
programa
Fundamentos del aprendizaje automático en Python
16 h
Un árbol de decisión único ( ) es fácil de interpretar, pero tiende a sobreajustarse. Un modelo lineal simple se generaliza bien, pero pasa por alto los patrones complejos. Cada tipo de modelo tiene puntos ciegos que limitan su precisión en datos del mundo real.
Los métodos conjuntos abordan este problema combinando múltiples modelos en un solo modelo. En lugar de basarse en un único predictor, agregan predicciones de muchos modelos para que los errores individuales se cancelen entre sí. El resultado suele ser más preciso que cualquier modelo por separado.
En este tutorial, te enseñaré las diferencias entre los métodos básicos de ensamblaje y me centraré en los dos algoritmos de ensamblaje más populares: Bosque aleatorio y XGBoost.
Aprenderás cómo funciona cada uno, los implementarás en un problema de clasificación multiclase y compararás su rendimiento. El objetivo es proporcionarte una comprensión práctica de cuándo utilizar cada enfoque y cómo adaptarlos a tus propios proyectos.
Si buscas más práctica, te recomiendo que eches un vistazo al curso curso Métodos de conjunto en Python.
El aprendizaje conjunto entrena múltiples modelos y combina sus predicciones en un único resultado. La idea es sencilla: los diferentes modelos cometen errores diferentes, por lo que promediar o votar entre muchos modelos tiende a cancelar los errores individuales.
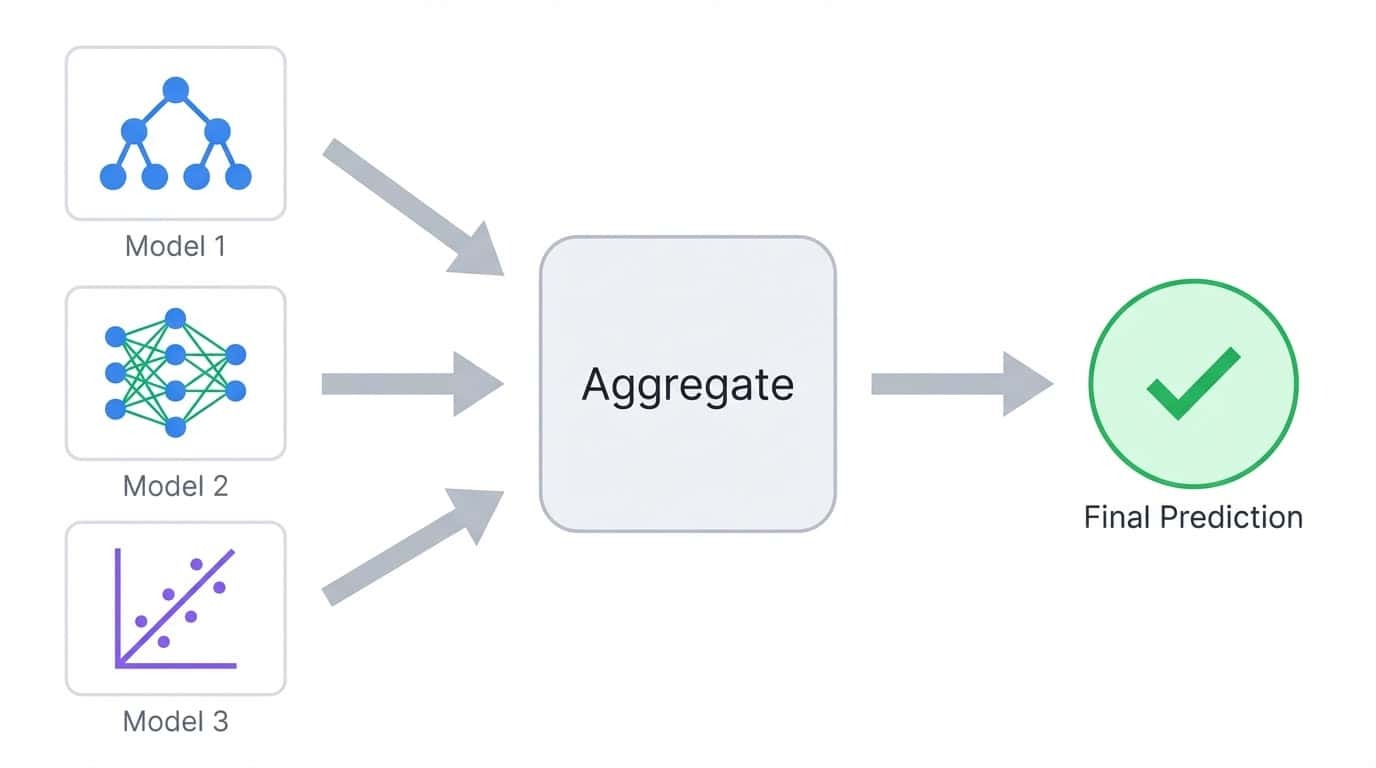
El aprendizaje conjunto combina predicciones de múltiples modelos en un único resultado agregado.
Considera una tarea de clasificación en la que entrenas cinco árboles de decisión. Cada árbol puede acertar el 80 % de las predicciones, pero no todos fallarán en los mismos ejemplos. Cuando se suman tus votos, la mayoría suele acertar, incluso cuando uno o dos árboles se equivocan. Este es el principio fundamental que subyace a todos los métodos de conjunto.
Los modelos dentro de un conjunto se denominan «base learners» (aprendices básicos). Pueden ser cualquier algoritmo, pero los árboles de decisión son la opción más común porque se entrenan rápidamente y producen de forma natural predicciones diversas cuando se les proporcionan diferentes subconjuntos de datos.
Los errores del modelo provienen de dos fuentes: sesgo y varianza.
El sesgo es el error que se produce al simplificar en exceso el problema. Un modelo lineal que intenta ajustarse a una relación curva tiene un alto sesgo porque no puede representar el patrón real, independientemente de la cantidad de datos que se le proporcionen. Los modelos de alta polarización producen predicciones similares en diferentes conjuntos de entrenamiento, pero esas predicciones siempre están desviadas del objetivo.
La varianza es el error que se produce por ser demasiado sensible a los datos de entrenamiento. Un árbol de decisión profundo que memoriza el conjunto de entrenamiento tiene una alta varianza porque captura el ruido junto con la señal. Si reentrenaras el mismo árbol con una muestra ligeramente diferente, obtendrías predicciones muy diferentes. El modelo se ajusta bien a los datos de entrenamiento, pero falla con cualquier dato nuevo.

Sesgo frente a varianza ilustrados con dianas: un sesgo elevado muestra predicciones consistentes pero desviadas del objetivo, mientras que una varianza elevada muestra predicciones dispersas e inconsistentes.
Puedes considerarlo como un problema de estabilidad. Los modelos con sesgo elevado son estables, pero siempre se equivocan de la misma manera. Los modelos de alta varianza son inestables y erróneos de diferentes maneras, dependiendo de los datos que hayan visto.
El modelo ideal es estable y preciso, pero la reducción de un tipo de error a menudo aumenta el otro.
Los árboles de decisión se sitúan claramente en el campo de la alta varianza. Utilizan la división codiciosa, lo que significa que pequeños cambios en los datos de entrenamiento pueden producir estructuras de árbol completamente diferentes.
