
Course
Understanding Machine Learning
2 hr
294.5K
Machine learning projects are iterative processes. You don’t just stop at a successful model inside a Jupyter notebook. You don’t even stop after the model is online, and people can access it. Even after deployment, you have to constantly babysit it so that it works just as well as it did during the development phase.
Zillow’s scandal is a perfect example of what happens if you don’t. In 2021, Zillow lost a stunning 304 million dollars because of their machine learning model that estimated house prices. Zillow overpaid for more than 7000 homes and had to offload them at a much lower price. The company was “ripped off” by its own model and had to reduce its workforce by 25%.
These types of silent model failures are common with real-world models, so they need to be constantly updated before their production performance drops. Failing to do so damages companies’ reputation, trust with stakeholders, and ultimately, their pockets.
This article will teach you how to implement an end-to-end workflow to monitor machine learning models after deployment with NannyML.
NannyML is a growing open-source library focused on post-deployment machine learning. It offers a wide range of features to solve all types of problems that arise in production ML environments. To name a few:
We will learn the technical bits of these features one by one.
We will learn the fundamental concepts of model monitoring through the analogy of a robot mastering archery.
In our analogy:
So, let’s start.
Imagine we’ve carefully prepared the bow, arrows, and target (like data preparation). Our robot, equipped with many sensors and cameras, shoots 10000 times during training. Over time, it starts to hit the bull’s eye with impressive frequency. We are thrilled with the performance and begin selling our robot and its copies to archery lovers (deploying the model).
But soon, we get a stream of complaints. Some users report that the robot is totally missing the target. Surprised, we gather a team to discuss what went wrong.
What we find is a classic case of data drift. The environment in which the robots are operating has changed — different wind patterns, varying humidity levels, and even changes in the physical characteristics of the arrows (weight, balance) and bow.
This real-world shift in input features has thrown off our robot’s accuracy, similar to how a machine learning model might underperform when input data, especially the relationship between features, changes over time.
After addressing these issues, we release a new batch of robots. Yet, in a few weeks, similar complaints flow in. Puzzled, we dig deeper and discover that the targets have been frequently replaced by users.
These new targets vary in size and are placed at varying distances. This change requires a different approach to the robot’s shooting technique — a textbook example of concept drift.
In machine learning terms, concept drift happens when the relationship between the input variables and the target outcome changes. For our robots, the new types of targets meant they now need to adapt to shooting differently, just as a machine learning model needs to adjust when the dynamics of the data it was trained on change significantly.
To drive the points home, let’s explore some real-world examples of how data and concept drift occurs.
Now, let’s consider an end-to-end ML monitoring workflow.
Model monitoring involves three major steps that ML engineers should follow iteratively.
The first step is, of course, keeping a close eye on model performance in deployment. But this is easier said than done.
When ground truth is immediately available for a model in production, it is easy to detect changes in model behavior. For example, the users can immediately tell what’s wrong in our robot/archery analogy because they can look at the target and tell us that the robot missed — immediate ground truth.
In contrast, take the example of a model that predicts loan defaults. Such models predict whether a user defaults on the next payment or not every month. To verify the prediction, the model must wait until the actual payment date. This is an example of delayed ground truth, which is most common in real-world machine learning systems.
In such cases, it is too costly to wait for the ground truth to be available to see if models are performing well. So, ML engineers need methods to estimate model performance without them. This is where algorithms such as CBPE or DLE come in (more on them later).
Monitoring models can also be done by measuring the direct business impact, i.e., monitoring KPIs (key performance indicators). In Zillow’s case, a proper monitoring system could have detected profit loss and alerted the engineers (hypothetically).
If the monitoring system detects a performance drop, regardless of whether the system analyzed realized performance (with ground truth) or estimated performance (without ground truth), ML engineers must identify the cause behind the drop.
This usually involves checking features individually or in combination for data (feature drift) and examining the targets for concept drift.
Based on their findings, they employ various issue-resolution techniques.
Here is a non-exclusive list of techniques to mitigate the damages caused by post-deployment performance degradation:
Each method has its application context, and often, you may end up implementing a combination of them.
