
Kurs
Arbeiten mit Llama 3
2 Std.
13.9K
Kimi K2, entwickelt von Moonshot AI, ist ein supermodernes Mixture-of-Experts (MoE)-Sprachmodell. Es ist super in Sachen neuem Wissen, logischem Denken und Programmieren und wurde extra für agentenbasierte Fähigkeiten wie den Einsatz von Tools und selbstständiges Lösen von Problemen optimiert.
Wie wir in unserem Kimi K2-Leitfaden, erzielt das Modell hervorragende Benchmark-Ergebnisse und ist damit das beste Open-Source-Sprachmodell für allgemeine Zwecke. Wir erleben gerade die Deepseek R1, und um das zu feiern, zeige ich dir, wie du dieses riesige 1-Terabyte-Modell auf einer einzigen GPU laufen lassen kannst.
Wir zeigen dir, wie du den Runpod-Rechner auf setzt, llama.cpp installierst und das Modell schneller runterladen kannst. Außerdem werden wir das Modell mit der CLI llama.cpp ausführen und die Modellschichten in den RAM auslagern. Letztendlich werden wir uns mit den typischen Problemen beschäftigen, die beim Ausführen dieser Modelle auftauchen.
Geh zur Runpod GPU Cloud und erstelle eine Cloud mit dem A100 SXM-Rechner unter Verwendung des Python Container Image Version 2.8.0.
Erhöhe dann den Speicherplatz für den Container mit der Option „Pod bearbeiten“ auf 300 GB.
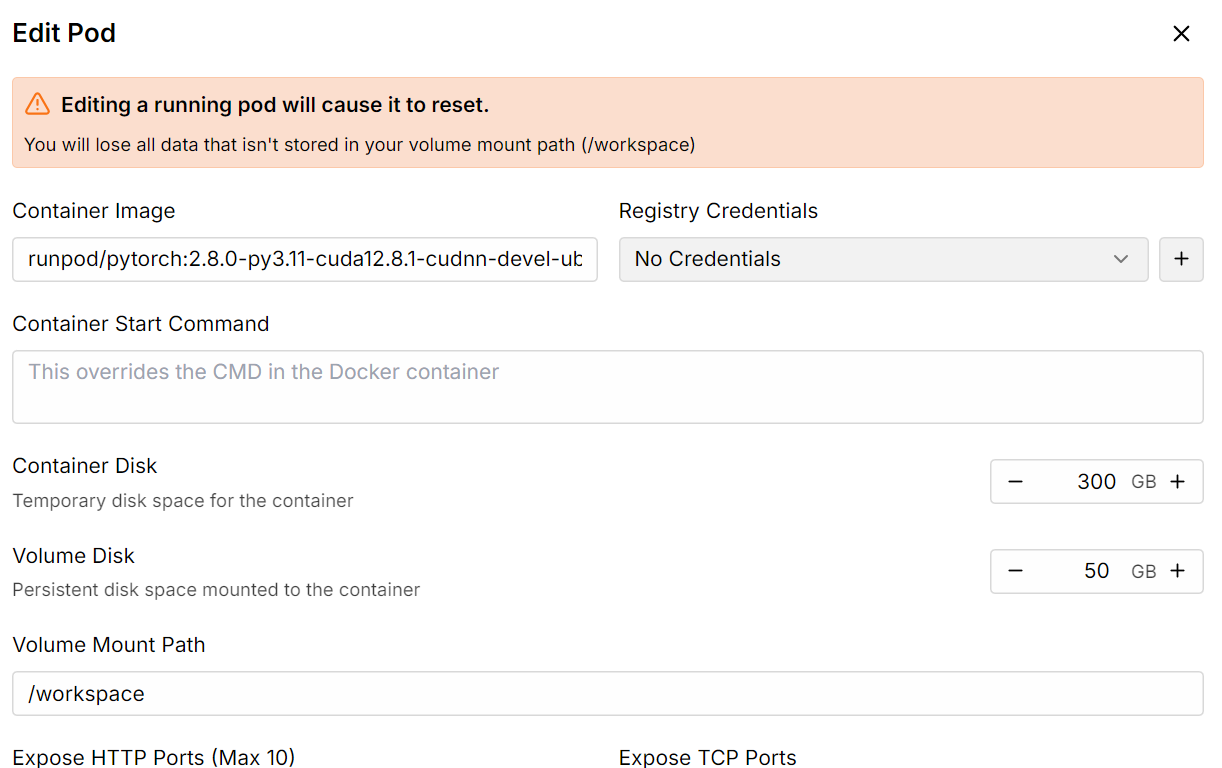
Sobald alles eingerichtet ist, siehst du, dass du 300 GB Speicherplatz hast, was ausreichend ist, da unser 1-Bit-quantisiertes Modell 250 GB Speicherplatz benötigt.
