
Track
Llama Fundamentals
4 hr
Running DeepSeek-R1 locally gives you complete control over model execution without dependency on external servers. Here are a few advantages to running DeepSeek-R1 locally:
Ollama simplifies running LLMs locally by handling model downloads, quantization, and execution seamlessly.
First, download and install Ollama from the official website.
Once the download is complete, install the Ollama application like you would do for any other application.
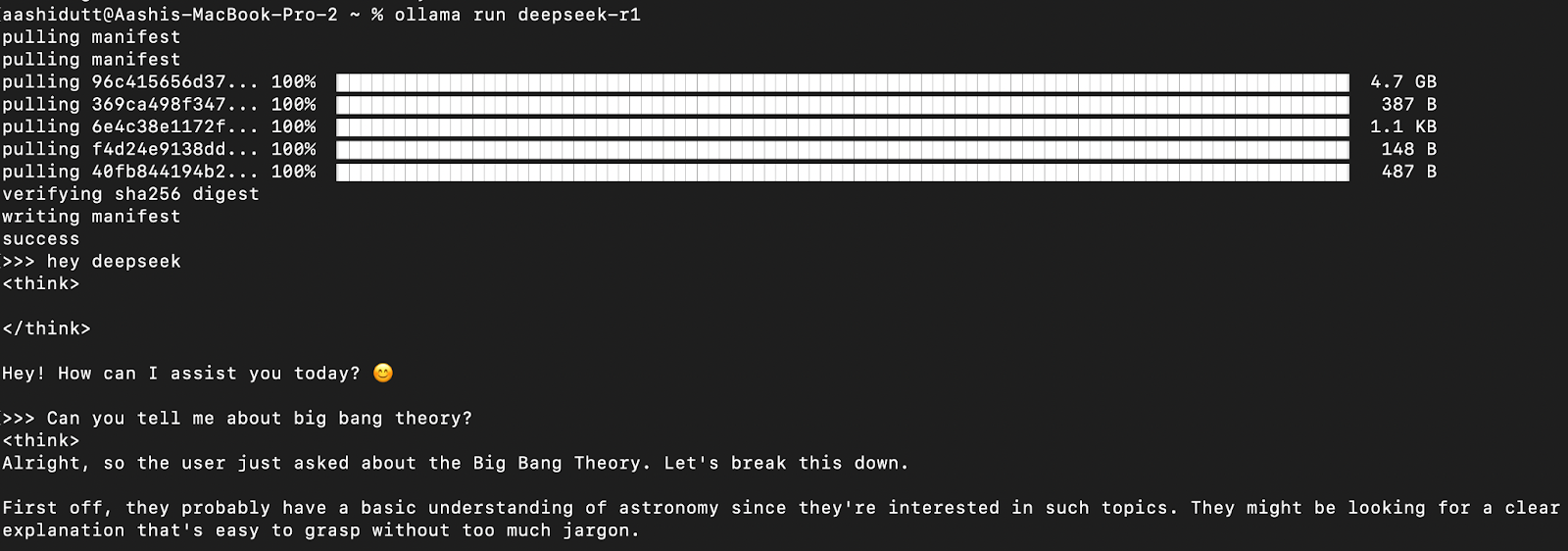
Let’s test the setup and download our model. Launch the terminal and type the following command.
ollama run deepseek-r1Ollama offers a range of DeepSeek R1 models, spanning from 1.5B parameters to the full 671B parameter model. The 671B model is the original DeepSeek-R1, while the smaller models are distilled versions based on Qwen and Llama architectures. If your hardware cannot support the 671B model, you can easily run a smaller version by using the following command and replacing the X below with the parameter size you want (1.5b, 7b, 8b, 14b, 32b, 70b, 671b):
ollama run deepseek-r1:XbWith this flexibility, you can use DeepSeek-R1's capabilities even if you don’t have a supercomputer.
To run DeepSeek-R1 continuously and serve it via an API, start the Ollama server:
ollama serveThis will make the model available for integration with other applications.
Once the model is downloaded, you can interact with DeepSeek-R1 directly in the terminal.
