
Course
Understanding ChatGPT
1 hr
424.4K

LoRA: Low-Rank Adaptation of Large Language Models
The field of machine learning and natural language processing (NLP) has witnessed a remarkable advancement with the introduction of Large Language Models (LLMs) such as GPT, LLaMa, Claude 2, etc. These models have shown exceptional capabilities in various applications, ranging from text generation to language understanding.
However, the practical deployment and fine-tuning of these models come with significant challenges, primarily due to their size and complexity.
This is where Low-Rank Adaptation (LoRA) comes into play, offering an effective solution to these challenges.
The objective of this tutorial is to build a theoretical and practical understanding of What LoRA is and how you can benefit from it.
The inception of LoRA dates back to early 2021, following the release of GPT-3. Microsoft, in collaboration with OpenAI, faced the challenge of making large models like GPT-3 commercially viable.
They discovered that one-shot prompting alone was insufficient for achieving optimal performance in production, especially for complex tasks like translating natural language to code. This led to an exploration of fine-tuning methods that were cost-effective yet efficient.
The invention of LoRA is based on the product's need to enable fast, efficient, and cost-effective fine-tuning of large language models to enable domain specificity, efficient task switching, or user switching at run time.
The LoRA research paper was published in October 2021 by a team of researchers from Microsoft.
Let’s understand the problem before we even understand what LoRa is and how it solves it.
Large language models like GPT-4, Claude 2, LLaMA 70b, etc., are great, but they are very generic and large. To adopt these large language models for specific domains like healthcare or banking or for specific tasks like converting text into code, we need something called fine-tuning.
Fine-tuning is the process of training a pre-trained model on a specific, smaller dataset to specialize its performance on a particular task or domain. As the models get larger (For example, GPT-3 has 175 billion parameters), full fine-tuning, which retrains all model parameters, becomes less feasible because of time, cost, and resources.
LoRA is a technique used for fine-tuning large models.
At a high-level here is how LoRA works:
It keeps the original model unchanged and adds small, changeable parts to each layer of the model. This significantly reduces the trainable parameters of the model and reduces the GPU memory requirement for the training process, which is another significant challenge when it comes to fine-tuning or training large models.
For example, Full fine-tuning of the GPT-3 model will require us to train 175 billion parameters. Using LoRA, the trainable parameters for GPT-3 will be reduced roughly by 10,000 times and GPU memory requirements by three times.
In essence, LoRA solves these problems:
Before we go into the details of LoRA, let’s understand the concept of Lower-rank matrices.
Lower-rank matrices are a concept in mathematics, specifically in the field of linear algebra. In simple terms, the rank of a matrix is a measure of the "information content" or the "dimensionality" of the data represented by the matrix. Let's break this down:
Example:
Consider a 3 x 3 matrix:
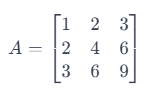
Here, the second row is just the first row multiplied by 2, and the third row is the first row multiplied by 3. This means the rows are not linearly independent. The rank of this matrix is 1 (since only the first row is independent), which is lower than the maximum possible rank for a 3x3 matrix, which is 3. So, this is a lower-rank matrix.
Lower-rank matrices are significant in various applications like data compression, where reducing the rank of a matrix helps to compress the data while preserving as much information as possible.
The rank in a matrix applies equally to both rows and columns. The crucial point to understand is that the rank of a matrix is the same whether you calculate it based on rows or columns. This is because of a fundamental property in linear algebra known as the Rank-Nullity Theorem.
In simpler terms, the theorem states that the dimensions of the row space (space spanned by the rows) and the column space (space spanned by the columns) of a matrix are equal. This common dimension is what we refer to as the rank of the matrix.
So, in the above example of the 3 x 3 matrix, the rank is 1, which means there is only one linearly independent row and only one linearly independent column.
In very simple words, LoRA leverages the concept of lower-rank matrices to make the model training process extremely efficient and fast.
Large models have a lot of parameters. For example, GPT-3 has 175 billion parameters. These parameters are just numbers stored in matrices. Storing them requires a lot of storage.
Full fine-tuning means all the parameters will be trained, and this will require an extraordinary amount of compute resources that can easily cost in the millions of dollars for a model size like GPT.
Unlike traditional fine-tuning that requires adjusting the entire model, LoRA focuses on modifying a smaller subset of parameters (lower-rank matrices), thereby reducing computational and memory overhead.
LoRA is built on the understanding that large models inherently possess a low-dimensional structure. By leveraging low-rank matrices, LoRA adapts these models effectively. This method focuses on the core concept that significant model changes can be represented with fewer parameters, thus making the adaptation process more efficient.
