
Programa
Fundamentos de machine learning Em Python
16 h
Uma árvore de decisão única ( ) é fácil de entender, mas pode acabar se ajustando demais. Um modelo linear simples generaliza bem, mas não consegue captar padrões complexos. Cada tipo de modelo tem pontos cegos que limitam sua precisão em dados do mundo real.
Os métodos de conjunto resolvem isso juntando vários modelos em um só. Em vez de confiar em um único indicador, eles juntam as previsões de vários modelos para que os erros individuais se cancelem. O resultado geralmente é mais preciso do que qualquer modelo isolado.
Neste tutorial, vou te mostrar as diferenças entre os principais métodos de ensemble e focar nos dois algoritmos de ensemble mais populares: Floresta aleatória e XGBoost.
Você vai aprender como cada um funciona, implementar os dois em um problema de classificação multiclasse e comparar o desempenho deles. O objetivo é te dar uma compreensão prática de quando usar cada abordagem e como ajustá-las para seus próprios projetos.
Se você quer praticar mais, recomendo dar uma olhada no curso curso Métodos Ensemble em Python.
O aprendizado conjunto treina vários modelos e junta as previsões deles em um único resultado. A ideia é simples: modelos diferentes cometem erros diferentes, então calcular a média ou votar entre muitos modelos tende a cancelar os erros individuais.
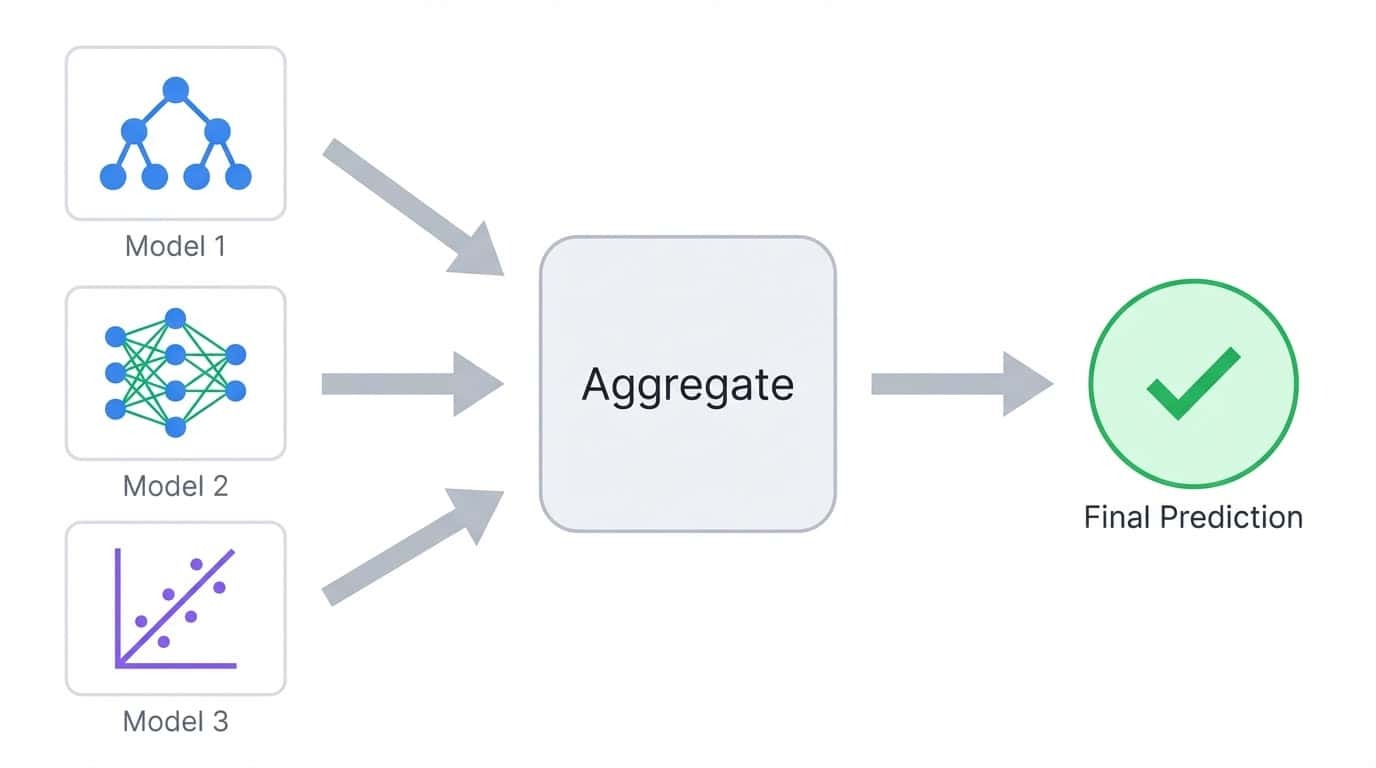
O aprendizado conjunto junta as previsões de vários modelos em um único resultado agregado.
Pense em uma classificação onde você treina cinco árvores de decisão. Cada árvore pode acertar 80% das previsões, mas elas não vão falhar todas nos mesmos exemplos. Quando você soma os votos deles, a maioria geralmente acerta, mesmo quando uma ou duas árvores estão erradas. Esse é o princípio básico por trás de todos os métodos de conjunto.
Os modelos dentro de um conjunto são chamados de aprendizes básicos. Podem ser qualquer algoritmo, mas as árvores de decisão são a escolha mais comum porque são rápidas de treinar e produzem naturalmente previsões diversas quando recebem diferentes subconjuntos de dados.
Os erros do modelo vêm de duas fontes: viés e variância.
O viés é o erro de simplificar demais o problema. Um modelo linear que tenta ajustar uma relação curva tem um viés alto porque não consegue representar o padrão real, não importa quantos dados você forneça. Modelos com alta polarização geram previsões parecidas em diferentes conjuntos de treinamento, mas essas previsões estão sempre erradas.
A variância de o é o erro de ser muito sensível aos dados de treinamento. Uma árvore de decisão profunda que memoriza o conjunto de treinamento tem alta variância porque captura ruído junto com o sinal. Se você treinasse a mesma árvore em uma amostra um pouco diferente, teria previsões bem diferentes. O modelo se encaixa bem nos dados de treinamento, mas não funciona com nada novo.

Viés versus variância ilustrados com alvos de dardos: um viés alto mostra previsões consistentes, mas fora do alvo, enquanto uma variância alta mostra previsões dispersas e inconsistentes.
Você pode pensar nisso como um problema de estabilidade. Modelos com viés elevado são estáveis, mas errados da mesma forma todas as vezes. Modelos de alta variância são instáveis e errados de diferentes maneiras, dependendo dos dados que eles acabaram vendo.
O modelo ideal é estável e preciso, mas reduzir um tipo de erro muitas vezes aumenta o outro.
As árvores de decisão estão bem no meio das coisas com muita variação. Eles usam divisão gananciosa, o que significa que pequenas mudanças nos dados de treinamento podem produzir estruturas de árvore completamente diferentes.
Treine o mesmo algoritmo de árvore em duas amostras aleatórias da mesma população e você poderá obter dois modelos que não se parecem em nada. Essa instabilidade torna as árvores individuais pouco confiáveis, mas também as torna blocos de construção perfeitos para conjuntos.
Alta variação significa que dá pra melhorar com a agregação. As árvores também são rápidas para treinar e lidar com relações não lineares sem engenharia manual de recursos, e é por isso que Random Forest e XGBoost as utilizam, apesar de atacarem diferentes partes do problema de viés-variância.
Os métodos de conjunto quebram essa relação de compensação ao combinar vários modelos:
Bagging treina vários modelos em paralelo em subconjuntos aleatórios de dados e, em seguida, calcula a média de suas previsões. Isso reduz a variação, suavizando as peculiaridades de cada modelo. A ideia é simples: se cada modelo comete erros meio independentes, a média tende a cancelar esses erros. Quanto mais modelos você juntar, mais estável vai ficar a previsão final. É por isso que o Random Forest usa 100 árvores por padrão, em vez de 10.
O Boosting treina modelos de forma sequencial, onde cada novo modelo se concentra nos erros dos anteriores. Isso reduz o viés ao criar um aluno forte a partir de muitos alunos fracos.
Vamos ver como funcionam na prática o bagging e o boosting.
Bagging significa agregação bootstrap. O processo tem três etapas:
1. Crie vários conjuntos de treinamento fazendo uma amostragem dos dados originais com reposição (amostras bootstrap).
2. Treine um modelo em cada amostra bootstrap de forma independente.
3. Junta as previsões usando a média (regressão) ou a maioria dos votos (classificação).
A amostragem Bootstrap significa que cada conjunto de treinamento tem o mesmo tamanho do original, mas alguns exemplos aparecem várias vezes, enquanto outros são totalmente deixados de fora. Em média, cada amostra bootstrap tem cerca de 63% dos exemplos únicos dos dados originais. Os 37% restantes são chamados de amostras fora da embalagem e podem ser usados para validação.
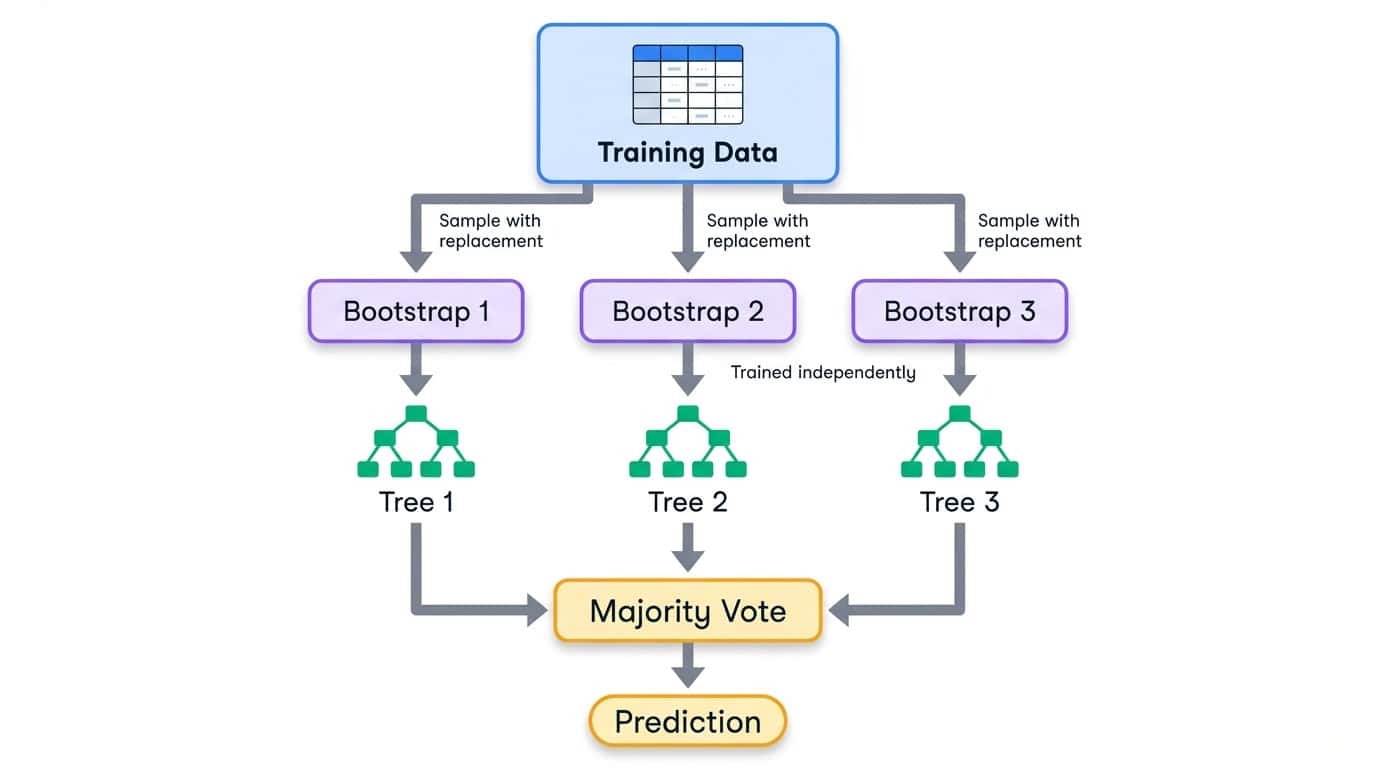
Fluxo de trabalho de ensacamento mostrando os dados de treinamento divididos em amostras bootstrap, cada uma treinando uma árvore de decisão independente e, em seguida, combinando-as por meio de votação majoritária.
Como cada modelo vê uma parte diferente dos dados, eles desenvolvem peculiaridades diferentes. Alguns se ajustam demais a uma região do espaço de características, outros a uma região diferente. Quando você junta as previsões deles, esses erros individuais acabam se cancelando. A previsão do conjunto é mais estável do que qualquer modelo individual.
O treinamento rola ao mesmo tempo, já que os modelos não dependem um do outro. Isso facilita a escalabilidade do ensacamento em vários núcleos de CPU. A Random Forest, que você vai implementar mais tarde neste tutorial, é o algoritmo de bagging mais usado. Para saber mais sobre a teoria, dá uma olhada no guia do DataCamp guia sobre bagging em machine learning.
O impulso tem uma abordagem diferente. Em vez de treinar os modelos de forma independente, ele os treina um após o outro, com cada novo modelo focando nos exemplos que os modelos anteriores erraram.
O processo geral é assim:
1. Treine um modelo fraco no conjunto de treinamento completo
2. Identifique quais exemplos o modelo previu mal.
3. Treine o próximo modelo com ênfase extra nesses exemplos difíceis.
4. Repita, adicionando modelos que corrijam os erros restantes.
5. Junta todos os modelos numa soma ponderada, onde os modelos com melhor desempenho recebem pesos mais altos.
O termo “aprendiz fraco” se refere a um modelo que tem um desempenho só um pouco melhor do que adivinhar aleatoriamente. Os troncos de decisão (árvores com uma única fenda) são uma escolha comum. Individualmente, um toco é quase inútil. Mas o boosting empilha centenas deles, cada um corrigindo os erros deixados pelos anteriores. O conjunto final é um forte aprendiz construído a partir de muitas contribuições fracas.
