Course
Understanding Machine Learning
2 hr
294.5K
Welcome to the final entry of our month-long data demystified series. As part of Data Literacy Month, this series clarified key concepts from the world of data and attempted to answer the questions you may be too afraid to ask. If you want to start at the beginning, read our first entry in the series: What is a Dataset?

In this entry, we will continue on the theme from the previous entry of data demystified, and discuss the potentially harmful effects of AI, how it can perpetuate bias against certain groups of people, and the different types of AI bias everyone should be aware of.
Most AI systems today leverage machine learning. Machine learning, by definition, applies advanced statistical techniques to learn the pattern from past data and make predictions for future events.
The widespread adoption of machine learning has led to a steep increase in cases where it has made a biased prediction. Biased AI algorithms have been a serious concern in the AI community and are a product of the data used for model training. Bias can manifest in many forms—it could be societal or structural and can exist towards a particular gender, color, religion, or nationality.
Consequently, AI algorithms learn bias from the training data as they try to mimic human judgment. Let us revisit a few examples from the past where biased AI predictions have negatively impacted society and humanity as a whole:
Amazon developed a recruiting engine to automate job applicants' resume screening for further interviews. However, the algorithm reflected the bias it learned from the past data and ended up choosing the profiles of male candidates only.
PredPol, or Predictive Policing, built a heatmap of areas of high criminal activity and identified minority-specific locations as hot zones. The algorithm was trained on the biased input data that consisted of several criminal incidents reported from such areas.
Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) software was used to assess the likelihood of a repeat offense by a criminal. However, the algorithm was biased as part of an investigation in 2016. The software labeled black criminals more likely to re-offend than white criminals.
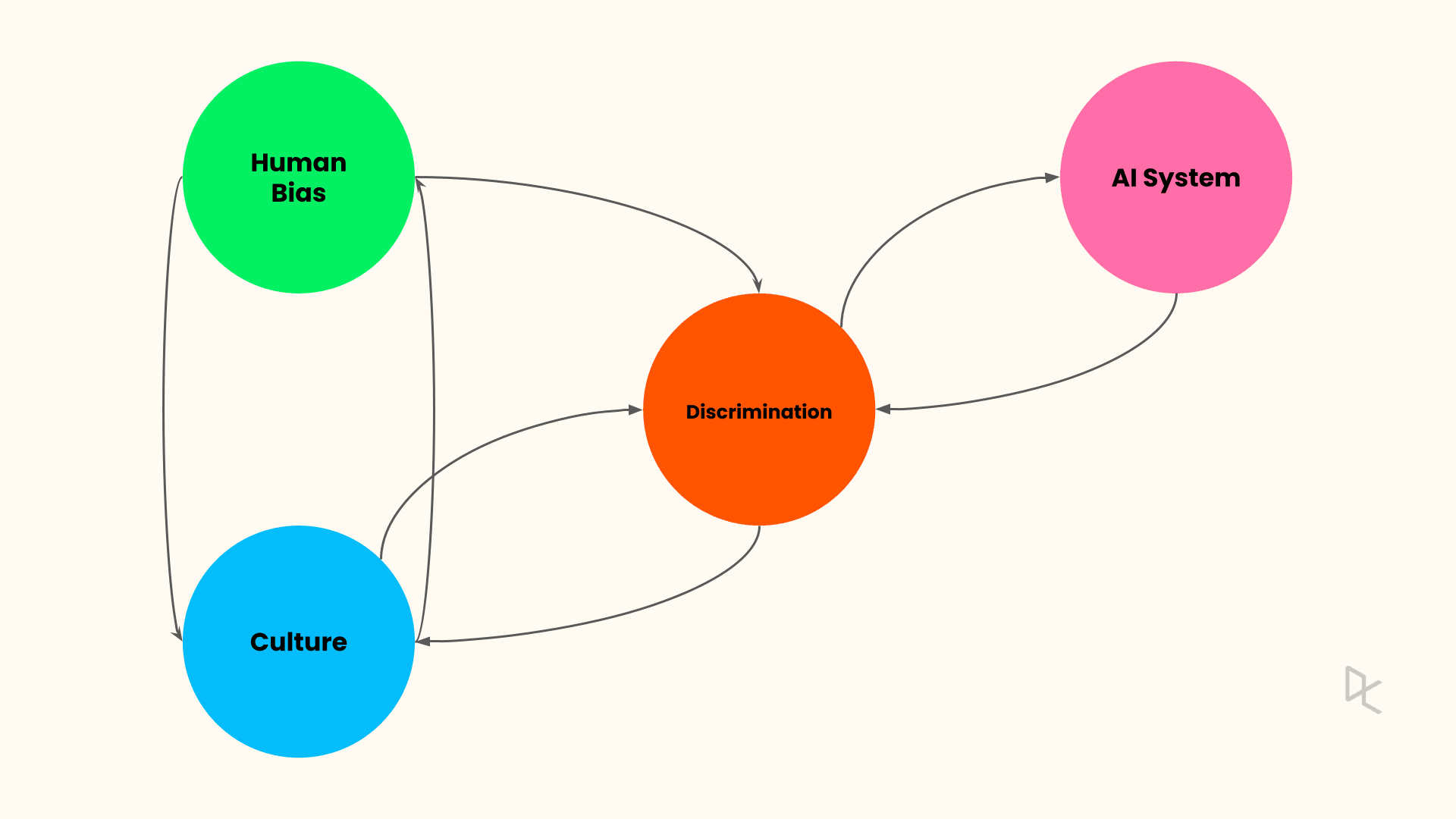
As witnessed from the above examples, machine learning algorithms learn bias from the training data in addition to other data regularities. Unless treated at the origin, bias can manifest in AI/ML pipelines in multiple forms. As AI becomes more widespread in organizations and society, everyone should be aware of AI systems' different types of biases. Below are three of the most common types of bias in AI.
When the training data reflects existing prejudices, stereotypes, and societal assumptions, these biases get embedded in the learned model; such a bias is called a Prejudice bias. For example, when you search for “doctor,” the search result comprises many male doctors' images. In contrast, a similar search for “nurse” results in female nurse images. This speaks volumes about societal gender-based stereotypes.
Sample selection bias occurs when the training data is not representative of the population under study. An example could be here AI systems trained to detect skin cancer. If the original dataset is not representative of the wider population, this system will underperform for members of an underrepresented group in the dataset.
Measurement bias comes from an error in the data collection or measurement process. For example, if images from a camera used in supplying data for an image recognition system are of poor quality, this could lead to biased results against specific populations. Another example can come from human judgment. For example, a medical diagnostic algorithm can be trained to predict the likelihood of sickness based on proxy metrics such as doctor visits instead of actual symptoms.
Throughout this month, we’ve highlighted the importance of data literacy for individuals and organizations. Data literacy allows non-technical stakeholders to become conversational with data and AI experts and understand AI systems' limitations. More importantly, it promotes a two-way conversation between subject matter experts and AI experts that allow for a thoughtful discussion on the potential harm of an AI system.
To equip yourself with the necessary knowledge to have these conversations, take our Understanding Machine Learning course and start your data literacy journey. For more data literacy and data demystified content, check out the following resources:
Data Literacy Courses
Course
Course
Course
blog
Richie Cotton
8 min
blog
Richie Cotton
5 min
blog
Richie Cotton
5 min
blog
Nisha Arya Ahmed
12 min
blog
Austin Chia
podcast




