
Programa
Llama Fundamentals
4 h
Neste tutorial, explicarei passo a passo como executar o DeepSeek-R1 localmente e como configurá-lo usando o Ollama. Também exploraremos a criação de um aplicativo RAG simples que seja executado em seu laptop usando o modelo R1, LangChain e Gradio.
Se você quiser apenas uma visão geral do modelo R1, recomendo este artigo do DeepSeek-R1. Para saber como fazer o ajuste fino do R1, recomendo este tutorial sobre o ajuste fino do DeepSeek-R1.
Ao executar o DeepSeek-R1 localmente, você tem controle total sobre a execução do modelo sem depender de servidores externos. Aqui estão algumas vantagens de executar o DeepSeek-R1 localmente:
O Ollama simplifica a execução de LLMs localmente, lidando com downloads de modelos, quantização e execução de forma integrada.
Primeiro, faça o download e instale o Ollama no site oficial oficial.
Quando o download estiver concluído, instale o aplicativo Ollama como você faria com qualquer outro aplicativo.
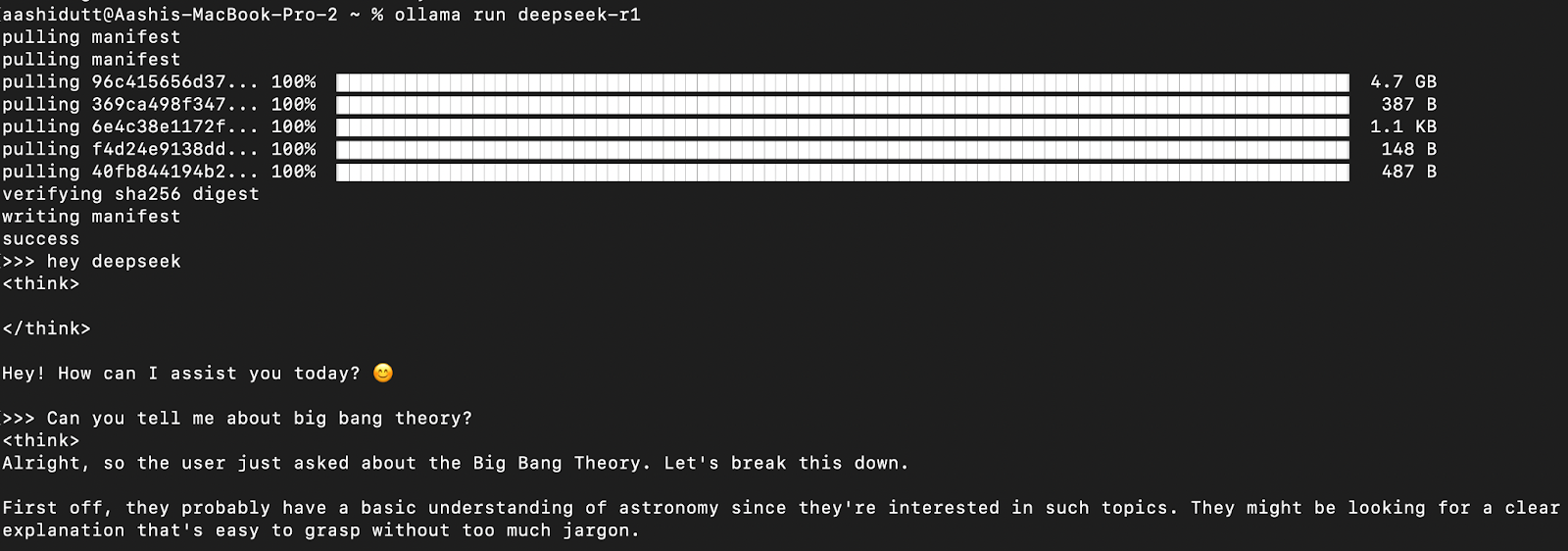
Vamos testar a configuração e fazer o download do nosso modelo. Abra o terminal e digite o seguinte comando.
ollama run deepseek-r1A Ollama oferece uma variedade de modelos DeepSeek R1, abrangendo desde parâmetros de 1,5B até o modelo completo de 671B parâmetros. O modelo 671B é o DeepSeek-R1 original, enquanto os modelos menores são versões destiladas baseadas nas arquiteturas Qwen e Llama. Se o seu hardware não for compatível com o modelo 671B, você poderá executar facilmente uma versão menor usando o seguinte comando e substituindo o X abaixo pelo tamanho do parâmetro desejado (1.5b, 7b, 8b, 14b, 32b, 70b, 671b):
ollama run deepseek-r1: XbCom essa flexibilidade, você pode usar os recursos do DeepSeek-R1 mesmo que não tenha um supercomputador.
Para executar o DeepSeek-R1 continuamente e servi-lo por meio de uma API, inicie o servidor Ollama:
ollama serveIsso tornará o modelo disponível para integração com outros aplicativos.
Depois que o modelo for baixado, você poderá interagir com o DeepSeek-R1 diretamente no terminal.
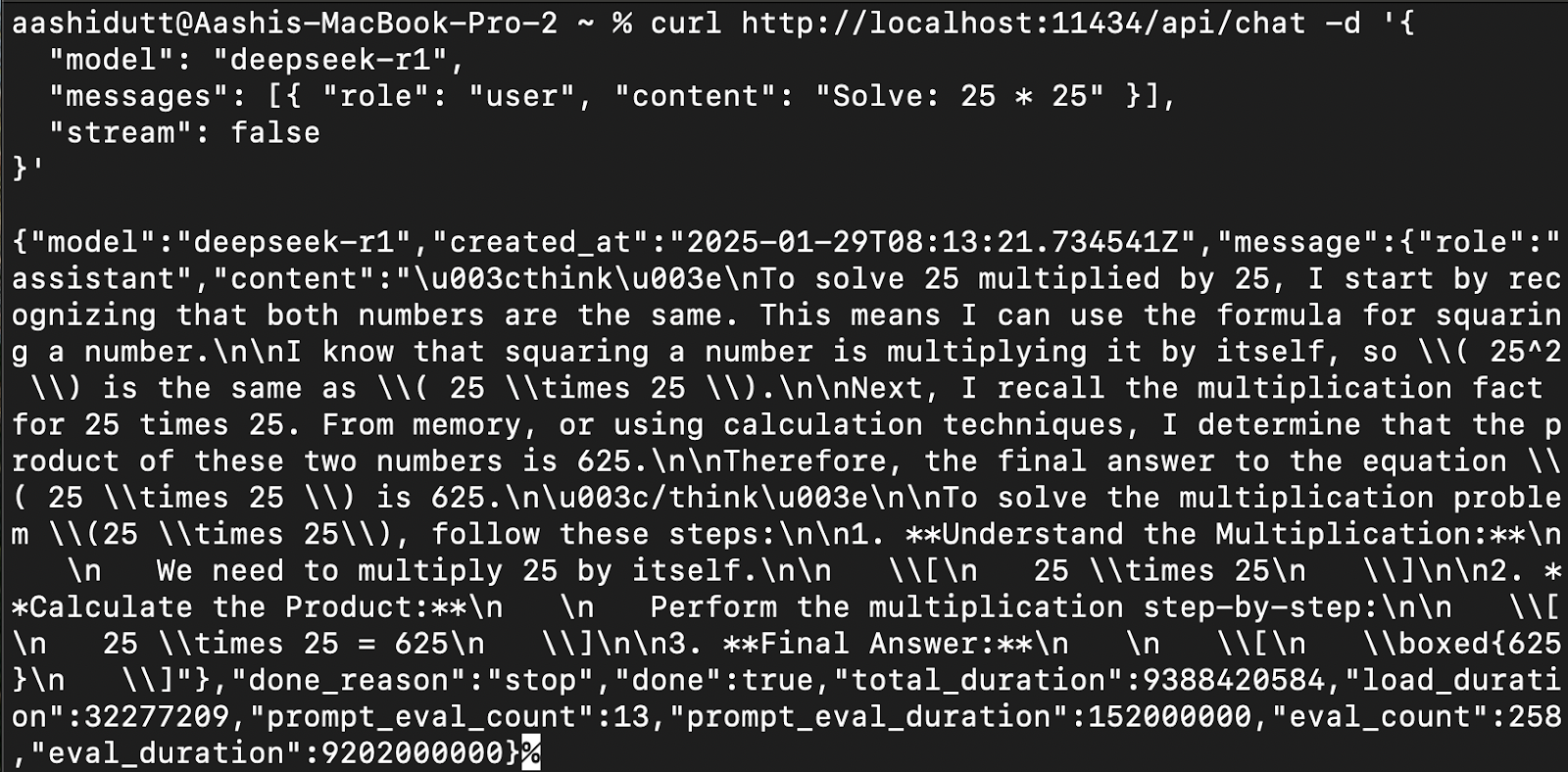
Para integrar o DeepSeek-R1 aos aplicativos, use a API Ollama usando curl:
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "Solve: 25 * 25" }],
"stream": false
}'curl é uma ferramenta de linha de comando nativa do Linux, mas também funciona no macOS. Ele permite que os usuários façam solicitações HTTP diretamente do terminal, o que o torna uma excelente ferramenta para interagir com APIs.