NannyML deals with the first two steps of this iterative process. So, let’s get down to it.
Apart from training and validation sets, NannyML requires two additional sets called a reference and analysis in specific formats to get started with monitoring. This section teaches you how to create them from any data.
First, we need a model that is already trained and ready to be deployed into production so that we can monitor it. For this purpose, we will use the diamonds dataset and train an XGBoost regressor.
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
warnings.filterwarnings("ignore")
The first step after importing modules is to load the Diamonds dataset from Seaborn. However, we will be using a special version of the dataset that I specifically prepared for this article to illustrate what monitoring looks like. You can load the dataset into your environment using the snippet below:
dataset_link = "https://raw.githubusercontent.com/BexTuychiev/medium_stories/master/2024/1_january/4_intro_to_nannyml/diamonds_special.csv"
diamonds_special = pd.read_csv(dataset_link)
diamonds_special.head()
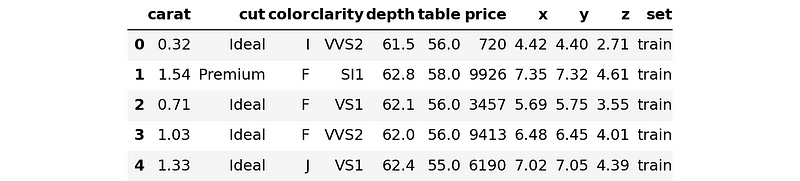
This special version of the dataset has a column named “set”, which we will get to in a second.
For now, we will extract all feature names, the categorical feature names, and the target name:
# Extract all feature names
all_feature_names = diamonds_special.drop(["price", "set"], axis=1).columns.tolist()
# Extract the columns and cast into category
cats = diamonds_special.select_dtypes(exclude=np.number).columns
# Define the target column
target = "price"
The task is a regression — we will be predicting diamond prices given their physical attributes.
The diamonds dataset is fairly clean. So, the only preprocessing we perform is casting the text features into Pandas category data type. This is a requirement to enable automatic categorical data preprocessing by XGBoost.
for col in cats:
diamonds_special[col] = diamonds_special[col].astype("category")
Let’s move on to splitting the data.
Yes, you read that right. We will be splitting the data into four sets. Traditionally, you may have only split it into three:
Model monitoring workflows require another set to mimic production data. This is to ensure that our system correctly detects performance drops by using the right algorithms and reports what went wrong.
For this purpose, I’ve labeled the rows of Diamonds Special with four categories in the set column:
diamonds_special.set.unique()
['train', 'val', 'test', 'prod']
Categories (4, object): ['prod', 'test', 'train', 'val']
The training set represents 70%, while the rest iare 10% each of the total data. Let’s split it:
tr = diamonds_special[diamonds_special.set == "train"].drop("set", axis=1)
val = diamonds_special[diamonds_special.set == "validation"].drop("set", axis=1)
test = diamonds_special[diamonds_special.set == "test"].drop("set", axis=1)
prod = diamonds_special[diamonds_special.set == "prod"].drop("set", axis=1)
tr.shape
(37758, 10)
But, real-world datasets don’t come with in-built set labels, so you have to split the data manually into four sets yourself. Here’s a function that does the task using train_test_split from sklearn:
def split_into_four(df, train_size=0.7):
"""
A function to split a dataset into four sets:
- Training
- Validation
- Testing
- Production
train_size is set by the user.
The remaining data will be equally divided between the three sets.
"""
# Do the splits
training, the_rest = train_test_split(df, train_size=train_size)
validation, the_rest = train_test_split(the_rest, train_size=1 / 3)
testing, production = train_test_split(the_rest, train_size=0.5)
# Reset the indices
sets = (training, validation, testing, production)
for set in sets:
set.reset_index(inplace=True, drop=True)
return sets
tr, val, test, prod = split_into_four(your_dataset)
Note: Use the “Explain code” button to get a line-by-line explanation of the function.
Now, let’s move on to model training.
