Machine learning operations (MLOps) is now a core focus for many data leaders and practitioners, with interest increasing significantly in the past two years. This meteoric rise is driven by a significant challenge faced by many organizations; investment in machine learning and AI is not delivering the promised return on investment.
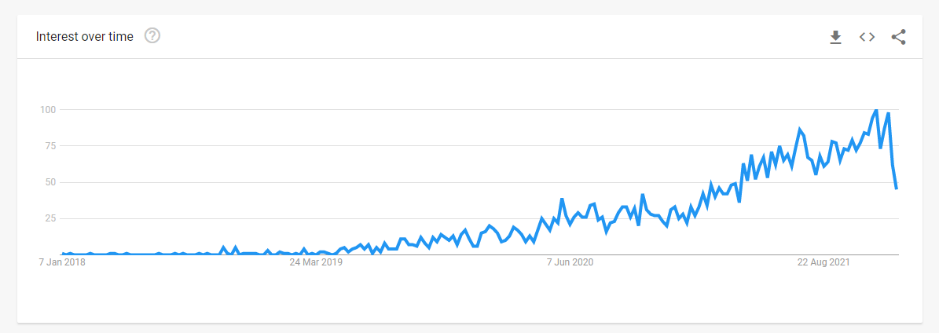
In 2019, Venturebeat reported that only 13% of machine learning models make it to production. While a recent poll by KDNuggets suggests an improvement in 2022, 35% of responders still cited technical hurdles preventing the deployment of their models.
McKinsey's State of AI 2021 report shows AI adoption is up to 56%, from 50% in 2020. As organizations ramp up investments in their machine learning systems and talent, the necessity to deploy and extract value from models efficiently becomes more apparent than ever. This is where MLOps comes in. Organizations that adopt MLOps successfully are seeing better returns on their investments. By adopting MLOps, data teams are reducing the time needed to prototype, develop, and deploy machine learning systems.
The goal of MLOps is to combine technology with organizational change to apply software engineering concepts to machine learning. By looking at machine learning as an engineering discipline, it promises a straightforward path to production and greater longevity models in production.
This article will define MLOps, why it’s important, and present five guiding principles that define a successful MLOps practice today.
What Is MLOps?
MLOps is best defined as "a set of tools, practices, techniques, and culture that ensure reliable and scalable deployment of machine learning systems." MLOps borrows from software engineering best practices such as automation and automated testing, version control, implementation of agile principles, and data management to reduce technical debt.
Technical debt or code debt is a concept from software engineering itself. It describes the “debt” accrued as a result of rapid development where processes such as automation, documentation, and unit tests are refactored at a later stage. In a nutshell, it is debt development teams carry into the future, by not adopting best practices in the present.
Machine learning systems can incur high levels of technical debt, as the models data scientists produce are a small part of a larger puzzle—one that is comprised of infrastructure, model monitoring, feature storage, and many other considerations.
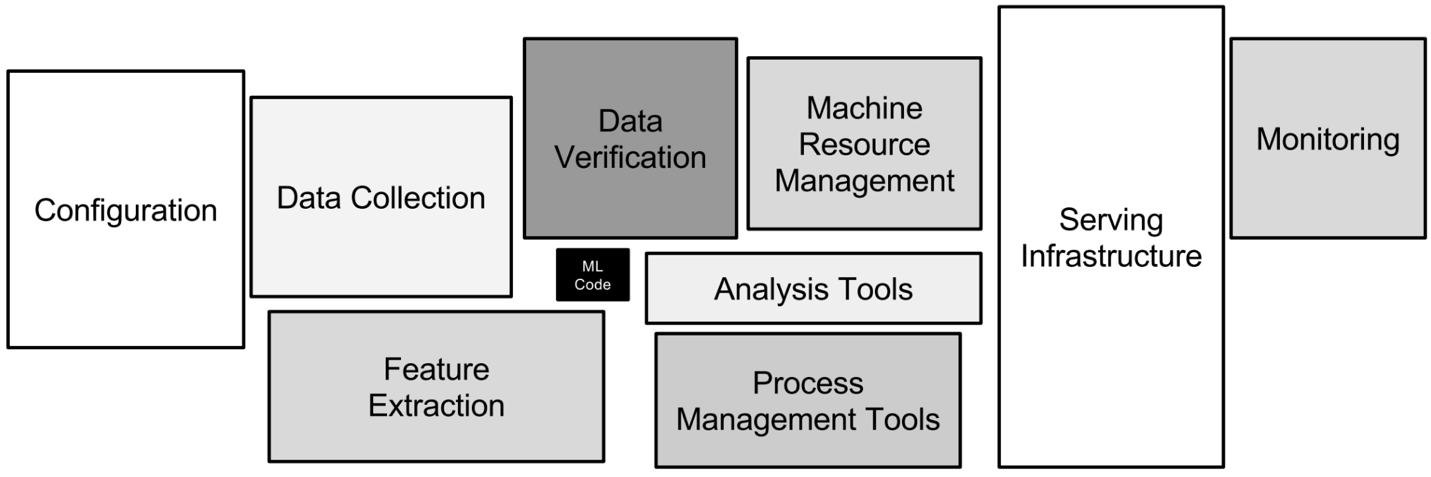
What makes MLOPs unique
The software engineering best practices aimed at reducing technical debt are often referred to as DevOps. DevOps combines the development activities of writing code, versioning, and testing with IT operations of release, deployment, and monitoring.
The two core principles of DevOps are Continuous Integration and Continuous Delivery (CI/CD).
- Continuous Integration (CI): New code changes are regularly built, tested, and merged into a shared repository.
- Continuous Delivery (CD): Any changes made to an application are automatically tested and uploaded to a repository, where they can be deployed into a live environment.
Productionizing and scaling machine learning systems bring in additional complexities. Software engineering is mainly designing well-defined solutions with precise inputs and outputs. On the other hand, machine learning systems rely on real-world data that is modeled through statistical methods. This introduces further considerations that need to be taken into account, such as:
- Data: Machine learning takes in highly complex input data. This data has to be transformed so that machine learning models can produce meaningful predictions.
- Modeling: Developing machine learning systems requires experimentation. To experiment efficiently, tracking data changes and parameters of each experiment is essential.
- Testing: Going beyond unit testing, where small, testable parts of an application are tested independently, machine learning systems require more complex tests of both the data and model performance. For example, testing whether new input data share similar statistical properties to the training data.
- Model Drift: Machine learning model performance will always decay over time. The leading cause of this is two-fold. Concept Drift is where the properties of the outcome we’re trying to predict change. A great example was during COVID-19 lockdowns, where many retailers experienced an unexpected spike in products such as toilet rolls. How would a model trained on standard data handle this? Data Drift on the other hand is where properties of the independent variables change due to various factors, including seasonality, changing consumer behavior, or the release of new products.
- Continuous Training: Machine learning models must be retrained as new data becomes available to combat model drift.
- Pipeline Management: Data must go through various transformation steps before it is fed to a model and should be regularly tested before and after training. Pipelines combine these steps to be monitored and maintained efficiently.
5 Principles for Successful MLOps
Adopting MLOps isn't as straightforward as simply engaging with a new SaaS vendor or spinning up new cloud computing instances. It requires careful planning and a consistent approach between teams and departments. Here are five principles for successful MLOps implementation:
Understand Your MLOps Maturity
Leading cloud providers such as Microsoft and Google look at MLOps adoption through a maturity model. This is because MLOps requires organizational change and modern working methods. This only happens over time as the organization's systems and processes mature.
Successful adoption of MLOps requires an honest assessment of the organization's progress in its MLOps maturity. After a reliable maturity level assessment, organizations can understand what tactics they can employ to move up the maturity level. This involves process changes like applying DevOps to deployment or adding new hires to the team.
Understanding how maturity levels can help organizations prioritize MLOps initiatives is also essential. For example, a feature store is a single repository for data that houses commonly used features for machine learning. Feature stores are helpful for relatively data mature organizations where many disparate data teams need to use consistent features and reduce duplicate work. If an organization only has a few data scientists, a feature store isn’t probably worth its time.
By using a maturity model for MLOps, organizations allow teams, processes, and their technology stack to develop together. It ensures iteration can happen and tools can be tested before implementation.
Apply Automation in Your Processes
Automation goes hand-in-hand with the concept of maturity models. Advanced and widespread automation facilitates increasing MLOps maturity for an organization. In environments without MLOps, many tasks within machine learning systems are executed manually. These tasks can include data cleaning and transformation, feature engineering, splitting training, and testing data, writing model training code, etc. By doing these steps manually, data scientists introduce more margin for error and lose time better spent on experimentation.
A great example of automation is continuous retraining, where data teams can set up pipelines for data ingestion, validation, experimentation, feature engineering, model testing, and more. Often seen as one of the early steps in machine learning automation, continuous retraining helps avoid model drift.
Pipelines in MLOps aren't any different from those in data engineering or DevOps. A machine learning pipeline is a series of steps that orchestrate data flow into and out of a machine learning model.
To illustrate the power of pipelines, we can imagine an example where data scientists have extracted some of the data manually but were able to automate their validation, data preparation, model training, and evaluation processes. This pipeline can be later re-used when the model is productionized to make predictions on new data.
Prioritize Experimentation and Tracking
Experimentation is a core part of the machine learning lifecycle. Data scientists experiment with datasets, features, machine learning models, corresponding hyperparameters, etc. There are many ''levers'’ to pull while experimenting. To find the right combination, tracking each iteration of experiments is essential.
In traditional notebook-based experimentation, data scientists track model parameters and details manually. This can lead to process inconsistencies and an increased margin for human error. Manual execution is also time-consuming and is a big obstacle in rapid experimentation.
While git is widely used for tracking code, it isn't easy to version control the different experiments data scientists run. This is where data teams can use model registries, a location for data scientists to store models, track performance, and other changes.
Tracking experiments enable data teams to roll back models if need be—and improve the overall model auditing process. It reduces a considerable manual effort for data scientists, leaving more time for experimentation. All of which results in significantly improved reproducibility of results through versioning and tracking
Go Beyond CI/CD
We've looked at CI/CD in the context of DevOps, but these are also essential components for high-maturity MLOps.
- When applying CI to MLOps, we extend automated testing and validation of code to apply to data and models.
- Similarly, CD concepts apply to pipelines and models as they are retrained.
We can also consider other "continuous' concepts":
- Continuous Training (CT): We've already touched on how increasing automation allows a model to be retrained when new data becomes available.
- Continuous Monitoring (CM): Another reason to retrain a model is decreasing performance. We should also understand whether models are still delivering value against business metrics.
Applying continuous concepts with automated testing allows rapid experimentation and ensures minimal errors at scale. Additionally, successful implementation of all four continuous concepts can drastically minimize the time to deployment.
Consider the example pipeline we looked at in the automation section. Applying CI/CD concepts to this would result in a codebase that is stored in a repository. In line with CI, a series of automated unit tests would be applied to this repository, such as testing engineered features, ensuring there are no missing values and testing for overfitting. The individual components of the pipeline can then be validated and deployed, ensuring compatibility and compute demands are tested and met. This level of automation allows swift new deployments, enabling organizations to react to external drivers and changes.
Adopt Organizational Change
Organizational change must happen alongside evolution in MLOps maturity. This requires process changes that promote collaboration between teams, resulting in a breaking down of silos. In some cases, restructuring overall teams is necessary to facilitate consistent MLOps maturity. Microsoft's maturity model covers how people's behavior must change as maturity increases.
Low-maturity environments typically have data scientists, engineers, and software engineers working in silos. As maturity increases, every member needs to collaborate. Data scientists and engineers must partner to convert experimentation code into repeatable pipelines, while software and data engineers must work together to automatically integrate models into application code.
Increased collaboration makes the entire deployment process less reliant on a single person. It ensures that teamwork is implemented to reduce costly manual efforts. These different areas of expertise come together to develop the level of automation high-maturity MLOps requires. Increased collaboration and automation are essential in reducing technical debt.
The Rise of MLOps is still in its infancy
MLOps was born out of a need to deploy ML models quickly and efficiently. With companies now heavily investing in machine learning, more and more models are being developed, increasing the demand for MLOps. While MLOps is still in its early stages, it is safe to say that organizations are looking to converge around a set of principles that can unlock the ROI of machine learning.
If you’re interested in learning more about MLOps, you can also check out the following resources:
- A practical guide to MLOps by Noah Gift
- Operationalizing Machine Learning with MLOps with Alessya Visnjic
- From Predictions to Decisions with Dan Becker
- Our Guide to MLOps Certifications
