
Cursus
Principes fondamentaux de l'apprentissage automatique en Python
16 h
Un arbre de décision unique de type « a » est facile à interpréter, mais présente un risque de surajustement. Un modèle linéaire simple permet une bonne généralisation, mais ne permet pas de détecter les schémas complexes. Chaque type de modèle présente des lacunes qui limitent sa précision sur les données réelles.
Les méthodes d'ensemble résolvent ce problème en combinant plusieurs modèles en un seul. Au lieu de se baser sur un seul prédicteur, ils regroupent les prédictions de nombreux modèles afin que les erreurs individuelles s'annulent. Le résultat est généralement plus précis que n'importe quel modèle pris isolément.
Dans ce tutoriel, je vais vous présenter les différences entre les principales méthodes d'ensemble et me concentrer sur les deux algorithmes d'ensemble les plus populaires : Forêt aléatoire et XGBoost.
Vous apprendrez comment chacun d'eux fonctionne, les mettrez en œuvre tous les deux sur un problème de classification multiclasses et comparerez leurs performances. L'objectif est de vous fournir une compréhension pratique de quand utiliser chaque approche et comment les adapter à vos propres projets.
Si vous souhaitez approfondir vos connaissances pratiques, je vous recommande de consulter le cours Ensemble Methods in Python.
L'apprentissage d'ensemble forme plusieurs modèles et combine leurs prédictions en une seule sortie. Le concept est simple : différents modèles commettent différentes erreurs, donc faire la moyenne ou voter entre plusieurs modèles tend à annuler les erreurs individuelles.
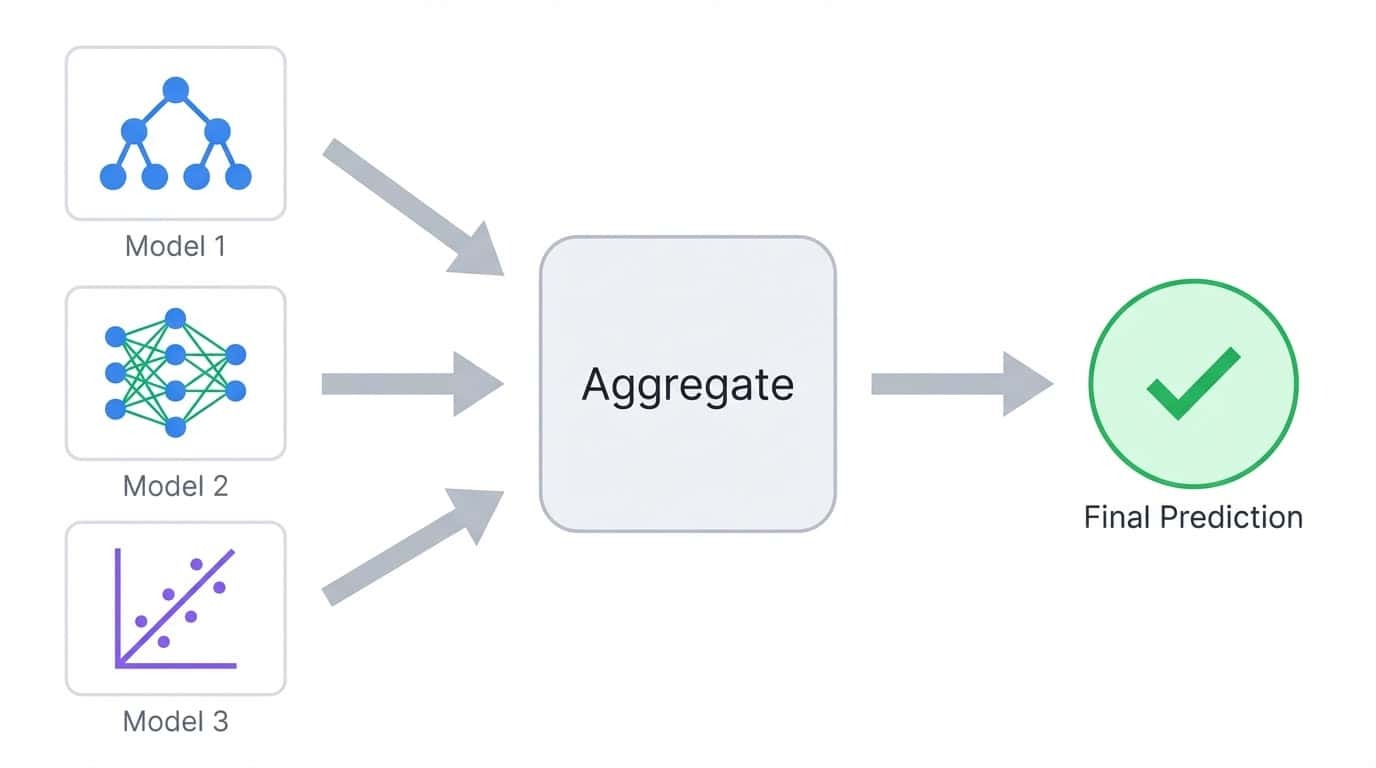
L'apprentissage d'ensemble combine les prédictions de plusieurs modèles en un seul résultat agrégé.
Veuillez considérer une classification dans laquelle vous entraînez cinq arbres de décision. Chaque arbre peut obtenir 80 % de prédictions correctes, mais ils n'échoueront pas tous sur les mêmes exemples. Lorsque vous cumulez leurs votes, la majorité a souvent raison, même si un ou deux arbres se trompent. Il s'agit du principe fondamental qui sous-tend toutes les méthodes d'ensemble.
Les modèles au sein d'un ensemble sont appelés « apprenants de base » (base learners). Il peut s'agir de n'importe quel algorithme, mais les arbres de décision sont le choix le plus courant, car ils sont rapides à former et produisent naturellement des prédictions variées lorsqu'on leur fournit différents sous-ensembles de données.
Les erreurs de modélisation proviennent de deux sources : le biais et la variance.
Le biais est l'erreur résultant d'une simplification excessive du problème. Un modèle linéaire qui tente d'ajuster une relation courbe présente un biais élevé, car il ne peut pas représenter le véritable schéma, quelle que soit la quantité de données fournies. Les modèles à forte biais produisent des prédictions similaires sur différents ensembles d'apprentissage, mais ces prédictions sont toujours inexactes.
L' de variance est l'erreur résultant d'une sensibilité excessive aux données d'apprentissage. Un arbre de décision profond qui mémorise l'ensemble d'apprentissage présente une variance élevée, car il capture le bruit en même temps que le signal. Si vous réentraîniez le même arbre sur un échantillon légèrement différent, vous obtiendriez des prédictions très différentes. Le modèle s'adapte bien aux données d'entraînement, mais ne fonctionne pas correctement avec de nouvelles données.

Biais et variance illustrés à l'aide de cibles de fléchettes : un biais élevé indique des prédictions cohérentes mais hors cible, tandis qu'une variance élevée indique des prédictions dispersées et incohérentes.
Vous pouvez considérer cela comme un problème de stabilité. Les modèles à biais élevé sont stables, mais ils sont systématiquement erronés de la même manière. Les modèles à forte variance sont instables et erronés de différentes manières selon les données qu'ils ont pu observer.
Le modèle idéal est à la fois stable et précis, mais la réduction d'un type d'erreur augmente souvent l'autre.
Les arbres de décision se situent clairement dans le camp des modèles à forte variance. Ils utilisent le fractionnement glouton, ce qui signifie que de petits changements dans les données d'apprentissage peuvent produire des structures arborescentes complètement différentes.
