
Lernpfad
Grundlagen des maschinellen Lernens in Python
16 Std.
Ein einzelner Entscheidungsbaum nach dem Prinzip „ “ ist leicht zu verstehen, neigt aber dazu, zu überanpassen. Ein einfaches lineares Modell lässt sich gut verallgemeinern, verpasst aber komplexe Muster. Jeder Modelltyp hat Schwachstellen, die seine Genauigkeit bei realen Daten einschränken.
Ensemble-Methoden lösen das, indem sie mehrere Modelle zu einem einzigen kombinieren. Anstatt sich auf einen einzigen Prädiktor zu verlassen, kombinieren sie Vorhersagen aus vielen Modellen, sodass sich einzelne Fehler gegenseitig aufheben. Das Ergebnis ist meistens genauer als jedes einzelne Modell für sich.
In diesem Tutorial zeig ich dir die Unterschiede zwischen den wichtigsten Ensemble-Methoden und konzentriere mich auf die beiden beliebtesten Ensemble-Algorithmen: Random Forest und XGBoost.
Du lernst, wie die beiden funktionieren, wendest sie auf ein Multiklassen-Klassifizierungsproblem an und vergleichst ihre Leistung. Das Ziel ist, dir ein praktisches Verständnis dafür zu geben, wann du welchen Ansatz verwenden solltest und wie du sie für deine eigenen Projekte anpassen kannst.
Wenn du noch mehr praktische Übungen suchst, empfehle ich dir den Kurs Kurs „Ensemble Methods in Python”.
Beim Ensemble-Lernen werden mehrere Modelle trainiert und ihre Vorhersagen zu einem einzigen Ergebnis zusammengefasst. Die Idee ist einfach: Verschiedene Modelle machen unterschiedliche Fehler, also gleicht man durch Mittelwertbildung oder Abstimmung über viele Modelle einzelne Fehler meistens aus.
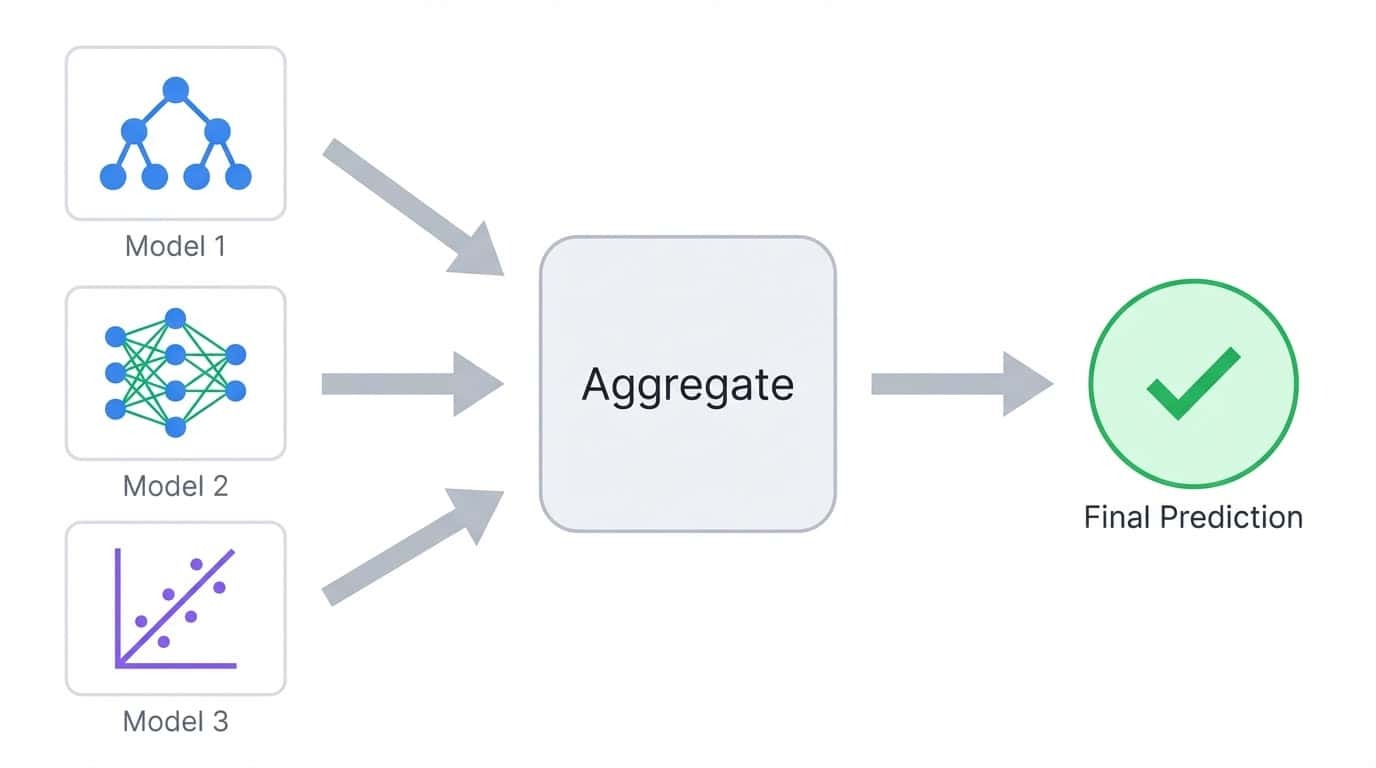
Beim Ensemble-Lernen werden die Vorhersagen von mehreren Modellen zu einem einzigen Ergebnis zusammengefasst.
Überleg dir mal eine Aufgabe, bei der du fünf Entscheidungsbäume trainierst. Jeder Baum trifft vielleicht 80 % der Vorhersagen richtig, aber sie werden nicht alle bei denselben Beispielen danebenliegen. Wenn du ihre Stimmen zusammenzählst, hat die Mehrheit oft recht, auch wenn ein oder zwei Bäume falsch liegen. Das ist das Hauptprinzip hinter allen Ensemble-Methoden.
Die Modelle in einem Ensemble werden als Basis-Lernerbezeichnet. Es kann sich um beliebige Algorithmen handeln, aber Entscheidungsbäume sind die häufigste Wahl, weil sie schnell trainiert werden können und bei unterschiedlichen Datenuntergruppen ganz natürlich vielfältige Vorhersagen liefern.
Modellfehler kommen aus zwei Quellen: Verzerrung und Varianz.
Voreingenommenheit ist der Fehler, der entsteht, wenn man das Problem zu stark vereinfacht. Ein lineares Modell, das versucht, eine gekrümmte Beziehung anzupassen, hat eine hohe Verzerrung, weil es das wahre Muster nicht darstellen kann, egal wie viele Daten du ihm gibst. Modelle mit hoher Verzerrung machen ähnliche Vorhersagen für verschiedene Trainingssätze, aber diese Vorhersagen sind immer daneben.
Die Varianz t der Fehler, der entsteht, wenn man zu empfindlich auf Trainingsdaten reagiert. Ein tiefer Entscheidungsbaum, der sich das Trainingsset merkt, hat eine hohe Varianz, weil er neben dem Signal auch Rauschen mit einfängt. Wenn du denselben Baum mit einer leicht abweichenden Stichprobe neu trainieren würdest, würdest du völlig andere Vorhersagen erhalten. Das Modell passt gut zu den Trainingsdaten, funktioniert aber nicht bei neuen Sachen.

Bias vs. Varianz, erklärt mit Dartscheiben: Hoher Bias bedeutet, dass die Vorhersagen zwar konsistent, aber daneben sind, während hohe Varianz für verstreute, inkonsistente Vorhersagen steht.
Du kannst dir das wie ein Stabilitätsproblem vorstellen. Modelle mit hoher Verzerrung sind zwar stabil, aber jedes Mal auf die gleiche Weise falsch. Modelle mit hoher Varianz sind instabil und auf unterschiedliche Weise falsch, je nachdem, welche Daten sie zufällig gesehen haben.
Das ideale Modell ist sowohl stabil als auch genau, aber wenn man eine Art von Fehler reduziert, wird oft die andere schlimmer.
Entscheidungsbäume gehören eindeutig zu den Sachen mit hoher Varianz. Sie nutzen gieriges Teilen, was bedeutet, dass schon kleine Änderungen in den Trainingsdaten ganz unterschiedliche Baumstrukturen erzeugen können.
Wenn du denselben Baumalgorithmus auf zwei zufälligen Stichproben aus derselben Population trainierst, bekommst du möglicherweise zwei Modelle, die sich überhaupt nicht ähneln. Diese Instabilität macht einzelne Bäume unzuverlässig, aber sie sind dadurch auch super Bausteine für Ensembles.
Hohe Varianz heißt, dass man durch Aggregation noch was verbessern kann. Bäume lassen sich auch schnell trainieren und können nichtlineare Beziehungen ohne manuelles Feature Engineering verarbeiten. Deshalb nutzen sowohl Random Forest als auch XGBoost sie, obwohl sie unterschiedliche Aspekte des Bias-Varianz-Problems angehen.
Ensemble-Methoden lösen dieses Problem, indem sie mehrere Modelle kombinieren:
Bagging trainiert viele Modelle gleichzeitig mit zufälligen Teilmengen der Daten und macht dann den Durchschnitt ihrer Vorhersagen. Das verringert die Abweichungen, indem es die Eigenheiten einzelner Modelle ausgleicht. Die Idee ist einfach: Wenn jedes Modell mehr oder weniger unabhängige Fehler macht, werden diese Fehler durch den Durchschnitt tendenziell ausgeglichen. Je mehr Modelle du kombinierst, desto zuverlässiger wird die endgültige Vorhersage. Deshalb hat Random Forest standardmäßig 100 Bäume statt 10.
Boosting trainiert Modelle nacheinander, wobei jedes neue Modell sich auf die Fehler der vorherigen konzentriert. Das macht das Ganze fairer, indem aus vielen schwachen Lernenden ein starker entsteht.
Schauen wir mal genauer, wie Bagging und Boosting in der Praxis funktionieren.
Bagging steht für Bootstrap-Aggregation. Der Prozess hat drei Schritte:
1. Mach mehrere Trainingssätze, indem du aus den Originaldaten mit Ersetzung (Bootstrap-Stichproben) Stichproben nimmst.
2. Trainiere ein Modell unabhängig für jede Bootstrap-Stichprobe.
3. Kombiniere Vorhersagen durch Mittelwertbildung (Regression) oder Mehrheitsentscheidung (Klassifizierung).
Bootstrap-Sampling heißt, dass jeder Trainingssatz genauso groß ist wie das Original, aber manche Beispiele kommen mehrmals vor, während andere komplett weggelassen werden. Im Schnitt hat jede Bootstrap-Stichprobe ungefähr 63 % der einzigartigen Beispiele aus den Originaldaten. Die restlichen 37 % sind sogenannte Out-of-Bag-Proben und können zur Validierung genutzt werden.
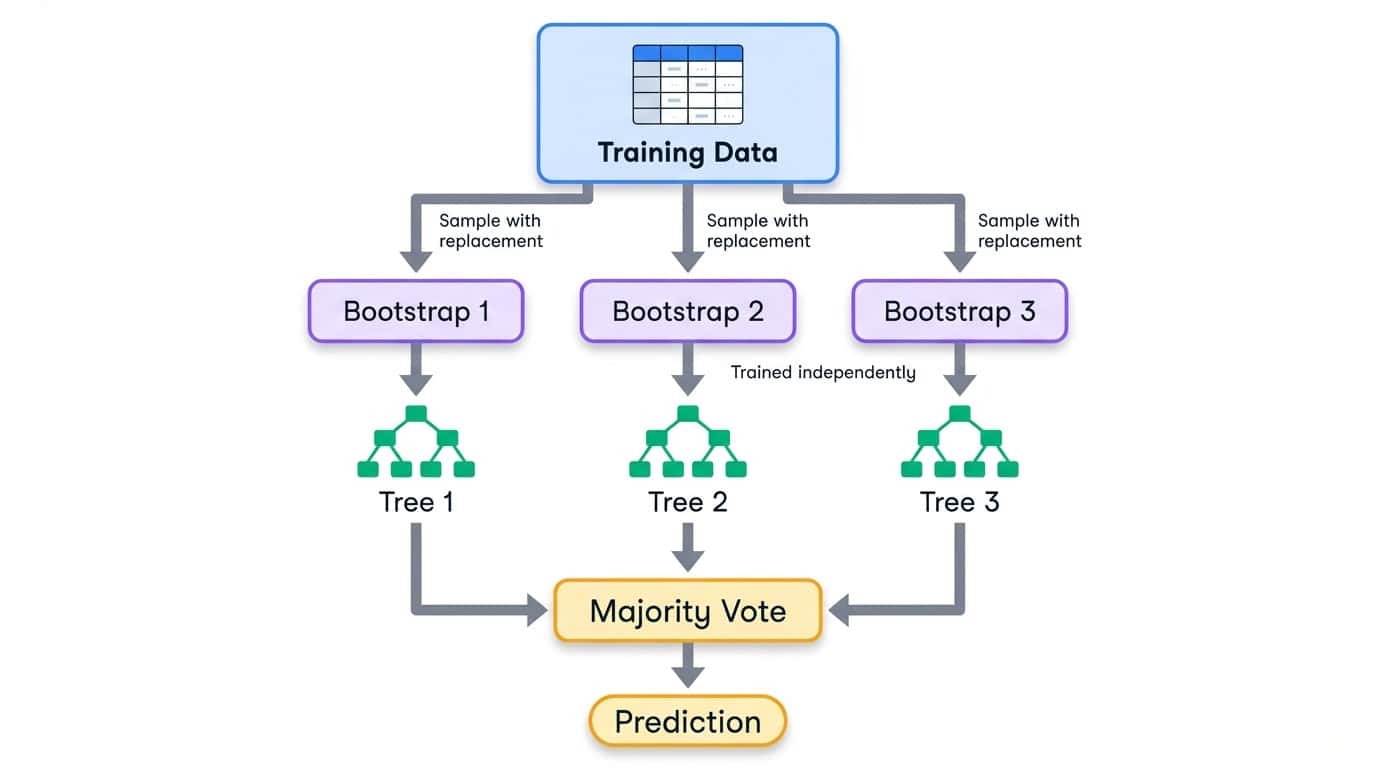
Der Bagging-Workflow zeigt, wie Trainingsdaten in Bootstrap-Stichproben aufgeteilt werden, wobei jede einen eigenen Entscheidungsbaum trainiert und dann per Mehrheitsbeschluss kombiniert wird.
Weil jedes Modell einen anderen Ausschnitt der Daten sieht, entwickeln sie unterschiedliche Eigenheiten. Einige passen sich zu sehr an einen Bereich des Merkmalsraums an, andere an einen anderen Bereich. Wenn du ihre Vorhersagen zusammenfasst, gleichen sich diese einzelnen Fehler meistens aus. Die Ensemble-Vorhersage ist stabiler als jedes einzelne Modell.
Das Training läuft parallel, weil die Modelle nicht voneinander abhängen. Dadurch lässt sich das Bagging ganz einfach auf mehrere CPU-Kerne skalieren. Random Forest, das du später in diesem Tutorial umsetzen wirst, ist der am häufigsten verwendete Bagging-Algorithmus. Für einen tieferen Einblick in die Theorie schau dir den DataCamp-Leitfaden an Leitfaden zum Bagging im maschinellen Lernen.
Boosting geht anders ran. Anstatt Modelle unabhängig voneinander zu trainieren, werden sie nacheinander trainiert, wobei sich jedes neue Modell auf Beispiele konzentriert, die die vorherigen Modelle falsch erkannt haben.
Der allgemeine Ablauf sieht so aus:
1. Trainiere ein schwaches Modell auf dem kompletten Trainingssatz.
2. Finde raus, welche Beispiele das Modell schlecht vorhergesagt hat.
3. Trainiere das nächste Modell und konzentriere dich dabei besonders auf die schwierigen Beispiele.
4. Wiederhole das Ganze und füge Modelle hinzu, die die restlichen Fehler korrigieren.
5. Alle Modelle zu einer gewichteten Summe zusammenfassen, wobei die Modelle mit besserer Leistung höhere Gewichte bekommen.
Der Begriff „schwacher Lerner” beschreibt ein Modell, das nur ein bisschen besser ist als zufälliges Raten. Entscheidungsstümpfe (Bäume mit einer einzigen Spalte) sind eine gängige Wahl. Für sich genommen ist ein Baumstumpf fast nutzlos. Aber Boosting stapelt Hunderte davon, wobei jeder einzelne die Fehler der vorherigen wegputzt. Das endgültige Ensemble ist ein starker Lerner, der aus vielen schwachen Beiträgen entstanden ist.
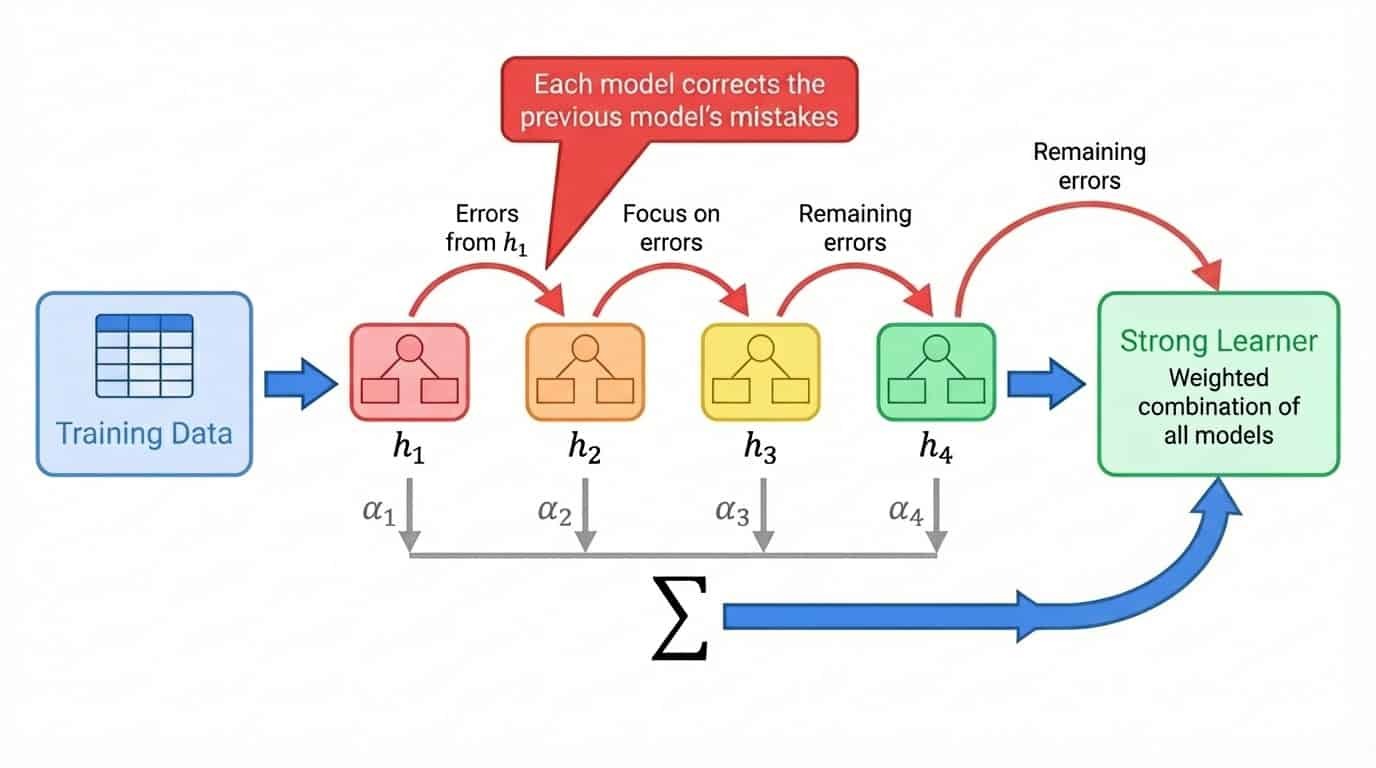
Verbesserung des Workflows durch sequentielles Modelltraining, bei dem jedes Modell die Fehler des vorherigen Modells korrigiert, kombiniert zu einer gewichteten Summe.
Im Gegensatz zum Bagging läuft Boosting von Natur aus sequenziell ab. Du kannst Modell 47 erst trainieren, wenn du weißt, mit welchen Beispielen die Modelle 1 bis 46 Probleme hatten. Dadurch dauert das Training langsamer, aber es führt oft zu einer höheren Genauigkeit, weil jedes Modell speziell dafür gemacht ist, bestimmte Schwächen im Ensemble zu beheben.
XGBoost, das du später in diesem Tutorial umsetzen wirst, ist ein Gradient-Boosting-Algorithmus, der sich bei tabellarischen Daten als erste Wahl durchgesetzt hat. Ich empfehle die Einführung in das Boosting, die die Mathematik genauer erklärt, wenn du dich näher damit beschäftigen möchtest.
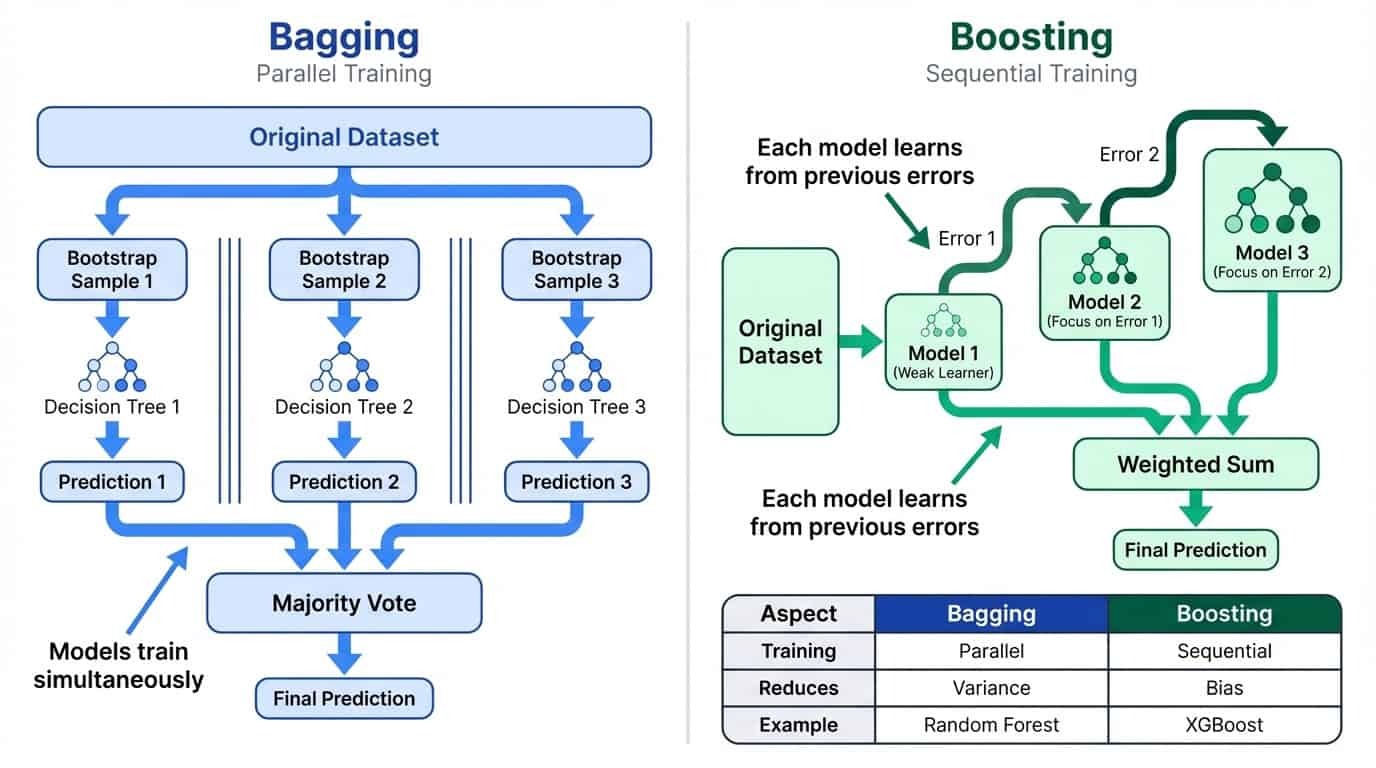
Direkter Vergleich von Bagging und Boosting: Bagging nutzt paralleles Training, um die Varianz zu verringern, Boosting nutzt sequentielles Training, um die Verzerrung zu verringern.
Bagging und Boosting sind die am häufigsten verwendeten Ensemble-Strategien, aber sie sind nicht die einzigen Optionen. Bevor wir uns mit Random Forest und XGBoost beschäftigen, solltest du wissen, was es sonst noch gibt.
Der einfachste Weg, Modelle zu kombinieren, ist, sie abstimmen zu lassen. Bei der harten Abstimmung macht jedes Modell eine Vorhersage, und die Klasse mit den meisten Stimmen gewinnt. Wenn du eine logistische Regression, eine Support-Vektor-Maschine und einen Entscheidungsbaum hast und zwei davon Klasse A vorhersagen, während einer Klasse B vorhersagt, gibt das Ensemble Klasse A aus.
Soft Voting geht noch einen Schritt weiter, indem es die vorhergesagten Wahrscheinlichkeiten mittelt, anstatt einzelne Stimmen zu zählen. Ein Modell, das Klasse A mit 90 %iger Sicherheit vorhersagt, hat mehr Einfluss auf die endgültige Entscheidung als eins, das A mit 51 %iger Sicherheit vorhersagt. Das ist meistens besser als eine reine Abstimmung, weil es zeigt, wie sicher sich jedes Modell ist.
Du kannst auch Gewichte zuweisen, um stärkeren Modellen mehr Einfluss zu geben. Wenn deine logistische Regression bei den Validierungsdaten zuverlässig besser abschneidet als die anderen, kannst du ihre Vorhersagen mit dem Faktor 2 gewichten, während du die anderen mit dem Faktor 1 belässt.
Abstimmungen funktionieren am besten, wenn man Modelle kombiniert, die das Problem unterschiedlich angehen. Ein lineares Modell, ein baumbasiertes Modell und ein Modell mit nächstgelegenem Nachbarn haben jeweils unterschiedliche Schwachstellen. Ihre kombinierte Vorhersage ist oft besser als die eines einzelnen Modells, auch wenn kein einzelnes Modell besonders stark ist. scikit-learn bietet dafür die Funktionen „ VotingClassifier “ und „VotingRegressor “.
Das Stapeln geht noch einen Schritt weiter als das Ensemble-Konzept. Anstatt Vorhersagen zu mitteln, trainierst du ein zweites Modell (ein sogenanntes Meta-Lernmodell), um sie zu kombinieren. Der Prozess läuft so ab: Man trainiert mehrere Basismodelle, sammelt ihre Vorhersagen in einem Validierungssatz und trainiert dann den Meta-Lerner, um diese Vorhersagen den richtigen Labels zuzuordnen. Der Meta-Lerner lernt, welchem Basismodell er in welchen Situationen vertrauen kann.
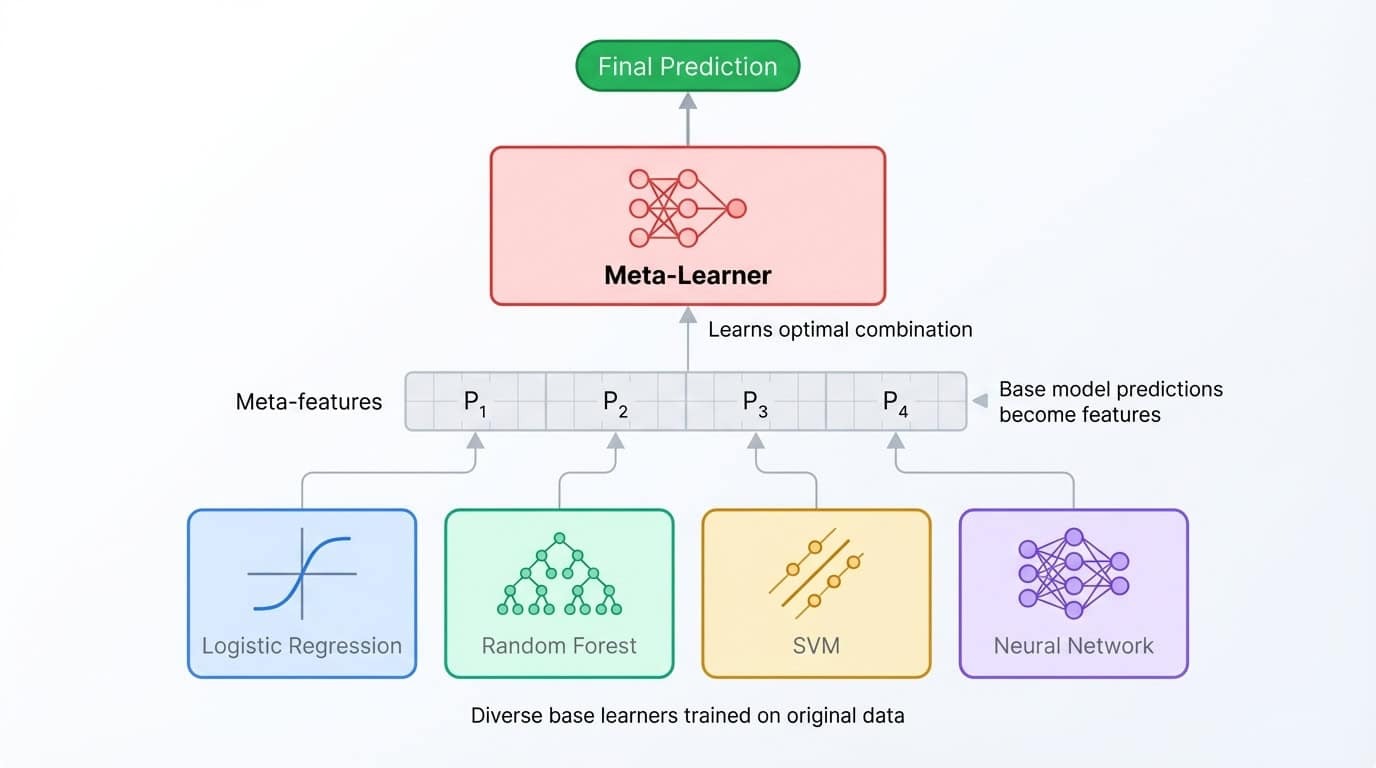
Eine gestapelte Ensemble-Architektur, bei der verschiedene Basismodelle ihre Vorhersagen an einen Meta-Lerner weitergeben, der sie für die endgültige Ausgabe zusammenführt.
Blending ist eine einfachere Variante, bei der man nur einen einzigen Holdout-Satz statt Kreuzvalidierungs-Folds benutzt. Die Implementierung geht schneller, aber es gehen Trainingsdaten verloren und es kann leichter zu einer Überanpassung des Holdout-Sets kommen.
Beide Techniken können für mehr Genauigkeit sorgen, aber die Vorteile sind oft gering (0,1–0,5 % Verbesserung) im Vergleich zur zusätzlichen Komplexität. Gestapelte Ensembles sind schwieriger zu debuggen, langsamer zu trainieren und den Beteiligten schwerer zu erklären. Sie sind super bei Kaggle-Wettbewerben, wo es auf jede Dezimalstelle ankommt und die Trainingszeit kein Problem ist, aber in der Produktion sind sie den Aufwand meistens nicht wert.
Interessanterweise nutzen die meisten gestapelten Ensembles sowieso Random Forest und XGBoost als Basis-Lernalgorithmen. Diese beiden Algorithmen sind so stark, dass das Stapeln oft nur eine komplizierte Methode ist, um ihre Vorhersagen zu mitteln.
Dieses Tutorial konzentriert sich auf Random Forest (Bagging) und XGBoost (Boosting), weil sie die meisten Probleme mit tabellarischen Daten in der Praxis lösen können. Sie sind einfacher zu implementieren, leichter anzupassen und unkomplizierter zu warten als mehrstufige gestapelte Ensembles.
Wenn du dich näher mit Abstimmungen und Stapelung beschäftigen willst, schau dir DataCamps Ensemble-Methoden in Python von DataCamp deckt alle Techniken ab. Lass uns jetzt mal mit dem Datensatz rumspielen.
Dieses Tutorial nutzt den Datensatz „Dry Beans” aus dem UCI Machine Learning Repository. Die Forscher Koklu und Ozkan (2020) haben 13.611 getrocknete Bohnen von sieben Sorten fotografiert und aus jedem Bild 16 geometrische Merkmale herausgeholt, darunter Fläche, Umfang, Achsenlängen und Formfaktoren. Die Aufgabe ist, jede Bohne anhand dieser Messungen nach Sorte zu sortieren.
Der Datensatz passt super für dieses Tutorial, weil es ein klares Multiklassenproblem mit nur numerischen Merkmalen ist. Keine fehlenden Werte, keine kategoriale Kodierung, keine Textvorverarbeitung. Du kannst dich voll und ganz auf die Ensemble-Methoden konzentrieren.
!uv add ucimlrepo scikit-learn pandas xgboost
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
import pandas as pd
dry_bean = fetch_ucirepo(id=602)
X = dry_bean.data.features
y = dry_bean.data.targets.values.ravel()
print(f"Features shape: {X.shape}")
print(f"Target classes: {pd.Series(y).nunique()}")Features shape: (13611, 16)
Target classes: 7X.head()|
Fläche |
Perimeter |
MajorAxisLength |
MinorAxisLength |
AspectRatio |
Exzentrizität |
ConvexArea |
EquivDiameter |
Ausmaß |
Solidität |
Rundheit |
Kompaktheit |
ShapeFactor1 |
ShapeFactor2 |
ShapeFactor3 |
|
28395 |
610.291 |
208.178 |
173.889 |
1.197 |
0,550 |
28715 |
190,141 |
0,764 |
0,989 |
0,958 |
0,913 |
0,007 |
0,003 |
0,834 |
|
28734 |
638.018 |
200.525 |
182.734 |
1.097 |
0,412 |
29172 |
191.273 |
0,784 |
0,985 |
0,887 |
0,954 |
0,007 |
0,004 |
0,910 |
|
29380 |
624.110 |
212.826 |
175.931 |
1.210 |
0,563 |
29690 |
193.411 |
0,778 |
0,990 |
0,948 |
0,909 |
0,007 |
0,003 |
0,826 |
|
30008 |
645.884 |
210.558 |
182.517 |
1.154 |
0,499 |
30724 |
195.467 |
0,783 |
0,977 |
0,904 |
0,928 |
0,007 |
0,003 |
0,862 |
|
30140 |
620,134 |
201.848 |
190.279 |
1.061 |
0,334 |
30417 |
195.897 |
0,773 |
0,991 |
0,985 |
0,971 |
0,007 |
0,004 |
0,942 |
pd.Series(y).value_counts()DERMASON 3546
SIRA 2636
SEKER 2027
HOROZ 1928
CALI 1630
BARBUNYA 1322
BOMBAY 522Die Klassen sind ziemlich ausgewogen, wobei Dermason am häufigsten und Bombay am seltensten vorkommt. Eine geschichtete Aufteilung behält diese Proportionen sowohl im Trainings- als auch im Testsatz bei:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"Training set: {X_train.shape[0]} samples")
print(f"Test set: {X_test.shape[0]} samples")Training set: 10888 samples
Test set: 2723 samplesJetzt, wo die Daten fertig sind, ist es Zeit, das erste Ensemble-Modell zu trainieren. In diesem Abschnitt geht's darum, wie Random Forest im Hintergrund läuft, wir schauen uns das Training und die Bewertung an und zeigen, wie man die Hyperparameter anpasst.
Random Forest nutzt Bagging für Entscheidungsbäume, aber mit einem kleinen Extra. Jeder Baum wird mit einer Bootstrap-Stichprobe der Daten trainiert (wie im vorherigen Abschnitt beschrieben), aber bei jeder Teilung berücksichtigt der Algorithmus nur eine zufällige Teilmenge der Merkmale und nicht alle.
Diese zufällige Auswahl verhindert, dass die Bäume sich zu sehr ähneln. Ohne das würden die gleichen starken Prädiktoren jeden Baum dominieren, und das Ensemble wäre einfach nur eine Menge Kopien von fast identischen Modellen.
Indem der Algorithmus bei jeder Teilung die Auswahl aus einem begrenzten Funktionsumfang erzwingt, entstehen unterschiedliche Bäume, die verschiedene Fehler machen. Wenn diese Bäume zusammen abstimmen, gleichen sich ihre individuellen Fehler meistens aus.
Bei der Klassifizierung geht scikit-learn standardmäßig von der Quadratwurzel der Gesamtmerkmale bei jeder Teilung aus. Bei 16 Merkmalen im Datensatz „Dry Beans“ werden bei jeder Aufteilung nur 4 zufällig ausgewählte Merkmale bewertet. Das Ergebnis ist ein Ensemble von dekorrelierten Bäumen, das besser verallgemeinert als es ein einzelner Baum könnte.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred_rf):.4f}")
print(classification_report(y_test, y_pred_rf))Accuracy: 0.9199
precision recall f1-score support
BARBUNYA 0.94 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.92 0.91 709
HOROZ 0.96 0.95 0.96 386
SEKER 0.94 0.96 0.95 406
SIRA 0.86 0.85 0.86 527
accuracy 0.92 2723
macro avg 0.93 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723Dieser Code baut einen Wald aus 100 Entscheidungsbäumen auf, trainiert sie mit den Bootstrap-Stichproben und macht Vorhersagen per Mehrheitsbeschluss. Der Parameter „ random_state ” legt den Zufallsstartwert fest, damit die Ergebnisse immer gleich sind.
Der Klassifizierungsbericht zeigt die Leistung nach Klassen auf. Die Präzision zeigt, wie viele der vorhergesagten positiven Ergebnisse richtig waren, die Recall-Rate zeigt, wie viele der tatsächlichen positiven Ergebnisse gefunden wurden, und der F1-Score ist der harmonische Mittelwert davon. Bombay-Bohnen sind super klassifiziert (wahrscheinlich, weil sie optisch anders aussehen), während Sira-Bohnen am schwersten von anderen Sorten zu unterscheiden sind.
Ein Vorteil von Random Forest ist, dass die Wichtigkeit der Merkmale leicht zu verstehen ist. Der Algorithmus verfolgt, wie stark jedes Merkmal die Unreinheit (standardmäßig der Gini-Index) über alle Bäume hinweg reduziert, und gibt dir so ein integriertes Maß dafür, welche Variablen am wichtigsten sind:
import matplotlib.pyplot as plt
importances = rf.feature_importances_
feature_names = X.columns
sorted_idx = importances.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances[sorted_idx][::-1])
plt.yticks(range(10), feature_names[sorted_idx][::-1])
plt.xlabel("Feature importance")
plt.title("Top 10 features (Random Forest)")
plt.tight_layout()
plt.show()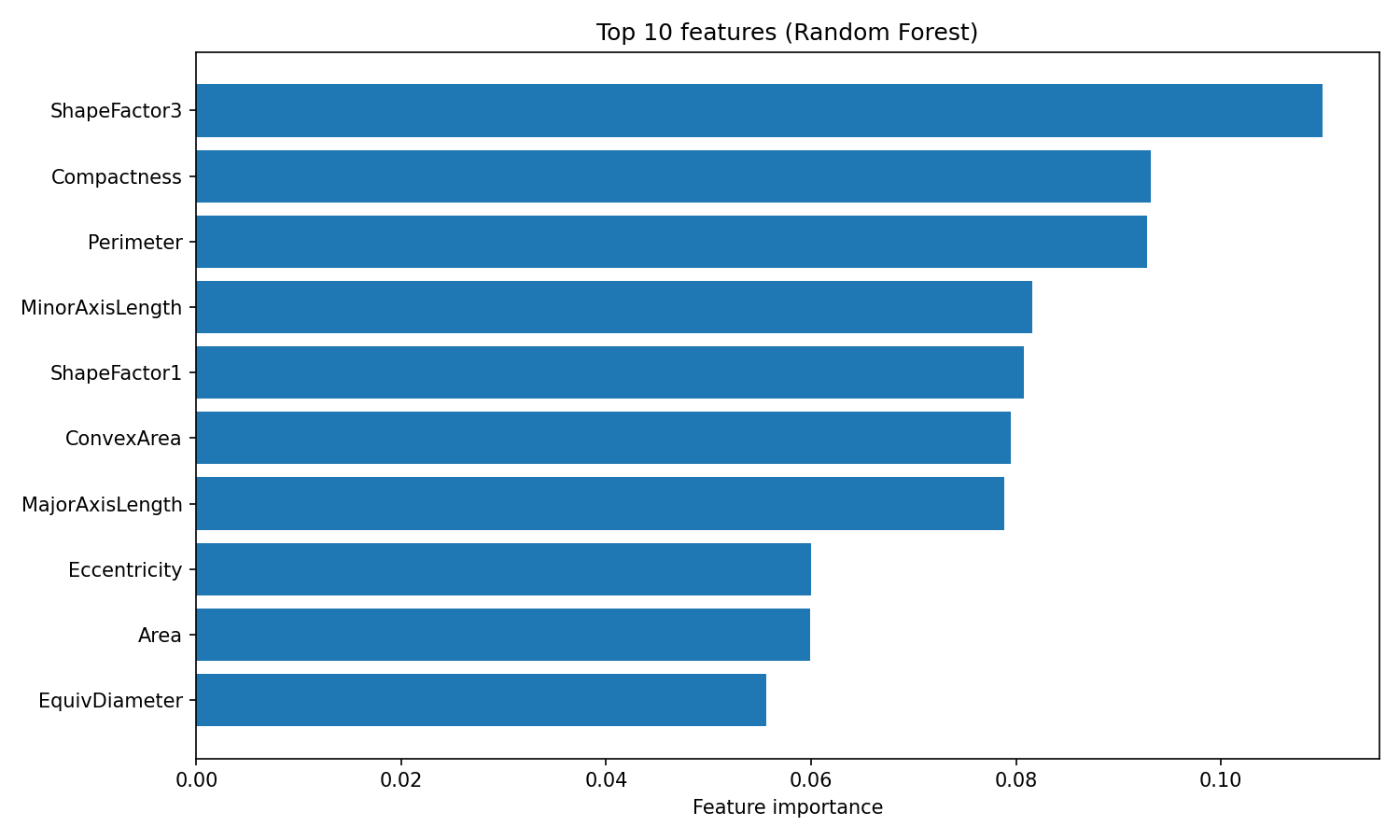
Bedeutung der Random-Forest-Merkmale
Das Attribut „ feature_importances_ “ gibt ein Array von Werten zurück, die zusammen 1 ergeben, wobei höhere Werte auf Merkmale hinweisen, die mehr zur Aufteilungsentscheidung beigetragen haben. ShapeFactor3 und Kompaktheit sind am wichtigsten für die Klassifizierung, dann kommen geometrische Messungen wie Umfang und MinorAxisLength. Diese formbasierten Merkmale zeigen die optischen Unterschiede zwischen den verschiedenen Bohnensorten, die die ursprünglichen Forscher mit dem Datensatz messen wollten.
Random Forest hat drei wichtige Hyperparameter, die man anpassen sollte:
n_estimators: Die Anzahl der Bäume im Wald. Mehr Bäume sorgen für stabilere Vorhersagen, brauchen aber länger zum Trainieren. Die Renditen sinken bei den meisten Datensätzen nach 200 Bäumen.max_depth: Die maximale Tiefe jedes Baums. Die Standardeinstellung (None) baut Bäume auf, bis die Blätter rein sind oder weniger als zwei Samples haben. Niedrigere Werte können ein Überanpassen verhindern.max_features: Die Anzahl der Merkmale, die bei jeder Teilung berücksichtigt werden. Der Standard- "sqrt" -Algorithmus funktioniert gut für die Klassifizierung. Mit „ "log2" ” wird die Vielfalt erhöht, aber die Genauigkeit für einzelne Bäume leidet darunter.Eine schnelle Rastersuche über diese Parameter:
from sklearn.model_selection import GridSearchCV
param_grid = {
"n_estimators": [100, 200],
"max_depth": [10, 20, None],
"max_features": ["sqrt", "log2"]
}
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print(f"Best params: {grid_search.best_params_}")
print(f"Best CV accuracy: {grid_search.best_score_:.4f}")Best params: {'max_depth': None, 'max_features': 'sqrt', 'n_estimators': 200}
Best CV accuracy: 0.9244GridSearchCV probiert jede Kombination von Parametern im Raster aus und schaut sich jede einzelne mit Kreuzvalidierung an. Das Argument „ cv=3 ” teilt die Trainingsdaten in drei Teile auf, trainiert auf zwei Teilen und validiert auf einem Teil, wobei alle Kombinationen durchlaufen werden. Das Flag „ n_jobs=-1 “ macht die Suche auf allen verfügbaren CPU-Kernen gleichzeitig.
y_pred_tuned = grid_search.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test, y_pred_tuned):.4f}")Tuned test accuracy: 0.9214Die Genauigkeit wurde von 92,0 % auf 92,1 % verbessert, was eine kleine Verbesserung ist. Die beste Konfiguration nutzt die Standardeinstellungen für „ max_depth “ und „ max_features “ mit 200 statt 100 Bäumen. Random Forest funktioniert oft direkt nach dem Auspacken super, was einer seiner größten Vorteile ist. Wenn du mehr über Random Forest und seine Parameter wissen willst, schau dir das Tutorial von DataCamp zur Random-Forest-Klassifizierung an. Tutorial zur Random-Forest-Klassifizierung.
XGBoost (Extreme Gradient Boosting) geht bei der Genauigkeit anders vor als Random Forest. Während Random Forest die Varianz durch Mittelwertbildung unabhängiger Bäume reduziert, verringert XGBoost die Verzerrung durch sequentielles Training der Bäume, wobei jeder neue Baum die Fehler des bisherigen Ensembles korrigiert. In diesem Abschnitt geht's darum, wie Gradient Boosting funktioniert, was XGBoost so besonders macht und wie man es mit dem Dry Beans-Datensatz trainieren und optimieren kann.
Gradient Boosting baut ein Ensemble, indem es einen Baum nach dem anderen erstellt. Der erste Baum macht Vorhersagen zum ursprünglichen Ziel. Der zweite Baum wird nicht auf dem ursprünglichen Ziel trainiert, sondern auf den Restfehlern vom ersten Baum. Der dritte Baum passt zu den Restwerten, die nach dem Hinzufügen der Vorhersagen des zweiten Baums übrig bleiben. Das geht über Hunderte von Runden so weiter, wobei jeder neue Baum die verbleibenden Fehler nach und nach beseitigt.
Der Begriff „Gradient“ beschreibt, wie der Algorithmus entscheidet, was angepasst werden soll. Bei jedem Schritt berechnet es den Gradienten der Verlustfunktion in Bezug auf die aktuellen Vorhersagen. Bei der Regression mit quadratischem Fehlerverlust ist dieser Gradient einfach der Rest (tatsächlicher Wert minus vorhergesagter Wert). Bei der Klassifizierung ist die Mathematik etwas komplizierter, aber die Idee ist die gleiche: Jeder Baum wird so trainiert, dass er Vorhersagen in die Richtung verschiebt, die den Verlust am meisten reduziert.
Ein Lernratenparameter reduziert den Beitrag jedes Baums, bevor er zum Ensemble hinzugefügt wird. Bei einer Lernrate von 0,1 werden zum Beispiel nur 10 % der Vorhersage jedes Baums hinzugefügt. Das zwingt den Algorithmus dazu, kleinere Schritte zu machen, und verbessert normalerweise die Verallgemeinerung. Der Nachteil ist, dass du mehr Bäume brauchst, um das gleiche Maß an Passform zu erreichen. Eine kleine Lernrate plus viele Bäume führt meistens zu besseren Ergebnissen als eine große Lernrate mit wenigen Bäumen.
XGBoost ist eine von mehreren Implementierungen des Gradient Boosting, zusammen mit LightGBM und CatBoost. Es wurde beliebt, weil es gegenüber früheren Implementierungen wie scikit-learns „ GradientBoostingClassifier ” einige Verbesserungen mitbrachte.
Die wichtigsten Neuerungen sind:
Diese Features machen XGBoost schneller und widerstandsfähiger gegen Überanpassung als das normale Gradient Boosting. Mit den Regularisierungsparametern kannst du die Komplexität des Modells direkt steuern, was bei der Arbeit mit verrauschten oder hochdimensionalen Daten nützlich ist.
XGBoost braucht numerische Klassenbezeichnungen statt Zeichenfolgen, also musst du zuerst die Zielvariable codieren:
from xgboost import XGBClassifier
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.transform(y_test)
xgb = XGBClassifier(n_estimators=100, random_state=42, eval_metric="mlogloss")
xgb.fit(X_train, y_train_encoded)
y_pred_xgb = xgb.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test_encoded, y_pred_xgb):.4f}")
print(classification_report(y_test_encoded, y_pred_xgb, target_names=le.classes_))Accuracy: 0.9232
precision recall f1-score support
BARBUNYA 0.95 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.93 0.91 709
HOROZ 0.96 0.96 0.96 386
SEKER 0.95 0.96 0.95 406
SIRA 0.87 0.86 0.87 527
accuracy 0.92 2723
macro avg 0.94 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723Die Funktion „ LabelEncoder “ ordnet Klassennamen ganzen Zahlen (0 bis 6) zu und speichert diese Zuordnung, damit du Vorhersagen wieder in Klassennamen umwandeln kannst. Das Argument „ eval_metric="mlogloss" ” sagt XGBoost, dass es für die interne Bewertung den Multiclass-Log-Verlust verwenden soll.
XGBoost erreicht direkt nach dem Auspacken eine Genauigkeit von 92,3 % und ist damit ein bisschen besser als Random Forest mit 92,0 %. Das Muster pro Klasse ist ähnlich: Bombay-Bohnen sind super klassifiziert, während Sira-Bohnen immer noch am schwersten zu unterscheiden sind.
XGBoost gibt die Wichtigkeit von Merkmalen anhand des Gewinns an, der die durchschnittliche Verbesserung der Genauigkeit misst, die jedes Merkmal in allen Spaltungen beiträgt, in denen es verwendet wird:
importances_xgb = xgb.feature_importances_
sorted_idx_xgb = importances_xgb.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances_xgb[sorted_idx_xgb][::-1])
plt.yticks(range(10), feature_names[sorted_idx_xgb][::-1])
plt.xlabel("Feature importance (gain)")
plt.title("Top 10 features (XGBoost)")
plt.tight_layout()
plt.show()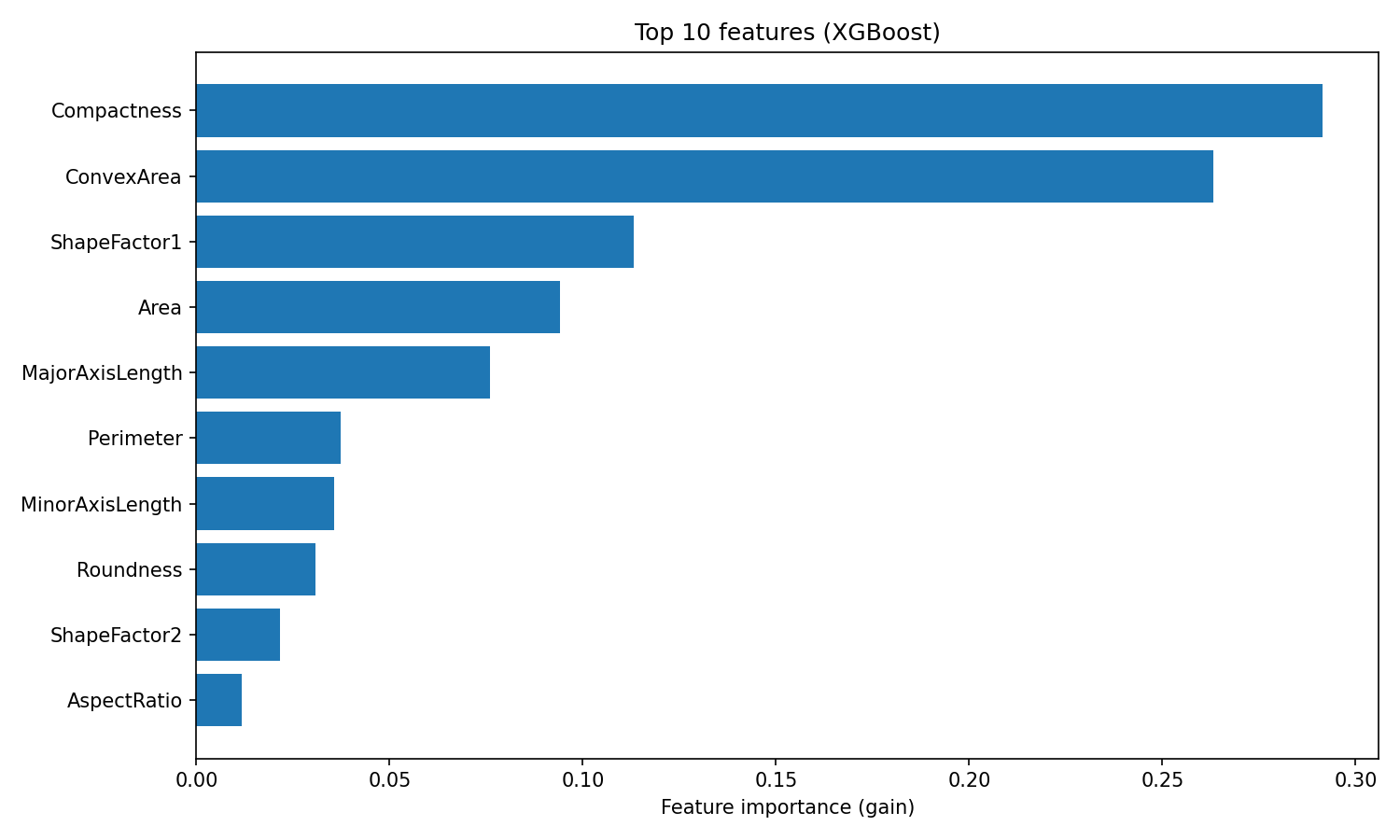
Bedeutung der XGBoost-Funktion
Das Ranking ist anders als bei Random Forest. XGBoost setzt Kompaktheit und konvexe Fläche ganz oben auf die Liste, während Random Forest ShapeFactor3 an erster Stelle hat.
Dieser Unterschied zeigt, wie die beiden Algorithmen Merkmale nutzen: Random Forest schaut, wie oft ein Merkmal die Unreinheit über viele unabhängige Bäume hinweg verringert, während XGBoost misst, wie viel Genauigkeit jedes Merkmal bei der Korrektur von Residuen hinzufügt. Beide Rankings sind okay, sie zeigen nur verschiedene Aspekte der Nützlichkeit von Funktionen.
XGBoost hat mehr Einstellungsmöglichkeiten als Random Forest, was zeigt, dass es flexibler ist. Die wichtigsten Parameter, die man beachten sollte, sind:
learning_rate: Schrumpfung für jeden Baum (Standardwert 0,3). Niedrigere Werte brauchen mehr Bäume, lassen sich aber oft besser verallgemeinern.max_depth: Maximale Baumtiefe (Standardwert 6). Flachere Bäume machen das Überanpassen weniger wahrscheinlich. Die Standardeinstellung von XGBoost ist konservativer als die unbegrenzte Tiefe von Random Forest.n_estimators: Anzahl der Boosting-Runden. Mehr Runden ermöglichen feinere Korrekturen, vor allem bei einer niedrigen Lernrate.reg_alpha: L1-Regularisierung für Blattgewichte (Standardwert 0). Höhere Werte verschieben die Gewichte in Richtung Null, wodurch spärlichere Modelle entstehen.reg_lambda: L2-Regularisierung für Blattgewichte (Standardwert 1). Höhere Werte machen große Gewichte unvorteilhaft und glätten die Vorhersagen.Eine Rastersuche über ein paar dieser Parameter:
param_grid_xgb = {
"learning_rate": [0.05, 0.1],
"max_depth": [4, 6],
"n_estimators": [100, 200],
"reg_lambda": [1, 5]
}
grid_search_xgb = GridSearchCV(
XGBClassifier(random_state=42, eval_metric="mlogloss"),
param_grid_xgb,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search_xgb.fit(X_train, y_train_encoded)
print(f"Best params: {grid_search_xgb.best_params_}")
print(f"Best CV accuracy: {grid_search_xgb.best_score_:.4f}")Best params: {'learning_rate': 0.1, 'max_depth': 4, 'n_estimators': 200, 'reg_lambda': 5}
Best CV accuracy: 0.9284y_pred_xgb_tuned = grid_search_xgb.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test_encoded, y_pred_xgb_tuned):.4f}")Tuned test accuracy: 0.9251Die beste Konfiguration nutzt flachere Bäume (max_depth=4), mehr Regularisierung (reg_lambda=5) und doppelt so viele Boosting-Runden (n_estimators=200). Dieses Muster ist echt häufig: XGBoost läuft oft am besten, wenn man mehrere schwächere einzelne Bäume durch mehr Boosting-Runden kombiniert. Durch die Optimierung wird die Testgenauigkeit von 92,3 % auf 92,5 % verbessert.
Wenn du mehr über die Parameter und erweiterten Funktionen von XGBoost wie Early Stopping erfahren willst, schau dir das Tutorial „XGBoost in Python” von DataCamp an. Tutorial „XGBoost in Python”.
Nachdem beide Modelle trainiert und optimiert wurden, hier ein Vergleich anhand des Dry Beans-Datensatzes.
|
Metrisch |
Zufälliger Wald |
XGBoost |
|
Genauigkeit (Standard) |
92,0 % |
92,3 % |
|
Genauigkeit (optimiert) |
92,1 % |
92,5 % |
|
Makro-Genauigkeit |
0,93 |
0,94 |
|
Makro-Abruf |
0,93 |
0,93 |
|
Macro F1 |
0,93 |
0,93 |
|
Trainingszeit |
Schnell |
Mäßig |
|
Tuning-Aufwand |
Niedrig |
Mäßig |
Die Genauigkeitswerte sprechen für XGBoost, aber der Abstand wird kleiner, wenn man sich den Makro-F1-Wert ansieht. Beide Modelle erreichen einen Wert von 0,93, was bedeutet, dass sie in allen sieben Bohnenklassen gleich gut abschneiden und nicht nur in der Mehrheitsklasse herausragende Leistungen zeigen.
Die Leistung pro Klasse zeigt ein ähnliches Bild:
|
Klasse |
Zufälliger Wald F1 |
XGBoost F1 |
|
Bombay |
1,00 |
1,00 |
|
Horoz |
0,96 |
0,96 |
|
Seker |
0,95 |
0,95 |
|
Cali |
0,94 |
0,94 |
|
Barbunya |
0,92 |
0,92 |
|
Dermason |
0,91 |
0,91 |
|
Sira |
0,86 |
0,87 |
Beide Modelle ordnen die Klassen gleich ein. Bombay-Bohnen sind am einfachsten zu sortieren (sie sind die größten und sehen am deutlichsten anders aus), während Sira-Bohnen am schwierigsten sind (sie sehen ähnlich aus wie Dermason- und Seker-Bohnen). Der einzige Vorteil von XGBoost pro Klasse ist eine Verbesserung des F1-Werts um 1 Punkt gegenüber Sira.
Der praktische Unterschied zwischen diesen Modellen ist nicht die Genauigkeit. Es kommt drauf an, wie viel Zeit du in die Abstimmung stecken willst. Random Forest hat mit den Standardparametern eine Leistung von 0,4 % gegenüber XGBoost gezeigt. XGBoost musste eine Rastersuche über die Lernrate, die Baumtiefe und die Regularisierung machen, um die Nase vorn zu haben.
|
Szenario |
Empfehlung |
|
Schnelle Basislinie |
Random Forest (starke Standardeinstellungen, minimale Anpassung) |
|
Genauigkeit maximieren |
XGBoost (höhere Obergrenze bei richtiger Einstellung) |
|
Nur für kurze Zeit zum Optimieren |
Random Forest (weniger empfindlich gegenüber Hyperparametern) |
|
Richtig große Datensätze |
XGBoost (bessere Speichereffizienz, GPU-Unterstützung) |
|
Interpretierbarkeit erforderlich |
Entweder (beide bieten wichtige Funktionen) |
|
Produktionsbereitstellung |
Beide haben ausgereifte, stabile Bibliotheken. |
Ein vernünftiger Arbeitsablauf: Fang mit Random Forest an, um eine Basis zu schaffen, und probier dann XGBoost aus, wenn du noch mehr Leistung rausholen willst. Die beste Wahl hängt von deinen Einschränkungen ab, nicht von irgendeiner allgemeingültigen Rangliste von Algorithmen.
In diesem Tutorial habe ich gezeigt, wie man mit Bagging und Boosting schwache Modelle in starke verwandeln kann. Die Modelle werden parallel trainiert und ihre Fehler werden ausgeglichen. Boosting trainiert sie nacheinander, wobei jeder die Fehler des vorherigen korrigiert.
Random Forest und XGBoost sind die gängigen Implementierungen. Beim Datensatz „Dry Beans“ lagen beide bei einer Genauigkeit von etwa 92 %. XGBoost hat nach der Optimierung die Nase vorn, aber Random Forest hat das fast ohne Konfiguration geschafft. Das ist der eigentliche Kompromiss: Random Forest ist pflegeleicht, XGBoost lohnt sich, wenn man sich mehr Mühe gibt.
Wenn du ein neues Problem angehst, fang mit einem Random Forest an. Es ist eine solide Basis, die man in wenigen Minuten einrichten kann. Wenn du die Genauigkeit erhöhen musst und Zeit zum Optimieren hast, wechsel zu XGBoost.
Für mehr praktische Übungen mit diesen Algorithmen empfehle ich den Kurs „Maschinelles Lernen mit baumbasierten Modellen ” von DataCamp.
Die besten Kurse zum Thema maschinelles Lernen
Lernpfad
Kurs
Kurs