Course
Preprocessing for Machine Learning in Python
4 hr
66.5K

Machine learning models are not like traditional software solutions. These models need constant updates as new data becomes available for accurate and reliable predictions. In complex and sensitive scenarios, relying on a single model may not be sufficient to generate an optimal result, and this is where ensemble modeling can help.
This conceptual tutorial covers what ensemble modeling in machine learning is and how it can improve your overall model performance. Then, we’ll provide an overview of various ensemble methods before diving into the illustration of a real-world scenario using a step-by-step implementation with Python.
Our Ensemble Learning in R with SuperLearner tutorial explains how to boost your machine learning results and based on ensemble learning approach using the SuperLearner package in R.
Let’s imagine a music manager participating in an international competition. They have access to a wide variety of musicians with different expertise:
Given the broad spectrum of musical expertise and background, the manager can combine all of them to create a unique and memorable performance.
Think of ensemble models as an orchestra of musicians, where each person specializes in a specific instrument like piano, trumpet, drum, and more. The combination of those skills creates a harmonious melody.
Ensemble learning uses the same logic:
It combines multiple algorithms to obtain better predictive performance than the one from a single model. There is no predefined number of models to consider, and some business goals may require more models than others.
The error emerging from any machine model can be broken down into three components mathematically:
Bias + Variance + Irreducible error
Why is this important in the current context? To understand what goes on behind an ensemble model, you need first to know what causes an error in the model.
Let’s look at these errors:
This is useful to quantify how much, on an average, the predicted values are different from the actual value. A high bias error means we have an underperforming model that keeps missing essential trends.
On the other side, Variance quantifies how the predictions made on the same observation differ. A high variance model will over-fit on your training population and perform poorly on any observation beyond training. The following diagram will give you more clarity (assume that the red spot is the real value, and the blue dots are predictions):
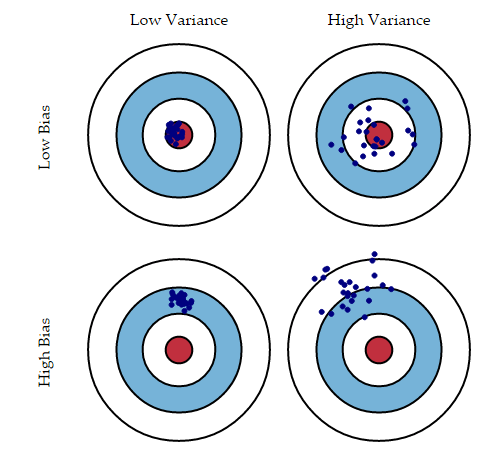
Typically, as you increase the complexity of your model, you will see a reduction in error due to lower bias in the model. However, this only happens until a particular point. As you continue to make your model more complex, you end up over-fitting your model, and hence your model will start suffering from the high variance.
Now that you are familiar with the basics of ensemble learning let's look at different ensemble learning techniques:
There are different types of ensemble methods, and each one brings a set of advantages and disadvantages. This section covers those aspects to help you make the right choice for your use cases.
Before diving into each method, let’s understand what meta and base learners are for a better understanding of the next concepts.
Bagging is also known as bootstrap aggregation. This technique is similar to random forest, but it uses all the predictors, whereas random forest uses only a subset of predictors in each tree.
