
Kurs
Einführung in LLMs mit Python
3 Std.
33.6K
DeepSeek hat die KI-Landschaft aufgemischt und die Vorherrschaft von OpenAI mit einer neuen Reihe von fortschrittlichen Denkmodellen herausgefordert. Und das Beste daran? Diese Modelle sind völlig frei und ohne Einschränkungen nutzbar, sodass sie für jeden zugänglich sind.
In diesem Lernprogramm werden wir das Modell DeepSeek-R1-Distill-Llama-8B anhand des medizinischen Chain-of-Thought-Datensatzes von Hugging Face feinabstimmen. Dieses destillierte DeepSeek-R1-Modell wurde durch eine Feinabstimmung des Llama 3.1 8B-Modells auf die mit DeepSeek-R1 erzeugten Daten erstellt. Es verfügt über ähnliche Argumentationsfähigkeiten wie das ursprüngliche Modell.
Wenn du dich noch nicht mit LLMs und Feintuning befasst hast, empfehle ich dir den Kurs Einführung in LLMs in Python Kurs.

Bild vom Autor
Das chinesische KI-Unternehmen DeepSeek AI hat seine Denkmodelle der ersten Generation, DeepSeek-R1 und DeepSeek-R1-Zero, veröffentlicht, die in Bezug auf die Leistung bei Denkaufgaben wie Mathematik, Codierung und Logik mit OpenAIs o1 konkurrieren. Du kannst unseren vollständigen Leitfaden zu DeepSeek R1 um mehr zu erfahren.
DeepSeek-R1-Zero ist das erste Open-Source-Modell, das ausschließlich mit groß angelegtem Reinforcement Learning (RL) anstelle von überwachter Feinabstimmung (SFT) trainiert. Dieser Ansatz ermöglicht es dem Modell, unabhängig die chain-of-thought (CoT) zu erforschen, komplexe Probleme zu lösen und seine Ergebnisse iterativ zu verfeinern. Allerdings gibt es auch Herausforderungen wie sich wiederholende Argumentationsschritte, schlechte Lesbarkeit und Sprachmischung, die die Klarheit und Benutzerfreundlichkeit beeinträchtigen können.
DeepSeek-R1 wurde eingeführt, um die Beschränkungen von DeepSeek-R1-Zero zu überwinden, indem Kaltstartdaten vor dem Verstärkungslernen einbezogen werden und so eine solide Grundlage für schlussfolgernde und nicht schlussfolgernde Aufgaben geschaffen wird.
Dieses mehrstufige Training ermöglicht es dem Modell, bei Mathematik-, Code- und Argumentations-Benchmarks eine mit OpenAI-o1 vergleichbare Spitzenleistung zu erzielen und gleichzeitig die Lesbarkeit und Kohärenz der Ergebnisse zu verbessern.
Neben den großen Sprachmodellen, die viel Rechenleistung und Speicherplatz benötigen, hat DeepSeek auch destillierte Modelle eingeführt. Diese kleineren, effizienteren Modelle haben gezeigt, dass sie immer noch eine bemerkenswerte Denkleistung erbringen können.
Mit einer Bandbreite von 1,5B bis 70B Parametern verfügen diese Modelle über starke Argumentationsfähigkeiten, wobei DeepSeek-R1-Distill-Qwen-32B die OpenAI-o1-mini in mehreren Benchmarks übertrifft.
Kleinere Modelle übernehmen die Argumentationsmuster der größeren Modelle und zeigen so die Effektivität des Destillationsprozesses.
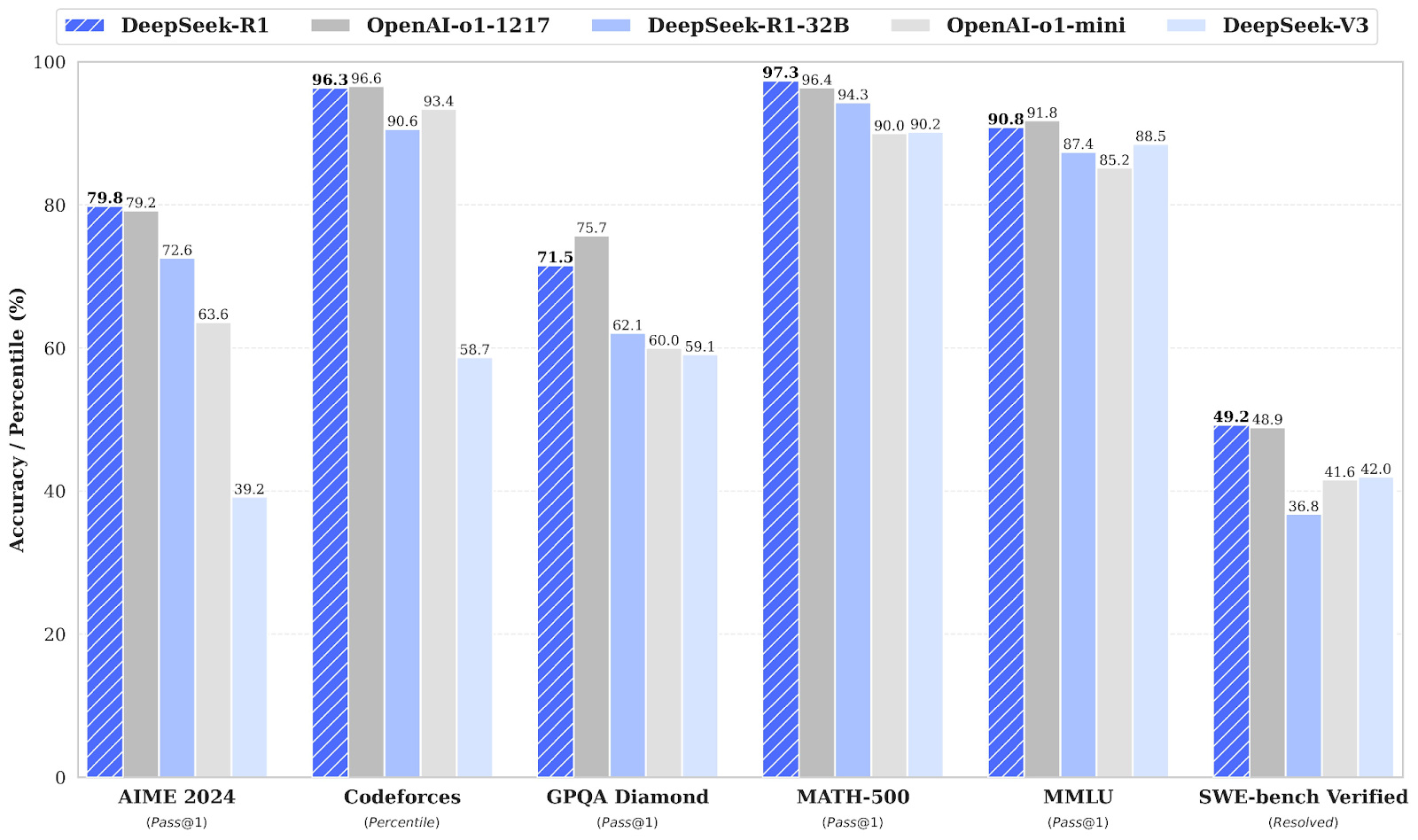
Quelle: deepseek-ai/DeepSeek-R1
Lies die DeepSeek-R1: Funktionen, o1-Vergleich, destillierte Modelle & mehr Blog, um mehr über die wichtigsten Funktionen, den Entwicklungsprozess, destillierte Modelle, den Zugang, die Preise und den Vergleich mit OpenAI o1 zu erfahren.
Um das DeepSeek R1-Modell fein abzustimmen, kannst du die folgenden Schritte ausführen:
Für dieses Projekt nutzen wir Kaggle als Cloud-IDE, weil es kostenlosen Zugang zu GPUs bietet, die oft leistungsfähiger sind als die in Google Colab verfügbaren. Um loszulegen, erstellst du ein neues Kaggle-Notizbuch und fügst deinen Hugging Face Token und deinen Weights & Biases Token als Geheimnisse hinzu.
Du kannst Geheimnisse hinzufügen, indem du in der Kaggle-Notebook-Oberfläche zum Reiter Add-ons navigierst und die Option Secrets auswählst.
Nachdem du die Geheimnisse eingerichtet hast, installiere das unsloth Python-Paket. Unsloth ist ein Open-Source-Framework, das die Feinabstimmung großer Sprachmodelle (LLMs) um den Faktor 2 schneller und speichereffizienter machen soll.
Lies unseren Unsloth Guide: Optimiere und beschleunige die LLM-Feinabstimmung, um mehr über die wichtigsten Funktionen von Unsloth zu erfahren und zu lernen, wie du deinen Feinabstimmungs-Workflow optimieren kannst .
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.gitMelde dich bei der CLI von Hugging Face an, indem du die API von Hugging Face verwendest, die wir sicher von Kaggle Secrets extrahiert haben.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Melde dich mit deinem API-Schlüssel bei Weights & Biases (wandb) an und erstelle ein neues Projekt, um die Versuche und den Fortschritt der Feinabstimmung zu verfolgen.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)Für dieses Projekt laden wir die Unsloth-Version von DeepSeek-R1-Distill-Llama-8B. Außerdem laden wir das Modell in 4-Bit-Quantisierung, um die Speichernutzung und die Leistung zu optimieren.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)Um einen Prompt-Stil für das Modell zu erstellen, definieren wir einen Systemprompt und fügen Platzhalter für die Frage- und Antwortgenerierung hinzu. Die Aufforderung leitet das Modell an, Schritt für Schritt zu denken und eine logische, genaue Antwort zu geben.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""In diesem Beispiel geben wir eine medizinische Frage an prompt_style weiter, wandeln sie in Token um und übergeben die Token dann an das Modell, um eine Antwort zu generieren.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])Auch ohne Feinabstimmung hat unser Modell erfolgreich eine Gedankenkette erzeugt und Argumente geliefert, bevor es die endgültige Antwort lieferte. Der Denkprozess ist in den <think></think>-Tags gekapselt.
Warum brauchen wir also noch eine Feinabstimmung? Der Begründungsprozess war zwar detailliert, aber langatmig und nicht prägnant. Außerdem wurde die endgültige Antwort in Form von Aufzählungspunkten präsentiert, was von der Struktur und dem Stil des Datensatzes abweicht, an dem wir die Feinabstimmung vornehmen wollen.
<think>
Okay, so I have this medical question to answer. Let me try to break it down. The patient is a 61-year-old woman with a history of involuntary urine loss during activities like coughing or sneezing, but she doesn't leak at night. She's had a gynecological exam and a Q-tip test. I need to figure out what cystometry would show regarding her residual volume and detrusor contractions.
First, I should recall what I know about urinary incontinence. Involuntary urine loss during activities like coughing or sneezing makes me think of stress urinary incontinence. Stress incontinence typically happens when the urethral sphincter isn't strong enough to resist increased abdominal pressure from activities like coughing, laughing, or sneezing. This usually affects women, especially after childbirth when the pelvic muscles and ligaments are weakened.
The Q-tip test is a common diagnostic tool for stress urinary incontinence. The test involves inserting a Q-tip catheter, which is a small balloon catheter, into the urethra. The catheter is connected to a pressure gauge. The patient is asked to cough, and the pressure reading is taken. If the pressure is above normal (like above 100 mmHg), it suggests that the urethral sphincter isn't closing properly, which is a sign of stress incontinence.
So, based on the history and the Q-tip test, the diagnosis is likely stress urinary incontinence. Now, moving on to what cystometry would show. Cystometry, also known as a filling cystometry, is a diagnostic procedure where a catheter is inserted into the bladder, and the bladder is filled with a liquid to measure how much it can hold (residual volume) and how it responds to being filled (like during a cough or sneeze). This helps in assessing the capacity and compliance of the bladder.
In a patient with stress incontinence, the bladder's capacity might be normal, but the sphincter's function is impaired. So, during the cystometry, the residual volume might be within normal limits because the bladder isn't overfilled. However, when the patient is asked to cough or perform a Valsalva maneuver, the detrusor muscle (the smooth muscle layer of the bladder) might not contract effectively, leading to an increase in intra-abdominal pressure, which might cause leakage.
Wait, but detrusor contractions are usually associated with voiding. In stress incontinence, the issue isn't with the detrusor contractions but with the sphincter's inability to prevent leakage. So, during cystometry, the detrusor contractions would be normal because they are part of the normal voiding process. However, the problem is that the sphincter doesn't close properly, leading to leakage.
So, putting it all together, the residual volume might be normal, but the detrusor contractions would be normal as well. The key finding would be the impaired sphincter function leading to incontinence, which is typically demonstrated during the Q-tip test and clinical history. Therefore, the cystometry would likely show normal residual volume and normal detrusor contractions, but the underlying issue is the sphincter's inability to prevent leakage.
</think>
Based on the provided information, the cystometry findings in this 61-year-old woman with stress urinary incontinence would likely demonstrate the following:
1. **Residual Volume**: The residual volume would be within normal limits. This is because the bladder's capacity is typically normal in cases of stress incontinence, where the primary issue lies with the sphincter function rather than the bladder's capacity.
2. **Detrusor Contractions**: The detrusor contractions would also be normal. These contractions are part of the normal voiding process and are not impaired in stress urinary incontinence. The issue is not with the detrusor muscle but with the sphincter's inability to prevent leakage.
In summary, the key findings of the cystometry would be normal residual volume and normal detrusor contractions, highlighting the sphincteric defect as the underlying cause of the incontinence.<|end▁of▁sentence|>Wir werden den Prompt-Stil für die Verarbeitung des Datensatzes leicht verändern, indem wir den dritten Platzhalter für die Spalte "Komplexe Gedankenkette" hinzufügen.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Schreibe die Python-Funktion, die eine "Text"-Spalte im Datensatz erstellt, die aus dem Stil der Zugabfrage besteht. Fülle die Platzhalter mit Fragen, Textketten und Antworten.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Wir laden die ersten 500 Proben aus dem FreedomIntelligence/medical-o1-reasoning-SFT geladen, die im Hugging Face Hub verfügbar sind. Danach werden wir die Spalte text mit der Funktion formatting_prompts_func zuordnen.
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]Wie wir sehen können, enthält die Textspalte eine Systemaufforderung, Anweisungen, eine Gedankenkette und die Antwort.
"Below is an instruction that describes a task, paired with an input that provides further context. \nWrite a response that appropriately completes the request. \nBefore answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.\n\n### Instruction:\nYou are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. \nPlease answer the following medical question. \n\n### Question:\nA 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?\n\n### Response:\n<think>\nOkay, let's think about this step by step. There's a 61-year-old woman here who's been dealing with involuntary urine leakages whenever she's doing something that ups her abdominal pressure like coughing or sneezing. This sounds a lot like stress urinary incontinence to me. Now, it's interesting that she doesn't have any issues at night; she isn't experiencing leakage while sleeping. This likely means her bladder's ability to hold urine is fine when she isn't under physical stress. Hmm, that's a clue that we're dealing with something related to pressure rather than a bladder muscle problem. \n\nThe fact that she underwent a Q-tip test is intriguing too. This test is usually done to assess urethral mobility. In stress incontinence, a Q-tip might move significantly, showing urethral hypermobility. This kind of movement often means there's a weakness in the support structures that should help keep the urethra closed during increases in abdominal pressure. So, that's aligning well with stress incontinence.\n\nNow, let's think about what would happen during cystometry. Since stress incontinence isn't usually about sudden bladder contractions, I wouldn't expect to see involuntary detrusor contractions during this test. Her bladder isn't spasming or anything; it's more about the support structure failing under stress. Plus, she likely empties her bladder completely because stress incontinence doesn't typically involve incomplete emptying. So, her residual volume should be pretty normal. \n\nAll in all, it seems like if they do a cystometry on her, it will likely show a normal residual volume and no involuntary contractions. Yup, I think that makes sense given her symptoms and the typical presentations of stress urinary incontinence.\n</think>\nCystometry in this case of stress urinary incontinence would most likely reveal a normal post-void residual volume, as stress incontinence typically does not involve issues with bladder emptying. Additionally, since stress urinary incontinence is primarily related to physical exertion and not an overactive bladder, you would not expect to see any involuntary detrusor contractions during the test.<|end▁of▁sentence|>"Mit den Zielmodulen richten wir das Modell ein, indem wir den Low-Rank-Adopter in das Modell aufnehmen.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)Als Nächstes richten wir die Trainingsargumente und den Trainer ein, indem wir das Modell, die Tokenizer, den Datensatz und andere wichtige Trainingsparameter angeben, die unseren Feinabstimmungsprozess optimieren werden.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)Führe den folgenden Befehl aus, um das Training zu starten.
trainer_stats = trainer.train()Der Ausbildungsprozess dauerte 44 Minuten. Der Trainingsverlust hat sich allmählich verringert, was ein gutes Zeichen für eine bessere Modellleistung ist.
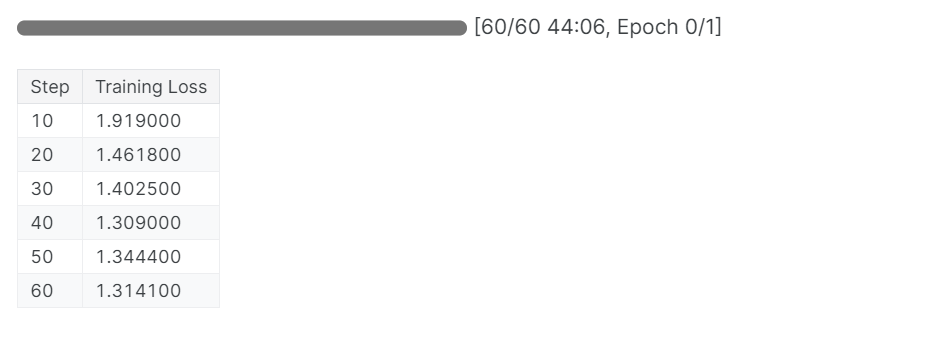
Du kannst den Bewertungsbericht für das Füllmodell auf dem Dashboard für Gewichte und Bais einsehen, indem du dich auf der Website einloggst und das Projekt aufrufst.
Wenn du Probleme beim Ausführen des obigen Codes hast, lies bitte den Abschnitt Feinabstimmung von DeepSeek R1 (Reasoning Model) Kaggle Notizbuch.
Um die Ergebnisse zu vergleichen, stellen wir dem feinabgestimmten Modell dieselbe Frage wie zuvor, um zu sehen, was sich verändert hat.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Das ist viel besser und genauer. Die Gedankenkette war direkt, und die Antwort war einfach und in einem Absatz. Die Feinabstimmung war erfolgreich.
<think>
Okay, so let's think about this. We have a 61-year-old woman who's been dealing with involuntary urine loss during things like coughing or sneezing, but she's not leaking at night. That suggests she might have some kind of problem with her pelvic floor muscles or maybe her bladder.
Now, she's got a gynecological exam and a Q-tip test. Let's break that down. The Q-tip test is usually used to check for urethral obstruction. If it's positive, that means there's something blocking the urethra, like a urethral stricture or something else.
Given that she's had a positive Q-tip test, it's likely there's a urethral obstruction. That would mean her urethra is narrow, maybe due to a stricture or some kind of narrowing. So, her bladder can't empty properly during activities like coughing because the urethral obstruction is making it hard.
Now, let's think about what happens when her bladder can't empty. If there's a urethral obstruction, the bladder is forced to hold more urine, increasing the residual volume. That's because her bladder doesn't empty completely. So, her residual volume is probably increased.
Also, if her bladder can't empty properly, she might have increased detrusor contractions. These contractions are usually stronger to push the urine out. So, we expect her detrusor contractions to be increased.
Putting it all together, if she has a urethral obstruction and a positive Q-tip test, we'd expect her cystometry results to show increased residual volume and increased detrusor contractions. That makes sense because of the obstruction and how her bladder is trying to compensate by contracting more.
</think>
Based on the findings of the gynecological exam and the positive Q-tip test, it is most likely that the cystometry would reveal increased residual volume and increased detrusor contractions. The positive Q-tip test indicates urethral obstruction, which would force the bladder to retain more urine, thereby increasing the residual volume. Additionally, the obstruction can lead to increased detrusor contractions as the bladder tries to compensate by contracting more to expel the urine.<|end▁of▁sentence|>
Jetzt wollen wir den Adopter, das vollständige Modell und den Tokenizer lokal speichern, damit wir sie in anderen Projekten verwenden können.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
Wir werden den Adopter, den Tokenizer und das Modell auch an Hugging Face Hub weitergeben, damit die KI-Community dieses Modell in ihre Systeme integrieren kann.
new_model_online = "kingabzpro/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method = "merged_16bit")
Quelle: kingabzpro/DeepSeek-R1-Medical-COT - Hugging Face
Der nächste Schritt auf deiner Lernreise ist die Bereitstellung deines Modells in der Cloud. Du kannst die Anleitung Wie man LLMs mit BentoML einsetzt Anleitung folgen, in der du Schritt für Schritt erfährst, wie du große Sprachmodelle mit BentoML und Tools wie vLLM effizient und kostengünstig einsetzen kannst.
Wenn du das Modell lieber lokal verwenden möchtest, kannst du es auch in das GGUF-Format konvertieren und auf deinem Rechner ausführen. Schau dir dazu die Feinabstimmung von Llama 3.2 und seine lokale Nutzung der detaillierte Anweisungen für die lokale Nutzung enthält.
Die Dinge ändern sich schnell im Bereich der KI. Die Open-Source-Community übernimmt nun das Ruder und stellt die Dominanz der proprietären Modelle in Frage, die die KI-Landschaft in den letzten drei Jahren beherrscht haben.
Open-Source-Language-Modelle (LLMs) werden immer besser, schneller und effizienter, so dass es einfacher denn je ist, sie mit geringeren Rechen- und Speicherressourcen fein abzustimmen.
In diesem Tutorial haben wir das Reasoning-Modell DeepSeek R1 erkundet und gelernt, wie man seine destillierte Version für medizinische Q&A-Aufgaben feinabstimmen kann. Ein fein abgestimmtes Reasoning-Modell verbessert nicht nur die Leistung, sondern ermöglicht auch die Anwendung in kritischen Bereichen wie Medizin, Notfalldienste und Gesundheitswesen.
Als Reaktion auf die Einführung von DeepSeek R1 hat OpenAI zwei leistungsstarke Tools eingeführt: OpenAIs o3, ein fortschrittlicheres Argumentationsmodell, und OpenAIs Operator KI-Agent, der auf dem neuen Computer-Using-Agent (CUA)-Modell basiert und selbstständig durch Websites navigieren und Aufgaben erledigen kann.
Top DataCamp Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