Entraînez le même algorithme d'arbre sur deux échantillons aléatoires provenant de la même population, et vous pourriez obtenir deux modèles qui ne se ressemblent pas du tout. Cette instabilité rend les arbres individuels peu fiables, mais en fait également des éléments de construction parfaits pour les ensembles.
Une variance élevée indique qu'il existe une marge d'amélioration grâce à l'agrégation. Les arbres sont également rapides à former et à gérer des relations non linéaires sans ingénierie manuelle des caractéristiques, ce qui explique pourquoi Random Forest et XGBoost les utilisent tous deux, bien qu'ils s'attaquent à des aspects différents du problème de biais-variance.
Les méthodes d'ensemble permettent de surmonter ce compromis en combinant plusieurs modèles :
Le bagging consiste à entraîner entraîne plusieurs modèles en parallèle sur des sous-ensembles aléatoires de données, puis calcule la moyenne de leurs prédictions. Cela réduit la variance en lissant les particularités des modèles individuels. L'intuition est simple : si chaque modèle commet des erreurs quelque peu indépendantes, la moyenne tend à annuler ces erreurs. Plus vous combinez de modèles, plus la prédiction finale devient stable. C'est pourquoi Random Forest utilise par défaut 100 arbres plutôt que 10.
Boosting entraîne les modèles de manière séquentielle, chaque nouveau modèle se concentrant sur les erreurs des précédents. Cela permet de réduire les biais en formant un apprenant solide à partir de nombreux apprenants moins expérimentés.
Examinons comment le bagging et le boosting fonctionnent dans la pratique.
Bagging signifie « bootstrap aggregating » (agrégation bootstrap). Le processus comprend trois étapes :
1. Créer plusieurs ensembles d'apprentissage en échantillonnant les données originales avec remplacement (échantillons bootstrap).
2. Entraîner un modèle sur chaque échantillon bootstrap de manière indépendante.
3. Combiner les prédictions par moyennage (régression) ou vote majoritaire (classification)
L'échantillonnage bootstrap signifie que chaque ensemble d'apprentissage est de la même taille que l'original, mais que certains exemples apparaissent plusieurs fois tandis que d'autres sont entièrement omis. En moyenne, chaque échantillon bootstrap contient environ 63 % des exemples uniques provenant des données originales. Les 37 % restants sont appelés échantillons hors sac et peuvent être utilisés à des fins de validation.
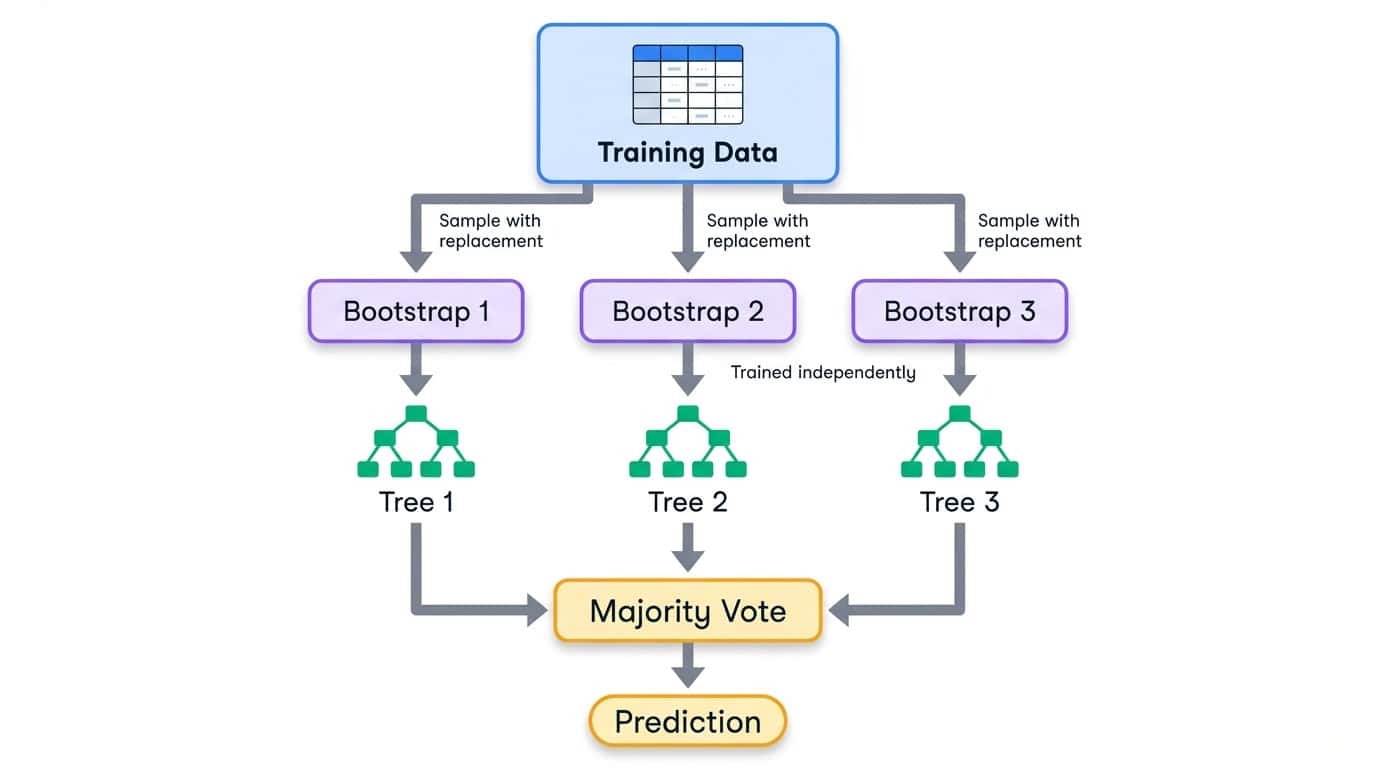
Flux de travail de bagging illustrant la division des données d'apprentissage en échantillons bootstrap, chacun entraînant un arbre de décision indépendant, puis combinés par vote majoritaire.
Étant donné que chaque modèle traite une partie différente des données, ils développent des particularités distinctes. Certains s'adaptent de manière excessive à une région de l'espace des caractéristiques, d'autres à une région différente. Lorsque l'on agrège leurs prévisions, ces erreurs individuelles ont tendance à s'annuler. La prédiction d'ensemble est plus stable que n'importe quel modèle individuel.
La formation se déroule en parallèle, car les modèles ne dépendent pas les uns des autres. Cela facilite considérablement la mise à l'échelle du bagging sur plusieurs cœurs de processeur. Random Forest, que vous implémenterez plus tard dans ce tutoriel, est l'algorithme de bagging le plus largement utilisé. Pour approfondir la théorie, veuillez consulter le guide de DataCamp sur le bagging dans l'apprentissage automatique. guide sur le bagging dans l'apprentissage automatique.
Le boostage adopte une approche différente. Au lieu de former les modèles indépendamment les uns des autres, il les forme successivement, chaque nouveau modèle se concentrant sur les exemples que les modèles précédents ont mal interprétés.
Le processus général se présente comme suit :
1. Entraîner un modèle peu performant sur l'ensemble complet de données d'entraînement
2. Identifier les exemples pour lesquels le modèle a fourni des prédictions peu satisfaisantes
3. Veuillez entraîner le prochain modèle en mettant particulièrement l'accent sur ces exemples complexes.
4. Répétez l'opération en ajoutant des modèles qui corrigent les erreurs restantes.
5. Combiner tous les modèles en une somme pondérée, où les modèles les plus performants obtiennent des pondérations plus élevées.
Le terme « apprenant faible » désigne un modèle dont les performances ne sont que légèrement supérieures à celles d'une estimation aléatoire. Les souches (arbres présentant une seule fente) constituent un choix courant. À lui seul, un moignon est pratiquement inutilisable. Cependant, l'augmentation des piles en contient des centaines, chacune corrigeant les erreurs laissées par les précédentes. L'ensemble final est un apprenant performant constitué de nombreuses contributions modestes.
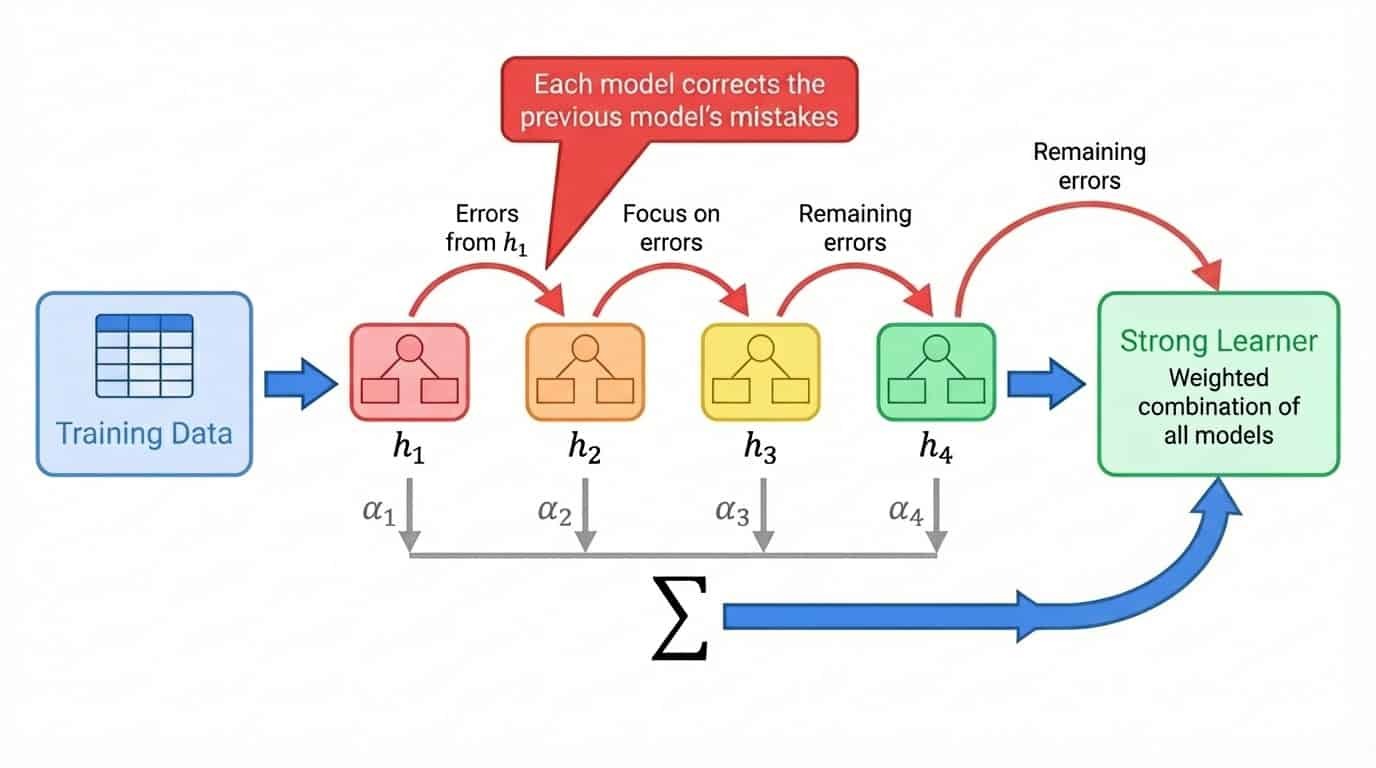
Amélioration du flux de travail illustrant l'entraînement séquentiel des modèles, où chaque modèle corrige les erreurs du modèle précédent, combinés en une somme pondérée.
Contrairement au bagging, le boosting est intrinsèquement séquentiel. Il n'est pas possible de former le modèle 47 tant que l'on ne connaît pas les exemples avec lesquels les modèles 1 à 46 ont rencontré des difficultés. Cela ralentit l'entraînement du boosting, mais permet souvent d'obtenir une plus grande précision, car chaque modèle est spécialement conçu pour corriger les faiblesses spécifiques de l'ensemble.
XGBoost, que vous implémenterez plus tard dans ce tutoriel, est un algorithme de gradient boosting qui est devenu le choix incontournable pour les données tabulaires. Je recommande l'introduction au boosting, qui aborde les aspects mathématiques de manière plus approfondie si vous souhaitez approfondir vos connaissances.
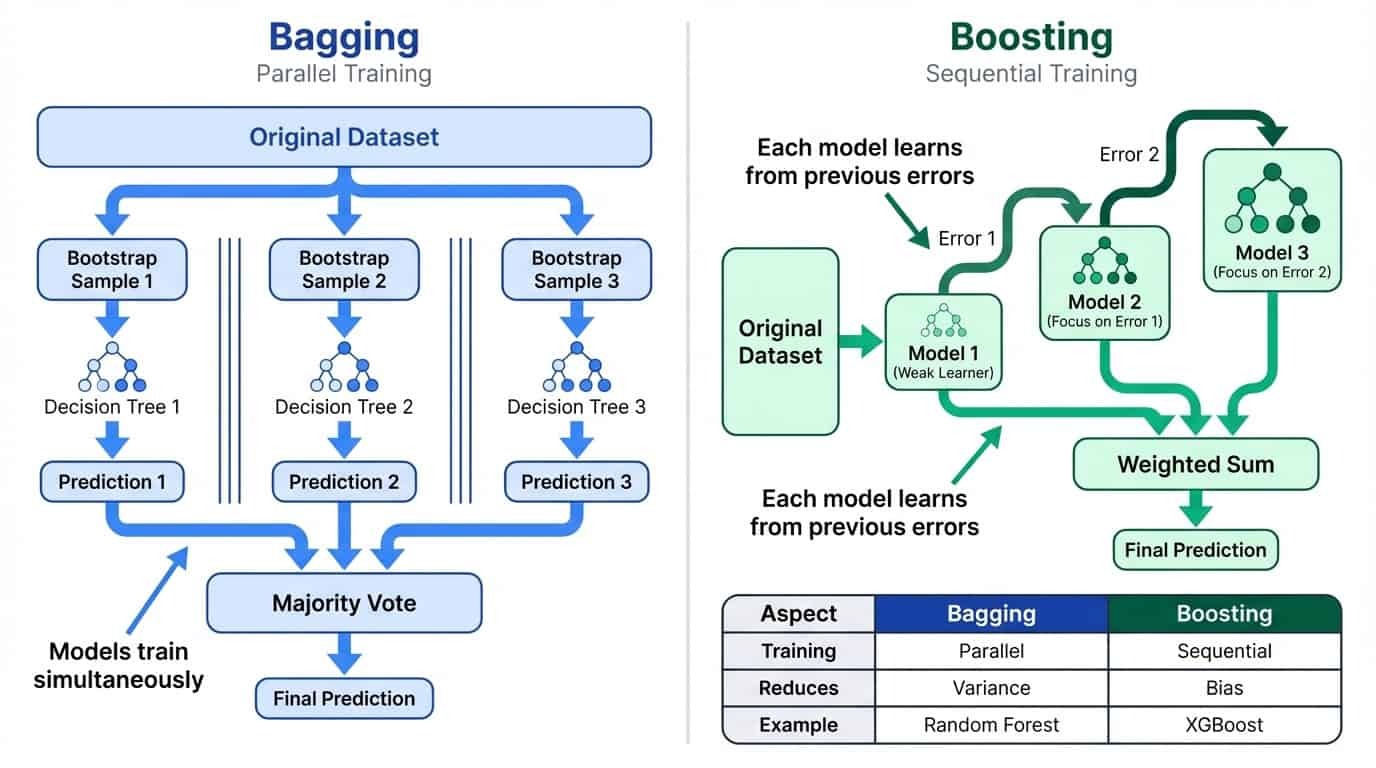
Comparaison côte à côte entre le bagging et le boosting : le bagging utilise un apprentissage parallèle pour réduire la variance, tandis que le boosting utilise un apprentissage séquentiel pour réduire le biais.
Le bagging et le boosting sont les stratégies d'ensemble les plus couramment utilisées, mais ce ne sont pas les seules options disponibles. Avant d'approfondir Random Forest et XGBoost, il est important de connaître les autres options disponibles.
La manière la plus simple de combiner des modèles consiste à les soumettre à un vote. Dans le cadre d'un vote strict, chaque modèle formule une prédiction, et la classe ayant obtenu le plus grand nombre de votes est déclarée gagnante. Si vous disposez d'une régression logistique, d'une machine à vecteurs de support et d'un arbre de décision, et que deux d'entre eux prédisent la classe A tandis que le troisième prédit la classe B, l'ensemble produit la classe A.
Le vote pondéré va plus loin en calculant la moyenne des probabilités prédites au lieu de compter les votes individuels. Un modèle qui prédit la classe A avec un niveau de confiance de 90 % contribue davantage à la décision finale qu'un modèle qui prédit A avec un niveau de confiance de 51 %. Cette méthode est généralement plus efficace que le vote strict, car elle permet de mesurer le degré de certitude de chaque modèle.
Vous pouvez également attribuer des pondérations afin de donner plus d'influence aux modèles les plus performants. Si votre régression logistique surpasse de manière fiable les autres sur les données de validation, vous pourriez pondérer ses prédictions à 2x tout en conservant les autres à 1x.
Le vote fonctionne mieux lorsqu'il combine des modèles qui abordent le problème de manière différente. Un modèle linéaire, un modèle arborescent et un modèle du plus proche voisin présentent chacun des lacunes différentes. Leurs prédictions combinées surpassent souvent celles de n'importe quel modèle individuel, même si aucun modèle n'est particulièrement performant. scikit-learn fournit les fonctions VotingClassifier et VotingRegressor à cette fin.
L'empilement approfondit davantage le concept d'ensemble. Au lieu de calculer la moyenne des prédictions, vous entraînez un deuxième modèle (appelé méta-apprenant) pour les combiner. Le processus fonctionne de la manière suivante : entraîner plusieurs modèles de base, collecter leurs prédictions sur un ensemble de validation, puis entraîner le méta-apprenant à mapper ces prédictions aux étiquettes correctes. Le méta-apprenant identifie à quel modèle de base se fier dans quelles situations.
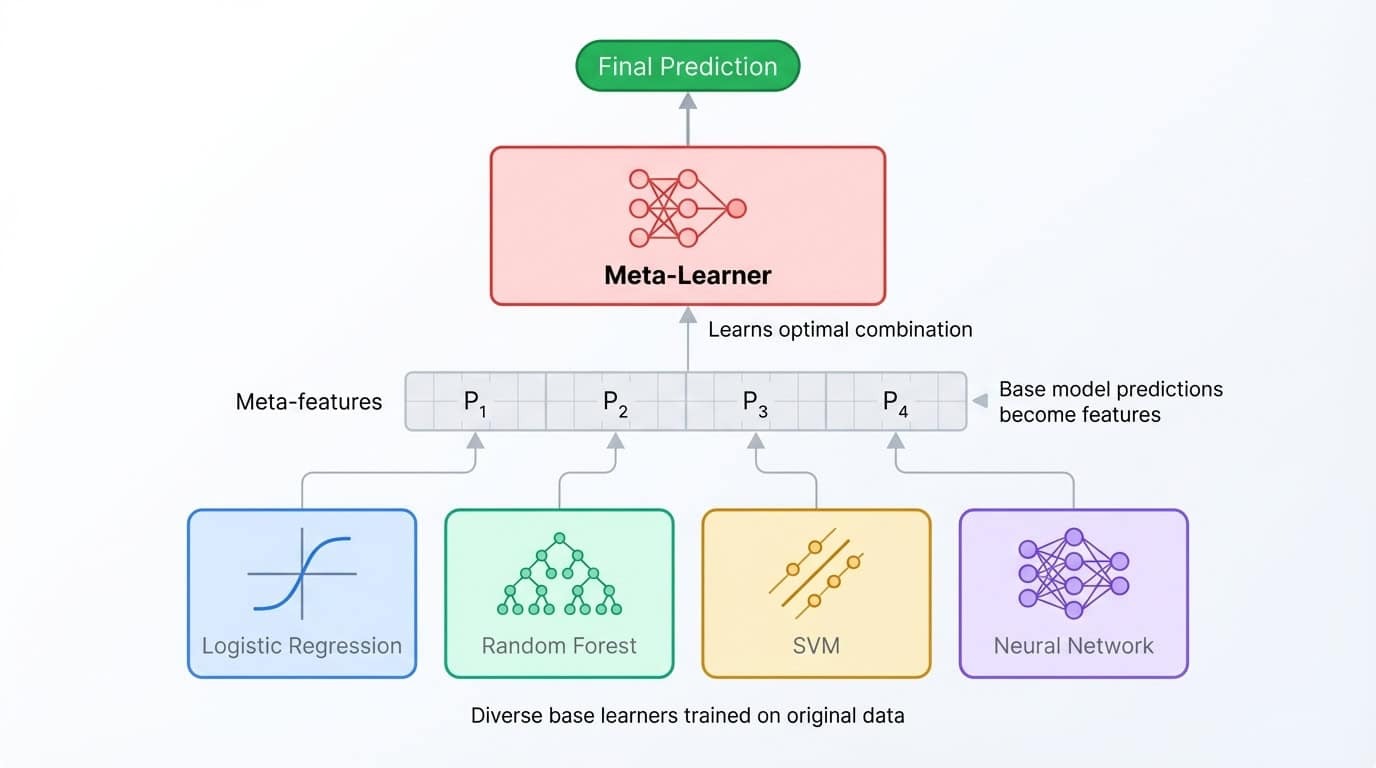
Architecture d'ensemble empilée présentant divers modèles de base fournissant des prédictions à un méta-apprenant qui les combine pour obtenir le résultat final.
Le mélange est une variante plus simple qui utilise un seul ensemble de test plutôt que des plis de validation croisée. Sa mise en œuvre est plus rapide, mais elle entraîne une perte de certaines données d'apprentissage et peut être plus susceptible de surapprendre l'ensemble de validation.
Les deux techniques permettent d'obtenir une précision accrue, mais les gains sont souvent modestes (amélioration de 0,1 à 0,5 %) par rapport à la complexité supplémentaire qu'elles impliquent. Les ensembles empilés sont plus complexes à déboguer, plus lents à former et plus difficiles à expliquer aux parties prenantes. Ils excellent dans les concours Kaggle où chaque décimale compte et où le temps de formation est illimité, mais ils justifient rarement les coûts supplémentaires en production.
Il est intéressant de noter que la plupart des ensembles empilés utilisent de toute façon Random Forest et XGBoost comme apprentissages de base. Ces deux algorithmes sont si puissants que leur combinaison revient souvent à une méthode sophistiquée pour calculer la moyenne de leurs prédictions.
Ce tutoriel se concentre sur Random Forest (bagging) et XGBoost (boosting) car ces deux méthodes permettent de traiter la grande majorité des problèmes liés aux données tabulaires dans le monde réel. Ils sont plus simples à mettre en œuvre, plus faciles à régler et plus faciles à entretenir que les ensembles empilés à plusieurs niveaux.
Si vous souhaitez approfondir vos connaissances en matière de vote et d'empilement, consultez les méthodes d'ensemble de DataCamp en Python. Ensemble Methods in Python de DataCamp couvre l'ensemble des techniques. Pour l'instant, nous allons nous familiariser avec l'ensemble de données.
Ce tutoriel utilise l'ensemble de données ensemble de données Dry Beans provenant du référentiel d'apprentissage automatique de l'UCI. Les chercheurs Koklu et Ozkan (2020) ont photographié 13 611 haricots secs de sept variétés différentes et ont extrait 16 caractéristiques géométriques de chaque image, notamment la surface, le périmètre, la longueur des axes et les facteurs de forme. La tâche consiste à classer chaque haricot par variété en fonction de ces mesures.
L'ensemble de données convient parfaitement à ce tutoriel, car il s'agit d'un problème multiclasses clair avec toutes les caractéristiques numériques. Aucune valeur manquante, aucun encodage catégoriel, aucun prétraitement du texte. Vous pouvez vous concentrer entièrement sur les méthodes d'ensemble.
!uv add ucimlrepo scikit-learn pandas xgboost
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
import pandas as pd
dry_bean = fetch_ucirepo(id=602)
X = dry_bean.data.features
y = dry_bean.data.targets.values.ravel()
print(f"Features shape: {X.shape}")
print(f"Target classes: {pd.Series(y).nunique()}")Features shape: (13611, 16)
Target classes: 7X.head()|
Zone |
Périmètre |
MajorAxisLength |
MinorAxisLength |
AspectRatio |
Excentricité |
Zone convexe |
Diamètre équivalent |
Étendue |
Solidité |
Rondesse |
Compacité |
ShapeFactor1 |
ShapeFactor2 |
ShapeFactor3 |
|
28395 |
610 291 |
208,178 |
173 889 |
1 197 |
0,550 |
28715 |
190,141 |
0,764 |
0,989 |
0,958 |
0,913 |
0,007 |
0,003 |
0,834 |
|
28734 |
638 018 |
200 525 |
182 734 |
1 097 |
0,412 |
29172 |
191 273 |
0,784 |
0,985 |
0,887 |
0,954 |
0,007 |
0,004 |
0,910 |
|
29380 |
624.110 |
212 826 |
175 931 |
1.210 |
0,563 |
29690 |
193 411 |
0,778 |
0,990 |
0,948 |
0,909 |
0,007 |
0,003 |
0,826 |
|
30008 |
645 884 |
210 558 |
182 517 |
1,154 |
0,499 |
30724 |
195 467 |
0,783 |
0,977 |
0,904 |
0,928 |
0,007 |
0,003 |
0,862 |
|
30140 |
620,134 |
201 848 |
190 279 |
1,061 |
0,334 |
30417 |
195 897 |
0,773 |
0,991 |
0,985 |
0,971 |
0,007 |
0,004 |
0,942 |
pd.Series(y).value_counts()DERMASON 3546
SIRA 2636
SEKER 2027
HOROZ 1928
CALI 1630
BARBUNYA 1322
BOMBAY 522Les classes sont raisonnablement équilibrées, Dermason étant la plus courante et Bombay la moins courante. Une division stratifiée préserve ces proportions à la fois dans les ensembles d'entraînement et de test :
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"Training set: {X_train.shape[0]} samples")
print(f"Test set: {X_test.shape[0]} samples")Training set: 10888 samples
Test set: 2723 samplesUne fois les données préparées, il est temps de former le premier modèle d'ensemble. Cette section explique le fonctionnement interne de Random Forest, décrit le processus d'apprentissage et d'évaluation, et montre comment ajuster ses hyperparamètres.
La forêt aléatoire applique le bagging aux arbres de décision avec une variante supplémentaire. Chaque arbre est entraîné sur un échantillon bootstrap des données (comme indiqué dans la section précédente), mais à chaque division, l'algorithme ne prend en compte qu'un sous-ensemble aléatoire de caractéristiques plutôt que l'ensemble complet.
Cette randomisation empêche les arbres de devenir trop similaires. Sans cela, les mêmes prédicteurs puissants domineraient chaque arbre, et l'ensemble ne serait constitué que de nombreuses copies de modèles presque identiques.
En obligeant chaque division à choisir parmi un ensemble limité de caractéristiques, l'algorithme crée des arbres diversifiés qui commettent des erreurs différentes. Lorsque ces arbres votent ensemble, leurs erreurs individuelles ont tendance à s'annuler.
Pour la classification, scikit-learn considère par défaut la racine carrée du nombre total de caractéristiques à chaque division. Avec 16 caractéristiques dans l'ensemble de données Dry Beans, chaque division n'évalue que 4 caractéristiques choisies de manière aléatoire. Le résultat est un ensemble d'arbres décorrélés qui généralise mieux que n'importe quel arbre individuel.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred_rf):.4f}")
print(classification_report(y_test, y_pred_rf))Accuracy: 0.9199
precision recall f1-score support
BARBUNYA 0.94 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.92 0.91 709
HOROZ 0.96 0.95 0.96 386
SEKER 0.94 0.96 0.95 406
SIRA 0.86 0.85 0.86 527
accuracy 0.92 2723
macro avg 0.93 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723Ce code génère une forêt de 100 arbres de décision, les entraîne sur les échantillons bootstrap et produit des prédictions par vote majoritaire. Le paramètre « random_state » fixe la graine aléatoire afin que les résultats soient reproductibles.
Le rapport de classification présente les performances par classe. La précision mesure le nombre de prédictions positives correctes, le rappel mesure le nombre de positives réelles trouvées, et le score F1 est leur moyenne harmonique. Les haricots Bombay sont parfaitement classés (probablement parce qu'ils sont physiquement distincts), tandis que les haricots Sira sont les plus difficiles à distinguer des autres variétés.
L'un des avantages de Random Forest réside dans l'interprétabilité de l'importance des caractéristiques. L'algorithme suit la mesure dans laquelle chaque caractéristique réduit l'impureté (l'indice de Gini, par défaut) dans tous les arbres, vous fournissant ainsi une mesure intégrée des variables les plus importantes :
import matplotlib.pyplot as plt
importances = rf.feature_importances_
feature_names = X.columns
sorted_idx = importances.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances[sorted_idx][::-1])
plt.yticks(range(10), feature_names[sorted_idx][::-1])
plt.xlabel("Feature importance")
plt.title("Top 10 features (Random Forest)")
plt.tight_layout()
plt.show()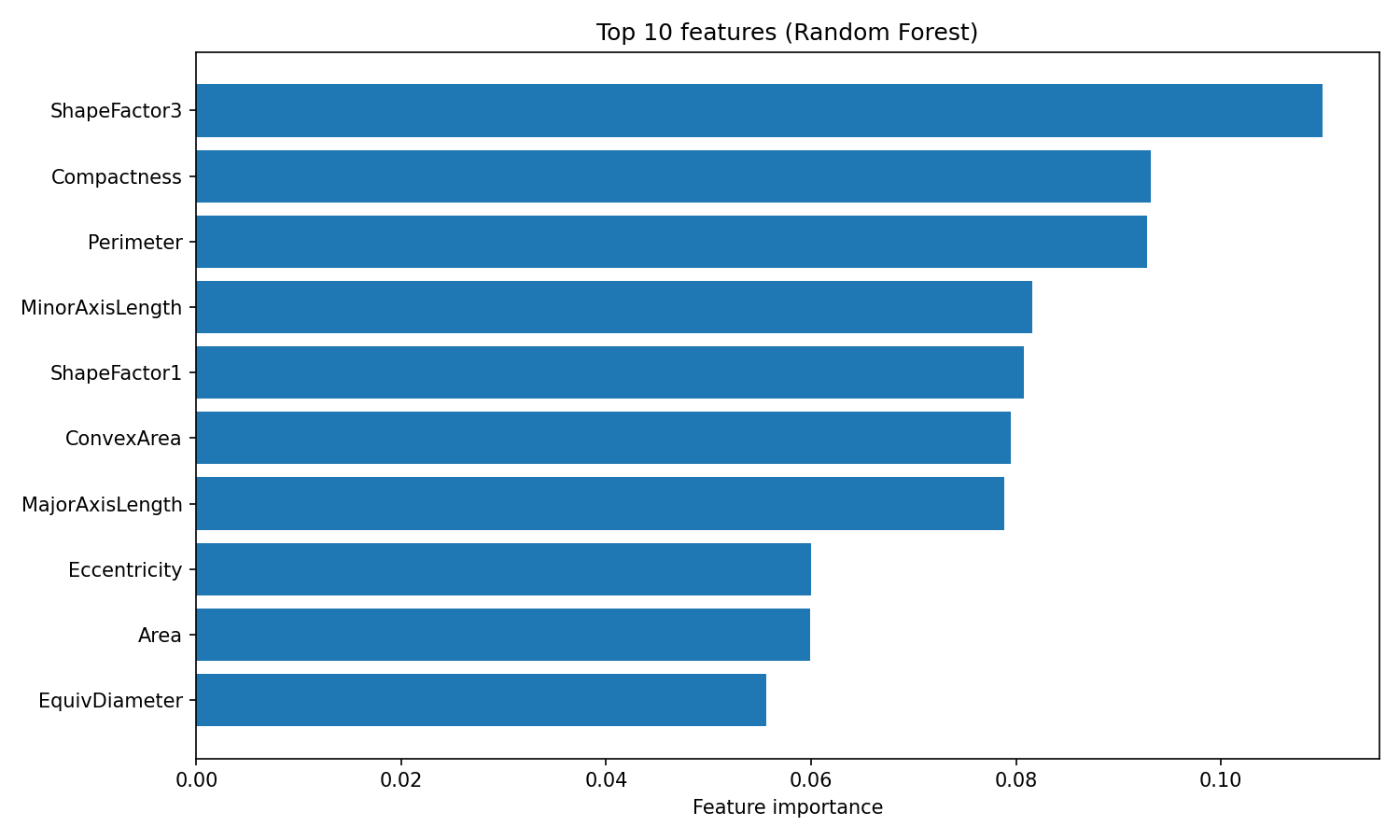
Importance des caractéristiques de la forêt aléatoire
L'attribut « feature_importances_ » renvoie un tableau de scores dont la somme est égale à 1, les valeurs les plus élevées indiquant les caractéristiques qui ont le plus contribué aux décisions de division. ShapeFactor3 et Compactness contribuent le plus à la classification, suivis par les mesures géométriques telles que Perimeter et MinorAxisLength. Ces caractéristiques basées sur la forme permettent de saisir les différences visuelles entre les variétés de haricots que les chercheurs à l'origine de l'étude ont cherché à mesurer dans leur ensemble de données.
Random Forest comporte trois hyperparamètres principaux qui méritent d'être ajustés :
n_estimators: Le nombre d'arbres dans la forêt. Un plus grand nombre d'arbres permet d'obtenir des prévisions plus stables, mais nécessite davantage de temps pour l'apprentissage. Les rendements diminuent au-delà de 200 arbres pour la plupart des ensembles de données.max_depth: La profondeur maximale de chaque arbre. La valeur par défaut (None) développe les arbres jusqu'à ce que les feuilles soient pures ou contiennent moins de deux échantillons. Des valeurs plus faibles peuvent empêcher le surajustement.max_features: Le nombre de caractéristiques prises en compte à chaque division. L'"sqrt" e par défaut fonctionne efficacement pour la classification. L'utilisation de l' "log2" e augmente la diversité au détriment de la précision individuelle des arbres.Une recherche rapide sur ces paramètres :
from sklearn.model_selection import GridSearchCV
param_grid = {
"n_estimators": [100, 200],
"max_depth": [10, 20, None],
"max_features": ["sqrt", "log2"]
}
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print(f"Best params: {grid_search.best_params_}")
print(f"Best CV accuracy: {grid_search.best_score_:.4f}")Best params: {'max_depth': None, 'max_features': 'sqrt', 'n_estimators': 200}
Best CV accuracy: 0.9244GridSearchCV teste toutes les combinaisons de paramètres dans la grille et évalue chacune d'entre elles à l'aide d'une validation croisée. L'argument ` cv=3 ` divise les données d'apprentissage en trois parties, en utilisant deux pour l'apprentissage et une pour la validation, en alternant toutes les combinaisons. Le drapeau ` n_jobs=-1 ` permet de paralléliser la recherche sur tous les cœurs de processeur disponibles.
y_pred_tuned = grid_search.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test, y_pred_tuned):.4f}")Tuned test accuracy: 0.9214Amélioration de la précision des bosses de 92,0 % à 92,1 %, une amélioration modeste. La configuration optimale utilise les valeurs par défaut pour max_depth et max_features, avec 200 arbres au lieu de 100. Random Forest offre souvent de bonnes performances dès son installation, ce qui constitue l'un de ses principaux atouts. Pour approfondir vos connaissances sur la forêt aléatoire et ses paramètres, veuillez consulter le tutoriel de DataCamp sur la classification par forêt aléatoire. tutoriel sur la classification Random Forest.
XGBoost (Extreme Gradient Boosting) adopte une approche différente de celle de Random Forest en matière de précision. Alors que Random Forest réduit la variance en calculant la moyenne d'arbres indépendants, XGBoost réduit le biais en entraînant les arbres de manière séquentielle, chaque nouvel arbre corrigeant les erreurs de l'ensemble jusqu'à présent. Cette section explique le fonctionnement du gradient boosting, ce qui rend XGBoost unique, et comment l'entraîner et l'ajuster sur l'ensemble de données Dry Beans.
Le gradient boosting construisent un ensemble arbre par arbre. Le premier arbre effectue des prédictions sur la cible d'origine. Le deuxième arbre n'est pas formé sur la cible d'origine, mais sur les erreurs résiduelles du premier arbre. Le troisième arbre s'adapte aux résidus restants après avoir ajouté les prédictions du deuxième arbre. Ce processus se poursuit pendant des centaines de cycles, chaque nouvel arbre éliminant les erreurs restantes.
Le terme « gradient » fait référence à la manière dont l'algorithme détermine ce qu'il convient d'ajuster. À chaque étape, il calcule le gradient de la fonction de perte par rapport aux prédictions actuelles. Pour la régression avec perte quadratique, ce gradient correspond simplement au résidu (valeur réelle moins valeur prédite). Pour la classification, les calculs sont plus complexes, mais le principe est le même : chaque arbre est entraîné à orienter les prédictions dans la direction qui réduit le plus les pertes.
Un paramètre de taux d'apprentissage réduit la contribution de chaque arbre avant de l'ajouter à l'ensemble. Avec un taux d'apprentissage de 0,1, par exemple, seulement 10 % de la prédiction de chaque arbre est ajoutée. Cela oblige l'algorithme à effectuer des pas plus petits et améliore généralement la généralisation. Le compromis est que vous avez besoin de plus d'arbres pour atteindre le même niveau d'ajustement. Un faible taux d'apprentissage associé à un grand nombre d'arbres tend à produire de meilleurs résultats qu'un taux d'apprentissage élevé associé à un petit nombre d'arbres.
XGBoost est l'une des nombreuses implémentations du gradient boosting, aux côtés de LightGBM et CatBoost. Il est devenu populaire car il a apporté plusieurs améliorations par rapport aux implémentations précédentes telles que scikit-learn's GradientBoostingClassifier.
Les principales nouveautés sont les suivantes :
Ces caractéristiques rendent XGBoost à la fois plus rapide et plus résistant au surajustement que le gradient boosting classique. Les paramètres de régularisation vous permettent de contrôler directement la complexité du modèle, ce qui est utile lorsque vous travaillez avec des données bruitées ou à haute dimension.
XGBoost attend des étiquettes de classe numériques plutôt que des chaînes de caractères. La première étape consiste donc à encoder la variable cible :
from xgboost import XGBClassifier
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.transform(y_test)
xgb = XGBClassifier(n_estimators=100, random_state=42, eval_metric="mlogloss")
xgb.fit(X_train, y_train_encoded)
y_pred_xgb = xgb.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test_encoded, y_pred_xgb):.4f}")
print(classification_report(y_test_encoded, y_pred_xgb, target_names=le.classes_))Accuracy: 0.9232
precision recall f1-score support
BARBUNYA 0.95 0.89 0.92 265
BOMBAY 1.00 1.00 1.00 104
CALI 0.94 0.94 0.94 326
DERMASON 0.90 0.93 0.91 709
HOROZ 0.96 0.96 0.96 386
SEKER 0.95 0.96 0.95 406
SIRA 0.87 0.86 0.87 527
accuracy 0.92 2723
macro avg 0.94 0.93 0.93 2723
weighted avg 0.92 0.92 0.92 2723L'LabelEncoder e associe les noms de classes à des entiers (de 0 à 6) et stocke cette correspondance afin que vous puissiez reconvertir les prédictions en noms de classes. L'argument « eval_metric="mlogloss" » indique à XGBoost d'utiliser la perte logarithmique multiclasses pour l'évaluation interne.
Dès son installation, XGBoost atteint une précision de 92,3 %, légèrement supérieure à celle de Random Forest (92,0 %). Le modèle par classe est similaire : Les haricots Bombay sont parfaitement classés, tandis que les haricots Sira restent les plus difficiles à distinguer.
XGBoost fournit des importances de caractéristiques basées sur le gain, qui mesure l'amélioration moyenne de la précision apportée par chaque caractéristique dans toutes les divisions où elle est utilisée :
importances_xgb = xgb.feature_importances_
sorted_idx_xgb = importances_xgb.argsort()[::-1][:10]
plt.figure(figsize=(10, 6))
plt.barh(range(10), importances_xgb[sorted_idx_xgb][::-1])
plt.yticks(range(10), feature_names[sorted_idx_xgb][::-1])
plt.xlabel("Feature importance (gain)")
plt.title("Top 10 features (XGBoost)")
plt.tight_layout()
plt.show()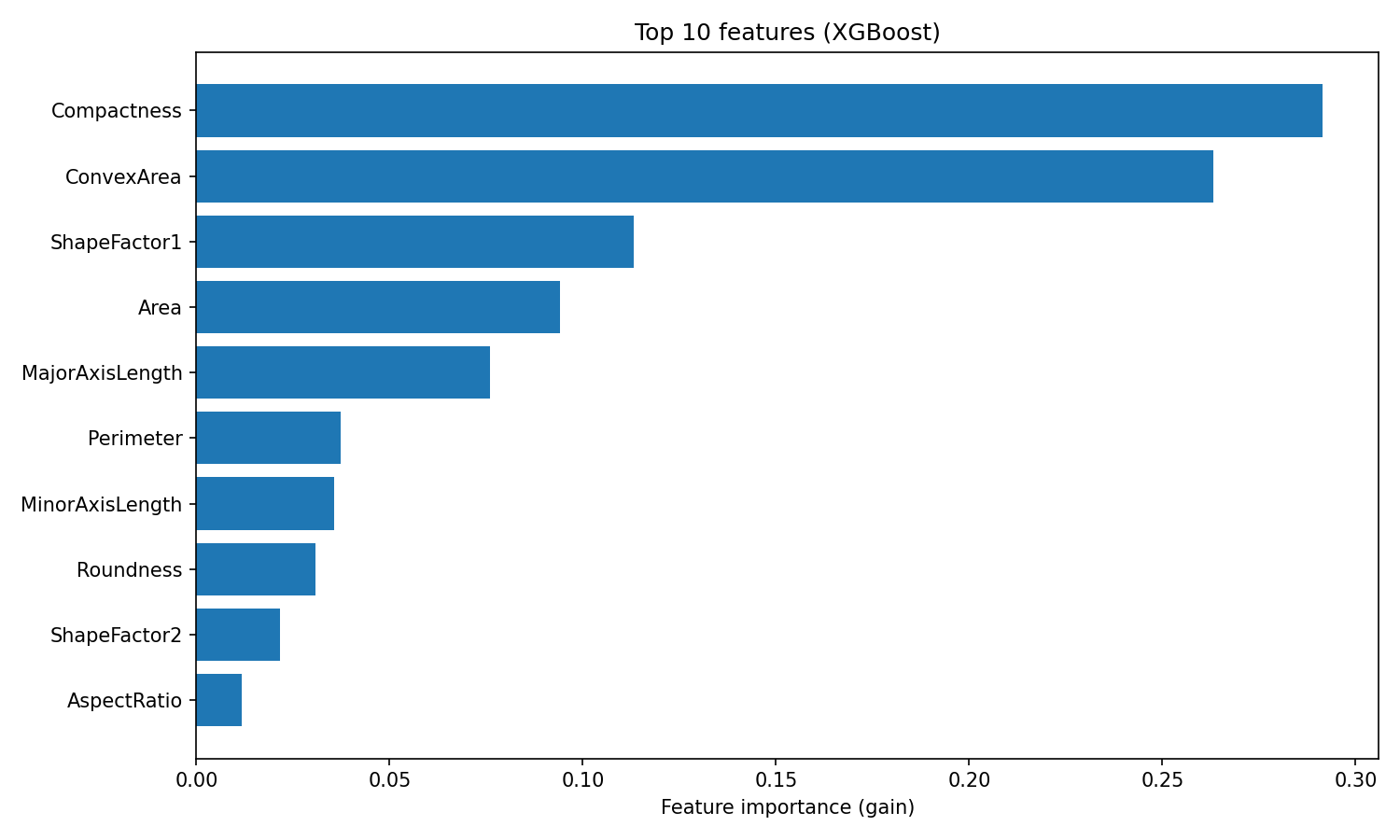
Importance des caractéristiques XGBoost
Le classement diffère de celui de Random Forest. XGBoost place la compacité et la zone convexe en tête, tandis que Random Forest classe ShapeFactor3 en première position.
Cette différence reflète la manière dont les deux algorithmes utilisent les caractéristiques : Random Forest évalue la fréquence à laquelle une caractéristique réduit l'impureté dans de nombreux arbres indépendants, tandis que XGBoost mesure le degré de précision que chaque caractéristique ajoute lors de la correction des résidus. Les deux classements sont valables, ils reflètent simplement différents aspects de l'utilité des fonctionnalités.
XGBoost dispose de plus de paramètres de réglage que Random Forest, ce qui reflète sa plus grande flexibilité. Les principaux paramètres à prendre en compte sont les suivants :
learning_rate: Rétrécissement appliqué à chaque arbre (valeur par défaut : 0,3). Des valeurs plus faibles nécessitent davantage d'arbres, mais permettent souvent une meilleure généralisation.max_depth: Profondeur maximale de l'arborescence (valeur par défaut : 6). Les arbres moins profonds réduisent le surajustement. La valeur par défaut de XGBoost est plus prudente que la profondeur illimitée de Random Forest.n_estimators: Nombre de cycles de renforcement. Un nombre plus élevé de cycles permet d'effectuer des corrections plus précises, en particulier avec un faible taux d'apprentissage.reg_alpha: Régularisation L1 sur les poids des feuilles (valeur par défaut : 0). Des valeurs plus élevées tendent vers zéro, ce qui crée des modèles plus clairsemés.reg_lambda: Régularisation L2 sur les poids des feuilles (valeur par défaut : 1). Les valeurs plus élevées pénalisent les poids importants, ce qui lisse les prévisions.Une recherche par grille sur certains de ces paramètres :
param_grid_xgb = {
"learning_rate": [0.05, 0.1],
"max_depth": [4, 6],
"n_estimators": [100, 200],
"reg_lambda": [1, 5]
}
grid_search_xgb = GridSearchCV(
XGBClassifier(random_state=42, eval_metric="mlogloss"),
param_grid_xgb,
cv=3,
scoring="accuracy",
n_jobs=-1
)
grid_search_xgb.fit(X_train, y_train_encoded)
print(f"Best params: {grid_search_xgb.best_params_}")
print(f"Best CV accuracy: {grid_search_xgb.best_score_:.4f}")Best params: {'learning_rate': 0.1, 'max_depth': 4, 'n_estimators': 200, 'reg_lambda': 5}
Best CV accuracy: 0.9284y_pred_xgb_tuned = grid_search_xgb.best_estimator_.predict(X_test)
print(f"Tuned test accuracy: {accuracy_score(y_test_encoded, y_pred_xgb_tuned):.4f}")Tuned test accuracy: 0.9251La meilleure configuration utilise des arbres moins profonds (max_depth=4), davantage de régularisation (reg_lambda=5) et deux fois plus de cycles de boosting (n_estimators=200). Ce schéma est courant : XGBoost obtient souvent de meilleurs résultats avec des arbres individuels plus faibles combinés à travers plusieurs cycles de boosting. Le réglage améliore la précision du test de 92,3 % à 92,5 %.
Pour approfondir vos connaissances sur les paramètres et les fonctionnalités avancées de XGBoost, telles que l'arrêt anticipé, veuillez consulter le tutoriel DataCamp intitulé XGBoost in Python.
Une fois les deux modèles entraînés et ajustés, voici comment ils se comparent sur l'ensemble de données Dry Beans.
|
Système métrique |
Forêt aléatoire |
XGBoost |
|
Précision (par défaut) |
92,0 % |
92,3 % |
|
Précision (ajustée) |
92,1 % |
92,5 % |
|
Précision macro |
0,93 |
0,94 |
|
Rappel macro |
0,93 |
0,93 |
|
Macro F1 |
0,93 |
0,93 |
|
Durée de la formation |
Rapide |
Modéré |
|
Effort de réglage |
Faible |
Modéré |
Les chiffres relatifs à la précision sont favorables à XGBoost, mais l'écart se réduit lorsque l'on examine le macro F1. Les deux modèles obtiennent un score de 0,93, ce qui signifie qu'ils affichent des performances équivalentes pour les sept catégories de grains, plutôt que d'exceller uniquement pour la catégorie majoritaire.
Les performances par classe présentent une tendance similaire :
|
Classe |
Forêt aléatoire F1 |
XGBoost F1 |
|
Bombay |
1,00 |
1,00 |
|
Horoz |
0,96 |
0,96 |
|
Seker |
0,95 |
0,95 |
|
Cali |
0,94 |
0,94 |
|
Barbunya |
0,92 |
0,92 |
|
Dermason |
0,91 |
0,91 |
|
Sira |
0,86 |
0,87 |
Les deux modèles classent les classes de manière identique. Les haricots Bombay sont les plus faciles à classer (ils sont les plus gros et les plus distincts physiquement), tandis que les haricots Sira sont les plus difficiles (leur forme se confond avec celle des haricots Dermason et Seker). Le seul avantage de XGBoost par classe est une amélioration de 1 point du score F1 par rapport à Sira.
La différence pratique entre ces modèles ne réside pas dans leur précision. Il s'agit de l'effort que vous êtes prêt à consacrer au réglage. Random Forest a obtenu des résultats similaires à ceux de XGBoost, avec un écart de 0,4 % en utilisant les paramètres par défaut. XGBoost a nécessité une recherche par grille sur le taux d'apprentissage, la profondeur de l'arbre et la régularisation pour prendre l'avantage.
|
Scénario |
Recommandation |
|
Référence rapide |
Forêt aléatoire (paramètres par défaut solides, réglage minimal) |
|
Optimisation de la précision |
XGBoost (plafond plus élevé avec un réglage approprié) |
|
Temps limité pour le réglage |
Forêt aléatoire (moins sensible aux hyperparamètres) |
|
Ensembles de données de grande taille |
XGBoost (meilleure efficacité mémoire, prise en charge GPU) |
|
Nécessité d'interprétabilité |
L'un ou l'autre (les deux fournissent des informations importantes) |
|
Déploiement de la production |
L'un ou l'autre (les deux disposent de bibliothèques matures et stables) |
Un processus de travail raisonnable : commencez par Random Forest pour établir une base de référence, puis essayez XGBoost si vous avez besoin d'optimiser les performances. Le choix optimal dépend de vos contraintes, et non d'un classement universel des algorithmes.
Dans ce tutoriel, j'ai démontré comment le bagging et le boosting transforment des modèles faibles en modèles performants. Modèles de trains parallèles et calcul de la moyenne de leurs erreurs. Le renforcement les entraîne dans l'ordre, chacun corrigeant les erreurs du précédent.
Random Forest et XGBoost sont les implémentations les plus courantes. Sur l'ensemble de données Dry Beans, les deux ont atteint une précision d'environ 92 %. XGBoost a pris l'avantage après réglage, mais Random Forest a atteint le résultat souhaité sans presque aucune configuration. C'est le véritable compromis : Random Forest nécessite peu de maintenance, tandis que XGBoost récompense les efforts supplémentaires.
Lorsque vous abordez un nouveau problème, commencez par ajuster une forêt aléatoire. Il s'agit d'une base solide qui ne nécessite que quelques minutes pour être configurée. Si vous avez besoin d'une plus grande précision et disposez du temps nécessaire pour effectuer des réglages, veuillez passer à XGBoost.
Pour acquérir davantage d'expérience pratique avec ces algorithmes, je recommande le cours « Machine Learning with Tree-Based Models » (Apprentissage automatique avec des modèles basés sur des arbres) de DataCamp.
Meilleurs cours sur l'apprentissage automatique
Cursus
Cours
Cours