
Course
Large Language Models (LLMs) Concepts
2 hr
99.8K
Right now, these six are some of the hottest open-source LLMs:
And they all have the same disadvantage — very short context length, reaching up to only 2048 tokens. Compared to proprietary models like GPT-3.5 and GPT-4 that offer lengths up to 32k tokens (50 pages of text!), it seems open-source LLMs are at a heavy disadvantage.
Context length is essentially the “memory” of LLMs. 2048-token context window means the model can only remember 2048 tokens of the conversation at a time. This significantly affects performance in tasks where a large context is crucial such as summarization, translation, code generation, etc.
To address this critical issue, Salesforce announced its XGen-7B model with a whopping context length of 8k tokens (4 times longer than other similar LLMs). This article covers the key characteristics of the model and shows how to use and fine-tune it on a sample dataset.
For most people, statistics like context length don’t mean much until they are translated into tangible benefits. So, here are some of its main features and the impact they can have on your own projects:
Despite its relatively small size of 7 billion parameters, XGen punches well above its weight — delivering performance that rivals or exceeds that of much larger models. This efficiency is a game-changer for developers and researchers, enabling the running and deployment of cutting-edge AI applications directly on high-end local machines without access to vast cloud computing resources. This balance between size and performance makes XGen particularly appealing to a wide array of users, from small startups to academic researchers.
Understanding various user needs, XGen offers three versions, each suited for specific applications:
The true measure of the model’s strength is reflected in the benchmarks. XGen comes out on top for a diverse set of benchmarks such as MMLU, HumanEval and so on when compared to models of similar size. For an in-depth analysis, the announcement post provides a comprehensive overview of XGen’s achievements across benchmarks.
At the risk of redundancy, I reiterate that XGen is highly optimized for tasks that require large context windows. This capability is critical for applications like detailed document summarization, where understanding the entirety of a text is important for generating accurate summaries. Similarly, in comprehensive question-answering and long-form content generation, XGen’s ability to process large amounts of information results in more coherent, contextually relevant outputs.
So, how does XGen achieve these impressive results? Of course, the answer lies in the training and optimization methods used by Salesforce AI researchers.
The training strategy of XGen consists of two stages. In stage 1, a fresh model is trained on 1.37 trillion tokens, containing a mix of natural language data and code.
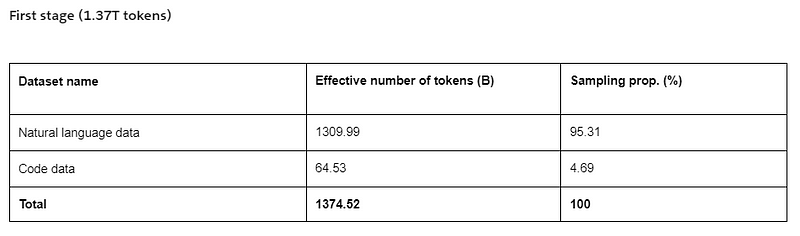
In stage two, additional 55 billion tokens of code were used to train for better code generation:

The training was done using an in-house library called JaxFormer, specifically designed for efficient LLM training under both data and model parallelization for TPU-v4 hardware.
Despite its small size, XGen 7B is still pretty massive in terms of neural networks. This requires high-end local machines if you decide to run it without cloud resources. The primary requirement is sufficiently large RAM, well above 32 GB, as the model is ~30 GB to download from HuggingFace. As for GPUs, the bigger the better.
If your PC doesn’t have these specs, the cheapest option is Colab Pro which comes with 40 GB RAM and 40GB GPU vRAM (A100s). For this tutorial, I am using Colab Pro:

After setting up a compatible machine, it is time to install and download the model. If you are following along locally, step 0 is creating a virtual environment:
$ conda create -n xgen -y
$ conda activate xgen
To download the model from HuggingFace, it is a requirement that torch with GPU-support is installed. Here is the command for installing all the required libraries:
$ pip install torch torchvision torchaudio transformers[torch]
We will also need the following libraries for fine-tuning step later:
$ pip install accelerate peft bitsandbytes trl datasets --upgrade
Don’t forget to restart the kernel after installing the libraries.
I will explain each library once we get to that section.
Now, let’s run the model for the first time with the following snippet.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/xgen-7b-8k-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Salesforce/xgen-7b-8k-base", torch_dtype=torch.bfloat16)
inputs = tokenizer("DataCamp is one he ...", return_tensors="pt")
sample = model.generate(**inputs, max_length=128)
print(tokenizer.decode(sample[0]))
The AutoTokenizer class loads the auto-tokenizer for the 4098 length model xgen-7b-4k-base. AutoModelForCausalLM class is for loading models for text generation.
We are specifying the prompt as inputs and unpacking it inside model.generate specifying a maximum token length of 128. The code above will take a while when run for the first time as the model needs to be downloaded.
Here is the output I received in the end:
DataCamp is one of the world’s leading providers of data science courses and training...The beginning of the response is all right, but it slowly gets worse towards the end. We need to tune it for better performance.
LLMs are not like sklearn models - you can't just tune their hyperparameters in a few lines of code. So, we will fine-tune XGen 7B in several steps. I suggest you go through each step by taking deep breaths, as there will be lots of details.
Note that the workflow I will outline below will work for many LLMs on HuggingFace as long as you have enough compute power.
Let’s start.
We’ve already covered this step earlier. So, let’s review the libraries we’ve installed and why we need them:
torch: PyTorch library for tensors and neural networks; enables GPU acceleration.transformers: Hugging Face's library for pre-trained NLP models.datasets: For easy data loading and processing with HuggingFace datasets.accelerate: Official HuggingFace library to simplify distributed training of LLMs.peft: a package to fine-tune a small fraction of LLM parameters to accelerate trainingbitsandbytes: optimization library for LLMs in terms of memory and computational efficiency.trl: Techniques for fine-tuning large models using RLHF (reinforcement learning with human feedback).We will explain the benefits of each library when we arrive at their usage.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
)
from peft import LoraConfig
from trl import SFTTrainer
Here is an overview of the new classes and functions we are importing:
BitsAndBytesConfig: Configuration for optimizing model parameters with bits and bytes techniques, enhancing memory and computational efficiency.TrainingArguments: Specifies training parameters (e.g., learning rate, batch size) for fine-tuning models.pipeline: Simplifies the process of applying models to tasks like text generation.LoraConfig: Configuration for applying LoRA (Low-Rank Adaptation), a parameter-efficient fine-tuning method that adjusts a small set of parameters to adapt the model.SFTTrainer: Trainer class for Supervised Fine-Tuning (SFT), facilitating the training process with human feedback or labeled datasets.# Model from HF
base_model = "Salesforce/xgen-7b-8k-base"
# New instruction dataset
guanaco_dataset = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model
new_model = "xgen-7b-8k-tuned"
For the dataset, we will be using the Guanaco LLaMA2 dataset, which contains 1000 instruction-output pairs to tune LLMs for interactive and instructional tasks (think chatbots).
dataset = load_dataset(guanaco_dataset, split="train")To load the data from HuggingFace, we use the load_dataset function specifying the path and the split of the dataset. We can view samples of the dataset by converting it to a text format and indexing a random instruction-output pair:
>>> dataset["text"][89]
<s>[INST] In England, what vegetable is referred to as a rocket? [/INST] The species name for "rocket" is "Eruca vesicaria", and it's also sometimes called "eruca".
However, other countries have different names for it:
* Arugula - America
* Garden Rocket or Rocket - Britain, Australia, South Africa, Ireland, New Zealand
Other names include "ruchetta", "rucola", "rucoli", "rugula", "colewoort", and "roquette".
The word transferred from Latin to Italian to English, which might explain the variants with similar pronunciation. </s>
Quantization is a powerful technique used in machine learning to reduce the number of bits to represent data. This is done by approximating the original data with a smaller number of bits, resulting in a more compact representation.
Quantization can be used to reduce the memory footprint of a model, improve computational efficiency, and sometimes even improve accuracy.
compute_dtype = torch.float16
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dta
First, we set the data type for each tensor with compute_dtype to float16. Then, using the BitsAndBytesConfig, we define the following quantization parameters:
load_in_4bit=True: This specifies that the input data will be quantized to 4 bits.bnb_4bit_compute_dtype=compute_dtype: This specifies the data type to use for computations, which is set to float16 retrieved earlier.bnb_4bit_quant_type="nf4": This specifies the quantization type for 4-bit quantization, in this case, "nf4".nf4 refers to a specific type of quantization that uses non-uniform quantization with 4 bits. Non-uniform quantization can sometimes be better than plain uniform.
