
Course
Understanding Data Engineering
2 hr
355.8K
Traditionally, data engineers have had to focus on ETL (extract, transform, and load) operations, which entail extracting data from multiple sources, converting it to an appropriate format, and loading it into a data warehouse. However, the necessity to operationalize this data—to make it accessible and useful for common business applications—has led to the development of reverse ETL.
In this article, we will explore reverse ETL's definition, how it differs from traditional ETL, and the tools available for implementation. We will also examine practical use cases to show its importance. If you're new to the topic, check out our ETL and ELT in Python course and our Introduction to Data Engineering course on DataCamp to get started. Our Getting Started with Data Pipelines code-along is another very helpful resource.
Reverse ETL is the process of extracting data from a data warehouse, transforming it to fit the requirements of operational systems, and then loading it into those other systems. This approach contrasts with traditional ETL, where data is extracted from operational systems, transformed, and loaded into a data warehouse.
Historically, data management evolved from ETL to ELT (extract, load, transform) to address the growing need for real-time data processing. Reverse ETL represents the latest step in this evolution. While ETL and ELT focus on centralizing data, Reverse ETL aims to operationalize this data by making it actionable within third-party systems such as CRMs, marketing platforms, and other operational tools.
We said that reverse ETL is a data integration process that moves insights from a data warehouse or analytics platform into operational systems. In other words, it reverses the traditional ETL process. Let's now look more closely at each step.
The process begins by choosing the most relevant information from a data warehouse or analytics platform. This might include customer data, sales metrics, or something else. After we know what we want from storage, we still might need to filter, aggregate, or somehow transform the data to meet our needs.
As a next step, data from the source system is mapped to corresponding fields in the target system. Optional data enrichment can be performed at this stage by adding fields from external sources, such as adding demographic data to customer profiles. There’s probably additional transformation that happens so the data matches the target system's requirements, like converting data types or handling date formats.
Finally, the transformed data is loaded into the target system using its API with either real-time or batch updates. Error-handling mechanisms, including retry logic and recovery procedures, prevent issues during loading. There will be a process will verify the integrity of the data upon loading.
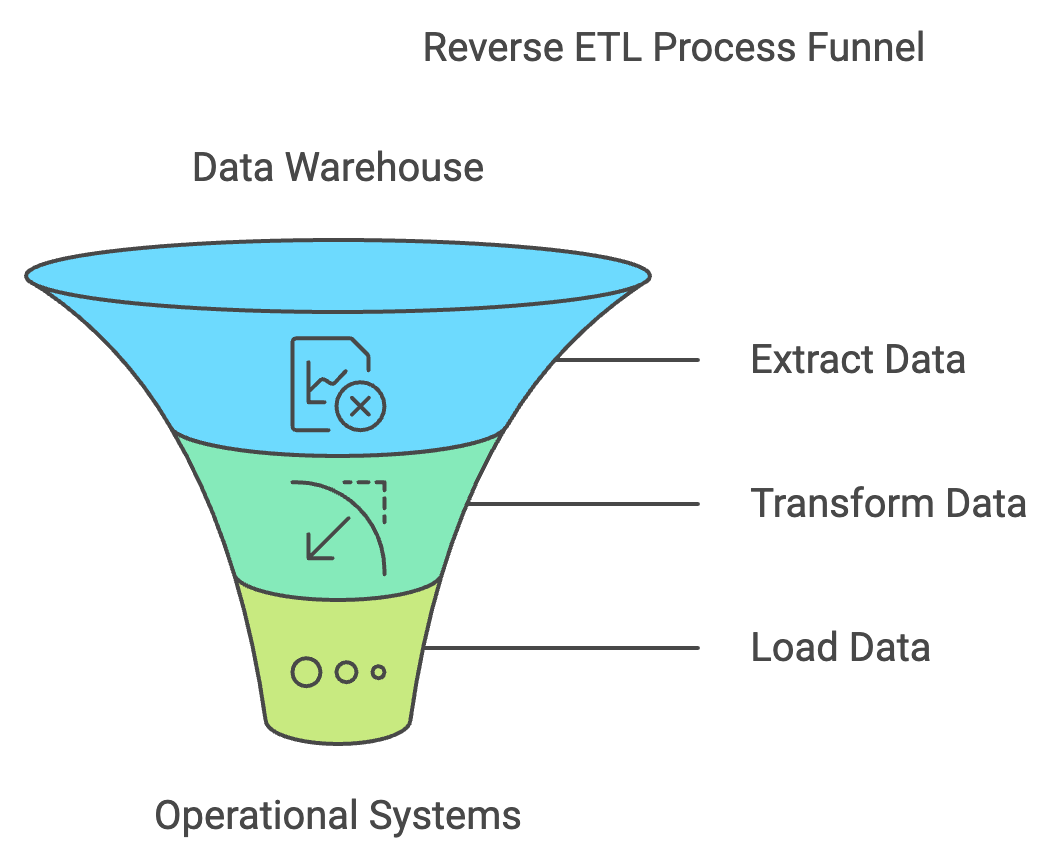
Basic illustration of reverse ETL. Source: napkin.ai
To illustrate, consider a marketing team using a data warehouse to analyze customer behavior. Reverse ETL can extract customer segments based on purchase history and demographics and load this data into a marketing automation platform. This enables the team to create targeted campaigns and personalize customer interactions.