Entrena el mismo algoritmo de árbol en dos muestras aleatorias de la misma población y es posible que obtengas dos modelos que no se parecen en nada. Esta inestabilidad hace que los árboles individuales no sean fiables, pero también los convierte en bloques de construcción perfectos para conjuntos.
Una alta varianza significa que hay margen de mejora mediante la agregación. Los árboles también son rápidos para entrenar y manejar relaciones no lineales sin ingeniería manual de características, por lo que Random Forest y XGBoost los utilizan a pesar de abordar diferentes aspectos del problema del sesgo-varianza.
Los métodos conjuntos rompen esta disyuntiva combinando múltiples modelos:
El empaquetado entrena muchos modelos en paralelo en subconjuntos aleatorios de datos y, a continuación, calcula la media de sus predicciones. Esto reduce la varianza al suavizar las peculiaridades de los modelos individuales. La intuición es sencilla: si cada modelo comete errores más o menos independientes, el promedio tiende a cancelar esos errores. Cuantos más modelos se combinen, más estable será la predicción final. Por eso Random Forest utiliza por defecto 100 árboles en lugar de 10.
El refuerzo entrena modelos de forma secuencial, de modo que cada nuevo modelo se centra en los errores de los anteriores. Esto reduce el sesgo al crear un alumno fuerte a partir de muchos alumnos débiles.
Analicemos cómo funcionan en la práctica el bagging y el boosting.
Bagging significa «agregación bootstrap». El proceso consta de tres pasos:
1. Crea varios conjuntos de entrenamiento mediante el muestreo de los datos originales con reemplazo (muestras bootstrap).
2. Entrena un modelo en cada muestra bootstrap de forma independiente.
3. Combinar predicciones mediante el promedio (regresión) o el voto mayoritario (clasificación).
El muestreo bootstrap significa que cada conjunto de entrenamiento tiene el mismo tamaño que el original, pero algunos ejemplos aparecen varias veces, mientras que otros se omiten por completo. De media, cada muestra bootstrap contiene aproximadamente el 63 % de los ejemplos únicos de los datos originales. El 37 % restante se denomina muestras fuera de la bolsa y se puede utilizar para la validación.
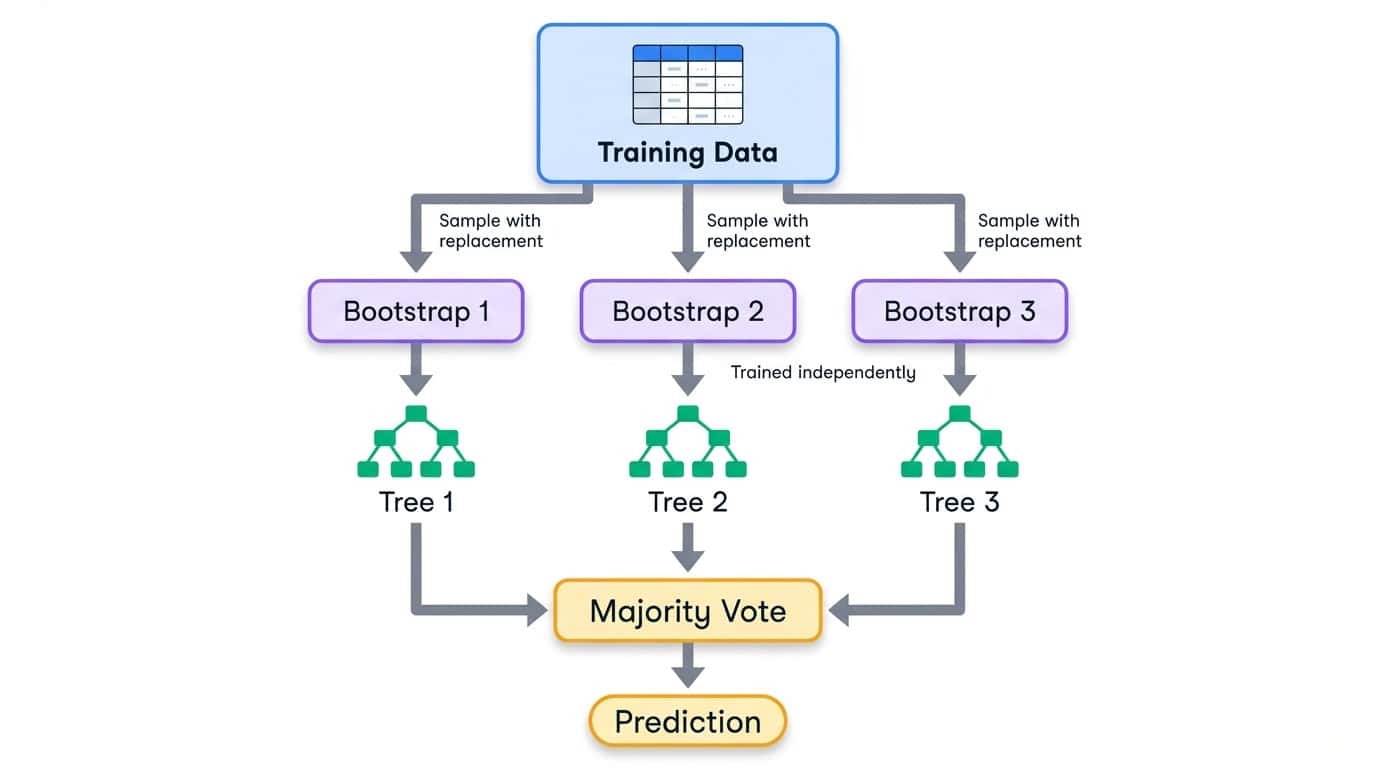
Flujo de trabajo de empaquetado que muestra los datos de entrenamiento divididos en muestras bootstrap, cada una de las cuales entrena un árbol de decisión independiente y luego se combinan mediante votación mayoritaria.
Dado que cada modelo ve una parte diferente de los datos, desarrollan peculiaridades diferentes. Algunos se ajustan excesivamente a una región del espacio de características, otros a una región diferente. Cuando se agregan tus predicciones, estos errores individuales tienden a desaparecer. La predicción conjunta es más estable que cualquier modelo individual.
El entrenamiento se lleva a cabo en paralelo, ya que los modelos no dependen unos de otros. Esto hace que el empaquetado sea fácil de escalar a través de múltiples núcleos de CPU. Random Forest, que implementarás más adelante en este tutorial, es el algoritmo de bagging más utilizado. Para profundizar en la teoría, consulta DataCamp guía sobre bagging en machine learning.
El impulso adopta un enfoque diferente. En lugar de entrenar los modelos de forma independiente, los entrena uno tras otro, y cada nuevo modelo se centra en los ejemplos que los modelos anteriores no han acertado.
El proceso general es el siguiente:
1. Entrena un modelo débil en el conjunto de entrenamiento completo.
2. Identifica qué ejemplos el modelo predijo mal.
3. Entrena el siguiente modelo haciendo especial hincapié en esos ejemplos difíciles.
4. Repite, añadiendo modelos que corrijan los errores restantes.
5. Combinar todos los modelos en una suma ponderada, en la que los modelos con mejor rendimiento obtienen ponderaciones más altas.
El término «aprendiz débil» se refiere a un modelo que solo funciona ligeramente mejor que las conjeturas aleatorias. Los troncos de decisión (árboles con una sola hendidura) son una opción habitual. Por sí solo, un tocón es prácticamente inútil. Pero al aumentar las pilas, cientos de ellas, cada una va eliminando los errores dejados por las anteriores. El conjunto final es un aprendedor fuerte construido a partir de muchas contribuciones débiles.
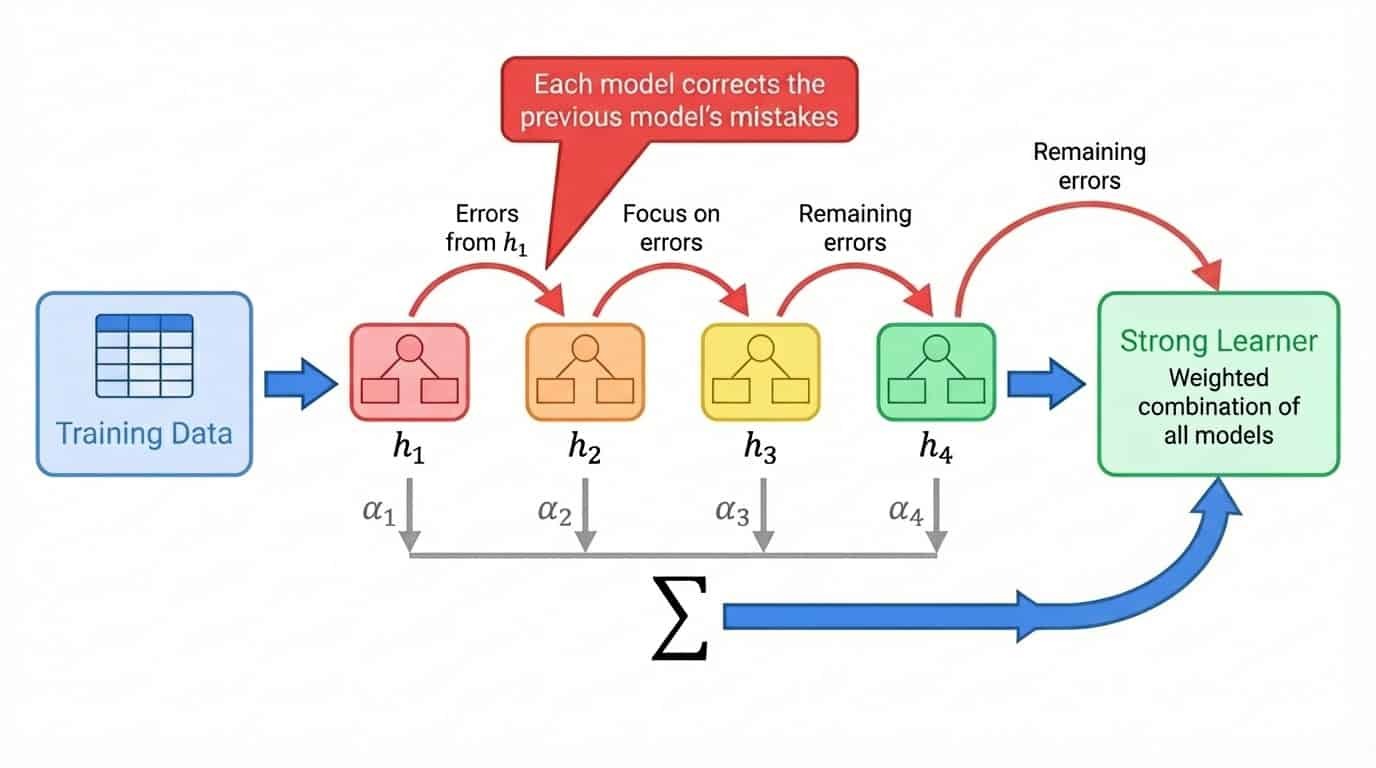
Mejora del flujo de trabajo mostrando el entrenamiento secuencial de modelos, en el que cada modelo corrige los errores del modelo anterior, combinados en una suma ponderada.
A diferencia del bagging, el boosting es intrínsecamente secuencial. No puedes entrenar el modelo 47 hasta que sepas con qué ejemplos tuvieron dificultades los modelos del 1 al 46. Esto hace que el boosting sea más lento de entrenar, pero a menudo produce una mayor precisión, ya que cada modelo está diseñado específicamente para corregir debilidades concretas del conjunto.
XGBoost, que implementarás más adelante en este tutorial, es un algoritmo de refuerzo de gradiente que se ha convertido en la opción preferida para los datos tabulares. Recomiendo la introducción al boosting, que trata los aspectos matemáticos con más detalle si quieres profundizar en el tema.
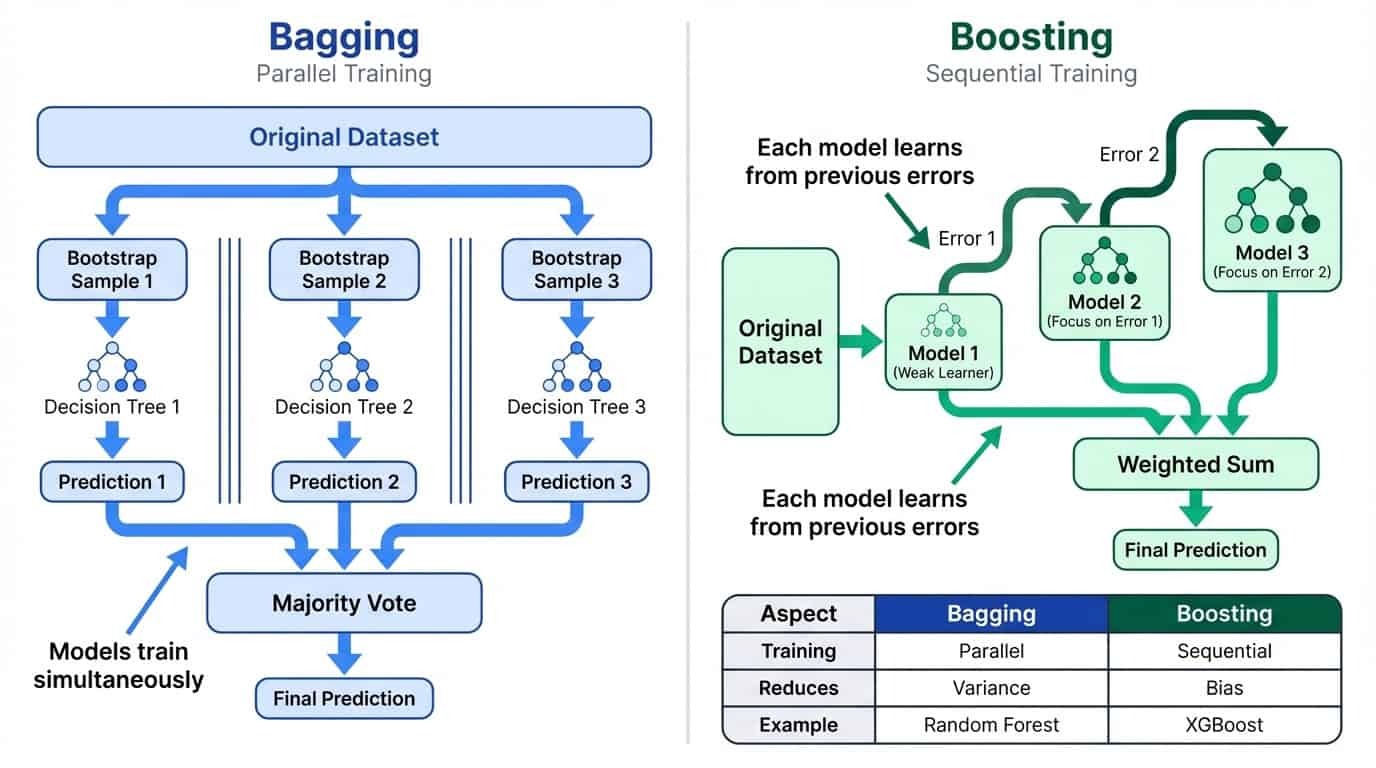
Comparación entre bagging y boosting: el bagging utiliza el entrenamiento paralelo para reducir la varianza, mientras que el boosting utiliza el entrenamiento secuencial para reducir el sesgo.
