GPT-3, the third-generation Generative Pre-trained Transformer. is a cutting-edge neural network deep learning model created by OpenAI. By using vast amounts of internet data, GPT-3 can produce diverse and robust machine-generated text with minimal input. GPT-3 has a diverse range of applications and is not limited to text summarization, translation, chatbot development, and content generation.
Despite its robustness, GPT-3 performance can be further improved by fine-tuning it on a specific use case.
But what do we mean by fine-tuning?
It is the process of training the pre-trained GPT-3 on a custom use case dataset. This allows the model to better adapt to the nuance of that specific use case or domain, leading to more accurate results.
The prerequisites for successfully performing the fine-tuning are (1) a basic understanding of Python programming and (2) and a familiarity with machine learning and natural language processing.
Our Classification in Machine Learning: An Introduction article helps you learn about classification in machine learning, looking at what it is, how it's used, and some examples of classification algorithms.
We will use the openai Python package provided by OpenAI to make it more convenient to use their API and access GPT-3’s capabilities.
This article will walk through the fine-tuning process of the GPT-3 model using Python on the user’s own data, covering all the steps, from getting API credentials to preparing data, training the model, and validating it.
Which GPT Models Can be Fine-Tuned?
The GPT models that can be fine-tuned include Ada, Babbage, Curie, and Davinci. These models belong to the GPT-3 family. Also, it is important to note that fine-tuning is currently not available for more recent GPT-3.5-turbo models or other GPT-4.
Read our beginner’s guide to GPT-3 for more information about the model.
What are Good Use Cases for Fine-Tuning GPT?
Classification and conditional generation are the two types of problems that can benefit from fine-tuning a language model like GPT-3. Let’s briefly explore each one.
Classification
For classification problems, each input in the prompt is assigned one of the predefined classes, and some of the cases are illustrated below:
- Ensuring truthful statements: If a company wants to verify that ads on their website mention the correct product and company, a classifier can be fine-tuned to filter out incorrect ads, ensuring the model isn't making things up.
- Sentiment analysis: This involves classifying text based on sentiment, such as positive, negative, or neutral.
- Email triage categorization: To sort incoming emails into one of many predefined categories, those categories can be converted into numbers, which work well well for up to ~500 categories.
Conditional generation
The problems in this category involve generating content based on a given input. Applications include paraphrasing, summarizing, entity extraction, product description writing, virtual assistants (chatbots), and more. Examples include:
- Creating engaging ads from Wikipedia articles. In this generative use case, ensure that the samples provided are high-quality, as the fine-tuned model will attempt to imitate the style (and mistakes) of the examples.
- Entity extraction. This task is akin to a language transformation problem. Improve performance by sorting extracted entities alphabetically or in the same order as they appear in the original text.
- Customer support chatbot. A chatbot typically includes relevant context about the conversation (order details), a summary of the conversation so far, and the most recent messages.
- Product description based on technical properties. Convert input data into a natural language to achieve superior performance in this context.
A Step-by-Step Implementation of Fine Tuning GPT-3
Creating an OpenAI developer account is mandatory to access the API key, and the steps are provided below:
First, create an account from the OpenAI official website.
