
Course
Understanding ChatGPT
1 hr
424.4K
The rise of large language models (LLMs) has been a defining trend in the realm of Natural Language Processing (NLP), leading to their widespread adoption across various applications. However, this advancement has often been exclusive, with most LLMs developed by resource-rich organizations remaining inaccessible to the public.
This exclusivity poses a significant question: What if there was a way to democratize access to these powerful language models? This is where BLOOM enters the scene.
This article is a complete overview of what BLOOM is by first providing more details about its genesis. Then, it walks through the technical specifications of BLOOM and how to use it before highlighting its limitations and ethical considerations.
BigScience Large Open-science Open-access Multilingual Language Model (BLOOM for short), represents a considerable advance in democratizing language model technology.
Developed collaboratively by over 1200 participants from 39 countries, including a significant number from the United States, BLOOM is the product of a global effort. Coordinated by BigScience in collaboration with Hugging Face and the French NLP community, this project transcends geographical and institutional boundaries.
It is an open-source and a decoder-only transformer model with 176B-parameter trained on the ROOTS corpus, which is a dataset of over hundreds of sources in 59 languages: 46 spoken languages and 13 programming languages.
Below is the piechart of the distribution of the training languages.
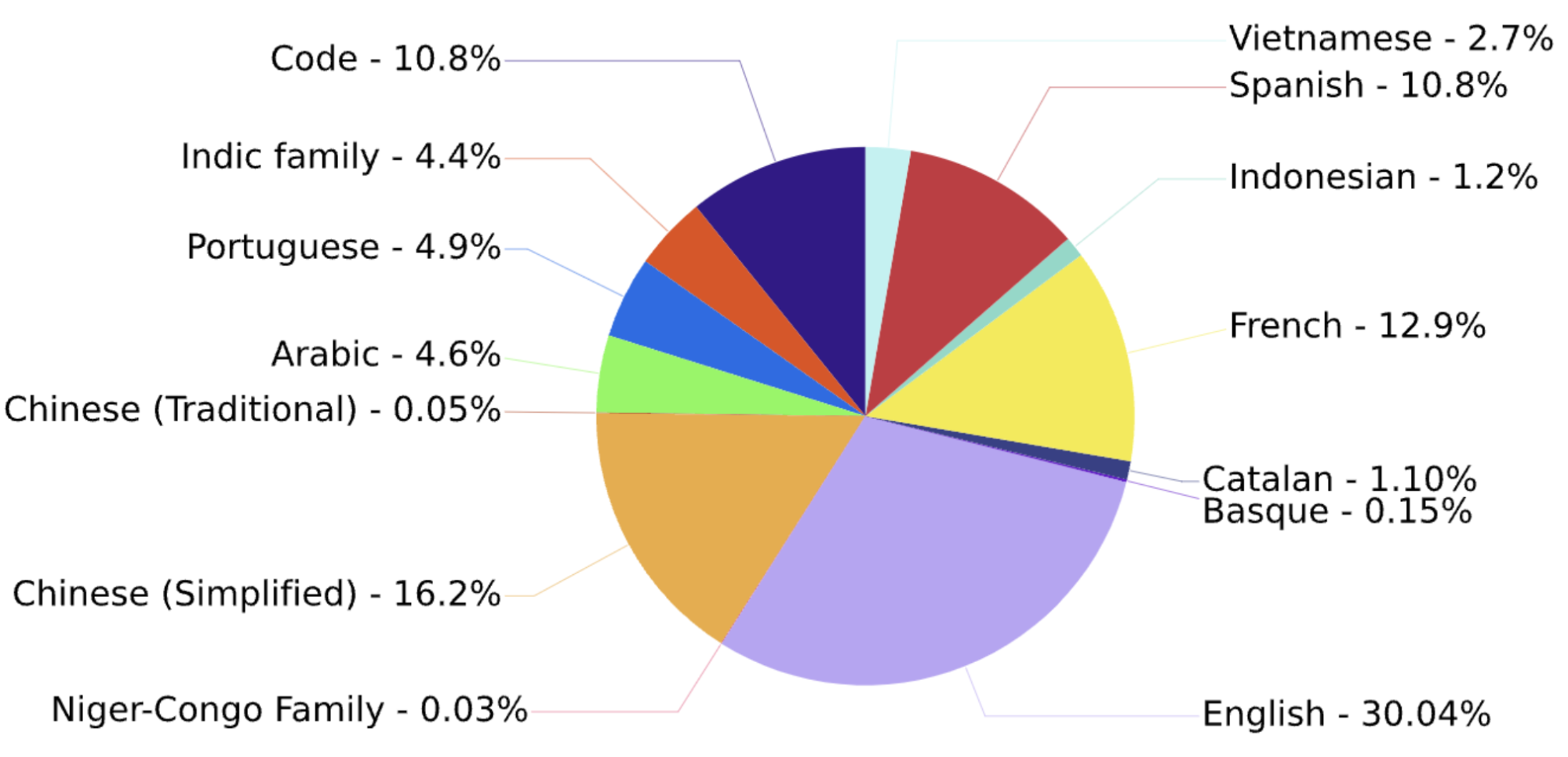
Distribution of the training languages (source)
The model was found to achieve a remarkable performance on a wide variety of benchmarks, and it reached better results after multitask prompted finetuning.
The project culminated in a 117-day (March 11 - July 6) training session on the Jean Zay supercomputer in Paris, backed by a substantial compute grant from the French research agencies CNRS and GENCI.
BLOOM stands not only as a technological marvel but also as a symbol of international cooperation and the power of collective scientific pursuit.
Now, let's describe BLOOM’s architecture in more detailed manner, which involves multiple components.
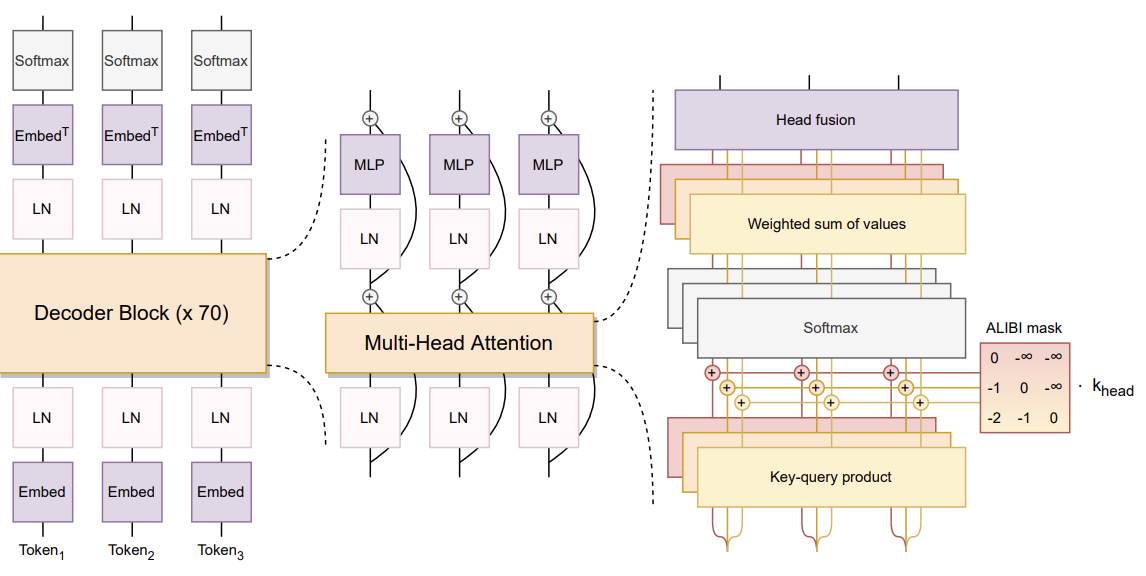
Bloom architecture (source)
The architecture of the BLOOM model, as detailed in the paper, includes several notable aspects:
These components reflect the team's focus on balancing innovation with proven techniques to optimize the model's performance and stability.
In addition to the architectural components of BLOOM, let’s understand two additional relevant components: data preprocessing and prompted datasets.
In this example, we'll use BLOOM to generate a creative story. The code provided is structured to set up the environment, prepare the model, and generate text based on a given prompt. The corresponding source code is available on GitHub, and it is highly inspired of the amrrs tutorial.
The BLOOM model is resource intensive, hence a proper configuration of the workspace is crucial, and the main steps are described below.
First, the transformer library is used to provide the interfaces for working with the BLOOM model, and other transformer-based nodels in general.
!pip install transformers -qUsing nvidia-smi, we check the properties of the available GPU to ensure we have the necessary computational resources to run the model
!nvidia-smi
We import required modules from transformers and torch. torch is used for setting the default tensor type to leverage GPU acceleration.
Then, since we are using a GPU, the torch library is set up using the set_default_tensor_type function to ensure the use of the GPU.
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
torch.set_default_tensor_type(torch.cuda.FloatTensor)The target model being used is the 7 billion parameter BLOOM model, and it is accessible from BigScience’s Hubbing Face repository under bigscience/bloom-1b7, which corresponds to the unique identifier of the model.
model_ID = "bigscience/bloom-1b7"Next, we load the pre-trained BLOOM model and tokenizer from Hugging Face, and set the seed for reproducibility using the set_seed function with any number. The value of the number itself does not matter, but it is important to use a non-floating value.
To learn more about the untapped potentials of Large Language Models with Langchain, which is an open-source Python framework for building advanced AI applications, our tutorial How to Build LLM Applications with LangChain Tutorial is the right guide.
Furthermore, if you are data engineer and interested in the use of LangChain for data applications, our article Introduction to LangChain for Data Engineering & Data Applications provides an overview of what you can do with LangChain, including the problems that LangChain solves and examples of data use cases.
model = AutoModelForCausalLM.from_pretrained(model_ID, use_cache=True)
tokenizer = AutoTokenizer.from_pretrained(model_ID)
set_seed(2024)
Now, we can define the title of the story to be generated, along with the prompt.
story_title = 'An Unexpected Journey Through Time'
prompt = f'This is a creative story about {story_title}.\n'Finally, we tokenize the prompt and map to the appropriate model device before generating the model’s result after decoding.
input_ids = tokenizer(prompt, return_tensors="pt").to(0)
sample = model.generate(**input_ids,
max_length=200, top_k=1,
temperature=0, repetition_penalty=2.0)
generated_story = tokenizer.decode(sample[0], skip_special_tokens=True)The final result is formatted using the textwrap module, to ensure that the maximum number of characters per line is 80 for better readability.
import textwrap
wrapper = textwrap.TextWrapper(width=80)formated_story = wrapper.fill(text=generated_story)
print(formated_story)The final result is given below:
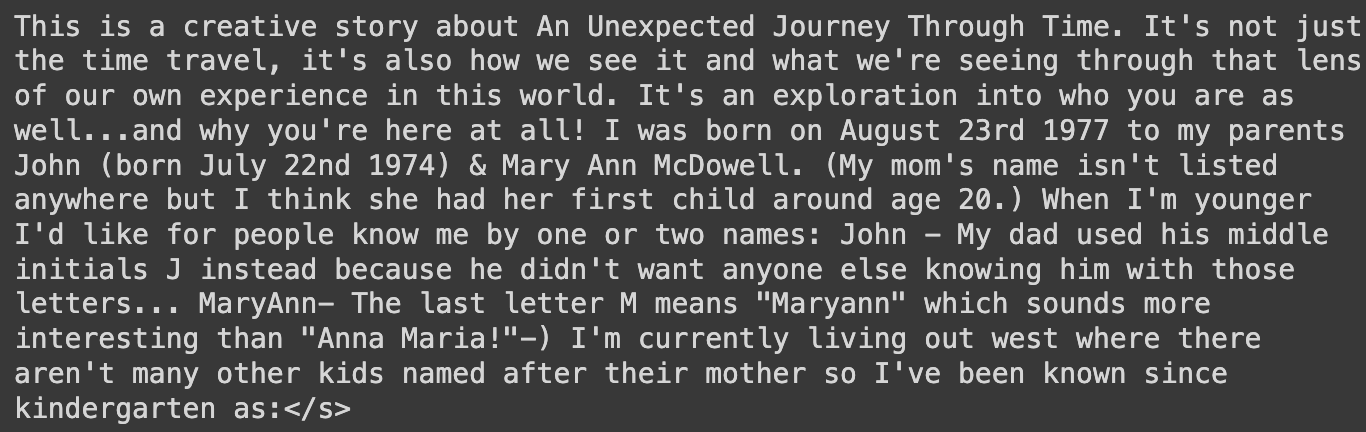
Story generated using BLOOM model
With a few lines of code, we were able to generate meaningful content using the BLOOM model.
If you are interested in mastering the process of training large language models using PyTorch, from initial setup to final implementation, our tutorial How to Train an LLM with PyTorch provides a complete guide to reach that goal.
Like all technological advancements, BLOOM comes with its own set of suitable and unsuitable applications. This section delves into its appropriate and inappropriate use cases, highlighting where its capabilities can be best utilized and where caution is advised. Understanding these boundaries is crucial for harnessing BLOOM's potential responsibly and effectively.
BLOOM is a versatile tool designed to push the boundaries of language processing and generation. Its intended uses span across various domains, each leveraging its expansive language capabilities.
Understanding the limitations of BLOOM is crucial to ensure its ethical and practical application. Some use cases fall outside the scope of what BLOOM LLM is intended for, primarily due to ethical considerations or technical constraints.
BLOOM, as an advanced Large Language Model (LLM), offers a wide array of benefits that extend to various user groups. Its capabilities not only directly influence certain professionals and sectors but also have a broader effect, indirectly impacting a wider range of stakeholders.
This exploration of BLOOM's users aims to highlight how different groups leverage and are affected by this innovative tool.
By understanding the direct and indirect users of BLOOM, we can appreciate the model's extensive influence and the diverse ways in which it contributes to advancing technology and society.
The deployment of BLOOM, like any Large Language Model (LLM), brings with it a range of ethical considerations and limitations. These aspects are crucial to understand for responsible usage and to anticipate the broader impact of the technology. This section addresses the ethical implications, risks, and inherent limitations associated with using BLOOM.
The development and release of BLOOM have significant implications in the real world, both in terms of its impact and the controversies it raises. This section discusses these aspects, grounded in the insights from the BLOOM research paper.
In the fast-paced world of Artificial Intelligence (AI), the relevance of Large Language Models (LLMs) like BLOOM is a topic of ongoing discussion.
Developed by a vast team of international researchers, BLOOM was a significant leap forward in language processing. However, the AI landscape is continually evolving, with new models emerging and shifting the focus.
Let's examine whether BLOOM still holds its ground in this competitive domain.
This article provided an overview of the BLOOM project, a significant contribution to the evolving field of Large Language Models.
We explored BLOOM's development, highlighting its technical specifications and the collaboration behind its creation. The article also served as a guide for accessing and effectively utilizing BLOOM, emphasizing its appropriate uses and limitations.
Furthermore, it covered the ethical implications and real-world impact of BLOOM AI project, reflecting on its reception and relevance in today’s AI landscape. Whether you're directly involved in AI or an enthusiast, this exploration of BLOOM offers essential perspectives for navigating the complex world of large language models.
For those looking to deepen their engagement with advanced language models, our additional course, Large Language Models (LLMs) Concepts, provides a path to discover the full potential of LLMs with our conceptual course covering LLM applications, training methodologies, ethical considerations, and the latest research.
Start Your AI Journey Today!
Course
Course
Course
blog
Javier Canales Luna
12 min
blog
Nisha Arya Ahmed
12 min
blog
Andrea Valenzuela
15 min
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
code-along
Richie Cotton

