Course
Introduction to Python
4 hr
6.9M
Dictionary is a built-in Python Data Structure that is mutable. It is similar in spirit to List, Set, and Tuples. However, it is not indexed by a sequence of numbers but indexed based on keys and can be understood as associative arrays. On an abstract level, it consists of a key with an associated value. In Python, the Dictionary represents the implementation of a hash-table.
As shown in the figure below, keys are immutable ( which cannot be changed ) data types that can be either strings or numbers. However, a key can not be a mutable data type, for example, a list. Keys are unique within a Dictionary and can not be duplicated inside a Dictionary. If it is used more than once, subsequent entries will overwrite the previous value.
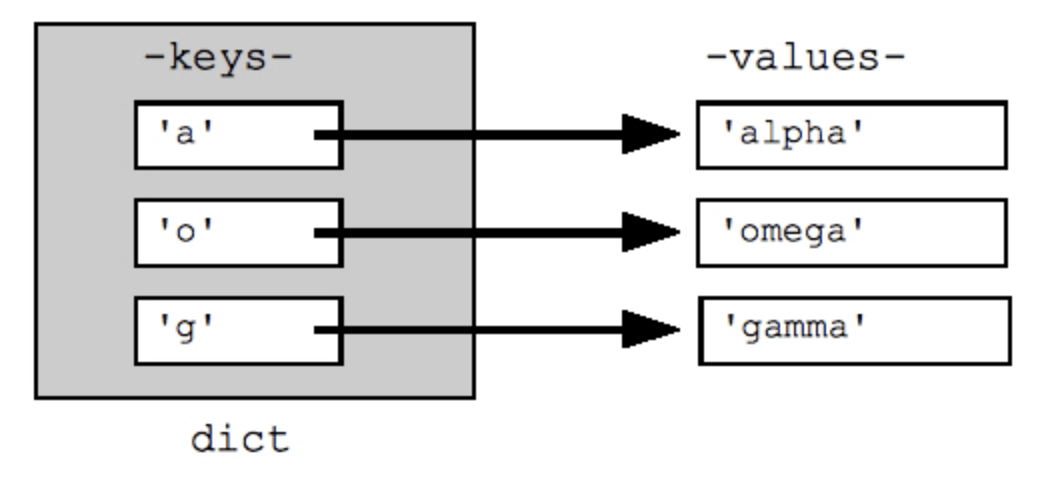
Key connects with the value, hence, creating a map-like structure. For example, remove keys from the picture; all you are left with is a data structure containing a sequence of numbers. Dictionaries, therefore, hold a key: value pair at each position.
A Dictionary is represented by a pair of curly braces {} in which enclosed are the key: value pairs separated by a comma.
As a refresher, here is a recipe for creating a Dictionary:
my_dict = {
"key1":"value1",
"key2":"value2"
}
In the above syntax, both the keys and the values are strings.
pop = [30.55, 2.77, 39.21]
countries = ["afghanistan", "albania", "algeria"]
Let's convert the population data to a Dictionary. To create the Dictionary, you will use the curly brackets. Next, inside the brackets, you will have a bunch of key:value pairs. In this case, the keys are country names, and values are the corresponding populations.
The first key is Afghanistan, and its corresponding value is 30.55. Notice the colon that separates the key and value pair. Let's do the same for the other two key:value pairs and store the result in the variable world.
Now, to find the population for Albania, simply type world, and then the string Albania inside square brackets. In other words, you pass the key in square brackets and get the corresponding values.
world = {"afghanistan":30.55, "albania":2.77, "algeria":39.21}
world["albania"]
2.77
This approach is not only intuitive, but it is also very efficient because Python can look up these keys very fast, even for huge dictionaries.
In the below example, you will use the strings in countries and capitals, create a Dictionary called europe with 4 key:value pairs. Here the countries will be the keys, and capitals will be the values. Beware of capitalization! Make sure you use lowercase characters everywhere. Finally, print out europe to see if the result is what you expected.
# Definition of countries and capital
countries = ['spain', 'france', 'germany', 'norway']
capitals = ['madrid', 'paris', 'berlin', 'oslo']
# From string in countries and capitals, create dictionary europe
europe = {'spain':'madrid', 'france':'paris', 'germany':'berlin', 'norway':'oslo'}
# Print europe
print(europe)
When you run the above code, it produces the following result:
{'norway': 'oslo', 'germany': 'berlin', 'france': 'paris', 'spain': 'madrid'}
To learn more about dictionaries in Python, please see this video from our course Intermediate Python.
This content is taken from DataCamp’s Intermediate Python course by Hugo Bowne-Anderson.
Python Courses
Course
Course
Course
Tutorial
Aditya Sharma
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Oluseye Jeremiah