
Cursus
Les fondamentaux du lama
4 h
Dans ce tutoriel, je vais vous expliquer étape par étape comment exécuter DeepSeek-R1 localement et comment le configurer à l'aide d'Ollama. Nous explorerons également la construction d'une application RAG simple qui fonctionne sur votre ordinateur portable en utilisant le modèle R1, LangChain et Gradio.
Si vous ne souhaitez qu'une vue d'ensemble du modèle R1, je vous recommande cet article de DeepSeek-R1. Pour apprendre à affiner le réglage de R1, je vous recommande ce tutoriel sur l'affinement de DeepSeek-R1.
L'exécution locale de DeepSeek-R1 vous permet de contrôler entièrement l'exécution du modèle sans dépendre de serveurs externes. Voici quelques avantages à exécuter DeepSeek-R1 localement :
Ollama simplifie l'exécution locale des LLM en gérant les téléchargements de modèles, la quantification et l'exécution de manière transparente.
Tout d'abord, téléchargez et installez Ollama depuis le officiel.
Une fois le téléchargement terminé, installez l'application Ollama comme vous le feriez pour n'importe quelle autre application.
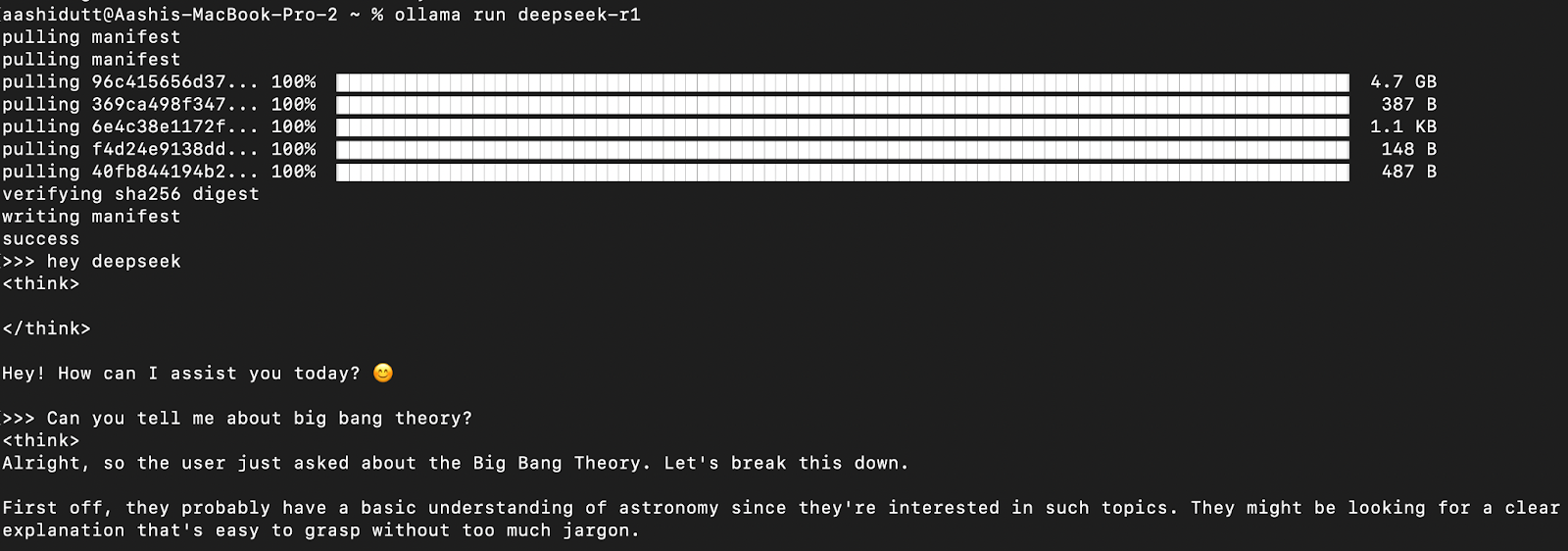
Testons la configuration et téléchargeons notre modèle. Lancez le terminal et tapez la commande suivante.
ollama run deepseek-r1Ollama propose une gamme de modèles DeepSeek R1, allant de 1,5B paramètres au modèle complet de 671B paramètres. Le modèle 671B est le DeepSeek-R1 original, tandis que les modèles plus petits sont des versions distillées basées sur les architectures Qwen et Llama. Si votre matériel ne supporte pas le modèle 671B, vous pouvez facilement exécuter une version plus petite en utilisant la commande suivante et en remplaçant le X ci-dessous par la taille de paramètre que vous souhaitez (1.5b, 7b, 8b, 14b, 32b, 70b, 671b) :
ollama run deepseek-r1: XbGrâce à cette flexibilité, vous pouvez utiliser les capacités de DeepSeek-R1 même si vous ne disposez pas d'un superordinateur.
Pour exécuter DeepSeek-R1 en continu et le servir via une API, démarrez le serveur Ollama :
ollama serveLe modèle pourra ainsi être intégré à d'autres applications.
Une fois le modèle téléchargé, vous pouvez interagir avec DeepSeek-R1 directement dans le terminal.
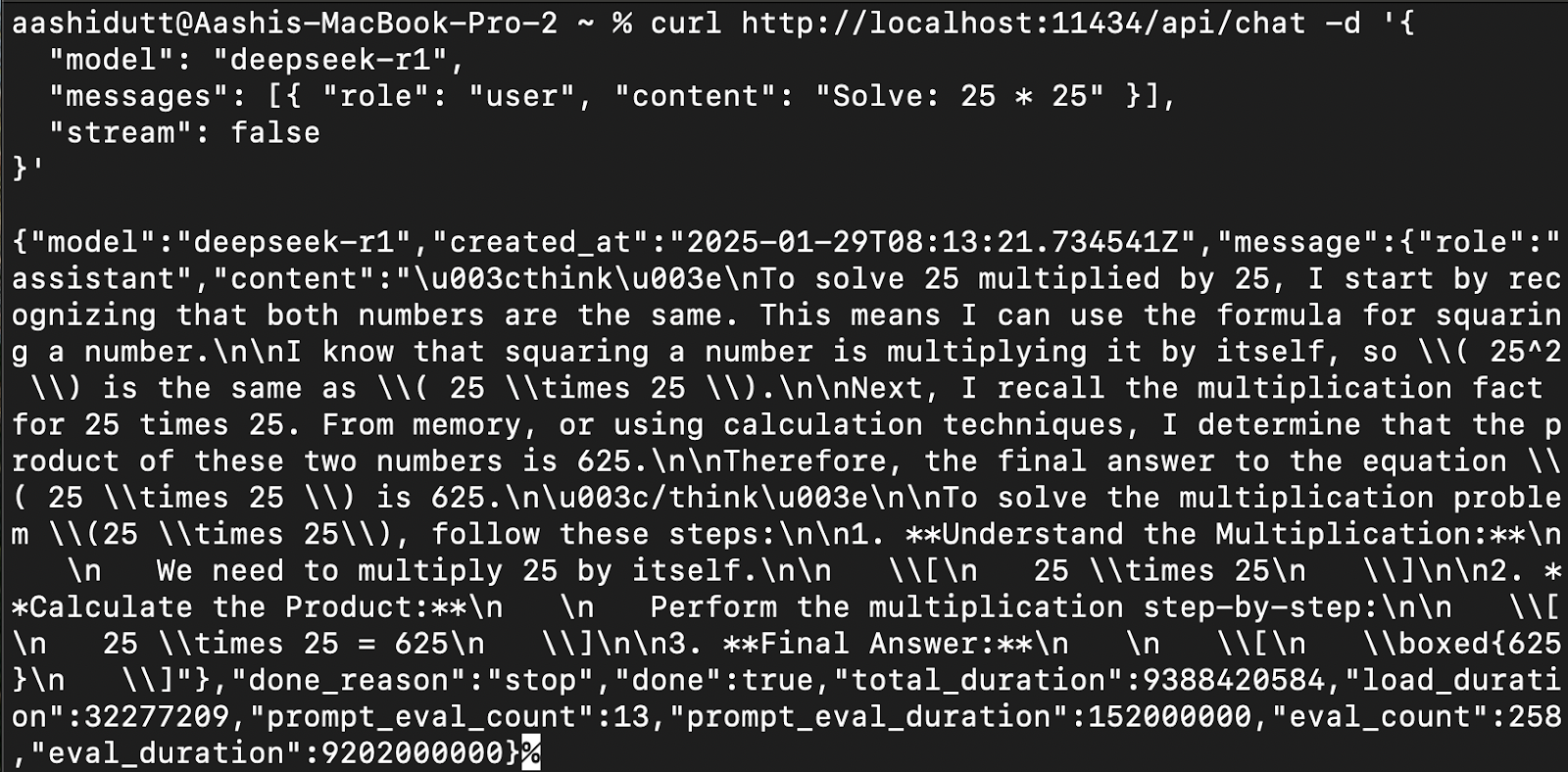
Pour intégrer DeepSeek-R1 dans des applications, utilisez l'API Ollama à l'aide de curl:
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "Solve: 25 * 25" }],
"stream": false
}'curl est un outil de ligne de commande natif de Linux, mais qui fonctionne également sur macOS. Il permet aux utilisateurs de faire des requêtes HTTP directement à partir du terminal, ce qui en fait un excellent outil pour interagir avec les API.