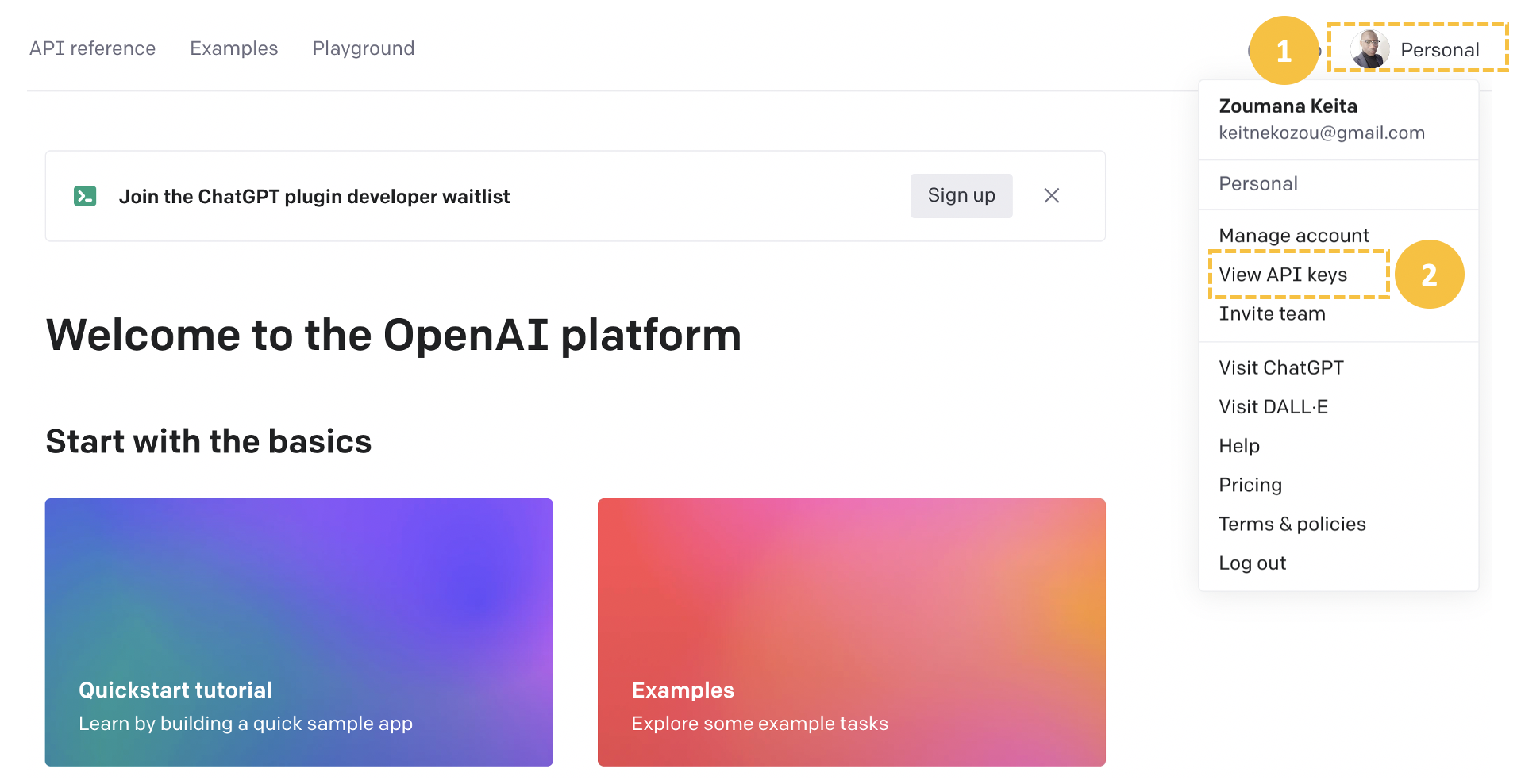
Then, select the user profile icon on the top-right corner and click “View API Keys” to access the page for creating a new API key or using an existing one.
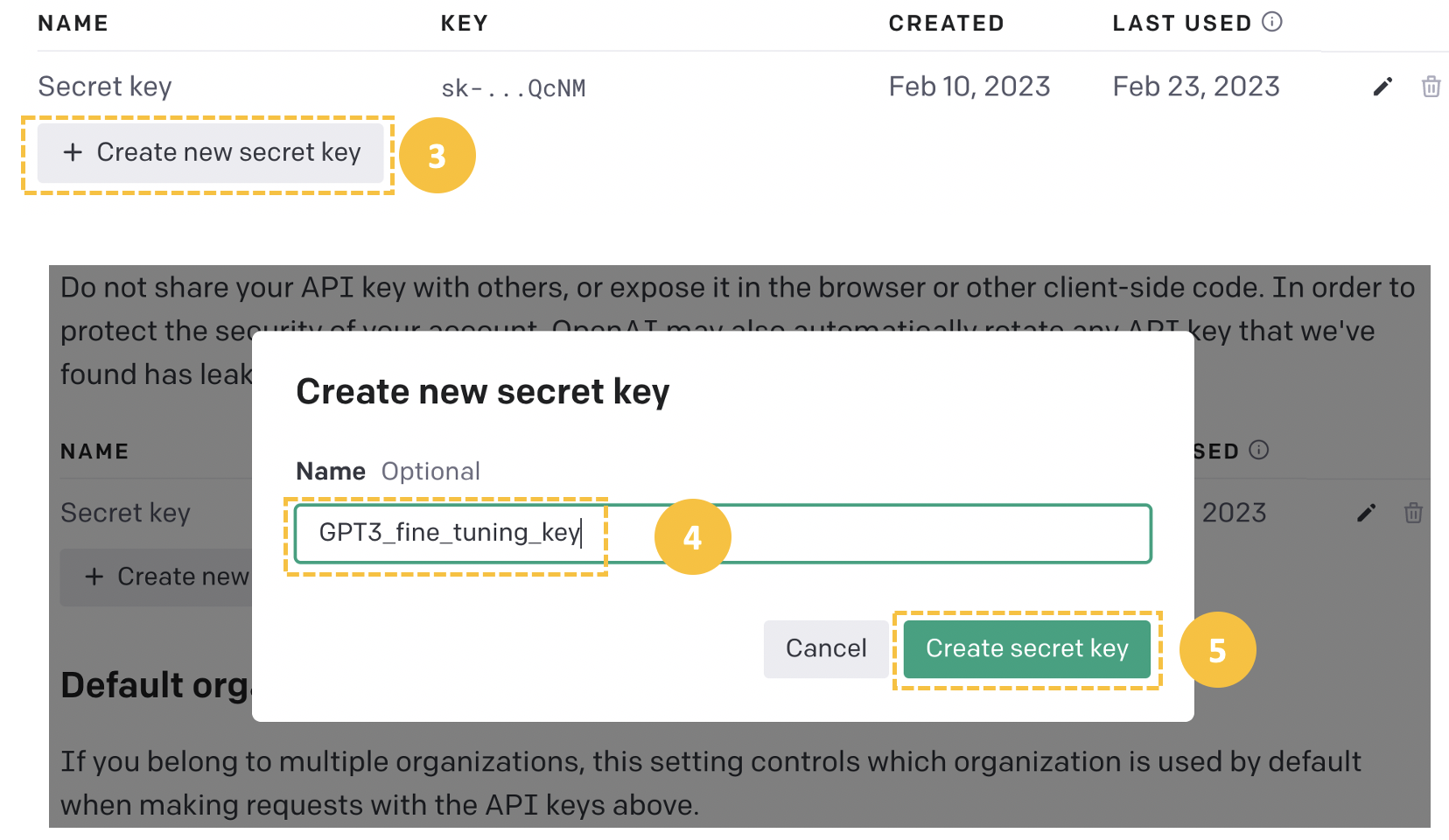
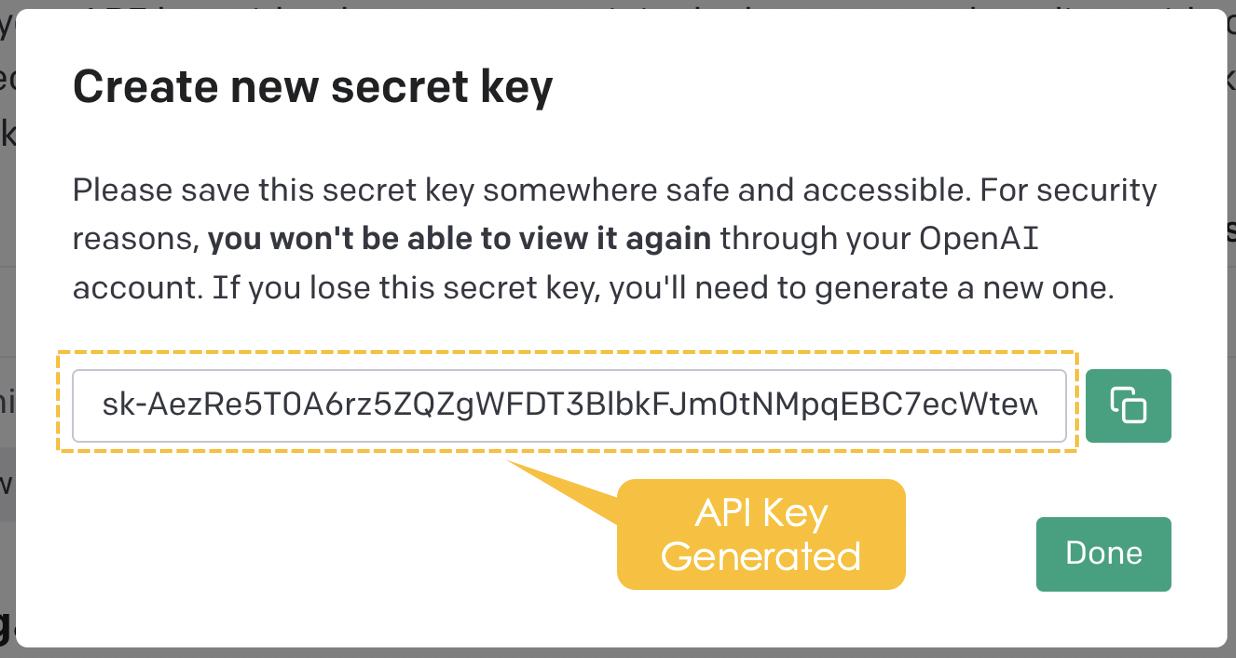
Create a new secret key from the “Create new secret key” tab by providing a meaningful name (GPT3_fine_tuning_key in this case), and then the API key is automatically generated.
If you are stuck or facing difficulties, be sure to check out the DataLab workbook with all the code.
Dataset
In this use case, we will fine-tune the GPT-3 model for a question-answering scenario, consisting of a structured question-answer pattern designed to help the model understand the task the model needs to perform. A consistent format is maintained for each pair of questions and answers across the entire training and testing data.
An instance in the question-answering dataset has the following format:
{
"prompt": "my prompt ->",
"completion": "the answer of the prompt. \n"
}- “prompt” is the input text read and processed by the model. The main separator is the arrow sign (->) to delineate the prompt from the expected response.
- “completion” is the expected response to the prompt. A backslash “\n” sign is used as a stop sequence to indicate the end of the answer.
With this understanding of the format of the dataset, we can generate both the training and the validation dataset, as shown below. These prompts and completions have been generated using ChatGPT.
Our ChatGPT Cheat Sheet for Data Science provides users access to 60+ prompts for Data Science tasks.
training_data = [
{
"prompt": "What is the capital of France?->",
"completion": """ The capital of France is Paris.\n"""
},
{
"prompt": "What is the primary function of the heart?->",
"completion": """ The primary function of the heart is to pump blood throughout the body.\n"""
},
{
"prompt": "What is photosynthesis?->",
"completion": """ Photosynthesis is the process by which green plants and some other organisms convert sunlight into chemical energy stored in the form of glucose.\n"""
},
{
"prompt": "Who wrote the play 'Romeo and Juliet'?->",
"completion": """ William Shakespeare wrote the play 'Romeo and Juliet'.\n"""
},
{
"prompt": "Which element has the atomic number 1?->",
"completion": """ Hydrogen has the atomic number 1.\n"""
},
{
"prompt": "What is the largest planet in our solar system?->",
"completion": """ Jupiter is the largest planet in our solar system.\n"""
},
{
"prompt": "What is the freezing point of water in Celsius?->",
"completion": """ The freezing point of water in Celsius is 0 degrees.\n"""
},
{
"prompt": "What is the square root of 144?->",
"completion": """ The square root of 144 is 12.\n"""
},
{
"prompt": "Who is the author of 'To Kill a Mockingbird'?->",
"completion": """ The author of 'To Kill a Mockingbird' is Harper Lee.\n"""
},
{
"prompt": "What is the smallest unit of life?->",
"completion": """ The smallest unit of life is the cell.\n"""
}
]
validation_data = [
{
"prompt": "Which gas do plants use for photosynthesis?->",
"completion": """ Plants use carbon dioxide for photosynthesis.\n"""
},
{
"prompt": "What are the three primary colors of light?->",
"completion": """ The three primary colors of light are red, green, and blue.\n"""
},
{
"prompt": "Who discovered penicillin?->",
"completion": """ Sir Alexander Fleming discovered penicillin.\n"""
},
{
"prompt": "What is the chemical formula for water?->",
"completion": """ The chemical formula for water is H2O.\n"""
},
{
"prompt": "What is the largest country by land area?->",
"completion": """ Russia is the largest country by land area.\n"""
},
{
"prompt": "What is the speed of light in a vacuum?->",
"completion": """ The speed of light in a vacuum is approximately 299,792 kilometers per second.\n"""
},
{
"prompt": "What is the currency of Japan?->",
"completion": """ The currency of Japan is the Japanese Yen.\n"""
},
{
"prompt": "What is the smallest bone in the human body?->",
"completion": """ The stapes, located in the middle ear, is the smallest bone in the human body.\n"""
}
]Setup
Before diving into the implementation process, we need to prepare the working environment by installing the necessary libraries, especially the OpenAI Python library, as shown below:
pip install --upgrade openaiNow we can import the library.
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ['OPENAI_API_KEY'],
)Prepare the dataset
Dealing with list format, as shown above, might be convenient for small datasets. However, there are several benefits to saving the data in JSONL (JSON Lines) format. The benefits include scalability, interoperability, simplicity, and also compatibility with OpenAI API, which requires data in JSONL format when creating fine-tuning jobs.
The following code leverages the helper function prepare_data to create both the training and validation data in JSONL formats:
import json
training_file_name = "training_data.jsonl"
validation_file_name = "validation_data.jsonl"
def prepare_data(dictionary_data, final_file_name):
with open(final_file_name, 'w') as outfile:
for entry in dictionary_data:
json.dump(entry, outfile)
outfile.write('\n')
prepare_data(training_data, "training_data.jsonl")
prepare_data(validation_data, "validation_data.jsonl")Finally, we upload the two datasets to the OpenAI developer account as follows:
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")Successful execution of the previous code displays below the unique identifier of the training and validation data.

At this level we have all the information to proceed with the fine-tuning.
Create a fine-tuning job
This fine-tuning process is highly inspired by the openai-cookbook performing fine-tuning on Microsoft Azure.
To perform the fine-tuning we will use the following two steps: (1) define hyperparameters, and (2) trigger the fine-tuning.
We will fine-tune the davinci model and run it for 15 epochs using a batch size of 3 and a learning rate multiplier of 0.3 using the training and validation datasets.
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="davinci-002",
hyperparameters={
"n_epochs": 15,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
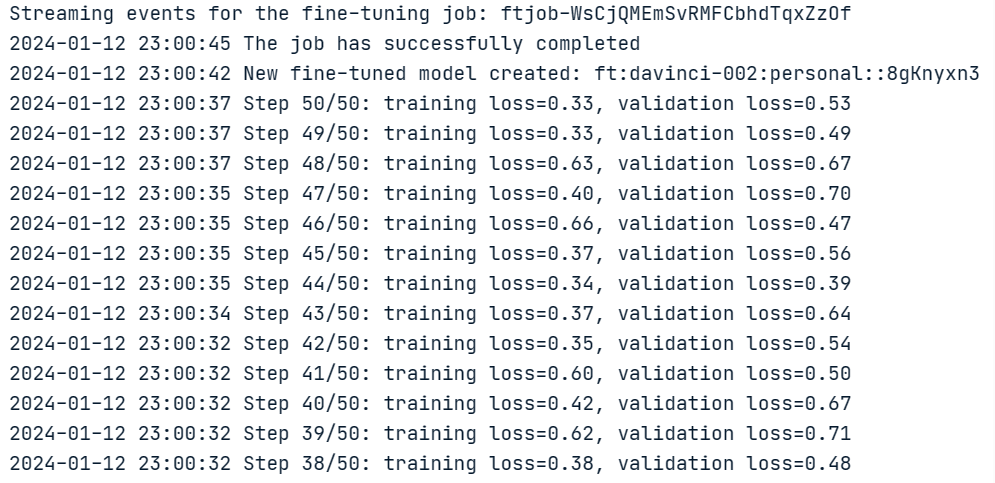
print(f"Training Status: {status}")The code above generates the following information for the jobID (`ftjob-WsCjQMEmSvRMFCbhdTqxZzOf`), the training response, and the training status (pending).

This pending status does not provide any relevant information. However, we can have more insight into the training process by running the following code:
import signal
import datetime
def signal_handler(sig, frame):
status = client.fine_tuning.jobs.retrieve(job_id).status
print(f"Stream interrupted. Job is still {status}.")
return
print(f"Streaming events for the fine-tuning job: {job_id}")
signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id)
try:
for event in events:
print(
f'{datetime.datetime.fromtimestamp(event.created_at)} {event.message}'
)
except Exception:
print("Stream interrupted (client disconnected).")All the epochs are generated below, along with the status of the fine-tuning, which is succeeded.
Check the fine-tuning job status
Let's verify that our operation was successful, and additionally, we can examine all the fine-tuning operations by using a list operation.
import time
status = client.fine_tuning.jobs.retrieve(job_id).status
if status not in ["succeeded", "failed"]:
print(f"Job not in terminal status: {status}. Waiting.")
while status not in ["succeeded", "failed"]:
time.sleep(2)
status = client.fine_tuning.jobs.retrieve(job_id).status
print(f"Status: {status}")
else:
print(f"Finetune job {job_id} finished with status: {status}")
print("Checking other finetune jobs in the subscription.")
result = client.fine_tuning.jobs.list()
print(f"Found {len(result.data)} finetune jobs.")The result of the execution is given below:

There is a total of 2 finetune jobs.
Validation of the model
Finally, the fine-tuned model can be retrieved from the “fine_tuned_model” attribute. The following print statement shows that the name of the final mode is: `ft:davinci-002:personal::8gKnyxn3`
# Retrieve the finetuned model
fine_tuned_model = result.data[0].fine_tuned_model
print(fine_tuned_model)
![]()
With this model, we can run queries to validate its results by providing a prompt, the model name, and creating a query with the openai.Completion.create() function. The result is retrieved from the answer dictionary as follows:
new_prompt = "Which part is the smallest bone in the entire human body?"
answer = client.completions.create(
model=fine_tuned_model,
prompt=new_prompt
)
print(answer.choices[0].text)
new_prompt = "Which type of gas is utilized by plants during the process of photosynthesis?"
answer = client.completions.create(
model=fine_tuned_model,
prompt=new_prompt
)
print(answer.choices[0].text)Even though the prompts are not written exactly the same as in the validation dataset, the model still managed to map them to the correct answers. The answers to the previous requests are shown below.

With very few training samples, we managed to have a decent fine-tuned model. Better results can be achieved with a larger training size.
Conclusion
In this article, we have explored the potential of GPT-3, and discussed the process of fine-tuning the model to improve its performance for specific use cases. We have outlined the prerequisites for successfully fine-tuning GPT-3, including a basic understanding of Python programming and familiarity with machine learning and natural language processing.
Furthermore, we have introduced the openai Python package, used to simplify the process of accessing GPT-3's capabilities through OpenAI's API. The article has covered all the steps involved in fine-tuning the GPT-3 model using Python and custom datasets, from obtaining API credentials to preparing data, training the model, and validating it.
By highlighting the benefits of fine-tuning and providing a comprehensive guide to the process, this article aims to assist data scientists, developers, and other stakeholders with the necessary tools and knowledge to create more accurate and efficient GPT-3 models tailored to their specific needs and requirements.
We have an article covering What is GPT-4 and Why Does it Matter? and also An Introduction to Using Transformers and Hugging Face tutorial. Make sure to read them to take your knowledge to the next level.
Introduction to ChatGPT Course
Get Started with ChatGPT





