
Course
Introduction to MongoDB in Python
3 hr
24K
A graph database is a specialized, single-purpose platform used to create and manipulate data of an associative and contextual nature. The graph itself contains nodes, edges, and properties that come together to allow users to represent and store data in a way that relational databases aren’t equipped to do.
The main concept of a graph database system is a relationship. Relationships are defined as first-class citizens — this means everything you can do with all other elements can be done with a relationship. Data is related together in a graph to store a collection of nodes and edges, where the edges represent the relationship between nodes.
Relationships allow data within the system to be linked together directly. Querying relationships in a graph database is fast since they’re stored in a way that doesn’t change. You may also visualize them, which makes them great for deriving insights for heavily interconnected data.
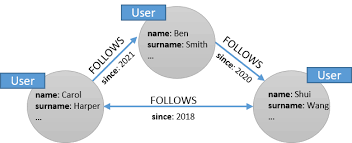
A representation of relationships in a social network graph database
You may still wonder how a graph database differs from a relational one. Both store information and are used to represent relationships between data, but the way they each achieve this goal is different.
We will split the differences between them into five categories:
Let’s delve deeper into how they differ.
Relational databases use data tables to structure information into rows and columns. Each column defines a specific attribute of the data entity, while the rows represent an individual data record. Since data tables have a fixed schema, users must define the relationships between different tables using primary and foreign keys.
In contrast, a graph database structures data using a graph structure in which nodes, edges, and properties are used to represent data. Namely, nodes define the objects, edges illustrate the relationships between nodes, and properties describe the attributes of the nodes and edges. More on this further down.
Relational databases leverage the power of SQL to manipulate data. SQL enables developers to perform various queries and effectively handles structured data with well-defined relationships between tables. It particularly excels in filtering, aggregating, and joining data against multiple tables.
Graph databases use traversal algorithms to query the graph data model. Traversal algorithms may be depth-first or breadth-first, which helps to discover and retrieve connected data rapidly.
Though it’s possible to scale a relation database horizontally (i.e., using sharding), it significantly enhances the complexity of data storage and may give rise to further issues such as consistency. The recommended way to scale a relational database is vertically. Vertical scaling is when the hardware is upgraded (e.g., CPU, storage, memory, etc.) to increase the workload a server can handle.
On the other hand, graph databases do a great job of scaling horizontally. They achieve this feat using partitioning, which is a technique that divides stored database objects into separate parts on different servers. These partitions then enable many servers to process graph queries in parallel.
Graph databases typically use index-free adjacency. This means each node directly references its neighboring nodes. Thus, accessing relationships and related data simply consists of memory point lookup. This essentially means it’s fast.
Relational databases must conduct scans of different tables to identify relationships between entities. For example, if you wanted to join multiple tables, the database system would have to scan the entire data to find the relationships. This means as the data gets larger, the performance decreases.
Relationships are central to graph databases. This makes them extremely easy to work with when using connected data, especially while performing multi-hop queries – queries to perform traverse paths with multiple relationships. In a relational database, this must be performed with SQL. Writing a multi-hop query in SQL doesn’t come naturally. They can become quite complex and easily lead to bulk queries that are difficult to read and maintain.
The focus on relationships makes graph databases well-suited for tasks that frequently observe dynamic changes and adaptations. Such tasks include semantic search and recommendation engines. In contrast, the rigidity of relational databases makes them ideal for structured data first well into tables. Examples of such data include customer data and transactions.
|
Graph database |
Relational database |
|
|
Data model / Schema |
Fixed |
Flexible |
|
Operations |
Traversal algorithms |
SQL |
|
Scalability |
Horizontal using partitioning |
Vertically (can do horizontal but adds complexity). |
|
Performance |
Fast (including large datasets) |
Slower as the dataset gets larger |
|
Ease of use |
Intuitive |
Unnatural (but are much more mature and popular in many use cases). |
|
Application |
Tasks that frequently observe dynamic changes and adaptations (e.g., Semantic search, recommendation engines, etc.). |
Tasks that depend on data integrity (e.g., customer data, transactions, etc.). |
As previously stated, graph databases enable users to represent data as a graph. The three vital components used to model data in this format are nodes, edges, and properties.
Objects or instances are represented using a node. Conceptually, nodes are the equivalent of a row in a relational database and act as a vertex within a graph. Grouping a node is simply done by applying a label to each member.
Another name for the edges in a graph is relationships. Relationships always consist of a start node, end node, type, and direction. They form the data patterns by describing parent-child relationships, actions, ownership, and the like.
Quite simply, properties are the information associated with nodes.
Let’s take a look at some of the most popular graph databases available for use today, helping us understand what their key features are.

Some popular graph databases
Neo4j is one of the world’s leading graph databases to enable users to deeply, easily, and quickly discover patterns and insights across billions of data connections. Namely, Neo4j is a highly scalable NoSQL open-source database developed using Java. Check out our NoSQL concepts course to learn more.
Key features include:
Applications working with densely connected data may be quickly and easily developed and run using Amazon Neptune, a fast, dependable, and fully managed graph database service. A purpose-built, high-performance graph database engine serves as the foundation of Neptune. This engine is designed to query the graph with millisecond latency while maintaining billions of relationships.
Key features include:
Two other popular options are ArangoDB and OrientDB.
ArangoDB is a free, open-source, NoSQL graph database system. It supports three data models (graphs, JSON documents, and key/value), which means it’s multi-model, with a single database core and a unified query language, ArangoDB Query Language (AQL). The tool is predominantly a query language and enables the combination of various data access patterns in a single query.
OrientDB is an open-source NoSQL database management system written in Java. Similar to ArangoDB, OrientDB is also a multi-model database that supports graphs, JSON documents, key/value, and object models; however, relationships are managed as they are in graph databases (i.e., direct connections between records). The tool has a robust security profiling system based on users and roles and supports querying with Gremlin along with SQL extended for graph traversal.
Our guide on NoSQL databases explores more reasons why they’re so useful for data science.
Social media networks are naturally represented with the graph data model. Leveraging a graph database simplifies the process of capturing relationships since the data does not need to be converted from a graph to a table and back again. The graph data model can be used directly to represent things such as users and their relationships.
Relationships between information categories such as friends in a network, customer interest, and purchase history may be stored in a graph database. Product recommendations can then be made to a user based on products purchased by other users with similar interests or purchase histories. In the friends in a network scenario, you may be able to use the graph database to discover users with friends in common who aren’t yet connected and recommend them to one another.
Graph databases can be used to store relationships between transactions, people, and other relevant information to enable users to find common patterns and build applications capable of detecting fraudulent activities. For example, it may be used to easily discover relationship patterns indicative of fraud, such as multiple individuals associated with a single email address or multiple people sharing the same IP address but residing in different physical addresses.
In this guide, you learned graph databases are specialized, single-purpose platforms used to create and manipulate data of an associative and contextual nature. You also learned that despite the obvious duty of storing data and representing relationships, relational and graph databases are quite different in how they achieve their objective. For example, relational databases use SQL for their operations, whereas graph databases use traversal algorithms, which make them much faster, even for large datasets, and better suited for data with a great deal of interconnectedness.
Learn more about databases from these resources:
Start your Database Journey Today!
Course
Course
Course
Tutorial
Kurtis Pykes
Tutorial
Eduardo Oliveira
Tutorial
Javier Canales Luna
Tutorial
Gary Alway
Tutorial
Kurtis Pykes
Tutorial
Francisco Javier Carrera Arias

