
Kurs
Grundlagen von Data Engineering
2 Std.
356K
Bislang mussten sich Dateningenieure auf ETL-Vorgänge (Extrahieren, Transformieren und Laden) konzentrieren, bei denen Daten aus verschiedenen Quellen extrahiert, in ein geeignetes Format umgewandelt und in ein Data Warehouse geladen werden. Die Notwendigkeit, diese Daten zu operationalisieren, um sie für gängige Geschäftsanwendungen zugänglich und nutzbar zu machen, hat jedoch zur Entwicklung von Reverse ETL geführt.
In diesem Artikel werden wir uns mit der Definition von Reverse ETL beschäftigen, wie es sich von traditionellem ETL unterscheidet und welche Werkzeuge für die Umsetzung zur Verfügung stehen. Wir werden auch praktische Anwendungsfälle untersuchen, um seine Bedeutung zu zeigen. Wenn du dich mit dem Thema noch nicht auskennst, solltest du dir unseren Kurs "ETL und ELT in Python" und unseren Kurs "Einführung in das Data Engineering" auf DataCamp ansehen, um den Einstieg zu finden. Unser Getting Started with Data Pipelines Code-Along ist eine weitere sehr hilfreiche Ressource.
Reverse ETL ist der Prozess, bei dem Daten aus einem Data Warehouse extrahiert, so umgewandelt werden, dass sie den Anforderungen der operativen Systeme entsprechen, und dann in diese anderen Systeme geladen werden. Dieser Ansatz steht im Gegensatz zum traditionellen ETL, bei dem Daten aus operativen Systemen extrahiert, transformiert und in ein Data Warehouse geladen werden.
In der Vergangenheit entwickelte sich das Datenmanagement von ETL zu ELT (Extrahieren, Laden, Transformieren), um dem wachsenden Bedarf an Echtzeit-Datenverarbeitung gerecht zu werden. Reverse ETL ist der neueste Schritt in dieser Entwicklung. Während sich ETL und ELT auf die Zentralisierung von Daten konzentrieren, zielt Reverse ETL darauf ab, diese Daten zu operationalisieren, indem sie in Systemen von Drittanbietern wie CRMs, Marketingplattformen und anderen operativen Tools nutzbar gemacht werden.
Wir haben gesagt, dass Reverse ETL ein Datenintegrationsprozess ist, der Erkenntnisse aus einem Data Warehouse oder einer Analyseplattform in betriebliche Systeme überträgt. Mit anderen Worten: Es kehrt den traditionellen ETL-Prozess um. Schauen wir uns nun jeden Schritt genauer an.
Der Prozess beginnt mit der Auswahl der wichtigsten Informationen aus einem Data Warehouse oder einer Analyseplattform. Das können Kundendaten, Verkaufszahlen oder etwas anderes sein. Wenn wir wissen, was wir von der Speicherung wollen, müssen wir die Daten vielleicht noch filtern, aggregieren oder irgendwie umwandeln, damit sie unseren Anforderungen entsprechen.
In einem nächsten Schritt werden die Daten aus dem Quellsystem den entsprechenden Feldern im Zielsystem zugeordnet. In dieser Phase kann eine optionale Datenanreicherung durchgeführt werden, indem Felder aus externen Quellen hinzugefügt werden, z. B. demografische Daten zu Kundenprofilen. Damit die Daten den Anforderungen des Zielsystems entsprechen, müssen sie wahrscheinlich noch umgewandelt werden, z. B. in Datentypen oder Datumsformate.
Schließlich werden die umgewandelten Daten über die API des Zielsystems entweder in Echtzeit oder per Batch-Update in das System geladen. Mechanismen zur Fehlerbehandlung, einschließlich Wiederholungslogik und Wiederherstellungsverfahren, verhindern Probleme beim Laden. Es wird ein Verfahren geben, das die Integrität der Daten beim Laden überprüft.
