
#1 Organizations accelerate culture transformation programs
Data culture is the collective behaviors and beliefs of people who value, practice and encourage the use of data to improve decision-making. It sets the foundation and mindset for companies to effectively capture value from their ever-growing datasets.
Unfortunately, the lack of data culture is a major roadblock in an organization’s roadmap to becoming data-driven.
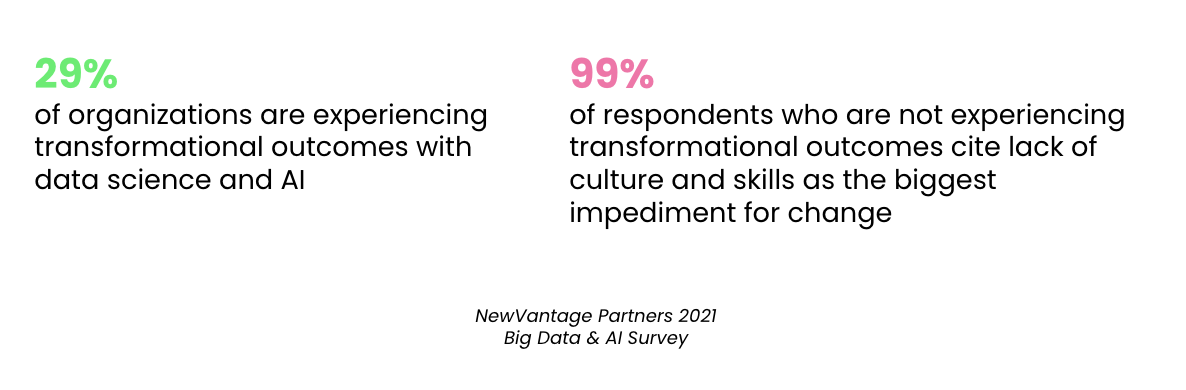
In 2022, we anticipate chief data officers (CDO) to focus on the key building blocks of data culture, which include proper data governance, data literacy programs, and nurturing a data-driven mindset. These are catalysts for organization-wide data-driven decision-making processes.
#2 Organizations will scale data governance
The growing demand for self-serve analytics fueled the need for compliant, actionable, and high-quality data. Yet, the challenge of measuring and maintaining data quality scales in tandem with the size and complexity of the datasets. As such, companies are adapting their data governance strategies.
One such strategy is to adopt data observability in data pipelines. Simply put, data observability aims to identify, troubleshoot, and resolve data issues in near real-time.
In 2022 and beyond, more companies will scale their data governance programs and adopt new and modern tools to monitor and detect data quality issues.
#3: NLP ushers in a new generation of low-code data tools
NLP has grown tremendously in the past few years, thanks to the arms race for ever-larger large language models (LLM) like T5, GPT-3, and Megatron-Turing NLG.
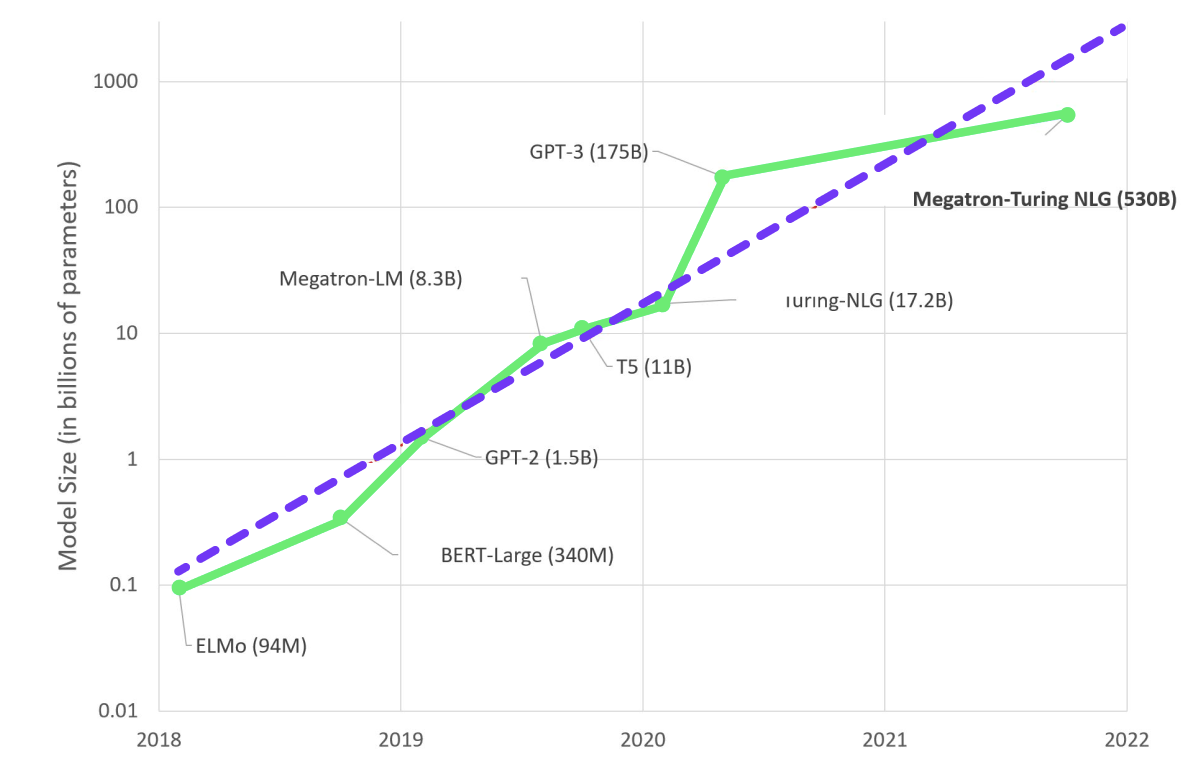 Large language models get larger over the years (Source)
Large language models get larger over the years (Source)LLMs are pushing the limits of what NLP can do. The most recent models surprised the community with their ability to generate various types of texts (like computer code and guitar tabs) without any explicit training.
Such NLP models have the potential to usher in the age of low-code and no-code tools. Today, Microsoft’s Power App allows non-technical users to build apps with natural speech. Such tools will continue to lower the barriers to coding and facilitate the rise of citizen developers and citizen data scientists within organizations.
#4 L&D becomes a fabric of company culture
Driven by the C-suite’s concern over their organization’s lack of key skills, companies will continue to invest heavily in learning and development (L&D) programs in 2022. The benefits of such L&D programs are obvious–the World Economic Forum predicted that 38% of GDP can be gained from upskilling by 2030.
As the workforce continues to cope with the pandemic, we expect companies to allocate their L&D budgets on virtual learning ecosystems that facilitate effective learning and provide communities of practice. Companies looking to improve their employees’ data literacy at scale can leverage existing L&D programs as internal data science skill academies.
Data Trend #5: MLOps will continue to mature within organizations
MLOps is a set of practices that combine machine learning, data engineering, and DevOps. It includes standardized processes that automate the machine learning workflow.
Companies can only extract value from machine learning at scale with production-level AI systems. This explains why the demand for MLOps is expected to grow immensely. In fact, the industry is estimated to be valued at $126.1 billion by 2025.
In the upcoming year, MLOps tools like KubeFlow and MLFlow will continue to mature. It is only a matter of time before they become a staple for all data science teams.
Data Trend #6: Responsible AI becomes more operationalized
Unfortunately, many existing AI systems today are rife with hidden biases. As such, regulators in the EU are planning to hold such AI accountable, and many are expected to follow suit. Companies must ensure that their AI systems remain fair and responsible. Those that fail to do so risk damaging their reputations and are culpable for exacerbating inequality.
That is why companies are increasingly operationalizing principles of Responsible AI to ensure that AI remains fair, interpretable, privacy-preserving, and secure. An example of a framework is PwC’s Responsible AI Toolkit, which addresses the various dimensions of Responsible AI.
Data Trend #7: Rise of the data mesh
Most data architectures today are in the form of data lakes. That might change soon as a new form of data architecture addresses the weakness of data lakes.
A new alternative, coined by Zhamak Dehghani is called the data mesh. A data mesh has distributed “data products”–each handled by a cross-functional team of data engineers and product owners. Adopting a data mesh architecture allows companies to deliver data faster and achieve greater business domain agility.
Soon, as the pains of using data lakes become more acute, companies will begin experimenting with data mesh, as did Zalando and Intuit.
Data Trend #8: New generation of tooling will improve the data team’s productivity
Various data science productivity tools emerged in 2021 and will continue to gain popularity in the years to come. These tools reduce the need for manual work and allow data scientists to perform higher-value tasks.
Such productivity tools include AutoML tools (like H2O AutoML and Auto PyTorch), which automates the process of machine learning model selection and even hyperparameter tuning.
A multitude of synthetic data generation tools have also been on the rise. Their ability in creating balanced and labeled datasets at scale is particularly attractive for data-hungry companies.
Large data science teams might also find collaboration tools like Databricks and DataCamp Workspace useful. These tools allow data scientists to collaborate asynchronously in data exploration and ML modeling.
Data Trend #9: The talent crunch and flexible work will broaden and improve the search for data talent
As the Great Resignation rages on, the talent crunch becomes ever more severe. This phenomenon prompts organizations to rethink how they recruit and retain data talent.
In particular, we expect companies to prioritize skills over zip codes in their hiring policies, as evident from the 280% increase in remote job postings on LinkedIn since March 2020. Moreover, as FAANG companies embrace the work-from-home arrangement, we expect other tech companies to follow suit and provide their employees with flexible working options too.
For more on our data trends and predictions for 2022, download the free white paper, or register for our upcoming webinar where we’ll deep-dive into what’s coming in data science in the new year!