In bagging, a random sample of data from the training set is selected with replacement, which enables the duplication of sample instances in a set. Below are the main steps involved in bagging:
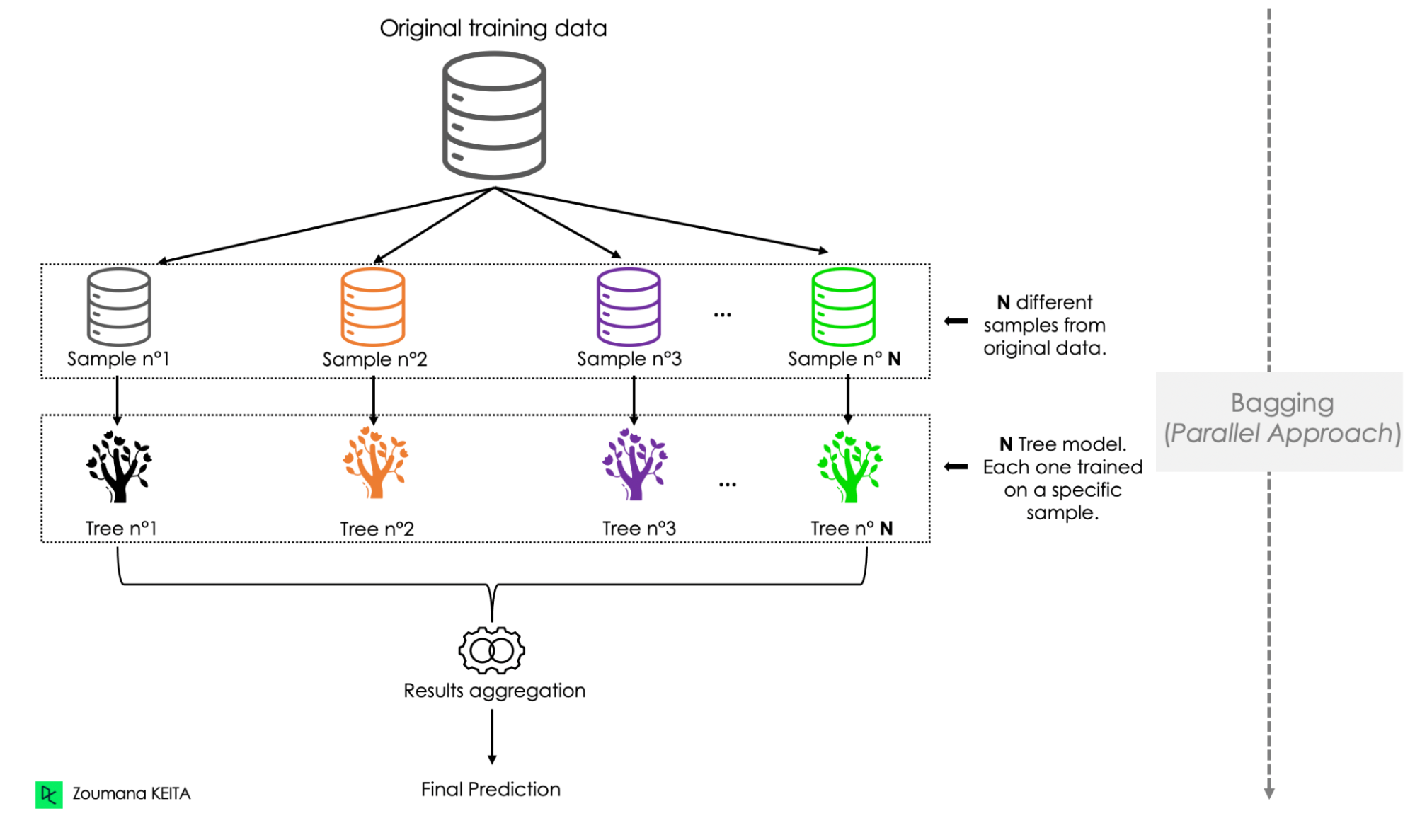
Bagging presents several key advantages and disadvantages when used for classification or regression tasks.