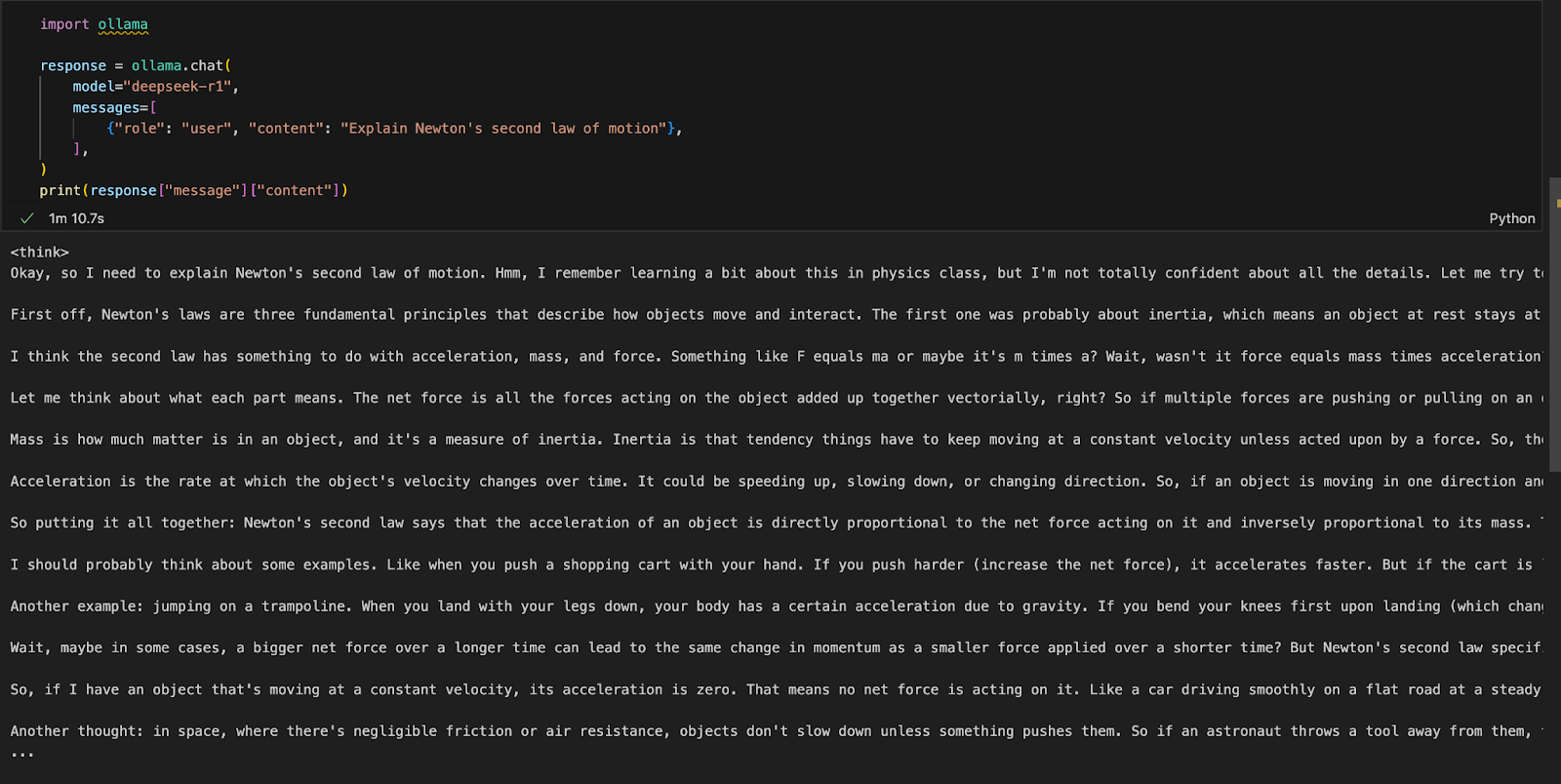
Você pode executar o Ollama em qualquer ambiente de desenvolvimento integrado (IDE) de sua preferência. Você pode instalar o pacote Ollama Python usando o seguinte código:
!pip install ollamaDepois que o Ollama estiver instalado, use o script a seguir para interagir com o modelo:
import ollama
response = ollama.chat(
model="deepseek-r1",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])A função ollama.chat() usa o nome do modelo e um prompt do usuário, processando-o como uma troca de conversas. Em seguida, o script extrai e imprime a resposta do modelo.
Vamos criar um aplicativo de demonstração simples usando o Gradio para consultar e analisar documentos com o DeepSeek-R1.
Antes de mergulhar na implementação, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
Execute os seguintes comandos para instalar as dependências necessárias:
!pip install langchain chromadb gradio
!pip install -U langchain-communityQuando as dependências acima estiverem instaladas, execute os seguintes comandos de importação:
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollamaDepois que as bibliotecas forem importadas, processaremos o PDF carregado.
def process_pdf(pdf_bytes):
if pdf_bytes is None:
return None, None, None
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
embeddings = OllamaEmbeddings(model="deepseek-r1")
vectorstore=Chroma.from_documents(documents=chunks, embedding=embeddings)
retriever = vectorstore.as_retriever()
return text_splitter, vectorstore, retrieverA função process_pdf:
PyMuPDFLoader.RecursiveCharacterTextSplitter.OllamaEmbeddings.Depois que os embeddings são recuperados, precisamos uni-los. A função combine_docs() mescla vários pedaços de documentos recuperados em uma única string.
def combine_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)Como os modelos baseados em recuperação extraem trechos relevantes em vez de documentos inteiros, essa função garante que o conteúdo extraído permaneça legível e formatado adequadamente antes de ser passado para o DeepSeek-R1.
Agora, nossa entrada para o modelo está pronta. Vamos configurar o DeepSeek R1 usando o Ollama.
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(model="deepseek-r1", messages=[{'role': 'user', 'content': formatted_prompt}])
response_content = response['message']['content']
# Remove content between <think> and </think> tags to remove thinking output
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerA função ollama_llm() formata a pergunta do usuário e o contexto do documento recuperado em um prompt estruturado. Essa entrada formatada é então enviada ao DeepSeek-R1 por meio do site ollama.chat(), que processa a pergunta dentro do contexto fornecido e retorna uma resposta relevante. Se você precisar da resposta sem o script de raciocínio do modelo, use a função strip() para retornar a resposta final.
Agora que temos todos os componentes necessários, vamos criar o pipeline RAG para nossa demonstração.
def rag_chain(question, text_splitter, vectorstore, retriever):
retrieved_docs = retriever.invoke(question)
formatted_content = combine_docs(retrieved_docs)
return ollama_llm(question, formatted_content)A função acima primeiro pesquisa o armazenamento de vetores usando retriever.invoke(question), retornando os trechos de documentos mais relevantes. Esses trechos são formatados em uma entrada estruturada usando a função combine_docs e enviados para ollama_llm, garantindo que o DeepSeek-R1 gere respostas bem informadas com base no conteúdo recuperado.
Temos nosso pipeline RAG em funcionamento. Agora, podemos criar a interface do Gradio localmente junto com o modelo DeepSeek-R1 para processar a entrada de PDF e fazer perguntas relacionadas a ela.
def ask_question(pdf_bytes, question):
text_splitter, vectorstore, retriever = process_pdf(pdf_bytes)
if text_splitter is None:
return None # No PDF uploaded
result = rag_chain(question, text_splitter, vectorstore, retriever)
return {result}
interface = gr.Interface(
fn=ask_question,
inputs=[gr.File(label="Upload PDF (optional)"), gr.Textbox(label="Ask a question")],
outputs="text",
title="Ask questions about your PDF",
description="Use DeepSeek-R1 to answer your questions about the uploaded PDF document.",
)
interface.launch()Executamos as seguintes etapas:
process_pdf para extrair o texto e gerar incorporação de documentos.rag_chain() para recuperar informações relevantes e gerar uma resposta contextualmente precisa.gr.Interface(), aceitando um arquivo PDF e uma consulta de texto como entradas.interface.launch() para permitir perguntas e respostas interativas e sem interrupções baseadas em documentos por meio de um navegador da Web.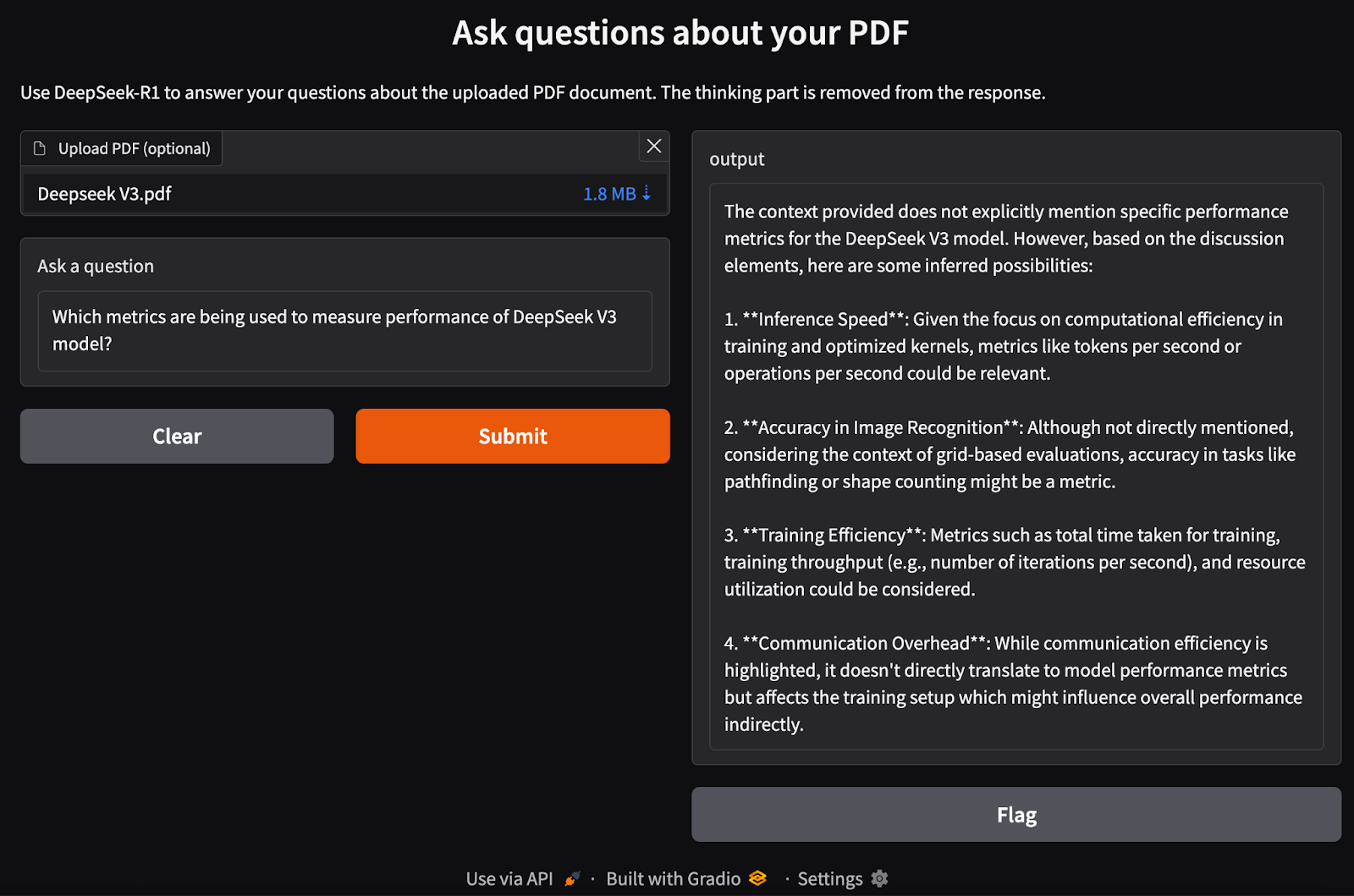
A execução do DeepSeek-R1 localmente com o Ollama permite uma inferência de modelo mais rápida, privada e econômica. Com um processo de instalação simples, interação CLI, suporte a API e integração com Python, você pode usar o DeepSeek-R1 para uma variedade de aplicativos de IA, desde consultas gerais até tarefas complexas baseadas em recuperação.
Para que você fique por dentro dos últimos desenvolvimentos em IA, recomendo estes blogs:
Aprenda IA com estes cursos!
Programa
Curso
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Ryan Ong
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita