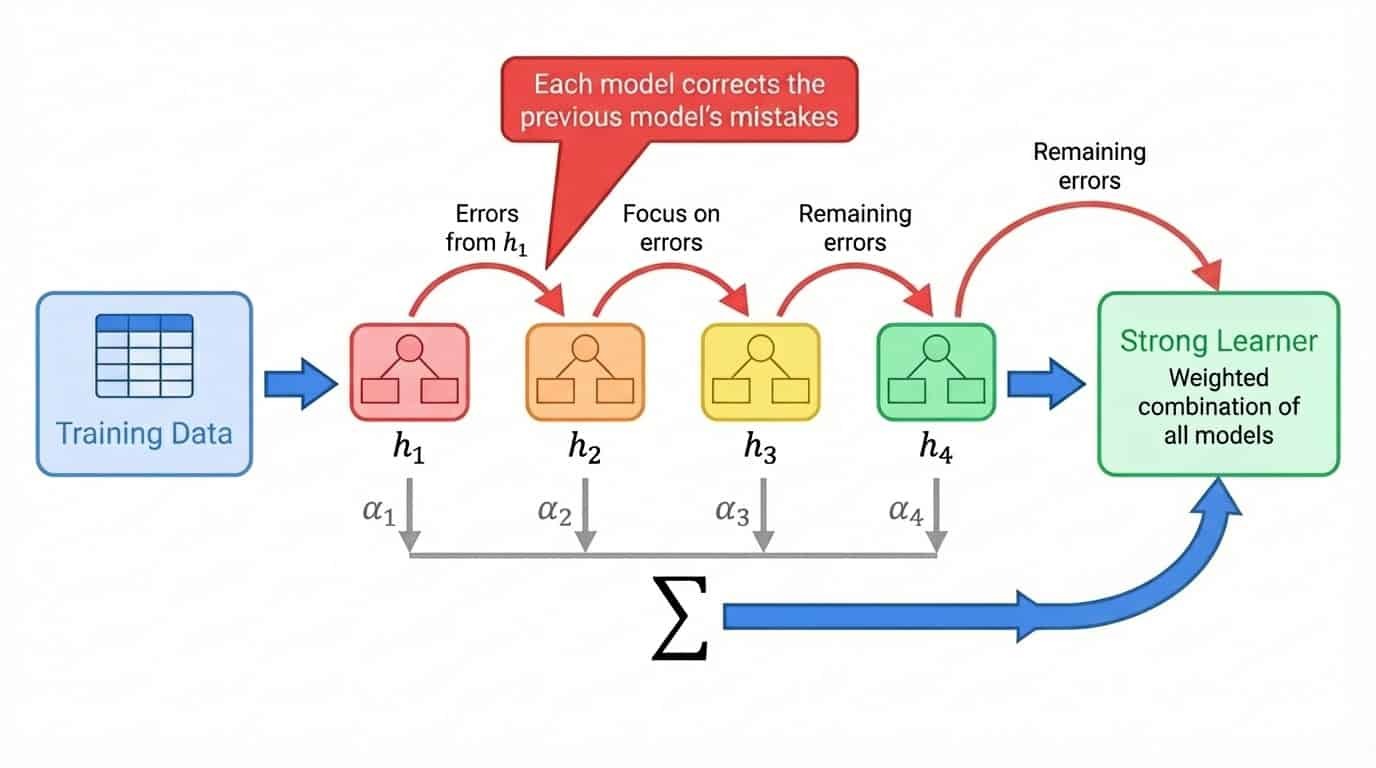
Aprimorando o fluxo de trabalho mostrando o treinamento sequencial de modelos, onde cada modelo corrige os erros do modelo anterior, combinados em uma soma ponderada.
Diferente do bagging, o boosting é, por natureza, sequencial. Você não pode treinar o modelo 47 até saber com quais exemplos os modelos 1 a 46 tiveram dificuldade. Isso faz com que o boosting demore mais pra treinar, mas geralmente dá uma precisão maior porque cada modelo é feito pra resolver pontos fracos específicos no conjunto.
O XGBoost, que você vai implementar mais tarde neste tutorial, é um algoritmo de reforço de gradiente que se tornou a escolha preferida para dados tabulares. Eu recomendo a introdução ao boosting, que fala mais sobre a matemática por trás disso, se você quiser saber mais.
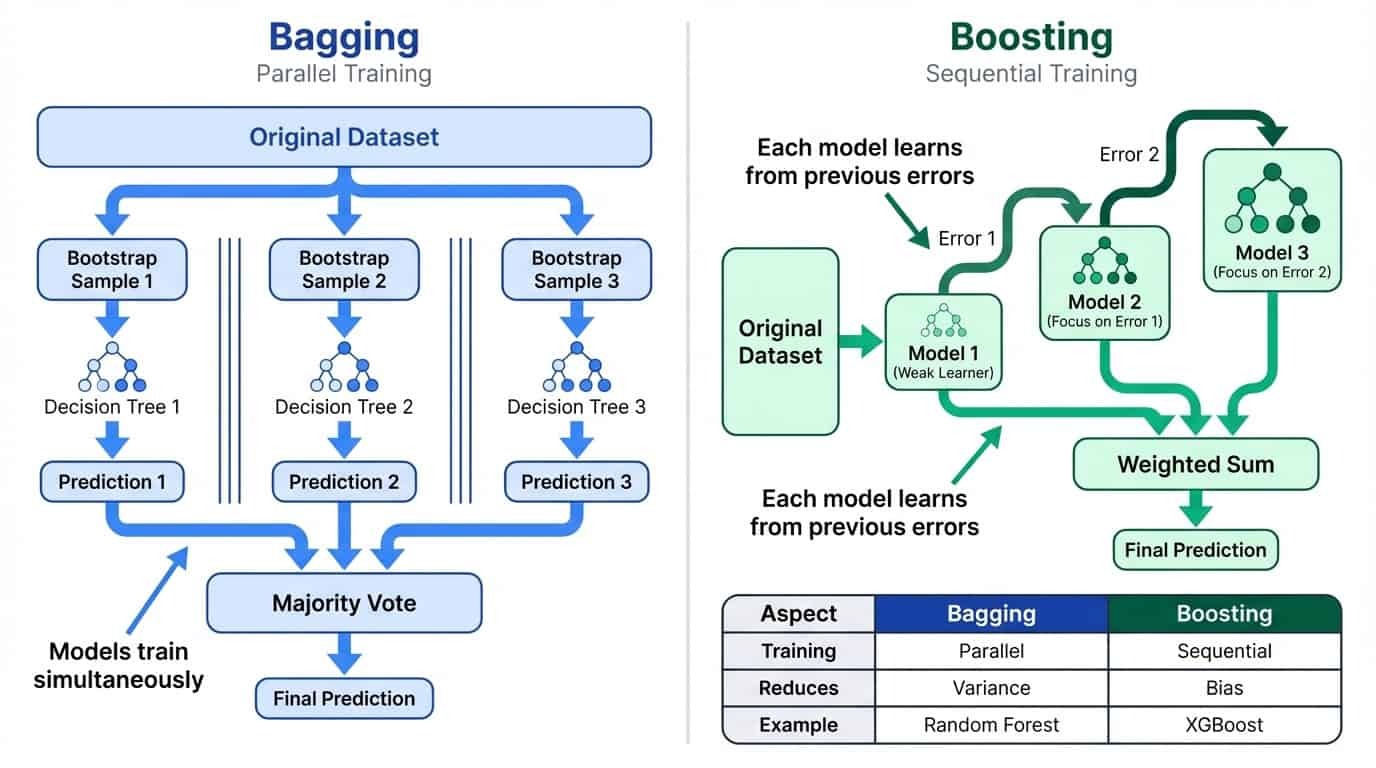
Comparando lado a lado o bagging e o boosting: o bagging usa treinamento paralelo pra diminuir a variação, enquanto o boosting usa treinamento sequencial pra reduzir o viés.
Bagging e boosting são as estratégias de conjunto mais usadas, mas não são as únicas opções. Antes de mergulhar no Random Forest e no XGBoost, vale a pena saber o que mais existe.
A maneira mais fácil de juntar modelos é deixar que eles votem. Na votação direta, cada modelo faz uma previsão e a classe com mais votos ganha. Se você tem uma regressão logística, uma máquina de vetor de suporte e uma árvore de decisão, e duas delas prevêem a classe A enquanto uma prevê a classe B, o conjunto produz a classe A.
A votação suave vai além disso, calculando a média das probabilidades previstas em vez de contar votos discretos. Um modelo que prevê a classe A com 90% de confiança contribui mais para a decisão final do que um que prevê A com 51% de confiança. Isso geralmente supera a votação rígida, porque mostra o quanto cada modelo é confiável.
Você também pode atribuir pesos para dar mais influência aos modelos mais fortes. Se a sua regressão logística tiver um desempenho confiável superior aos outros nos dados de validação, você pode ponderar suas previsões em 2x, mantendo as outras em 1x.
A votação funciona melhor quando se combinam modelos que abordam o problema de maneiras diferentes. Um modelo linear, um modelo baseado em árvore e um modelo de vizinho mais próximo têm pontos cegos diferentes. A previsão combinada deles geralmente supera qualquer previsão individual, mesmo que nenhum modelo isolado seja muito forte. O scikit-learn oferece VotingClassifier e VotingRegressor para essa finalidade.
Empilhar leva a ideia de conjunto a um nível mais profundo. Em vez de calcular a média das previsões, você treina um segundo modelo (chamado meta-aprendiz) para combiná-las. O processo funciona assim: treine vários modelos básicos, colete suas previsões em um conjunto de validação e, em seguida, treine o meta-aprendiz para mapear essas previsões para os rótulos corretos. O meta-aprendiz aprende em qual modelo básico confiar em quais situações.
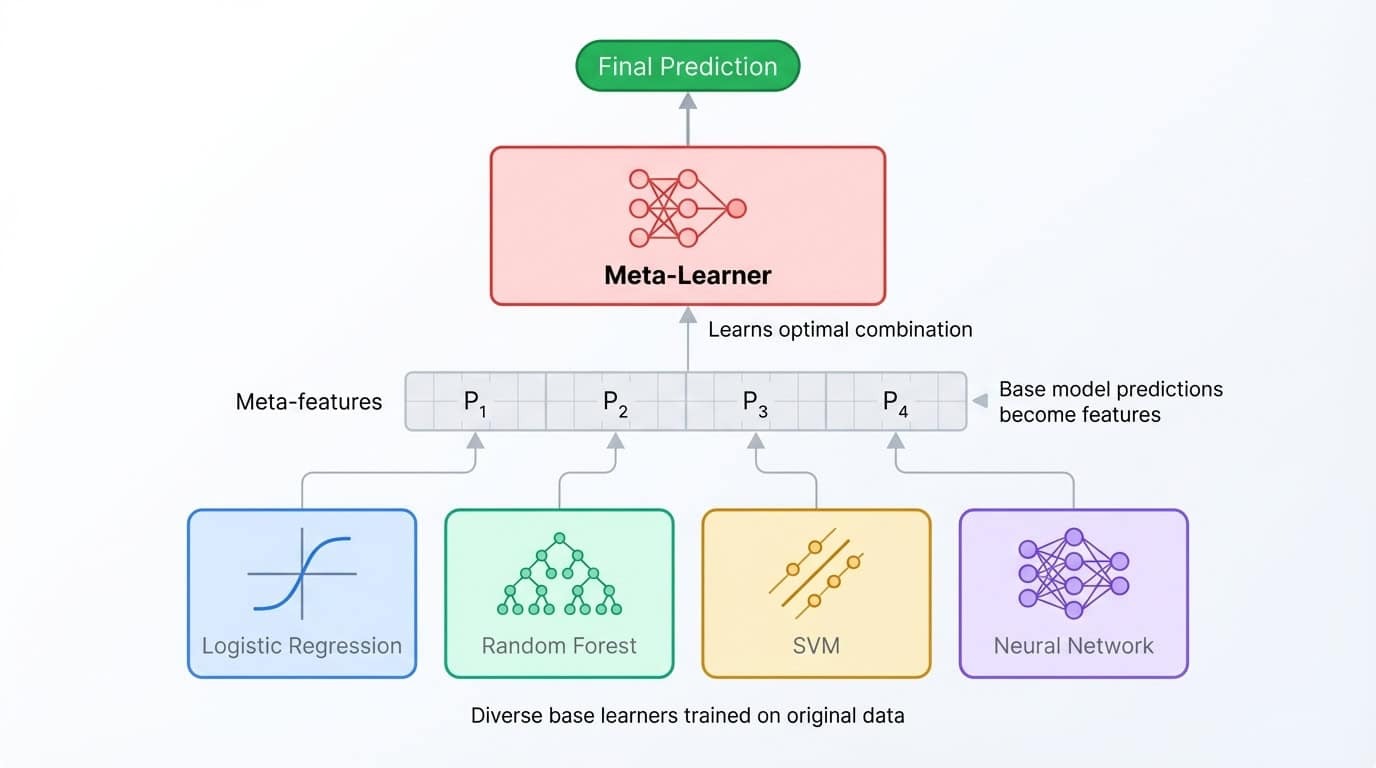
Arquitetura de conjunto empilhado mostrando diversos modelos básicos que alimentam previsões para um meta-aprendiz que os combina para a saída final.
A mistura é uma variante mais simples que usa um único conjunto de retenção em vez de dobras de validação cruzada. É mais rápido de implementar, mas desperdiça alguns dados de treinamento e pode ser mais propenso a sobreajustar o conjunto de retenção.
Ambas as técnicas podem aumentar a precisão, mas os ganhos são geralmente pequenos (melhoria de 0,1-0,5%) em relação à complexidade adicional. Conjuntos empilhados são mais difíceis de depurar, mais lentos para treinar e mais complicados de explicar para as partes interessadas. Eles se destacam nas competições Kaggle, onde cada ponto decimal é importante e o tempo de treinamento é ilimitado, mas raramente valem a pena na produção.
Curiosamente, a maioria dos conjuntos empilhados usa Random Forest e XGBoost como aprendizes básicos de qualquer maneira. Esses dois algoritmos são tão fortes que, muitas vezes, empilhá-los acaba sendo só uma maneira mais elaborada de calcular a média das previsões deles.
Este tutorial se concentra em Random Forest (bagging) e XGBoost (boosting) porque eles lidam com a grande maioria dos problemas de dados tabulares do mundo real. Eles são mais simples de implementar, mais fáceis de ajustar e mais diretos de manter do que conjuntos empilhados em vários níveis.
Se você quiser se aprofundar em votação e empilhamento, os Métodos Ensemble do DataCamp em Python Ensemble Methods in Python cobre toda a gama de técnicas. Por enquanto, vamos dar uma olhada no conjunto de dados.
Esse tutorial usa o conjunto de dados conjunto de dados Dry Beans do Repositório de Machine Learning da UCI. Os pesquisadores Koklu e Ozkan (2020) tiraram fotos de 13.611 feijões secos de sete variedades e pegaram 16 características geométricas de cada imagem, incluindo área, perímetro, comprimentos dos eixos e fatores de forma. A tarefa é classificar cada grão por variedade com base nessas medições.
O conjunto de dados funciona bem para este tutorial porque é um problema multiclasse simples, com todas as características numéricas. Sem valores perdidos, sem codificação categórica, sem pré-processamento de texto. Você pode se concentrar totalmente nos métodos de conjunto.
!uv add ucimlrepo scikit-learn pandas xgboost
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
import pandas as pd
dry_bean = fetch_ucirepo(id=602)
X = dry_bean.data.features
y = dry_bean.data.targets.values.ravel()
print(f"Features shape: {X.shape}")
print(f"Target classes: {pd.Series(y).nunique()}")Features shape: (13611, 16)
Target classes: 7X.head()|
Área |
Perímetro |
MajorAxisLength |
MinorAxisLength |
AspectRatio |
Excentricidade |
ConvexArea |
Diâmetro Equivalente |
Extensão |
Solidez |
Arredondamento |
Compacidade |
ShapeFactor1 |
ShapeFactor2 |
ShapeFactor3 |
|
28395 |
610.291 |
208.178 |
173.889 |
1.197 |
0,550 |
28715 |
190.141 |
0,764 |
0,989 |
0,958 |
0,913 |
0,007 |
0,003 |
0,834 |
|
28734 |
638.018 |
200.525 |
182.734 |
1.097 |
0,412 |
29172 |
191.273 |
0,784 |
0,985 |
0,887 |
0,954 |
0,007 |
0,004 |
0,910 |
|
29380 |
624.110 |
212.826 |
175.931 |
1.210 |
0,563 |
29690 |
193.411 |
0,778 |
0,990 |
0,948 |
0,909 |
0,007 |
0,003 |
0,826 |
|
30008 |
645.884 |
210.558 |
182.517 |
1.154 |
0,499 |
30724 |
195.467 |
0,783 |
0,977 |
0,904 |
0,928 |
0,007 |
0,003 |
0,862 |
|
30140 |
620.134 |
201.848 |
190.279 |
1.061 |
0,334 |
30417 |
195.897 |
0,773 |
0,991 |
0,985 |
0,971 |
0,007 |
0,004 |
0,942 |
pd.Series(y).value_counts()DERMASON 3546
SIRA 2636
SEKER 2027
HOROZ 1928
CALI 1630
BARBUNYA 1322
BOMBAY 522As classes são razoavelmente equilibradas, sendo Dermason a mais comum e Bombay a menos comum. Uma divisão estratificada mantém essas proporções tanto nos conjuntos de treinamento quanto nos conjuntos de teste:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"Training set: {X_train.shape[0]} samples")
print(f"Test set: {X_test.shape[0]} samples")Training set: 10888 samples
Test set: 2723 samplesCom os dados prontos, é hora de treinar o primeiro modelo de conjunto. Essa seção fala sobre como o Random Forest funciona por trás dos panos, mostra como é o treinamento e a avaliação e ensina a ajustar seus hiperparâmetros.
A Random Forest usa o bagging nas árvores de decisão com um toque a mais. Cada árvore é treinada em uma amostra bootstrap dos dados (como falamos na seção anterior), mas em cada divisão, o algoritmo só considera um subconjunto aleatório de características, em vez de todas elas.
Essa aleatoriedade evita que as árvores fiquem muito parecidas. Sem isso, os mesmos fortes indicadores dominariam todas as árvores, e o conjunto seria só um monte de cópias de modelos quase iguais.
Ao forçar cada divisão a escolher entre um conjunto limitado de recursos, o algoritmo cria árvores diferentes que cometem erros diferentes. Quando essas árvores votam juntas, seus erros individuais tendem a se cancelar.
Para classificação, o scikit-learn considera por padrão a raiz quadrada do total de características em cada divisão. Com 16 características no conjunto de dados Dry Beans, cada divisão avalia apenas 4 características escolhidas aleatoriamente. O resultado é um conjunto de árvores descorrelacionadas que generalizam melhor do que qualquer árvore isolada poderia fazer.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred_rf):.4f}")
print(classification_report(y_test, y_pred_rf))Accuracy: 0.9199
precision recall f1-score support
BARBUNYA 0.94 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.92 0.91 709
HOROZ 0.96 0.95 0.96 386
SEKER 0.94 0.96 0.95 406
SIRA 0.86 0.85 0.86 527
accuracy 0.92 2723
macro avg 0.93 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723Esse código cria uma floresta de 100 árvores de decisão, treina-as nas amostras bootstrap e gera previsões por maioria de votos. O parâmetro ` random_state ` fixa a semente aleatória para que os resultados sejam reproduzíveis.
O relatório de classificação divide o desempenho por classe. A precisão mede quantos positivos previstos estavam corretos, a recuperação mede quantos positivos reais foram encontrados e a pontuação F1 é a média harmônica deles. Os grãos de Bombaim são super fáceis de classificar (provavelmente porque são bem diferentes fisicamente), enquanto os grãos Sira são os mais difíceis de diferenciar das outras variedades.
Uma vantagem do Random Forest é a importância interpretável das características. O algoritmo acompanha o quanto cada característica reduz a impureza (o índice de Gini, por padrão) em todas as árvores, dando uma medida embutida de quais variáveis são mais importantes:
import matplotlib.pyplot as plt
importances = rf.feature_importances_
feature_names = X.columns
sorted_idx = importances.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances[sorted_idx][::-1])
plt.yticks(range(10), feature_names[sorted_idx][::-1])
plt.xlabel("Feature importance")
plt.title("Top 10 features (Random Forest)")
plt.tight_layout()
plt.show()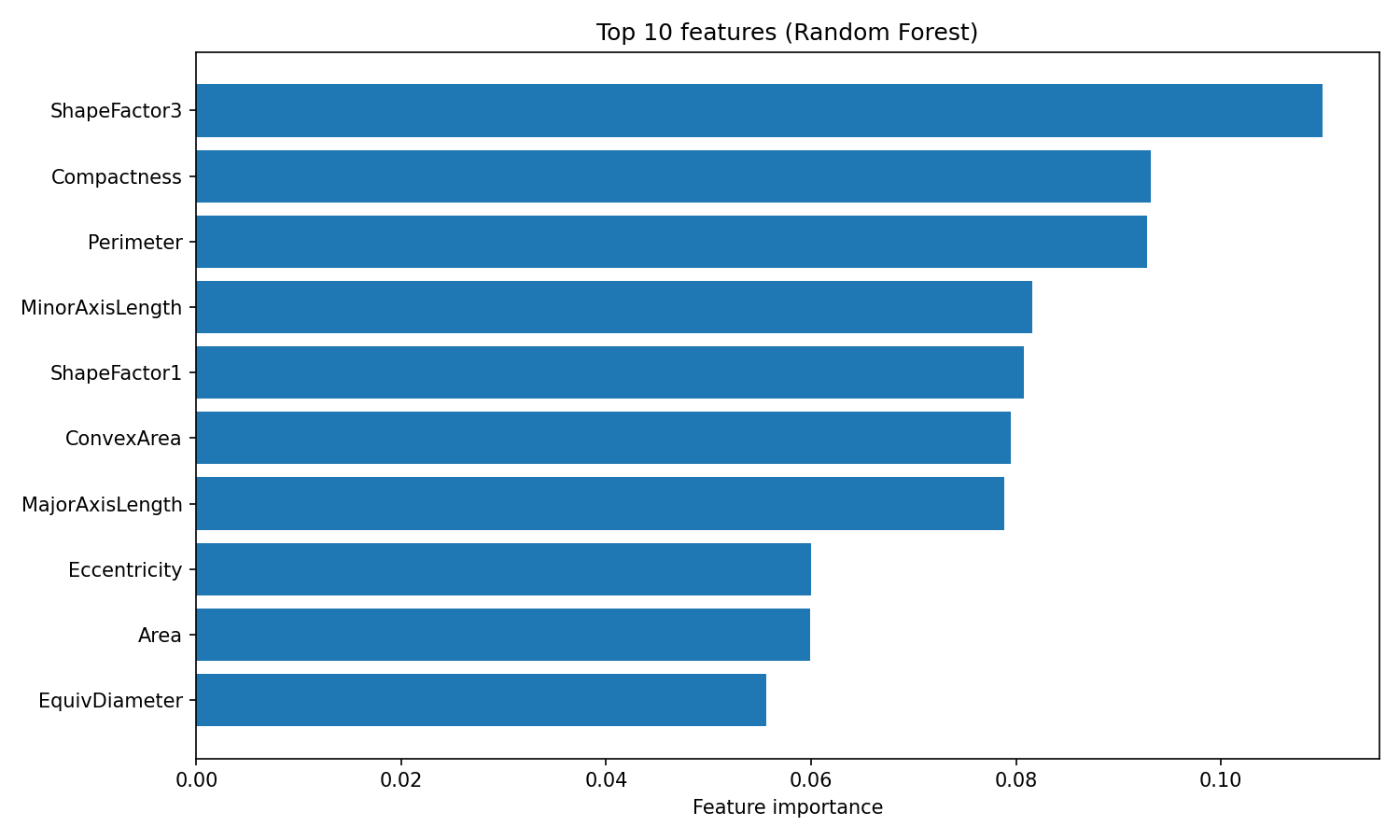
Importância dos recursos da Random Forest
O atributo “ feature_importances_ ” mostra um conjunto de pontuações que somam 1, onde valores mais altos indicam características que ajudaram mais nas decisões de divisão. O ShapeFactor3 e a Compactação são os que mais ajudam na classificação, seguidos por medidas geométricas como Perímetro e Comprimento do Eixo Menor. Essas características baseadas na forma capturam as diferenças visuais entre as variedades de feijão que os pesquisadores originais projetaram o conjunto de dados para medir.
A Random Forest tem três hiperparâmetros principais que vale a pena ajustar:
n_estimators: O número de árvores na floresta. Mais árvores dão previsões mais estáveis, mas demoram mais tempo para treinar. Os retornos diminuem após 200 árvores para a maioria dos conjuntos de dados.max_depth: A profundidade máxima de cada árvore. O padrão (None) faz as árvores crescerem até que as folhas sejam puras ou tenham menos de 2 amostras. Valores mais baixos podem evitar o sobreajuste.max_features: O número de características consideradas em cada divisão. O padrão "sqrt" funciona bem para classificação. Usar o método de árvore de decisão ( "log2" ) aumenta a diversidade, mas pode prejudicar a precisão individual das árvores.Uma busca rápida por esses parâmetros:
from sklearn.model_selection import GridSearchCV
param_grid = {
"n_estimators": [100, 200],
"max_depth": [10, 20, None],
"max_features": ["sqrt", "log2"]
}
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print(f"Best params: {grid_search.best_params_}")
print(f"Best CV accuracy: {grid_search.best_score_:.4f}")Best params: {'max_depth': None, 'max_features': 'sqrt', 'n_estimators': 200}
Best CV accuracy: 0.9244GridSearchCV tenta todas as combinações de parâmetros na grade e avalia cada uma usando validação cruzada. O argumento ` cv=3 ` divide os dados de treinamento em três partes, treinando em duas e validando em uma, alternando entre todas as combinações. A bandeira ` n_jobs=-1 ` faz a busca em todos os núcleos de CPU disponíveis ao mesmo tempo.
y_pred_tuned = grid_search.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test, y_pred_tuned):.4f}")Tuned test accuracy: 0.9214Ajustando a precisão das saliências de 92,0% para 92,1%, uma melhoria modesta. A melhor configuração usa os padrões para max_depth e max_features, com 200 árvores em vez de 100. A Random Forest costuma funcionar bem logo de cara, o que é um dos seus principais atrativos. Para saber mais sobre Random Forest e seus parâmetros, dá uma olhada no tutorial de classificação Random Forest do DataCamp. tutorial de classificação Random Forest.
O XGBoost (Extreme Gradient Boosting) usa um jeito diferente do Random Forest pra chegar na precisão. Enquanto o Random Forest diminui a variação calculando a média de árvores independentes, o XGBoost reduz o viés treinando árvores em sequência, com cada nova árvore corrigindo os erros do conjunto até o momento. Essa seção fala sobre como funciona o reforço de gradiente, o que torna o XGBoost especial e como treiná-lo e ajustá-lo no conjunto de dados Dry Beans.
O reforço de gradiente constrói um conjunto uma árvore de cada vez. A primeira árvore faz previsões sobre o alvo original. A segunda árvore não é treinada com base no alvo original, mas sim nos erros residuais da primeira árvore. A terceira árvore encaixa os resíduos que sobraram depois de adicionar as previsões da segunda árvore. Isso continua por centenas de rodadas, com cada nova árvore eliminando qualquer erro que ainda exista.
O termo “gradiente” é como o algoritmo decide o que ajustar. Em cada etapa, ele calcula o gradiente da função de perda em relação às previsões atuais. Para regressão com perda de erro quadrático, esse gradiente é só o resíduo (valor real menos valor previsto). Para classificação, a matemática é mais complexa, mas a intuição é a mesma: cada árvore é treinada para mover as previsões na direção que mais reduz a perda.
Um parâmetro de taxa de aprendizagem reduz a contribuição de cada árvore antes de adicioná-la ao conjunto. Com uma taxa de aprendizagem de 0,1, por exemplo, só 10% da previsão de cada árvore é adicionada. Isso faz com que o algoritmo dê passos menores e geralmente melhora a generalização. A desvantagem é que você precisa de mais árvores para atingir o mesmo nível de adequação. Uma taxa de aprendizagem pequena com muitas árvores costuma dar resultados melhores do que uma taxa de aprendizagem grande com poucas árvores.
O XGBoost é uma das várias implementações de reforço de gradiente, junto com o LightGBM e o CatBoost. Ele ficou famoso porque trouxe várias melhorias em relação a implementações anteriores, como o GradientBoostingClassifier do scikit-learn.
As principais adições são:
Essas características fazem com que o XGBoost seja mais rápido e mais resistente ao sobreajuste do que o gradiente de reforço básico. Os parâmetros de regularização permitem controlar diretamente a complexidade do modelo, o que é útil quando se trabalha com dados ruidosos ou de alta dimensão.
O XGBoost espera rótulos de classe numéricos em vez de strings, então o primeiro passo é codificar a variável alvo:
from xgboost import XGBClassifier
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.transform(y_test)
xgb = XGBClassifier(n_estimators=100, random_state=42, eval_metric="mlogloss")
xgb.fit(X_train, y_train_encoded)
y_pred_xgb = xgb.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test_encoded, y_pred_xgb):.4f}")
print(classification_report(y_test_encoded, y_pred_xgb, target_names=le.classes_))Accuracy: 0.9232
precision recall f1-score support
BARBUNYA 0.95 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.93 0.91 709
HOROZ 0.96 0.96 0.96 386
SEKER 0.95 0.96 0.95 406
SIRA 0.87 0.86 0.87 527
accuracy 0.92 2723
macro avg 0.94 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723O LabelEncoder mapeia nomes de classes para números inteiros (de 0 a 6) e guarda o mapeamento para que você possa converter as previsões de volta para nomes de classes. O argumento ` eval_metric="mlogloss" ` diz ao XGBoost para usar a perda logarítmica multiclasse para avaliação interna.
Logo de cara, o XGBoost consegue uma precisão de 92,3%, um pouco mais alta do que os 92,0% da Random Forest. O padrão por classe é parecido: Os grãos de Bombaim são super fáceis de classificar, enquanto os grãos Sira continuam sendo os mais difíceis de distinguir.
O XGBoost fornece importâncias de características com base no ganho, que mede a melhoria média na precisão que cada característica contribui em todas as divisões em que é usada:
importances_xgb = xgb.feature_importances_
sorted_idx_xgb = importances_xgb.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances_xgb[sorted_idx_xgb][::-1])
plt.yticks(range(10), feature_names[sorted_idx_xgb][::-1])
plt.xlabel("Feature importance (gain)")
plt.title("Top 10 features (XGBoost)")
plt.tight_layout()
plt.show()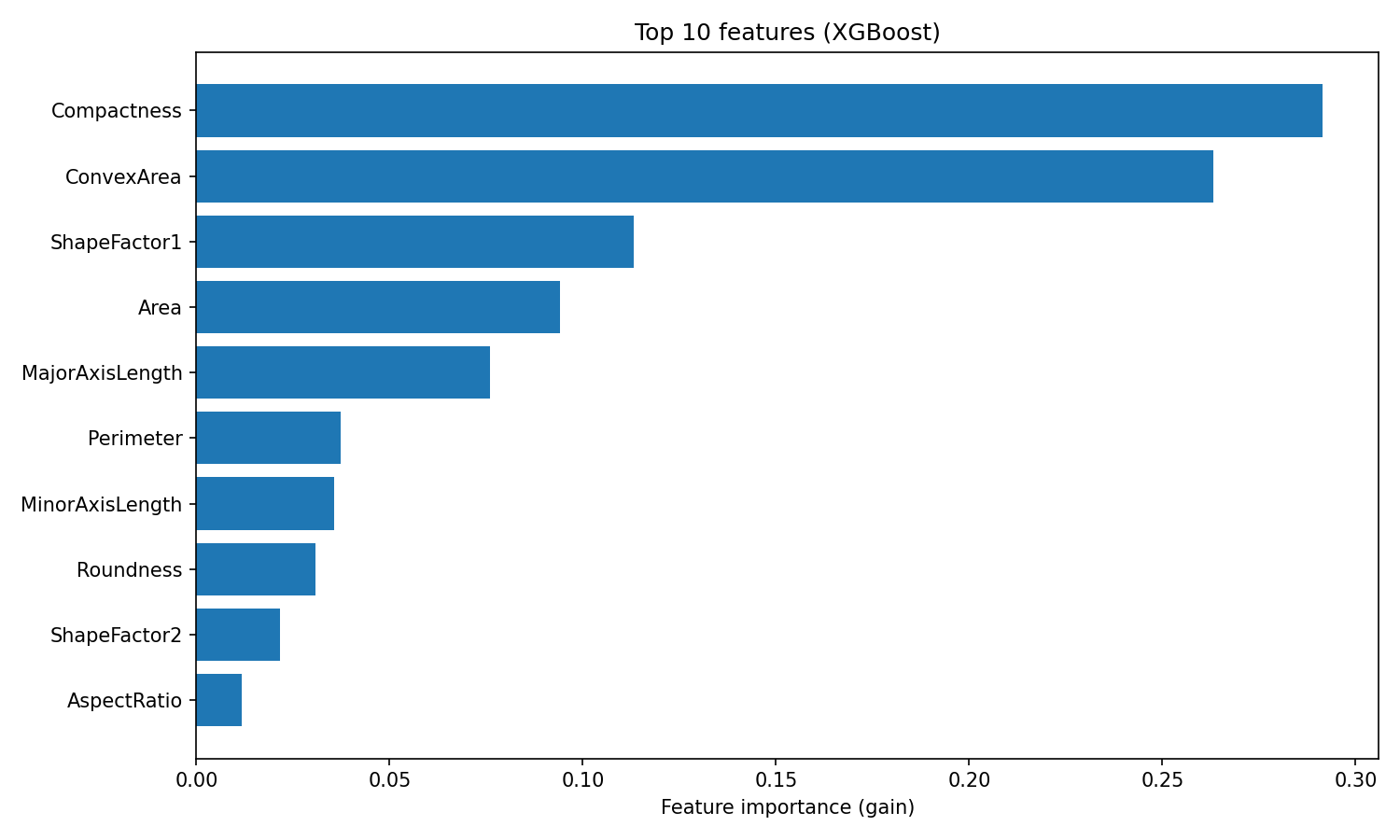
Importância dos recursos do XGBoost
A classificação é diferente da Random Forest. O XGBoost coloca Compactness e ConvexArea no topo, enquanto o Random Forest colocou o ShapeFactor3 em primeiro lugar.
Essa diferença mostra como os dois algoritmos usam os recursos: A Random Forest mede a frequência com que uma característica reduz a impureza em muitas árvores independentes, enquanto o XGBoost mede a precisão que cada característica adiciona ao corrigir resíduos. Ambas as classificações são válidas, elas só mostram diferentes aspectos da utilidade dos recursos.
O XGBoost tem mais opções de ajuste do que o Random Forest, o que mostra que ele é mais flexível. Os principais parâmetros a considerar são:
learning_rate: Encolhimento aplicado a cada árvore (padrão 0,3). Valores mais baixos exigem mais árvores, mas geralmente generalizam melhor.max_depth: Profundidade máxima da árvore (padrão 6). Árvores mais rasas reduzem o sobreajuste. A configuração padrão do XGBoost é mais conservadora do que a profundidade ilimitada do Random Forest.n_estimators: Número de rodadas de reforço. Mais rodadas permitem correções mais precisas, especialmente com uma taxa de aprendizagem baixa.reg_alpha: Regularização L1 nos pesos das folhas (padrão 0). Valores mais altos empurram os pesos para zero, criando modelos mais esparsos.reg_lambda: Regularização L2 nos pesos das folhas (padrão 1). Valores mais altos penalizam pesos grandes, suavizando as previsões.Uma pesquisa em grade sobre alguns desses parâmetros:
param_grid_xgb = {
"learning_rate": [0.05, 0.1],
"max_depth": [4, 6],
"n_estimators": [100, 200],
"reg_lambda": [1, 5]
}
grid_search_xgb = GridSearchCV(
XGBClassifier(random_state=42, eval_metric="mlogloss"),
param_grid_xgb,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search_xgb.fit(X_train, y_train_encoded)
print(f"Best params: {grid_search_xgb.best_params_}")
print(f"Best CV accuracy: {grid_search_xgb.best_score_:.4f}")Best params: {'learning_rate': 0.1, 'max_depth': 4, 'n_estimators': 200, 'reg_lambda': 5}
Best CV accuracy: 0.9284y_pred_xgb_tuned = grid_search_xgb.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test_encoded, y_pred_xgb_tuned):.4f}")Tuned test accuracy: 0.9251A melhor configuração usa árvores mais rasas (max_depth=4), mais regularização (reg_lambda=5) e o dobro de rodadas de reforço (n_estimators=200). Esse padrão é bem comum: O XGBoost costuma funcionar melhor com árvores individuais mais fracas combinadas por meio de mais rodadas de reforço. O ajuste melhora a precisão do teste de 92,3% para 92,5%.
Para saber mais sobre os parâmetros do XGBoost e recursos avançados como parada antecipada, dá uma olhada no tutorial do DataCamp sobre tutorial XGBoost em Python.
Com os dois modelos treinados e ajustados, veja como eles se comparam no conjunto de dados Dry Beans.
|
Métrico |
Floresta Aleatória |
XGBoost |
|
Precisão (padrão) |
92,0% |
92,3% |
|
Precisão (ajustada) |
92,1% |
92,5% |
|
Precisão macro |
0,93 |
0,94 |
|
Recuperação de macro |
0,93 |
0,93 |
|
Macro F1 |
0,93 |
0,93 |
|
Tempo de treinamento |
Rápido |
Moderado |
|
Esforço de ajuste |
Baixo |
Moderado |
Os números de precisão favorecem o XGBoost, mas a diferença diminui quando você olha para o macro F1. Os dois modelos têm 0,93, o que quer dizer que funcionam bem nas sete classes de grãos, em vez de só se destacarem na classe majoritária.
O desempenho por turma mostra uma história parecida:
|
Aula |
Floresta Aleatória F1 |
XGBoost F1 |
|
Bombaim |
1,00 |
1,00 |
|
Horoz |
0,96 |
0,96 |
|
Seker |
0,95 |
0,95 |
|
Cali |
0,94 |
0,94 |
|
Barbunya |
0,92 |
0,92 |
|
Dermason |
0,91 |
0,91 |
|
Sira |
0,86 |
0,87 |
Os dois modelos classificam as turmas da mesma forma. Os feijões Bombay são os mais fáceis de classificar (são os maiores e mais distintos fisicamente), enquanto os feijões Sira são os mais difíceis (a sua forma se sobrepõe aos feijões Dermason e Seker). A única vantagem do XGBoost por classe é uma melhoria de 1 ponto no F1 em relação ao Sira.
A diferença prática entre esses modelos não é a precisão. É quanto esforço você quer dedicar ao ajuste. O Random Forest teve um desempenho dentro de 0,4% do XGBoost usando os parâmetros padrão. O XGBoost precisava de uma pesquisa em grade sobre taxa de aprendizagem, profundidade da árvore e regularização para sair na frente.
|
Cenário |
Recomendação |
|
Linha de base rápida |
Floresta aleatória (padrões fortes, ajuste mínimo) |
|
Máxima precisão |
XGBoost (limite superior mais alto com ajuste adequado) |
|
Tempo limitado para ajustes |
Floresta aleatória (menos sensível a hiperparâmetros) |
|
Conjuntos de dados bem grandes |
XGBoost (melhor eficiência de memória, suporte a GPU) |
|
Interpretabilidade necessária |
Qualquer um (ambos fornecem importâncias de recursos) |
|
Implantação da produção |
Qualquer um (ambos têm bibliotecas maduras e estáveis) |
Um fluxo de trabalho razoável: comece com Random Forest para estabelecer uma linha de base e, em seguida, experimente o XGBoost se precisar obter um desempenho extra. A melhor escolha depende das suas limitações, não de uma classificação universal de algoritmos.
Neste tutorial, mostrei como o bagging e o boosting transformam modelos fracos em modelos fortes. Treina modelos em paralelo e calcula a média dos erros deles. O Boosting treina-os em sequência, com cada um corrigindo o que o anterior errou.
Random Forest e XGBoost são as implementações mais utilizadas. No conjunto de dados Dry Beans, ambos tiveram uma precisão de cerca de 92%. O XGBoost ficou na frente depois do ajuste, mas o Random Forest chegou lá quase sem nenhuma configuração. Essa é a verdadeira troca: A Random Forest é de baixa manutenção, enquanto o XGBoost recompensa o esforço extra.
Quando você estiver começando um novo problema, ajuste primeiro uma Random Forest. É uma base sólida que leva só alguns minutos pra configurar. Se você precisa aumentar a precisão e tem tempo para ajustar, mude para o XGBoost.
Pra ter mais prática com esses algoritmos, recomendo o curso Machine Learning com Modelos Baseados em Árvores do DataCamp.
Os melhores cursos de machine learning
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Tutorial
Moez Ali
Tutorial
Vidhi Chugh