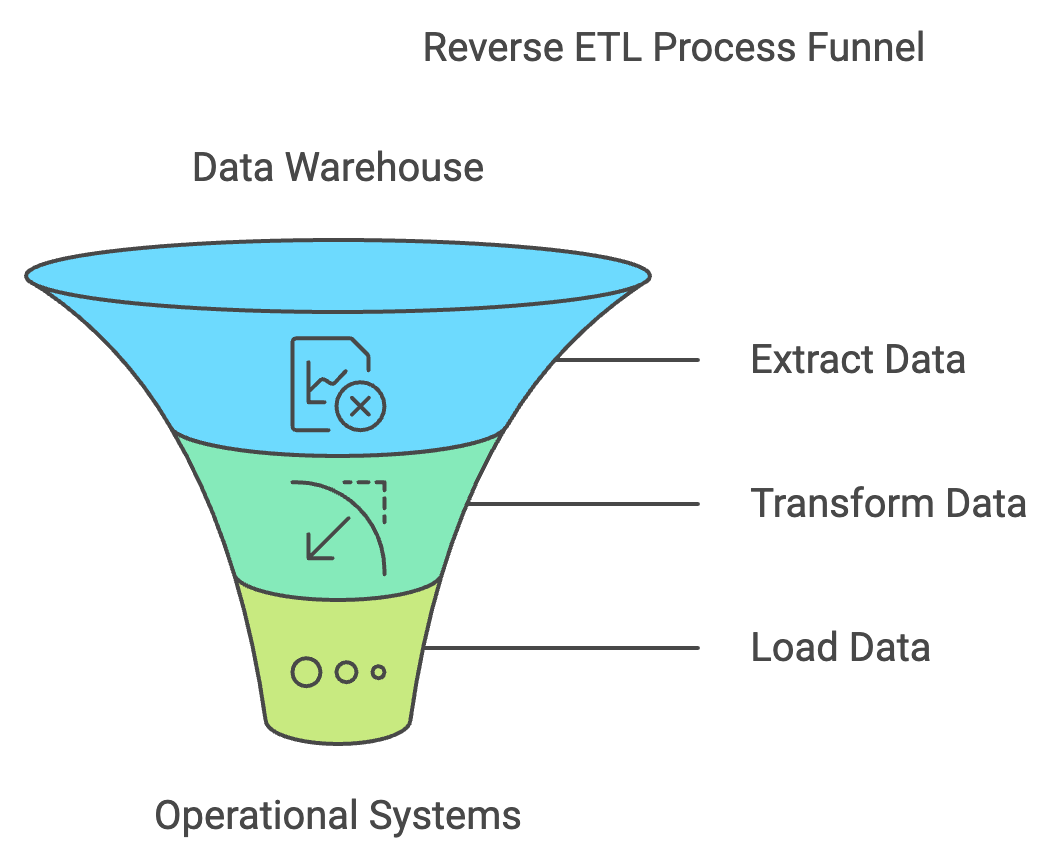
Grundlegende Illustration von Reverse ETL. Quelle: napkin.ai
Zur Veranschaulichung: Stell dir vor, ein Marketingteam nutzt ein Data Warehouse, um das Kundenverhalten zu analysieren. Reverse ETL kann Kundensegmente auf der Grundlage der Kaufhistorie und demografischer Daten extrahieren und diese Daten in eine Marketingautomatisierungsplattform laden. So kann das Team gezielte Kampagnen erstellen und Kundeninteraktionen personalisieren.
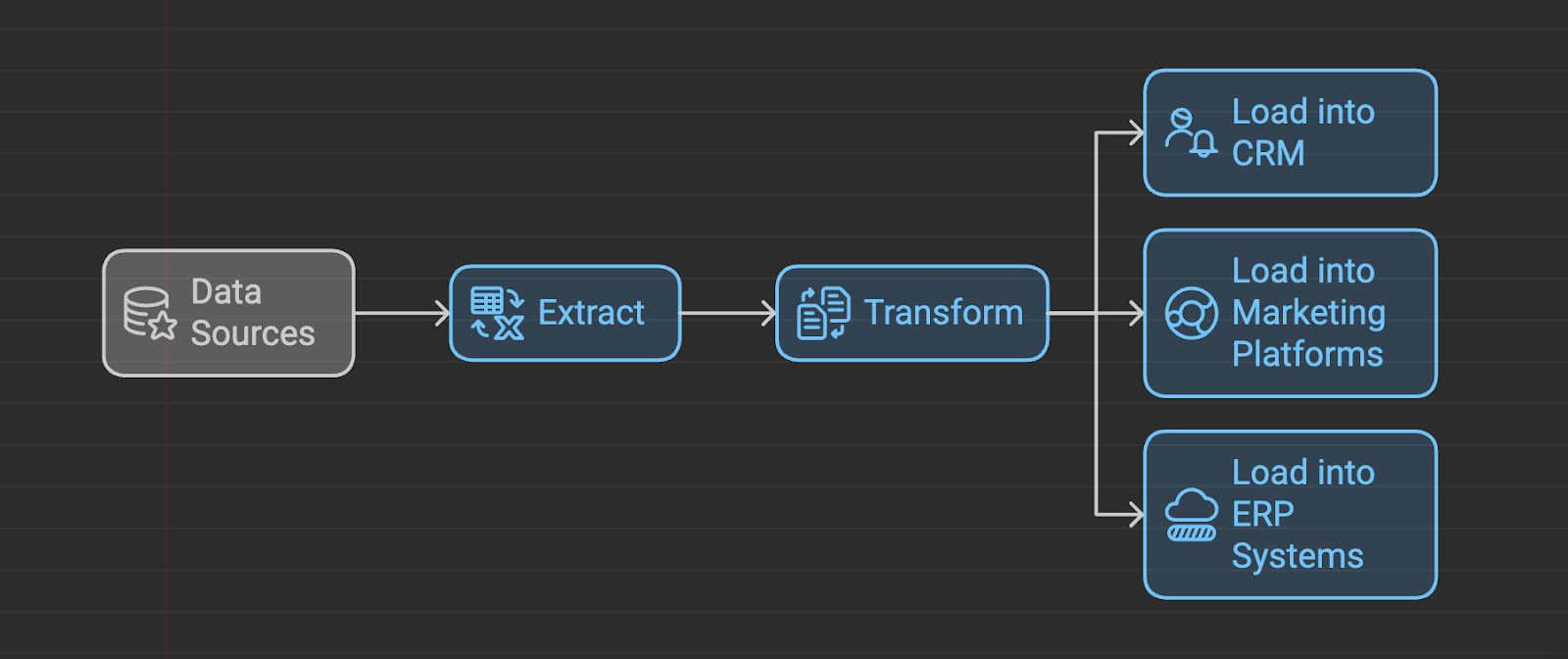
ETL-Prozess umkehren. Quelle: napkin.ai
Reverse ETL ist zwar vielversprechend, aber nicht perfekt. Für Dateningenieure kann es eine Herausforderung sein sicherzustellen, dass alle Daten korrekt sind und sich in verschiedenen und manchmal ungewohnten Systemen zurechtzufinden. Eine der größten Herausforderungen ist die Aufrechterhaltung der Datenqualität. Inkonsistente Daten können zu schlechten Entscheidungen führen, daher sind strenge Datenvalidierungs- und Bereinigungsprozesse wichtig.
Auch das Datenvolumen und die Geschwindigkeit können überwältigend sein. Der effiziente Umgang mit großen Datenbeständen erfordert Strategien wie inkrementelle Aktualisierungen und die Erfassung von Änderungsdaten. Diese Techniken konzentrieren sich darauf, nur notwendige Daten zu verarbeiten, die Leistung zu optimieren und die Systembelastung zu verringern. Eine weitere Hürde ist die Komplexität der API. Verschiedene Systeme haben unterschiedliche API-Fähigkeiten. Effektives API-Management und Standardisierung können helfen.
ETL ist ein traditioneller Datenintegrationsansatz, bei dem Daten aus verschiedenen Quellen extrahiert, in ein geeignetes Format umgewandelt und dann in ein Data Warehouse geladen werden. Dieser Prozess erfordert eine umfangreiche Datenbereinigung und -umwandlung, was ihn ressourcenintensiv und zeitaufwändig macht.
Bei ELT hingegen stehen Geschwindigkeit und Flexibilität im Vordergrund. Die Daten werden aus den Quellen extrahiert und in ihrem Rohformat direkt in ein Data Warehouse geladen. Die Umwandlung erfolgt innerhalb des Data Warehouse, oft mit Hilfe leistungsstarker Abfrageprogramme. Dieser Ansatz nutzt die Rechenleistung moderner Data Warehouses und sorgt für mehr Flexibilität bei der Datenexploration und -analyse.