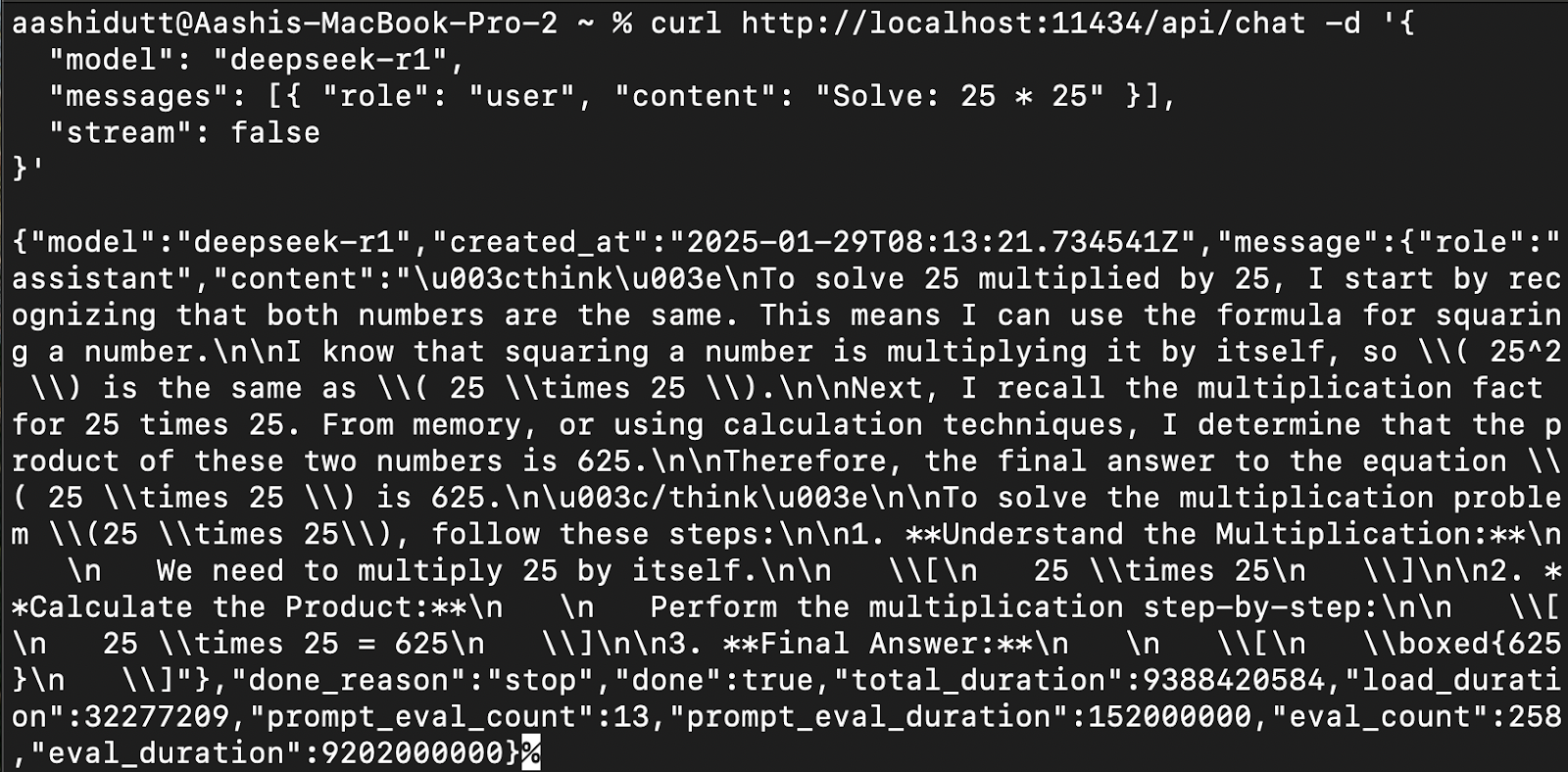
To integrate DeepSeek-R1 into applications, use the Ollama API using curl:
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "Solve: 25 * 25" }],
"stream": false
}'curl is a command-line tool native to Linux but also works on macOS. It allows users to make HTTP requests directly from the terminal, making it an excellent tool for interacting with APIs.
