
Kurs
Databricks-Konzepte
4 Std.
22.1K
Databricks APIs ermöglichen die programmatische Interaktion mit Databricks, sodass Nutzer Workflows automatisieren, Cluster verwalten, Jobs ausführen und auf Daten zugreifen können. Diese APIs unterstützen die Authentifizierung über persönliche Zugangstoken, OAuth oder Azure Active Directory.
In diesem Artikel führe ich dich durch eine ausführliche, praktische Reise durch die Databricks REST API. Egal, ob du neu bei Databricks bist oder deine bestehenden Arbeitsabläufe optimieren willst, dieser Leitfaden hilft dir, die wichtigsten Vorgänge wie Authentifizierung, Jobmanagement und Integration mit externen Systemen zu meistern.
Am Ende dieses Artikels wirst du einen klaren Plan haben, wie du vorgehen kannst:
Wenn du ganz neu bei Databricks bist und dich schnell einarbeiten willst, lies unseren Blogbeitrag Wie man Databricks lernt: A Beginner's Guide to the Unified Data Platform, der dir hilft, die Kernfunktionen und Anwendungen von Databricks zu verstehen, und dir einen strukturierten Weg bietet, mit dem Lernen zu beginnen.
Die Databricks REST API bietet Entwicklern und Dateningenieuren leistungsstarke Funktionen, mit denen sie Ressourcen programmatisch verwalten und Arbeitsabläufe rationalisieren können. Hier erfährst du, wie die Databricks-API einen großen Unterschied machen kann:
Die Databricks-API ermöglicht es Nutzern, Aufgaben wie die Auftragsplanung und das Cluster-Management zu automatisieren. Dadurch verringert sich der manuelle Aufwand für die Verwaltung dieser Prozesse und es bleibt mehr Zeit für strategische Aktivitäten. Durch die Automatisierung sich wiederholender Aufgaben können Unternehmen ihre Effizienz steigern und die Wahrscheinlichkeit menschlicher Fehler verringern, die zu kostspieligen Fehlern oder Ausfallzeiten führen können.
Die Databricks-API ist auf Flexibilität ausgelegt und ermöglicht die Integration mit externen Plattformen wie Orchestrierungstools wie Apache Airflow oder Azure Data Factory.
Du kannst Databricks API auch für Überwachungs- und Alarmsysteme wie Prometheus oder Datadog nutzen. Databricks API wird auch in Daten-Ingestion-Pipelines von Tools wie Kafka oder RESTful-Datendiensten verwendet. Diese Integrationen helfen dabei, End-to-End-Workflows zu erstellen, die Daten-Engineering und -Analysen über mehrere Systeme hinweg verbinden.
Die Databricks-API unterstützt die Erstellung und Verwaltung von Tausenden von automatisierten Pipelines. Sie lässt sich mühelos skalieren, um Tausende von Jobs parallel zu verwalten und den Cluster je nach Bedarf dynamisch zu skalieren. Diese Skalierbarkeit stellt sicher, dass sich deine Infrastruktur nahtlos an die geschäftlichen Anforderungen anpasst, selbst im Unternehmensmaßstab.
Die Databricks REST-API bietet eine Vielzahl von Operationen zur Verwaltung von Jobs, Clustern, Dateien und Zugriffsberechtigungen. Im Folgenden werde ich die wichtigsten API-Vorgänge mit praktischen Beispielen erläutern, die dir helfen, robuste Arbeitsabläufe zu erstellen und zu automatisieren.
Jobs sind das Rückgrat der automatisierten Workflows in Databricks. Mit der API kannst du nahtlos Aufträge erstellen, verwalten und überwachen.
Verwende den Endpunkt POST /API/2.1/jobs/create, um einen neuen Auftrag zu definieren. Der folgende JSON-Payload erstellt zum Beispiel einen neuen Databricks-Job mit dem Namen My Job und führt ein Notebook unter /path/to/notebook aus. Die Nutzlast verwendet dann ein bestehendes Cluster mit der ID cluster-id, sodass kein neues Cluster erstellt werden muss. Wenn der Auftrag fehlschlägt, sendet die Nutzlast eine E-Mail-Benachrichtigung an user@example.com.
{
"name": "My Job",
"existing_cluster_id": "cluster-id",
"notebook_task": {
"notebook_path": "/path/to/notebook"
},
"email_notifications": {
"on_failure": ["user@example.com"]
}
}Du kannst den Endpunkt GET /api/2.1/jobs/list verwenden, um eine Liste aller Jobs in deinem Arbeitsbereich abzurufen. Der folgende Beispielbefehl listet zum Beispiel alle Aufträge auf:
curl -n -X GET \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/listVerwende den Endpunkt POST /api/2.1/jobs/run-now, um einen sofortigen Lauf eines Jobs auszulösen.
curl -n -X POST \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/run-now?job_id=123456789Die neueste API-Version verfügt zwar nicht über einen direkten Endpunkt zum Löschen von Aufträgen, aber du kannst Auftragsläufe und ihren Lebenszyklus über andere Endpunkte verwalten. Verwende den Endpunkt Delete a Job: POST /api/2.1/jobs/delete, um einen Job zu löschen, und POST /api/2.1/jobs/runs/cancel, um einen Lauf abzubrechen.
Verwende GET /api/2.1/jobs/runs/get, um den Status eines Auftrags zu überwachen. Rufe Protokolle ab oder behandle Fehler über das Feld run_state.
Cluster stellen die Rechenressourcen für die Ausführung von Aufträgen bereit. Die API vereinfacht die Verwaltung des Lebenszyklus von Clustern.
Erstelle einen Cluster mit POST /api/2.1/clusters/create. Du kannst z.B. folgendes in den Request Body schreiben.
{
"cluster_name": "Example Cluster",
"spark_version": "12.2.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 4
}Führe dann den unten stehenden Beispielbefehl aus, um diesen Cluster zu erstellen.
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"cluster_name": "My Cluster", "spark_version": "7.3.x-scala2.12", "node_type_id": "i3.xlarge", "num_workers": 2}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/clusters/createVerwende die folgenden APIs, um:
Start Cluster: POST /api/2.1/clusters/start
Cluster neu starten: POST /api/2.1/clusters/restart
Größe des Clusters ändern: PATCH /api/2.1/clusters/edit
Beende den Cluster: POST /api/2.1/clusters/delete
Beachte die folgenden Best Practices für:
DBFS ermöglicht das Speichern und Abrufen von Dateien in Databricks.
Du kannst die API POST /api/2.1/dbfs/upload verwenden, um Dateien in Stücken (Multipart) oder bei großen Dateien (>1MB) in das DBFS hochzuladen. Die GET /api/2.1/dbfs/read API wird zum Herunterladen von Dateien verwendet.
Verwende GET /api/2.1/dbfs/list, um Verzeichnisse zu erkunden und Dateien programmatisch zu verwalten. Für große Datei-Uploads verwende Chunked Uploads mit POST /api/2.1/dbfs/put und dem Parameter overwrite.
Die Secrets API gewährleistet die sichere Speicherung und den Abruf sensibler Informationen.
Verwende den Endpunkt POST /api/2.1/secrets/create, um ein neues Geheimnis für die Speicherung sensibler Informationen zu erstellen.
Du kannst den Request Body zum Beispiel wie folgt in JSON erstellen:
{
"scope": "my-scope",
"key": "my-key",
"string_value": "my-secret-value"
}Dann erstellst du das Geheimnis mit dem folgenden Befehl:
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"scope": "my-scope", "key": "my-key", "string_value": "my-secret-value"}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/secrets/createVerwende den Endpunkt GET /API/2.1/secrets/get, um Geheimnisse für externe Integrationen abzurufen.
Die Databricks-Plattform ermöglicht eine granulare Kontrolle über den Zugang zu Jobs und Ressourcen.
Verwende den Endpunkt POST /api/2.1/permissions/jobs/update, um Rollen wie Eigentümer oder Betrachter zuzuweisen. Der folgende Payload wird zum Beispiel zum Aktualisieren von Berechtigungen verwendet:
{
"access_control_list": [
{
"user_name": "user@example.com",
"permission_level": "CAN_MANAGE"
}
]
}Verwende die integrierte rollenbasierte Zugriffskontrolle (RBAC) von Databricks, um die Berechtigungen für verschiedene Rollen in deinem Unternehmen zu verwalten.
Wenn du mit der Databricks REST-API arbeitest, ist es wichtig, die Ratenbeschränkungen zu berücksichtigen, Fehler elegant zu behandeln und häufige Probleme zu lösen, um eine zuverlässige Leistung und einen reibungslosen Betrieb zu gewährleisten. In diesem Abschnitt gehe ich auf die Strategien zur Optimierung der API-Nutzung und zur effektiven Fehlerbehebung ein.
Die Databricks-API setzt Ratenlimits durch, um eine faire Nutzung zu gewährleisten und die Zuverlässigkeit des Dienstes zu erhalten.
Im Folgenden findest du die häufigsten Probleme, die mit Databricks APIs auftreten können, und wie du sie lösen kannst.
Wenn du auf Leistungsengpässe stößt, solltest du die folgenden Lösungen in Betracht ziehen:
Die REST-API von Databricks ist äußerst vielseitig und unterstützt sowohl einfache Single-Thread-Workflows als auch komplexe Parallelverarbeitung. Durch den Einsatz fortschrittlicher Workflows kannst du die Effizienz optimieren und nahtlos mit externen Systemen zusammenarbeiten. Schauen wir uns an, wie man diese Funktionen implementiert.
Als Hinweis: Konfiguriere deine Umgebungsvariablen immer mit:
DATABRICKS_HOST: Diese Variable speichert die URL deiner Databricks-Instanz, die für die Erstellung von API-Anfragen benötigt wird.
DATABRICKS_TOKEN: Diese Variable enthält dein Access Token, was die Einbindung in API-Aufrufe vereinfacht.
Der sequentielle Aufruf eines einzelnen API-Endpunkts ist effektiv für kleinere Aufgaben oder einfache Automatisierung. Im Folgenden findest du ein praktisches Beispiel für die Verwendung der Request-Bibliothek in Python.
import requests
import os
# Set up environment variables
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
# API request to list jobs
url = f"{DATABRICKS_HOST}/api/2.1/jobs/list"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
jobs = response.json().get("jobs", [])
for job in jobs:
print(f"Job ID: {job['job_id']}, Name: {job['settings']['name']}")
else:
print(f"Error: {response.status_code} - {response.text}")Die parallele Verarbeitung kann die Effizienz bei der Aufnahme größerer Datenmengen oder beim Umgang mit mehreren Endpunkten erheblich verbessern. Das folgende Beispiel zeigt, wie du Apache Spark nutzt, um API-Aufrufe gleichzeitig zu verteilen.
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
import requests
# Initialize Spark session
spark = SparkSession.builder.appName("ParallelAPI").getOrCreate()
# Sample data for parallel calls
data = [{"job_id": 123}, {"job_id": 456}, {"job_id": 789}]
df = spark.createDataFrame(data)
# Define API call function
def fetch_job_details(job_id):
url = f"{DATABRICKS_HOST}/api/2.1/jobs/get"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers, params={"job_id": job_id})
if response.status_code == 200:
return response.json().get("settings", {}).get("name", "Unknown")
return f"Error: {response.status_code}"
# Register UDF
fetch_job_details_udf = udf(fetch_job_details)
# Apply UDF to DataFrame
results_df = df.withColumn("job_name", fetch_job_details_udf("job_id"))
results_df.show()Beachte die folgenden Tipps für den Kompromiss zwischen Skalierbarkeit und Kosten.
Die Integration von Databricks mit externen Orchestrierern wie Airflow oder Dagster ermöglicht es dir, komplexe Workflows zu verwalten und die Jobausführung über verschiedene Systeme hinweg zu automatisieren. Das folgende Beispiel zeigt, wie du Airflow nutzt, um einen Databricks-Job auszulösen.
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator
from datetime import datetime
# Define default arguments for the DAG
default_args = {
"owner": "airflow", # Owner of the DAG
"depends_on_past": False, # Do not depend on past DAG runs
"retries": 1, # Number of retry attempts in case of failure
}
# Define the DAG
with DAG(
dag_id="databricks_job_trigger", # Unique DAG ID
default_args=default_args, # Apply default arguments
schedule_interval=None, # Manually triggered DAG (no schedule)
start_date=datetime(2023, 1, 1), # DAG start date
) as dag:
# Task to trigger a Databricks job
run_job = DatabricksRunNowOperator(
task_id="run_databricks_job", # Unique task ID
databricks_conn_id="databricks_default", # Connection ID for Databricks
job_id=12345, # Replace with the actual Databricks job ID
)
# Set task dependencies (if needed)
run_jobFür CI/CD-Pipelines können Tools wie die Git-Integration mit Databricks die Bereitstellung von Code und Assets in verschiedenen Umgebungen automatisieren. So wird sichergestellt, dass Änderungen getestet und validiert werden, bevor sie in die Produktion einfließen.
# Example of using Databricks REST API in a CI/CD pipeline
import requests
def deploy_to_production():
# Assuming you have a personal access token
token = "your_token_here"
headers = {"Authorization": f"Bearer {token}"}
# Update job or cluster configurations as needed
url = "https://your-databricks-instance.cloud.databricks.com/api/2.1/jobs/update"
payload = {"job_id": "123456789", "new_settings": {"key": "value"}}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
print("Deployment successful.")
else:
print(f"Deployment failed. Status code: {response.status_code}")Nachdem wir nun die verschiedenen Anwendungen von Databricks API kennengelernt haben, möchte ich dir ein Beispiel für eine automatisierte Pipeline zeigen. Diese Pipeline nimmt Daten von einer externen API auf, wandelt die Daten in Databricks um und schreibt die Ergebnisse dann in eine Databricks Tabelle. Dieses Szenario ist ein typischer End-to-End-Workflow für moderne Data Engineering-Aufgaben. Wenn du dein Wissen über die wichtigsten Funktionen von Databricks, einschließlich der Dateneingabe, auffrischen möchtest, empfehle ich dir unser Tutorial über die 7 wichtigsten Konzepte für jeden Datenspezialisten.
Um mit der Databricks REST API zu interagieren, musst du dich mit einem Personal Access Token (PAT) authentifizieren. Befolge diese Schritte, um den PAT zu erstellen.
Databricks Arbeitsbereich. Bild vom Autor.
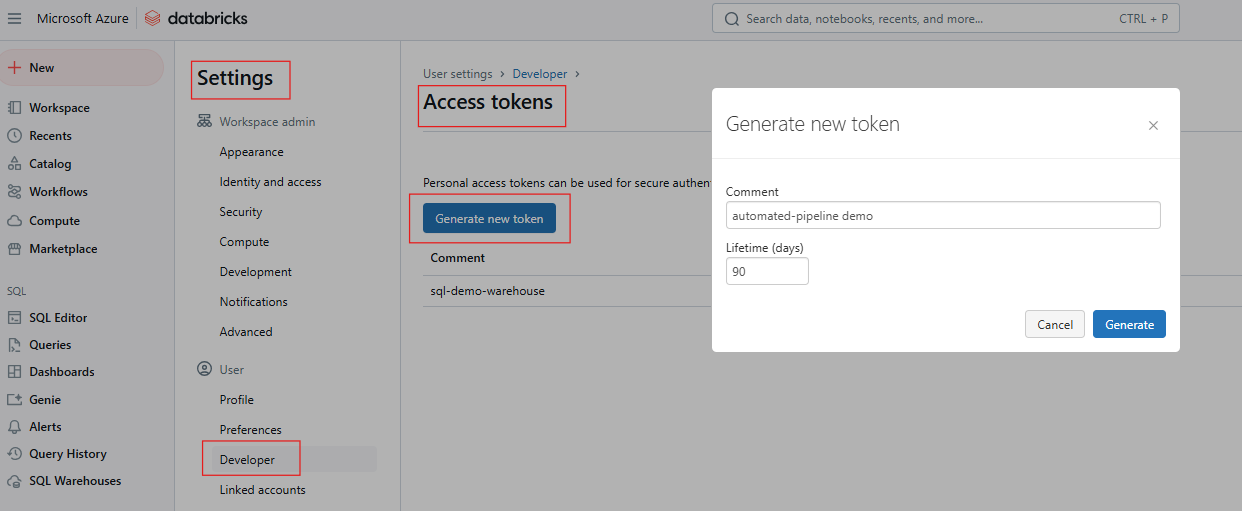
Erzeugen von Zugriffstoken in Databricks. Bild vom Autor.
Wenn du dein Wissen über Databricks SQL auffrischen musst, empfehle ich dir, unser Databricks SQL-Tutorial zu lesen, um zu erfahren, wie du das SQL Warehouse über die Databricks-Weboberfläche einrichtest.
Richte die Umgebungsvariablen auf eine der folgenden Arten ein:
export DATABRICKS_HOST=https://<your-databricks-instance>
export DATABRICKS_TOKEN=<your-access-token>import os
import requests
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}Ein Databricks-Job kann aus mehreren Aufgaben bestehen, die jeweils einen Schritt in der Pipeline ausführen. Für dieses Beispiel kannst du dir folgendes vorstellen:
Das folgende Beispiel verwendet den Endpunkt POST /api/2.1/jobs/create, um den Auftrag zu erstellen.
{
"name": "Multi-Step Pipeline",
"tasks": [
{
"task_key": "fetch_data",
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/fetch_data"
}
},
{
"task_key": "transform_data",
"depends_on": [{"task_key": "fetch_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/transform_data"
}
},
{
"task_key": "write_results",
"depends_on": [{"task_key": "transform_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/write_results"
}
}
]
}Lösen Sie den Auftrag mit POST /api/2.1/jobs/run-now
curl -n -X POST \
https://$DATABRICKS_HOST/api/2.1/jobs/run-now?job_id=your_job_idÜberprüfe den Lernpfad GET /api/2.1/jobs/runs/get mit run_id, um den Arbeitsfortschritt zu verfolgen.
response = requests.get(f"{DATABRICKS_HOST}/api/2.1/jobs/runs/get", headers=headers, params={"run_id": run_id})
print(response.json())Rufe die Ausgabeprotokolle oder die Ergebnisse der Aufgaben mit GET /api/2.1/jobs/runs/get-output auf.
Für die Protokollierung konfigurierst du die Job-Protokolle so, dass sie in das DBFS oder ein Überwachungstool wie Datadog oder Splunk geschrieben werden. Außerdem solltest du für eine bessere Rückverfolgbarkeit detaillierte Aufzeichnungen in das Notizbuch jeder Aufgabe aufnehmen.
Implementiere auch try-except-Blöcke in Notizbüchern, um Ausnahmen abzufangen und zu protokollieren. Verwende die Databricks Jobs API, um Jobprotokolle zur Fehlersuche bei fehlgeschlagenen Läufen abzurufen. Das folgende Beispiel zeigt die Fehlerbehandlung in einem Notizbuch.
try:
# Code to fetch data from API
response = requests.get(api_url)
# Process data
except Exception as e:
print(f"An error occurred: {e}")
# Log error and exitDu kannst auch E-Mail- oder Slack-Benachrichtigungen mit der Databricks Alerts API oder Tools von Drittanbietern integrieren.
Die Umsetzung von Best Practices in Databricks kann die Sicherheit deutlich erhöhen, die Kosten senken und die Zuverlässigkeit des Systems insgesamt verbessern. Im Folgenden findest du die wichtigsten Strategien, die du bei der Nutzung von Databricks API berücksichtigen solltest, und die kritischen Bereiche.
Vermeide es, einfache Token in Codes oder Notizbüchern zu speichern. Verwende stattdessen Databricks Secret, um sensible Informationen wie API-Schlüssel oder Anmeldedaten sicher mit der Databricks Secrets API zu speichern. So wird sichergestellt, dass sensible Daten nicht im Klartext im Code oder in Notizbüchern veröffentlicht werden. Verwende immer Umgebungsvariablen, um Token oder Geheimnisse an Skripte zu übergeben, aber stelle sicher, dass diese Variablen sicher verwaltet und nicht in die Versionskontrolle übertragen werden.
Nutze die rollenbasierte Zugriffskontrolle (Role-Based Access Control, RBAC), um Berechtigungen auf Arbeitsbereichs-, Cluster- und Job-Ebene zu definieren und den Zugriff auf sensible APIs auf die erforderlichen Benutzer oder Servicekonten zu beschränken.
Für ein effektives Kostenmanagement solltest du den Einsatz von Single-Node-Clustern für kontinuierliche Aufgaben mit geringer Last in Betracht ziehen. Sie können jedoch kosteneffizient sein, wenn sie nicht vollständig genutzt werden. Außerdem werden ephemere Jobcluster automatisch für Jobs erstellt und beendet, damit die Ressourcen nicht ungenutzt bleiben.
Aufgrund der dynamischen Preisgestaltung für Cloud-Ressourcen kann die Planung außerhalb der Spitzenzeiten die Kosten erheblich senken. Verwende die Jobs-API, um Jobpläne während kostengünstiger Zeitfenster zu definieren.
Überprüfe regelmäßig die Auslastung des Clusters, um sicherzustellen, dass keine Ressourcen verschwendet werden. Konfiguriere die Cluster so, dass sie sich nach einer bestimmten Leerlaufzeit automatisch beenden, um unnötige Kosten zu vermeiden.
Für automatisierte Tests und Auftragsdefinitionen solltest du Unit-Tests für die Auftragslogik implementieren, um Fehler frühzeitig zu erkennen. Überwache Lernpfade und protokolliere Leistungskennzahlen, um die Lernpfade programmatisch zu verfolgen und historische Daten zu analysieren:
Mit der REST-API von Databricks können Teams Arbeitsabläufe automatisieren, Kosten optimieren und nahtlos in externe Systeme integrieren, was die Verwaltung von Datenpipelines und Analysen verändert. Ich empfehle dir, zunächst einen einfachen API-Aufruf zu testen, wie z.B. das Erstellen eines Jobs, um Vertrauen in die Plattform aufzubauen. Du kannst auch andere fortgeschrittene Themen wie den Unity-Katalog für fein abgestufte Governance erforschen oder in Echtzeit-Streaming-Anwendungsfälle eintauchen.
Außerdem empfehle ich dir, die offiziellen Databricks REST API Docs zu lesen, um offene Fragen zu beantworten, und die GitHub-Repositories für die Databricks CLI und das Databricks SDK für Python zu erkunden, um mehr über die rationalisierte Entwicklung zu erfahren.
Wenn du die grundlegenden Konzepte von Databricks kennenlernen möchtest, empfehle ich dir unseren Kurs Einführung in Databricks. In diesem Kurs lernst du Databricks als Data Warehousing-Lösung für Business Intelligence kennen. Ich empfehle auch einen Blick in unseren Blogbeitrag Databricks-Zertifizierungen im Jahr 2024, um zu erfahren, wie du Databricks-Zertifizierungen erlangen kannst, welche Vorteile du für deine Karriere hast und wie du die richtige Zertifizierung für deine Karriereziele findest.
Cloud lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