Boosting adopts a sequential approach, where the prediction of the current model is transferred to the next one. Each model iteratively focuses attention on the observations that are misclassified by its predecessors. We’ve outlined the general process below:
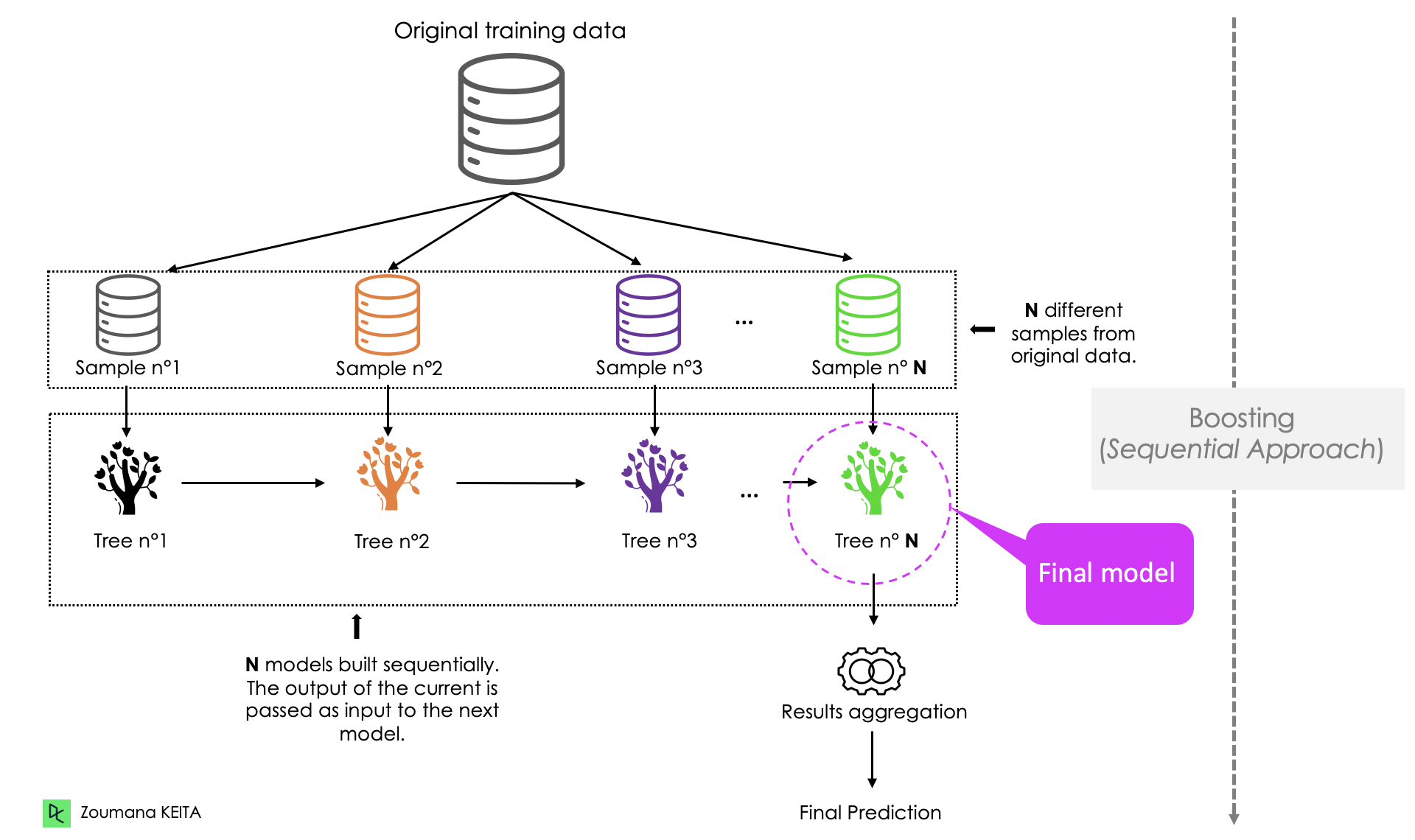
Stacking is pretty similar to boosting. The predictions from the base learners are stacked together and are used as the input to train the meta learner to produce more robust predictions. The meta learner is then used to make final predictions. Bagging and boosting typically use homogeneous base learners, whereas stacking tends to include heterogeneous ones.