El bagging y el boosting son las estrategias de conjunto más utilizadas, pero no son las únicas opciones. Antes de profundizar en Random Forest y XGBoost, conviene saber qué más existe.
La forma más sencilla de combinar modelos es dejar que voten. En la votación dura, cada modelo hace una predicción y gana la clase con más votos. Si tienes una regresión logística, una máquina de vectores de soporte y un árbol de decisión, y dos de ellos predicen la clase A mientras que uno predice la clase B, el conjunto da como resultado la clase A.
La votación suave va más allá al calcular el promedio de las probabilidades previstas en lugar de contar votos discretos. Un modelo que predice la clase A con un 90 % de confianza contribuye más a la decisión final que uno que predice A con un 51 % de confianza. Esto suele superar a la votación directa, ya que refleja el grado de certeza de cada modelo.
También puedes asignar ponderaciones para dar más influencia a los modelos más sólidos. Si tu regresión logística supera de forma fiable a las demás en los datos de validación, puedes ponderar sus predicciones con un factor de 2, mientras que mantienes las demás en 1.
La votación funciona mejor cuando se combinan modelos que abordan el problema de manera diferente. Un modelo lineal, un modelo basado en árboles y un modelo de vecino más cercano tienen cada uno diferentes puntos ciegos. Su predicción combinada suele superar a cualquier predicción individual, incluso si ningún modelo por sí solo es muy sólido. scikit-learn proporciona VotingClassifier y VotingRegressor para este fin.
El apilamiento lleva la idea del conjunto un nivel más allá. En lugar de promediar las predicciones, entrenas un segundo modelo (denominado meta-aprendiz) para combinarlas. El proceso funciona así: entrena varios modelos base, recopila sus predicciones en un conjunto de validación y, a continuación, entrena al meta-aprendiz para que asigne esas predicciones a las etiquetas correctas. El meta-aprendiz aprende en qué modelo base confiar en cada situación.
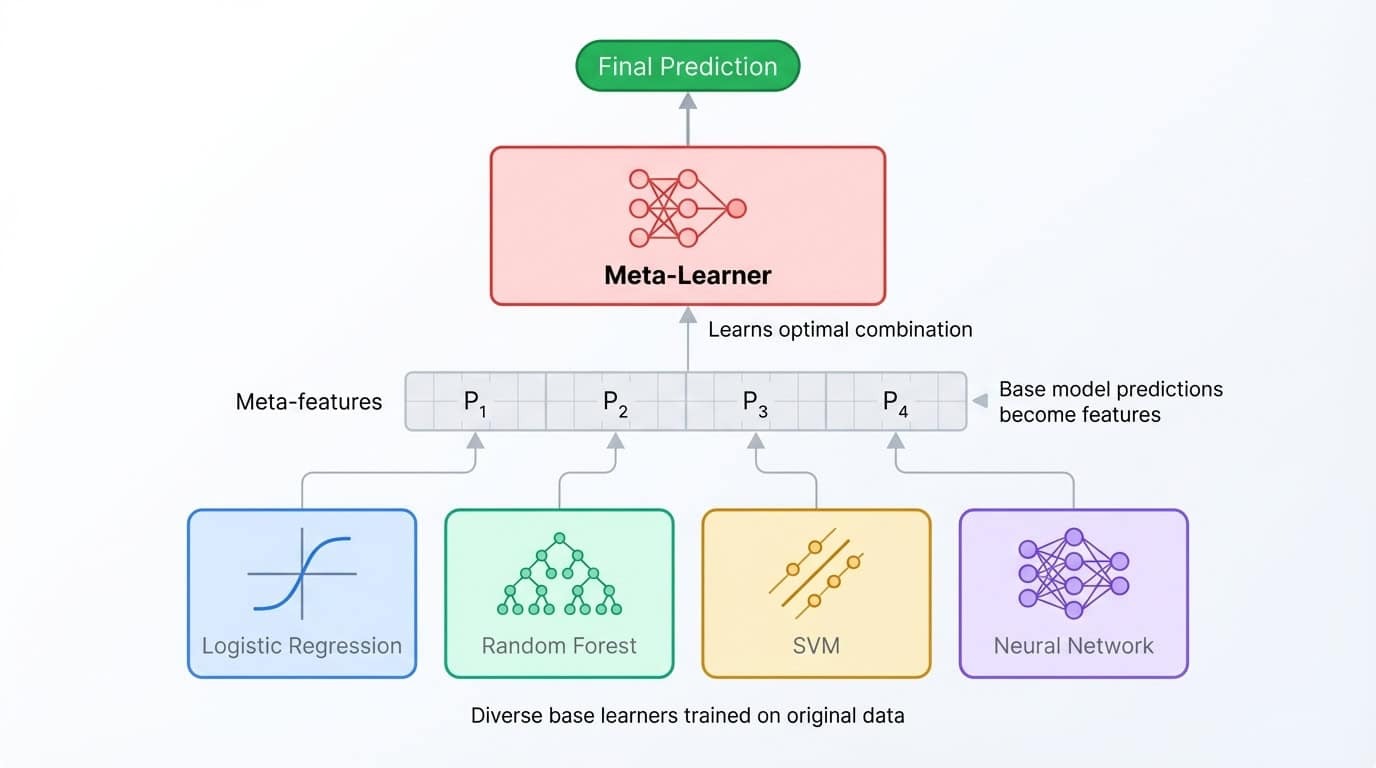
Arquitectura de conjunto apilado que muestra diversos modelos base que alimentan predicciones a un metaaprendiz que las combina para obtener el resultado final.
La combinación es una variante más sencilla que utiliza un único conjunto de reserva en lugar de pliegues de validación cruzada. Es más rápido de implementar, pero desperdicia algunos datos de entrenamiento y puede ser más propenso al sobreajuste del conjunto de validación.
Ambas técnicas pueden aportar una mayor precisión, pero las ventajas suelen ser pequeñas (una mejora del 0,1-0,5 %) en relación con la complejidad añadida. Los conjuntos apilados son más difíciles de depurar, más lentos de entrenar y más difíciles de explicar a las partes interesadas. Destacan en las competiciones de Kaggle, donde cada decimal cuenta y el tiempo de entrenamiento es ilimitado, pero rara vez merecen la pena el coste adicional que suponen en la producción.
Curiosamente, la mayoría de los conjuntos apilados utilizan Random Forest y XGBoost como aprendices básicos de todos modos. Estos dos algoritmos son tan potentes que, a menudo, el apilamiento se convierte en una forma elaborada de promediar sus predicciones.
Este tutorial se centra en Random Forest (bagging) y XGBoost (boosting) porque son los que se utilizan para resolver la gran mayoría de los problemas relacionados con datos tabulares en el mundo real. Son más sencillos de implementar, más fáciles de ajustar y más fáciles de mantener que los conjuntos apilados de varios niveles.
Si deseas profundizar en el voto y el apilamiento, los métodos de conjunto de DataCamp en Python Métodos de conjunto en Python cubre toda la gama de técnicas. Por ahora, vamos a ponernos manos a la obra con el conjunto de datos.
Este tutorial utiliza el conjunto de datos conjunto de datos Dry Beans del repositorio de machine learning de la UCI. Los investigadores Koklu y Ozkan (2020) fotografiaron 13 611 frijoles secos de siete variedades y extrajeron 16 características geométricas de cada imagen, incluyendo el área, el perímetro, la longitud de los ejes y los factores de forma. La tarea consiste en clasificar cada grano por variedad basándose en estas mediciones.
El conjunto de datos funciona bien para este tutorial porque es un problema multiclase limpio con todas las características numéricas. Sin valores perdidos, sin codificación categórica, sin preprocesamiento de texto. Puedes centrarte por completo en los métodos de conjunto.
!uv add ucimlrepo scikit-learn pandas xgboost
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
import pandas as pd
dry_bean = fetch_ucirepo(id=602)
X = dry_bean.data.features
y = dry_bean.data.targets.values.ravel()
print(f"Features shape: {X.shape}")
print(f"Target classes: {pd.Series(y).nunique()}")Features shape: (13611, 16)
Target classes: 7X.head()|
Área |
Perímetro |
MajorAxisLength |
MinorAxisLength |
AspectRatio |
Excentricidad |
ConvexArea |
EquivDiameter |
Alcance |
Solidez |
Redondez |
Compacidad |
ShapeFactor1 |
ShapeFactor2 |
ShapeFactor3 |
|
28395 |
610 291 |
208,178 |
173 889 |
1,197 |
0,550 |
28715 |
190,141 |
0,764 |
0,989 |
0,958 |
0,913 |
0,007 |
0,003 |
0,834 |
|
28734 |
638 018 |
200 525 |
182 734 |
1,097 |
0,412 |
29172 |
191 273 |
0,784 |
0,985 |
0,887 |
0,954 |
0,007 |
0,004 |
0,910 |
|
29380 |
624.110 |
212 826 |
175 931 |
1,210 |
0,563 |
29690 |
193 411 |
0,778 |
0,990 |
0,948 |
0,909 |
0,007 |
0,003 |
0,826 |
|
30008 |
645 884 |
210 558 |
182 517 |
1,154 |
0,499 |
30724 |
195 467 |
0,783 |
0,977 |
0,904 |
0,928 |
0,007 |
0,003 |
0,862 |
|
30140 |
620,134 |
201 848 |
190 279 |
1,061 |
0,334 |
30417 |
195 897 |
0,773 |
0,991 |
0,985 |
0,971 |
0,007 |
0,004 |
0,942 |
pd.Series(y).value_counts()DERMASON 3546
SIRA 2636
SEKER 2027
HOROZ 1928
CALI 1630
BARBUNYA 1322
BOMBAY 522Las clases están razonablemente equilibradas, siendo Dermason la más común y Bombay la menos común. Una división estratificada conserva estas proporciones tanto en los conjuntos de entrenamiento como en los de prueba:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"Training set: {X_train.shape[0]} samples")
print(f"Test set: {X_test.shape[0]} samples")Training set: 10888 samples
Test set: 2723 samplesCon los datos listos, es hora de entrenar el primer modelo conjunto. Esta sección explica cómo funciona Random Forest, describe el proceso de entrenamiento y evaluación, y muestra cómo ajustar sus hiperparámetros.
Random Forest aplica el bagging a los árboles de decisión con un giro adicional. Cada árbol se entrena con una muestra bootstrap de los datos (como se ha explicado en la sección anterior), pero en cada división, el algoritmo solo tiene en cuenta un subconjunto aleatorio de características en lugar de todas ellas.
Esta aleatorización de características evita que los árboles se vuelvan demasiado similares. Sin él, los mismos predictores fuertes dominarían todos los árboles, y el conjunto sería simplemente muchas copias de modelos casi idénticos.
Al obligar a cada división a elegir entre un conjunto limitado de características, el algoritmo crea árboles diversos que cometen errores diferentes. Cuando estos árboles votan juntos, sus errores individuales tienden a cancelarse.
Para la clasificación, scikit-learn considera por defecto la raíz cuadrada del total de características en cada división. Con 16 características en el conjunto de datos Dry Beans, cada división evalúa solo 4 características elegidas al azar. El resultado es un conjunto de árboles decorrelacionados que generaliza mejor que cualquier árbol individual.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred_rf):.4f}")
print(classification_report(y_test, y_pred_rf))Accuracy: 0.9199
precision recall f1-score support
BARBUNYA 0.94 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.92 0.91 709
HOROZ 0.96 0.95 0.96 386
SEKER 0.94 0.96 0.95 406
SIRA 0.86 0.85 0.86 527
accuracy 0.92 2723
macro avg 0.93 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723Este código crea un bosque de 100 árboles de decisión, los entrena con las muestras de bootstrap y genera predicciones por mayoría de votos. El parámetro « random_state » fija la semilla aleatoria para que los resultados sean reproducibles.
El informe de clasificación desglosa el rendimiento por clase. La precisión mide cuántos positivos predichos eran correctos, la recuperación mide cuántos positivos reales se encontraron y la puntuación F1 es su media armónica. Los frijoles Bombay están perfectamente clasificados (probablemente porque son físicamente distintos), mientras que los frijoles Sira son los más difíciles de distinguir de otras variedades.
Una ventaja de Random Forest es la importancia interpretable de las características. El algoritmo rastrea cuánto reduce cada característica la impureza (el índice de Gini, por defecto) en todos los árboles, lo que te proporciona una medida integrada de las variables más importantes:
import matplotlib.pyplot as plt
importances = rf.feature_importances_
feature_names = X.columns
sorted_idx = importances.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances[sorted_idx][::-1])
plt.yticks(range(10), feature_names[sorted_idx][::-1])
plt.xlabel("Feature importance")
plt.title("Top 10 features (Random Forest)")
plt.tight_layout()
plt.show()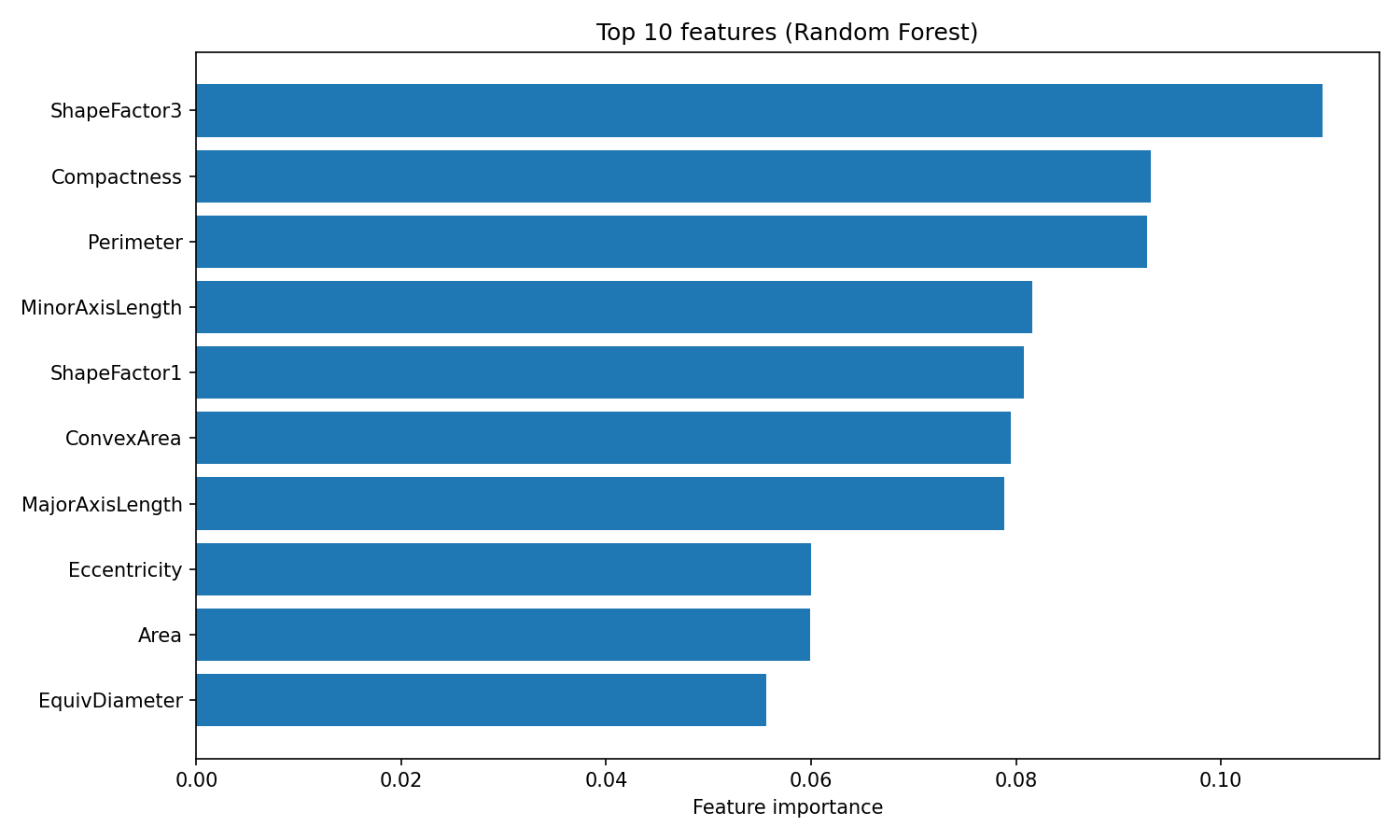
Importancia de las características del bosque aleatorio
El atributo « feature_importances_ » devuelve un arreglo de puntuaciones cuya suma es 1, donde los valores más altos indican las características que más han contribuido a las decisiones de división. ShapeFactor3 y Compactness son los que más contribuyen a la clasificación, seguidos de mediciones geométricas como Perimeter y MinorAxisLength. Estas características basadas en la forma capturan las diferencias visuales entre las variedades de frijoles que los investigadores originales diseñaron el conjunto de datos para medir.
Random Forest tiene tres hiperparámetros principales que vale la pena ajustar:
n_estimators: El número de árboles del bosque. Cuantos más árboles, más estables son las predicciones, pero más tiempo lleva entrenarlos. Los rendimientos disminuyen a partir de los 200 árboles en la mayoría de los conjuntos de datos.max_depth: La profundidad máxima de cada árbol. El valor predeterminado (None) hace crecer los árboles hasta que las hojas son puras o contienen menos de dos muestras. Los valores más bajos pueden evitar el sobreajuste.max_features: El número de características consideradas en cada división. El valor predeterminado "sqrt" funciona bien para la clasificación. El uso de "log2" aumenta la diversidad a costa de la precisión de cada árbol individual.Una búsqueda rápida en la cuadrícula con estos parámetros:
from sklearn.model_selection import GridSearchCV
param_grid = {
"n_estimators": [100, 200],
"max_depth": [10, 20, None],
"max_features": ["sqrt", "log2"]
}
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print(f"Best params: {grid_search.best_params_}")
print(f"Best CV accuracy: {grid_search.best_score_:.4f}")Best params: {'max_depth': None, 'max_features': 'sqrt', 'n_estimators': 200}
Best CV accuracy: 0.9244GridSearchCV prueba todas las combinaciones de parámetros de la cuadrícula de parámetros y evalúa cada una de ellas mediante validación cruzada. El argumento « cv=3 » divide los datos de entrenamiento en tres partes, entrenando en dos y validando en una, rotando a través de todas las combinaciones. La bandera ` n_jobs=-1 ` paraleliza la búsqueda en todos los núcleos de CPU disponibles.
y_pred_tuned = grid_search.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test, y_pred_tuned):.4f}")Tuned test accuracy: 0.9214Ajustando la precisión de los baches del 92,0 % al 92,1 %, una mejora modesta. La mejor configuración utiliza los valores predeterminados para max_depth y max_features, con 200 árboles en lugar de 100. Random Forest suele funcionar bien desde el primer momento, lo cual es uno de sus principales atractivos. Para obtener más información sobre Random Forest y sus parámetros, consulta el tutorial de DataCamp sobre clasificación con Random Forest. tutorial sobre clasificación de Random Forest.
XGBoost (Extreme Gradient Boosting) toma un camino diferente al de Random Forest para alcanzar la precisión. Mientras que Random Forest reduce la varianza promediando árboles independientes, XGBoost reduce el sesgo entrenando árboles de forma secuencial, de modo que cada nuevo árbol corrige los errores del conjunto hasta ese momento. En esta sección se explica cómo funciona el gradiente boosting, qué hace que XGBoost sea especial y cómo entrenarlo y ajustarlo en el conjunto de datos Dry Beans.
El refuerzo de gradientes construye un conjunto árbol por árbol. El primer árbol realiza predicciones sobre el objetivo original. El segundo árbol no se entrena en el objetivo original, sino en los errores residuales del primer árbol. El tercer árbol se ajusta a los residuos que quedan después de añadir las predicciones del segundo árbol. Esto continúa durante cientos de rondas, y cada nuevo árbol va eliminando cualquier error que quede.
El término «gradiente» se refiere a cómo decide el algoritmo qué ajustar. En cada paso, calcula el gradiente de la función de pérdida con respecto a las predicciones actuales. Para la regresión con pérdida por error cuadrático, este gradiente es simplemente el residuo (real menos predicho). Para la clasificación, las matemáticas son más complejas, pero la intuición es la misma: cada árbol se entrena para mover las predicciones en la dirección que más reduce la pérdida.
Un parámetro de tasa de aprendizaje reduce la contribución de cada árbol antes de añadirlo al conjunto. Con una tasa de aprendizaje de 0,1, por ejemplo, solo se añade el 10 % de la predicción de cada árbol. Esto obliga al algoritmo a dar pasos más pequeños y, por lo general, mejora la generalización. La desventaja es que necesitas más árboles para alcanzar el mismo nivel de ajuste. Una tasa de aprendizaje pequeña más muchos árboles tiende a producir mejores resultados que una tasa de aprendizaje grande con pocos árboles.
XGBoost es una de las varias implementaciones de refuerzo de gradiente, junto con LightGBM y CatBoost. Se hizo popular porque añadía varias mejoras con respecto a implementaciones anteriores, como el algoritmo de aprendizaje automático de scikit-learn ( GradientBoostingClassifier).
Las principales novedades son:
Estas características hacen que XGBoost sea más rápido y más resistente al sobreajuste que el gradiente boosting básico. Los parámetros de regularización te permiten controlar directamente la complejidad del modelo, lo cual resulta útil cuando se trabaja con datos ruidosos o de alta dimensión.
XGBoost espera etiquetas de clase numéricas en lugar de cadenas, por lo que el primer paso es codificar la variable de destino:
from xgboost import XGBClassifier
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.transform(y_test)
xgb = XGBClassifier(n_estimators=100, random_state=42, eval_metric="mlogloss")
xgb.fit(X_train, y_train_encoded)
y_pred_xgb = xgb.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test_encoded, y_pred_xgb):.4f}")
print(classification_report(y_test_encoded, y_pred_xgb, target_names=le.classes_))Accuracy: 0.9232
precision recall f1-score support
BARBUNYA 0.95 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.93 0.91 709
HOROZ 0.96 0.96 0.96 386
SEKER 0.95 0.96 0.95 406
SIRA 0.87 0.86 0.87 527
accuracy 0.92 2723
macro avg 0.94 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723LabelEncoder a los nombres de clase a números enteros (del 0 al 6) y almacena la asignación para que puedas convertir las predicciones de nuevo a nombres de clase. El argumento ` eval_metric="mlogloss" ` indica a XGBoost que utilice la pérdida logarítmica multiclase para la evaluación interna.
De fábrica, XGBoost alcanza una precisión del 92,3 %, ligeramente superior al 92,0 % de Random Forest. El patrón por clase es similar: Los frijoles Bombay están perfectamente clasificados, mientras que los frijoles Sira siguen siendo los más difíciles de distinguir.
XGBoost proporciona importancias de características basadas en la ganancia, que mide la mejora media en la precisión que aporta cada característica en todas las divisiones en las que se utiliza:
importances_xgb = xgb.feature_importances_
sorted_idx_xgb = importances_xgb.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances_xgb[sorted_idx_xgb][::-1])
plt.yticks(range(10), feature_names[sorted_idx_xgb][::-1])
plt.xlabel("Feature importance (gain)")
plt.title("Top 10 features (XGBoost)")
plt.tight_layout()
plt.show()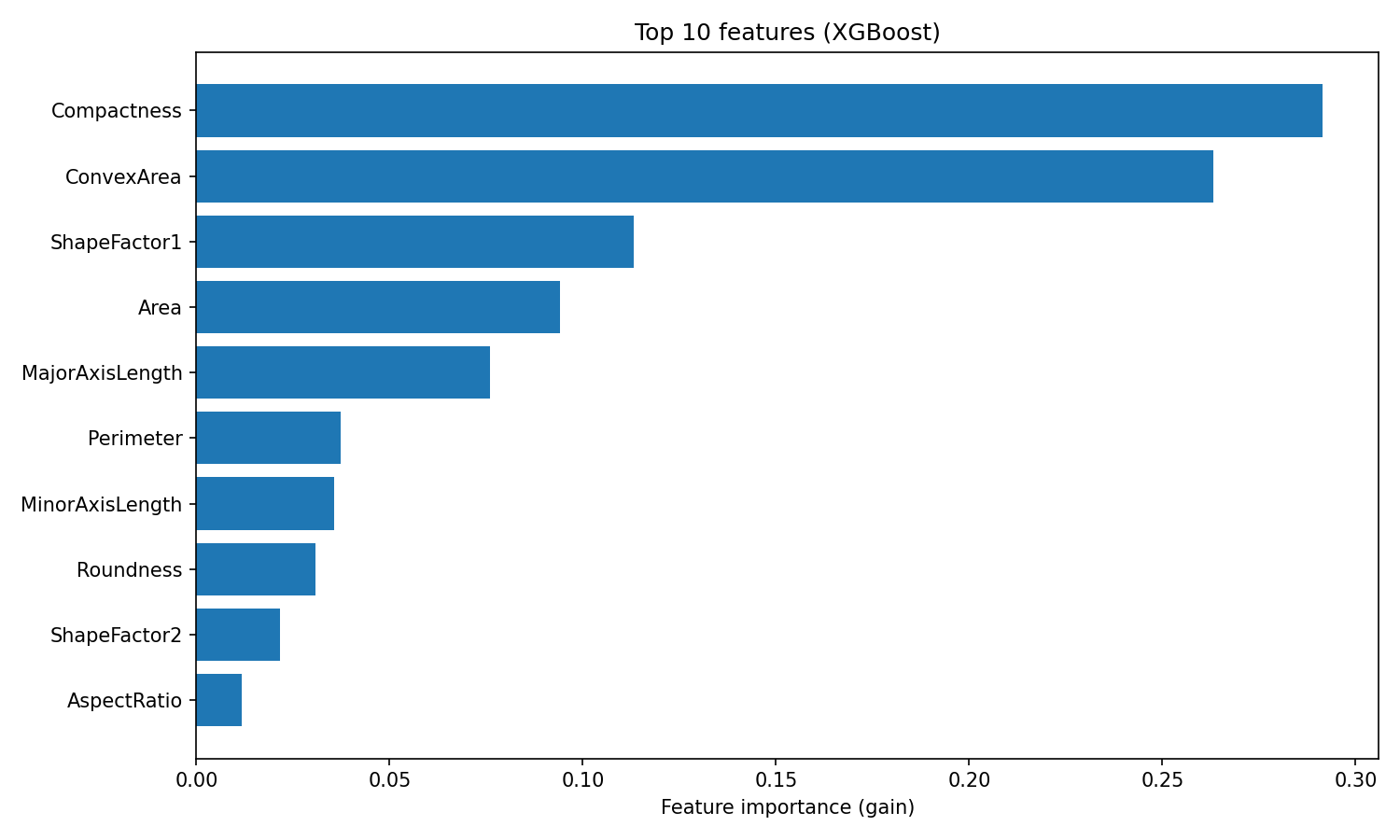
Importancia de las características de XGBoost
La clasificación difiere de Random Forest. XGBoost coloca Compactness y ConvexArea en los primeros puestos, mientras que Random Forest sitúa ShapeFactor3 en primer lugar.
Esta diferencia refleja cómo utilizan las características los dos algoritmos: Random Forest mide la frecuencia con la que una característica reduce la impureza en muchos árboles independientes, mientras que XGBoost mide la precisión que añade cada característica al corregir los residuos. Ambas clasificaciones son válidas, simplemente reflejan diferentes aspectos de la utilidad de las funciones.
XGBoost tiene más controles de ajuste que Random Forest, lo que refleja su mayor flexibilidad. Los principales parámetros a tener en cuenta son:
learning_rate: Contracción aplicada a cada árbol (por defecto 0,3). Los valores más bajos requieren más árboles, pero a menudo se generalizan mejor.max_depth: Profundidad máxima del árbol (por defecto, 6). Los árboles menos profundos reducen el sobreajuste. El valor predeterminado de XGBoost es más conservador que la profundidad ilimitada de Random Forest.n_estimators: Número de rondas de refuerzo. Más rondas permiten correcciones más precisas, especialmente con una tasa de aprendizaje baja.reg_alpha: Regularización L1 en los pesos de las hojas (por defecto 0). Los valores más altos empujan los pesos hacia cero, creando modelos más dispersos.reg_lambda: Regularización L2 en los pesos de las hojas (por defecto 1). Los valores más altos penalizan los pesos grandes, suavizando las predicciones.Una búsqueda por cuadrícula sobre algunos de estos parámetros:
param_grid_xgb = {
"learning_rate": [0.05, 0.1],
"max_depth": [4, 6],
"n_estimators": [100, 200],
"reg_lambda": [1, 5]
}
grid_search_xgb = GridSearchCV(
XGBClassifier(random_state=42, eval_metric="mlogloss"),
param_grid_xgb,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search_xgb.fit(X_train, y_train_encoded)
print(f"Best params: {grid_search_xgb.best_params_}")
print(f"Best CV accuracy: {grid_search_xgb.best_score_:.4f}")Best params: {'learning_rate': 0.1, 'max_depth': 4, 'n_estimators': 200, 'reg_lambda': 5}
Best CV accuracy: 0.9284y_pred_xgb_tuned = grid_search_xgb.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test_encoded, y_pred_xgb_tuned):.4f}")Tuned test accuracy: 0.9251La mejor configuración utiliza árboles menos profundos (max_depth=4), más regularización (reg_lambda=5) y el doble de rondas de refuerzo (n_estimators=200). Este patrón es común: XGBoost suele funcionar mejor con árboles individuales más débiles combinados a través de más rondas de refuerzo. El ajuste mejora la precisión de la prueba del 92,3 % al 92,5 %.
Para obtener más información sobre los parámetros y las funciones avanzadas de XGBoost, como la detención temprana, consulta el tutorial de DataCamp tutorial XGBoost en Python.
Una vez entrenados y ajustados ambos modelos, así es como se comparan en el conjunto de datos Dry Beans.
|
Métrico |
Bosque aleatorio |
XGBoost |
|
Precisión (predeterminado) |
92,0 % |
92,3 % |
|
Precisión (ajustada) |
92,1 % |
92,5 % |
|
Precisión macro |
0,93 |
0,94 |
|
Recuperación de macros |
0,93 |
0,93 |
|
Macro F1 |
0,93 |
0,93 |
|
Tiempo de entrenamiento |
Rápido |
Moderado |
|
Esfuerzo de ajuste |
Bajo |
Moderado |
Las cifras de precisión favorecen a XGBoost, pero la diferencia se reduce cuando se analiza el macro F1. Ambos modelos alcanzan un 0,93, lo que significa que funcionan igual de bien en las siete clases de granos, en lugar de destacar solo en la clase mayoritaria.
El rendimiento por clase muestra una tendencia similar:
|
Clase |
Bosque aleatorio F1 |
XGBoost F1 |
|
Bombay |
1,00 |
1,00 |
|
Horoz |
0,96 |
0,96 |
|
Seker |
0,95 |
0,95 |
|
Cali |
0,94 |
0,94 |
|
Barbunya |
0,92 |
0,92 |
|
Dermason |
0,91 |
0,91 |
|
Sira |
0,86 |
0,87 |
Ambos modelos clasifican las clases de forma idéntica. Los frijoles Bombay son los más fáciles de clasificar (son los más grandes y los más distintos físicamente), mientras que los frijoles Sira son los más difíciles (su forma se superpone con la de los frijoles Dermason y Seker). La única ventaja de XGBoost por clase es una mejora de 1 punto en F1 con respecto a Sira.
La diferencia práctica entre estos modelos no es la precisión. Depende del esfuerzo que quieras dedicar al ajuste. Random Forest obtuvo un rendimiento similar al de XGBoost, con una diferencia del 0,4 % utilizando los parámetros predeterminados. XGBoost necesitaba una búsqueda por cuadrícula sobre la tasa de aprendizaje, la profundidad del árbol y la regularización para adelantarse.
|
Escenario |
Recomendación |
|
Referencia rápida |
Bosque aleatorio (valores predeterminados sólidos, ajuste mínimo) |
|
Maximizar la precisión |
XGBoost (techo más alto con un ajuste adecuado) |
|
Tiempo limitado para ajustar |
Bosque aleatorio (menos sensible a los hiperparámetros) |
|
Conjuntos de datos muy grandes |
XGBoost (mejor eficiencia de memoria, compatibilidad con GPU) |
|
Se necesita interpretabilidad |
Cualquiera de los dos (ambos proporcionan importancias de características) |
|
Implementación de la producción |
Cualquiera de los dos (ambos tienen bibliotecas maduras y estables). |
Un flujo de trabajo razonable: comienza con Random Forest para establecer una línea de base y, a continuación, prueba XGBoost si necesitas sacar un rendimiento adicional. La mejor opción depende de tus limitaciones, no de una clasificación universal de algoritmos.
En este tutorial, he mostrado cómo el bagging y el boosting convierten los modelos débiles en modelos fuertes. Agrupa modelos en paralelo y calcula el promedio de sus errores. El refuerzo los entrena en secuencia, y cada uno corrige los errores del anterior.
Random Forest y XGBoost son las implementaciones más utilizadas. En el conjunto de datos Dry Beans, ambos alcanzaron una precisión de alrededor del 92 %. XGBoost se adelantó tras el ajuste, pero Random Forest lo consiguió casi sin necesidad de configuración. Esa es la verdadera compensación: Random Forest requiere poco mantenimiento, mientras que XGBoost recompensa el esfuerzo adicional.
Cuando comiences un nuevo problema, primero ajusta un bosque aleatorio. Es una base sólida que se configura en cuestión de minutos. Si necesitas aumentar la precisión y tienes tiempo para ajustar, cambia a XGBoost.
Para obtener más práctica con estos algoritmos, recomiendo el curso «Machine learning con modelos basados en árboles » de DataCamp.
Los mejores cursos de machine learning
programa
Curso
Curso
Tutorial
Bekhruz Tuychiev
Tutorial
Adam Shafi
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani