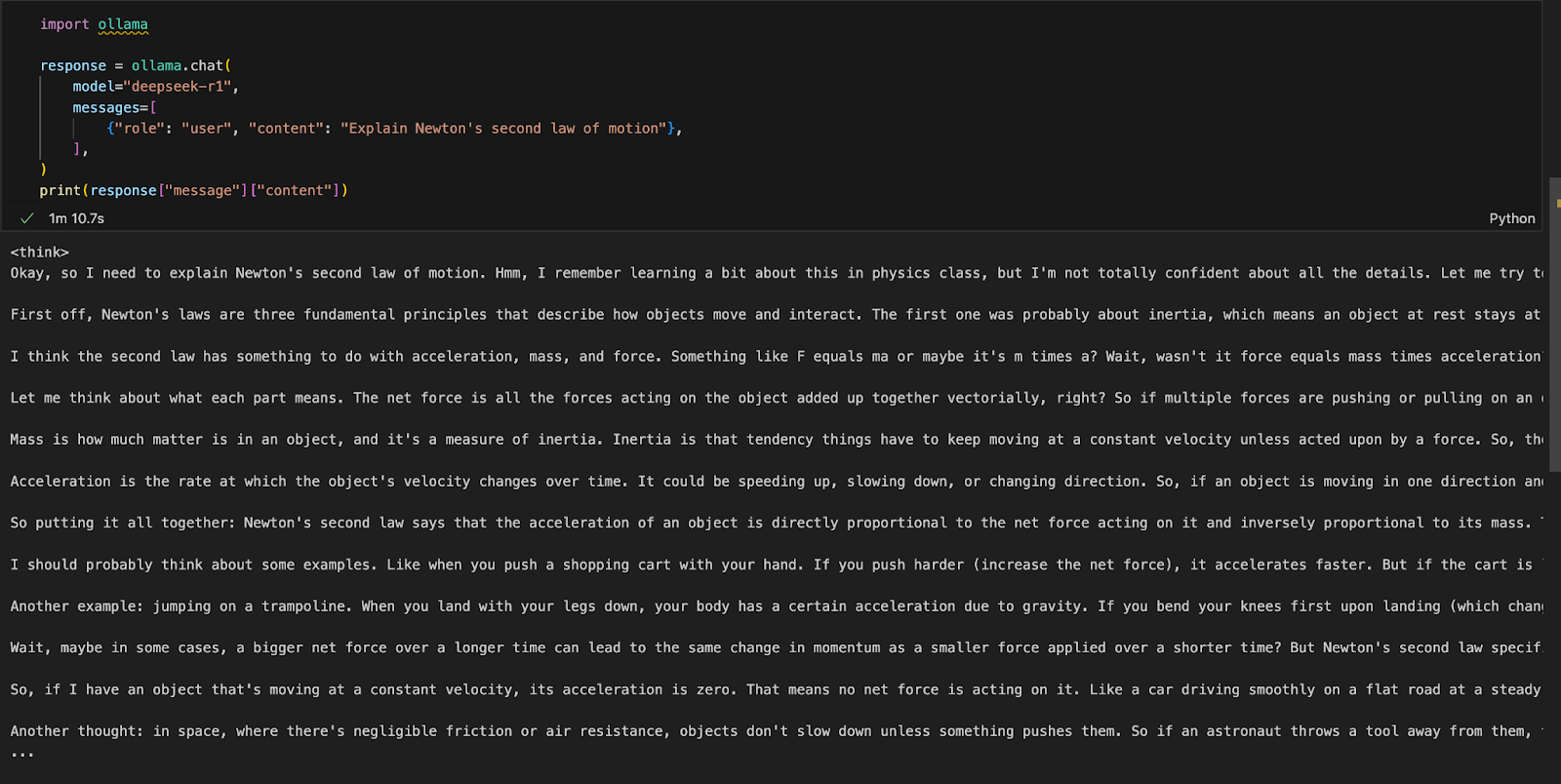
We can run Ollama in any integrated development environment (IDE) of choice. You can install the Ollama Python package using the following code:
!pip install ollamaOnce Ollama is installed, use the following script to interact with the model:
import ollama
response = ollama.chat(
model="deepseek-r1",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])The ollama.chat() function takes the model name and a user prompt, processing it as a conversational exchange. The script then extracts and prints the model's response.
Let’s build a simple demo app using Gradio to query and analyze documents with DeepSeek-R1.
Before diving into the implementation, let’s ensure that we have the following tools and libraries installed:
Run the following commands to install the necessary dependencies:
!pip install langchain chromadb gradio
!pip install -U langchain-communityOnce the above dependencies are installed, run the following import commands:
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollamaOnce the libraries are imported, we will process the uploaded PDF.
def process_pdf(pdf_bytes):
if pdf_bytes is None:
return None, None, None
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=100
)
chunks = text_splitter.split_documents(data)
embeddings = OllamaEmbeddings(model="deepseek-r1")
vectorstore = Chroma.from_documents(
documents=chunks, embedding=embeddings, persist_directory="./chroma_db"
)
retriever = vectorstore.as_retriever()
return text_splitter, vectorstore, retrieverThe process_pdf function:
PyMuPDFLoader.RecursiveCharacterTextSplitter.OllamaEmbeddings.Once the embeddings are retrieved, next we need to stitch these together. The combine_docs() function merges multiple retrieved document chunks into a single string.
def combine_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)Since retrieval-based models pull relevant excerpts rather than entire documents, this function ensures that the extracted content remains readable and properly formatted before being passed to DeepSeek-R1.
Now, our input to the model is ready. Let’s set up DeepSeek R1 using Ollama.
import re
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(
model="deepseek-r1",
messages=[{"role": "user", "content": formatted_prompt}],
)
response_content = response["message"]["content"]
# Remove content between <think> and </think> tags to remove thinking output
final_answer = re.sub(r"<think>.*?</think>", "", response_content, flags=re.DOTALL).strip()
return final_answerThe ollama_llm() function formats the user’s question and the retrieved document context into a structured prompt. This formatted input is then sent to DeepSeek-R1 via ollama.chat(), which processes the question within the given context and returns a relevant answer. If you need the answer without the model's thinking script, use the strip() function to return the final answer.
Now we have all the required components, let’s build the RAG pipeline for our demo.
def rag_chain(question, text_splitter, vectorstore, retriever):
retrieved_docs = retriever.invoke(question)
formatted_content = combine_docs(retrieved_docs)
return ollama_llm(question, formatted_content)The above function first searches the vector store using retriever.invoke(question), returning the most relevant document excerpts. These excerpts are formatted into a structured input using combine_docs function and sent to ollama_llm, ensuring that DeepSeek-R1 generates well-informed answers based on the retrieved content.
We have our RAG pipeline in place. Now, we can build the Gradio interface locally along with the DeepSeek-R1 model to process PDF input and ask questions related to it.
def ask_question(pdf_bytes, question):
text_splitter, vectorstore, retriever = process_pdf(pdf_bytes)
if text_splitter is None:
return None # No PDF uploaded
result = rag_chain(question, text_splitter, vectorstore, retriever)
return {result}
interface = gr.Interface(
fn=ask_question,
inputs=[
gr.File(label="Upload PDF (optional)"),
gr.Textbox(label="Ask a question"),
],
outputs="text",
title="Ask questions about your PDF",
description="Use DeepSeek-R1 to answer your questions about the uploaded PDF document.",
)
interface.launch()We do the following steps:
process_pdf function to extract text and generate document embeddings.rag_chain() function to retrieve relevant information and generate a contextually accurate response.gr.Interface() function, accepting a PDF file and a text query as inputs.interface.launch() to enable seamless, interactive document-based Q&A via a web browser.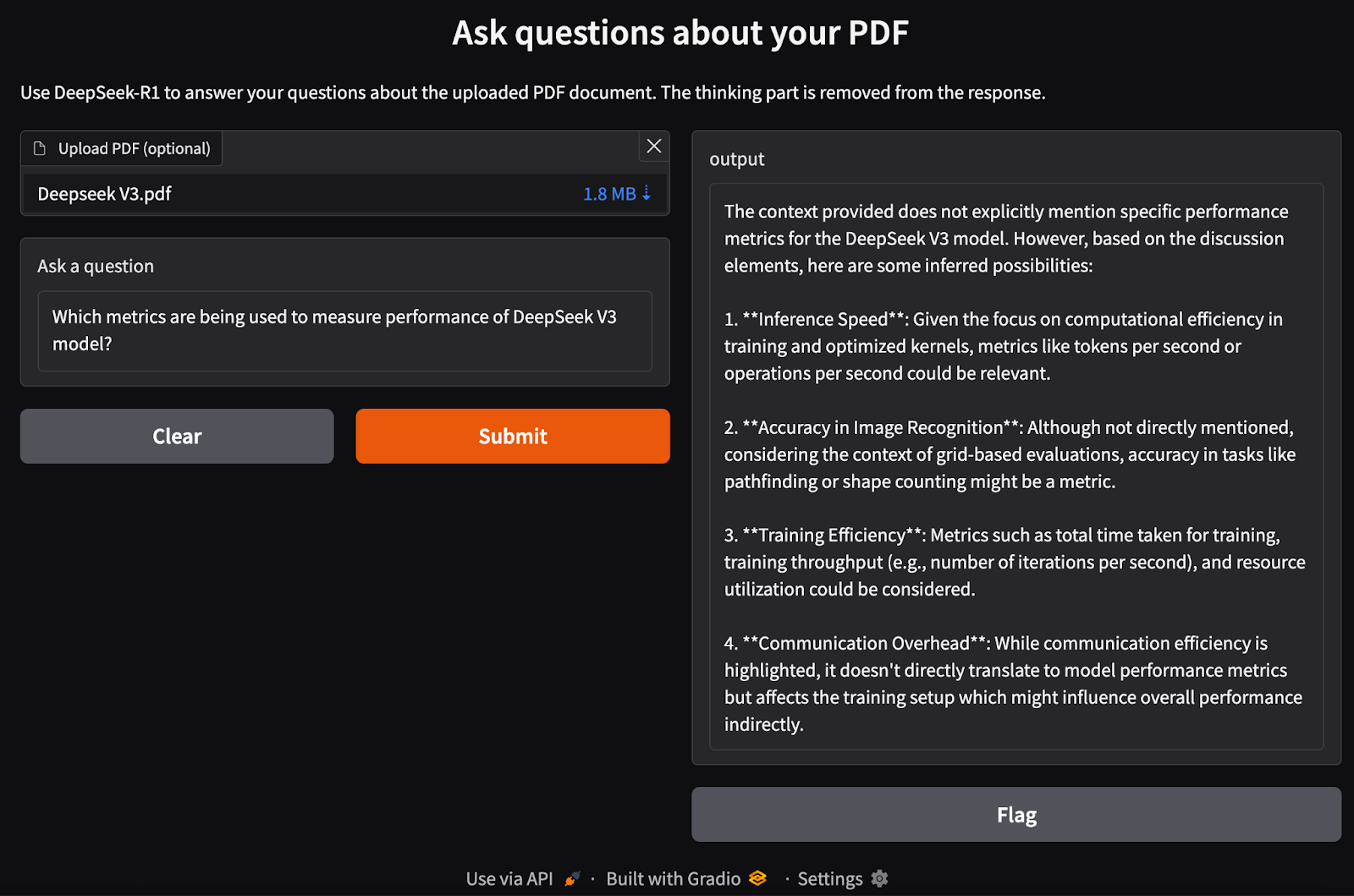
Running DeepSeek-R1 locally with Ollama enables faster, private, and cost-effective model inference. With a simple installation process, CLI interaction, API support, and Python integration, you can use DeepSeek-R1 for a variety of AI applications, from general queries to complex retrieval-based tasks.
To keep up with the latest developments in AI, I recommend these blogs:
Learn AI with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Aashi Dutt
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