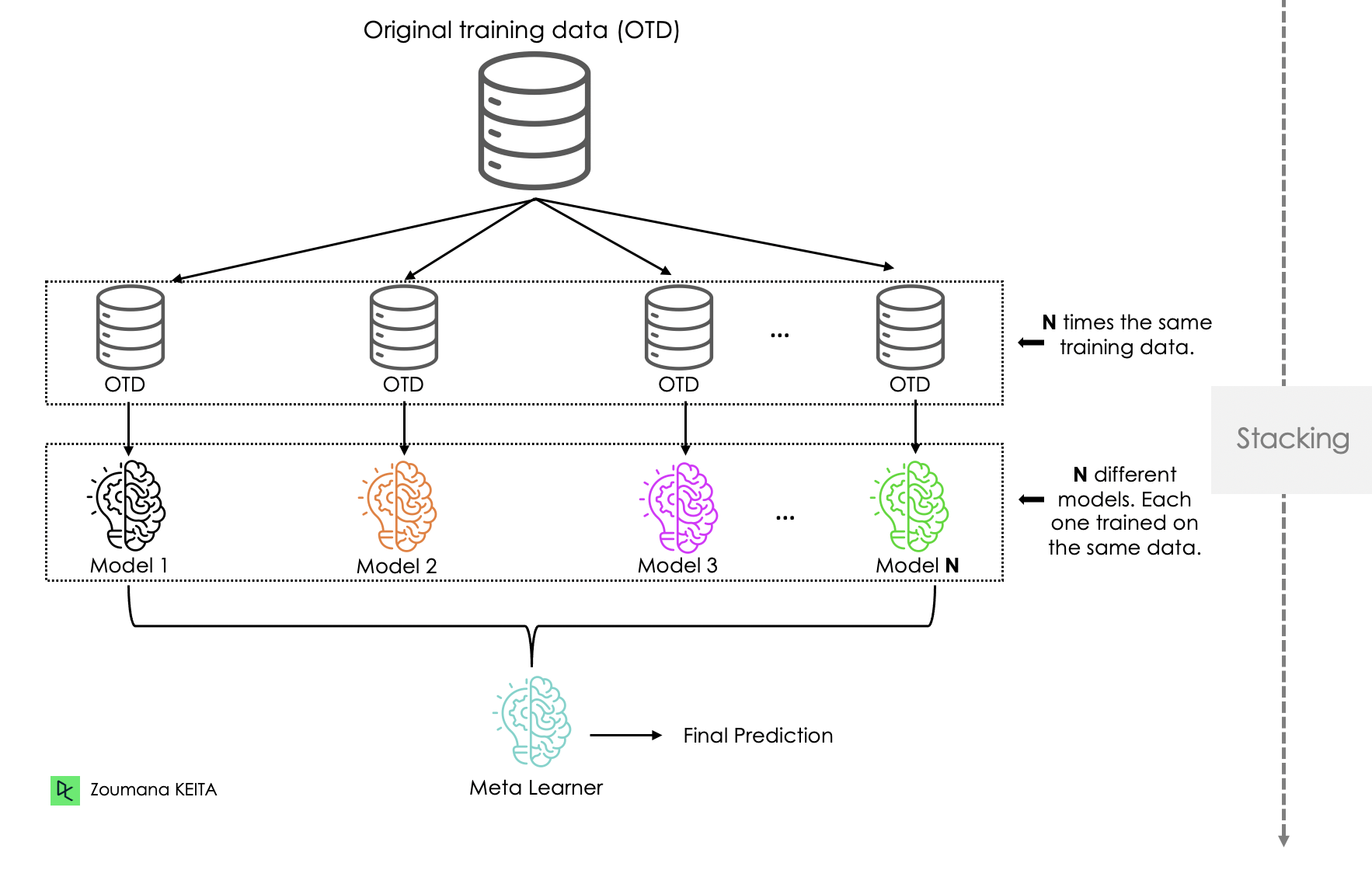
Blending is similar to Stacking. In blending, the structure of the data is made of training, hold-out, and test data. The meta learners are trained on the training data. Then their predictions are combined with the hold-out data to build the final meta model, which uses the test data to make the final predictions.
In voting, multiple models are trained independently, and their predictions are combined to make a final prediction using either hard voting, soft voting, or weighted voting:
Cascading uses a stacking approach but with only one model in each layer. The first model is trained on the whole training data, and the next model is trained on the output of the model before. The goal of using the strategy is to learn complex patterns from the data, hence allow the model to make better predictions.
The previous sections covered the different types of ensemble models. Now, let’s have a brief overview of some popular models.
Random Forest is a commonly used model that can solve both classification and regression problems. A random forest is made up of many decision trees that are trained using bagging. Its outcome is determined by taking the average of the prediction of individual trees.
The node size, the number of trees, and number of features sampled are the three main hyperparameters that need to be set before training the random forest.
What about randomness in a random forest?
Feature bagging, also known as feature randomness, creates a random sample of features to ensure low correlation among decision trees. This approach sets apart random forests from decision trees which consider all the possible feature splits, whereas random forests consider only a subset of those features. Read in our random forest classification tutorial.
Extreme Gradient Boosting, or XGBoost for short, is used for both classification and regression. XGBoost is designed to be scalable and highly efficient, and it implements the gradient boosting decision trees framework.
It is suitable for processing large-scale data sets, and is compatible with major distributed environments such as Hadoop, MPI (Message Passing Inference), and SGI (Sun Grid Engine). You can learn more in our XGBoost tutorial.
Adaptive Boosting, or AdaBoost, is one of the first ensemble boosting classifiers for successful boosting algorithms for binary classification. It is adaptive as the weights are re-assigned to every instance, and misclassified instances are assigned with higher weights. Read more about AdaBoost Classification in Python in our separate tutorial.
Now you understand the main idea of ensemble modeling and how some models work, this section will focus on the technical implementation using Python.
To begin, you will need to have Python installed on your computer, along with the following libraries:
You can install these libraries using pip, the Python package manager, as follows:
pip install scikit-learn
pip install pandas
pip install matplotlib seabornTo better illustrate the use case, we will be using the Loan Data available on DataLab. The code for this tutorial is also available on DataLab in this workbook; you can create your own workbook copy and edit and run the code in your browser without needing to install anything on your computer.
The data set has 9,500 loans with information on the loan structure, the borrower, and whether the loan was paid back in full, represented by the not.fully.paid column. The first five observations are shown below:
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()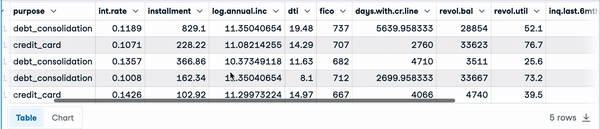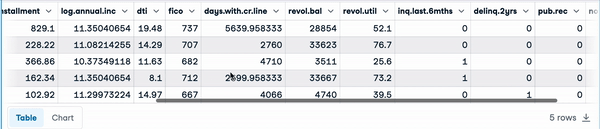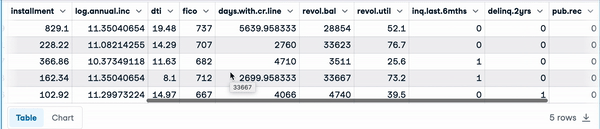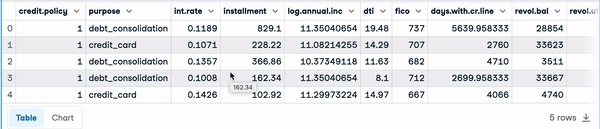
Using the info() function generates the following relevant information about the data:
purpose, which is object and gives the textual description of the purpose of the load. non-null tag for each column means that there is no missing information in that specific column in none of the columns. loan_data.info()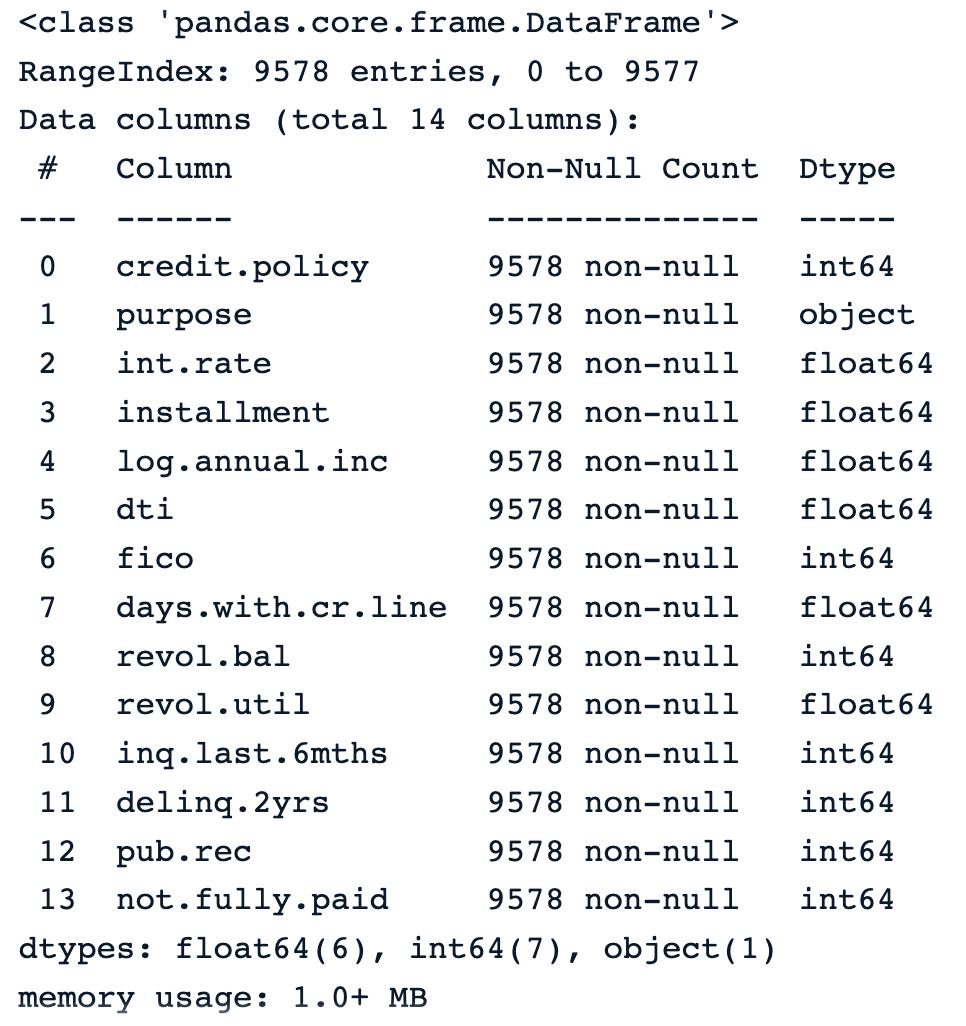
We notice an imbalanced data scenario, where there are many more observations with class 0 (8045 observations) than there are for class 1 (only 1533 observations).
print(loan_data['not.fully.paid'].value_counts())
loan_data['not.fully.paid'].value_counts().plot(kind='barh')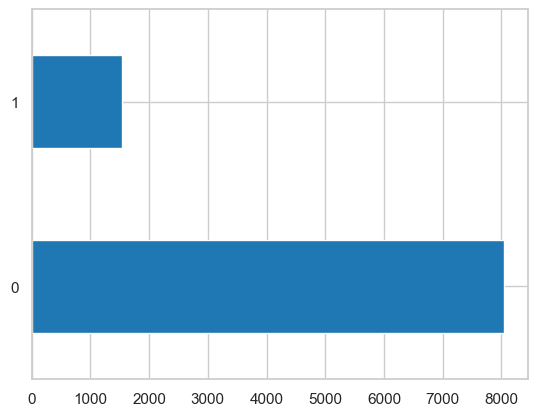
Using such imbalanced data for model training affects the overall performance.
One way of tackling this issue is using the undersampling approach, meaning we are reducing the number of the majority observations (class 0). In this scenario, there will be as many observations for class 0 as there are for class 1, and the process is as follows:
First get the number of class 1.
Select N random observations from class 0, where N is the size of the dataframe of class 1.
Concatenate the previous two dataframes.
loan_data_class_1 = loan_data[loan_data['not.fully.paid'] == 1]
number_class_1 = len(loan_data_class_1)
loan_data_class_0 = loan_data[loan_data['not.fully.paid'] == 0].sample(number_class_1)
final_loan_data = pd.concat([loan_data_class_1,
loan_data_class_0])
print(final_loan_data.shape)The Diving Deep with Imbalanced Data tutorial provides more resources to learn the techniques to deal with an imbalance dataset.
After the undersampling, we get:
And the final balanced distribution is shown below.
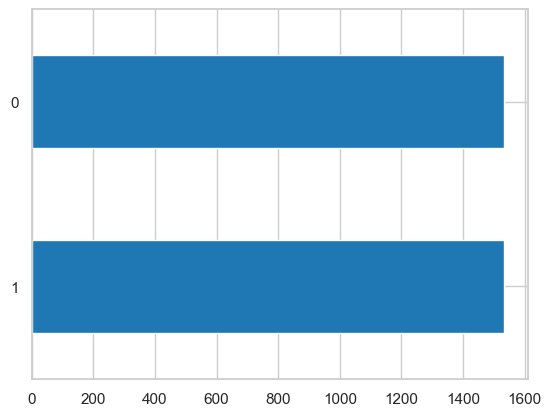
By looking at the data set, we notice that not all the features have the same scale, and some machine learning models such as KNN are sensitive to such a scaling. This issue can be addressed by normalizing the ranges of the features to the same scale using the MinMaxScaler module. In this case, between 0 and 1.
Also, we will remove the purpose column for simplicity’s sake since it requires additional preprocessing.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
# Remove unwanted 'purpose' column and get the data
final_loan_data.drop('purpose', axis=1, inplace=True)
X = final_loan_data.drop('not.fully.paid', axis=1)
normalized_X = scaler.fit_transform(X)Like in any predictive task, we need to split the data into training and testing sets. In this case, we will use 77% for training and the remaining 33% for testing.
Stratify is used to ensure that the y target value is evenly distributed in both training and testing data.
from sklearn.model_selection import train_test_split
y = final_loan_data['not.fully.paid']
r_state = 2023
t_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(normalized_X, y,
test_size=t_size,
random_state=r_state,
stratify=y)All the models will follow the sequence of training on the training data, make the prediction on the testing data and evaluate the models’ performance.
Random Forest is the bagging model used in this section. We will use the default parameters for simplicity.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# Define the model
random_forest_model = RandomForestClassifier()
# Fit the random search object to the data
random_forest_model.fit(X_train, y_train)After training the model, the performance is generated using the accuracy_score function as follows:
# Make predictions
y_pred = random_forest_model.predict(X_test)
# Get the performance
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy) The previous print statement generates 0.6156 which is 61.56%
Now let's compare this score to the performance of a blending aggregation approach.
For blending, we will use two base models: a decision tree and a K-Nearest Neighbors classifier. A final regression model is used to make the final predictions.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegressionThe original training data is split into a new training data set and a validation data set. The base models are trained on the training data.
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train,
test_size=t_size,
random_state=r_state)Two dataframes are then generated from the predictions of those base models:
# Decision Tree Model
dt_model = DecisionTreeClassifier()
dt_model.fit(X_train, y_train)
dt_model_pred_val = dt_model.predict(X_val)
dt_model_pred_test= dt_model.predict(X_test)
dt_model_pred_val = pd.DataFrame(dt_model_pred_val)
dt_model_pred_test = pd.DataFrame(dt_model_pred_test)
# KNN Model
knn_model = KNeighborsClassifier()
knn_model.fit(X_train,y_train)
knn_model_pred_val = knn_model.predict(X_val)
knn_model_pred_test = knn_model.predict(X_test)
knn_model_pred_val = pd.DataFrame(knn_model_pred_val)
knn_model_pred_test = pd.DataFrame(knn_model_pred_test)
The final logistic regression model is built using the concatenated validation data, and evaluated using the concatenated test data.
x_val = pd.DataFrame(X_val)
x_test = pd.DataFrame(X_test)
df_val_lr = pd.concat([x_val, knn_model_pred_val,
dt_model_pred_val], axis=1)
df_test_lr = pd.concat([x_test, dt_model_pred_test,
knn_model_pred_test],axis=1)
# Logistic Regression Model
lr_model = LogisticRegression()
lr_model.fit(df_val_lr,y_val)
lr_model.score(df_test_lr,y_test)Using the .score() function computes the accuracy score by default and does not need actual predictions.
The performance result is 0.6383, which is 63.83% and is around 2% higher than the initial random forest; hence the blending model provides the best performance.
Our course Ensemble Methods in Python and Machine Learning with Tree-Based Models in R could be a great next step to continue your machine learning journey by diving into the wonderful world of ensemble classifier methods, respectively in Python and R.
This article has covered different types of ensemble modeling along with their features, advantages and their disadvantages. Also, it provided a brief overview of some examples of ensemble model-based algorithms such as Random Forest, Adaboost, XGBoost, Gradient Boosting Trees, and Gradient Boosting machines.
When building ensemble models, it is important to be aware of their pros and cons for better business insights.
Homogeneous learners are learners with a similar type of algorithm and hyperparameters. Random forest can be considered to be an ensemble of homogeneous learners.
Heterogeneous ones, on the other hand, have different algorithms and hyperparameters. Random forest, neural network, and KNN can be heterogeneous learners of an ensemble model.
Using ensemble models can make better predictions over a single model.
Ensemble models can suffer from a lack of interpretability, meaning that the knowledge learned by the ensemble models is not understandable by end users.
The use of ensemble models should be avoided in the following conditions but not limited to: high interpretability, limited data, real-time constraint, and high computation cost.
Bagging, boosting, stacking, voting, blending, and cascading are the main types of ensemble methods in machine learning.
Learn more about Python and Machine Learning
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
Kurtis Pykes
Tutorial
Sayak Paul
Tutorial
Hugo Bowne-Anderson
Tutorial
Hugo Bowne-Anderson