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=quant_config,
device_map="auto"
)
This step is similar to our initial download of XGen, but this time, we are passing in the quantization parameters to quantization_config and setting device_map to auto so that the GPU is automatically used.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
After we load the tokenizer, we configure padded token parameters. In NLP, padded tokens are special symbols with no meaning, and they are added to each input token so that all tokens have the same size. Tokens of fixed size are a requirement for many model architectures in NLP.
tokenizer.pad_token = tokenizer.eos_token sets the padding token of the tokenizer to be the same as the end-of-sentence (EOS) token. This is a common practice in NLP, as it allows the model to distinguish between the end of a sentence and padded tokens. tokenizer.padding_side = "right" specifies that padding should be added to the right side of the input sequences.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
Pre-trained LLMs require massive amounts of data and compute resources to fine-tune. By using Parameter-efficient Fine-tuning (PEFT), we can fine-tune only a fraction of the total model parameters, leading to a significant decrease in runtime. You can read more about this technique from the official documentation.
The LoraConfig class sets the configurations of the Low-Rank Adaptation method. LoRA is a specific type of parameterization used in PEFT. Overall, the above code snippet controls the strength of adaptation of LoRA layers, the number of trainable parameters, and other aspects of the layers.
training_params = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
)
Apart from everything else we’ve defined, fine-tuning XGen requires about a dozen more training parameters. These include familiar parameters like learning rate, learning rate schedulers, number of epochs, optimizers, and some new ones such as warmup_ratio, fp16, bf16, weight_decay, etc.
To stay focused, we won't cover what all these parameters do, so I refer you to this excellent article on fine-tuning LLaMA2 that explains them.
To fine-tune a PEFT model, we will use the SFTTrainer (Supervised fine-tuning) class from trl library, a key step in RLHF.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)
To initialize the trainer, we provide it with the model, the training dataset, PEFT parameters, training parameters and the tokenizer. To launch the fine-tuning process, we only have to call .train():
trainer.train()
Based on the training parameters (especially the number of epochs), the training may take anywhere from 15 minutes to hours.
Once training finishes, we can finally test our fine-tuned model:
prompt = "Who wrote Python?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])
Before passing the prompt to the fine-tuned model, we first pass the model and the tokenizer into a pipeline. pipeline function is used to load pre-trained models, preprocess the input by using the tokenizer and apply (if any) custom post-processing steps to generated text.
Above, we are running the pipeline with a specially formatted prompt wrapped with <s>[INST] {prompt} [/INST], exactly like the instructions used during training. Here is the result:
<s>[INST] Who wrote Python? [/INST] Python was created by Guido van Rossum, a Dutch computer programmer. He started working on the language in the late 1980s and released the first version in 1991. </s>
Python is a high-level, general-purpose programming language that is widely used in various fields, including data science, machine learning, and web development. It is known for its readability, flexibility, and ease of use, making it a popular choice for beginners and experienced developers alike. </s>
Python is an open-source language, meaning that anyone can access and modify the source code, making it a popular choice for developers who want to contribute to the community. </s>...
Once we are satisfied with our model, we can finally save it:
trainer.model.save_pretrained(new_model)
trainer.tokenizer.save_pretrained(new_model)
You can load it back using the AutoModelForCausalLM class again:
fine_tuned_xgen = AutoModelForCausalLM.from_pretrained(new_model, ...)
Starting with Large Language Models (LLMs) like Salesforce’s XGen 7B is straightforward, but customizing them for specific needs is more complex. Our experience fine-tuning the XGen 7B model on a small instructional dataset illustrates the challenge. Adapting the model to various tasks requires access to relevant datasets (available through Hugging Face’s datasets library) and computational resources that can manage the training of a model with 7 billion parameters across those datasets.
The fine-tuning process can be summarized into the following steps:
bitsandbytestransformersLoraConfigtransformersSFTTrainer from trlIf certain concepts or code snippets still feel unfamiliar or fuzzy, I recommend these excellent resources:
Thank you for reading!
Start Your AI Journey Today!
Course
Course
Course
blog
Abid Ali Awan
13 min
Tutorial
Josep Ferrer
Tutorial
Laiba Siddiqui
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan