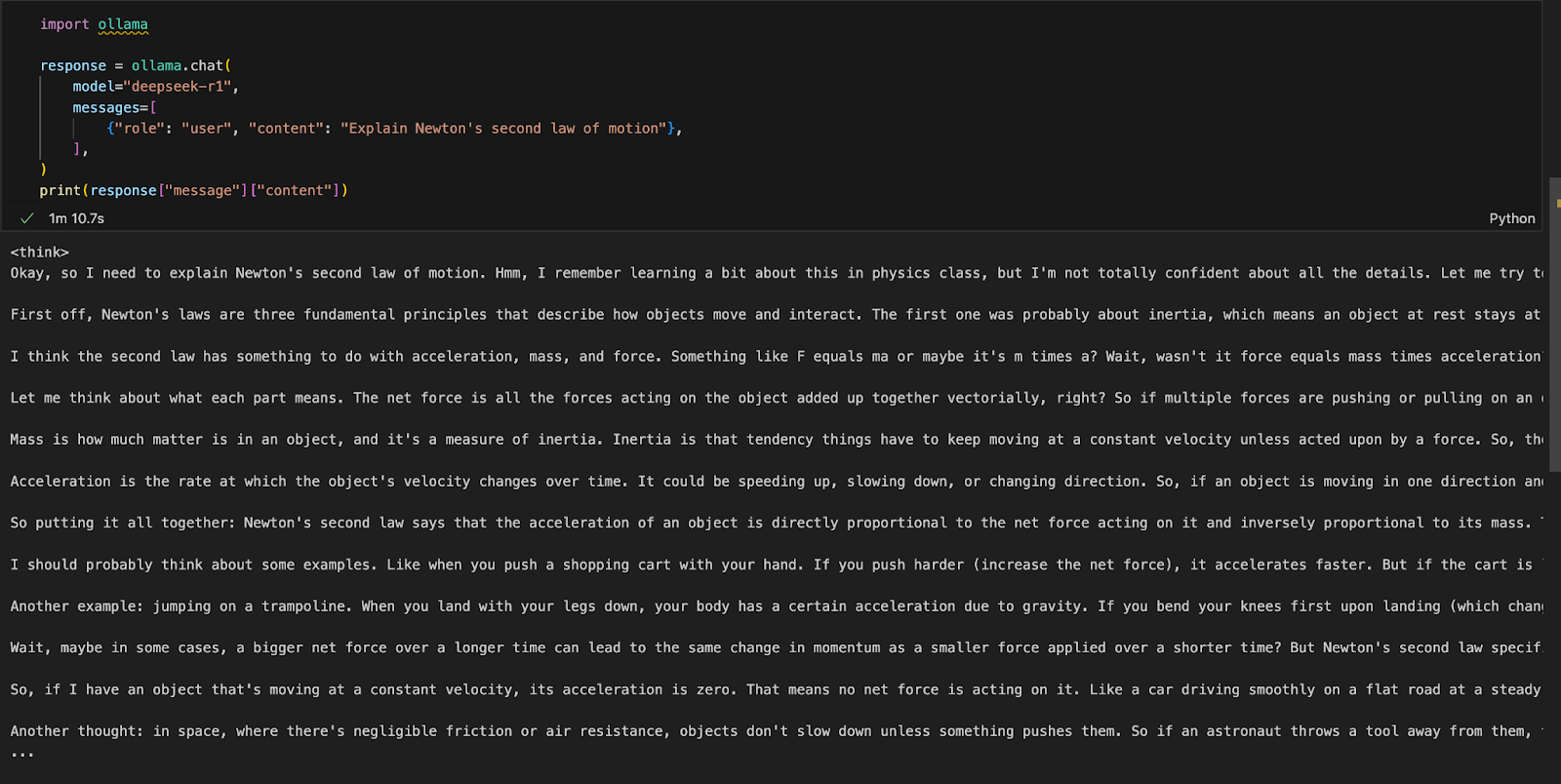
Nous pouvons exécuter Ollama dans l'environnement de développement intégré (IDE) de notre choix. Vous pouvez installer le paquetage Python d'Ollama en utilisant le code suivant :
!pip install ollamaUne fois Ollama installé, utilisez le script suivant pour interagir avec le modèle :
import ollama
response = ollama.chat(
model="deepseek-r1",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])La fonction ollama.chat() prend le nom du modèle et une invite de l'utilisateur, qu'elle traite comme un échange conversationnel. Le script extrait et imprime ensuite la réponse du modèle.