Before training an XGBoost model, we need to convert the datasets into DMatrices. Here is the code:
dtrain = xgb.DMatrix(tr[all_feature_names], label=tr[target], enable_categorical=True)
dval = xgb.DMatrix(val[all_feature_names], label=val[target], enable_categorical=True)
dtest = xgb.DMatrix(
test[all_feature_names], label=test[target], enable_categorical=True
)
dprod = xgb.DMatrix(
prod[all_feature_names], label=prod[target], enable_categorical=True
)
Now, here is the code to train a regressor with hyperparameters already tuned:
# Define optimized parameters
params = {
"n_estimators": 10000,
"learning_rate": 0.1,
"tree_method": "gpu_hist",
"max_depth": 6,
"min_child_weight": 1,
"gamma": 0,
"subsample": 0.8,
"colsample_bytree": 0.8,
"objective": "reg:squarederror",
"reg_alpha": 0.01,
"reg_lambda": 1,
}
# Training with early stopping
regressor = xgb.train(
params,
dtrain,
num_boost_round=10000,
evals=[(dtrain, "train"), (dval, "eval")],
early_stopping_rounds=50,
verbose_eval=500,
)
[0] train-rmse:3638.77217 eval-rmse:0.00000
[49] train-rmse:502.61376 eval-rmse:0.00000Great — we have a model that achieves 503$ in terms of RMSE on the validation set. Let’s evaluate the model one final time on the test set:
from sklearn.metrics import mean_squared_error
# Predict on the test set
y_test_pred = regressor.predict(dtest)
# Evaluate
mean_squared_error(test[target], y_test_pred, squared=False)
551.2763827068798
The testing performance is 551$. That’s good enough.
Up until this point, everything was pretty straightforward. Now, we come to the main part — creating reference and analysis sets.
A reference set is another name for the test set used in model monitoring context. NannyML uses the model’s performance on the test set as a baseline for production performance. The reference set must have two columns apart from the features:
y_test_predRight now, our test set contains the features and the target but is missing y_test_pred:
test.columns # Ignore the `set` column
Index(['carat', 'cut', 'color', 'clarity', 'depth', 'table', 'price', 'x', 'y',
'z'],
dtype='object')
Let’s add it:
test["y_pred"] = y_test_predNow, we will rename the test set into reference:
reference = test.copy(deep=True)
reference.columns
Index(['carat', 'cut', 'color', 'clarity', 'depth', 'table', 'price', 'x', 'y',
'z', 'y_pred'],
dtype='object')
At this point, let’s imagine that our regressor is deployed into the cloud. Imagining is simpler than actually deploying the model, which is overkill for this article.
After we deploy our diamonds pricing model, we receive the news that a large shipment of diamonds is coming. Before the cargo arrives, the physical measurements of diamonds have been sent to us as prod (we are still imagining) so that we can generate prices for them and start marketing them on our website. So, let's generate.
# Generate prices for production data
y_prod_pred = regressor.predict(dprod)
Before the actual diamonds arrive and a human specialist verifies the prices generated by our model, we have to check if our model is performing well. We don’t want to display the diamonds with inaccurate prices on our website.
To do this, we would need to measure the performance of the model by comparing y_prod_pred to the actual prices of new diamonds, the ground truth. But we won't have ground truth before the prices are verified. So, we would need to estimate the performance of the model without ground truth.
To do this task, NannyML requires an analysis set — the data that contains the production data with predictions made by the model.
Creating an analysis set is similar to creating a reference:
# Add the predictions of new diamonds to prod
prod["y_pred"] = y_prod_pred
analysis = prod.copy(deep=True)
analysis.columns
Index(['carat', 'cut', 'color', 'clarity', 'depth', 'table', 'price', 'x', 'y',
'z', 'y_pred'],
dtype='object')
Now, we are ready to estimate the performance of the regressor.
NannyML provides two major algorithms for estimating the performance of regression and classification models:
We will use the DLE algorithm for our task. DLE can measure the performance of a production model without ground truth and report various regression pseudo-metrics such as RMSE, RMSLE, MAE, etc.
To use DLE, we first need to fit it to reference to establish a baseline performance.
import nannyml # pip install nannyml
estimator = nannyml.DLE(
feature_column_names=all_feature_names,
y_true=target,
y_pred="y_pred",
metrics=["rmse"],
chunk_size=250,
)
Initializing DLE requires three parameters - the input feature names, the name of the column containing ground truth for testing and the name of the column containing testing predictions.
Additionally, we are also passing RMSE as a metric and a chunk size of 250. Let’s fit the estimator to reference and estimate performance on analysis:
# Fit to the reference set
estimator.fit(reference)
# Estimate on the analysis set
estimated_results = estimator.estimate(analysis)
estimated_results
<nannyml.performance_estimation.direct_loss_estimation.result.Result at 0x7f3954af1c90>
We have a NannyML Result object which can be plotted. Let's see what it produces:
estimated_results.plot().show()
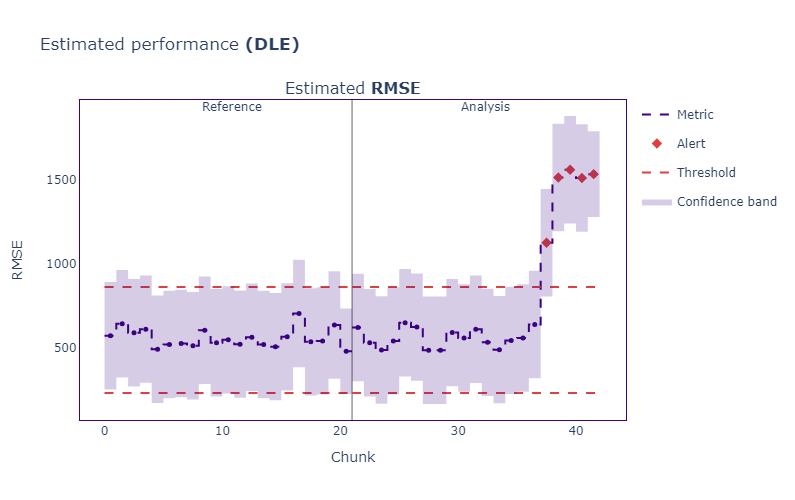
Let’s interpret the plot — it has two sections that display performance on the reference and analysis sets. If the estimated production RMSE goes up beyond the thresholds, NannyML marks them as alerts.
As we can see, we have a few alerts for production data, suggesting something fishy is going on in the last batches.
Our monitoring system tells us that model performance dropped by about half in production. But it is only an estimate — we can’t say it for certain.
While we are plotting the estimated performance, the shipment has arrived, and our diamonds specialist calculated their actual price. We’ve stored them as price into prod.
Now, we can compare the realized performance (actual performance) of the model against the estimated performance to see if our monitoring system is working well.
NannyML provides with a PerformanceCalculator class to do so:
calculator = nannyml.PerformanceCalculator(
problem_type="regression",
y_true=target,
y_pred="y_pred",
metrics=["rmse"],
chunk_size=250,
)
calculator.fit(reference)
realized_results = calculator.calculate(analysis)
The class requires four parameters:
problem_type: What's the task?y_true: What are the labels?y_pred: Where can I find the predictions?metrics: Which metrics do I use to calculate the performance?After passing those and fitting the calculator to reference, we calculate on the analysis set.
To compare realized_results to estimated_results, we use a visual again:
estimated_results.compare(realized_results).plot().show()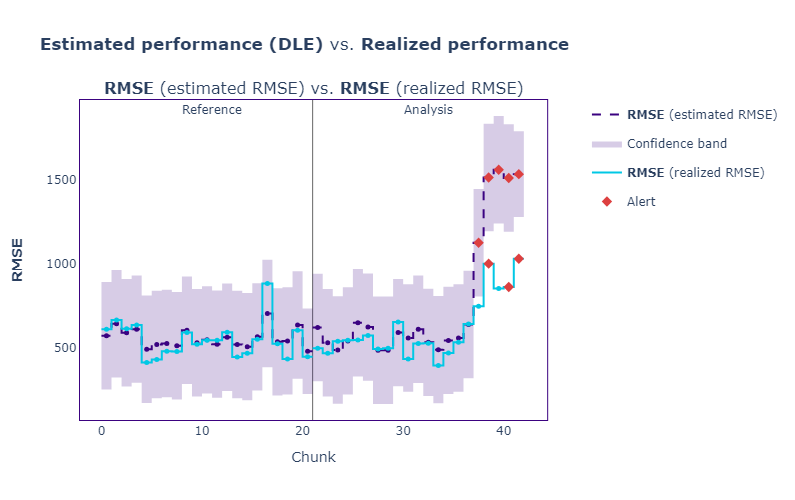
Well, it looks like the estimated RMSE (purple) was pretty close to the actual performance (realized RMSE, blue).
This tells us one thing — our monitoring system is working well, but our model isn’t, as indicated by the rising loss. So, what is the reason(s)?
We will dive into this now.
As mentioned in the intro, one of the most common reasons why models fail in production is drift. In this section, we will focus on data (feature) drift detection.
Drift detection is part of the root cause analysis step of the model monitoring workflow. It typically starts with multivariate drift detection.
One of the best multivariate drift detection methods is calculating data reconstruction error using PCA. It works remarkably well and can catch even the slightest of drifts in feature distributions. Here is a high-level overview of this method:
1. PCA fits to reference and compresses it to a lower dimension - reference_lower.
2. reference_lower is then decompressed into its original dimensionality - reference_reconstructed.
reference.3. The difference between reference and reference_reconstructed is found and named as data reconstruction error - reconstruct_error.
reconstruct_error works as a baseline to compare the reconstruction error of production data4. The same reduction/reconstruction method is applied to batches of production data.
These four steps are implemented as DataReconstructionDriftCalculator class in NannyML. Here is how to use it:
# Initialize
multivariate_calc = nannyml.DataReconstructionDriftCalculator(
column_names=all_feature_names,
chunk_size=250,
)
# Fit
multivariate_calc.fit(reference)
# Calculate error
multivariate_results = multivariate_calc.calculate(analysis)
Once we have the error for each chunk of data (250 rows each), we can plot it:
multivariate_results.plot().show()
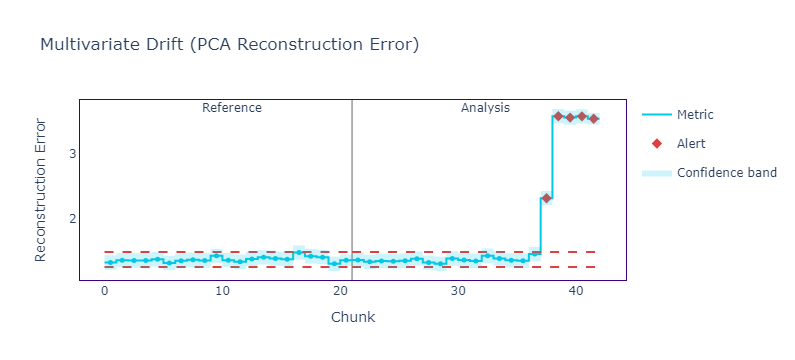
As we can see, the reconstruction error is very high, indicating a drift in features. We can compare the error to realized performance as well:
multivariate_results.compare(realized_results).plot().show(config={"staticPlot": True})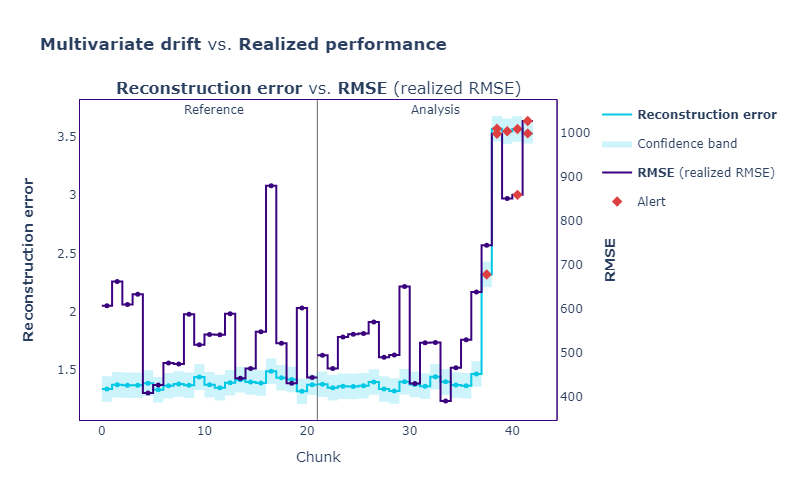
As we can see, all the spikes in loss are corresponding with alerts in reconstruction error.
Data reconstruction error is a single number to measure the drift for all features. But how about the drift of individual features? If our dataset contained hundreds of features, how would we find the most drifting features and take appropriate measures?
That’s where we use univariate drift detection methods. NannyML offers several depending on feature type:
All of these compare the distribution of individual features in reference to those of the analysis set. We can use some (or even all) within UnivariateDriftCalculator class:
univariate_calc = nannyml.UnivariateDriftCalculator(
column_names=all_feature_names,
continuous_methods=["wasserstein"],
categorical_methods=["jensen_shannon"],
chunk_size=250,
)
univariate_calc.fit(reference)
univariate_results = univariate_calc.calculate(analysis)
The only required parameter is column_names, the rest can use defaults set by NannyML. But, to keep things simple, we are using wasserstein and jensen_shannon for continuous and categorical features.
Right now, we have 11 features, so calling plot().show() may not yield the most optimal results. Instead, we can use an alert count ranker to return the features that gave the most number of alerts (when all chunks are considered). Here is the code:
# Initialize the ranker
alert_count_ranker = nannyml.AlertCountRanker()
# Filter the univariate results for only columns containing the metrics
filtered_univariate = univariate_results.filter(
continuous_methods=["wasserstein"],
categorical_methods=["jensen_shannon"],
only_drifting=False,
)
# Rank the alerts
ranker_results = alert_count_ranker.rank(filtered_univariate)
Once we have the ranker results, we can print its head as it is a Pandas DataFrame:
ranker_results.head(10)
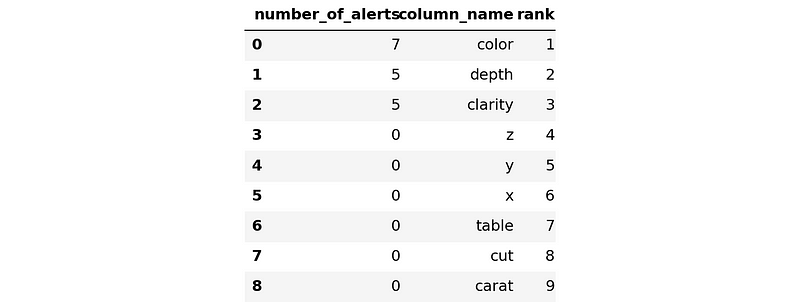
We can see that the most problematic features are color and depth. This shouldn’t surprise me as it was me who artificially caused them to drift before writing the article.
But if this was a real-world scenario, you would want to spend some time working on issue resolution for these features.
I find model monitoring fascinating because it shatters the illusion that machine learning is finished once you have a good model. As the Earth goes round and user patterns change, no model ever stays relevant for a long time. This makes model monitoring a crucial part of any ML engineer’s skill set.
Today, we’ve covered a basic model monitoring workflow. We’ve started by talking about fundamental monitoring concepts. Then, we dove head-first into the code: we’ve forged the data into a format compatible with NannyML; created our first plot for estimated model performance, created another one to compare it to realized performance; received a few alerts that performance is dropping; checked it with multivariate drift detection; found heavy feature drift; double-checked it with individual feature drift detection; identified the drifting features.
Unfortunately, we stopped right at issue resolution. That last step of monitoring workflow is beyond the scope of this article. However, I have some excellent recommendations that cover it and much more about model monitoring:
Both of these courses are created from the very best person you could hope for — the CEO and founder of NannyML. In the courses, there are many nuggets of information you can’t miss.
I also recommend reading the Nanny ML docs for some hands-on tutorials.
Start Your Machine Learning Journey Today!
Course
Course
Course
podcast
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
code-along
Weston Bassler
code-along
Folkert Stijnman
code-along
George Boorman



