
Curso
Trabalhando com Llama 3
2 h
13.8K
O Kimi K2, criado pela Moonshot AI, é um modelo de linguagem Mixture-of-Experts (MoE) super avançado. É super bom em conhecimento de ponta, raciocínio e tarefas de codificação, e é especialmente otimizado para capacidades de agente, incluindo uso de ferramentas e resolução autônoma de problemas.
Conforme a gente vê no nosso guia do Kimi K2, o modelo está conseguindo resultados incríveis em testes de benchmark, tornando-o o melhor modelo de linguagem de código aberto para uso geral. Estamos vendo o momento do Deepseek R1, e pra comemorar, vou te ensinar como rodar esse modelo enorme de 1 terabyte em uma única GPU.
Vamos aprender como configurar a máquina Runpod, instalar o llama.cpp e baixar o modelo mais rápido. Além disso, vamos rodar o modelo usando a CLI llama.cpp, transferindo as camadas do modelo para a RAM. Por fim, vamos falar sobre os problemas comuns que aparecem quando a gente usa esses modelos.
Vá para o Runpod GPU Cloud e crie uma nuvem com a máquina A100 SXM usando a imagem de contêiner Python versão 2.8.0.
Depois disso, aumente o armazenamento do disco do contêiner para 300 GB usando a opção Editar pod.
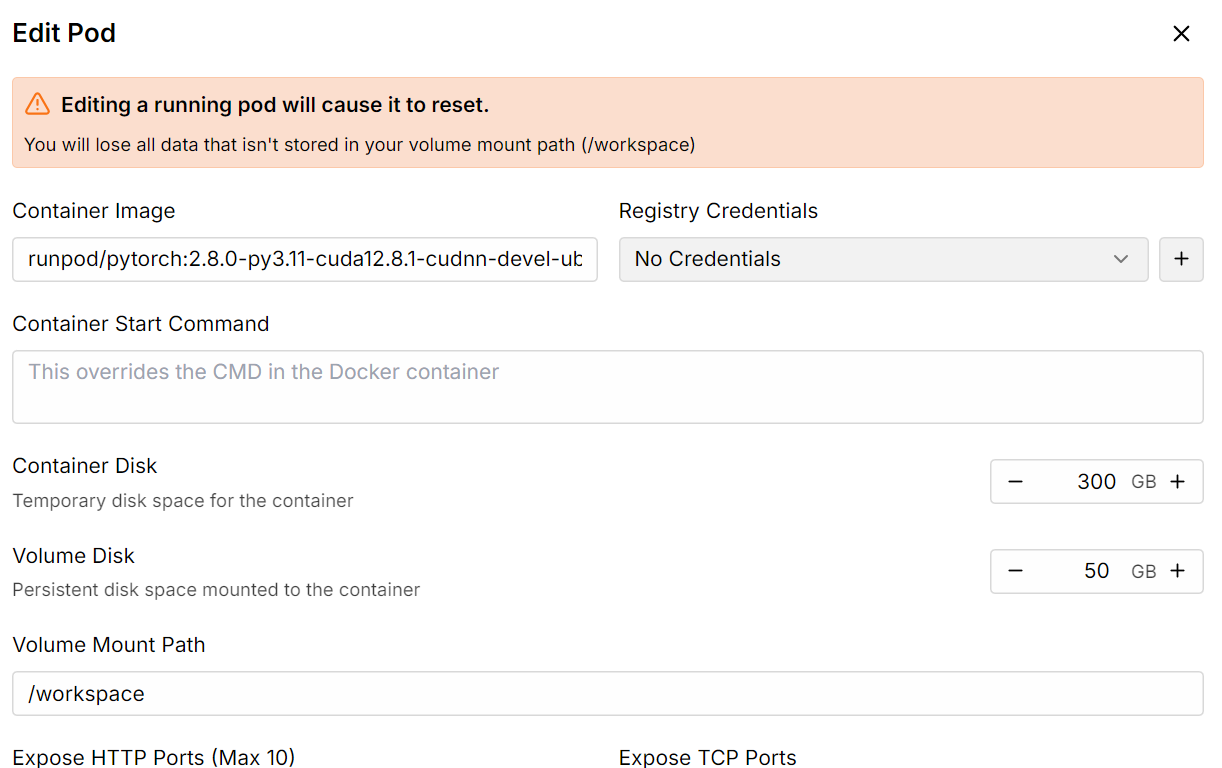
Depois que tudo estiver pronto, você vai ver que tem 300 GB de espaço, o que é suficiente, já que nosso modelo quantizado de 1 bit precisa de 250 GB.
1. Clique no botão “Conectar” e abra o Jupyter Lab. Crie um novo notebook e instale as ferramentas Linux necessárias, como cmake e curl.
!apt-get update
!apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
2. Mude o diretório para a raiz. Não vamos usar o diretório da área de trabalho. Isso é pra aumentar a velocidade de download e carregamento do modelo. Você vai saber mais sobre isso na seção de solução de problemas no final.
%cd ..3. Clone a versão mais recente do repositório llama.cpp.
!git clone https://github.com/ggml-org/llama.cpp
4. Configure as opções de compilação. Estamos executando a compilação para uma máquina com GPU. Se você quiser usar a inferência da CPU, troque DGGML_CUDA=ON por DGGML_CUDA=OFF.
!cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DLLAMA_CURL=ON \
-DCMAKE_CUDA_ARCHITECTURES="80;90" \
-DCMAKE_CUDA_FLAGS="-Wno-deprecated-gpu-targets"
5. Vamos usar o comando “ cmake ” para compilar as ferramentas: “ llama-quantize ”, “ llama-cli ”, “ llama-gguf-split ” e “ llama-mtmd-cli ”.
!cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split llama-mtmd-cli
6. Copie todas as ferramentas de compilação para o repositório principal para que possamos acessá-las facilmente.
!cp llama.cpp/build/bin/llama-* llama.cppAs versões quantizadas do modelo Kimi K2 da Unsloth suportam xnet, que permite downloads e uploads 4 vezes mais rápidos que o Git LFS. Para ativá-lo localmente, instale a versão mais recente do huggingface_hub e hf_transfer:
!pip install huggingface_hub hf_transfer
Use a API snapshot_download para baixar só os arquivos do modelo GGUF quantizado de 1 bit para o repositório:
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/Kimi-K2-Instruct-GGUF",
local_dir = "/unsloth/Kimi-K2-Instruct-GGUF",
allow_patterns = ["*UD-TQ1_0*"],
)O download pode demorar um pouco, dependendo da velocidade da sua internet e do espaço disponível no seu dispositivo.
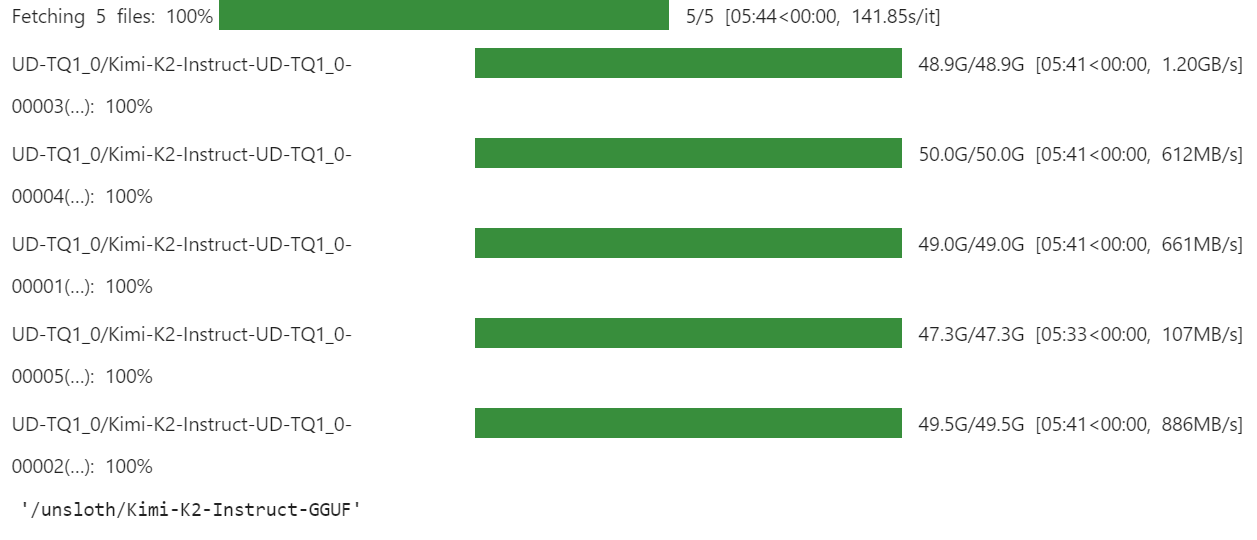
Para nós, foi super rápido, porque temos soluções de armazenamento mais rápidas com o xnet ativado.
