Many organizations today are adopting data science practices as part of their digital transformation initiatives. However, most of them won't reap the rewards of mining their data without a data strategy and a clear-cut blueprint for scaling data science within their organization. McKinsey found that only eight out of 1,000 companies undergoing digital transformation initiatives were able to scale data science beyond a few pilot projects.
Furthermore, while most organizations understand the value of being data-driven, many organizations treat data science as a siloed centralized support function that works on requests from different teams. This is inherently at odds with what data science should be, which is a means to an end to achieve business goals. As Anaconda's CEO Peter Wang puts it, data science is "a mode of inquiry and exploration" to navigate the business world.
Just as a physicist uses math to reason about the natural world, data scientists harness mathematical and computational tools to reason about the business world. —Peter Wang, Anaconda CEO
This siloing effect is exacerbated by the false premise that the end goal of data science should always be artificial intelligence models that automate or streamline major verticals of production within an organization. Companies looking for immediate returns on investment are disappointed to find out that this is often not the case.
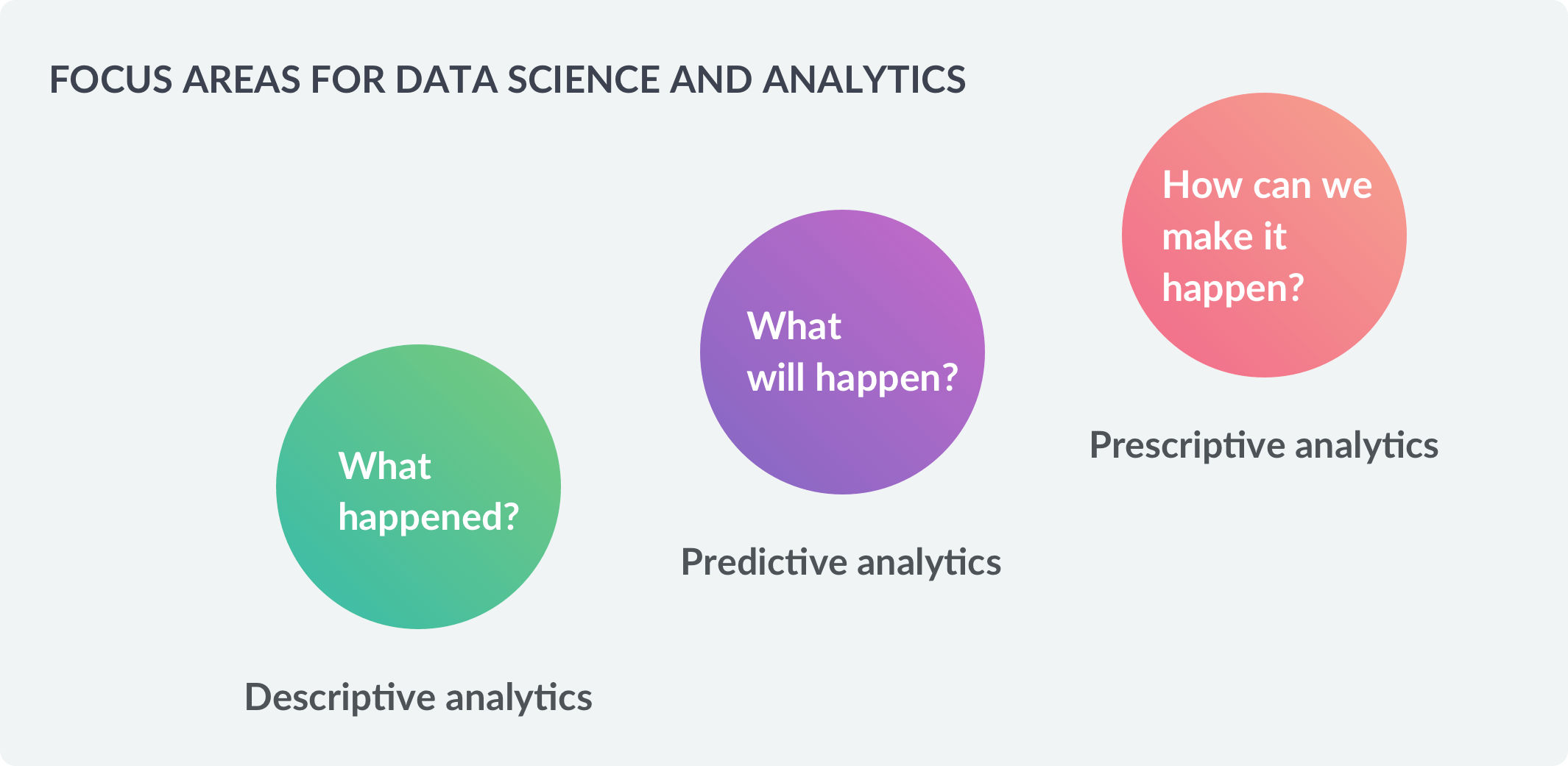
This narrow view of data science attributes its value to relatively difficult-to-achieve predictive analytics (i.e., the ability to predict the future with data) . It also ignores the infrastructure work needed to perform machine learning at scale. However, much of the value of data science comes from implementing relatively simpler descriptive analytics (the ability to describe data and put it in the right hands) and prescriptive analytics (making data-driven decisions).
Completing a successful digital transformation requires building organizational competencies in data science and analytics. This requires building and executing a smart, inclusive, and scalable data strategy.
This is where our IPTOP framework comes in. IPTOP is a framework that establishes five pillars (I nfrastructure, P eople, T ools, O rganization, and P rocesses) to scalably execute your data strategy to complete a successful digital transformation. Join our upcoming webinar series to find out more.
Infrastructure
The goal of any data strategy is to transform raw data into insights and decisions. This requires organizations to collect, record, and store their data safely and efficiently to be accessible by all. But data is often collected in different forms, shapes, and sizes. The various databases, data lakes, data warehouses, scripts, and dashboards that aid in this journey constitute data infrastructure. Building a robust data infrastructure requires understanding best practices.
People
Considering data science as a means to the end goal of better decisions allows organizations to build their teams based on the skills they need. A role-based approach requires identifying, assessing, and mapping performance goals with the skills needed to achieve business objectives, such as predicting churn or visualizing data with dashboards. This results in dedicated learning paths for each role.
A good example is Airbnb's Data University, which is their proprietary training program built to equip every employee with the skills needed to make data-driven decisions. Enabling employees who aren't data scientists by trade to become Citizen Data Scientists capable of making informed decisions has freed up the data science team's time to work on more strategic projects.
Tools
While infrastructure enables organizations to deliver insights from data, tools facilitate and incentivize the adoption of a common data language across the organization. Using tools for data access, analysis, visualizations, and dashboards allows organizations to become more efficient, driving down the time to achieve insights. These tools can range from open source programming languages like Python, R, and SQL to point-and-click-based tools like Power BI, Tableau, and Excel.
Building organization-specific frameworks that streamline access to data on top of these tools substantially reduces the barrier to entry to scaling data science. At DataCamp, we have proprietary Python and R packages that abstract away connecting to data lakes, querying data, and aggregating it using simple commands. Anyone can answer questions like "What was the rating of course X over the past Y weeks?" with one or two lines of code. Similarly, Airbnb has an R package that facilitates querying and visualizing data according to their desired aesthetics, which eliminates the guesswork to ensuring consistent data analysis and visualizations across the organization.
Organization
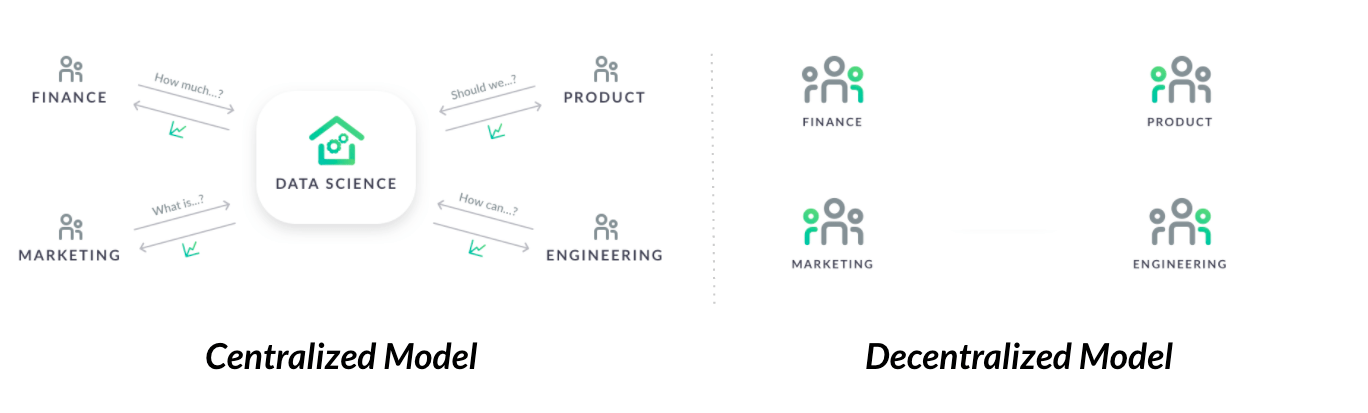
An important dimension of a data strategy is how data professionals are organized. Given that reporting structures and agendas drive work in most firms, organizational structure must set up your company for sustainable success. There are trade-offs between a centralized model where data scientists are part of one data science team and a decentralized model where data scientists are embedded in different departments.
In the centralized model, a central data science team prioritizes and works on information requests from other departments. In this model, questions come in and answers are expected to come out. This allows the data science team to become a center of excellence, where data scientists collaborate and share knowledge under one strategic direction. However, this siloes data science teams and their tools, which makes coordination and communication with other departments complicated for data scientists.
In the decentralized model, data scientists are embedded in different departments within the organization. This gives data science a seat at the table to influence their department's strategic direction, as data scientists acquire the domain knowledge needed to succeed. However, since they're dispersed and managed by business team managers, a drawback is that it comes at the expense of data scientists' growth, learning and development, and ability to collaborate.
These two models should be looked at as two opposing ends of a spectrum. There are many hybrid models that combine elements of the centralized and decentralized models, with different ways to group and bundle departments to maximize the value of data science at scale.
Processes
Finally, building a scalable data strategy requires alignment on conventions, best practices, and processes. Fostering alignment is essential to facilitating collaboration and avoiding a siloed organization. This allows all teams to seamlessly work together and communicate under a common data language.
An easy way to start building alignment on processes is to create a predefined project structure and template, where different tasks and subtasks for an analytics project are mapped out with their requirements ahead of time. Microsoft has adopted The Team Data Science Process, which allows any stakeholder to clearly understand the project requirements, utilize templates for data analysis and computing power access, and identify who owns different stages of the process.
Depending on your organization and industry, predefined project templates may be subject to specific regulatory requirements and may require complex processes. You can utilize open source tools to set project structure templates for increased alignment between teams and data professionals.
Take the data maturity assessment to better understand your team's approach to data.
