

Courses
Các khái niệm về Generative AI
2 giờ
110.7K
Những lời đồn về bản phát hành tiếp theo của Anthropic đã rộ lên vài ngày qua. Dù nhiều người kỳ vọng Claude Sonnet 5, bản phát hành đầu tiên của năm lại là Claude Opus 4.6.
Với cửa sổ ngữ cảnh 1 triệu token, tư duy thích ứng, nén hội thoại, và loạt điểm chuẩn dẫn đầu, Claude Opus 4.6 là bản nâng cấp so với Opus 4.5. Theo cách Anthropic gọi, họ đã nâng cấp mẫu thông minh nhất của mình. Cùng với mô hình, Anthropic cũng ra mắt các đội tác nhân trong Claude Code và Claude in PowerPoint.
Trong bài viết này, chúng tôi sẽ điểm qua mọi điều mới ở Claude Opus 4.6, xem các tính năng mới, khám phá các điểm chuẩn, và thử sức nó qua một số ví dụ thực hành.
Để tìm hiểu thêm về một số tính năng Claude mới nhất, tôi khuyến nghị xem các hướng dẫn về Claude Cowork và Claude Code, cũng như hướng dẫn OpenClaw của chúng tôi. Để so sánh với các đối thủ khác, hãy đọc các bài hướng dẫn về Muse Spark so với Claude Opus 4.6 và GPT-5.4 so với Claude Opus 4.6.
Claude Opus 4.6 là mô hình ngôn ngữ lớn mới nhất từ Anthropic. Kế thừa từ Opus 4.5, nó đại diện cho một nâng cấp đáng kể cho cấp mô hình "thông minh nhất" của công ty.
Theo bài blog phát hành, Anthropic cho biết họ tập trung hơn vào mã hóa theo hướng tác nhân, suy luận sâu và tự sửa lỗi. Điều này có nghĩa có sự chuyển dịch từ hành động sang hành động duy trì lâu dài.
Opus 4.6 được thiết kế để lập kế hoạch cẩn thận hơn, cải thiện tính mạch lạc trong thời gian dài hơn và tự phát hiện lỗi trong quá trình hoạt động. Tất cả những điều này giúp Claude Opus 4.6 dẫn đầu nhiều bài đánh giá, bao gồm điểm cao nhất trong đánh giá mã hóa Terminal-Bench 2.0 và vượt qua các mô hình tiên phong khác ở Humanity’s Last Exam.
Một điểm khiến tôi ấn tượng là cửa sổ ngữ cảnh được cải thiện ở Claude Opus 4.6. Với 1 triệu token ở bản beta, điều này đưa mô hình mới ngang hàng với Gemini 3, nghĩa là nó có thể xử lý nhiều thông tin hơn mà không đánh mất ngữ cảnh.
Có một số tính năng mới đáng chú ý trong Claude Opus 4.6, nhiều tính năng tập trung vào quy trình làm việc theo hướng tác nhân. Hãy xem một số điểm chính:
Đội tác nhân là cải tiến so với "tác nhân phụ" mà chúng ta thấy ở các phiên bản Claude trước. Đội tác nhân cho phép bạn khởi tạo nhiều phiên bản Claude hoàn toàn độc lập có thể làm việc song song. Một phiên là tác nhân "trưởng nhóm" điều phối, trong khi các "đồng đội" xử lý việc thực thi thực tế.
Điều thú vị là mỗi thành viên đều có cửa sổ ngữ cảnh riêng, cho phép thực thi kỹ lưỡng hơn. Mỗi đồng đội cũng có thể giao tiếp trực tiếp với những người khác trong nhóm.
Tất nhiên, tính năng này đi kèm một nhược điểm tiềm ẩn - chi phí. Vì mỗi tác nhân có cửa sổ ngữ cảnh riêng, bạn có thể nhanh chóng tiêu tốn nhiều token. Do đó, Anthropic khuyến nghị dùng chúng cho các kịch bản có mức độ phức tạp cao hơn.
Một tính năng hay của Claude Opus 4.6 là nén ngữ cảnh. Nâng cấp trải nghiệm này giúp tránh rắc rối khi bạn chạy các quy trình dài vượt ngưỡng cửa sổ ngữ cảnh. Thông thường, bạn sẽ chạm tới "bức tường ngữ cảnh" nơi hiệu năng bắt đầu suy giảm.
Với nén hội thoại, Claude Opus 4.6 có thể tự động phát hiện khi cuộc trò chuyện chạm ngưỡng token và tóm tắt cuộc trò chuyện hiện tại thành một khối súc tích (một khối nén).
Tính năng này sẽ giúp giữ lại những yếu tố cốt lõi trong tương tác của bạn đồng thời giải phóng dung lượng để tiếp tục công việc. Nếu bạn dự định dùng các tác nhân theo nhiệm vụ cần chạy lâu, điều này có thể giúp chúng đi đúng hướng với bộ nhớ được cải thiện đáng kể.
Có hai tính năng ở Claude Opus 4.6 quyết định liệu nó có cần sử dụng tư duy mở rộng và nó sẽ cố gắng đến mức nào với lối tư duy đó.
Tư duy thích ứng cho phép mô hình xác định mức độ phức tạp của lời nhắc của bạn. Dựa trên sự đơn giản hay phức tạp, nó sẽ quyết định có dùng tư duy mở rộng hay không. Thay vì có thiết lập thủ công cho số token dùng cho việc này, Claude sẽ điều chỉnh ngân sách dựa trên độ phức tạp của từng yêu cầu.
Tham số effort (mức nỗ lực) cho phép bạn đặt mức độ sẵn sàng hay thận trọng của Claude trong việc tiêu tốn token. Về cơ bản, nó giúp bạn cân bằng giữa hiệu quả token và độ kỹ lưỡng của câu trả lời.
Khi dùng Claude Opus 4.6 qua API, bạn có thể đặt các tham số này thủ công. Ví dụ:
Gần đây chúng tôi đã đề cập đến Claude in Excel, cho thấy tiện ích bổ sung có thể hỗ trợ bạn nhiều tác vụ trong bảng bên của bảng tính Excel. Bên cạnh việc cải thiện chức năng của công cụ này, Anthropic còn công bố Claude in PowerPoint.
Tích hợp này tôn trọng slide master, phông chữ và bố cục của bạn. Bạn có thể cung cấp cho nó một mẫu công ty và yêu cầu dựng một phần cụ thể, hoặc chọn một slide và yêu cầu chuyển văn bản dày đặc thành sơ đồ gốc có thể chỉnh sửa.
Việc nhấn mạnh tạo ra các đối tượng PowerPoint có thể chỉnh sửa thay vì chỉ là "ảnh của slide" khiến đây là công cụ năng suất thực sự chứ không chỉ là bộ tạo ý tưởng.
Claude in PowerPoint hiện đang ở giai đoạn xem trước nghiên cứu cho người dùng Max và Enterprise.
Nhiều tuyên bố nổi bật của Opus 4.6 xoay quanh các tác vụ mã hóa khó hơn và suy luận sâu hơn. Những kỹ năng này dựa trên một nền tảng nhất định: khả năng nắm giữ nhiều ràng buộc cùng lúc, suy luận qua nhiều bước và phát hiện sai sót.
Với điều này trong đầu, chúng tôi đã thử Opus 4.6 qua một loạt thử thách logic nhiều bước, toán học và mã hóa. Chúng tôi muốn xem liệu có thể phơi bày một số điểm yếu phổ biến của LLM hay không – những thứ như lỗi tính toán dây chuyền, suy luận không gian (luôn là vấn đề), và các câu hỏi có ràng buộc. Chúng tôi cũng đưa vào một bài gỡ lỗi cụ thể vì thông báo của Anthropic khoe rằng Opus 4.6 rất giỏi phân tích nguyên nhân gốc rễ và các vấn đề gỡ lỗi khác.
Bài kiểm tra đầu tiên kết hợp số nguyên tố, hệ thập lục phân và đếm:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Nghe có vẻ phức tạp, nhưng bài này khá dễ để chúng ta xác minh. Đáp án đúng là 2 vì số nguyên tố thứ 6 là 13; 13 bình phương là 169, chuyển sang hex là "A9". Chuỗi này có 1 chữ cái × 1 chữ số, nhân lại được 1, và số nguyên tố thứ nhất là 2.
Điều đáng lo là mô hình có thể vấp ở bước chuyển đổi hex, dẫn đến đáp án cuối sai hoàn toàn. Như bạn thấy, Opus 4.6 xử lý tốt:

Bài thứ hai kiểm tra khả năng suy luận không gian và xử lý số âm:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Bài này cần nhiều công để chúng tôi xác minh. Đáp án đúng là -6.065. Chúng tôi biết vậy vì ma trận sau khi xoay là [[1, 4], [5, 2]]; sau đó dùng Python tính định thức được -18, lập phương là -5.832; cuối cùng trừ 233 được -6.065.
Chúng tôi chọn bài này vì biết từ kinh nghiệm rằng các mô hình thường hoán đổi phần tử ma trận sai hoặc làm mất dấu âm giữa chừng. Một lần nữa, Opus 4.6 không gặp khó:

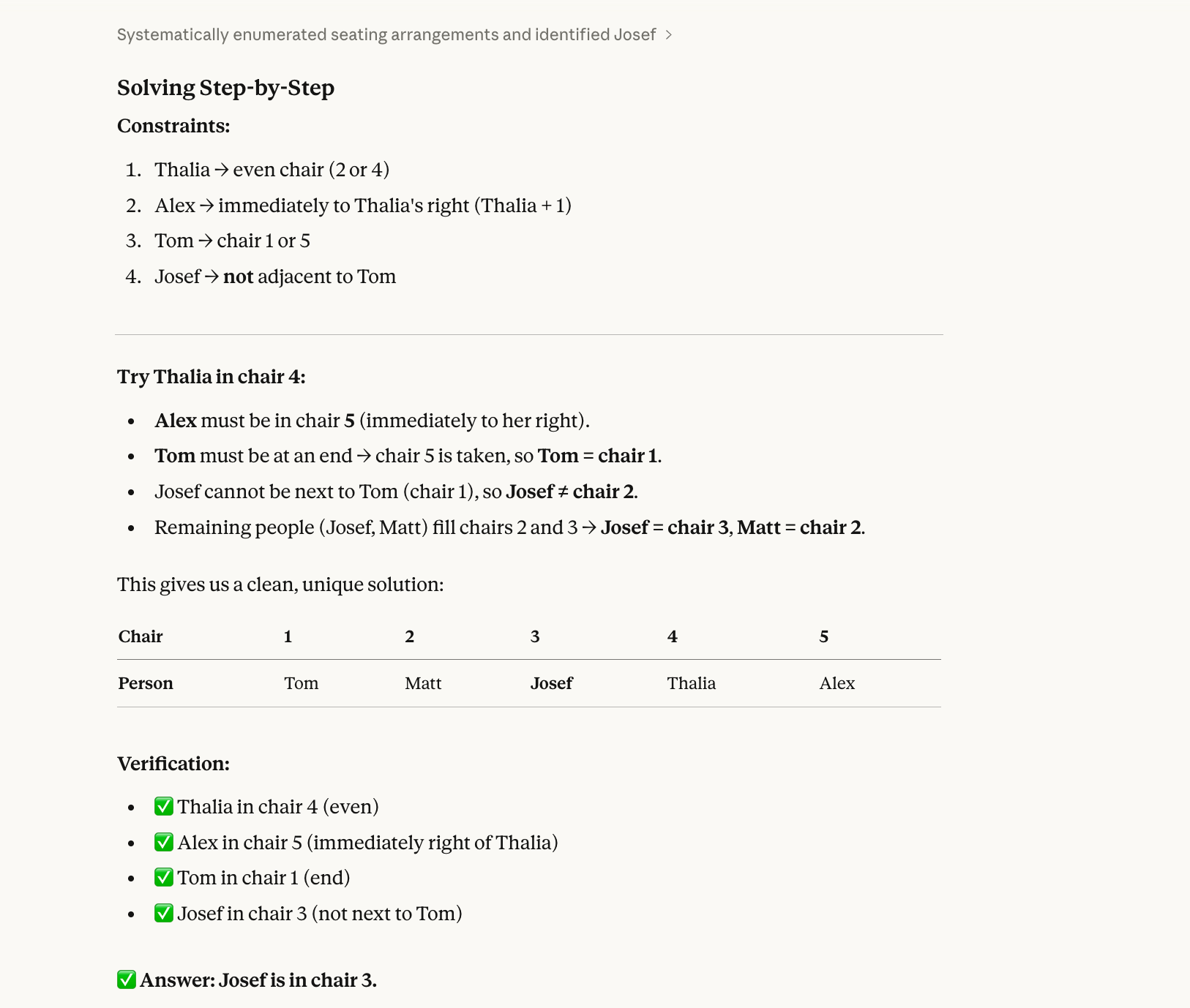
Ở bài thứ ba, chúng tôi thử một bài toán thỏa mãn ràng buộc cần quay lui:
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?Đáp án đúng là Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Bạn có thể giải ra trên giấy với chút công sức.
Lý do cơ bản khiến mô hình có thể sai ở kiểu câu này là vì các mô hình có lịch sử giải tuần tự, không toàn cục. Chúng đọc "Thalia ở ghế chẵn" rồi chọn một ghế (ví dụ ghế 2) mà không kiểm tra xem lựa chọn đó có phù hợp với tất cả ràng buộc khác không. Sau đó chúng cam kết, điền thêm ghế, và cuối cùng gặp xung đột, nhưng lúc đó đã tự đẩy mình vào góc mà không quay lại thử Thalia ở ghế 4.
Opus 4.6 cũng giải đúng bài này:
Bài thứ tư đánh giá trí hình dung không gian và trực giác vật lý:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Để xác minh, tôi thực sự tháo đồng hồ đeo tay và xoay nó.
Đáp án đúng là 2:30 chiều. Lúc 3:15, kim phút chỉ vào "3". Khi tôi xoay để số 12 hướng về cửa sổ bên trái, số "3" chuyển tới vị trí của "12". Sau đó tôi cộng 0 vào 3:15, trừ 45 phút, và được 2:30 chiều.
Khi thiết kế bài, chúng tôi kỳ vọng mô hình có thể nhầm giữa việc xoay mặt đồng hồ với di chuyển kim. Chúng tôi cũng từng nghe rằng các mô hình hay thấy việc cộng 0 là đáng ngờ nên sẽ cố ép ra số khác.
Tuy vậy, Opus 4.6 đã giải được; nó cũng cho ra đáp án đúng:

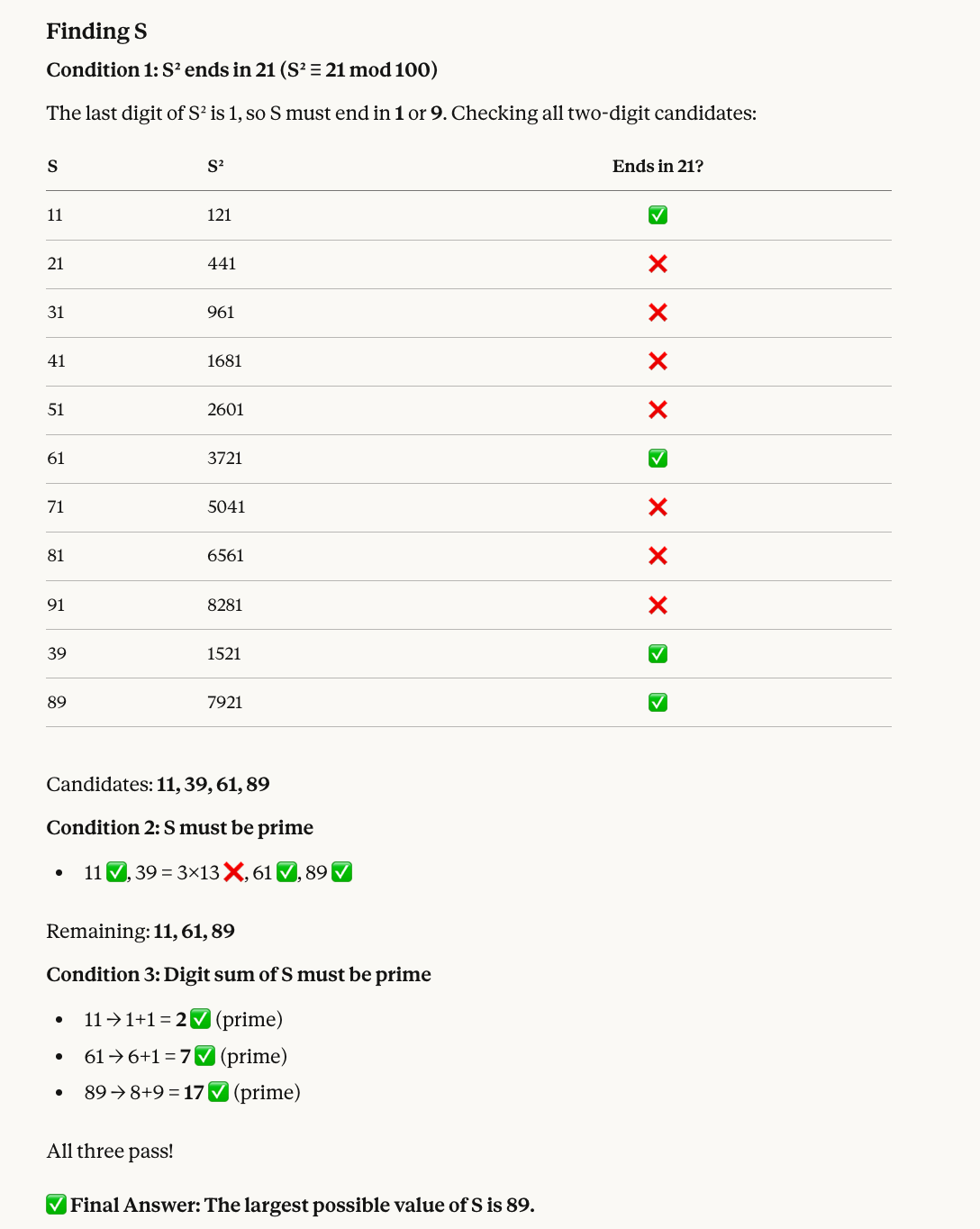
Bài thứ năm kết hợp số học modulo với lọc số nguyên tố:
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?Lý do đáp án đúng là 89: Các số có bình phương kết thúc bằng 21 gồm 11, 39, 61 và 89. Trong đó, 39 không phải số nguyên tố, nên còn 11, 61 và 89. Cả ba đều có tổng chữ số là số nguyên tố (2, 7 và 17), vì vậy số lớn nhất là 89.
Opus 4.6 lại cho đáp án đúng, và lần này còn kèm một hình minh họa hữu ích:
Bài tiếp theo xâu chuỗi giai thừa, xử lý chuỗi và số nguyên tố:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.Cách chúng tôi xác minh 425 là đáp án đúng: 5! = 120; trừ 1 được 119; đảo chữ số thành 911. Sau đó, dùng một ít mã R (bên dưới), chúng tôi thấy có 152 số nguyên tố giữa 10 và 911, và tổng của chúng là 64.598. Cuối cùng, tiếp tục dùng R, ta chia và làm tròn: 64.598 ÷ 152 ≈ 425.

Đây là script R chúng tôi dùng:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")Bài tiếp theo nhắm vào một tuyên bố lớn của Opus 4.6: chẩn đoán lỗi trong mã. Chúng tôi biết các mô hình thường lần theo mã đúng từng dòng nhưng không kết nối được việc lần theo với lỗi gốc.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Đây là đáp án và vì sao nó là một bài kiểm tra tốt: hàm luôn chia cho window (3), ngay cả khi đoạn chunk có ít hơn 3 phần tử ở đầu danh sách. Kết quả lỗi là [3.33, 10.0, 20.0, 30.0, 40.0], nhưng hai giá trị đầu phải là 10.0 và 15.0 vì các đoạn đó chỉ có 1 và 2 phần tử. Cách sửa là đổi / window thành / len(chunk).
Chúng tôi thích bài này vì các mô hình thường lần theo vòng lặp hoàn hảo, nhưng sau đó báo "kết quả trông đúng" — chúng thấy phép toán diễn ra từng bước và không đánh dấu rằng chia một phần tử cho 3 là sai. Bài này đòi hỏi mô hình giữ đồng thời ý định (trung bình trượt nên làm gì) cùng với thực thi (mã thực sự làm gì) và phát hiện khoảng cách giữa hai thứ đó.

Bài cuối không có toán, chỉ là suy luận phản thực.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Dĩ nhiên, không có một đáp án đúng duy nhất, và cũng khó để hình dung. Nhưng chúng tôi kỳ vọng mô hình tối thiểu phải suy luận về các hệ quả, và chúng tôi cho rằng câu trả lời của Claude Opus 4.6 là đủ hợp lý.
Tóm lại, Opus 4.6 đạt điểm tuyệt đối, dù như bạn thấy, chúng tôi có đưa vào một câu có phần chủ quan, nên bạn có thể là người chấm cuối cùng.

Opus 4.6 là quán quân không tranh cãi ở ít nhất bốn bài đánh giá quan trọng:
Terminal-Bench 2.0 là bài đánh giá mã hóa theo hướng tác nhân; Humanity’s Last Exam là bài kiểm tra suy luận phức tạp; GDPval-AA kiểm tra hiệu suất công việc tri thức; BrowseComp đo khả năng của mô hình trong việc tìm thông tin khó tìm trên mạng.
Các mô hình Claude nổi tiếng xứng đáng là một trong những "lập trình viên" tốt nhất. Vậy hãy bắt đầu bằng việc xem kết quả bài Terminal-Bench 2.0.
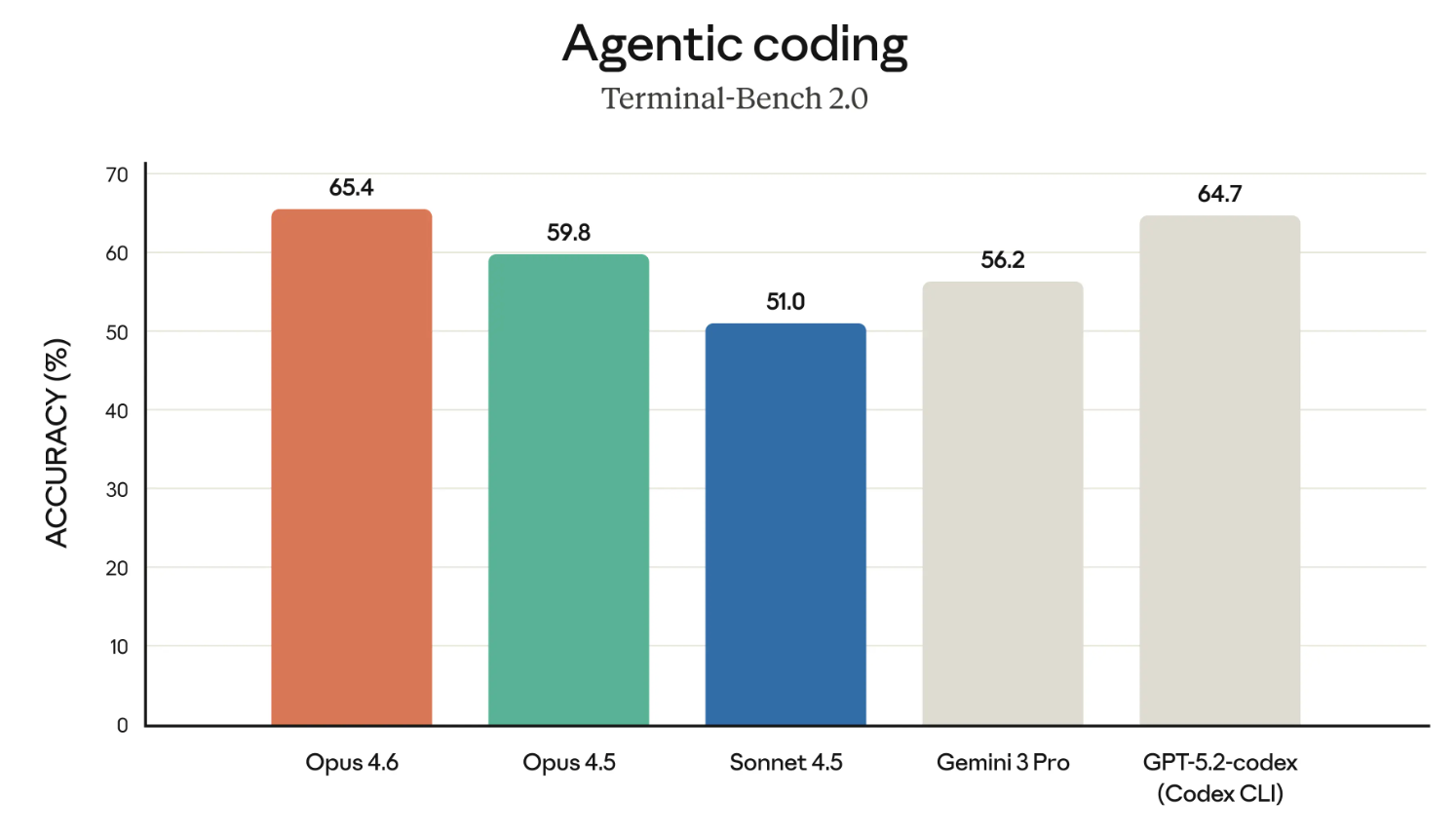
Nếu biểu đồ trên có vẻ làm nổi bật Opus 4.6 so với GPT-5.2-codex – vâng, điều đó hẳn là có chủ ý. Gần đây Anthropic trực tiếp thách thức OpenAI ở nhiều lĩnh vực và đang đưa ra lập luận cho việc sử dụng trong doanh nghiệp.
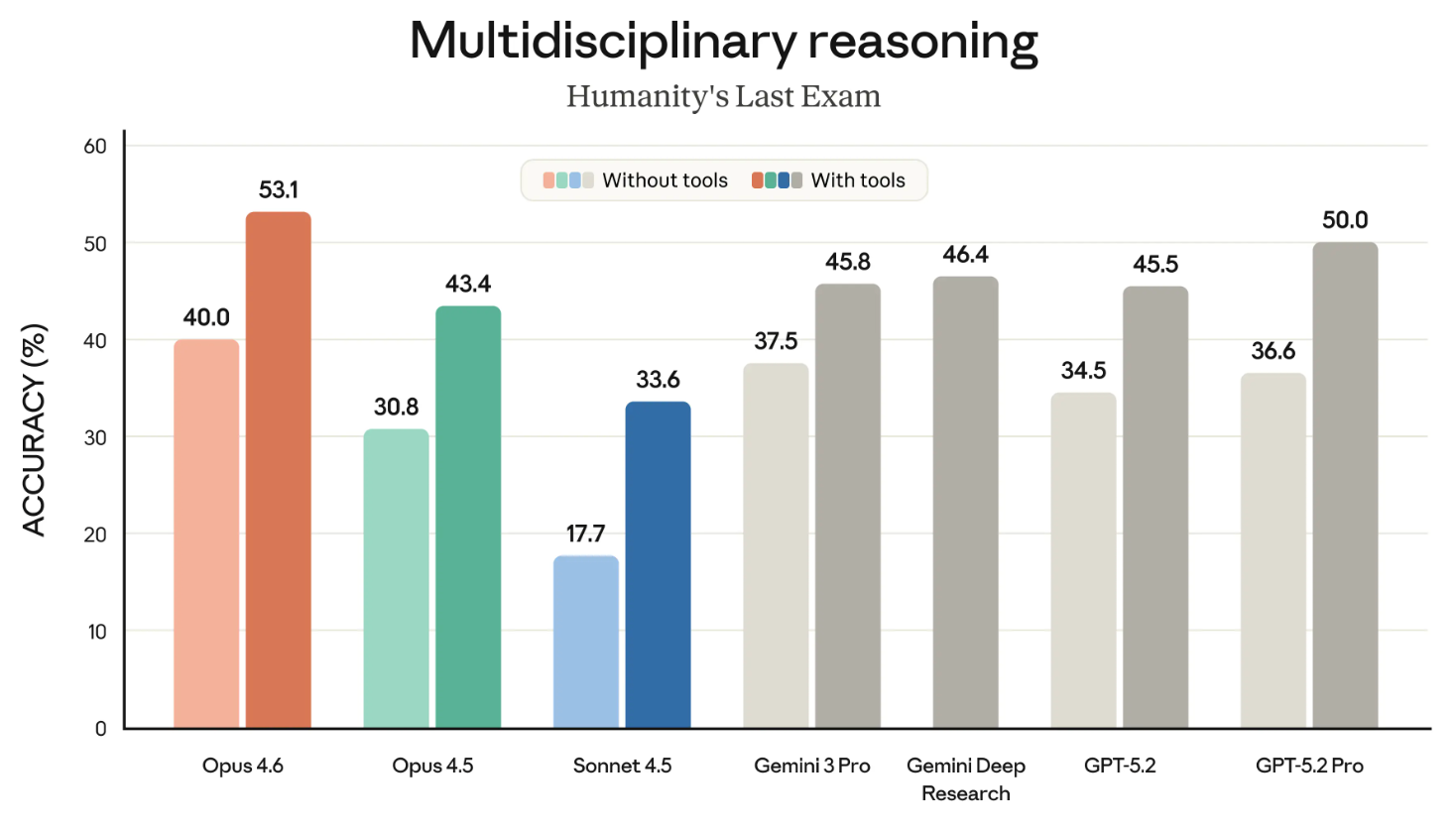
Humanity’s Last Exam là một trong những bài đánh giá nổi tiếng nhất và là bài mà tất cả chúng ta đều theo dõi sát sao. Nó đo khả năng suy luận tổng quát của mô hình.
Biểu đồ sau cho thấy mức độ thành công của các mô hình tiên phong khác nhau trên HLE cả khi có và không có công cụ. ("Có công cụ" nghĩa là mô hình được phép dùng các khả năng bên ngoài như tìm kiếm web và thực thi mã.)
Biểu đồ này có lẽ sẽ tốt hơn nếu tách làm hai. Bỏ qua điểm nhỏ đó, kết luận rất rõ: Opus 4.6 dẫn đầu ở cả hạng mục "có công cụ" và "không công cụ".
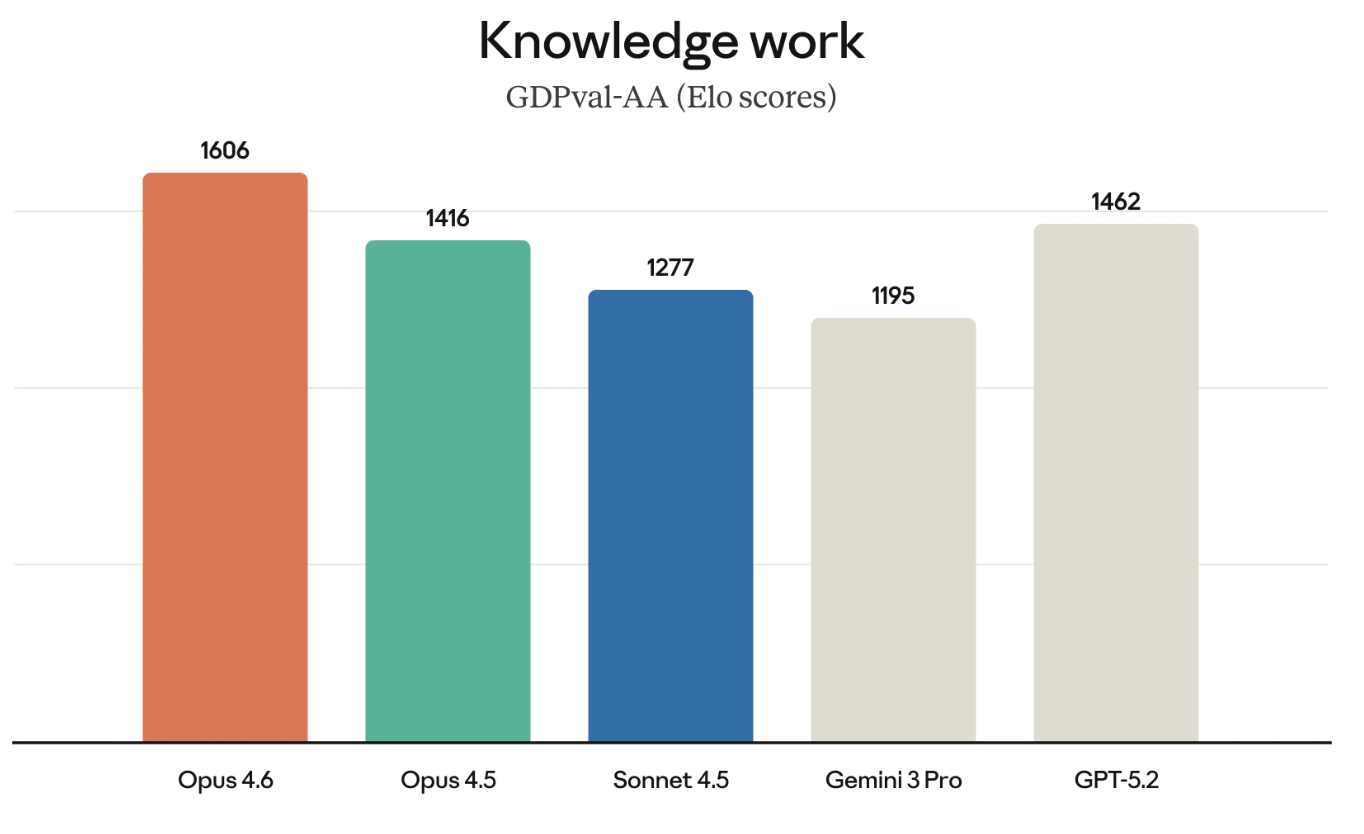
GDPval-AA (đúng như tên gọi) là bài kiểm tra những công việc tri thức được coi là có giá trị kinh tế. Hãy nghĩ tới những việc như chạy mô hình tài chính hoặc nghiên cứu.
GDPval-AA và các bài đánh giá tương tự ngày càng trở nên quan trọng vì chúng thực sự đo lường các loại công việc mà doanh nghiệp sẵn sàng chi trả. Thành công của Opus 4.6 ở GDPval-AA cũng là một thách thức trực diện khác với dòng mô hình GPT, vì OpenAI và Anthropic đang cạnh tranh cho rất nhiều khách hàng giống nhau.
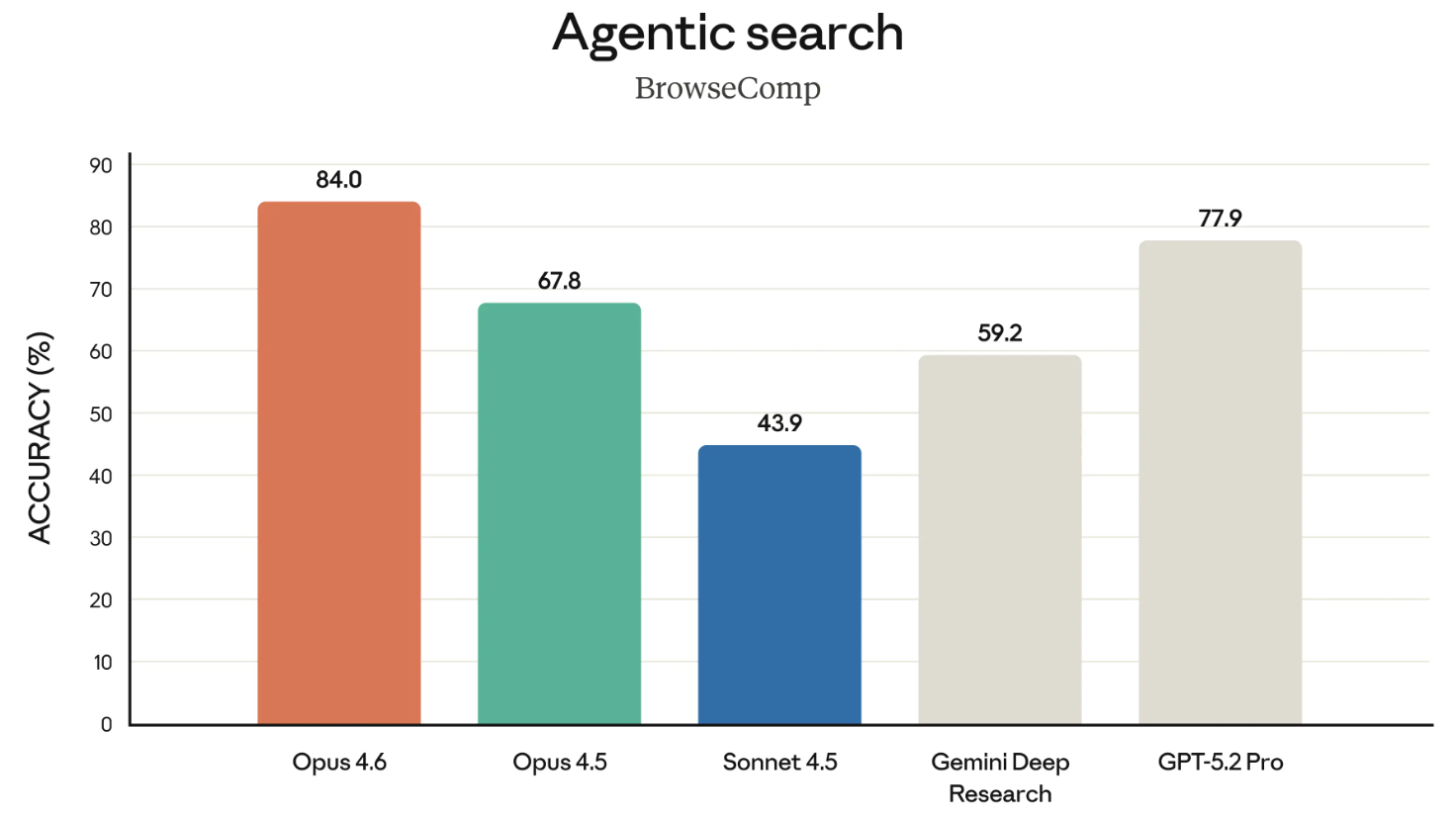
BrowseComp là bài đánh giá cuối cùng đáng nhắc đến trong lần phát hành này. Nó đo khả năng mô hình truy tìm thông tin khó tìm trên mạng. Một chút lịch sử: OpenAI thực ra đã phát triển BrowseComp để thể hiện khả năng tìm kiếm của các mô hình của họ.
Trong một động thái có phần thẳng thừng, ở lần phát hành này, Anthropic trực tiếp liên kết tới thông báo tháng 4/2025 của OpenAI về việc phát triển BrowseComp khi nhấn mạnh rằng Opus 4.6 đứng đầu bảng ở bài này. Có hơi "cà khịa" khi trích dẫn lại chính bài đánh giá của OpenAI như vậy.
Opus 4.6 hiện khả dụng rộng rãi tại thời điểm bài viết. Tuy nhiên, bạn không thể truy cập Opus 4.6 nếu không nâng cấp lên tài khoản pro, vốn đi kèm các lợi ích khác, như cho phép bạn dùng Claude in Excel.
Nếu bạn là nhà phát triển, bạn nên dùng claude-opus-4-6 trong Claude API. Mức giá không đổi: vẫn là $5/$25 mỗi triệu token. Nếu bạn bối rối về hai con số, hãy biết rằng số thứ nhất là số bạn trả để gửi token tới mô hình (ý tôi là lời nhắc của bạn), và số thứ hai là số bạn trả cho token mô hình tạo ra (câu trả lời).
Claude Opus 4.6 đứng đầu bảng ở các bài đánh giá quan trọng như GPDVal-AA, bài đo mức độ mô hình thực hiện tốt các tác vụ quan trọng về kinh tế, cũng là điều các khách hàng doanh nghiệp lớn quan tâm. OpenAI có thể bị lung lay bởi diễn biến này vì chỉ vài giờ trước khi Opus 4.6 ra mắt, họ đã công bố OpenAI Frontier, một nền tảng doanh nghiệp mới để xây dựng, triển khai và quản lý các tác nhân AI trong sản xuất.
Nói cách khác, thay vì cạnh tranh trên bảng điểm mô hình, Frontier cho thấy OpenAI tập trung vào hạ tầng quanh bộ mô hình của mình, cụ thể là cấp cho tác nhân AI ngữ cảnh doanh nghiệp chung, quyền hạn, và khả năng nhận cũng như học từ phản hồi theo thời gian. Khi mất lợi thế ở các điểm chuẩn, OpenAI đang phát tín hiệu rằng nền tảng của họ được định vị tốt hơn để biến tác nhân trở nên hữu ích thực sự trong công ty.
Đó là một chuyển hướng chiến lược hay lời thừa nhận ngầm rằng họ đang thua trong cuộc đua mô hình, điều đó là do bạn quyết định.
Tổng thể mà nói, chúng tôi ấn tượng với những gì Anthropic mang lại với Claude Opus 4.6, và chúng tôi mong được trực tiếp trải nghiệm đội tác nhân. Nếu bạn muốn tìm hiểu thêm về gia đình Claude, nhớ xem khóa Introduction to Claude Models.
Học AI với DataCamp
Courses
Courses
Courses