
Track
OpenAI Fundamentals
15 hr
When we, as users, interact with ChatGPT, we simply type a prompt into the web interface and press enter. Typically, we start receiving a response within a few seconds. However, beneath this seamless interaction lies a complex and orderly series of steps that enable ChatGPT to deliver such an experience.
The automatic execution of this series of steps, known as Large Language Model Operations (LLMOps), guarantees that the prompt not only reaches the model but is also processed efficiently, accurately, and reliably. This ensures the delivery of a well-crafted response within a reasonable timeframe.
In this article, we will delve into the LLMOps paradigm by tracing the journey of a prompt through a Large Language Model (LLM) service, like ChatGPT. We will examine the crucial stages, including prompt preprocessing, model selection, response generation, and the often-overlooked but vital aspects such as load balancing, monitoring, and Continuous Integration.
LLMOps are indeed an evolution of the well-known Machine Learning Operations (MLOps), tailored to meet the concrete challenges presented by LLMs. While MLOps is centered on the lifecycle management of general Machine Learning models, LLMOps incorporates aspects uniquely related to these types of models.
It is crucial to understand that whenever we interact with a model from OpenAI or Google, whether through a web interface or API calls from our code, LLMOps are transparent to us. In this scenario, we say these models are provided as-a-service.
On the other hand, if our goal is to provide our model for a specific use case without reliance on external providers, like an assistant for a company’s employees, then the responsibility of LLMOps falls on us.
Regardless of the capabilities of our new model, its success as a service will highly depend on the presence of a robust and reliable LLMOps infrastructure.If you are interested in knowing more about MLOps, the tutorial MLOps Fundamentals is for you!
Early LLMs such as GPT-2 were introduced in 2018. However, they have become popular more recently, primarily due to the significant advancements in the capabilities of the newer versions of those models, from GPT3 and beyond.
Multiple applications leveraging LLMs have emerged due to their impressive model capabilities. Examples include customer service chatbots, language translation services, and writing and coding assistants, among others.
Developing production-ready applications powered by LLMs presents a unique set of challenges, different from those encountered in traditional ML models. To address these challenges, novel tools and best practices for managing the LLM application lifecycle were developed, leading to the concept “LLMOps.”
LLMOps are essential for efficiently managing these complex models when deployed as-a-service for multiple reasons:
1. LLMs are not just big in terms of the amount of data they handle but also in their number of parameters. LLMOps ensure that the infrastructure can support these models in terms of storage and bandwidth.
2. Receiving an accurate response in the minimum time is crucial for users. LLMOps ensure that responses are delivered in a reasonable time, maintaining the fluidity of human-like interactions.
3. Continuous monitoring under LLMOps is not just about tracking the operational aspects or glitches in the infrastructure. It also entails careful tracking of the model’s behavior to understand its decision-making processes and to further improve the model in future iterations.
4. Running LLMs can be expensive due to the resources they need. LLMOps introduces cost-effective strategies to ensure that resources are used optimally without compromising on performance.
To understand LLMOps, it is important to be familiar with the “behind the scenes” of LLMs when offered as-a-service. That is the path that a prompt follows once it is provided to the model until the response is generated. The following schema represents this workflow:
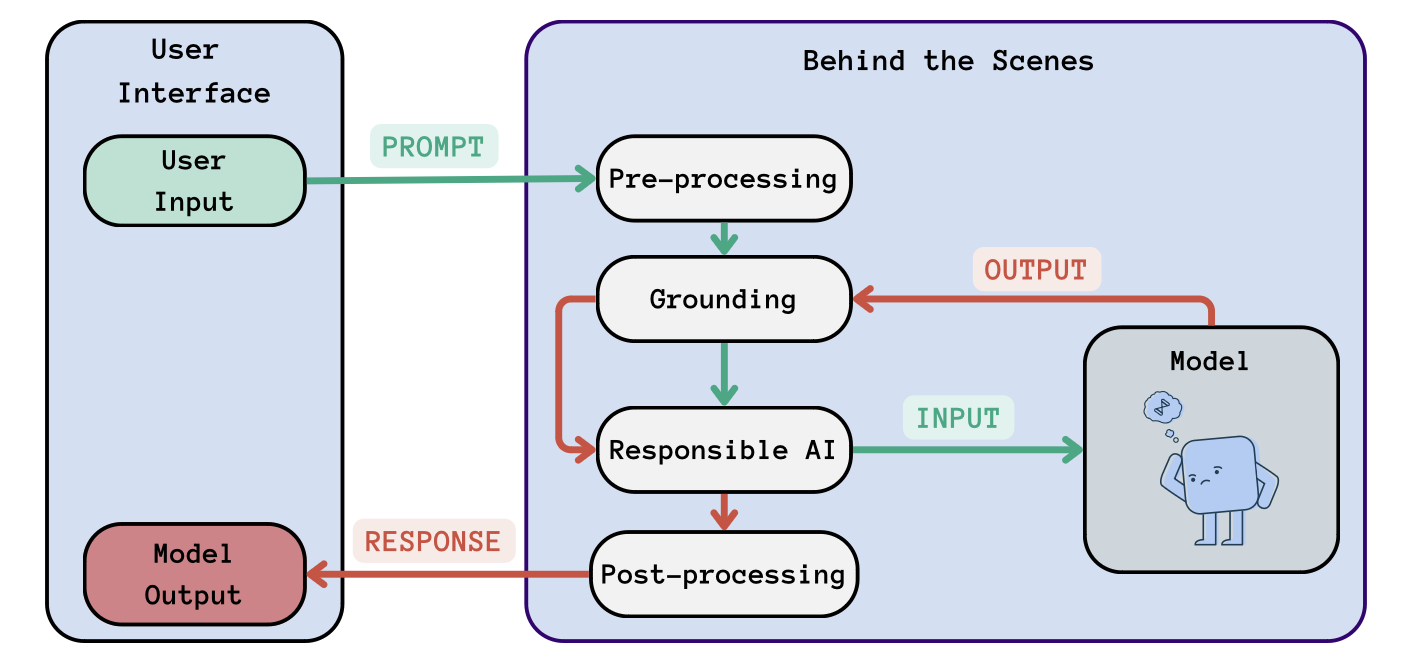
LLMOps workflow: The steps behind the scenes of a generic LLM as-a-service. User input (in green) undergoes some steps before it is input to the model. Similarly, the model output (in red) undergoes several transformations before being displayed to the user.
As we can observe from the schema above, the prompt undergoes several steps before reaching the model. While the number of steps can vary, there are basic ones to ensure, for example, that the input is clearly understood and that the model’s response is contextually relevant. Let’s break down these steps:
This step prepares the user’s prompt so that the model can understand and process it. It includes tokenization, where the prompt is segmented into smaller units called tokens. This step also involves data normalization, which includes removing or transforming noisy data, such as special characters, correcting typos, and standardizing the text.
Finally, during encoding, tokens are converted into a numerical form that the model can understand. This is done by using embeddings, which represent each token as a vector in a high-dimensional space.
This involves contextualizing the prompt based on previous conversation turns or external knowledge sources to ensure that the model’s response is coherent and contextually appropriate. Additionally, entity recognition and linking help the system identify entities (such as names, places, and dates) within the prompt and associate them with the relevant context.
To ensure the usage of LLMs has good purposes, some services implement sanity checks on the user’s prompts. Typically, the prompt is evaluated against safety and compliance guidelines, particularly in scenarios involving sensitive information, inappropriate content, bias, or potential misinformation.
Only after these steps, the prompt is finally forwarded to the model for processing. After the model generates the response, and before displaying it to the user, the response might redo again the steps on Grounding and Responsible AI, as well as an extra post-processing step:
The response generated by the model is in numerical form due to the previously mentioned vector embeddings. Therefore, a decoding process is essential to convert this numerical data back into human-readable text. Following the decoding, a refinement step is needed to polish the response for grammar, style, or readability.
Finally, the response is displayed to the user. The LLMOps infrastructure is responsible for executing these steps transparently to the user.
As of now, we have seen quite some steps that the LLMOps infrastructure needs to execute from the moment a user sends a prompt until they get the response back. At this point, a reasonable question to ask could be: How much time do these steps take?
When using ChatGPT, the response time is normally almost immediate. This response time is known as latency. Latency is a critical performance metric, especially in user-facing applications where response time significantly affects the user experience. Choosing the appropriate latency is crucial, depending on our use case.
When it comes to reducing the latency of the response, LLMOps employs various strategies and best practices to streamline the entire process from input reception to response delivery. LLMOps contribute to reducing model latency by executing all the required steps automatically and managing the resources needed efficiently so that no computation is waiting for available resources to run. Other best practices can also reduce latency:
Reducing latency not only improves the user experience but also contributes to cost efficiency by optimizing resource usage.
Up to this point, we haven’t discussed which model should be present in our LLMOps setup. There are various types of models available, each optimized for specific use cases, different size options, etc. Selecting the appropriate model is crucial and will largely depend on our application and available resources.
In addition, it seems that the number of LLMs and providers is increasing every day. That is why having a broad understanding of the different types of LLM and their providers is beneficial, especially when trying to identify the one that best suits our use case.
LLM models and providers can be categorized into the following types:
The primary benefits of open-source models lie in the transparency and the possibility to customize them. Open-source models normally offer full control on all the components, enabling easy debugging and extensive customization through training or fine-tuning. This degree of flexibility allows for better alignment of the LLM with your specific needs, as opposed to conforming to the predefined options set by the LLM provider.
However, managing open-source LLMs on your own can lead to significant engineering challenges and costs related to computing and storage. Even if there is a minimum infrastructure provided by open-source models, it is often challenging to compete with proprietary models in terms of latency, throughput, and inference costs.
There are many models out there to choose from. But how do we ensure we are choosing the right LLM?
Indeed, there are some criteria to consider depending on our use case and possibilities:
Whether proprietary or open-source, LLMs often require fine-tuning to be truly suited for specific applications.
Pre-fine-tuned LLMs are available for certain user tasks, commonly including chat models and models specialized in summarization or sentiment analysis. Another variant to consider is long-context models. Modern LLMs typically handle context lengths ranging from 2,000 to 8,000 tokens, meaning inputs and outputs beyond this range can’t be processed directly. However, some models offer long-context variants. For instance, GPT 3.5 has a larger 16k context-size variant.
Nevertheless, if the existing options don’t meet specific requirements, there is always the possibility of fine-tuning or even training a model ourselves. In this case, choosing an appropriate dataset is crucial, as it enables the model to understand the nature of the targeted task.
If you are interested in training an LLM model from scratch, I really recommend you to read the DataCamp tutorial, How to train an LLM with PyTorch.
If our application requires the fine-tuning of an existing model, the related steps should also be part of our LLMOps setup. Let’s add this customization step to our original diagram:
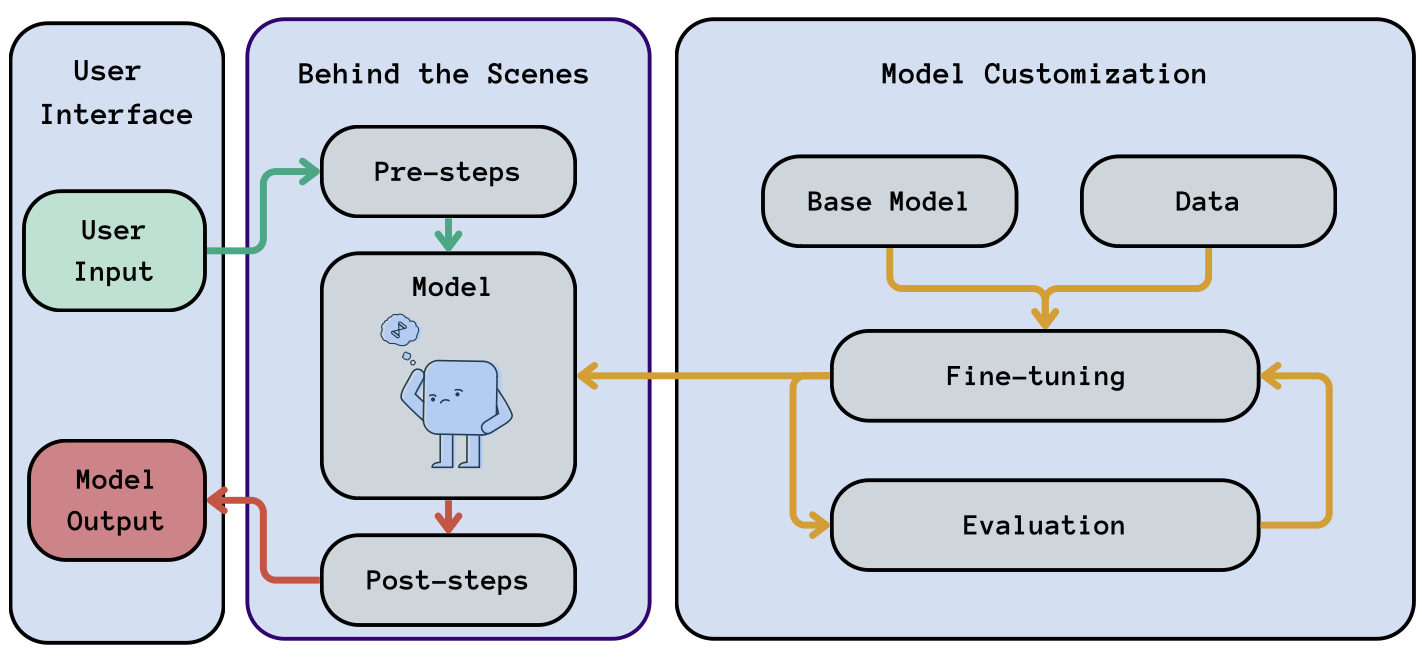
LLMOps workflow: Including the Model Customizatin steps (in orange) into our generic workflow.
Having a consistent fine-tuning pipeline can assist you in expanding your model’s knowledge over time as more data becomes available, allowing you to effortlessly upgrade your LLM version or make other modifications.
When depending on third-party models, it is important to note that these models can change from their availability to their cost. This can potentially force us to switch to a different base model. A robust LLMOps setup will enable us to handle this critical situation smoothly by just replacing the “Model” box with a different LLM.
One could think that fine-tuning your LLM or training it from scratch is a first step outside the LLMOps infrastructure since the LLM will operate once it is deployed to production. Nevertheless, that is not true, especially for the aforementioned reason: a successful service will need improvements in the model and be resilient to changes in providers, if necessary.
For effective training, fine-tuning, or model refinement in a generic LLMOps infrastructure, it is important to maintain data formatting consistent between training and posterior inference data. To do so, we typically format the training data in the JSON Lines (.jsonl) format. This format is highly suitable for fine-tuning LLMs due to its structure, allowing for efficient processing of large datasets. A typical .jsonl file for fine-tuning might look like this:
{"prompt": "Question: What is the capital of France?", "completion": "The capital of France is Paris."}
{"prompt": "Question: Who wrote Macbeth?", "completion": "Macbeth was written by William Shakespeare."}Each line in a .jsonl file is a distinct JSON object, representing a single training example, with prompt and completion keys indicating the input text and expected model response, respectively, as we would expect during inference. In addition, this format facilitates the incremental addition of new data to the model’s knowledge base.
Model parameters are also important when setting our LLMOps infrastructure since they have an impact on characteristics like model size and resource consumption.
Regarding training parameters, it is important to optimize training parameters to balance the model’s complexity with deployment limitations such as memory usage. This optimization is crucial for deploying models across diverse environments with varying resource capacities, ensuring that models are not just advanced but also practical for real-world applications.
Regarding the inference parameters, adjusting parameters like temperature and max tokens allows for controlling the length and randomness of the responses. These settings are managed as part of the LLMOps process to align the model’s output with the specific application requirements and user intention.
Prompt engineering techniques have been shown to enhance the default capabilities of LLMs. One reason for this is that they help to contextualize the model. For example, instructing the model to behave as an expert in a specific domain or guiding the model towards a desired output. Prompt Engineering and Management are crucial components that should be included in our LLMOps setup.
Among the most effective prompt engineering practices are few-shot prompting and chain-of-thought reasoning. Let’s briefly review these techniques and discuss how they can be integrated into our LLMOps setup:
Implementing techniques such as few-shot prompting and chain-of-thought reasoning within our LLMOps setup can be effectively achieved through the use of prompt templates.
Prompt templates are predefined structures used to guide the reasoning of LLMs. They provide a consistent structure, ensuring that similar types of requests are made uniformly or helping to include prompt engineering techniques transparently to the user.
Developing and managing a repository of well-crafted prompt templates for various use cases is crucial in an LLMOps setup. The selection of the appropriate prompt template for a specific use case is usually a preliminary step performed during the pre-processing phase before the query is sent to the model.
For few-shot prompting, the templates should be designed to include several examples that demonstrate the task or response style expected from the model. Similarly, to incorporate chain-of-thought reasoning, the prompt templates should be meticulously designed to include a step-by-step thought process. In essence, they should guide the model on how to methodically approach and decompose any given problem into simpler and more manageable steps.
Incorporating knowledge from external sources may be a step in the chain-of-thought reasoning, especially useful in frameworks like LangChain, where the model is instructed to retrieve information from the internet if its existing knowledge base is insufficient.
In both few-shot prompting and chain-of-thought reasoning, employing A/B testing of prompts is highly beneficial. This involves conducting controlled experiments by exposing different subsets of users to different prompt versions, objectively measuring their performance, and selecting the most effective ones based on the results. Moreover, in both cases, it is important to rely on performance data to iteratively improve our prompt templates.
Once the base model is trained or fine-tuned and we are happy with the result, it is time to deploy the model. Deployment of a model in the context of LLMOps refers to the process of making a language model available for use in a production environment. This involves taking the model out of the training environment and integrating it into the production infrastructure. This step is indicated in orange in our usual diagram:
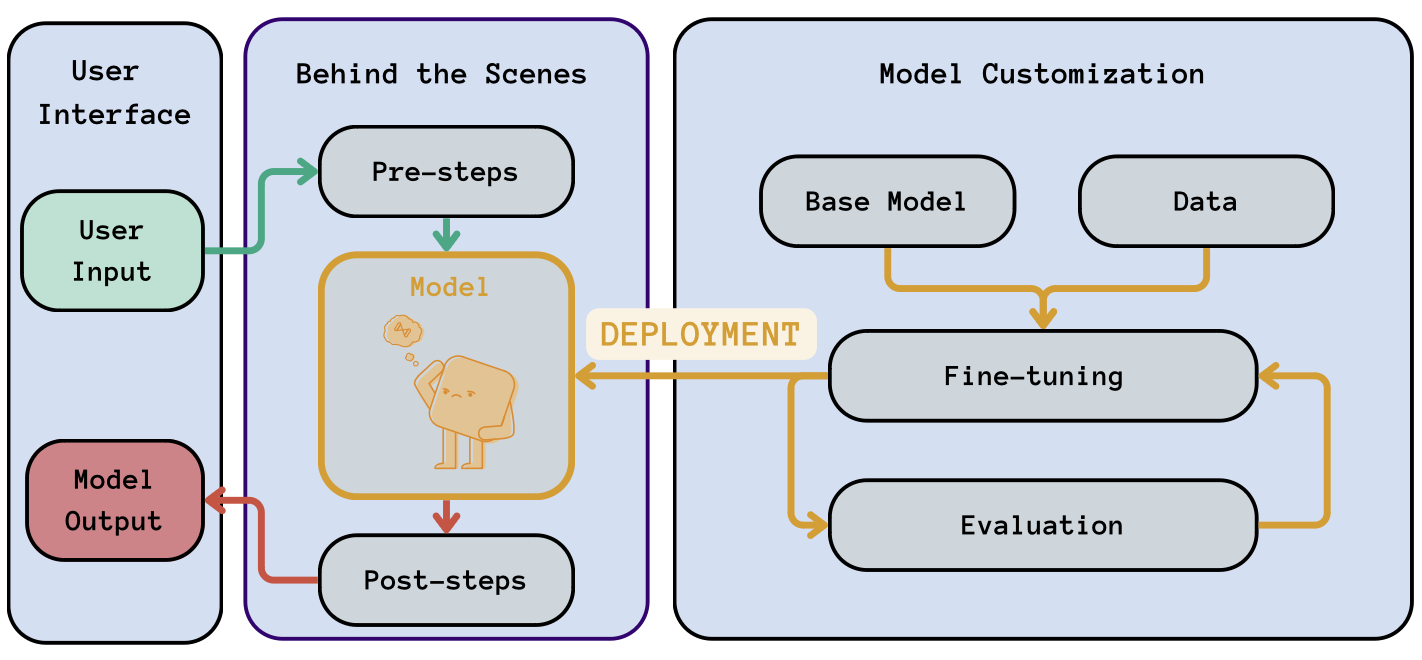
LLMOps workflow: Highlighting the deployment step (in orange) into our generic workflow. This step involves “moving” the model from the development environment to production.
The deployment also includes setting the interface that we will use to communicate with the model once in production. Generally, the interface depends on our processing mode:
The APIs can be deployed on web servers or cloud platforms, ensuring they are accessible to the users or the systems that need to interact with the model. Our LLMOps setup should ensure that the API can handle the expected load, with considerations for scaling, load balancing, and failover mechanisms.
For batch use cases, you can schedule batch jobs using tools like cron (in Unix-like systems) or cloud-based job scheduling services. These jobs will run the model on the new data at the specified intervals, process the data, and store the results.
Finally, deploying the model to the production setup normally involves model packaging and versioning:
Continuous Integration (CI) and Continuous Delivery (CD) pipelines automate the steps involved in bringing a model from the development environment to production, ensuring that the model is reliable, up-to-date, and deployed efficiently.
In LLMOps, as new code or changes are introduced to the model (like hyperparameter tuning, model architecture changes, or new training data), CI ensures that these changes are automatically tested. This includes running unit tests, integration tests, and any other checks to validate that the changes do not break the model or degrade its performance. In this sense, CI is a way of continuously monitoring our model.
Once the changes pass all tests in the CI phase, CD automates the model’s deployment to the production environment. This ensures that the most stable, tested version of the model is always running in the LLMOps production setup. CD also facilitates quick rollback to previous versions if an issue is detected in the production environment, minimizing downtime and ensuring service reliability.
Finally, there is one missing aspect that we haven’t commented on yet: how do we order our LLMOps components so that we form a reasonable chain of steps?
Orchestration involves defining and managing the order of operations in LLMOps setup, forming the so-called workflow. For example, defining the order of the pre and post-processing steps or the different tests that a new model must undergo until it is ready to be deployed.
In the LLM context, orchestration normally involves passing data between different components of the workflow. This is often managed by specifying data paths or workspaces where the output of one step is stored and then picked up by the next step.
Orchestration is often managed through configuration files, typically written in YAML (Yet Another Markup Language). These files define the components, their order, and the parameters for each step in the workflow. Domain Specific Languages (DSLs) are often used in these configuration files to provide a more intuitive and specialized syntax for defining the workflows.
Finally, workflows are normally automated. That ensures that once the workflow is initiated, all the related steps run smoothly without manual intervention, from one step to the next, thereby reducing the need for manual execution of tasks to avoid issues.
In this article, we have discussed the key components of an LLMOps infrastructure and their reason for being. Nevertheless, other advanced techniques can enhance your LLMOps infrastructure performance:
Ensuring data privacy and user protection in our LLMOps infrastructure is central to building a reliable service.
For example, implementing robust data anonymization techniques is critical. Techniques such as differential privacy, k-anonymity, or data masking can be used to ensure that the training data does not reveal sensitive personal information gathered when forming the training datasets. In addition, if we plan to use real-world data to iteratively improve our models, the user should be aware of it, and their data must be anonymized before incorporating it into the fine-tuning loop.
Another aspect concerning security is if we plan to store any private user information in our system, such as the conversation history in ChatGPT. In this case, we must ensure that all data is handled securely, and in compliance with data protection regulations like GDPR. This includes ensuring secure data storage and encrypted data transmission in our infrastructure.
Finally, we must ensure robust access controls in the LLMOps infrastructure, ensuring that only authorized people have access to the model, the data, and the training environment and that there won’t be any leaks exposing users’ personal information.
LLM-powered applications have been on the rise since last year, driven by the enhanced capabilities of recent LLM iterations. These applications deliver LLMs as-a-service, thereby necessitating a robust framework for their management and optimization, known as the LLMOps infrastructure.
In this article, we have explored the critical role of LLMOps as the backbone of a successful, efficient, and customer-centric LLM service. Firstly, we have reviewed the journey of a prompt from the moment a user sends it to the model until the response is received. LLMOps ensures that all these “behind the scenes” steps are streamlined and efficient.
Secondly, we have examined how LLMOps encompasses model training, deployment, monitoring, and maintenance. LLMOps also includes scaling resources to efficiently handle varying loads, thus guaranteeing the scalability and reliability of our LLM-based applications. Additionally, we have touched upon advanced best practices to refine our LLMOps infrastructure.
Finally, we have acknowledged how LLMOps is also involved in maintaining the integrity and security of LLMs as-a-service. As these models often process sensitive data, robust LLMOps practices are essential to enforce stringent security measures, ensuring data privacy and compliance with regulatory standards.
In conclusion, after reading this article, I hope I have convinced you of one important aspect: LLMOps is not just an operational necessity but a strategic asset that enhances the value, reliability, and sustainability of LLMs as-a-service.
Ready to put theory into practice? Dive deeper into the world of Large Language Models with our hands-on tutorial: "How to Build LLM Applications with LangChain". Start transforming your knowledge into actionable skills today!
Start Your LLM Journey Today!
Track
Course
Course
blog
Javier Canales Luna
12 min
blog
Zoumana Keita
13 min
blog
Nisha Arya Ahmed
12 min
blog
Adel Nehme
12 min
Tutorial
Andrea Valenzuela
Tutorial
Josep Ferrer