É hora de testar nossa versão quantizada do modelo. Essa é a parte em que passei a maior parte do tempo depurando, porque estou tentando rodar em uma única GPU. Embora isso não seja impossível, há vários problemas relacionados ao carregamento e execução do modelo.
Estamos usando todos os threads da CPU e maximizando o carregamento de camadas para a GPU, o que envolve a descarga da CPU das camadas de projeção ascendente e descendente da Mistura de Especialistas.
Aqui tá o comando que a gente tá rodando no terminal, que funciona direitinho:
./llama.cpp/llama-cli \
--model /unsloth/Kimi-K2-Instruct-GGUF/UD-TQ1_0/Kimi-K2-Instruct-UD-TQ1_0-00001-of-00005.gguf \
--cache-type-k q4_0 \
--threads -1 \
--n-gpu-layers 99 \
--temp 0.6 \
--min_p 0.01 \
--ctx-size 16384 \
--seed 3407 \
-ot ".ffn_(up|down)_exps.=CPU" \
--prompt "Hey"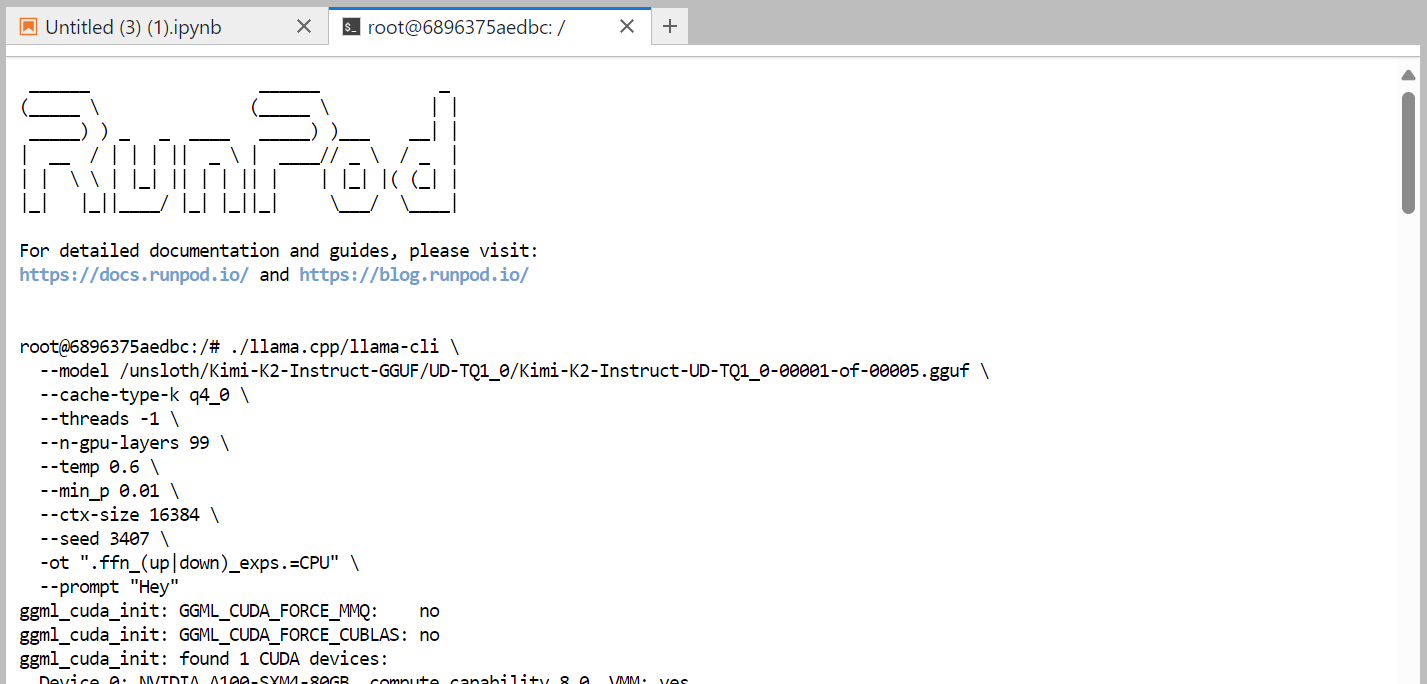
Demorou quase um minuto para carregar o modelo completo. Como dá pra ver, o modelo se encaixa direitinho na máquina.

Se você der uma olhada no painel do Runpod, vai ver que o uso da CPU tá alto e que tanto a memória RAM quanto a VRAM estão sendo usadas.
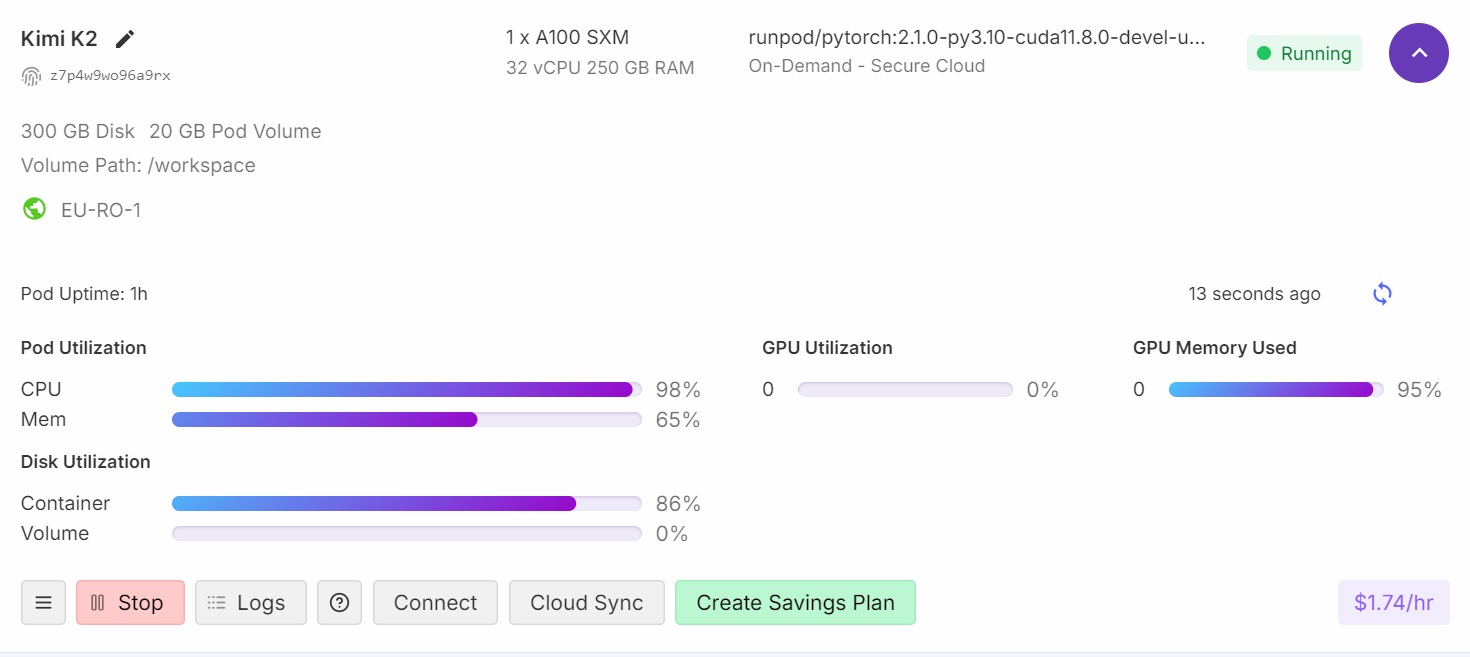
Depois de uns quatro minutos de carregar e aquecer, você tá pronto pra fazer perguntas pra modelo.

Fiz uma pergunta simples: O que é a monção? Escreva a resposta em uma linha.

Demorou quase cinco minutos pra terminar de gerar.
Fiz uma pesquisa pra entender por que a geração de tokens tá lenta e descobri que a GPU só tá sendo usada como memória, enquanto todo o processamento é feito pela CPU. Para resolver isso, você precisa transferir mais camadas para a GPU, o que significa que vai precisar de duas máquinas A100.
Nesta seção, vamos falar sobre os problemas comuns que aparecem quando você roda um modelo grande em uma única GPU e como você pode resolver isso.
Quando você vê 95% de uso da RAM da GPU, 0% de computação da GPU e 99% de carga da CPU, isso normalmente significa que a VRAM está agindo como armazenamento de memória para o modelo, enquanto o processamento real está acontecendo na CPU.
Mesmo os modelos altamente quantizados e menores de 1 bit ainda precisam ser carregados na memória, o que aumenta o uso da VRAM. A GPU só vai começar a ser usada pra computação se você mandar mais camadas pra VRAM.
Para melhorar a velocidade de geração de tokens, você precisa transferir mais camadas do modelo para a GPU. Talvez seja uma boa ideia pensar em uma configuração com várias GPUs, tipo três GPUs A100. Defina a temperatura para 0,6 para ajudar a reduzir a repetição e a incoerência no texto gerado.
Se você tem pouca VRAM ou RAM, ainda pode rodar modelos de 1 bit em um processador comum. Mas, a geração de tokens vai ser bem lenta (por exemplo, 1 token a cada 20 segundos).
A única regra pra rodar modelos de 1 bit é que o total de espaço no disco + RAM + VRAM seja maior ou igual a 250 GB.
Pra um desempenho legal (mais de 5 tokens por segundo), você vai precisar de pelo menos 250 GB de memória unificada ou um total de 250 GB de RAM e VRAM.
Instale a versão mais recente do huggingface_hub e hf_transfer para acessar o “xnet speed”, que é 4 vezes mais rápido que o Git LFS simples.
Para otimizar o armazenamento e o carregamento de arquivos fragmentados GGUF, é melhor usar um disco de contêiner para armazenamento em vez de um volume de contêiner. Isso acontece porque o tamanho dos contêineres pode deixar o download e o carregamento do modelo bem lentos.
Se o modelo demora pra carregar, pode ser que ele seja muito grande. Carregar modelos do armazenamento em rede pode deixar o processo de carregamento bem mais lento. Sempre use um SSD M.2 local pra guardar seus modelos. Os SSDs M.2 são muito mais rápidos pra ler e gravar do que os discos rígidos tradicionais ou o armazenamento em rede, o que deixa o tempo de carregamento bem menor.
Se não tiver RAM suficiente pra carregar o modelo, o sistema operacional pode começar a trocar dados pro disco (usando um arquivo de troca), o que é bem mais lento que a RAM e cria um gargalo. Tenta montar um sistema com várias GPUs e mais memória RAM.
A execução de versões quantizadas do Kimi K2 ainda pode apresentar desafios, pois ferramentas como llama.cpp estão sempre mudando pra acompanhar as últimas atualizações do modelo. Nas próximas semanas, a gente vai lançar soluções melhoradas que vão passar os cálculos de geração de tokens para GPUs, pra ter um desempenho melhor, em vez de depender só das CPUs.
Além disso, essa experiência foi super valiosa pra mim. Eu aprendi como a galera do código aberto trabalha junto pra otimizar e implementar esses modelos da melhor maneira possível.
O Kimi K2 é um dos melhores modelos de código aberto, quase chegando ao nível de modelos como o DeepSeek R1, com desempenho de ponta em conhecimento de ponta, matemática e codificação entre os modelos não pensantes.
É super forte na escolha de ferramentas e tarefas de agência, o que o torna uma opção econômica em comparação com modelos premium como o Claude 4 Sonnet para projetos de codificação ou codificação vibe.
Você pode usar a versão quantizada do Kimi K2 nas suas soluções internas seguindo este guia. O Llama.cpp permite que você use os modelos de linguagem como uma API compatível com o OpenAI. Para continuar aprendendo mais, não deixe de conferir nosso guia do Kimi K2 com exemplos. Se você quer saber mais sobre IA agênica, não deixe de fazer nosso novo curso sobre construção de sistemas multiagentes com LangGraph.
Os melhores cursos de IA
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Tutorial
Zoumana Keita
Tutorial
Tutorial
Aashi Dutt


