
Lernpfad
Grundlagen der KI
10 Std.
Stell dir vor, du beobachtest einen Vogelschwarm im Flug. Es gibt keinen Anführer, niemanden, der Anweisungen gibt, und doch gleiten sie in perfekter Harmonie zusammen. Es mag wie Chaos aussehen, aber es gibt eine versteckte Ordnung. Das gleiche Muster kannst du bei Fischschwärmen beobachten, die Raubtiere meiden, oder bei Ameisen, die den kürzesten Weg zum Futter finden. Diese Lebewesen verlassen sich auf einfache Regeln und lokale Kommunikation, um erstaunlich komplexe Aufgaben ohne zentrale Kontrolle zu bewältigen.
Das ist die Magie der Schwarmintelligenz.
Wir können dieses Verhalten mit Algorithmen nachahmen, die schwierige Probleme lösen, indem sie die Schwarmintelligenz imitieren.
Schwarmintelligenz ist ein rechnerischer Ansatz, der komplexe Probleme löst, indem er das dezentrale, selbstorganisierte Verhalten nachahmt, das in natürlichen Schwärmen wie Vogelschwärmen oder Ameisenvölkern zu beobachten ist.
Wir wollen zwei Schlüsselkonzepte untersuchen: Dezentralisierung und positives Feedback.
Der Kern der Schwarmintelligenz ist das Konzept der Dezentralisierung. Anstatt sich auf einen zentralen Anführer zu verlassen, der die Aktionen steuert, agiert jeder Einzelne, der "Agent", autonom auf der Grundlage begrenzter, lokaler Informationen.
Diese dezentralisierte Entscheidungsfindung führt zu einer emergenten Eigenschaft - komplexes, organisiertes Verhalten, das aus den einfachen Interaktionen der Agenten entsteht. In Schwarm-Systemen ist das Gesamtergebnis oder die Lösung nicht vorprogrammiert, sondern ergibt sich ganz natürlich aus den einzelnen Aktionen.
Nimm die Ameisen als Beispiel. Bei der Futtersuche erkundet eine Ameise wahllos ihre Umgebung, bis sie Nahrung findet und dann eine Pheromonspur auf ihrem Weg zurück zur Kolonie legt. Andere Ameisen, die auf diese Spur stoßen, folgen ihr mit größerer Wahrscheinlichkeit und verstärken den Weg, wenn sie am Ende Futter finden. Mit der Zeit ziehen kürzere oder effizientere Routen natürlich mehr Ameisen an, da sich entlang dieser Pfade stärkere Pheromonspuren bilden. Keine einzelne Ameise "weiß" von Anfang an die beste Route, aber gemeinsam, durch dezentrale Entscheidungen und die Verstärkung erfolgreicher Wege, konvergiert die Kolonie zur optimalen Lösung.
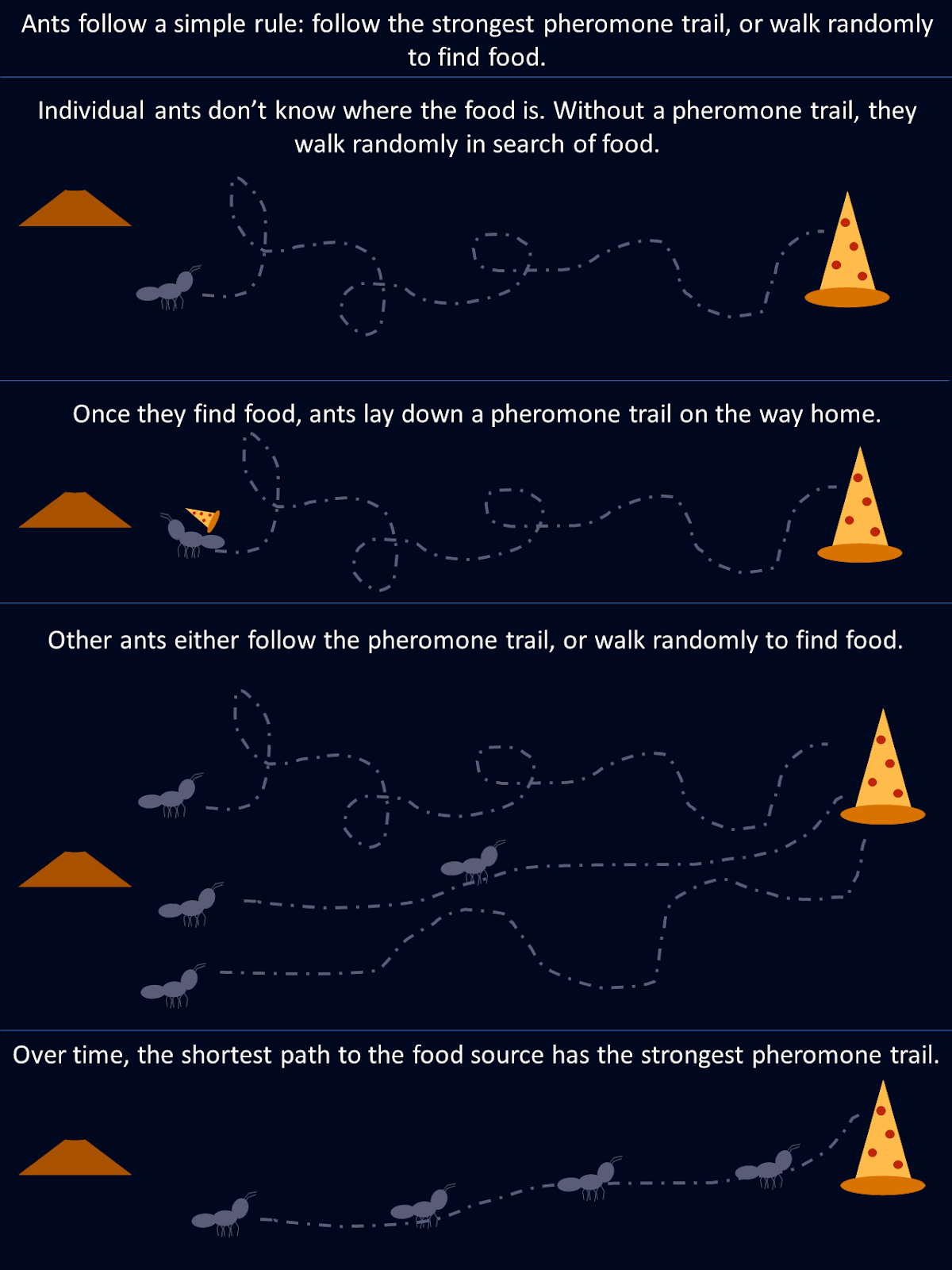
Dieses Diagramm zeigt, wie einfache Regeln, die von einzelnen Ameisen befolgt werden, zu einer optimalen Lösung für die gesamte Kolonie führen.
Positives Feedback ist ein Mechanismus in Schwarmintelligenzsystemen, bei dem erfolgreiche Aktionen belohnt und verstärkt werden. Das führt zu einem sich selbst verstärkenden Prozess, so wie die Ameisen die Pheromonspuren entlang kürzerer Futterwege verstärken. Diese Verstärkung von vorteilhaften Verhaltensweisen hilft dem Schwarm, seine Gesamtleistung im Laufe der Zeit zu verbessern.
Unter künstlichen IntelligenzDie Algorithmen der Schwarmintelligenz ahmen dies nach, indem sie Schlüsselfaktoren wie Wahrscheinlichkeiten oder Gewichte auf der Grundlage der Qualität der gefundenen Lösungen anpassen. Wenn bessere Lösungen entdeckt werden, konzentrieren sich die Agenten zunehmend auf diese, was den Konvergenzprozess beschleunigt. Diese dynamische Rückkopplungsschleife ermöglicht es Schwarm-Systemen, sich an veränderte Umgebungen anzupassen und ihre Leistung zu verbessern.
Es gibt mehrere Schwarmintelligenz-Algorithmen, die verschiedene biologische Systeme nachahmen. Sehen wir uns ein paar der beliebtesten an.
Die Ameisenkolonie-Optimierung (ACO) ist ein Algorithmus, der durch das oben beschriebene Futtersuchverhalten der Ameisen inspiriert wurde. Es wurde entwickelt, um die kombinatorische Optimierung Optimierungsprobleme zu lösen, insbesondere solche, bei denen wir die bestmögliche Lösung unter vielen finden müssen. Ein klassisches Beispiel dafür ist das Travelling-Salesman-Problembei dem es darum geht, die kürzestmögliche Route zu finden, die eine Reihe von Orten miteinander verbindet.
In der Natur kommunizieren Ameisen, indem sie Pheromonspuren hinterlassen, die anderen Ameisen den Weg zu einer Futterquelle signalisieren. Je mehr Ameisen dieser Spur folgen, desto stärker wird sie. ACO ahmt dieses Verhalten mit Pheromonen nach, die als mathematische Werte in einer Pheromonmatrix gespeichert sind. Diese Matrix hält die Wünschbarkeit verschiedener Lösungen fest und wird im Laufe des Algorithmus aktualisiert.
Bei ACO stellt jede "künstliche Ameise" eine potenzielle Lösung für das Problem dar, wie z.B. eine Route beim Travelling-Salesman-Problem. Der Algorithmus beginnt damit, dass alle Ameisen nach dem Zufallsprinzip Pfade auswählen, und die Pheromonwerte helfen dabei, zukünftige Ameisen zu leiten. Diese Werte werden in einer Matrix gespeichert, in der jeder Eintrag dem "Pheromonlevel" zwischen zwei Punkten (wie Städten) entspricht.
Diese mathematische Darstellung der Pheromone ermöglicht es ACO, ein effektives Gleichgewicht zwischen Erkundung und Ausbeutung herzustellen und große Lösungsräume zu durchsuchen, ohne in lokalen Optima stecken zu bleiben.
Versuchen wir es mit einem Beispiel, bei dem ACO ein einfaches Problem löst: Finde den kürzesten Weg zwischen Punkten in einem Diagramm.
Diese ACO-Implementierung simuliert, wie künstliche "Ameisen" 20 Knoten in einem Graphen durchqueren, um den kürzesten Weg zu finden. Jede Ameise startet an einem zufälligen Knotenpunkt und wählt ihren nächsten Zug anhand von Pheromonspuren und Entfernungen zwischen den Knotenpunkten aus. Nachdem sie alle Wege erkundet haben, kehren die Ameisen zu ihrem Ausgangspunkt zurück und vollenden so eine komplette Schleife.
Im Laufe der Zeit werden die Pheromone aktualisiert: Die kürzeren Pfade erhalten eine stärkere Verstärkung, während sich andere verflüchtigen. Durch diesen dynamischen Prozess konvergiert der Algorithmus zu einer optimalen Lösung.
import numpy as np
import matplotlib.pyplot as plt
# Graph class represents the environment where ants will travel
class Graph:
def __init__(self, distances):
# Initialize the graph with a distance matrix (distances between nodes)
self.distances = distances
self.num_nodes = len(distances) # Number of nodes (cities)
# Initialize pheromones for each path between nodes (same size as distances)
self.pheromones = np.ones_like(distances, dtype=float) # Start with equal pheromones
# Ant class represents an individual ant that travels across the graph
class Ant:
def __init__(self, graph):
self.graph = graph
# Choose a random starting node for the ant
self.current_node = np.random.randint(graph.num_nodes)
self.path = [self.current_node] # Start path with the initial node
self.total_distance = 0 # Start with zero distance traveled
# Unvisited nodes are all nodes except the starting one
self.unvisited_nodes = set(range(graph.num_nodes)) - {self.current_node}
# Select the next node for the ant to travel to, based on pheromones and distances
def select_next_node(self):
# Initialize an array to store the probability for each node
probabilities = np.zeros(self.graph.num_nodes)
# For each unvisited node, calculate the probability based on pheromones and distances
for node in self.unvisited_nodes:
if self.graph.distances[self.current_node][node] > 0: # Only consider reachable nodes
# The more pheromones and the shorter the distance, the more likely the node will be chosen
probabilities[node] = (self.graph.pheromones[self.current_node][node] ** 2 /
self.graph.distances[self.current_node][node])
probabilities /= probabilities.sum() # Normalize the probabilities to sum to 1
# Choose the next node based on the calculated probabilities
next_node = np.random.choice(range(self.graph.num_nodes), p=probabilities)
return next_node
# Move to the next node and update the ant's path
def move(self):
next_node = self.select_next_node() # Pick the next node
self.path.append(next_node) # Add it to the path
# Add the distance between the current node and the next node to the total distance
self.total_distance += self.graph.distances[self.current_node][next_node]
self.current_node = next_node # Update the current node to the next node
self.unvisited_nodes.remove(next_node) # Mark the next node as visited
# Complete the path by visiting all nodes and returning to the starting node
def complete_path(self):
while self.unvisited_nodes: # While there are still unvisited nodes
self.move() # Keep moving to the next node
# After visiting all nodes, return to the starting node to complete the cycle
self.total_distance += self.graph.distances[self.current_node][self.path[0]]
self.path.append(self.path[0]) # Add the starting node to the end of the path
# ACO (Ant Colony Optimization) class runs the algorithm to find the best path
class ACO:
def __init__(self, graph, num_ants, num_iterations, decay=0.5, alpha=1.0):
self.graph = graph
self.num_ants = num_ants # Number of ants in each iteration
self.num_iterations = num_iterations # Number of iterations
self.decay = decay # Rate at which pheromones evaporate
self.alpha = alpha # Strength of pheromone update
self.best_distance_history = [] # Store the best distance found in each iteration
# Main function to run the ACO algorithm
def run(self):
best_path = None
best_distance = np.inf # Start with a very large number for comparison
# Run the algorithm for the specified number of iterations
for _ in range(self.num_iterations):
ants = [Ant(self.graph) for _ in range(self.num_ants)] # Create a group of ants
for ant in ants:
ant.complete_path() # Let each ant complete its path
# If the current ant's path is shorter than the best one found so far, update the best path
if ant.total_distance < best_distance:
best_path = ant.path
best_distance = ant.total_distance
self.update_pheromones(ants) # Update pheromones based on the ants' paths
self.best_distance_history.append(best_distance) # Save the best distance for each iteration
return best_path, best_distance
# Update the pheromones on the paths after all ants have completed their trips
def update_pheromones(self, ants):
self.graph.pheromones *= self.decay # Reduce pheromones on all paths (evaporation)
# For each ant, increase pheromones on the paths they took, based on how good their path was
for ant in ants:
for i in range(len(ant.path) - 1):
from_node = ant.path[i]
to_node = ant.path[i + 1]
# Update the pheromones inversely proportional to the total distance traveled by the ant
self.graph.pheromones[from_node][to_node] += self.alpha / ant.total_distance
# Generate random distances between nodes (cities) for a 20-node graph
num_nodes = 20
distances = np.random.randint(1, 100, size=(num_nodes, num_nodes)) # Random distances between 1 and 100
np.fill_diagonal(distances, 0) # Distance from a node to itself is 0
graph = Graph(distances) # Create the graph with the random distances
aco = ACO(graph, num_ants=10, num_iterations=30) # Initialize ACO with 10 ants and 30 iterations
best_path, best_distance = aco.run() # Run the ACO algorithm to find the best path
# Print the best path found and the total distance
print(f"Best path: {best_path}")
print(f"Total distance: {best_distance}")
# Plotting the final solution (first plot) - Shows the final path found by the ants
def plot_final_solution(distances, path):
num_nodes = len(distances)
# Generate random coordinates for the nodes to visualize them on a 2D plane
coordinates = np.random.rand(num_nodes, 2) * 10
# Plot the nodes (cities) as red points
plt.scatter(coordinates[:, 0], coordinates[:, 1], color='red')
# Label each node with its index number
for i in range(num_nodes):
plt.text(coordinates[i, 0], coordinates[i, 1], f"{i}", fontsize=10)
# Plot the path (edges) connecting the nodes, showing the best path found
for i in range(len(path) - 1):
start, end = path[i], path[i + 1]
plt.plot([coordinates[start, 0], coordinates[end, 0]],
[coordinates[start, 1], coordinates[end, 1]],
'blue', linewidth=1.5)
plt.title("Final Solution: Best Path")
plt.show()
# Plotting the distance over iterations (second plot) - Shows how the path length improves over time
def plot_distance_over_iterations(best_distance_history):
# Plot the best distance found in each iteration (should decrease over time)
plt.plot(best_distance_history, color='green', linewidth=2)
plt.title("Trip Length Over Iterations")
plt.xlabel("Iteration")
plt.ylabel("Distance")
plt.show()
# Call the plotting functions to display the results
plot_final_solution(distances, best_path)
plot_distance_over_iterations(aco.best_distance_history)![Diese Grafik zeigt die endgültige Lösung, also den besten Weg, der gefunden wurde, um die einzelnen Knotenpunkte auf dem kürzesten Weg zu erreichen. In diesem Durchlauf wurde die beste Route gefunden: [4, 5, 17, 9, 11, 16, 13, 2, 7, 3, 6, 1, 14, 12, 18, 0, 10, 19, 15, 8, 4], mit einer Gesamtentfernung von 129.](https://media.datacamp.com/cms/google/ad_4nxcfk4zmpwq-et7v9dapocc9zbf7nm-mukhnmf83ih4ce-kh30kcuds_7ubqjmnv4ncv_iwr2nzg_oandfg1f6jc_wqkgdpu7jxlp4iilaruergyu4polxvvk5gu8x65jnuckjfj6knyoh-yqf8gpn_inper.png)
Diese Grafik zeigt die endgültige Lösung, den besten gefundenen Weg, um jeden Knotenpunkt auf dem kürzesten Weg zu erreichen. Bei diesem Lauf wurde die beste Route gefunden: [4, 5, 17, 9, 11, 16, 13, 2, 7, 3, 6, 1, 14, 12, 18, 0, 10, 19, 15, 8, 4], mit einer Gesamtentfernung von 129.
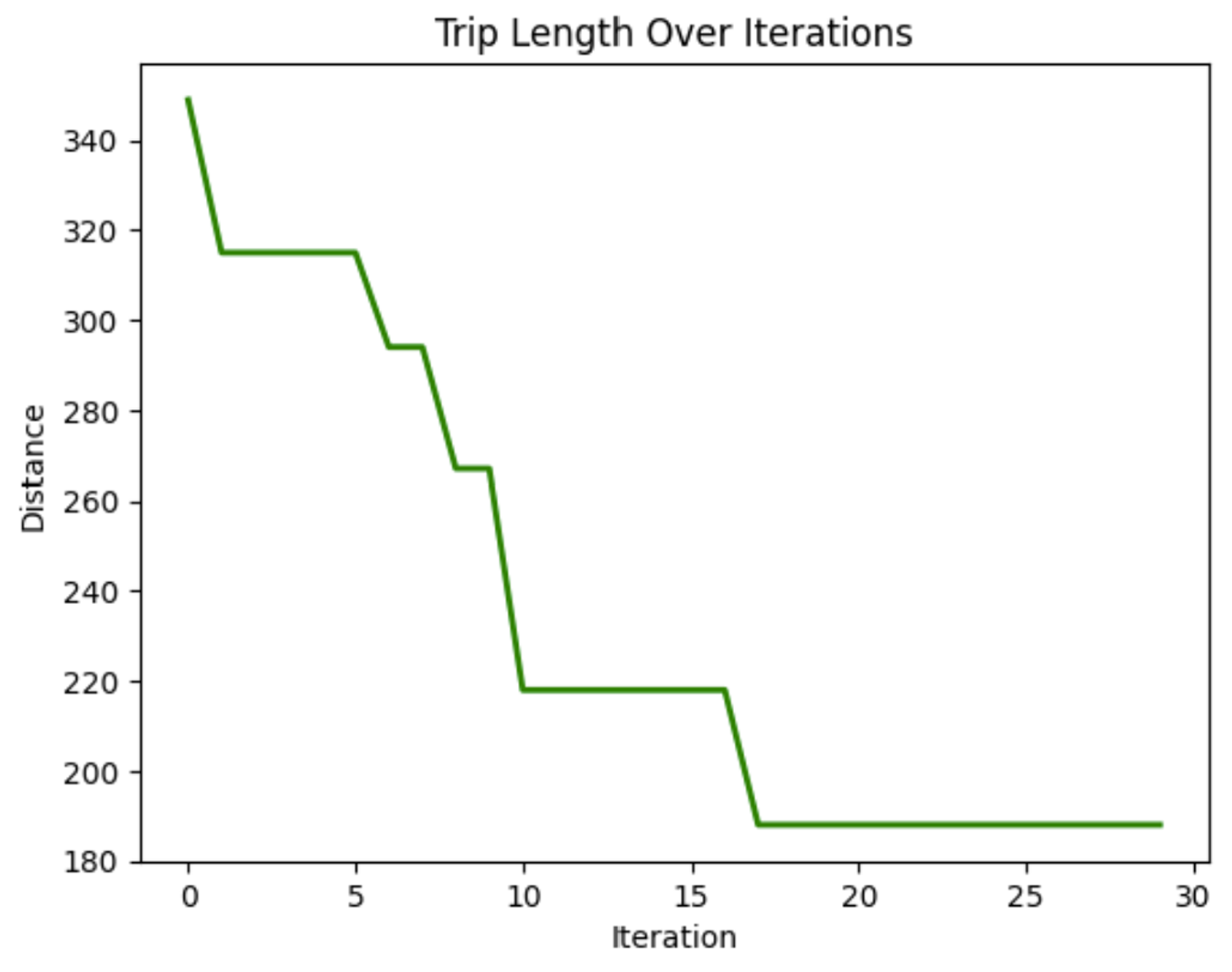
In diesem Diagramm können wir sehen, dass die zurückgelegte Strecke beim Durchqueren der Knoten im Laufe der Iterationen abnimmt. Das zeigt, dass das Modell die Fahrtdauer mit der Zeit verbessert.
Die Anpassungsfähigkeit und Effizienz von ACO machen es zu einem mächtigen Werkzeug in verschiedenen Branchen. Einige Anwendungen sind:
Die Stärke von ACO liegt in seiner Fähigkeit, sich weiterzuentwickeln und anzupassen. Dadurch eignet es sich für dynamische Umgebungen, in denen sich die Bedingungen ändern können, wie z.B. bei der Verkehrslenkung in Echtzeit oder der industriellen Planung.
Die Partikelschwarmoptimierung (PSO) orientiert sich am Verhalten von Vogelschwärmen und Fischschwärmen. In diesen natürlichen Systemen bewegen sich die Individuen auf der Grundlage ihrer eigenen früheren Erfahrungen und der Positionen ihrer Nachbarn und passen sich allmählich an, um den erfolgreichsten Mitgliedern der Gruppe zu folgen. PSO wendet dieses Konzept auf Optimierungsprobleme an, bei denen sich Partikel, sogenannte Agenten, durch den Suchraum bewegen, um eine optimale Lösung zu finden.
Im Vergleich zu ACO arbeitet PSO in kontinuierlichen und nicht in diskreten Räumen. Bei ACO liegt der Schwerpunkt auf der Pfadfindung und diskreten Entscheidungen, während PSO besser für Probleme mit kontinuierlichen Variablen geeignet ist, z. B. für die Parameterabstimmung.
Beim PSO erkunden die Partikel einen Suchraum. Sie passen ihre Position auf der Grundlage von zwei Faktoren an: ihre persönliche beste bekannte Position und die beste bekannte Position des gesamten Schwarms. Dieser doppelte Rückkopplungsmechanismus ermöglicht es ihnen, sich dem globalen Optimum anzunähern.
Der Prozess beginnt mit einem Schwarm von Partikeln, die nach dem Zufallsprinzip im Lösungsraum initialisiert werden. Jedes Partikel steht für eine mögliche Lösung des Optimierungsproblems. Während sich die Partikel bewegen, erinnern sie sich an ihre persönlich beste Position (die beste Lösung, die sie bisher gefunden haben) und werden von der global besten Position angezogen (die beste Lösung, die jedes Partikel gefunden hat).
Diese Bewegung wird von zwei Faktoren angetrieben: Ausbeutung und Erkundung. Bei der Ausbeutung wird die Suche um die aktuell beste Lösung herum verfeinert, während die Erkundung die Partikel dazu anregt, andere Teile des Lösungsraums zu durchsuchen, um zu vermeiden, dass sie in lokalen Optima stecken bleiben. Durch den Ausgleich dieser beiden Dynamiken konvergiert PSO effizient auf die beste Lösung.
Unter Finanzportfolio-Managementkann es schwierig sein, den besten Weg zu finden, um die besten Erträge zu erzielen und gleichzeitig die Risiken gering zu halten. Verwenden wir ein PSO, um herauszufinden, welche Mischung von Vermögenswerten uns die höchste Rendite bescheren wird.
Der folgende Code zeigt, wie PSO bei der Optimierung eines fiktiven Finanzportfolios funktioniert. Es beginnt mit einer zufälligen Vermögensaufteilung und optimiert diese dann in mehreren Iterationen auf der Grundlage der besten Ergebnisse, um nach und nach die optimale Mischung von Vermögenswerten für die höchste Rendite mit dem geringsten Risiko zu finden.
import numpy as np
import matplotlib.pyplot as plt
# Define the PSO parameters
class Particle:
def __init__(self, n_assets):
# Initialize a particle with random weights and velocities
self.position = np.random.rand(n_assets)
self.position /= np.sum(self.position) # Normalize weights so they sum to 1
self.velocity = np.random.rand(n_assets)
self.best_position = np.copy(self.position)
self.best_score = float('inf') # Start with a very high score
def objective_function(weights, returns, covariance):
"""
Calculate the portfolio's performance.
- weights: Asset weights in the portfolio.
- returns: Expected returns of the assets.
- covariance: Covariance matrix representing risk.
"""
portfolio_return = np.dot(weights, returns) # Calculate the portfolio return
portfolio_risk = np.sqrt(np.dot(weights.T, np.dot(covariance, weights))) # Calculate portfolio risk (standard deviation)
return -portfolio_return / portfolio_risk # We want to maximize return and minimize risk
def update_particles(particles, global_best_position, returns, covariance, w, c1, c2):
"""
Update the position and velocity of each particle.
- particles: List of particle objects.
- global_best_position: Best position found by all particles.
- returns: Expected returns of the assets.
- covariance: Covariance matrix representing risk.
- w: Inertia weight to control particle's previous velocity effect.
- c1: Cognitive coefficient to pull particles towards their own best position.
- c2: Social coefficient to pull particles towards the global best position.
"""
for particle in particles:
# Random coefficients for velocity update
r1, r2 = np.random.rand(len(particle.position)), np.random.rand(len(particle.position))
# Update velocity
particle.velocity = (w * particle.velocity +
c1 * r1 * (particle.best_position - particle.position) +
c2 * r2 * (global_best_position - particle.position))
# Update position
particle.position += particle.velocity
particle.position = np.clip(particle.position, 0, 1) # Ensure weights are between 0 and 1
particle.position /= np.sum(particle.position) # Normalize weights to sum to 1
# Evaluate the new position
score = objective_function(particle.position, returns, covariance)
if score < particle.best_score:
# Update the particle's best known position and score
particle.best_position = np.copy(particle.position)
particle.best_score = score
def pso_portfolio_optimization(n_particles, n_iterations, returns, covariance):
"""
Perform Particle Swarm Optimization to find the optimal asset weights.
- n_particles: Number of particles in the swarm.
- n_iterations: Number of iterations for the optimization.
- returns: Expected returns of the assets.
- covariance: Covariance matrix representing risk.
"""
# Initialize particles
particles = [Particle(len(returns)) for _ in range(n_particles)]
# Initialize global best position
global_best_position = np.random.rand(len(returns))
global_best_position /= np.sum(global_best_position)
global_best_score = float('inf')
# PSO parameters
w = 0.5 # Inertia weight: how much particles are influenced by their own direction
c1 = 1.5 # Cognitive coefficient: how well particles learn from their own best solutions
c2 = 0.5 # Social coefficient: how well particles learn from global best solutions
history = [] # To store the best score at each iteration
for _ in range(n_iterations):
update_particles(particles, global_best_position, returns, covariance, w, c1, c2)
for particle in particles:
score = objective_function(particle.position, returns, covariance)
if score < global_best_score:
# Update the global best position and score
global_best_position = np.copy(particle.position)
global_best_score = score
# Store the best score (negative return/risk ratio) for plotting
history.append(-global_best_score)
return global_best_position, history
# Example data for 3 assets
returns = np.array([0.02, 0.28, 0.15]) # Expected returns for each asset
covariance = np.array([[0.1, 0.02, 0.03], # Covariance matrix for asset risks
[0.02, 0.08, 0.04],
[0.03, 0.04, 0.07]])
# Run the PSO algorithm
n_particles = 10 # Number of particles
n_iterations = 10 # Number of iterations
best_weights, optimization_history = pso_portfolio_optimization(n_particles, n_iterations, returns, covariance)
# Plotting the optimization process
plt.figure(figsize=(12, 6))
plt.plot(optimization_history, marker='o')
plt.title('Portfolio Optimization Using PSO')
plt.xlabel('Iteration')
plt.ylabel('Objective Function Value (Negative of Return/Risk Ratio)')
plt.grid(False) # Turn off gridlines
plt.show()
# Display the optimal asset weights
print(f"Optimal Asset Weights: {best_weights}")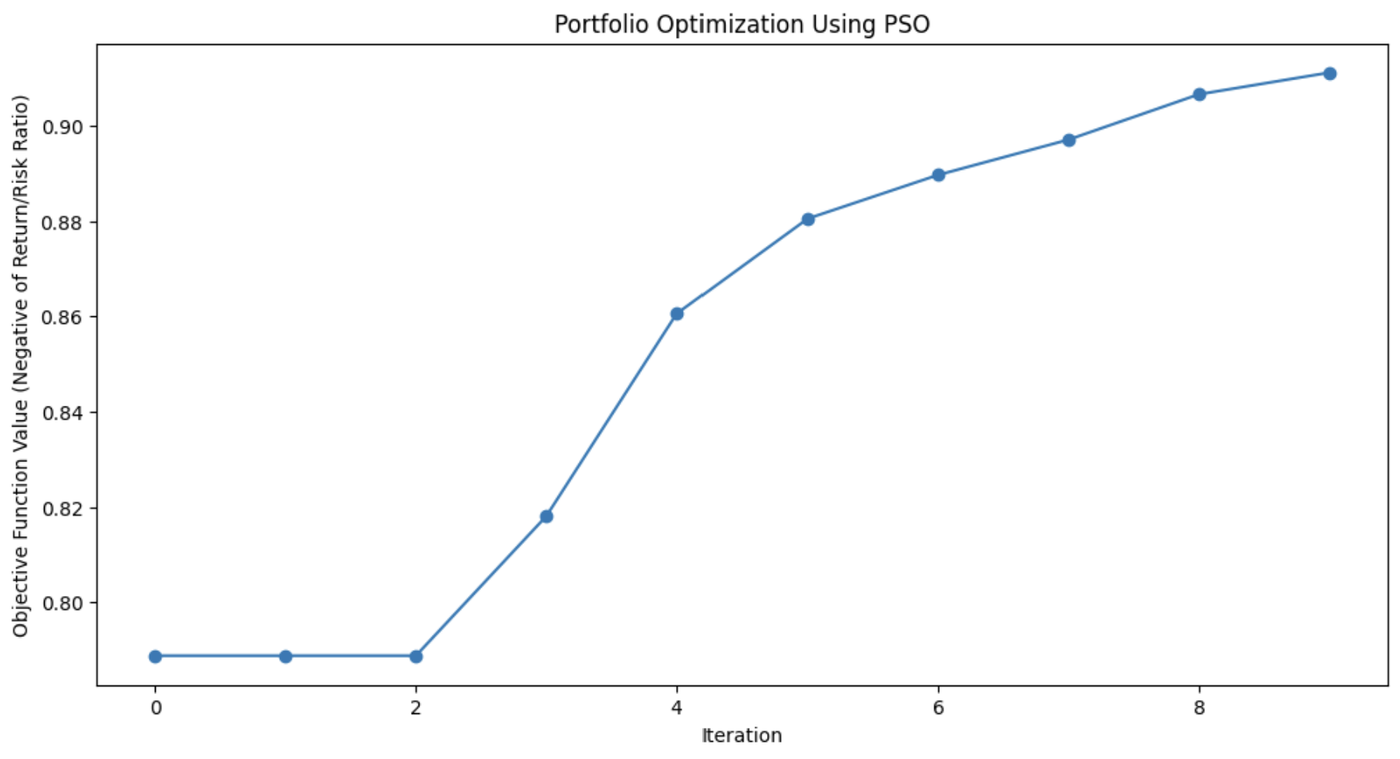
Diese Grafik zeigt, wie sehr der PSO-Algorithmus die Mischung der Vermögenswerte des Portfolios mit jeder Iteration verbessert hat.
PSO wird wegen seiner Einfachheit und Effektivität bei der Lösung verschiedener Optimierungsprobleme eingesetzt, insbesondere in kontinuierlichen Bereichen. Seine Flexibilität macht es für viele reale Szenarien nützlich, in denen präzise Lösungen benötigt werden.
Zu diesen Anwendungen gehören:
Die Fähigkeit von PSO, Lösungsräume effizient zu erkunden, macht es in allen Bereichen anwendbar, von der Robotik über das Energiemanagement bis hin zur Logistik.
Der ABC-Algorithmus (Artificial Bee Colony) ist dem Futtersuchverhalten von Honigbienen nachempfunden.
In der Natur suchen Honigbienen effizient nach Nektarquellen und teilen diese Informationen mit den anderen Mitgliedern des Bienenstocks. ABC fängt diesen kollaborativen Suchprozess ein und wendet ihn auf Optimierungsprobleme an, insbesondere auf solche, die komplexe, hochdimensionale Räume betreffen.
Was ABC von anderen Schwarmintelligenz-Algorithmen unterscheidet, ist seine Fähigkeit, ein Gleichgewicht zwischen Ausbeutung, d.h. der Verfeinerung aktueller Lösungen, und Erkundung, d.h. der Suche nach neuen und potenziell besseren Lösungen, herzustellen. Das macht ABC besonders nützlich für große Probleme, bei denen es auf globale Optimierung ankommt.
Beim ABC-Algorithmus wird der Bienenschwarm in drei spezialisierte Rollen aufgeteilt: Beschäftigte Bienen, Aufpasserinnen und Kundschafterinnen. Jede dieser Rollen ahmt einen anderen Aspekt der Nahrungssuche und -nutzung von Bienen in der Natur nach.
Diese Dynamik ermöglicht es ABC, die Suche zwischen der intensiven Erkundung vielversprechender Bereiche und der breit angelegten Erkundung neuer Bereiche des Suchraums auszubalancieren. So vermeidet der Algorithmus, dass er sich in lokalen Optima verfängt, und erhöht seine Chancen, ein globales Optimum zu finden.
Die Rastrigin-Funktion ist ein beliebtes Optimierungsproblem, das für seine zahlreichen lokalen Minima bekannt ist, was es für viele Algorithmen zu einer schwierigen Herausforderung macht. Das Ziel ist einfach: das globale Minimum zu finden.
In diesem Beispiel verwenden wir den Algorithmus der künstlichen Bienenkolonie, um dieses Problem zu lösen. Jede Biene im ABC-Algorithmus erkundet den Suchraum und sucht nach besseren Lösungen, um die Funktion zu minimieren. Der Code simuliert Bienen, die neue Gebiete erkunden, ausbeuten und auskundschaften, um ein Gleichgewicht zwischen Erkundung und Ausbeutung zu gewährleisten.
import numpy as np
import matplotlib.pyplot as plt
# Rastrigin function: The objective is to minimize this function
def rastrigin(X):
A = 10
return A * len(X) + sum([(x ** 2 - A * np.cos(2 * np.pi * x)) for x in X])
# Artificial Bee Colony (ABC) algorithm for continuous optimization of Rastrigin function
def artificial_bee_colony_rastrigin(n_iter=100, n_bees=30, dim=2, bound=(-5.12, 5.12)):
"""
Apply Artificial Bee Colony (ABC) algorithm to minimize the Rastrigin function.
Parameters:
n_iter (int): Number of iterations
n_bees (int): Number of bees in the population
dim (int): Number of dimensions (variables)
bound (tuple): Bounds for the search space (min, max)
Returns:
tuple: Best solution found, best fitness value, and list of best fitness values per iteration
"""
# Initialize the bee population with random solutions within the given bounds
bees = np.random.uniform(bound[0], bound[1], (n_bees, dim))
best_bee = bees[0]
best_fitness = rastrigin(best_bee)
best_fitnesses = []
for iteration in range(n_iter):
# Employed bees phase: Explore new solutions based on the current bees
for i in range(n_bees):
# Generate a new candidate solution by perturbing the current bee's position
new_bee = bees[i] + np.random.uniform(-1, 1, dim)
new_bee = np.clip(new_bee, bound[0], bound[1]) # Keep within bounds
# Evaluate the fitness of the new solution
new_fitness = rastrigin(new_bee)
if new_fitness < rastrigin(bees[i]):
bees[i] = new_bee # Update bee if the new solution is better
# Onlooker bees phase: Exploit good solutions
fitnesses = np.array([rastrigin(bee) for bee in bees])
probabilities = 1 / (1 + fitnesses) # Higher fitness gets higher chance
probabilities /= probabilities.sum() # Normalize probabilities
for i in range(n_bees):
if np.random.rand() < probabilities[i]:
selected_bee = bees[i]
# Generate a new candidate solution by perturbing the selected bee
new_bee = selected_bee + np.random.uniform(-0.5, 0.5, dim)
new_bee = np.clip(new_bee, bound[0], bound[1])
if rastrigin(new_bee) < rastrigin(selected_bee):
bees[i] = new_bee
# Scouting phase: Randomly reinitialize some bees to explore new areas
if np.random.rand() < 0.1: # 10% chance to reinitialize a bee
scout_index = np.random.randint(n_bees)
bees[scout_index] = np.random.uniform(bound[0], bound[1], dim)
# Track the best solution found so far
current_best_bee = bees[np.argmin(fitnesses)]
current_best_fitness = min(fitnesses)
if current_best_fitness < best_fitness:
best_fitness = current_best_fitness
best_bee = current_best_bee
best_fitnesses.append(best_fitness)
return best_bee, best_fitness, best_fitnesses
# Apply ABC to minimize the Rastrigin function
best_solution, best_fitness, best_fitnesses = artificial_bee_colony_rastrigin()
# Display results
print("Best Solution (x, y):", best_solution)
print("Best Fitness (Minimum Value):", best_fitness)
# Plot the performance over iterations
plt.figure()
plt.plot(best_fitnesses)
plt.title('Performance of ABC on Rastrigin Function Optimization')
plt.xlabel('Iterations')
plt.ylabel('Best Fitness (Lower is Better)')
plt.grid(True)
plt.show()
# Plot a surface graph of the Rastrigin function
x = np.linspace(-5.12, 5.12, 200)
y = np.linspace(-5.12, 5.12, 200)
X, Y = np.meshgrid(x, y)
Z = 10 * 2 + (X ** 2 - 10 * np.cos(2 * np.pi * X)) + (Y ** 2 - 10 * np.cos(2 * np.pi * Y))
plt.figure(figsize=(8, 6))
plt.contourf(X, Y, Z, levels=50, cmap='viridis')
plt.colorbar(label='Function Value')
plt.scatter(best_solution[0], best_solution[1], c='red', label='Best Solution')
plt.title('Rastrigin Function Optimization with ABC')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()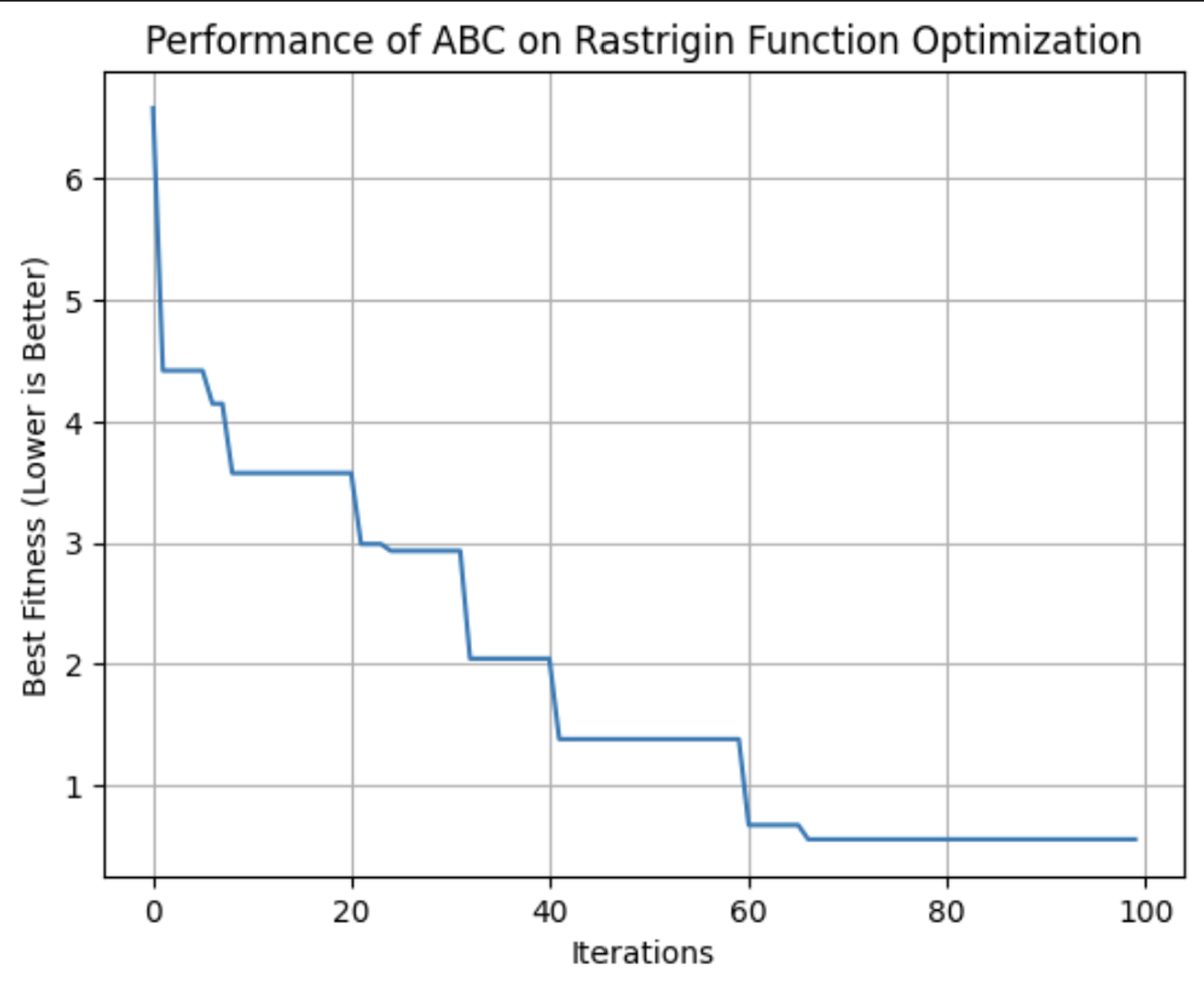
Diese Grafik zeigt die Fitness der besten Lösung, die der ABC-Algorithmus mit jeder Iteration gefunden hat. In diesem Lauf erreichte er seine optimale Fitness etwa bei der 64. Iteration.
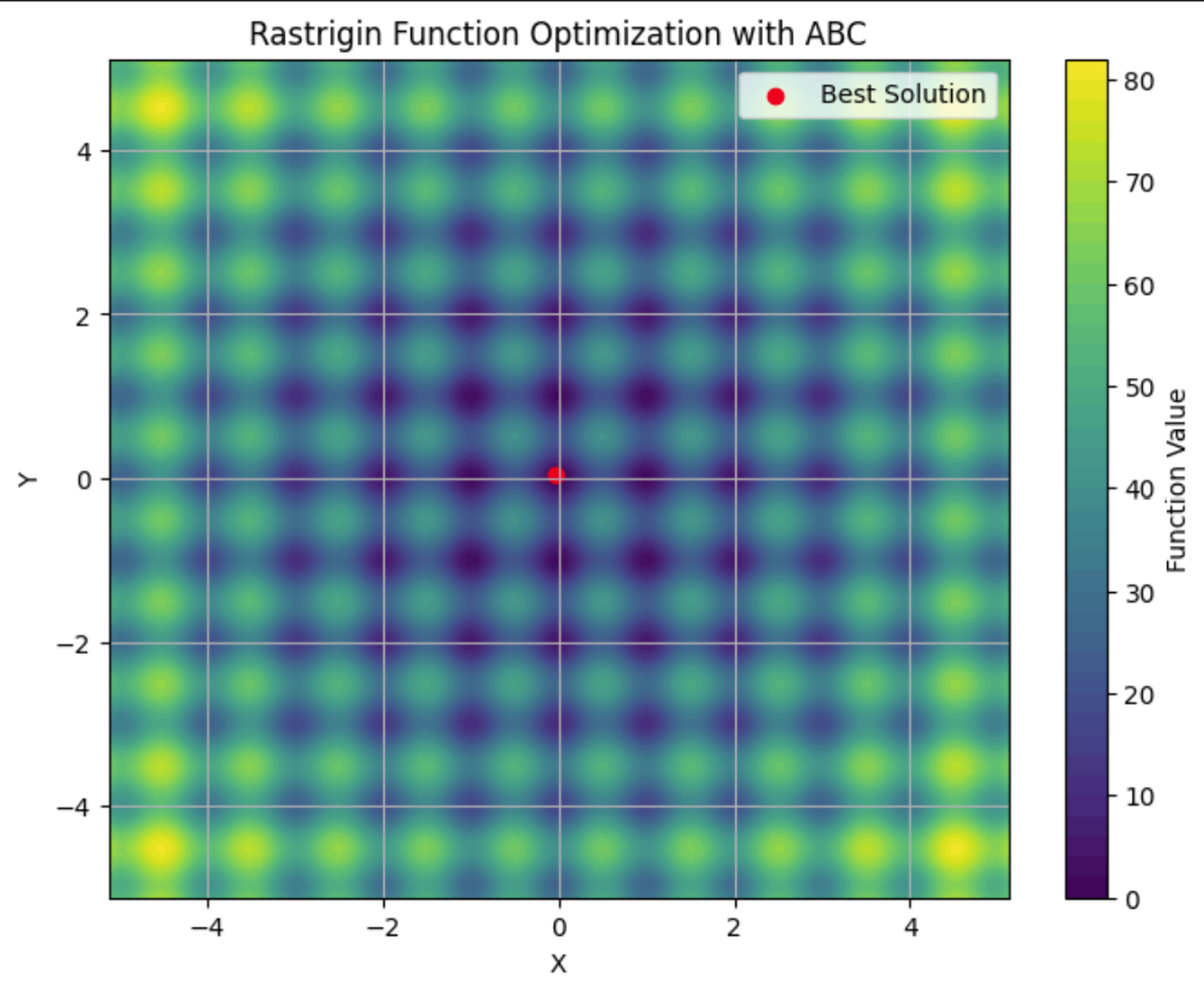
Hier siehst du die Rastrigin-Funktion in einem Konturdiagramm mit ihren vielen lokalen Minima. Der rote Punkt ist das globale Minimum, das wir mit dem ABC-Algorithmus gefunden haben.
Der ABC-Algorithmus ist ein robustes Werkzeug zur Lösung von Optimierungsproblemen. Seine Fähigkeit, große und komplexe Suchräume effizient zu durchsuchen, macht ihn zur ersten Wahl für Branchen, in denen Anpassungsfähigkeit und Skalierbarkeit entscheidend sind.
Zu diesen Anwendungen gehören:
ABC ist ein flexibler Algorithmus, der sich für jedes Problem eignet, bei dem optimale Lösungen in dynamischen, hochdimensionalen Umgebungen gefunden werden müssen. Aufgrund seiner dezentralen Natur eignet er sich gut für Situationen, in denen andere Algorithmen Schwierigkeiten haben, Erkundung und Ausbeutung effizient auszubalancieren.
Es gibt mehrere Schwarmintelligenz-Algorithmen, die jeweils unterschiedliche Eigenschaften haben. Wenn du dich für eine Lösung entscheidest, ist es wichtig, ihre Stärken und Schwächen abzuwägen, um zu entscheiden, welche deinen Bedürfnissen am besten entspricht.
ACO ist effektiv für kombinatorische Probleme wie Routing und Scheduling, kann aber erhebliche Rechenressourcen erfordern. PSO ist einfacher und eignet sich hervorragend für die kontinuierliche Optimierung, z. B. die Abstimmung von Hyperparametern, hat aber Probleme mit lokalen Optimierungen. ABC hält erfolgreich die Balance zwischen Erkundung und Ausbeutung, obwohl es eine sorgfältige Abstimmung erfordert.
Andere Algorithmen der Schwarmintelligenz, wie z.B. Firefly-Algorithmus und Kuckuckssuch-Optimierungbieten ebenfalls einzigartige Vorteile für bestimmte Arten von Optimierungsproblemen .
|
Algorithmus |
Stärken |
Schwachstellen |
Bevorzugte Bibliotheken |
Beste Anwendungen |
|
Ameisenkolonie-Optimierung (ACO) |
Effektiv für kombinatorische Probleme und gut geeignet für komplexe diskrete Räume |
Ist rechenintensiv und erfordert Feinabstimmung |
Routing-Probleme, Terminplanung und Ressourcenzuweisung |
|
|
Partikelschwarm-Optimierung (PSO) |
Gut für kontinuierliche Optimierung und einfach und leicht zu implementieren |
Kann zu lokalen Optima konvergieren und ist weniger effektiv für diskrete Probleme |
Abstimmung von Hyperparametern, technische Planung, Finanzmodellierung |
|
|
Künstliches Bienenvolk (ABC) |
Anpassungsfähig an große, dynamische Probleme und ausgewogene Erkundung und Ausbeutung |
Ist rechenintensiv und erfordert eine sorgfältige Abstimmung der Parameter |
Telekommunikation, groß angelegte Optimierung und hochdimensionale Räume |
|
|
Firefly-Algorithmus (FA) |
Hervorragend in multimodaler Optimierung und mit starker globaler Suchfähigkeit |
Empfindlich gegenüber Parametereinstellungen und langsamere Konvergenz |
Bildverarbeitung, technisches Design und multimodale Optimierung |
|
|
Kuckuckssuche (CS) |
Effiziente Lösung von Optimierungsproblemen und starke Explorationsfähigkeiten |
Kann vorzeitig konvergieren und die Leistung hängt von der Abstimmung ab |
Terminplanung, Auswahl von Merkmalen und technische Anwendungen |
Algorithmen der Schwarmintelligenz sind wie viele maschinelle Lernverfahren mit Herausforderungen konfrontiert, die ihre Leistung beeinträchtigen können. Dazu gehören:
Ein bemerkenswerter Trend ist die Integration von Schwarmintelligenz mit anderen maschinellen Lernverfahren. Die Forscher erforschen, wie Schwarmalgorithmen Aufgaben wie die Merkmalsauswahl und Hyperparameter-Optimierung. Check out Ein hybrider Partikelschwarm-Optimierungsalgorithmus zur Lösung von Ingenieurproblemen.
Jüngste Fortschritte konzentrieren sich auch auf die Bewältigung einiger traditioneller Herausforderungen, die mit Schwarmintelligenz verbunden sind, wie z.B. die vorzeitige Konvergenz. Es werden neue Algorithmen und Techniken entwickelt, um das Risiko der Konvergenz zu suboptimalen Lösungen zu mindern. Weitere Informationen findest du unter Speicherbasierte Ansätze zur Vermeidung von vorzeitiger Konvergenz in der Partikelschwarmoptimierung
Die Skalierbarkeit ist ein weiterer wichtiger Bereich der Forschung. Da die Probleme immer komplexer und die Datenmengen immer größer werden, arbeiten Forscher daran, die Algorithmen der Schwarmintelligenz skalierbarer und effizienter zu machen. Dazu gehört die Entwicklung von Algorithmen, die große Datensätze und hochdimensionale Räume effektiver verarbeiten können, und die Optimierung von Rechenressourcen, um die Zeit und die Kosten für die Ausführung dieser Algorithmen zu reduzieren. Mehr zu diesem Thema findest du unter Jüngste Entwicklungen in der Theorie und Anwendbarkeit der Schwarmsuche.
Schwarmalgorithmen werden auf Probleme aus der Robotikbis hin zu großen Sprachmodellen (LLMs), zur medizinischen Diagnose. Es gibt laufende Forschung ob diese Algorithmen nützlich sein können, um LLMs dabei zu helfen, Informationen strategisch zu vergessen, um die Bestimmungen desRechts auf Vergessenwerden einzuhalten . Und natürlich haben Schwarmalgorithmen eine Vielzahl von Anwendungen in der Datenwissenschaft.
Schwarmintelligenz bietet leistungsstarke Lösungen für Optimierungsprobleme in verschiedenen Branchen. Seine Prinzipien der Dezentralisierung, der positiven Rückkopplung und der Anpassung ermöglichen es ihm, komplexe, dynamische Aufgaben zu bewältigen, mit denen herkömmliche Algorithmen Probleme haben könnten.
Schau dir diesen Überblick über den aktuellen Stand der Schwarmalgorithmen an, "Schwarmintelligenz: Ein Überblick über Modellklassifizierung und Anwendungen".
Einen tieferen Einblick in die Geschäftsanwendungen von KI findest du in Strategie für künstliche Intelligenz (KI) oder Künstliche Intelligenz für Führungskräfte in der Wirtschaft. Mehr über andere Algorithmen, die die Natur nachahmen, erfährst du unter Genetischer Algorithmus: Vollständiger Leitfaden mit Python-Implementierung.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