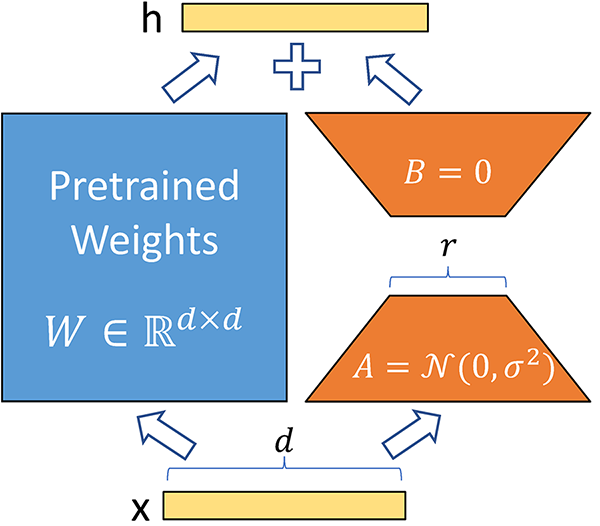
Source: Fine-Tuning LLMs: LoRA or Full-Parameter? An in-depth Analysis with Llama 2
First, we decompose the large weight matrices into smaller matrices using the lower-rank matrix technique, as explained above. This drastically reduces the number of trainable parameters. For a model like GPT-3, trainable parameters are reduced by 10000 times. This means instead of training 175 billion parameters, if you apply LoRA, you only have 17.5 million trainable parameters.
We do not change any parameters for a pre-trained model. Instead, only train lower-rank matrices, which happen relatively very quickly because of fewer parameters.
The weights are additive. This means for inference, we just add the weights of lower-rank matrices to pre-trained weights without any additional latency. The lower-rank matrices are very small in size as well so it is very easy to load and unload them for different tasks and different users.
There are several advantages that come with using LoRA for fine-tuning:
LoRA reduces the computational burden, allowing faster adaptation of models. By requiring fewer trainable parameters, LoRA makes it feasible to fine-tune large models on less powerful hardware.
Despite the reduced parameter count, LoRA maintains the original model's quality and inference speed.
LoRA dramatically reduces the size of model checkpoints. For instance, on GPT-3, the checkpoint size was reduced from 1 TB to just 25 MB.
LoRA does not introduce any additional latency during inference. While low-rank matrices are used during training, they are merged with the original parameters for inference, ensuring no slowdown. This enables rapid model switching at run time without additional inference latency.
LoRA is applicable to any model that utilizes matrix multiplication (such as support vector machine), making it a broadly applicable technique in many other use cases. In fact, LoRA is widely used in Stable Diffusion models to ingest the style in large image models.
The LoRA technique is also widely adopted in image models like Stable Diffusion.
The idea is pretty much the same as language models. Instead of fully fine-tuning large models like Stable Diffusion, we only train lower-rank matrices on small datasets.
In the case of language models, the goal is domain specificity. For image models, the most obvious use case is to adopt a style or a consistent character when generating images.
These lower-rank matrices are known as adapters; they are very small in size, and there are thousands of them on the internet that you can download and put on top of your base Stable Diffusion model and generate style-specific images.
Some common uses of LoRA Stable Diffusion models are:
You can combine multiple LoRAs to get outputs reflecting multiple specializations.

Different adapters for Stable Diffusion Models (Image Source)
If you want to learn how to successfully fine-tune Stable Diffusion XL on personal photos, check out Fine-tuning Stable Diffusion XL with DreamBooth and LoRA blog on Datacamp.
Prefix tuning is a lightweight method where continuous vectors called "prefixes'' are optimized and added to the input of each Transformer layer. The model is trained in a prefix-stripped manner, focusing only on these vectors.
LoRA and prefix tuning can be combined within the PEFT (Parameter Efficient Fine-Tuning) framework:
To implement LoRA, you can use the Loralib library by Microsoft. To install the library:
pip install loralib
The way you normally train your neural network doesn’t change much for the adoption of LoRA.
# ===== Before =====
# layer = nn.Linear(in_features, out_features)
# ===== After ======
import loralib as lora
# Add a pair of low-rank adaptation matrices with rank r=16
layer = lora.Linear(in_features, out_features, r=16)
Before the training loop begins, you simply have to add:
import loralib as lora
model = YourNeuralNetwork()
# This sets requires_grad to False for all parameters
lora.mark_only_lora_as_trainable(model)
# Training loop
for batch in dataloader:
...
When saving a checkpoint, you can generate a state_dic that only contains LoRA parameters.
# ===== Before =====
# torch.save(model.state_dict(), checkpoint_path)
# ===== After =====
torch.save(lora.lora_state_dict(model), checkpoint_path)
If you do not understand Neural Networks well enough, do not worry. Check out How to Train a LLM with PyTorch blog to master the process of training large language models using PyTorch, from initial setup to final implementation.
Credits: The code example has been re-produced from Microsoft/LoRA github.
LoRA emerges as an indispensable technique in addressing the substantial challenges posed by the size and complexity of large models.
By leveraging lower-rank matrices, LoRA offers a more efficient and cost-effective approach to model adaptation, significantly reducing the trainable parameters and GPU memory requirements, thus enabling faster training and memory efficiency.
The application of LoRA extends beyond language models, finding utility in image models like Stable Diffusion, where it facilitates style specialization and character consistency in image generation.
If you are curious and want to learn more about what you can build with these technologies, check out our guide on 5 Projects You Can Build with Generative AI Models blog to learn more.
Start Your AI Journey Today!
Course
Course
Course
blog
Javier Canales Luna
12 min
blog
Abid Ali Awan
8 min
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan