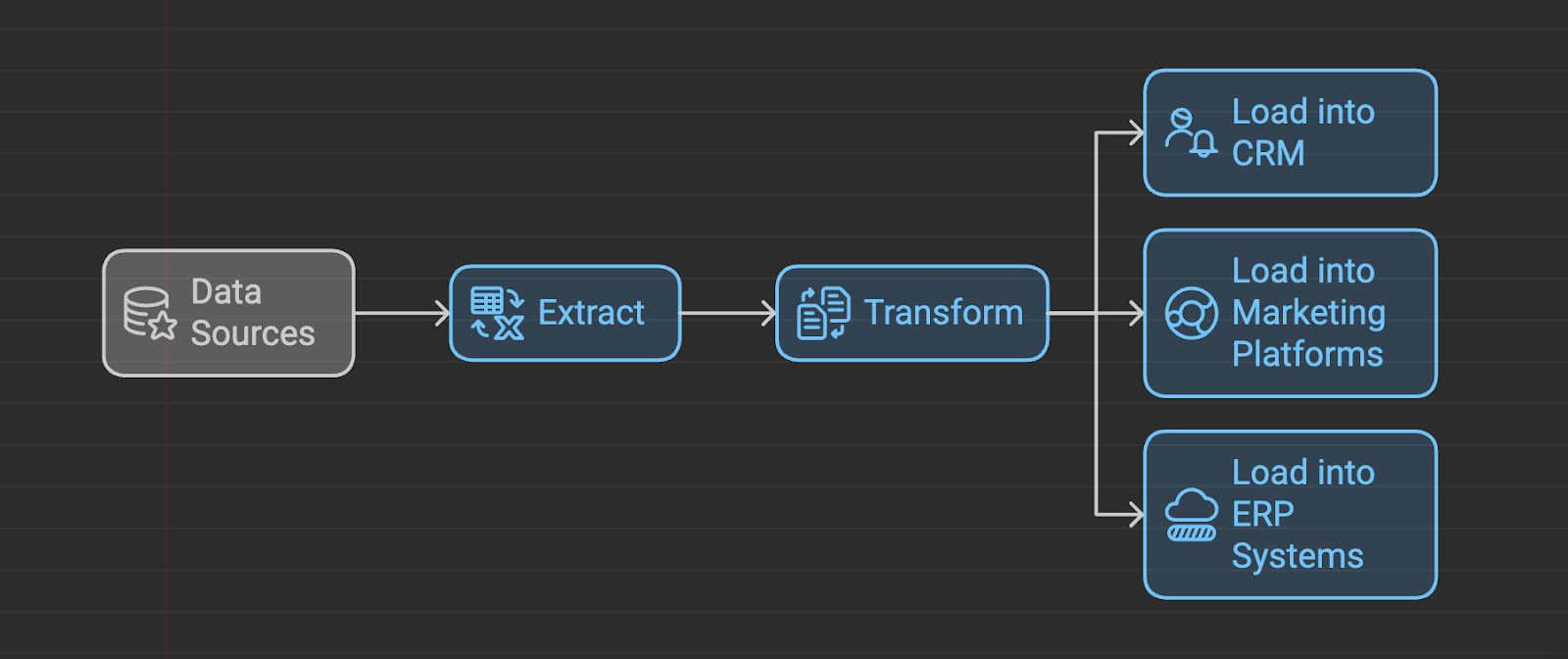
Reverse ETL process. Source: napkin.ai
While promising, reverse ETL isn't perfect. It can be challenging for data engineers to make sure all the data is accurate and find their way around different and sometimes unfamiliar systems. One of the biggest challenges is maintaining data quality. Inconsistent data can lead to bad decisions, so rigorous data validation and cleaning processes are important.
Data volume and speed can also be overwhelming. Handling large datasets efficiently requires strategies like incremental updates and change data capture. These techniques focus on processing only necessary data, optimizing performance, and reducing system load. Another hurdle is API complexity. Different systems have varying API capabilities. Effective API management and standardization can help.
ETL is a traditional data integration approach where data is extracted from various sources, transformed into a suitable format, and then loaded into a data warehouse. This process involves significant upfront data cleaning and transformation, making it resource-intensive and time-consuming.
ELT, on the other hand, prioritizes speed and flexibility. Data is extracted from sources and loaded directly into a data warehouse in its raw format. Transformations occur within the data warehouse, often using powerful query engines. This approach leverages the computational power of modern data warehouses and provides greater agility in data exploration and analysis.
While ETL and ELT focus on moving data into a data warehouse, reverse ETL takes a different approach. It extracts transformed data from the data warehouse and sends it to operational systems, such as CRM, marketing automation platforms, and customer support tools. This enables organizations to leverage insights derived from data analysis to drive real-time actions and improve business processes. The shift from ETL to ELT is primarily driven by the following factors:
In essence, the evolution of data management has been a journey toward greater efficiency, flexibility, and actionable insights. ETL laid the foundation, ELT accelerated data ingestion and transformation, and reverse ETL closed the loop by bringing insights into operational workflows.
ETL and ELT are both methods for moving data from one system to another. While they might sound similar, they have critical differences in how they handle data transformation. Here is a snapshot, but for a really detailed breakdown, read our ETL vs. ELT blog post.
| Feature | ETL | ELT |
|---|---|---|
| Data Transformation | Before Loading | After Loading |
| Data Quality | High Emphasis on Data Cleaning | Less emphasis on upfront cleaning |
| Processing Time | Longer time due to transformation | Faster due to parallel processing |
| Data Volume | Better suited for smaller datasets | Handles large datasets efficiently |
| Flexibility | Less flexibility | More flexibility due to raw data availability |
Reverse ETL is a powerful tool that bridges the gap between data insights and operational execution. You can unlock a world of possibilities by transferring valuable data from your data warehouse to operational systems.
Reverse ETL is even more than a data transfer tool. It's a strategic asset that can propel your business forward. Here are some of the important ideas I think are the most important.
If you are looking for additional insight from industry leaders, Liya Aizenberg, Director of Data Engineering at Away, shares great insight into how to best align data engineering initiatives with business goals.
Several tools and platforms are available for implementing reverse ETL, each with unique features and capabilities. The following table shows some popular options:
When choosing a reverse ETL tool, consider the following factors:
By carefully evaluating these factors and your organization's specific needs, you can select the most suitable reverse ETL tool to unlock your data's full potential.
I hope you can see and appreciate the importance of reverse ETL. It's much more than just a technical procedure. Companies that have the right resources, including data engineers who are experienced in reverse ETL, can transform from being something stodgy into one that is dynamic and uses real-time data to grow and increase sales and respond quickly to market changes.
If you are serious about data engineering, enroll in our comprehensive Data Engineer in Python career track, which focuses on Python's role in automating and optimizing data processes. If you feel like you could use more experience in SQL first, try our Associate Data Engineer in SQL career track first, which explores both ETL and ELT processes in detail, in addition to their relationship to PostgreSQL.
Learn with DataCamp
Course
Course
Course
blog
Austin Chia
7 min
blog
DataCamp Team
12 min
blog
Julia Winn
6 min
blog
Vahab Khademi
11 min
Tutorial
Jake Roach
code-along
Jake Roach