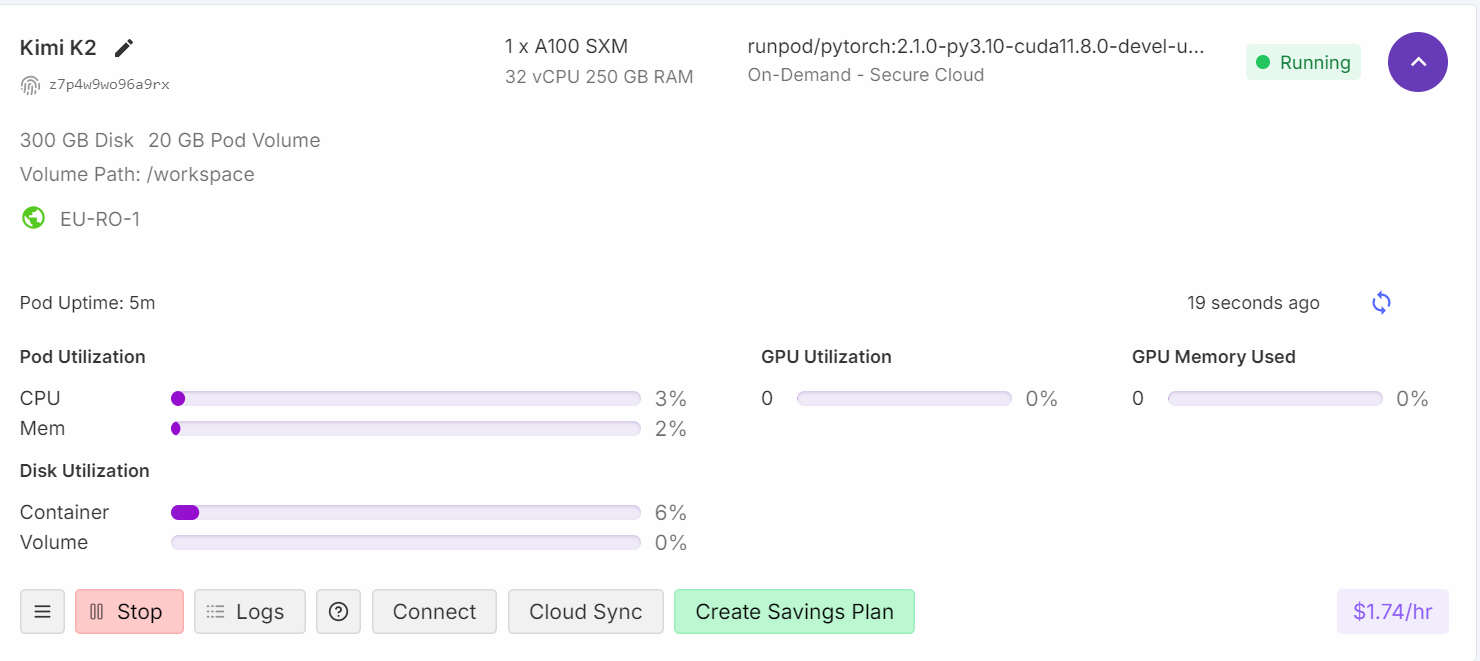
1. Klick auf den „Verbinden“-Button und starte die Jupyter Lab-Instanz. Mach ein neues Notebook und installiere die nötigen Linux-Tools, wie zum Beispiel cmake und curl.
!apt-get update
!apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
2. Wechsle ins Stammverzeichnis. Wir werden das Arbeitsverzeichnis nicht benutzen. Der Grund dafür ist, dass so sowohl die Download- als auch die Ladegeschwindigkeit des Modells erhöht werden. Mehr dazu erfährst du im Abschnitt zur Fehlerbehebung am Ende.
%cd ..3. Klon die neueste Version des Repositorys „llama.cpp“.
!git clone https://github.com/ggml-org/llama.cpp
4. Richte die Build-Optionen ein. Wir führen den Build für einen GPU-Rechner aus. Wenn du CPU-Inferenz nutzen willst, ändere bitte DGGML_CUDA=ON in DGGML_CUDA=OFF.
!cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DLLAMA_CURL=ON \
-DCMAKE_CUDA_ARCHITECTURES="80;90" \
-DCMAKE_CUDA_FLAGS="-Wno-deprecated-gpu-targets"
5. Wir verwenden den Befehl „ cmake “, um die Tools zu erstellen: „ llama-quantize “, „ llama-cli “, „ llama-gguf-split “ und „ llama-mtmd-cli “.
!cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split llama-mtmd-cli
6. Kopiere alle Build-Tools ins Haupt-Repository, damit wir sie leicht finden können.
!cp llama.cpp/build/bin/llama-* llama.cppDie quantisierten Versionen des Kimi K2-Modells von Unsloth unterstützen xnet, wodurch Downloads und Uploads viermal schneller als mit Git LFS möglich sind. Um es lokal zu aktivieren, installiere bitte die neueste Version von huggingface_hub und hf_transfer:
!pip install huggingface_hub hf_transfer
Mit der API „ snapshot_download “ kannst du nur die 1-Bit-quantisierten GGUF-Modelldateien für das Repository runterladen:
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/Kimi-K2-Instruct-GGUF",
local_dir = "/unsloth/Kimi-K2-Instruct-GGUF",
allow_patterns = ["*UD-TQ1_0*"],
)Der Download kann je nach Internetverbindung und Speicherplatz etwas dauern.
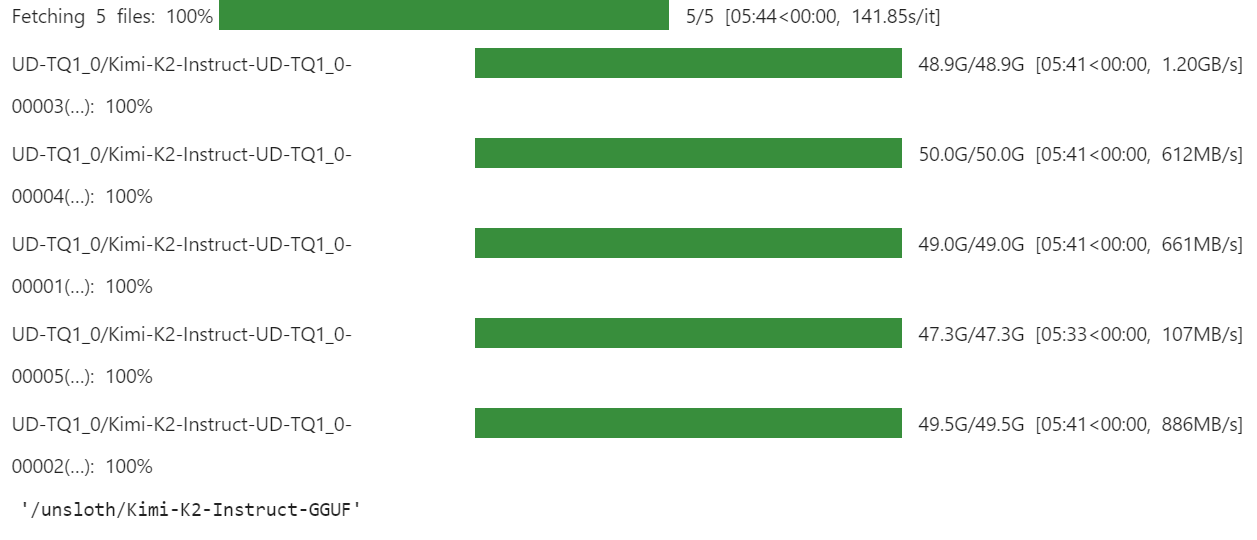
Für uns ging das super schnell, weil wir mit xnet schnellere Speicherlösungen haben.
Jetzt ist es an der Zeit, unsere quantisierte Version des Modells zu testen. Hier hab ich die meiste Zeit mit Debuggen verbracht, weil ich versuche, das Ganze auf einer einzigen GPU laufen zu lassen. Das ist zwar nicht unmöglich, bringt aber ein paar Probleme beim Laden und Ausführen des Modells mit sich.
Wir nutzen alle CPU-Threads und laden die GPU so viel wie möglich, was bedeutet, dass die CPU bei den Up- und Down- Projektions-Mixture-of-Experts-Layern entlastet wird.
Hier ist der Befehl, den wir im Terminal ausführen und der reibungslos funktioniert:
./llama.cpp/llama-cli \
--model /unsloth/Kimi-K2-Instruct-GGUF/UD-TQ1_0/Kimi-K2-Instruct-UD-TQ1_0-00001-of-00005.gguf \
--cache-type-k q4_0 \
--threads -1 \
--n-gpu-layers 99 \
--temp 0.6 \
--min_p 0.01 \
--ctx-size 16384 \
--seed 3407 \
-ot ".ffn_(up|down)_exps.=CPU" \
--prompt "Hey"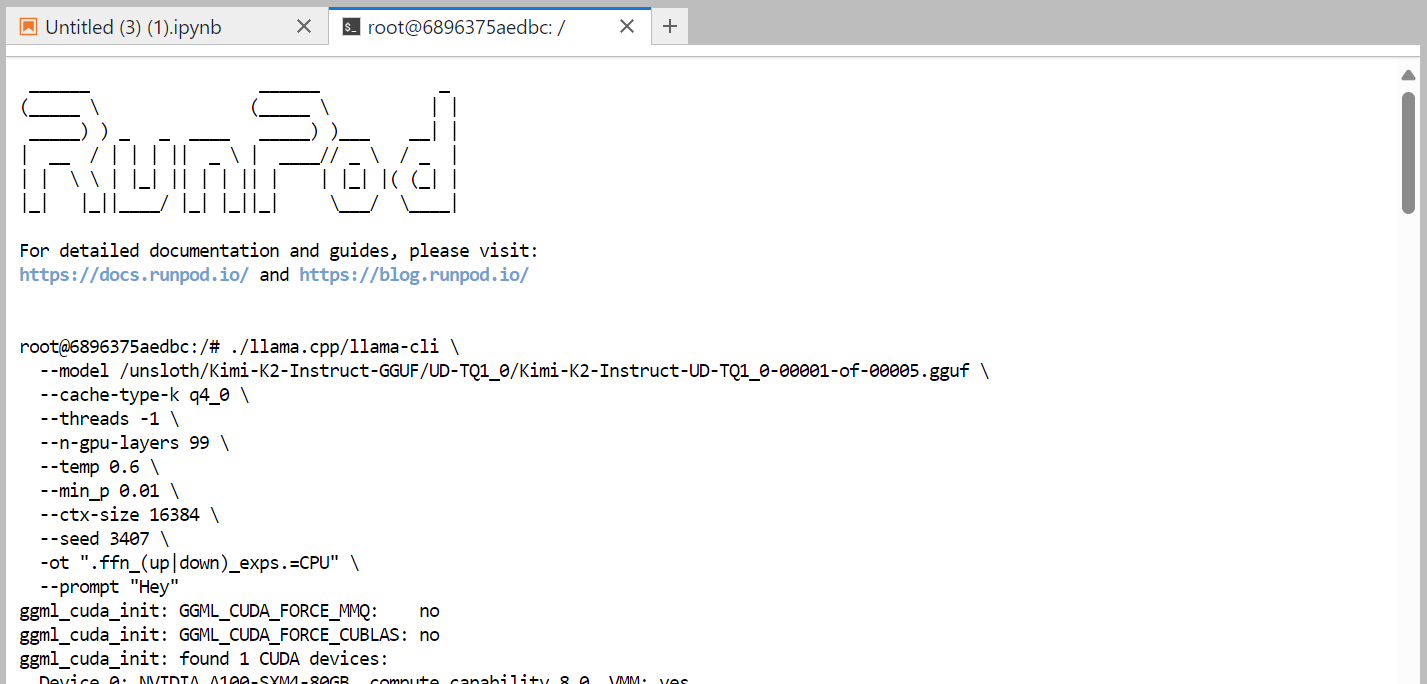
Es hat fast eine Minute gedauert, bis das ganze Modell geladen war. Wie wir sehen können, passt das Modell perfekt in die Maschine.

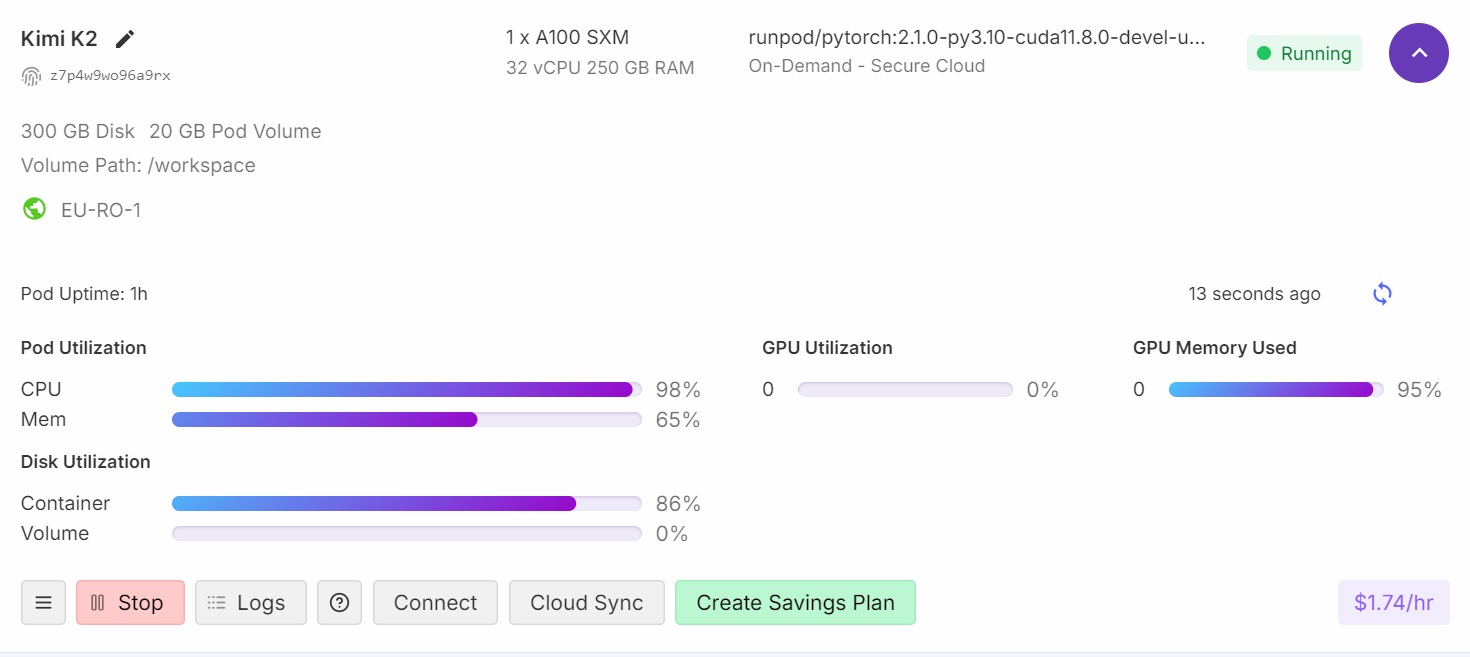
Wenn du dein Runpod-Dashboard checkst, wirst du sehen, dass deine CPU-Auslastung hoch ist und sowohl RAM- als auch VRAM-Speicher genutzt werden.
Nach etwa vier Minuten Ladezeit und Aufwärmphase kannst du dem Modell Fragen stellen.

Ich hab eine einfache Frage gestellt: Was ist Monsun? Schreib die Antwort in eine Zeile.

Die Erstellung hat fast fünf Minuten gedauert.
Ich hab mal nachgeschaut, warum die Token-Generierung so langsam ist, und es hat sich rausgestellt, dass die GPU nur als Speicher genutzt wird, während die CPU die ganze Verarbeitung macht. Um das Problem zu lösen, musst du mehr Schichten auf die GPU auslagern, was bedeutet, dass du zwei A100-Maschinen brauchst.
In diesem Abschnitt schauen wir uns die typischen Probleme an, die beim Ausführen eines großen Modells auf einer einzelnen GPU auftreten können, und wie du sie lösen kannst.
Wenn du 95 % GPU-RAM-Auslastung, 0 % GPU-Rechenleistung und 99 % CPU-Auslastung siehst, heißt das normalerweise, dass der VRAM als Speicher für das Modell genutzt wird, während die eigentliche Verarbeitung auf der CPU läuft.
Selbst hoch quantisierte und kleinere 1-Bit-Modelle müssen immer noch in den Speicher geladen werden, was den VRAM-Verbrauch erhöht. Die GPU-Auslastung für Berechnungen beginnt erst, wenn du mehr Ebenen in den VRAM auslagerst.
Um die Geschwindigkeit der Token-Generierung zu verbessern, musst du mehr Schichten des Modells auf die GPU auslagern. Vielleicht solltest du mal über eine Multi-GPU-Konfiguration nachdenken, zum Beispiel drei A100-GPUs. Stell die Temperatur auf 0,6 ein, um Wiederholungen und Unstimmigkeiten im generierten Text zu reduzieren.
Wenn du nur wenig VRAM oder RAM hast, kannst du trotzdem 1-Bit-Modelle auf einer normalen CPU laufen lassen. Allerdings wird die Token-Generierung echt langsam sein (z. B. 1 Token alle 20 Sekunden).
Die einzige wichtige Sache für 1-Bit-Modelle ist, dass dein Speicherplatz + RAM + VRAM zusammen mindestens 250 GB haben muss.
Für die beste Leistung (5+ Tokens/Sekunde) brauchst du mindestens 250 GB einheitlichen Speicher oder insgesamt 250 GB RAM und VRAM.
Installier die neueste Version von huggingface_hub und hf_transfer, um auf „xnet speed“ zuzugreifen, das viermal schneller ist als einfaches Git LFS.
Um die Speicherung und das Laden von GGUF-Shard-Dateien zu optimieren, solltest du lieber eine Container-Festplatte statt eines Container-Volumes zum Speichern nehmen. Das liegt daran, dass Container-Volumen zu langsamen Downloads und zum langsamen Laden von Modellen führen können.
Wenn ein Modell langsam geladen wird, ist es wahrscheinlich ziemlich groß. Das Laden von Modellen aus dem Netzwerkspeicher kann den Ladevorgang echt verlangsamen. Speicher deine Modelle immer auf einer lokalen M.2-SSD. M.2 SSDs sind viel schneller beim Lesen und Schreiben als normale Festplatten oder Netzwerkspeicher, was die Ladezeiten echt verkürzt.
Wenn nicht genug RAM zum Laden des Modells da ist, kann das Betriebssystem anfangen, Daten auf die Festplatte zu verschieben (mit einer Auslagerungsdatei), was viel langsamer ist als RAM und einen Engpass verursacht. Versuch mal, mehrere GPUs mit mehr RAM zu verwenden.
Beim Ausführen quantisierter Versionen von Kimi K2 kann es immer noch zu Problemen kommen, da Tools wie llama.cpp ständig weiterentwickelt werden, um mit den neuesten Updates des Modells Schritt zu halten. In den nächsten Wochen gibt's bessere Lösungen, die die Berechnungen für die Token-Generierung auf GPUs verlagern, um die Leistung zu verbessern, anstatt nur auf CPUs zu setzen.
Außerdem war das eine echt gute Erfahrung für mich. Ich hab einen guten Einblick bekommen, wie die Open-Source-Community zusammenarbeitet, um diese Modelle so effizient wie möglich zu optimieren und einzusetzen.
Kimi K2 ist echt ein Top-Open-Source-Modell und kommt an die Fähigkeiten von Modellen wie DeepSeek R1 ran. Es hat die aktuellste Performance in Sachen Grenzbereichswissen, Mathe und Codierung unter den nicht denkenden Modellen.
Es ist besonders gut bei der Werkzeugauswahl und agentenbezogenen Aufgaben, was es zu einer coolen Alternative zu Premium-Modellen wie Claude 4 Sonnet macht. Claude 4 Sonnet für Codierungsprojekte oder Vibe-Codierung.
Mit dieser Anleitung kannst du die quantisierte Version des Kimi K2 für deine eigenen Lösungen nutzen. Mit Llama.cpp kannst du die Sprachmodelle als API mit OpenAI-Kompatibilität bereitstellen. Wenn du mehr erfahren möchtest, schau dir unbedingt unsere Kimi K2-Handbuch mit Beispielen. Wenn du mehr über agentenbasierte KI erfahren möchtest, solltest du dir unseren neuen Kurs zum Thema Aufbau von Multiagentensystemen mit LangGraph.
Die besten KI-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Stephen Gruppetta
