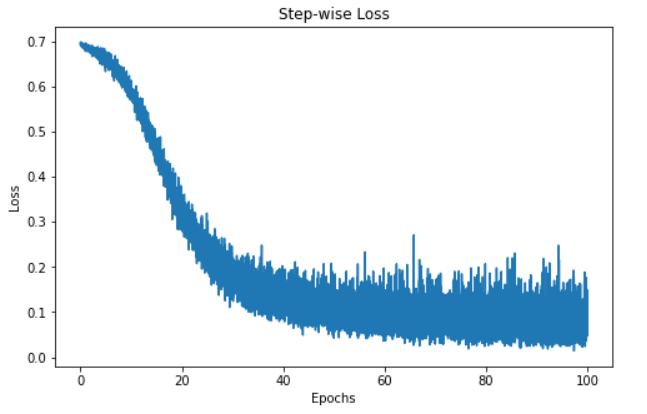
La visualizzazione sopra mostra la loss del nostro modello su 100 epoche. Inizialmente la loss parte da 0,7 e diminuisce gradualmente: questo ci dice che il modello ha migliorato le sue previsioni nel tempo. Tuttavia, sembra appiattirsi intorno alla sessantesima epoca, il che può dipendere da vari motivi, ad esempio il modello potrebbe trovarsi in prossimità di un minimo locale o globale della funzione di loss.
In ogni caso, il modello è stato addestrato ed è pronto a fare previsioni su nuove istanze: vediamo come farlo nella prossima sezione.
Fare previsioni con la nostra rete neurale in PyTorch è piuttosto semplice.
import itertools # Import this at the top of your script
# Initialize required variables
y_pred = []
y_test = []
correct = 0
total = 0
"""
We're not training so we don't need to calculate the gradients for our outputs
"""
with torch.no_grad():
for X, y in test_dataloader:
outputs = model(X) # Get model outputs
predicted = np.where(outputs.numpy() < 0.5, 0, 1) # Convert to NumPy and apply threshold
predicted = list(itertools.chain(*predicted)) # Flatten predictions
y_pred.append(predicted) # Append predictions
y_test.append(y.numpy()) # Append true labels as NumPy
total += y.size(0) # Increment total count
correct += (predicted == y.numpy()).sum().item() # Count correct predictions
print(f'Accuracy of the network on the 3300 test instances: {100 * correct // total}%')
"""
Accuracy of the network on the 3300 test instances: 97%
"""
Nota: a ogni esecuzione del codice otterrai un output diverso, quindi potresti non avere gli stessi risultati.
Il codice sopra scorre i batch di test, memorizzati nella variabile test_dataloader, senza calcolare i gradienti. Quindi prevediamo le istanze nel batch e memorizziamo i risultati in una variabile chiamata outputs. Successivamente impostiamo a 0 tutti i valori inferiori a 0,5 e a 1 quelli uguali o superiori a 0,5. Questi valori vengono poi aggiunti a una lista per le nostre previsioni.
Dopodiché aggiungiamo le classificazioni effettive delle istanze nel batch a una variabile chiamata total. Poi calcoliamo il numero di previsioni corrette identificando quante previsioni sono uguali alle classi reali e sommando. Il numero totale di previsioni corrette per ciascun batch viene incrementato e salvato nella nostra variabile correct.
Per calcolare l'accuratezza complessiva del modello, moltiplichiamo il numero di previsioni corrette per 100 (per ottenere una percentuale) e poi dividiamo per il numero di istanze nel test set. Il nostro modello ha ottenuto un'accuratezza del 97%. Approfondiamo con la matrice di confusione e il classification_report di scikit-learn per capire meglio come ha performato il modello.
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = list(itertools.chain(*y_pred))
y_test = list(itertools.chain(*y_test))
print(classification_report(y_test, y_pred))
"""
precision recall f1-score support
0.0 0.98 0.97 0.98 1635
1.0 0.98 0.98 0.98 1665
accuracy 0.98 3300
macro avg 0.98 0.98 0.98 3300
weighted avg 0.98 0.98 0.98 3300
"""
cf_matrix = confusion_matrix(y_test, y_pred)
plt.subplots(figsize=(8, 5))
sns.heatmap(cf_matrix, annot=True, cbar=False, fmt="g")
plt.show()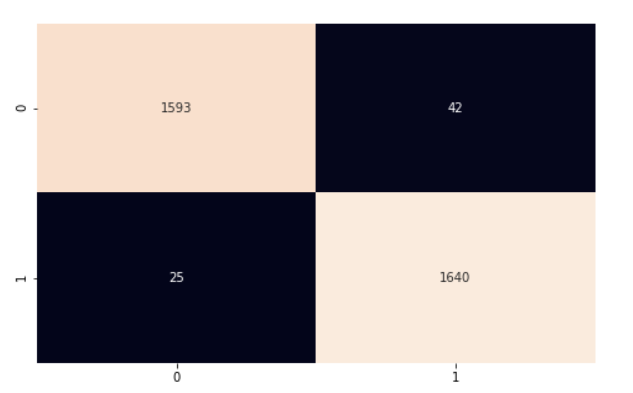
Il nostro modello si comporta piuttosto bene. Ti incoraggio a esplorare il codice e a fare qualche modifica per fissare meglio i concetti trattati in questo articolo.
In questo tutorial su PyTorch abbiamo coperto le basi fondanti delle reti neurali e usato PyTorch, una libreria Python per il deep learning, per implementare la nostra rete. Abbiamo usato il dataset dei cerchi di scikit-learn per addestrare una rete neurale a due strati per la classificazione. Abbiamo poi fatto previsioni sui dati e valutato i risultati usando la metrica di accuratezza.
Corsi per Python
Corso
Corso