Construisons une application de démonstration simple utilisant Gradio pour interroger et analyser des documents avec DeepSeek-R1.
Avant de plonger dans la mise en œuvre, assurons-nous que les outils et bibliothèques suivants sont installés :
Exécutez les commandes suivantes pour installer les dépendances nécessaires :
!pip install langchain chromadb gradio
!pip install -U langchain-communityUne fois les dépendances ci-dessus installées, exécutez les commandes d'importation suivantes :
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollamaUne fois les bibliothèques importées, nous traiterons le PDF téléchargé.
def process_pdf(pdf_bytes):
if pdf_bytes is None:
return None, None, None
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
embeddings = OllamaEmbeddings(model="deepseek-r1")
vectorstore=Chroma.from_documents(documents=chunks, embedding=embeddings)
retriever = vectorstore.as_retriever()
return text_splitter, vectorstore, retrieverLa fonction process_pdf:
PyMuPDFLoader.RecursiveCharacterTextSplitter.OllamaEmbeddings.Une fois que les encastrements ont été récupérés, il faut les assembler. La fonction combine_docs() fusionne plusieurs morceaux de documents récupérés en une seule chaîne.
def combine_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)Étant donné que les modèles basés sur la recherche tirent des extraits pertinents plutôt que des documents entiers, cette fonction garantit que le contenu extrait reste lisible et correctement formaté avant d'être transmis à DeepSeek-R1.
Notre entrée dans le modèle est maintenant prête. Mettons en place DeepSeek R1 en utilisant Ollama.
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(model="deepseek-r1", messages=[{'role': 'user', 'content': formatted_prompt}])
response_content = response['message']['content']
# Remove content between <think> and </think> tags to remove thinking output
final_answer = re.sub(r'<think>.*?</think>', '', response_content, flags=re.DOTALL).strip()
return final_answerLa fonction ollama_llm() formate la question de l'utilisateur et le contexte du document récupéré en une invite structurée. Cette entrée formatée est ensuite envoyée à DeepSeek-R1 via ollama.chat(), qui traite la question dans le contexte donné et renvoie une réponse pertinente. Si vous avez besoin de la réponse sans le script de réflexion du modèle, utilisez la fonction strip() pour obtenir la réponse finale.
Maintenant que nous avons tous les composants nécessaires, construisons le pipeline RAG pour notre démo.
def rag_chain(question, text_splitter, vectorstore, retriever):
retrieved_docs = retriever.invoke(question)
formatted_content = combine_docs(retrieved_docs)
return ollama_llm(question, formatted_content)La fonction ci-dessus effectue d'abord une recherche dans le magasin de vecteurs à l'aide de retriever.invoke(question) et renvoie les extraits de documents les plus pertinents. Ces extraits sont formatés dans une entrée structurée à l'aide de la fonction combine_docs et envoyés à ollama_llm, ce qui permet à DeepSeek-R1 de générer des réponses bien informées sur la base du contenu récupéré.
Nous avons mis en place notre pipeline RAG. Maintenant, nous pouvons construire l'interface Gradio localement avec le modèle DeepSeek-R1 pour traiter les entrées PDF et poser les questions qui s'y rapportent.
def ask_question(pdf_bytes, question):
text_splitter, vectorstore, retriever = process_pdf(pdf_bytes)
if text_splitter is None:
return None # No PDF uploaded
result = rag_chain(question, text_splitter, vectorstore, retriever)
return {result}
interface = gr.Interface(
fn=ask_question,
inputs=[gr.File(label="Upload PDF (optional)"), gr.Textbox(label="Ask a question")],
outputs="text",
title="Ask questions about your PDF",
description="Use DeepSeek-R1 to answer your questions about the uploaded PDF document.",
)
interface.launch()Nous procédons aux étapes suivantes :
process_pdf pour extraire le texte et générer des incorporations de documents.rag_chain() pour qu'elle récupère les informations pertinentes et génère une réponse adaptée au contexte.gr.Interface(), qui accepte un fichier PDF et une requête de texte comme entrées.interface.launch() pour permettre des questions-réponses interactives et transparentes basées sur des documents via un navigateur web.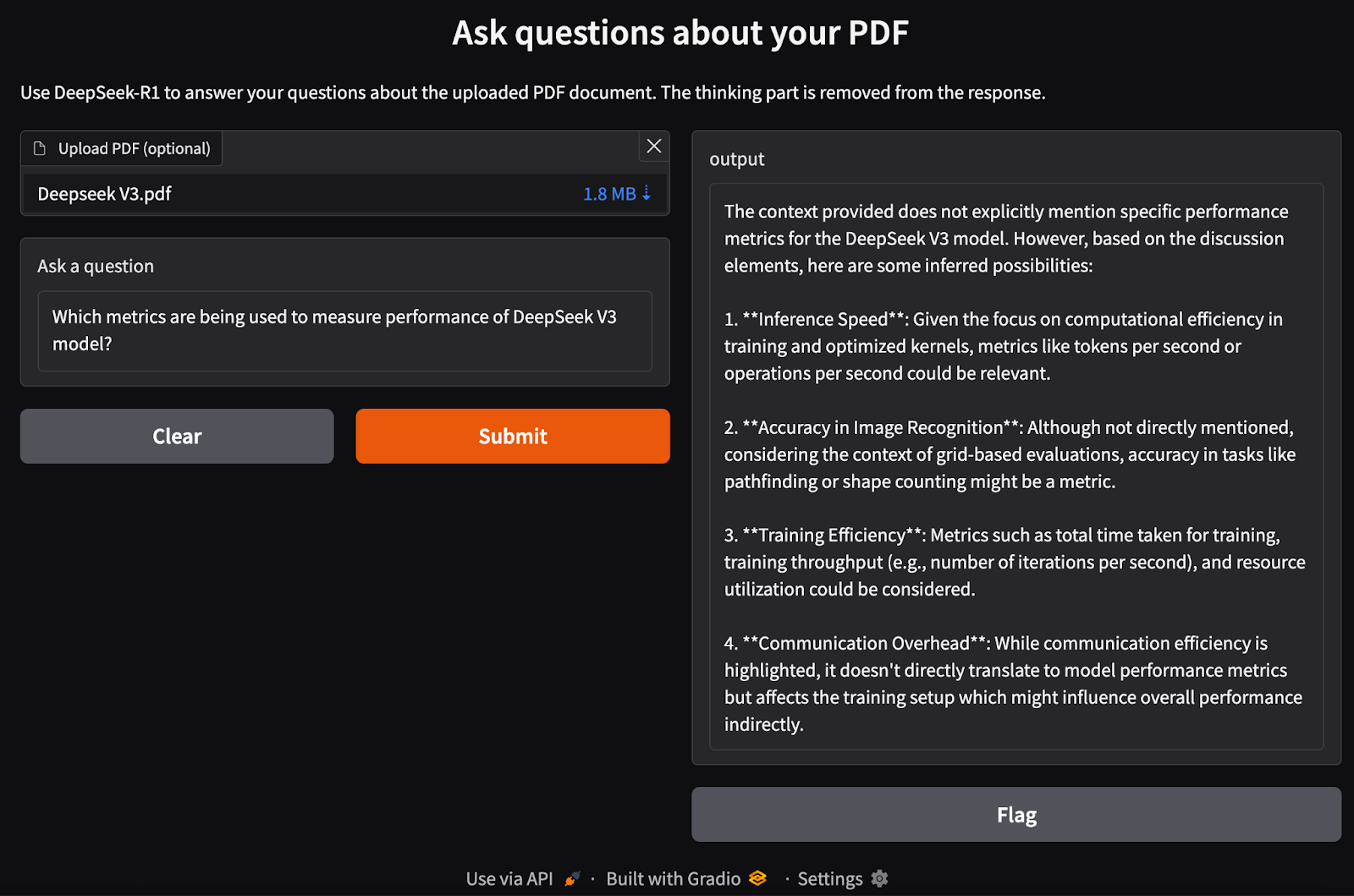
L'exécution locale de DeepSeek-R1 avec Ollama permet une inférence de modèle plus rapide, privée et rentable. Avec un processus d'installation simple, une interaction CLI, une prise en charge API et une intégration Python, vous pouvez utiliser DeepSeek-R1 pour une variété d'applications d'IA, des requêtes générales aux tâches complexes basées sur l'extraction.
Pour vous tenir au courant des derniers développements en matière d'IA, je vous recommande ces blogs :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach