
Lernpfad
Llama-Grundlagen
4 Std.
In diesem Tutorial erkläre ich Schritt für Schritt, wie du DeepSeek-R1 lokal ausführst und wie du es mit Ollama einrichtest. Wir werden auch eine einfache RAG-Anwendung erstellen, die auf deinem Laptop läuft und das R1-Modell, LangChain und Gradio verwendet.
Wenn du nur einen Überblick über das R1-Modell haben möchtest, empfehle ich dir diesen DeepSeek-R1-Artikel. Um zu lernen, wie du R1 fein abstimmst, empfehle ich dir dieses Tutorial zur Feinabstimmung von DeepSeek-R1.
Wenn du DeepSeek-R1 lokal ausführst, hast du die vollständige Kontrolle über die Modellausführung, ohne von externen Servern abhängig zu sein. Hier sind ein paar Vorteile, wenn du DeepSeek-R1 lokal ausführst:
Ollama vereinfacht die lokale Ausführung von LLMs, indem es Modell-Downloads, Quantisierung und Ausführung nahtlos handhabt.
Lade zunächst Ollama von der offiziellen Website herunter und installiere es. Website herunter..
Sobald der Download abgeschlossen ist, installierst du die Ollama-Anwendung wie jede andere Anwendung auch.
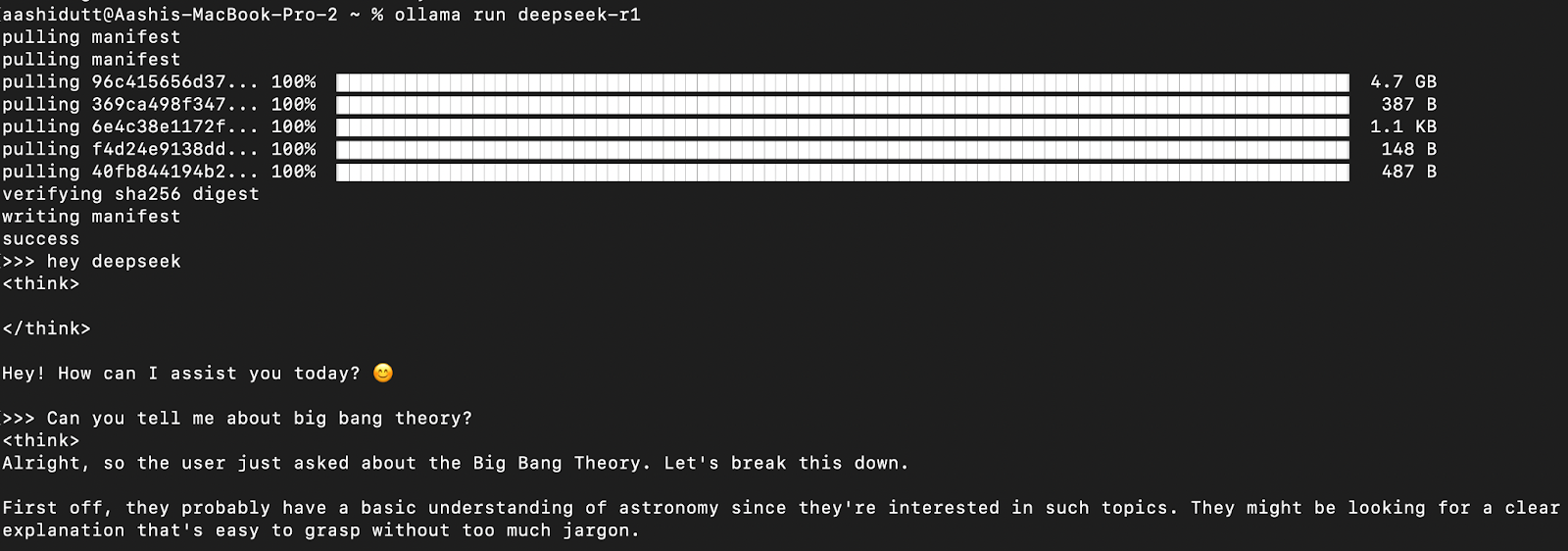
Testen wir das Setup und laden wir unser Modell herunter. Starte das Terminal und gib den folgenden Befehl ein.
ollama run deepseek-r1Ollama bietet eine Reihe von DeepSeek R1-Modellen an, die von 1,5 B Parametern bis zum vollen Modell mit 671 B Parametern reichen. Das Modell 671B ist der ursprüngliche DeepSeek-R1, während die kleineren Modelle destillierte Versionen sind, die auf den Architekturen Qwen und Llama basieren. Wenn deine Hardware das 671B-Modell nicht unterstützt, kannst du ganz einfach eine kleinere Version ausführen, indem du den folgenden Befehl verwendest und die X unten durch die gewünschte Parametergröße ersetzt (1.5b, 7b, 8b, 14b, 32b, 70b, 671b):
ollama run deepseek-r1: XbDank dieser Flexibilität kannst du die Möglichkeiten von DeepSeek-R1 auch dann nutzen, wenn du keinen Supercomputer hast.
Um DeepSeek-R1 kontinuierlich laufen zu lassen und über eine API bereitzustellen, starte den Ollama-Server:
ollama serveDadurch wird das Modell für die Integration in andere Anwendungen verfügbar.
Sobald das Modell heruntergeladen ist, kannst du direkt im Terminal mit DeepSeek-R1 arbeiten.
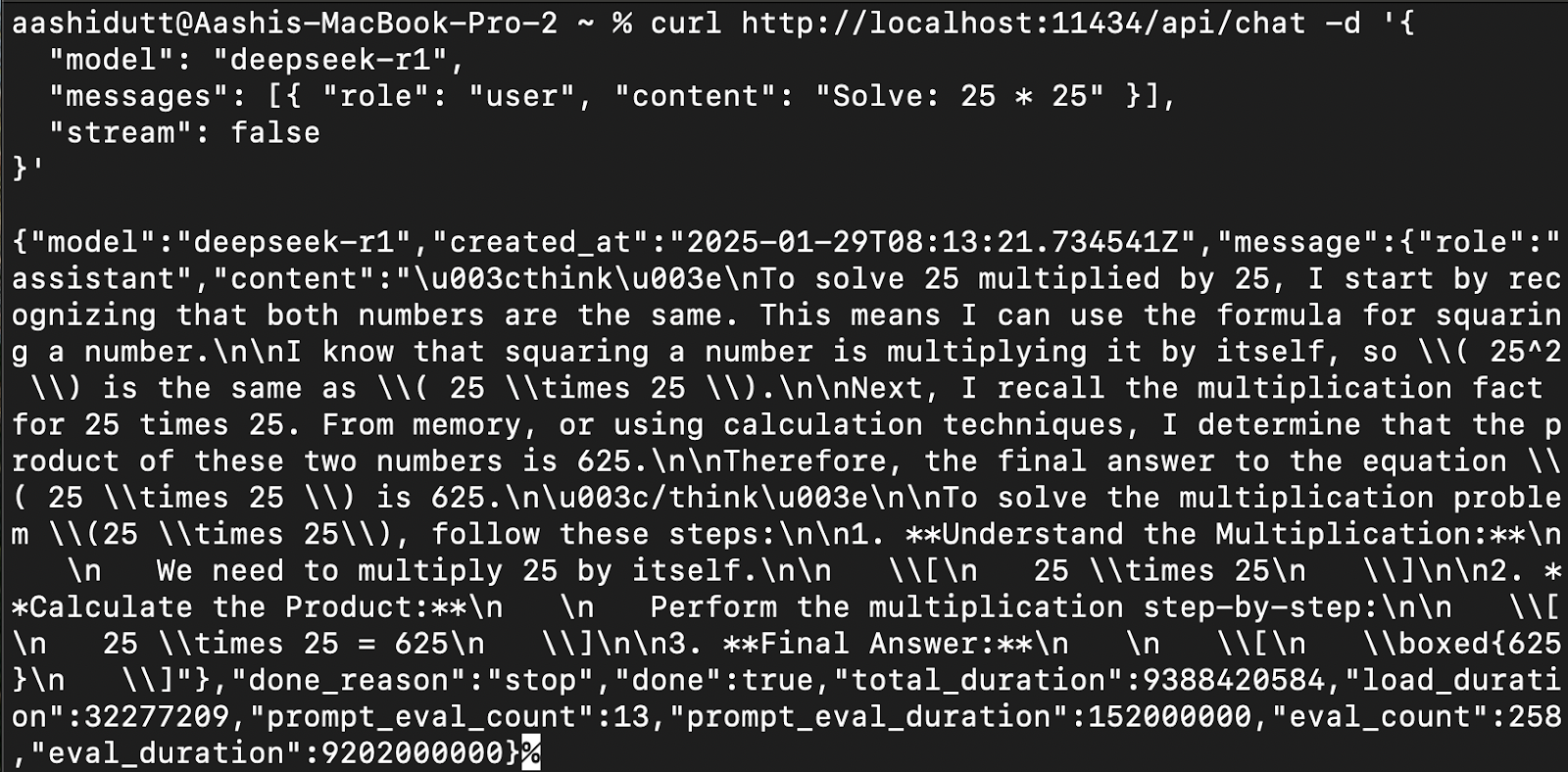
Um DeepSeek-R1 in Anwendungen zu integrieren, verwende die Ollama API unter curl:
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "Solve: 25 * 25" }],
"stream": false
}'curl ist ein Kommandozeilen-Tool, das unter Linux, aber auch unter macOS funktioniert. Sie ermöglicht es den Nutzern, HTTP-Anfragen direkt vom Terminal aus zu stellen, was sie zu einem hervorragenden Werkzeug für die Interaktion mit APIs macht.
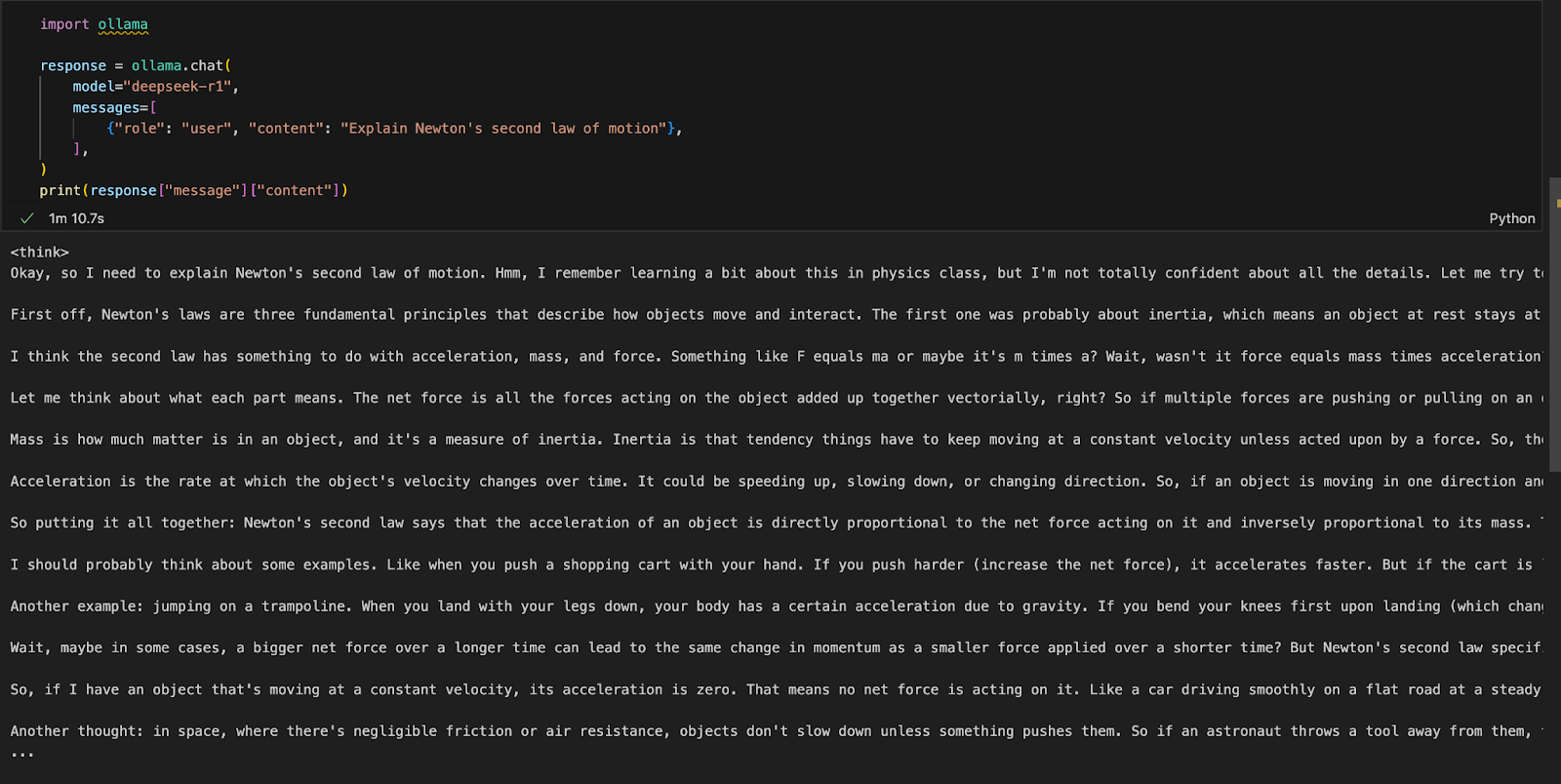
Wir können Ollama in jeder integrierten Entwicklungsumgebung (IDE) unserer Wahl ausführen. Du kannst das Ollama Python-Paket mit folgendem Code installieren:
!pip install ollamaSobald Ollama installiert ist, kannst du das folgende Skript verwenden, um mit dem Modell zu interagieren:
import ollama
response = ollama.chat(
model="deepseek-r1",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])Die Funktion ollama.chat() nimmt den Modellnamen und eine Eingabeaufforderung des Benutzers entgegen und verarbeitet sie als Konversationsaustausch. Das Skript extrahiert und druckt dann die Antwort des Modells.
Lass uns eine einfache Demo-App mit Gradio erstellen, um Dokumente mit DeepSeek-R1 abzufragen und zu analysieren.
Bevor wir mit der Implementierung beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
Führe die folgenden Befehle aus, um die notwendigen Abhängigkeiten zu installieren:
!pip install langchain chromadb gradio
!pip install -U langchain-communitySobald die oben genannten Abhängigkeiten installiert sind, führst du die folgenden Importbefehle aus:
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollamaSobald die Bibliotheken importiert sind, verarbeiten wir das hochgeladene PDF.
def process_pdf(pdf_bytes):
if pdf_bytes is None:
return None, None, None
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
embeddings = OllamaEmbeddings(model="deepseek-r1")
vectorstore=Chroma.from_documents(documents=chunks, embedding=embeddings)
retriever = vectorstore.as_retriever()
return text_splitter, vectorstore, retrieverDie Funktion process_pdf:
PyMuPDFLoader.RecursiveCharacterTextSplitter in einzelne Abschnitte auf.OllamaEmbeddings.Sobald wir die Einbettungen gefunden haben, müssen wir sie zusammenfügen. Die Funktion combine_docs() fasst mehrere abgefragte Dokumententeile zu einem einzigen String zusammen.
def combine_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)Da Retrieval-basierte Modelle relevante Auszüge und nicht ganze Dokumente abrufen, stellt diese Funktion sicher, dass der extrahierte Inhalt lesbar und richtig formatiert bleibt, bevor er an DeepSeek-R1 weitergeleitet wird.
Jetzt ist unser Input für das Modell fertig. Lass uns DeepSeek R1 mit Ollama einrichten.
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(model="deepseek-r1", messages=[{'role': 'user', 'content': formatted_prompt}])
response_content = response['message']['content']
# Remove content between <think> and </think> tags to remove thinking output
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerDie Funktion ollama_llm() formatiert die Frage des Nutzers und den abgerufenen Dokumentenkontext zu einer strukturierten Eingabeaufforderung. Diese formatierte Eingabe wird dann über ollama.chat() an DeepSeek-R1 gesendet, der die Frage im gegebenen Kontext verarbeitet und eine passende Antwort zurückgibt. Wenn du die Antwort ohne das Denkskript des Modells brauchst, kannst du die Funktion strip() verwenden, um die endgültige Antwort zu erhalten.
Jetzt, da wir alle benötigten Komponenten haben, können wir die RAG-Pipeline für unsere Demo erstellen.
def rag_chain(question, text_splitter, vectorstore, retriever):
retrieved_docs = retriever.invoke(question)
formatted_content = combine_docs(retrieved_docs)
return ollama_llm(question, formatted_content)Die obige Funktion durchsucht zunächst den Vektorspeicher mit retriever.invoke(question) und gibt die relevantesten Dokumentenauszüge zurück. Diese Auszüge werden mit der Funktion combine_docs in eine strukturierte Eingabe formatiert und an ollama_llm gesendet, um sicherzustellen, dass DeepSeek-R1 auf der Grundlage der abgerufenen Inhalte gut informierte Antworten generiert.
Wir haben unsere RAG-Pipeline eingerichtet. Jetzt können wir die Gradio-Schnittstelle lokal zusammen mit dem DeepSeek-R1-Modell erstellen, um PDF-Eingaben zu verarbeiten und Fragen dazu zu stellen.
def ask_question(pdf_bytes, question):
text_splitter, vectorstore, retriever = process_pdf(pdf_bytes)
if text_splitter is None:
return None # No PDF uploaded
result = rag_chain(question, text_splitter, vectorstore, retriever)
return {result}
interface = gr.Interface(
fn=ask_question,
inputs=[gr.File(label="Upload PDF (optional)"), gr.Textbox(label="Ask a question")],
outputs="text",
title="Ask questions about your PDF",
description="Use DeepSeek-R1 to answer your questions about the uploaded PDF document.",
)
interface.launch()Wir führen die folgenden Schritte durch:
process_pdf, um Text zu extrahieren und Dokumenteneinbettungen zu erstellen.rag_chain(), um relevante Informationen abzurufen und eine kontextgenaue Antwort zu generieren.gr.Interface(), die eine PDF-Datei und eine Textabfrage als Eingaben akzeptiert.interface.launch(), um nahtlose, interaktive dokumentenbasierte Fragen und Antworten über einen Webbrowser zu ermöglichen.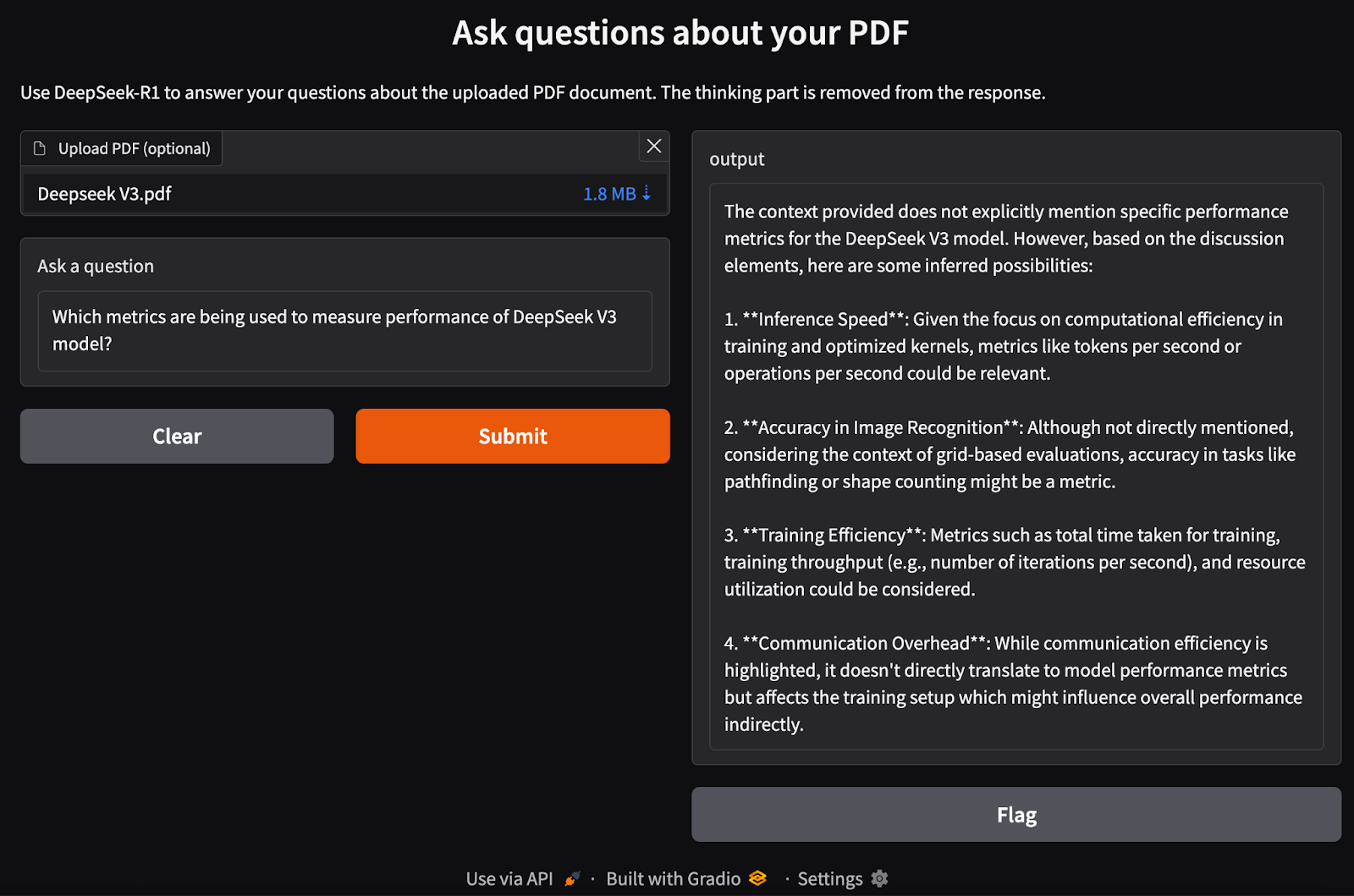
Die lokale Ausführung von DeepSeek-R1 mit Ollama ermöglicht eine schnellere, private und kostengünstige Modellinferenz. Mit einem einfachen Installationsprozess, CLI-Interaktion, API-Unterstützung und Python-Integration kannst du DeepSeek-R1 für eine Vielzahl von KI-Anwendungen nutzen, von allgemeinen Abfragen bis hin zu komplexen Retrieval-basierten Aufgaben.
Um über die neuesten Entwicklungen in der KI auf dem Laufenden zu bleiben, empfehle ich diese Blogs:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
