Lernpfad
Grundlagen der KI
10 Std.
Alibaba hat gerade Qwen2.5-Maxveröffentlicht , sein bisher fortschrittlichstes KI-Modell. Es handelt sich nicht um ein Argumentationsmodell wie DeepSeek R1 oder OpenAIs o1, das heißt, du kannst seinen Denkprozess nicht sehen.
Es ist besser, Qwen2.5-Max als generalistisches Modell zu betrachten und als Konkurrenz zu GPT-4o, Claude 3.5 Sonnet oder DeepSeek V3.
In diesem Blog gehe ich darauf ein, was Qwen2.5-Max ist, wie es entwickelt wurde, wie es sich von der Konkurrenz abhebt und wie du es nutzen kannst.
Qwen2.5-Max ist das bisher leistungsstärkste KI-Modell von Alibaba, das mit Spitzenmodellen wie GPT-4o, Claude 3.5 Sonnet und DeepSeek V3 konkurrieren soll.
Alibaba, eines der größten Tech-Unternehmen Chinas, ist vor allem für seine E-Commerce-Plattformen bekannt, hat sich aber auch eine starke Präsenz im Cloud Computing und künstlicher Intelligenz. Die Qwen-Reihe ist Teil des breiteren KI-Ökosystems, das von kleineren offenen Modellen bis hin zu großen proprietären Systemen reicht.

Im Gegensatz zu einigen früheren Qwen-Modellen ist Qwen2.5-Max nicht quelloffen, d.h. seine Gewichte sind nicht öffentlich zugänglich.
Qwen2.5-Max wurde auf 20 Billionen Token trainiert und verfügt über eine umfangreiche Wissensbasis und starke allgemeine KI-Fähigkeiten. Es ist jedoch kein Denkmodell wie DeepSeek R1 oder OpenAIs o1, d.h. es zeigt nicht explizit seinen Denkprozess. Angesichts der fortschreitenden KI-Expansion von Alibaba könnten wir jedoch in Zukunft ein spezielles Argumentationsmodell sehen - möglicherweise mit Qwen 3.
Qwen2.5-Max verwendet eine Mixture-of-Experts (MoE) Architektur, eine Technik, die auch von DeepSeek V3. Mit diesem Ansatz kann das Modell skaliert werden, während die Rechenkosten überschaubar bleiben. Schauen wir uns die wichtigsten Komponenten so an, dass sie leicht zu verstehen sind.
Im Gegensatz zu traditionellen KI-Modellen, die alle Parameter für jede Aufgabe nutzen, aktivieren MoE-Modelle wie Qwen2.5-Max und DeepSeek V3 nur die jeweils wichtigsten Teile des Modells.
Du kannst es dir wie ein Team von Spezialisten vorstellen: Wenn du eine komplexe Frage zur Physik stellst, antworten nur die Experten für Physik, während der Rest des Teams untätig bleibt. Diese selektive Aktivierung bedeutet, dass das Modell große Datenmengen effizienter verarbeiten kann, ohne extrem viel Rechenleistung zu benötigen.
Diese Methode macht Qwen2.5-Max sowohl leistungsfähig als auch skalierbar und ermöglicht es, sich mit dichten Modellen wie GPT-4o und Claude 3.5 Sonnet konkurrieren und gleichzeitig ressourceneffizienter sein - ein dichtes Modell ist ein Modell, bei dem alle Parameter für jede Eingabe aktiviert werden.
Qwen2.5-Max wurde auf 20 Billionen Token trainiert, die eine große Bandbreite an Themen, Sprachen und Kontexten abdecken.
Um die 20 Billionen Token in die richtige Perspektive zu rücken, sind das etwa 15 Billionen Wörter - eine so große Menge, dass sie kaum zu fassen ist. Zum Vergleich: George Orwells 1984 enthält etwa 89.000 Wörter, was bedeutet, dass Qwen2.5-Max auf das Äquivalent von 168 Millionen Exemplaren von 1984 trainiert wurde .
Da rohe Trainingsdaten allein jedoch kein Garant für ein hochwertiges KI-Modell sind, hat Alibaba es weiter verfeinert:
Qwen2.5-Max wurde gegen andere führende KI-Modelle getestet, um seine Fähigkeiten bei verschiedenen Aufgaben zu messen. Diese Benchmarks bewerten sowohl Instruct-Modelle (die für Aufgaben wie Chatten und Codieren fein abgestimmt sind) als auch Basismodelle (die als Rohbasis vor der Feinabstimmung dienen). Wenn du diesen Unterschied verstehst, wird klar, was die Zahlen wirklich bedeuten.
Die Unterrichtsmodelle sind auf reale Anwendungen abgestimmt, darunter Konversation, Codierung und allgemeine Wissensaufgaben. Qwen2.5-Max wird hier mit Modellen wie GPT-4o, Claude 3.5 Sonnet verglichen, Llama 3.1 405Bund DeepSeek V3.
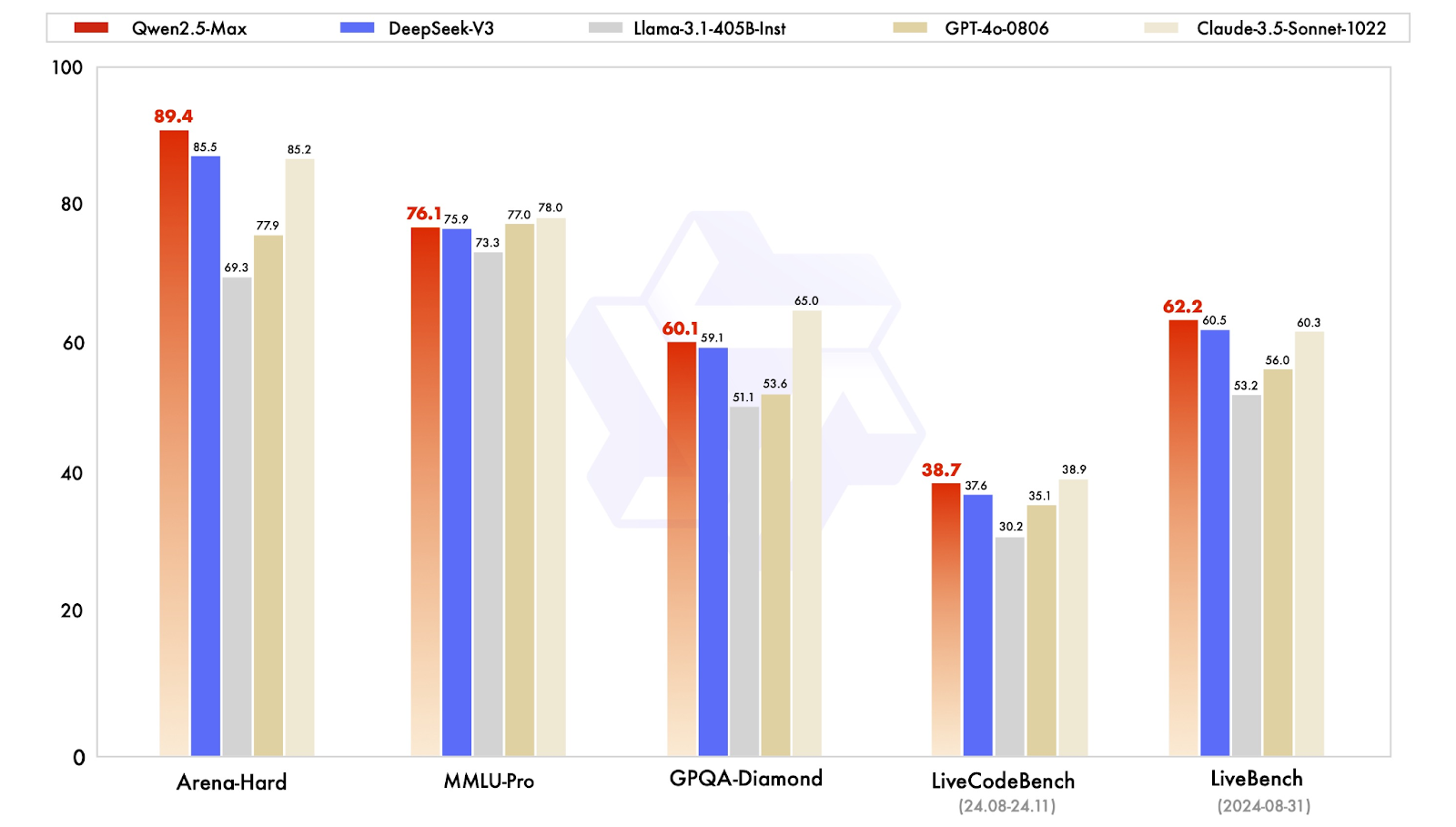
Vergleich der Instruktionsmodelle. Quelle: QwenLM
Schauen wir uns die Ergebnisse kurz an:
Insgesamt erweist sich Qwen2.5-Max als ein vielseitiges KI-Modell, das sich bei präferenzbasierten Aufgaben und allgemeinen KI-Fähigkeiten auszeichnet und gleichzeitig wettbewerbsfähige Kenntnisse und Programmierfähigkeiten besitzt.
Seit GPT-4o und Claude 3.5 Sonnet proprietäre Modelle ohne öffentlich verfügbare Basisversionen sind, beschränkt sich der Vergleich auf Modelle mit offenem Gewicht wie Qwen2.5-Max, DeepSeek V3, LLaMA 3.1-405B und Qwen 2.5-72B. Dadurch wird klarer, wie Qwen2.5-Max im Vergleich zu führenden offenen Großmodellen abschneidet.
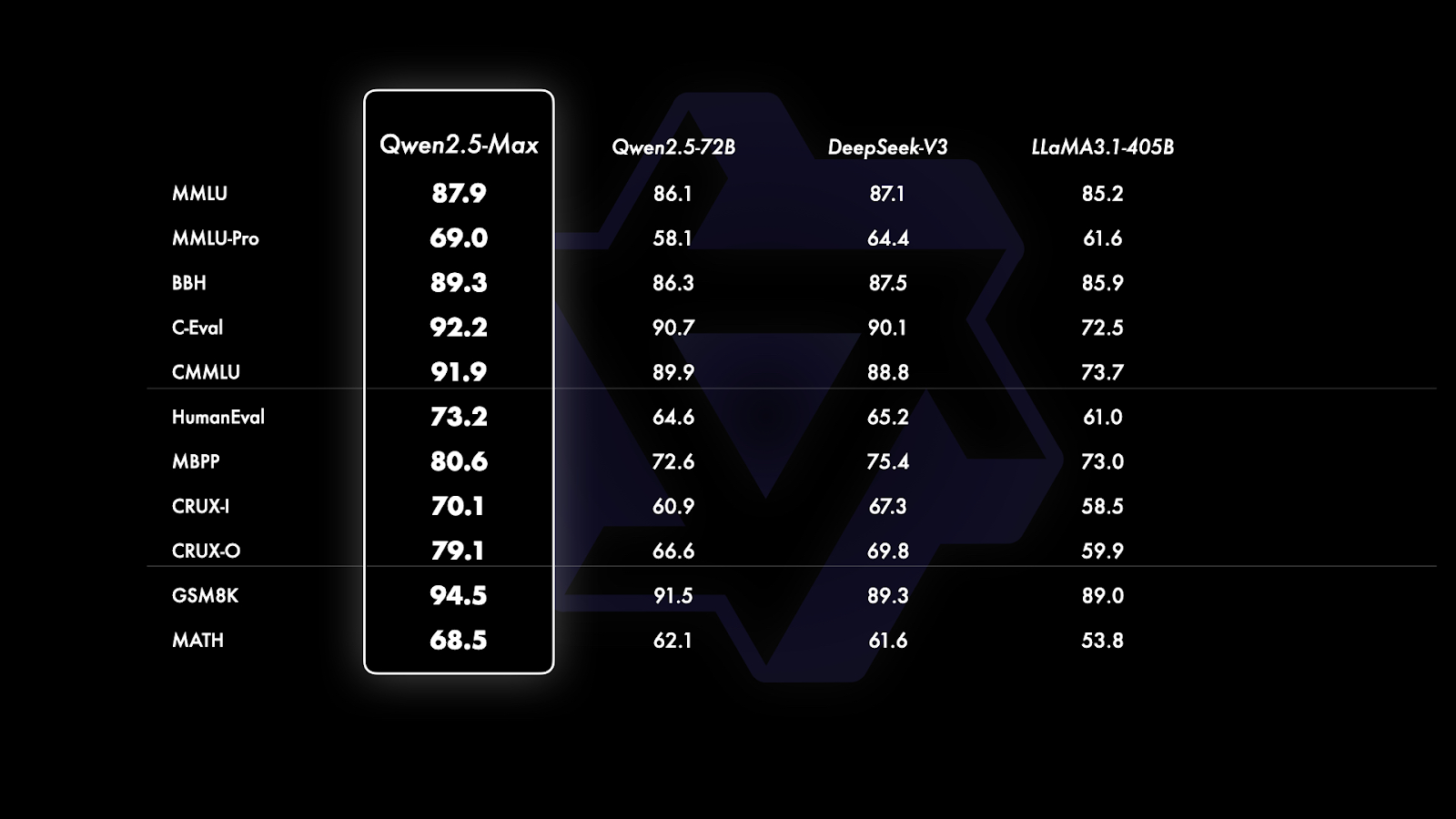
Vergleich der Basismodelle. Quelle: QwenLM
Wenn du dir die Grafik oben genau ansiehst, ist sie in drei Abschnitte unterteilt, die sich auf die Art der bewerteten Benchmarks beziehen:
Der Zugang zu Qwen2.5-Max ist ganz einfach und du kannst es kostenlos und ohne komplizierte Einrichtung ausprobieren.
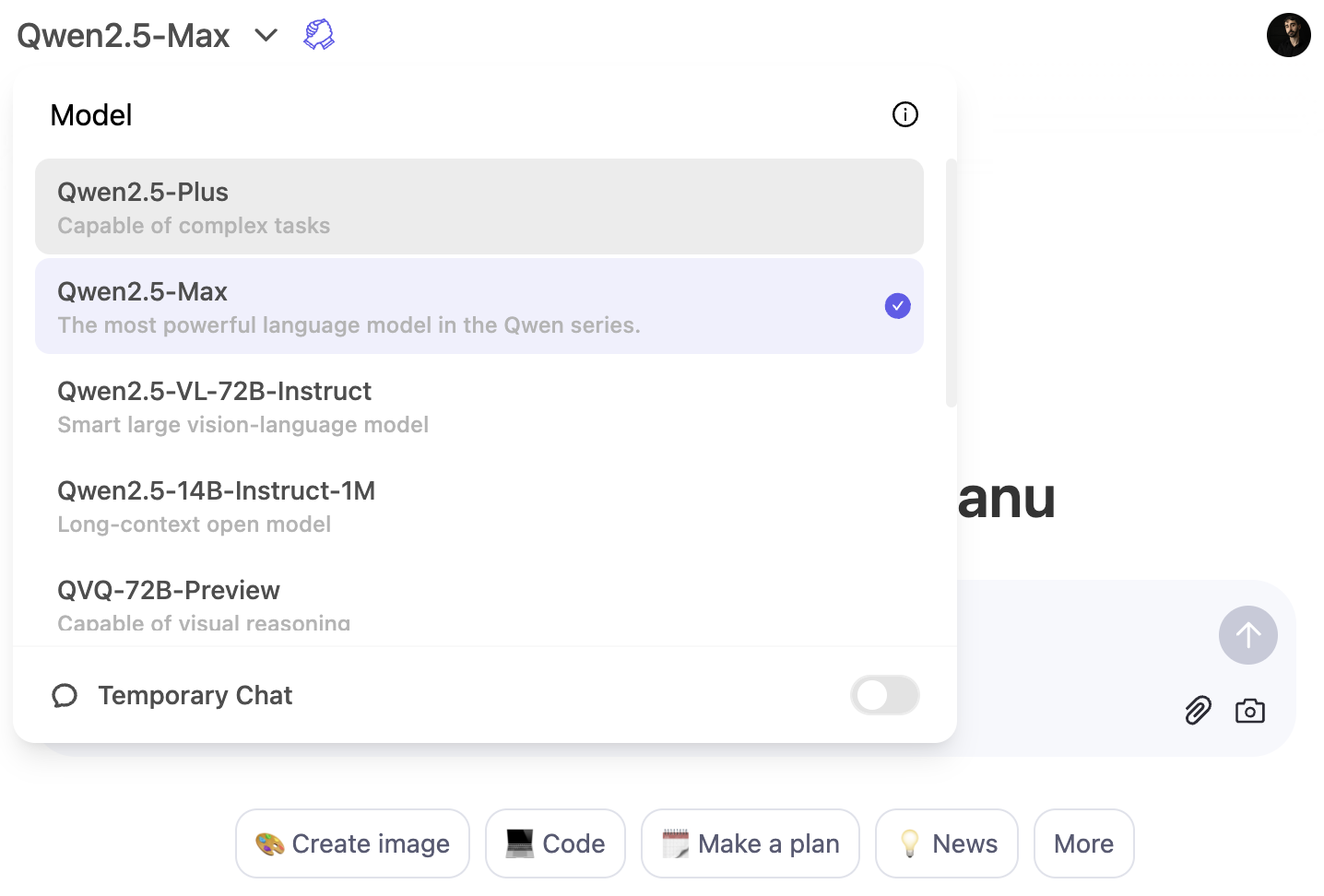
Der schnellste Weg, Qwen2.5-Max zu erleben, ist über den Qwen Chat Plattform. Dabei handelt es sich um eine webbasierte Schnittstelle, mit der du direkt in deinem Browser mit dem Modell interagieren kannst - so wie du ChatGPT in deinem Browser nutzen würdest.
Um das Modell Qwen2.5-Max zu verwenden, klicke auf das Modell-Dropdown-Menü und wähle Qwen2.5-Max:
Für Entwickler ist Qwen2.5-Max über die Alibaba Cloud Model Studio API verfügbar. Um es zu nutzen, musst du dich für ein Alibaba Cloud-Konto anmelden, den Model Studio-Dienst aktivieren und einen API-Schlüssel generieren.
Da die API dem Format von OpenAI folgt, sollte die Integration einfach sein, wenn du bereits mit den OpenAI-Modellen vertraut bist. Detaillierte Anweisungen zur Einrichtung findest du im offiziellen Qwen2.5-Max Blog.
Qwen2.5-Max ist das bisher leistungsstärkste KI-Modell von Alibaba, das mit Spitzenmodellen wie GPT-4o, Claude 3.5 Sonnet und DeepSeek V3 konkurrieren soll.
Im Gegensatz zu einigen früheren Qwen-Modellen ist Qwen2.5-Max nicht quelloffen, kann aber über den Qwen-Chat oder über den API-Zugang auf der Alibaba Cloud getestet werden.
Angesichts der kontinuierlichen Investitionen von Alibaba in KI wäre es nicht verwunderlich, wenn wir in Zukunft ein Modell sehen, das sich auf das Denken konzentriert - möglicherweise mit Qwen 3.
Wenn du mehr über KI lesen willst, empfehle ich dir diese Artikel:
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Tutorial
Matt Crabtree