Während sich ETL und ELT darauf konzentrieren, Daten in ein Data Warehouse zu verschieben, verfolgt Reverse ETL einen anderen Ansatz. Es extrahiert transformierte Daten aus dem Data Warehouse und sendet sie an operative Systeme wie CRM, Marketing-Automatisierungsplattformen und Kundensupport-Tools. So können Unternehmen die aus der Datenanalyse gewonnenen Erkenntnisse nutzen, um in Echtzeit zu handeln und ihre Geschäftsprozesse zu verbessern. Der Wechsel von ETL zu ELT wird vor allem durch die folgenden Faktoren vorangetrieben:
Die Entwicklung des Datenmanagements war im Wesentlichen eine Reise zu mehr Effizienz, Flexibilität und umsetzbaren Erkenntnissen. ETL legte den Grundstein, ELT beschleunigte die Datenaufnahme und -umwandlung, und Reverse ETL schloss den Kreislauf, indem es Einblicke in die betrieblichen Arbeitsabläufe ermöglichte.
ETL und ELT sind beides Methoden, um Daten von einem System in ein anderes zu übertragen. Auch wenn sie sich ähnlich anhören, gibt es entscheidende Unterschiede in der Art und Weise, wie sie mit der Datenumwandlung umgehen. Hier ist eine Momentaufnahme, aber eine wirklich detaillierte Aufschlüsselung findest du in unserem ETL vs. ETL. ELT blog post.
| Feature | ETL | ELT |
|---|---|---|
| Datenumwandlung | Vor dem Laden | Nach dem Laden |
| Datenqualität | Hoher Stellenwert der Datenbereinigung | Weniger Wert auf die Reinigung im Vorfeld |
| Bearbeitungszeit | Längere Zeit aufgrund der Transformation | Schneller durch parallele Verarbeitung |
| Datenvolumen | Besser geeignet für kleinere Datensätze | Effizienter Umgang mit großen Datensätzen |
| Flexibilität | Weniger Flexibilität | Mehr Flexibilität durch die Verfügbarkeit von Rohdaten |
Reverse ETL ist ein leistungsfähiges Werkzeug, das die Lücke zwischen Dateneinsicht und operativer Umsetzung schließt. Du kannst eine Welt voller Möglichkeiten erschließen, indem du wertvolle Daten aus deinem Data Warehouse in betriebliche Systeme überträgst.
Reverse ETL ist sogar mehr als nur ein Werkzeug zur Datenübertragung. Es ist ein strategischer Vorteil, der dein Unternehmen voranbringen kann. Hier sind einige der wichtigsten Ideen, die meiner Meinung nach am wichtigsten sind.
Liya Aizenberg, Director of Data Engineering bei Away, verrät, wie man Data-Engineering-Initiativen am besten auf die Unternehmensziele abstimmt.
Für die Implementierung von Reverse ETL stehen verschiedene Tools und Plattformen zur Verfügung, die jeweils über einzigartige Funktionen und Möglichkeiten verfügen. Die folgende Tabelle zeigt einige beliebte Optionen:
Bei der Auswahl eines Reverse-ETL-Tools solltest du die folgenden Faktoren berücksichtigen:
Wenn du diese Faktoren und die spezifischen Bedürfnisse deines Unternehmens sorgfältig abwägst, kannst du das am besten geeignete Reverse-ETL-Tool auswählen, um das volle Potenzial deiner Daten zu erschließen.
Ich hoffe, du kannst die Bedeutung von Reverse ETL erkennen und schätzen. Es ist viel mehr als nur ein technisches Verfahren. Unternehmen, die über die richtigen Ressourcen verfügen, darunter Dateningenieure, die sich mit Reverse ETL auskennen, können sich von einem schwerfälligen Unternehmen in ein dynamisches Unternehmen verwandeln, das Echtzeitdaten nutzt, um zu wachsen, den Umsatz zu steigern und schnell auf Marktveränderungen zu reagieren.
Wenn du dich ernsthaft für Data Engineering interessierst, melde dich für unseren umfassenden Data Engineer in Python an, der sich auf die Rolle von Python bei der Automatisierung und Optimierung von Datenprozessen konzentriert. Wenn du das Gefühl hast, dass du zunächst mehr Erfahrung in SQL gebrauchen könntest, solltest du zunächst unseren Karrierepfad Associate Data Engineer in SQL ausprobieren, in dem sowohl ETL- als auch ELT-Prozesse im Detail untersucht werden, zusätzlich zu ihrer Beziehung zu PostgreSQL.
Lernen mit DataCamp
Kurs
Kurs
Kurs